Hast du dich schon mal auf einer Webseite wiedergefunden, auf der kaum Infos direkt sichtbar sind und du dich durch unzählige Links klicken musst, um an die gewünschten Daten zu kommen? Das kostet nicht nur Zeit, sondern ist mittlerweile fast schon Standard, weil viele Seiten wichtige Details auf Unterseiten verstecken. Gerade wenn du größere Datenmengen sammeln willst, wird das schnell zur echten Geduldsprobe. Entwickler stecken viel Zeit in eigene Skripte, um diese Unterseiten abzugrasen, während alle ohne Programmierkenntnisse jeden Link einzeln öffnen müssen. Doch es gibt eine Lösung: List Crawling (auch Bulk Scraping genannt) und Subpage Scraping.
List Crawling und Subpage Scraping im Überblick
| Tool | Benutzerfreundlichkeit | Datenqualität | Idealer Anwendungsfall |
|---|---|---|---|
| List Crawling | ★★ | ★★★ | Umfangreiche Webseiten |
| Subpage Scraping | ★★★★★ | ★★★★ | Schnelles Scraping, spezielle Datenformate |
Was steckt hinter List Crawling?
Was bedeutet List Crawling?
List Crawling, auch als Bulk Scraping bekannt, ist eine Methode, bei der Daten aus einer Liste von URLs gesammelt werden. Am Anfang steht eine Sammlung von Ziel-URLs, die oft mit einem separaten Crawler erstellt wird. Die Qualität dieser Liste ist entscheidend: Wenn die Links auf Seiten mit unterschiedlichen Strukturen führen, wird das Ergebnis schnell unübersichtlich und die Nachbearbeitung aufwendig. Diese Methode ist besonders für Unternehmen, Forschende und Datenanalysten interessant, die große Mengen an strukturierten und einheitlichen Webdaten brauchen. Allerdings ist meist noch Handarbeit nötig, um die Daten zu sortieren und optimal weiterzuverwenden.
So läuft List Crawling ab

Beim List Crawling gehst du in der Regel so vor:
- URL-Liste zusammenstellen: Zuerst sammelst du alle Ziel-URLs, die du auslesen willst.
- HTTP-Anfragen schicken: Das Tool ruft die Webseiten per HTTP ab und lädt den HTML-Code.
- Daten herausziehen: Mit Parsing-Methoden wie BeautifulSoup, XPath oder regulären Ausdrücken filterst du die gewünschten Infos wie Texte, Bilder oder Links heraus.
- Daten abspeichern: Die gesammelten Daten landen dann in einer Datenbank oder Tabelle, zum Beispiel in Excel.
Nach dem Sammeln solltest du die Daten noch aufbereiten und analysieren – zum Beispiel mit Statistik, Zeitreihenanalysen, Korrelationen oder Clustering. Künstliche Intelligenz kann diesen Prozess deutlich beschleunigen, indem sie Aufgaben automatisiert und die Datenqualität verbessert.
Für besonders komfortables Arbeiten empfiehlt sich die Bulk Scraping-Funktion im Thunderbit KI-Web-Scraper.
