
Hast du dich schon mal gefragt, wie Unternehmen aus riesigen, verstreuten Datenmengen übersichtliche Dashboards und KI-gestützte Analysen zaubern? Die Antwort steckt im sogenannten Data Ingestion – dem oft unterschätzten, aber absolut entscheidenden Startpunkt jeder datengetriebenen Wertschöpfungskette. In einer Welt, in der wir bis 2025 erzeugen (das sind 21 Nullen!), ist es wichtiger denn je, Daten schnell, zuverlässig und im passenden Format von A nach B zu bekommen.
Nach vielen Jahren in der SaaS- und Automatisierungsbranche weiß ich: Die richtige Strategie für data ingestion entscheidet oft über Erfolg oder Misserfolg eines Unternehmens. Egal, ob du Leads sammelst, Markttrends beobachtest oder einfach nur deine Abläufe optimieren willst – zu verstehen, wie data ingestion funktioniert (und sich weiterentwickelt), ist der erste Schritt zu echtem Mehrwert. Also, worum geht’s bei data ingestion, warum ist es so wichtig und wie verändern moderne Tools wie die Spielregeln – für Analysten genauso wie für Gründer?
Was ist Data Ingestion? Das Fundament datengetriebener Unternehmen
Im Kern bedeutet data ingestion das Sammeln, Importieren und Laden von Daten aus verschiedenen Quellen in ein zentrales System – zum Beispiel eine Datenbank, ein Data Warehouse oder einen Data Lake. Erst dadurch werden Daten für Analysen, Visualisierungen oder Geschäftsentscheidungen nutzbar. Stell dir data ingestion wie die „Eingangstür“ deiner Datenpipeline vor: Hier landen alle Rohdaten (Tabellen, APIs, Logfiles, Webseiten, Sensordaten) in deiner „Küche“, bevor du daraus wertvolle Erkenntnisse „kochst“.
Data ingestion ist die allererste Stufe jeder Datenpipeline (). Sie sorgt dafür, dass hochwertige und aktuelle Daten für Analysen, Business Intelligence und Machine Learning bereitstehen. Ohne sie bleiben wertvolle Informationen in Silos gefangen – „unsichtbar für die, die sie brauchen“, wie es ein Branchenexperte mal treffend gesagt hat.
So fügt sich data ingestion ins Gesamtbild ein:
- Data Ingestion: Sammelt Rohdaten aus verschiedenen Quellen und bringt sie in ein zentrales System.
- Data Integration: Verknüpft und harmonisiert Daten aus unterschiedlichen Quellen, sodass sie gemeinsam nutzbar sind.
- Data Transformation: Bereinigt, formatiert und reichert Daten an, damit sie analysiert werden können.
Man kann es sich vorstellen wie den Wocheneinkauf: Data ingestion bringt alle Lebensmittel nach Hause, Integration räumt sie in die Vorratskammer, Transformation bereitet die Mahlzeit zu.
Warum Data Ingestion für moderne Unternehmen unverzichtbar ist
Fakt ist: Aktuelle und gut aufbereitete Daten sind ein strategischer Vorteil. Wer data ingestion beherrscht, kann Datensilos aufbrechen, Echtzeit-Einblicke gewinnen und schneller bessere Entscheidungen treffen. Umgekehrt führen schlechte Prozesse zu langsamen Berichten, verpassten Chancen und Entscheidungen auf Basis veralteter oder unvollständiger Daten.
Hier ein paar konkrete Beispiele, wie effiziente data ingestion echten Mehrwert bringt:
| Anwendungsfall | Wie effiziente Data Ingestion hilft |
|---|---|
| Lead-Generierung im Vertrieb | Führt Leads aus Webformularen, Social Media und Datenbanken fast in Echtzeit in einem System zusammen – so kann der Vertrieb schneller reagieren und die Abschlussquote steigern. |
| Operative Dashboards | Liefert kontinuierlich Daten aus Produktionssystemen an Analyseplattformen, sodass aktuelle KPIs fürs Management bereitstehen und schnelle Korrekturen möglich sind. |
| 360°-Kundensicht | Verknüpft Kundendaten aus CRM, Support, E-Commerce und Social Media zu einem einheitlichen Profil für personalisiertes Marketing und proaktiven Service (Cake.ai). |
| Predictive Maintenance | Nimmt große Mengen Sensor- und IoT-Daten auf, damit Analysen Anomalien erkennen und Ausfälle vorhersagen können – das spart Kosten und reduziert Ausfallzeiten. |
| Finanz-Risikoanalysen | Streamt Transaktionsdaten und Marktdaten in Risikomodelle, sodass Banken und Händler Risiken in Echtzeit erkennen und Betrug sofort aufdecken können. |
Die Zahlen sprechen für sich: – aber diese Investitionen zahlen sich nur aus, wenn die Daten auch zuverlässig aufgenommen und genutzt werden können.
Data Ingestion vs. Data Integration und Transformation: Was ist der Unterschied?
Die Begriffe werden oft durcheinandergebracht – hier die Klarstellung:
- Data Ingestion: Der erste Schritt – Rohdaten aus Quellsystemen einsammeln und importieren. Bildlich: „Alles in die Küche bringen.“
- Data Integration: Daten aus verschiedenen Quellen zusammenführen und vereinheitlichen. Bildlich: „Die Vorratskammer organisieren.“
- Data Transformation: Daten bereinigen, formatieren, aggregieren und anreichern. Bildlich: „Die Mahlzeit zubereiten.“
Ein häufiger Irrtum: Data ingestion und ETL (Extract, Transform, Load) seien dasselbe. Tatsächlich ist ingestion nur der „Extract“-Teil – also das Einsammeln der Rohdaten. Integration und Transformation folgen danach, um die Daten analysierbar zu machen ().
Warum ist das wichtig? Wer nur schnell Daten von einer Webseite braucht, kommt oft mit einem einfachen ingestion-Tool aus. Wer aber Daten aus mehreren Systemen zusammenführen und bereinigen will, braucht Integration und Transformation dazu.
Klassische Data Ingestion: ETL und ihre Grenzen
Jahrzehntelang war ETL (Extract, Transform, Load) der Standard für data ingestion. Dateningenieure schrieben Skripte oder nutzten spezialisierte Software, um regelmäßig Daten aus Quellsystemen zu ziehen, zu bereinigen und in ein Data Warehouse zu laden – meist als nächtliche Batch-Jobs.
Doch mit der Datenexplosion stößt das klassische ETL an seine Grenzen:
- Komplexe, zeitaufwändige Einrichtung: Aufbau und Wartung von ETL-Pipelines erfordern viel Programmieraufwand und Spezialwissen. Fachabteilungen müssen oft lange auf die IT warten ().
- Batch-Verarbeitung als Flaschenhals: ETL läuft in Intervallen – Daten stehen also oft erst mit Verzögerung zur Verfügung. In Zeiten, in denen Echtzeit zählt, ist das ein Nachteil ().
- Skalierungs- und Performance-Probleme: Alte Pipelines kommen mit heutigen Datenmengen oft nicht mehr mit und müssen ständig angepasst werden.
- Unflexibel bei Änderungen: Neue Datenquellen oder Schema-Änderungen führen schnell zu Fehlern oder aufwändigen Umbauten.
- Hoher Wartungsaufwand: Fehleranfällige Pipelines erfordern ständige Aufmerksamkeit von Experten.
- Begrenzt auf strukturierte Daten: Klassisches ETL ist für tabellarische Daten gemacht – mit unstrukturierten Daten (wie Webseiten oder Bildern), die heute ausmachen, kommt es kaum zurecht.
Kurz: ETL war für eine überschaubare Datenwelt ideal, ist aber für die heutigen Anforderungen oft zu langsam und unflexibel.
Moderne Data Ingestion: Automatisiert und KI-gestützt
Die neue Generation: Moderne Data-Ingestion-Tools setzen auf Automatisierung, Cloud und KI, um Daten schneller, einfacher und flexibler zu erfassen.
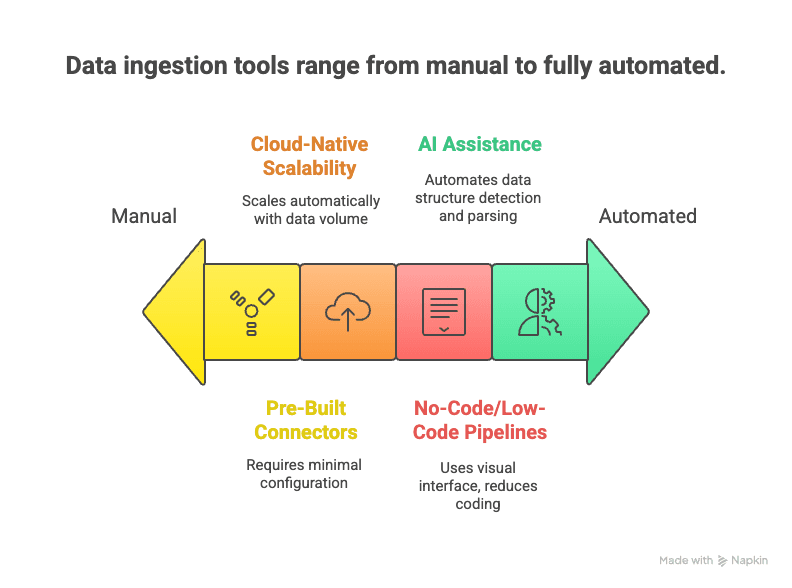
Was macht sie aus?
- No-Code/Low-Code-Pipelines: Drag-and-drop-Oberflächen und KI-Assistenten ermöglichen Datenflüsse ohne Programmierkenntnisse ().
- Vorgefertigte Konnektoren: Hunderte fertige Anbindungen an gängige Datenquellen – Zugangsdaten eingeben und loslegen.
- Cloud-native Skalierung: Elastische Cloud-Dienste verarbeiten riesige Datenströme in Echtzeit ().
- Echtzeit- und Streaming-Support: Moderne Tools unterstützen sowohl Streaming- als auch Batch-Ingestion – je nach Bedarf ().
- KI-Unterstützung: KI erkennt automatisch Datenstrukturen, schlägt Extraktionsregeln vor und prüft die Datenqualität in Echtzeit ().
- Unterstützung für unstrukturierte Daten: NLP und Computer Vision verwandeln Webseiten, PDFs oder Bilder in strukturierte Tabellen.
- Weniger Wartungsaufwand: Managed Services übernehmen Überwachung, Skalierung und Updates – du kannst dich auf die Nutzung der Daten konzentrieren.
Das Ergebnis: Data ingestion ist schneller eingerichtet, flexibler anpassbar und bewältigt auch die komplexesten Datenlandschaften.
Data Ingestion in der Praxis: Branchenbeispiele und Herausforderungen
Wie sieht data ingestion im Alltag aus – und welche Hürden gibt es?
Handel & E-Commerce
Händler erfassen Daten aus Kassensystemen, Onlineshops, Bonusprogrammen und sogar aus Sensoren im Laden. Durch die Zusammenführung von Transaktionen, Klickpfaden und Lagerbeständen erhalten sie einen Echtzeit-Überblick über Sortiment und Trends. Die Herausforderung: Hohe Datenvolumina (vor allem zu Stoßzeiten) und die Integration von Online- und Offline-Kanälen.
Finanzwesen & Banken
Banken und Broker erfassen Datenströme aus Transaktionen, Marktdaten und Kundeninteraktionen. Echtzeit-ingestion ist entscheidend für Betrugserkennung und Risikomanagement. Strenge Compliance- und Sicherheitsanforderungen machen den Prozess besonders sensibel.
Technologie & Internet
Tech-Unternehmen verarbeiten riesige Event-Streams (jeder Klick, Like oder Share), um Nutzerverhalten zu analysieren und Empfehlungen zu steuern. Die Herausforderung: Aus der Datenflut die relevanten Signale herausfiltern und Datenqualität sicherstellen.
Gesundheitswesen
Krankenhäuser erfassen Daten aus elektronischen Patientenakten, Laborsystemen und Medizingeräten, um vollständige Patientenprofile zu erstellen und Analysen zu ermöglichen. Die größten Hürden: Unterschiedliche Systeme („Sprachen“) und Datenschutz.
Immobilien
Immobilienfirmen sammeln Daten aus Portalen, Webseiten und öffentlichen Registern, um umfassende Datenbanken zu erstellen. Die Herausforderung: Unterschiedliche, oft unstrukturierte Quellen zusammenführen und Daten aktuell halten.
Branchenübergreifende Herausforderungen:
- Umgang mit verschiedenen Datentypen (strukturiert, semi-strukturiert, unstrukturiert)
- Echtzeit- vs. Batch-Anforderungen ausbalancieren
- Datenqualität und Konsistenz sicherstellen
- Sicherheits- und Compliance-Vorgaben erfüllen
- Skalierung für wachsende Datenmengen
Wer diese Hürden meistert, profitiert von besseren Analysen, schnelleren Entscheidungen und mehr Sicherheit.
Thunderbit: Data Ingestion leicht gemacht mit KI-Web-Scraper
Wie passt Thunderbit in dieses Bild? ist eine KI-gestützte Web-Scraper Chrome-Erweiterung, die Web-Datenaufnahme für alle zugänglich macht – ganz ohne Programmierkenntnisse.
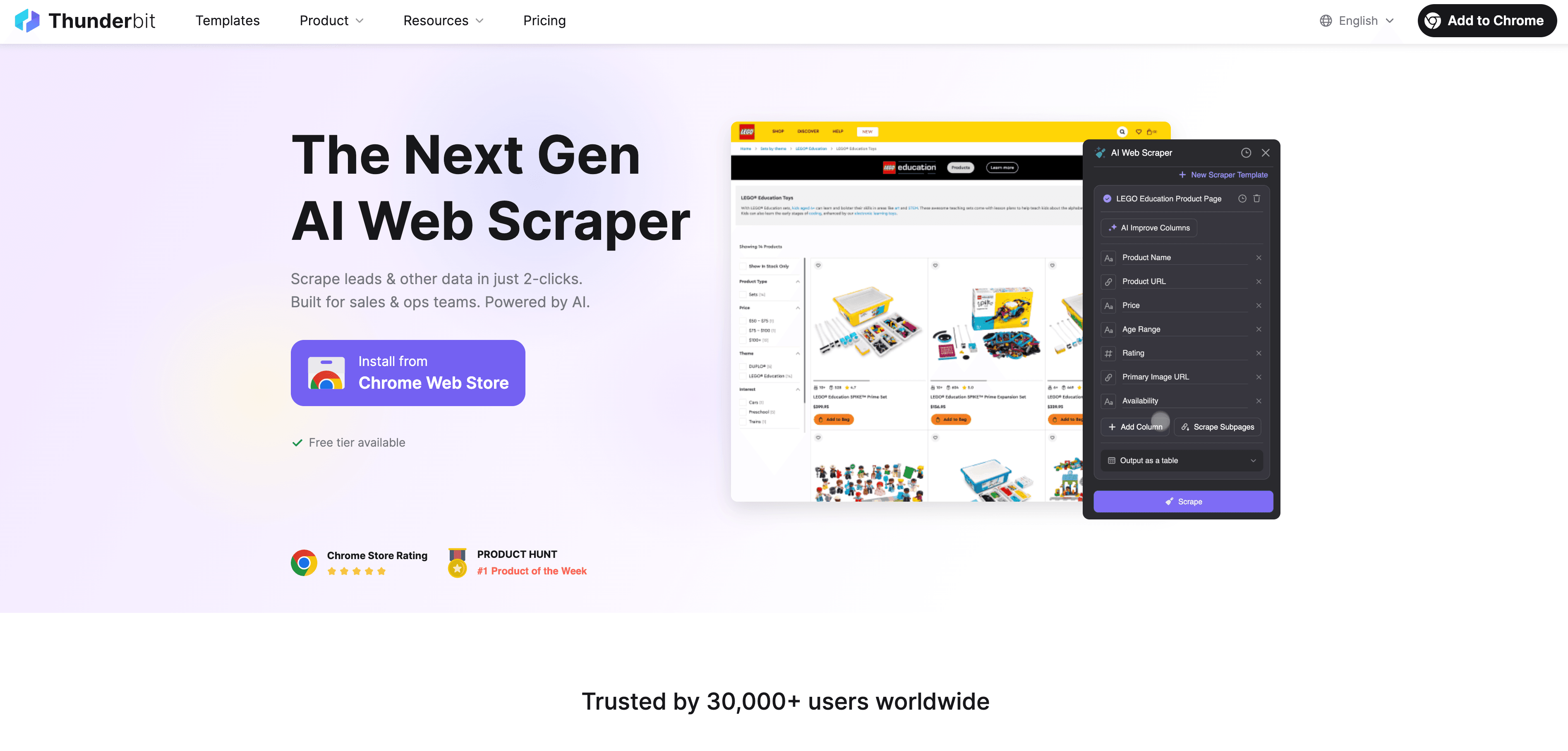
Das macht Thunderbit für Unternehmen so wertvoll:
- Web Scraping mit 2 Klicks: Von der unübersichtlichen Webseite zur strukturierten Tabelle in Sekunden. Einfach „KI-Felder vorschlagen“ und „Scrapen“ klicken – fertig.
- KI-gestützte Feldvorschläge: Thunderbit erkennt automatisch die wichtigsten Datenfelder – egal ob Firmenverzeichnis, Produktliste oder LinkedIn-Profil.
- Automatisches Scrapen von Unterseiten: Mehr Details nötig? Thunderbit besucht automatisch Unterseiten (z. B. Produktdetails) und ergänzt die Tabelle.
- Paginierung und Endlos-Scroll: Auch lange Listen und Seiten mit unendlichem Scrollen werden vollständig erfasst.
- Vorgefertigte Templates: Für beliebte Seiten wie Amazon, Zillow oder Shopify gibt es 1-Klick-Vorlagen – keine Einrichtung nötig.
- Kostenloser Datenexport: Exportiere deine Daten direkt nach Excel, Google Sheets, Airtable oder Notion – ohne Zusatzkosten.
- Geplanter Scraper: Richte wiederkehrende Scraping-Jobs ein, z. B. für tägliche Preisvergleiche.
- KI-Autofill: Automatisiere auch das Ausfüllen von Formularen und wiederkehrende Webaufgaben.
Thunderbit eignet sich perfekt für Vertriebsteams, die Leads sammeln, E-Commerce-Analysten, die Preise überwachen, oder Makler, die Immobilienangebote recherchieren. Ziel ist es, unstrukturierte Webdaten blitzschnell in verwertbare Informationen zu verwandeln.
Neugierig? Schau auf unserem vorbei oder stöbere in unserem für weitere Anleitungen.
Data Ingestion im Vergleich: Klassisch vs. modern
Hier ein schneller Überblick:
| Kriterium | Klassische ETL-Tools | Moderne KI-/Cloud-Tools | Thunderbit (KI-Web-Scraper) |
|---|---|---|---|
| Benutzerkenntnisse | Hoch (IT/Programmierung nötig) | Mittel (Low-Code, etwas Einrichtung) | Gering (2 Klicks, kein Code) |
| Datenquellen | Strukturiert (Datenbanken, CSV) | Vielfältig (Datenbanken, SaaS, APIs) | Jede Website, unstrukturierte Daten |
| Bereitstellungsgeschwindigkeit | Langsam (Wochen/Monate) | Schneller (Tage) | Sofort (Minuten) |
| Echtzeit-Support | Eingeschränkt (Batch) | Stark (Streaming/Batch) | On-Demand & geplant |
| Skalierbarkeit | Schwierig | Hoch (Cloud-nativ) | Mittel/Hoch (Cloud-Scraping) |
| Wartung | Hoch (anfällig) | Mittel (Managed Service) | Gering (KI passt sich an) |
| Transformation | Starr, vorab | Flexibel, nachgelagert | Basis (KI-Feldvorschläge) |
| Bestes Einsatzgebiet | Interne Batch-Integration | Analyse-Pipelines | Webdaten, externe Quellen |
Das Fazit: Wähle das passende Tool für deine Aufgabe. Für Webdaten oder unstrukturierte Quellen ist Thunderbit meist die schnellste und einfachste Lösung.
Die Zukunft von Data Ingestion: Automatisierung und Cloud-First
Der Blick nach vorn: Data ingestion wird immer intelligenter und automatisierter. Was erwartet uns?
- Echtzeit als Standard: Das alte Batch-Prinzip verschwindet. Immer mehr Pipelines werden für Echtzeit- und Event-Streaming gebaut ().
- Cloud-First und „Zero ETL“: Cloud-Plattformen ermöglichen die direkte Verbindung von Quellen und Zielen – ohne manuelle Pipelines.
- KI-gesteuerte Automatisierung: Machine Learning übernimmt Konfiguration, Überwachung und Optimierung – erkennt Fehler, korrigiert sie und reichert Daten automatisch an.
- No-Code und Self-Service: Immer mehr Tools erlauben es Fachanwendern, Datenflüsse per Spracheingabe oder visueller Oberfläche zu erstellen.
- Edge- und IoT-Ingestion: Daten werden immer häufiger direkt an der Quelle (z. B. im Gerät) aufgenommen und vorverarbeitet.
- Governance und Metadaten: Automatisierte Verschlagwortung, Herkunftsnachweise und Compliance werden zum Standard.
Kurz: Die Zukunft von data ingestion ist schneller, zugänglicher und zuverlässiger – damit du dich auf Erkenntnisse statt auf Technik konzentrieren kannst.
Fazit: Das Wichtigste für Unternehmen
- Data ingestion ist der entscheidende erste Schritt für jede datengetriebene Initiative. Wer Erkenntnisse will, muss Daten schnell und zuverlässig aufnehmen.
- Moderne, KI-gestützte Tools wie Thunderbit machen data ingestion für alle zugänglich – nicht nur für IT-Profis. Mit 2-Klick-Scraping, KI-Feldvorschlägen und geplanten Jobs werden aus Rohdaten wertvolle Geschäftsinformationen.
- Das richtige Tool wählen: Klassisches ETL für stabile, interne Daten; moderne Cloud-Tools für umfassende Analysen; Thunderbit für Web- und unstrukturierte Daten.
- Am Puls der Zeit bleiben: Automatisierung, Cloud und KI machen data ingestion immer smarter. Bleib offen für neue Lösungen und mach deine Datenstrategie zukunftssicher.
Häufige Fragen (FAQ)
1. Was ist Data Ingestion einfach erklärt?
Data ingestion ist der Prozess, bei dem Daten aus verschiedenen Quellen (wie Webseiten, Datenbanken oder Dateien) gesammelt und in ein zentrales System geladen werden, um sie analysieren oder für Geschäftsentscheidungen nutzen zu können. Es ist der allererste Schritt jeder Datenpipeline.
2. Worin unterscheidet sich Data Ingestion von Data Integration und Transformation?
Data ingestion bringt Rohdaten ins System. Data integration verknüpft und harmonisiert Daten aus verschiedenen Quellen. Data transformation bereinigt und formatiert die Daten für die Analyse. Kurz: Ingestion = sammeln, Integration = organisieren, Transformation = aufbereiten.
3. Was sind die größten Herausforderungen bei klassischen Data-Ingestion-Methoden?
Klassische Methoden wie ETL sind langsam in der Einrichtung, erfordern viel Programmieraufwand, kommen mit unstrukturierten Daten schlecht zurecht und sind wenig flexibel bei Änderungen. Außerdem sind sie wartungsintensiv und nicht für Echtzeit ausgelegt.
4. Wie vereinfacht Thunderbit die Data Ingestion?
Thunderbit nutzt KI, um Webdaten mit nur zwei Klicks zu extrahieren und zu strukturieren – ganz ohne Programmierung. Es kann Unterseiten und Paginierung verarbeiten, wiederkehrende Jobs planen und Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren.
5. Wie sieht die Zukunft von Data Ingestion aus?
Die Zukunft ist automatisiert, cloudbasiert und KI-gestützt. Es wird mehr Echtzeit-Datenflüsse, intelligente Fehlererkennung und Tools geben, mit denen auch Fachanwender Datenflüsse per Sprache oder visuell einrichten können.
Mehr erfahren: