
Alle wollen datengetrieben arbeiten. In der Praxis scheitert es aber oft schon an der Datenerfassung: zu viele Quellen, zu viel Copy-and-Paste, zu viele Formate, die nicht zusammenpassen. Wenn du schon einmal Kontakte, Preise, Produktdaten oder Bewertungen manuell aus Webseiten in eine Tabelle übertragen hast, kennst du das Problem. Genau hier setzt Data Scraping an.
💡 In diesem Beitrag geht es darum, was Data Scraping ist, wie sich die Technologie verändert hat und warum KI-gestütztes Scraping für Teams in Vertrieb, Operations, Research und E-Commerce inzwischen deutlich praktikabler ist. Außerdem schauen wir auf typische Grenzen klassischer Methoden, konkrete Einsatzszenarien und Tipps für sauberere Daten.
Was ist Data Scraping?
Data Scraping, auch Web Scraping genannt, ist das strukturierte Auslesen von Informationen aus Webseiten mithilfe von Tools. Häufig geht es um Daten, die zwar öffentlich sichtbar sind, aber nicht direkt als saubere Tabelle vorliegen. So kannst du zum Beispiel öffentliche Daten aus Google Maps für die Lead-Generierung sammeln, Produkt-SKUs von Amazon für Wiederverkauf oder Marktanalysen auslesen oder Bewertungen aus Yelp für bessere Kundeneinblicke erfassen.
Der technologische Wandel beim Data Scraping
Lange war Datenerfassung entweder etwas für Entwicklerinnen und Entwickler oder eine mühsame Aufgabe für Menschen mit viel Geduld und einer leeren Tabelle. 2025 sieht das anders aus: KI ist im Data Scraping angekommen. Damit wird Scraping nicht mehr nur über starre Selektoren, Skripte und einfache Automatisierung gedacht, sondern über semantisches Verständnis.
Klassische Methoden stoßen an ihre Grenzen
Moderne Websites sind für klassische Scraper deutlich schwieriger geworden: Inhalte werden dynamisch nachgeladen, etwa in React- oder Vue-Anwendungen, Daten liegen nicht mehr nur als Text vor, sondern auch in Bildern, Videos und PDFs, und selbst innerhalb einer Website können mehrere Seitenvorlagen parallel existieren. Aktuelle Studien nennen drei zentrale Schwachstellen klassischer Web-Scraping-Methoden:
-
Ein Fass ohne Boden bei den Wartungskosten
Herkömmliche Web-Scraper müssen laufend gepflegt werden, oft 3 bis 5 Stunden pro Monat und Website. Ändert sich eine Seite oder wechselt das Frontend-Framework, brechen rund 60 % der XPath-Selektoren. KI-Tools können dank Sprachmodellen und Code-Verständnis bis zu 90 % solcher Strukturänderungen automatisch abfedern und die Wartungskosten um 60 bis 80 % senken. Gerade bei React-/Vue-Seiten hilft semantisches Verständnis, damit Data Scraping stabil bleibt, auch wenn sich Klassennamen ändern. -
Begrenzte Datentiefe
Klassische Verfahren holen vor allem klar strukturierte Daten aus dem HTML. Viel Wertvolles bleibt dabei liegen, zum Beispiel:- Daten in Bildern
- Textinhalte in Artikeln
- Unstrukturierte Daten ohne HTML-Tags
-
Probleme bei der Datenqualität
Bei dynamischen Inhalten liefern starre Methoden schnell unvollständige oder fehlerhafte Ergebnisse:- Bei paginierten Inhalten, etwa Produktlisten im E-Commerce, erfassen klassische Scraper oft nur 30 bis 50 % des sichtbaren Inhalts der ersten Seite.
- Bei Seiten mit Endlos-Scrollen, etwa Social-Media-Feeds, gehen mehr als 60 % der wichtigen Daten verloren.
- Beim Abgleich unstrukturierter Daten kommt es häufig zu hohen Fehlerraten, etwa wenn Listenelemente falsch zugeordnet werden.
An dieser Stelle werden KI-gestützte Tools wie Thunderbit interessant. Schauen wir uns genauer an, was sich dadurch im Alltag verändert.
Der Aufstieg des KI-gestützten Data Scraping
Daten von jeder Website mit KI extrahieren Get Started Free
Bis 2025 haben KI und vor allem Large Language Models (LLMs) gezeigt, dass sie natürliche Sprache verstehen, komplexe Analyseaufgaben lösen und aus unübersichtlichen Quellen strukturierte Ergebnisse ableiten können. Viele Data-Scraping-Tools nutzen LLMs inzwischen, um die Schwächen klassischer Ansätze zu umgehen. Nach Tests mit 13 Data-Scraping-Tools ist der Thunderbit AI Web Scraper für viele Business-Teams die naheliegende Wahl.
Darum sticht Thunderbit hervor:
-
Revolutionäre Bedienung
Du beschreibst in natürlicher Sprache, welche Daten du brauchst, und das System erstellt daraus automatisch einen Scraping-Plan. Im Vergleich zu klassischen Tools verkürzt das die Einrichtungszeit um 87 %. -
Große Vorteile durch lokales Scraping
Als Browser-Erweiterung bietet Thunderbit:- sofortiges Data Scraping
- Scraping dynamischer Seiten und Seiten mit Endlos-Scrollen
- Scraping von Seiten, für die ein Login erforderlich ist
-
Starke Verarbeitung multimodaler Daten
Thunderbit kann unterschiedliche Datentypen verarbeiten, zum Beispiel:- Daten aus Artikeltexten extrahieren
- Finanztabellen aus PDFs auslesen
- Informationen aus mehreren Bildern erkennen und in Tabellen überführen
- Videountertitel auslesen und zusammenfassen
Damit deckt Thunderbit viele Datenerfassungs-Szenarien ab, die früher entweder Skripte, manuelle Nacharbeit oder mehrere Spezialtools gebraucht hätten. So gehst du praktisch vor.
So funktioniert Data Scraping mit KI
Mit diesen vier Schritten nutzt du Thunderbits KI-Web-Scraping-Funktionen:
-
Browser-Erweiterung installieren
Öffne die Thunderbit-Website und lade die Thunderbit-Erweiterung aus dem Chrome Web Store herunter. Nach der Installation pinnst du die Erweiterung an deine Browser-Symbolleiste, damit sie jederzeit griffbereit ist. -
Registrieren und kostenlose Credits sichern
Melde dich direkt in der Erweiterung an, um Test-Credits zu erhalten. Diese Credits kannst du für Kernfunktionen wie KI-Web-Scraping, Formular-Autofill und intelligente Zusammenfassungen nutzen. Sinnvoll ist, das Tool zuerst kostenlos im Playground auszuprobieren, bevor du Credits einsetzt. -
Intelligentes Scraping starten
Öffne eine Vorlage über die Thunderbit-Seitenleiste. Beschreibe in natürlicher Sprache, welche Daten und Datentypen du erfassen möchtest, lege das gewünschte Ausgabeformat fest oder passe weitere Details an. Danach klickst du auf den Scrape-Button, um das Data Scraping zu starten.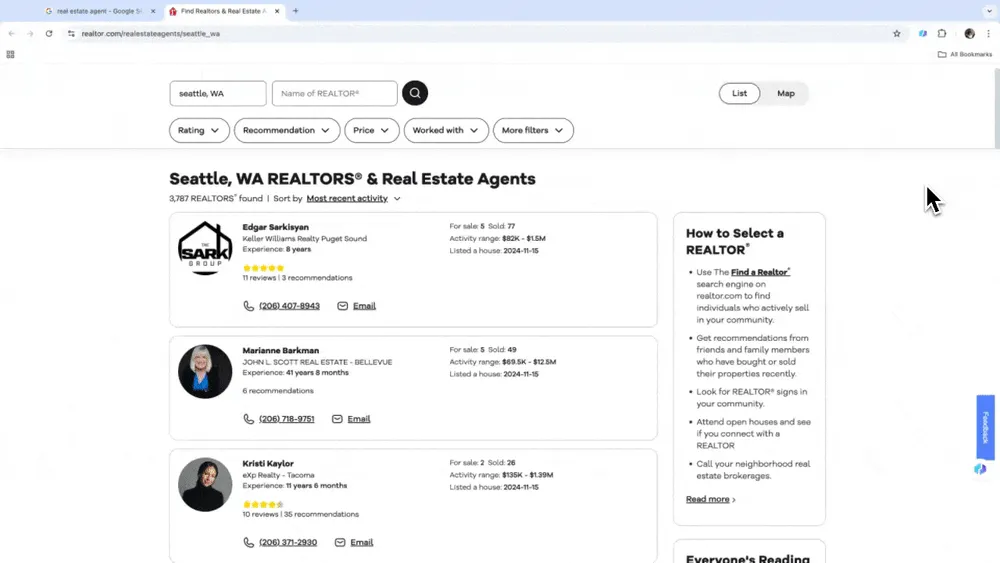
Erweiterte Scraping-Funktionen (Pro-Tier)
Mit dem Thunderbit Pro-Tier oder einem kostenlosen Testzugang schaltest du diese Funktionen frei:
-
Multimodale Datenverarbeitung Geeignet für komplexe Szenarien wie PDF-Dokumentenanalyse (Finanzberichte/Produkthandbücher), Bilddaten-Extraktion (Preisschilder/Datenblätter) und das Auslesen von Videountertiteln. Das System standardisiert unstrukturierte Daten automatisch.
-
Tiefes Unterseiten-Scraping Optional können alle Unterlinks einer Seite erfasst werden, etwa Produktdetailseiten oder Bewertungsseiten. Relevante Informationen werden intelligent erkannt und automatisch in die Haupttabelle zusammengeführt. Das ist besonders nützlich für Produktkataloge im E-Commerce, Immobilienangebote und ähnliche Datenbestände.
-
Vorlagenbibliothek mit sofort einsetzbaren Scraper-Templates Nutze direkt optimierte Scraping-Vorlagen für mehr als 30 Plattformen wie TikTok, Amazon und Zillow. Die Vorlagen passen sich automatisch an Änderungen in der Seitenstruktur an. Neue Nutzer sparen im Schnitt 83 % Einrichtungszeit.
-
Bulk-Scraping-Aufgaben Du kannst mehrere Scraping-Aufgaben gleichzeitig ausführen und URL-Listen für Batch-Scraping importieren.
-
Intelligente Behandlung von Paginierung Inhalte mit Seitenumbruch werden automatisch erkannt und erfasst, inklusive „Mehr laden“-Buttons und Seitennavigation. Auch Endlos-Scrollen wird unterstützt. In Tests wurden über 200 Seiten mit E-Commerce-Produktlisten vollständig ausgelesen.
Thunderbit in der Praxis
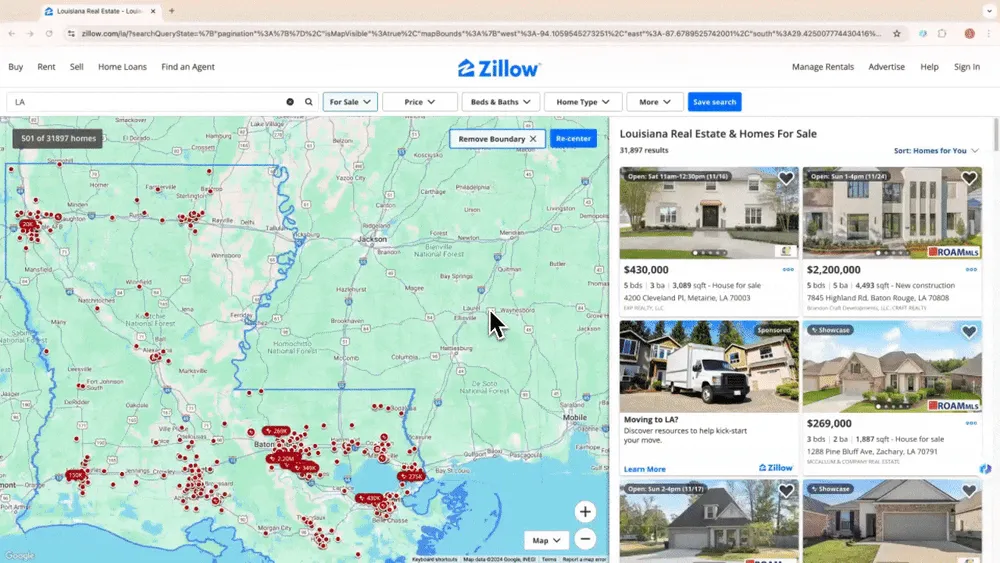
Szenario 1: Datenerfassung für Immobilien
Wenn du als Makler Immobiliendaten von Zillow sammeln willst oder als Investor nach attraktiven Chancen suchst, brauchst du vor allem verlässliche, aktuelle Objektdaten. Der KI-Web-Scraper von Thunderbit extrahiert wichtige Informationen aus Zillow, damit du Angebote, Preise und Marktbewegungen schneller vergleichen kannst. Das Tutorial-Video zeigt, wie du Zillow mit Thunderbit ausliest.
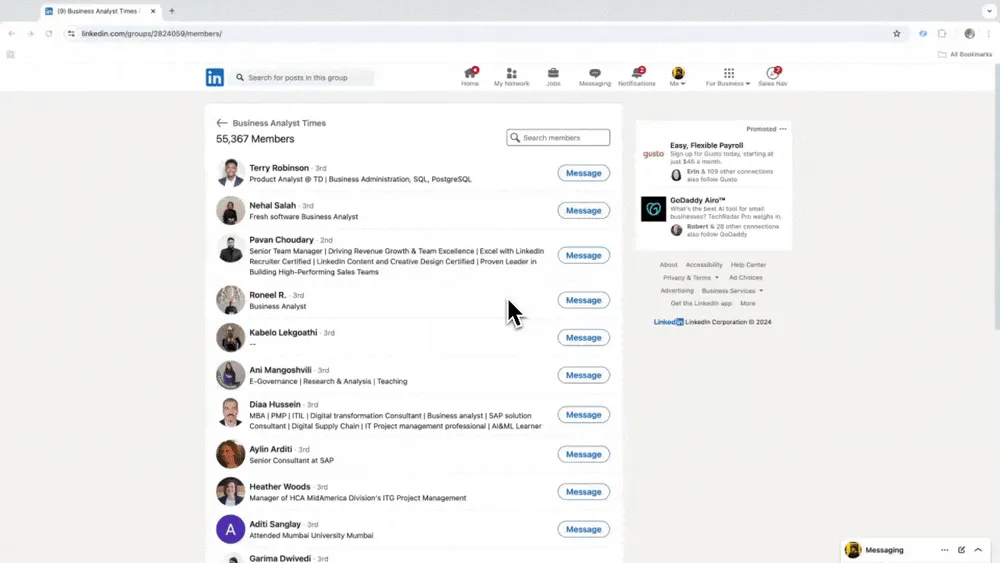
Szenario 2: Recruiting und Lead-Generierung
Wenn du im HR-Bereich Talente recherchierst oder im Vertrieb neue Leads aufbauen willst, ist ein zuverlässiger Web-Scraper ein sehr praktisches Werkzeug. Thunderbit hilft dir, öffentlich verfügbare Kontakt- und Unternehmensdaten von Websites, Verzeichnissen und Profilseiten zu extrahieren, damit Recruiting und Lead-Management nicht in manueller Recherche hängen bleiben. Spätestens nach den ersten sauberen Tabellen merkst du, wie viel Zeit früher in Copy-and-Paste geflossen ist. Für einen direkt einsetzbaren Workflow startest du mit dem Website Contact Scraper.
Szenario 3: Marktanalyse und Zielgruppenansprache
Wenn du standortbezogene Daten für Marktanalysen sammeln oder lokale Geschäftskontakte für den Vertrieb finden möchtest, nimmt ein guter Web-Scraper viel Handarbeit aus dem Prozess. Thunderbit kann wichtige Daten aus Google Maps extrahieren, damit du bessere Entscheidungen triffst und Outreach gezielter planst.
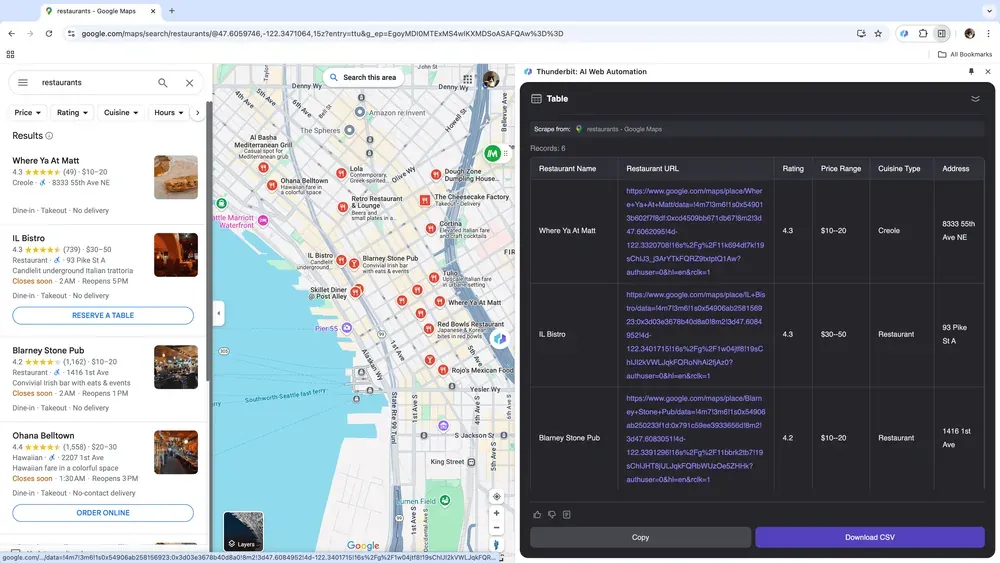
Szenario 4: Analyse von E-Commerce-Daten
Wenn du im Onlinehandel Wettbewerber beobachtest oder Markttrends früh erkennen willst, kann Thunderbit Produktdaten von Amazon erfassen, darunter detaillierte Beschreibungen, Preise und Kundenbewertungen. So bekommst du schneller ein belastbares Bild davon, was sich am Markt bewegt.
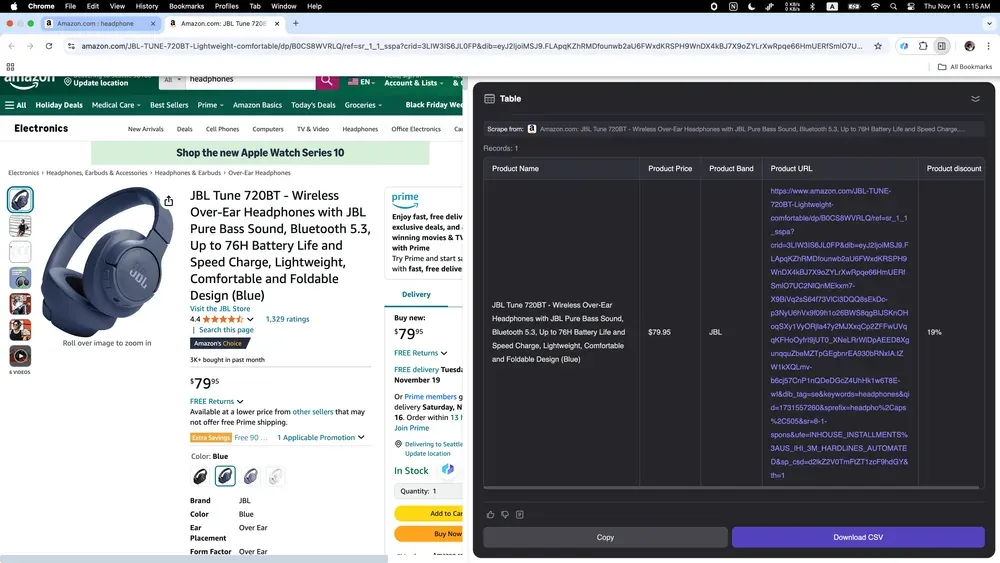
Der AI Web Scraper von Thunderbit verändert, wie Business-Anwender Daten sammeln: schneller, einfacher und mit deutlich weniger manueller Nacharbeit. Ob du Immobilienangebote recherchierst, potenzielle Kunden identifizierst oder E-Commerce-Trends analysierst, KI-Web-Scraper sparen viele Stunden Routinearbeit. Wenn Webdaten für deine Entscheidungen relevant sind, ist KI-gestütztes Scraping ein direkter Produktivitätshebel. Bereit zum Start? Probier Thunderbit aus und geh den ersten Schritt zu intelligenterem Web Scraping.
Thunderbit AI Web Scraper ausprobieren
Exklusive Tipps zur Datenbereinigung
Bei klassischen Scrapern beginnt die eigentliche Arbeit oft erst nach dem Data Scraping: Dubletten entfernen, Felder vereinheitlichen, Formate korrigieren, fehlende Angaben ergänzen. Thunderbit kann mithilfe von LLMs bereits während des Scraping-Prozesses Daten bereinigen und den Aufwand dafür mit den folgenden Funktionen um 83 % reduzieren:
Tipp 1: Intelligente Zuordnung von Feldern
Bei heterogenen Daten aus mehreren Quellen, etwa wenn du gleichzeitig E-Commerce-Produktseiten, Zillow-Immobiliendaten und Unternehmensverzeichnisse ausliest, erstellt Thunderbits KI automatisch semantische Zuordnungen:
- Erkennt Feldentsprechungen aus unterschiedlichen Quellen automatisch (z. B. „price“ ↔ „售价“ ↔ „Price“)
- Führt ähnliche Felder intelligent zusammen (z. B. „area“ und „square feet“)
- Standardisiert Daten plattformübergreifend (z. B. werden LinkedIns „current position“ und Zillows „property status“ einheitlich als Tag-Daten dargestellt)
Tipp 2: Kontextbasierte Ergänzung
Mit dem Kontextverständnis moderner Large Language Models erreicht Thunderbit eine branchenführende Daten-Vervollständigungsrate von 99 %:
- Adressergänzung: Stadt- und Bundesstaatenangaben werden anhand der Postleitzahl automatisch ergänzt (z. B. 10001 → New York City, NY)
- Karriere-Prognosen: Mögliche Berufserfahrungen werden auf Basis des Bildungswegs in LinkedIn abgeleitet
Tipp 3: Datenoptimierung
- Mehrsprachige Übersetzung (Echtzeitübersetzung in 12 Sprachen, darunter Englisch, Chinesisch und Japanisch)
- Intelligente Zusammenfassung (verkürzt eine 500-Wörter-Produktbeschreibung auf drei zentrale Verkaufsargumente)
- Einheitliche Maßeinheiten (konvertiert automatisch Quadratfuß ↔ Quadratmeter, Fahrenheit ↔ Celsius)
- Standardisiertes Format (Datumsangaben im Format YYYY-MM-DD, Währungen einheitlich in USD)
Tipp 4: Qualitätsprüfung
- Intelligente Fehlerkorrektur: behebt Formatfehler automatisch (z. B. Telefonnummer +01 138-1234-5678 → +113812345678)
- Logische Validierung: stellt sicher, dass das „Baujahr“ vor der „letzten Renovierung“ liegt
Tipp 5: KI-Tagging
Erzeugt mithilfe von Natural Language Processing automatisch intelligente Tags:
- Sentiment-Tags (markiert Kundenbewertungen automatisch als positiv/negativ/neutral)
- Business-Value-Tags (markiert automatisch „High-Potential-Kunden“/„Objekte zur Nachverfolgung“)
- Branchen-Tags (versehen LinkedIn-Profile automatisch mit Labels wie „tech|finance|healthcare“)
Die Schattenseite des Data Scraping
So nützlich Data Scraping ist, Unternehmen sollten die Risiken nicht ausblenden. Ganz vorn stehen rechtliche Fragen: Vorschriften wie die DSGVO und der CCPA setzen klare Grenzen für die Datenerhebung und verlangen saubere Datenschutzprozesse. Dazu kommen technische Schutzmechanismen. Viele Websites setzen Lösungen wie Cloudflare ein, um Scraping-Aktivitäten über IP-Beschränkungen zu erkennen und zu blockieren.
Die Zukunft des Data Scraping im KI-Zeitalter
KI macht Web Scraping für Unternehmen deutlich intuitiver. Stell dir vor, du gibst nur eine Domain ein, etwa zillow.com, und formulierst deinen Auftrag, zum Beispiel „alle Immobilienangebote in New York City erfassen“. Die KI ordnet dann automatisch die relevanten Datenpunkte zu, von Objektdetails bis zu Preisentwicklungen, ohne dass du manuell Selektoren konfigurieren musst. Solche Systeme können die gewonnenen Daten direkt in Geschäftsprozesse einbinden, etwa LinkedIn-Profilinformationen automatisch in CRMs übertragen oder E-Commerce-Kennzahlen in Analyse-Dashboards einspeisen. Fortschrittliche Mustererkennung ermöglicht außerdem prädiktive Scraping-Funktionen, die Lageränderungen oder neue Markttrends proaktiv überwachen. Gleichzeitig kann KI Compliance dynamisch berücksichtigen und Scraping-Parameter in Echtzeit an neue Vorschriften anpassen, inklusive transparenter Audit-Trails.
Dieser KI-getriebene Wandel demokratisiert nicht nur den Zugang zu wichtiger Business Intelligence. Er verändert auch, wie Unternehmen mit Webdaten arbeiten. Je reifer diese Technologien werden, desto stärker profitieren Frühadopter, die KI-gestützte Scraping-Lösungen wie Thunderbit in ihre datengetriebenen Entscheidungen einbauen.
FAQs
-
Was ist Thunderbit?
Thunderbit ist eine smarte Browser-Erweiterung auf Basis von Large Language Models (LLM), entwickelt für moderne Anforderungen an die Datenerfassung. Neben KI-Web-Scraping bietet Thunderbit multimodale Datenverarbeitung und unterstützt die umfassende Extraktion von Daten aus dynamischen Webseiten, PDF-Dokumenten, Bildern und Videos. Als lokalisierte Browser-Lösung kann Thunderbit auch mit öffentlich zugänglichen Seiten umgehen, die dynamisch laden oder Nutzerinteraktion erfordern, und sich automatisch an Änderungen moderner Frontend-Frameworks anpassen. -
Wie funktioniert Thunderbits AI Web Scraper?
Der AI Web Scraper von Thunderbit nutzt KI, um strukturierte Daten von Websites zu extrahieren. Du klickst auf „AI Suggest Columns“, damit die KI Vorschläge zur Erfassung der aktuellen Seite macht, und anschließend auf „Scrape“, um die Daten zu sammeln. So lassen sich Daten von jeder Website, aus PDFs oder Bildern mit nur zwei Klicks verarbeiten. -
Was ist der Unterschied zwischen Listen-Scraping und Unterseiten-Scraping?
Listen-Scraping ist für paginierte Szenarien optimiert, etwa Produktlisten im E-Commerce. Dabei werden Seitenlogiken automatisch erkannt und tausende Datensätze erfasst. Unterseiten-Scraping arbeitet mit einer Baumstruktur, etwa bei Zillow von der Immobilienliste über Detailseiten bis zu Grundrissen, und stellt durch semantische Zuordnung automatisch Beziehungen zwischen Haupt- und Nebentabellen her. -
Können auch Nicht-Programmierer Thunderbit nutzen?
Thunderbit setzt auf Interaktion in natürlicher Sprache: Du beschreibst einfach deinen Bedarf, etwa „Name, E-Mail, Telefonnummer“, und das System erstellt automatisch einen Scraping-Plan. Unsere Testdaten zeigen, dass 85 % der Nutzer ihre erste Datenerfassung innerhalb von 10 Minuten abschließen, ganz ohne Web-Programmierkenntnisse. -
Welche Datentypen kann Thunderbit verarbeiten?
Thunderbit erkennt intelligent viele verschiedene Datentypen:- Strukturierte Daten: Tabellen, Listen (z. B. Amazon-Produktspezifikationen)
- Unstrukturierte Daten: Bewertungstexte, PDF-Dokumente (automatische Erkennung)
- Multimodale Daten: Preisschilder in Bildern, Extraktion von Videountertiteln
- Dynamische Daten: Inhalte mit Endlos-Scrollen, Bilder mit Lazy Loading
- Verknüpfte Daten: über Seiten hinweg zugeordnete Beziehungen (z. B. LinkedIn-Kontakte → Unternehmensinformationen)
-
Wie fange ich mit Thunderbit an?
Erfahre mehr über unsere Scraping-Funktionen oder entdecke direkt unsere Vorlagenbibliothek, um sofort loszulegen.
Mehr erfahren:
- Die besten Web-Scraping-Tools und Software 2025
- So liest du jede Website mit KI aus
- So richtest du Thunderbit ein
KI Web Scraper ausprobieren Get Started Free