Empfohlene Tools
-
- Vorteile: Einfache Bedienung, flexible Datenerfassung, starke Features
- Nachteile: Lokale Ausführung und Browser nötig
- Ideal für: Hochwertige Datensammlung mit Fokus auf Datenqualität
- Scrapy
- Vorteile: Sehr leistungsstark, individuell anpassbar, für große Datenmengen geeignet
- Nachteile: Hohe Einstiegshürde, Programmierkenntnisse erforderlich
- Ideal für: Umfangreiche Datenprojekte
- Beautiful Soup
- Vorteile: Leicht zu nutzen, gute Dokumentation, flexibel beim Extrahieren
- Nachteile: Durchschnittliche Performance, keine Unterstützung für asynchrone Abläufe
- Ideal für: Kleine Scraping-Projekte, Datenanalyse
- Selenium
- Vorteile: Unterstützt dynamische Webseiten, kann Nutzeraktionen simulieren
- Nachteile: Langsam, braucht viele Ressourcen
- Ideal für: Webseiten mit viel JavaScript
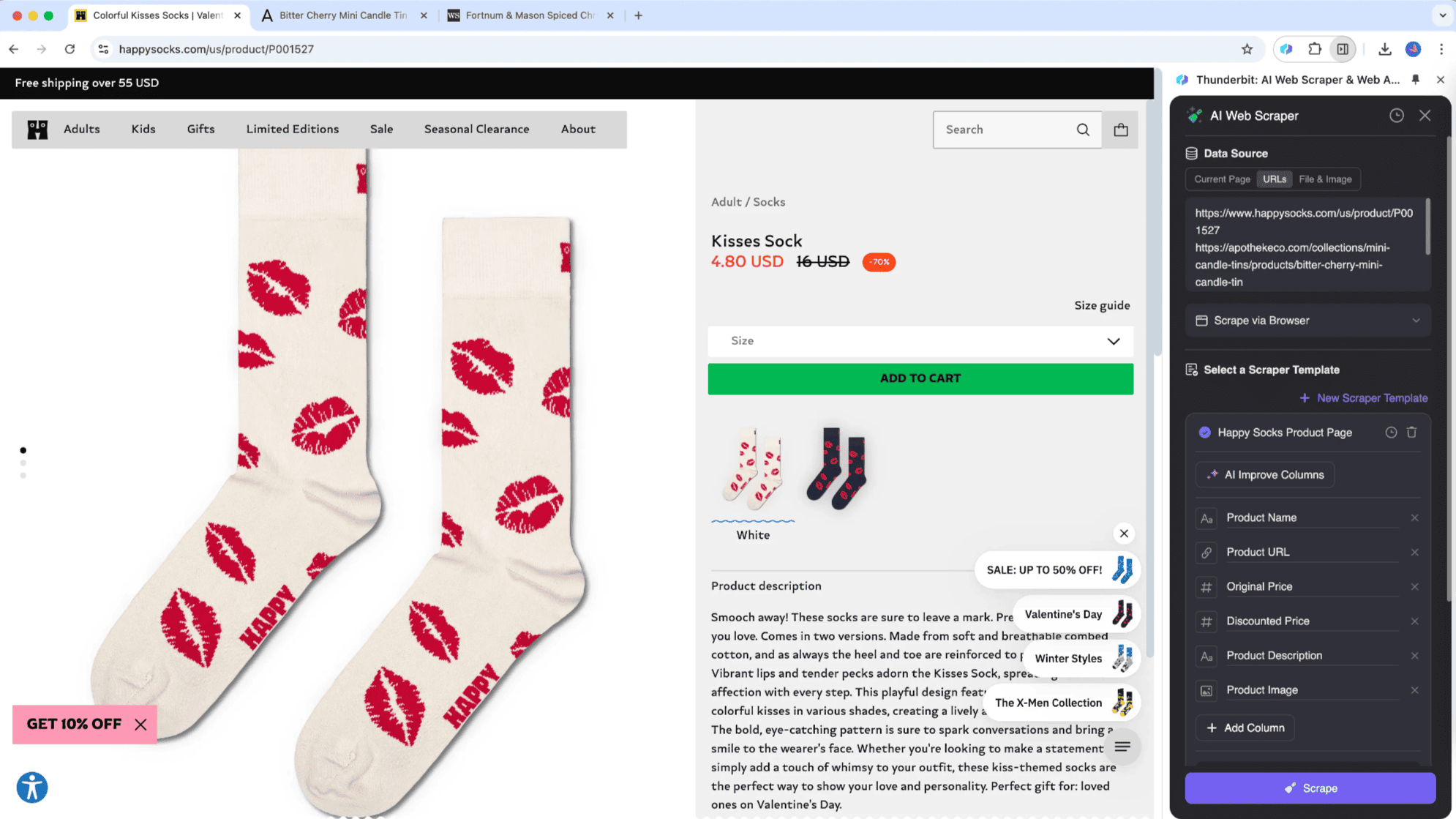
Subpage Scraping im Detail

Was ist Subpage Scraping?
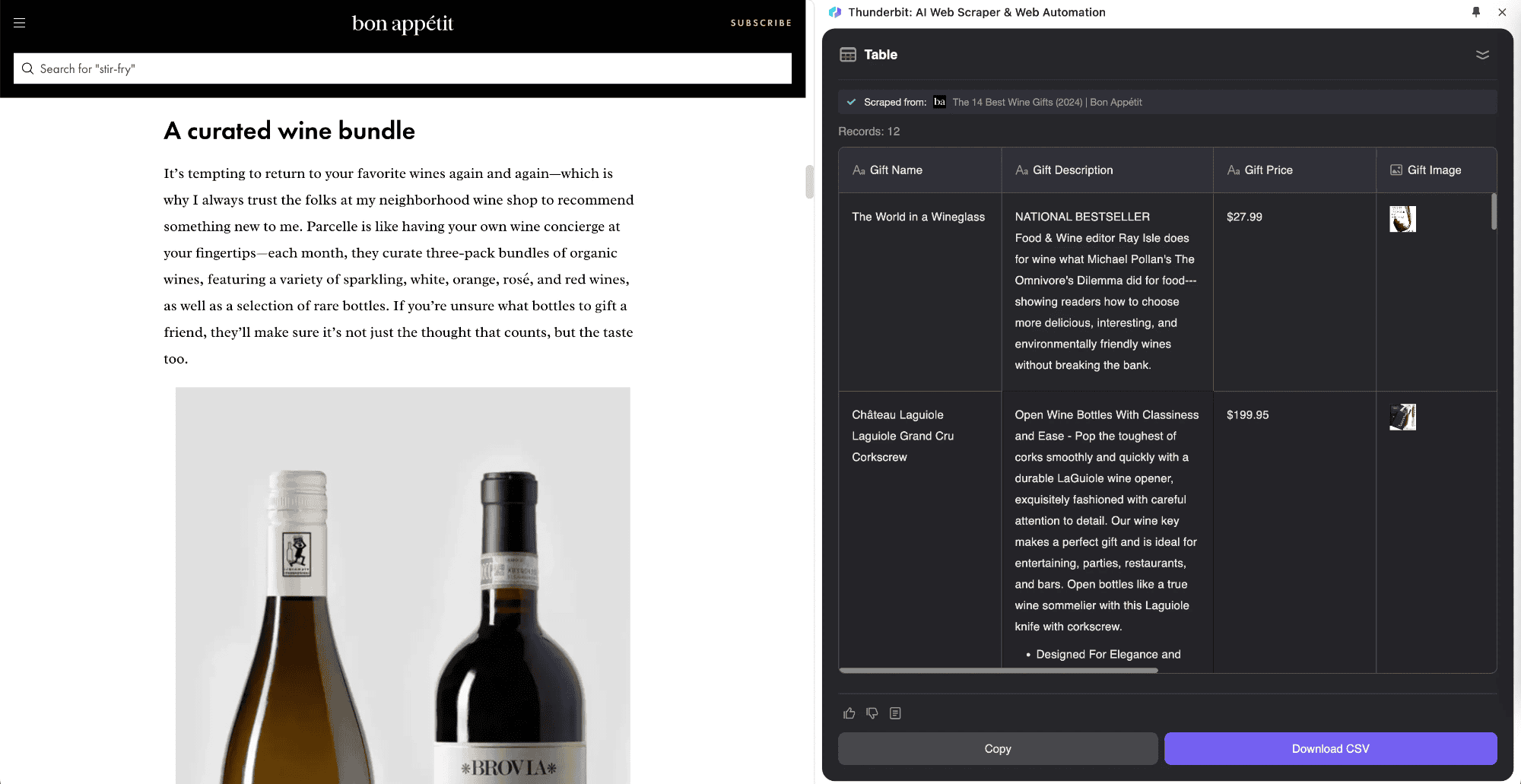
Subpage Scraping ist eine Technik, bei der Listen-Daten von einer Hauptseite gesammelt und Infos aus Unterseiten direkt in eine zentrale Tabelle übernommen werden. Thunderbit hat diesen cleveren Ansatz mit den KI-Funktionen seines KI-Web-Scrapers eingeführt. Besonders praktisch ist das für Seiten mit vielen Unterseiten, wie Produktübersichten, Blogs oder Navigationsseiten. Der große Vorteil: Subpage Scraping sammelt und verarbeitet die Infos aus den Unterseiten automatisch und fügt sie direkt in die Haupttabelle ein.
Ein Beispiel: Du liest einen Artikel wie „Aktuelle Börsenkurse“ und willst alle Aktienkurse extrahieren. Mit dem kannst du eine Tabelle anlegen, die automatisch die Kurse sammelt, die jeweiligen Detailseiten öffnet und die Daten in deine Haupttabelle übernimmt. So bekommst du gezielt die Infos, die du brauchst, während du Nachrichten liest. Thunderbits KI-Web-Scraper passt sich dabei flexibel an verschiedene Seitenstrukturen an – ein klarer Vorteil gegenüber klassischen Scraping-Tools.
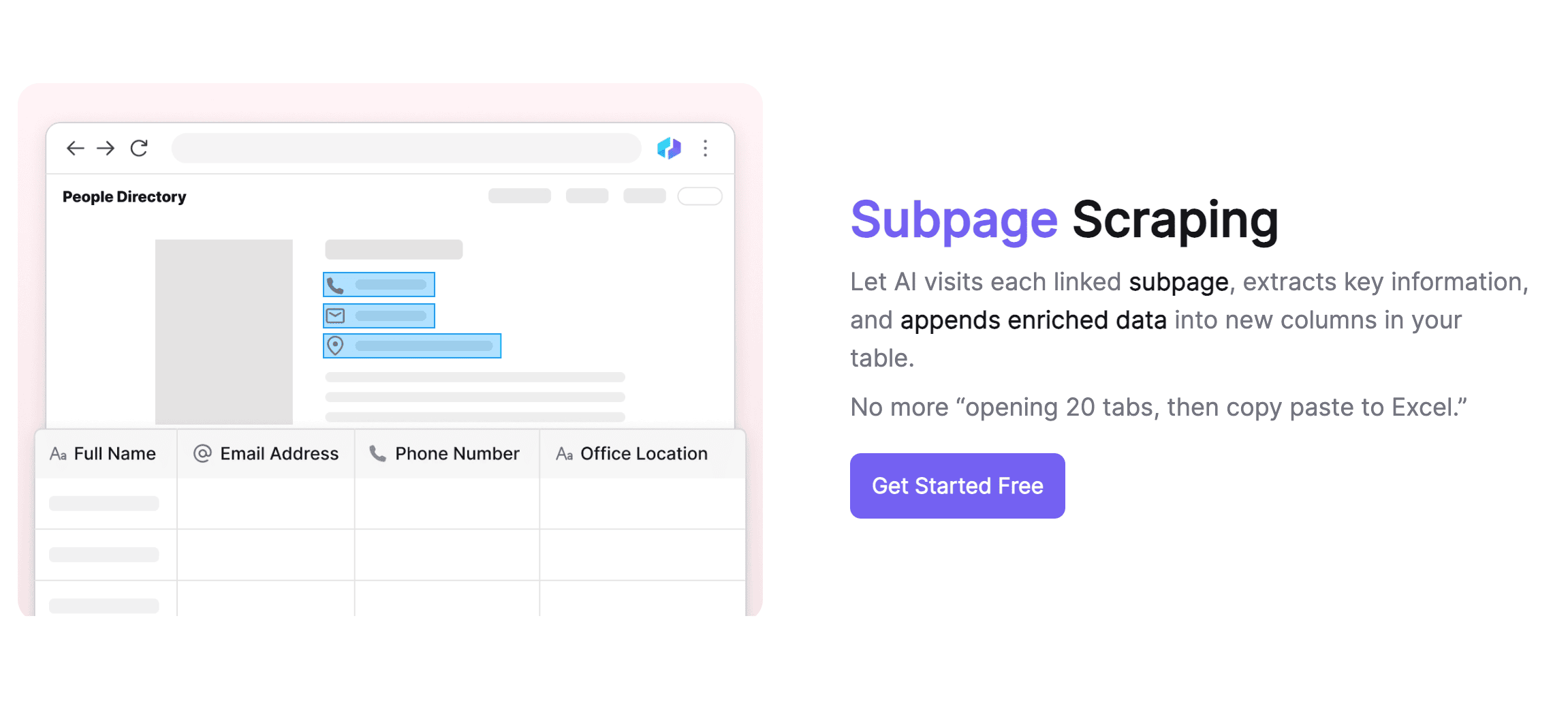
Warum Subpage Scraping nutzen?
Der Thunderbit KI-Web-Scraper bringt viele Features mit, die die Effizienz und Genauigkeit beim Datensammeln deutlich steigern.
Intelligente Datenerfassung
Thunderbit setzt auf KI-gestützte Datenerfassung, die sich automatisch an Änderungen im Webseitenaufbau anpasst. Du kannst einfach in Alltagssprache beschreiben, welche Daten du brauchst – die passenden Extraktionsregeln werden automatisch erstellt. Das macht die Datensammlung nicht nur genauer, sondern auch für Nicht-Techniker super einfach. Thunderbit unterstützt verschiedene Datentypen wie Text, Links und Bilder und ist damit für viele Einsatzzwecke geeignet.
Cleveres Subpage-Handling
Thunderbit glänzt besonders beim Umgang mit Unterseiten. Die KI erkennt und öffnet Subpages automatisch und kann mit nur einer Vorlage verschiedene Layouts verarbeiten. Selbst wenn sich der Seitenaufbau ändert, bleibt die Extraktion stabil. Die Inhalte der Unterseiten landen automatisch in der Haupttabelle, was die Organisation der Daten enorm erleichtert. Außerdem sorgt Thunderbit für hohe Datenqualität, indem es wie ein KI-Assistent Daten bereinigt, formatiert und wiederkehrende Aufgaben wie das Labeln übernimmt.
Effizientes Datenmanagement
Thunderbit bietet flexible Möglichkeiten zur Datenverwaltung und unterstützt verschiedene Exportformate sowie die Anbindung an Plattformen wie Google Sheets, Airtable oder Notion. So kannst du zum Beispiel eine Scraper-Vorlage direkt mit einer Google-Tabelle verknüpfen oder die Daten in einer Notion-Datenbank organisieren. Diese Exportoptionen machen es leicht, die gesammelten Daten weiterzuverarbeiten. Auch individuelle Datenkennzeichnung und -klassifizierung lassen sich automatisch an die Anforderungen der jeweiligen Plattform anpassen – für ein effizientes Datenmanagement.
Praktische Vorlagen für den Alltag
Um dir die Arbeit noch weiter zu erleichtern, stellt Thunderbit viele vorgefertigte Templates bereit. Diese decken Bereiche wie E-Commerce (z. B. , ), Immobilien (z. B. ), Social Media (z. B. , ) und Unternehmensdaten ab. Die Templates sparen Zeit und sorgen für konsistente, zuverlässige Ergebnisse.
Schritt-für-Schritt-Anleitung
Subpage Scraping umsetzen
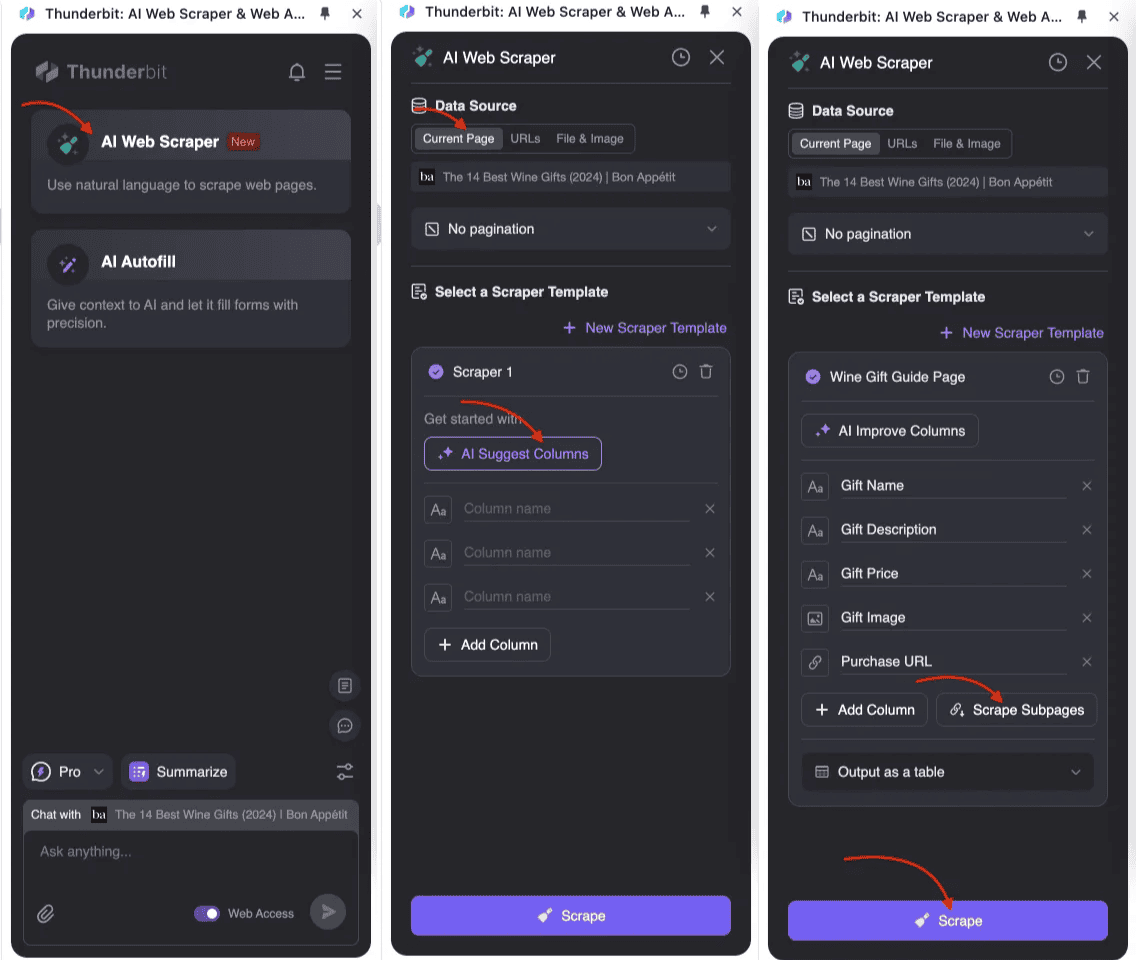
- : Starte den Thunderbit KI-Web-Scraper und leg eine neue Scraper-Vorlage an.
- Haupttabelle anlegen: Definiere in den Tabelleneinstellungen die gewünschten Felder wie Titel, Preis oder Beschreibung. Für Daten aus Unterseiten fügst du entsprechende Felder hinzu und aktivierst das Subpage Scraping.
- Scraper starten: Thunderbit sammelt zuerst die Listendaten von der Hauptseite, besucht dann automatisch jede Unterseite, holt sich die relevanten Infos und trägt sie in die Haupttabelle ein. Das Ganze läuft KI-gestützt und ohne komplizierte Programmierung.
List Crawling in der Praxis
Für Entwickler gibt es verschiedene Programmiersprachen und Tools, um List Crawling umzusetzen. Besonders beliebt ist Python, weil es leicht zu lernen ist und viele Bibliotheken bietet. Hier ein einfaches Beispiel mit requests und BeautifulSoup:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Beispielaufruf
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Fazit
Daten sind heute das Fundament erfolgreicher Unternehmen. Wer es schafft, Infos effizient zu sammeln und auszuwerten, verschafft sich einen echten Vorsprung. Daten helfen, Markttrends und Kundenwünsche zu erkennen und liefern wertvolle Impulse für Produktentwicklung und Marketing. Doch die gezielte Sammlung und Organisation der riesigen, verstreuten Datenmengen im Netz ist eine echte Herausforderung.
Mit Tools wie Thunderbit müssen sich Unternehmen keine Sorgen mehr um die Datensammlung machen. Es ist wie ein verlässlicher Assistent, der aus riesigen Datenmengen gezielt die wichtigsten Infos herausfiltert und so fundierte Entscheidungen ermöglicht. Dank intelligenter Datenerfassung und -verarbeitung bekommen Unternehmen schnell Zugriff auf Wettbewerbsanalysen, Markttrends, Nutzerbewertungen und vieles mehr – für bessere Geschäftsentscheidungen.
Thunderbit überzeugt nicht nur mit komfortabler Datensammlung, sondern auch mit starker Datenaufbereitung und Analyse. Die gesammelten Daten werden automatisch bereinigt und strukturiert, sodass anschauliche Berichte entstehen, die verborgene Zusammenhänge sichtbar machen. Für Unternehmen, die regelmäßig Marktentwicklungen beobachten, ist die automatisierte Datensammlung von Thunderbit ein echter Zeitgewinn.
Im digitalen Zeitalter ist ein Tool wie Thunderbit ein echter Pluspunkt. Es steigert die Effizienz der Datensammlung und unterstützt Unternehmen bei der digitalen Transformation. Da Daten für Geschäftsentscheidungen immer wichtiger werden, sind smarte Tools wie Thunderbit ein echter Wettbewerbsvorteil.
Häufige Fragen (FAQ)
-
Was ist Thunderbit? ist eine Chrome-Erweiterung, die Geschäftsanwendern hilft, Webaufgaben zu automatisieren. Zu den Funktionen gehören KI-Web-Scraper, KI-Clipboard und KI-Web-Chat, mit denen du Daten extrahieren, Formulare ausfüllen und Webseiten per KI zusammenfassen kannst. Das Tool spart Zeit und macht wiederkehrende Online-Aufgaben deutlich einfacher.
-
Wie funktioniert der KI-Web-Scraper von Thunderbit? Der KI-Web-Scraper von Thunderbit nutzt künstliche Intelligenz, um strukturierte Daten von Webseiten zu extrahieren. Mit „AI Suggest Columns“ schlägt die KI automatisch vor, wie die aktuelle Seite am besten ausgelesen werden kann. Mit einem Klick auf „Scrape“ werden die Daten gesammelt – egal ob von Webseiten, PDFs oder Bildern, und das in nur zwei Schritten.
-
Was ist der Unterschied zwischen List Crawling und Subpage Scraping? Beim List Crawling (Bulk Scraping) werden Daten aus einer Liste von URLs extrahiert – ideal für große Webseiten. Subpage Scraping hingegen sammelt Daten von einer Hauptseite und deren Unterseiten und führt die Infos in einer zentralen Tabelle zusammen. Thunderbits KI-Web-Scraper kann beides und bietet intelligente Datenextraktion und -verwaltung.
-
Können auch Nicht-Programmierer Thunderbit nutzen? Klar! Thunderbit ist so gestaltet, dass auch Nutzer ohne Programmierkenntnisse problemlos damit arbeiten können. Dank KI kannst du einfach in natürlicher Sprache beschreiben, welche Daten du brauchst – die Extraktionsregeln werden automatisch erstellt.
-
Welche Datentypen unterstützt Thunderbit? Thunderbit kann verschiedene Datentypen wie Text, Links und Bilder verarbeiten. Damit eignet es sich für E-Commerce, Immobilien, Social Media und Unternehmensdaten gleichermaßen.
-
Wie starte ich mit Thunderbit? Lade einfach die Thunderbit Chrome-Erweiterung von der herunter. Nach der Installation kannst du die Features wie KI-Web-Scraper, KI-Clipboard und KI-Web-Chat direkt nutzen und deine Produktivität steigern.
-
Gibt es vorgefertigte Templates bei Thunderbit? Ja, Thunderbit bietet viele für verschiedene Bereiche wie E-Commerce, Immobilien, Social Media und Unternehmensdaten. Diese Vorlagen sparen Zeit und sorgen für konsistente, zuverlässige Ergebnisse.
-
Wie stellt Thunderbit die Datenqualität sicher? Thunderbit nutzt KI, um Daten intelligent zu extrahieren und zu verarbeiten. Die Software passt sich automatisch an Änderungen im Webseitenaufbau an und bietet Features zur Datenbereinigung und -formatierung – wie ein KI-Assistent, der wiederkehrende Aufgaben übernimmt und die Datenqualität verbessert.
-
Anwendungsbeispiele für Web-Scraping Es gibt viele Einsatzmöglichkeiten für : Du kannst zum Beispiel oder . Viele Unternehmen sammeln zur Analyse. Mit KI-basierten Tools kannst du heute – ganz ohne komplizierte Programmierung. Für Social-Media-Analysen eignen sich spezialisierte Tools wie oder , um gezielt Daten für Marketingkampagnen zu sammeln.
Mehr erfahren: