

Aus einem Wust verstreuter Rohdaten saubere Dashboards und KI-Analysen zu machen, sieht von außen fast magisch aus. Tatsächlich steckt am Anfang dieser Kette ein unscheinbarer Schritt, über den kaum jemand spricht: Data Ingestion. Bevor irgendeine Auswertung möglich ist, müssen die Daten überhaupt erst einmal an einem Ort landen. Und das ist alles andere als trivial, wenn man bedenkt, dass 2025 weltweit 181 Zettabyte an Daten entstehen (Quelle) – eine Zahl mit 21 Nullen. Daten schnell, korrekt und in brauchbarer Form von der Quelle ins Zielsystem zu bringen, ist deshalb wichtiger denn je.
Wer ein paar Jahre in SaaS und Automatisierung unterwegs ist, hat es selbst erlebt: Die passende Ingestion-Strategie entscheidet oft darüber, ob ein Datenprojekt trägt oder im Sande verläuft. Egal, ob Sie Sales Leads verwalten, Markttrends beobachten oder einfach Ihre Abläufe sauber am Laufen halten wollen – wer versteht, wie Data Ingestion arbeitet und wohin sie sich entwickelt, legt den Grundstein für echten geschäftlichen Nutzen. Klären wir also: Was ist Data Ingestion, warum hängt so viel davon ab, und wie verschieben moderne Werkzeuge wie Thunderbit die Spielregeln für alle – vom Analysten bis zur Gründerin?
Was ist Data Ingestion? Das Fundament eines datengetriebenen Unternehmens
Data Ingestion beschreibt den Vorgang, Daten aus mehreren Quellen einzusammeln, zu importieren und in ein zentrales System zu überführen – etwa in eine Datenbank, ein Data Warehouse oder einen Data Lake –, damit sie sich anschließend analysieren, visualisieren oder für Entscheidungen heranziehen lassen. Bildlich gesprochen ist sie die Eingangstür Ihrer Datenpipeline: Hier kommen alle Rohzutaten herein – Tabellen, APIs, Logs, Webseiten, Sensordaten –, bevor in der Küche daraus Erkenntnisse entstehen.
Sie ist die allererste Phase jeder Datenpipeline (Montecarlodata). Indem sie Silos aufbricht, stellt sie sicher, dass aktuelle und hochwertige Daten für Analytics, Business Intelligence und Machine Learning bereitstehen. Fehlt dieser Schritt, bleiben wertvolle Informationen in einzelnen Systemen eingesperrt – „unsichtbar für die Menschen, die sie brauchen“, wie es ein Branchenexperte ausdrückte.
So ordnet sich das Ganze ins Gesamtbild ein:
- Data Ingestion: sammelt Rohdaten aus verschiedenen Quellen und führt sie in ein zentrales Repository.
- Data Integration: verknüpft und harmonisiert Daten unterschiedlicher Herkunft, damit sie zusammenspielen.
- Data Transformation: bereinigt, formatiert und reichert Daten an, bis sie analysefertig sind.
Anders gesagt: Ingestion ist das Heimbringen sämtlicher Einkäufe aus verschiedenen Läden. Integration heißt, alles ordentlich in der Speisekammer einzuräumen. Und Transformation ist das Vorbereiten und Kochen der Mahlzeit.
Warum Data Ingestion für moderne Unternehmen zählt
Eines vorweg: In der heutigen Geschäftswelt sind zeitnah und sauber aufgenommene Daten ein strategischer Vorteil. Wer Data Ingestion im Griff hat, bricht Silos auf, ermöglicht Echtzeit-Einblicke und entscheidet schneller wie auch fundierter. Läuft die Aufnahme dagegen schlecht, sind die Folgen verschleppte Berichte, verpasste Gelegenheiten und Entscheidungen auf Grundlage veralteter oder lückenhafter Daten.
Wie Sie mit KI jede Website scrapen Get Started Free
Ganz konkret schafft effiziente Data Ingestion auf diesen Wegen Mehrwert:
| Anwendungsfall | Wie effiziente Data Ingestion hilft |
|---|---|
| Sales-Lead-Generierung | Führt Leads aus Webformularen, sozialen Medien und Datenbanken nahezu in Echtzeit in einem System zusammen – damit Vertriebsteams schneller reagieren und die Conversion-Rate steigern können. |
| Operative Dashboards | Versorgt Analyseplattformen kontinuierlich mit Daten aus Produktionssystemen, liefert aktuelle KPIs für das Management und ermöglicht schnelle Korrekturmaßnahmen. |
| Kundensicht 360° | Integriert Kundendaten aus CRM, Support, E-Commerce und sozialen Medien zu einheitlichen Profilen für personalisiertes Marketing und proaktiven Service (Cake.ai). |
| Predictive Maintenance | Nimmt große Mengen an Sensor- und IoT-Daten auf, sodass Analysemodelle Anomalien erkennen und Ausfälle vorhersagen können – das reduziert Ausfallzeiten und senkt Kosten. |
| Finanzrisiko-Analytik | Streamt Transaktionsdaten und Marktdaten in Risikomodelle, gibt Banken und Tradern einen Echtzeitblick auf Risiken und ermöglicht sofortige Betrugserkennung. |
Und die Zahlen sprechen für sich: 97 % der Unternehmen haben in Big-Data-Initiativen investiert – doch dieses Geld zahlt sich nur aus, wenn die Daten zuverlässig aufgenommen und als vertrauenswürdig eingestuft werden können.
Data Ingestion vs. Data Integration und Data Transformation: Klarheit im Begriffsdschungel
Im Fachjargon verheddert man sich schnell – deshalb hier kurz und bündig die Abgrenzung:
- Data Ingestion: der erste Schritt, bei dem Rohdaten aus den Quellsystemen eingesammelt und importiert werden. Merken Sie sich: „alles in die Küche bringen“.
- Data Integration: das Zusammenführen und Abgleichen von Daten verschiedener Quellen, um Konsistenz und eine einheitliche Sicht herzustellen. Merken Sie sich: „die Speisekammer einräumen“.
- Data Transformation: das Umwandeln roher in nutzbare Daten – also bereinigen, formatieren, aggregieren und anreichern. Merken Sie sich: „kochen und anrichten“.
Ein hartnäckiger Irrtum lautet, Ingestion und ETL (Extract, Transform, Load) seien dasselbe. Tatsächlich entspricht Ingestion lediglich dem „Extract“-Teil – dem Einziehen der Rohdaten. Erst danach folgen Integration und Transformation, bis die Daten analysefertig sind (Astera).
Warum das für Sie relevant ist? Wenn Sie nur rasch einen Datensatz von einer Webseite ziehen wollen, genügt häufig ein schlankes Ingestion-Tool. Sobald Sie aber Daten aus fünf Systemen zusammenführen und säubern müssen, kommen Integration und Transformation hinzu.
Klassische Methoden: ETL und seine Grenzen
Jahrzehntelang galt ETL (Extract, Transform, Load) als Standard für Data Ingestion. Data Engineers schrieben Skripte oder setzten Spezialsoftware ein, um Daten in festen Abständen aus den Quellsystemen abzurufen, zu bereinigen, zu formatieren und ins Data Warehouse zu laden. Meist geschah das im Batch-Takt – typischerweise als nächtlicher Lauf.
Mit dem rasanten Wachstum von Datenmenge und -vielfalt zeigte ETL allerdings seine Schwächen:
- Aufwändige, langwierige Einrichtung: ETL-Pipelines aufzubauen und zu pflegen verlangte viel Code und Spezialwissen. Fachabteilungen mussten warten, bis die IT alles eingerichtet hatte (Medium).
- Engpässe durch Batch-Verarbeitung: ETL-Jobs liefen in Stapeln und verzögerten damit die Verfügbarkeit. Wo sofortige Einblicke zählen, sind Stunden oder Tage schlicht zu lang (SumaSoft).
- Probleme bei Tempo und Skalierung: Ältere Pipelines kamen mit den heutigen Datenbergen kaum zurecht und mussten ständig nachjustiert werden.
- Starr und unflexibel: Eine neue Quelle anzubinden oder ein Schema zu ändern war mühsam – nicht selten brachen Pipelines dabei oder mussten aufwendig umgebaut werden.
- Hoher Wartungsaufwand: Pipelines fielen aus den unterschiedlichsten Gründen aus und forderten so dauernd die Aufmerksamkeit der Engineers.
- Nur für strukturierte Daten: Klassisches ETL war auf saubere Zeilen und Spalten zugeschnitten – nicht auf das unordentliche, unstrukturierte Material wie Webseiten oder Bilder, das heute 90 % aller neuen Daten ausmacht.
Kurz: ETL war eine starke Lösung für einfachere Zeiten, kommt aber mit dem Tempo, dem Umfang und der Vielfalt moderner Daten zunehmend ins Straucheln.
Der Aufstieg moderner Data Ingestion: KI-gestützt und automatisiert
Nun zur neuen Generation: moderne Data-Ingestion-Tools, die auf Automatisierung, Cloud-Skalierung und KI setzen, um die Datensammlung schneller, leichter und beweglicher zu machen.
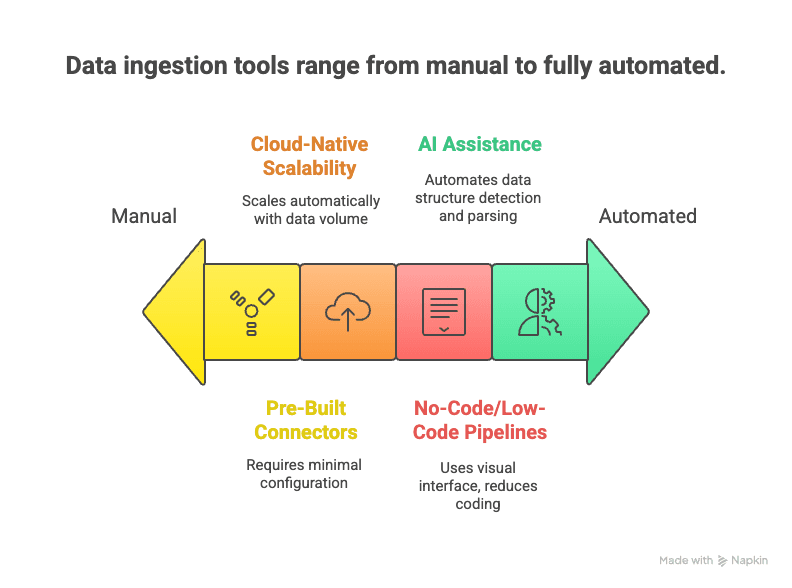
Das zeichnet sie aus:
- No-Code-/Low-Code-Pipelines: Per Drag-and-Drop und mit KI-Assistenten richten auch Nutzer ohne Programmierkenntnisse Datenflüsse ein (Medium).
- Vorgefertigte Connectoren: Hunderte sofort einsatzbereite Anbindungen für gängige Quellen – Zugangsdaten eintragen und loslegen.
- Cloud-native Skalierbarkeit: Elastische Cloud-Dienste verarbeiten gewaltige Datenströme in Echtzeit (Databricks).
- Echtzeit und Streaming: Moderne Tools beherrschen sowohl Streaming- als auch Batch-Ingestion, sodass Sie je nach Bedarf wählen (Cake.ai).
- KI-Unterstützung: KI erkennt Datenstrukturen automatisch, schlägt Parsing-Regeln vor und übernimmt sogar Qualitätsprüfungen (Cake.ai).
- Unstrukturierte Daten inklusive: Mit NLP und Computer Vision werden chaotische Webseiten, PDFs oder Bilder in strukturierte Tabellen überführt.
- Weniger Wartung: Managed Services kümmern sich um Monitoring, Skalierung und Updates – Sie konzentrieren sich auf die Daten statt auf die Pipeline.
Das Resultat? Eine Data Ingestion, die sich schneller aufsetzen, leichter anpassen lässt und mit der unübersichtlichen Datenwelt von heute mithält.
Data Ingestion in der Praxis: Branchen und ihre Hürden
Werfen wir einen Blick darauf, wie Data Ingestion im Arbeitsalltag aussieht – und mit welchen Hürden einzelne Branchen ringen.
Handel & E-Commerce
Händler nehmen Daten aus Kassensystemen, Onlineshops, Loyalty-Apps und sogar In-Store-Sensorik auf. Verkaufstransaktionen, Klickverhalten auf der Website und Bestandsprotokolle zusammengeführt, ergeben einen Echtzeitblick auf Lagerbestände und Kauftrends. Die Hürde? Hohe Volumina und schnelle Verarbeitung bewältigen – gerade in Spitzenzeiten – und dabei Online- wie Offline-Kanäle sauber verzahnen.
Finanzwesen & Banken
Banken und Trading-Firmen nehmen Datenströme aus Transaktionen, Märkten und Kundeninteraktionen auf. Für Betrugserkennung und Risikomanagement ist Echtzeit-Ingestion entscheidend. Angesichts strenger Compliance- und Sicherheitsvorgaben kann jeder Fehler im Aufnahmeprozess jedoch ernste Folgen haben.
Technologie- und Internetunternehmen
Tech-Giganten nehmen riesige Echtzeit-Ereignisströme auf – jeden Klick, jedes Like, jedes Teilen –, um Nutzerverhalten auszuwerten und Empfehlungssysteme zu speisen. Der Maßstab ist enorm, und die Hürde besteht darin, Signal von Rauschen zu trennen sowie Datenqualität und Konsistenz zu sichern.
Gesundheitswesen
Kliniken nehmen Daten aus elektronischen Patientenakten, Laborsystemen und Medizingeräten auf, um einheitliche Akten zu bilden und Predictive Analytics zu ermöglichen. Die größten Hürden? Interoperabilität – wenn Systeme verschiedene „Sprachen“ sprechen – und der Schutz sensibler Patientendaten.
Immobilien
Immobilienfirmen nehmen Daten aus Listing-Diensten, Portalen und öffentlichen Registern auf, um umfassende Datenbanken aufzubauen. Die Hürde liegt darin, oft unstrukturierte Quellen zu bündeln und alles aktuell zu halten, während sich Angebote im Minutentakt verändern.
Branchenübergreifend tauchen dieselben Herausforderungen auf:
- Umgang mit Datenvielfalt (strukturiert, semi-strukturiert, unstrukturiert)
- Balance zwischen Echtzeit- und Batch-Anforderungen
- Sicherstellung von Datenqualität und Konsistenz
- Erfüllung von Sicherheits- und Compliance-Vorgaben
- Skalierung für wachsende Datenmengen
Wer diese Hürden meistert, legt den Grundstein für bessere Ergebnisse – treffsichere Analysen, Entscheidungen in Echtzeit und solidere Compliance.
Thunderbit: Data Ingestion vereinfachen mit dem KI-Web-Scraper
Schauen wir nun, wo Thunderbit ins Spiel kommt. Thunderbit ist eine KI-gestützte Chrome-Erweiterung fürs Web-Scraping, die die Aufnahme von Webdaten allen zugänglich machen will – auch ohne eine einzige Zeile Code.
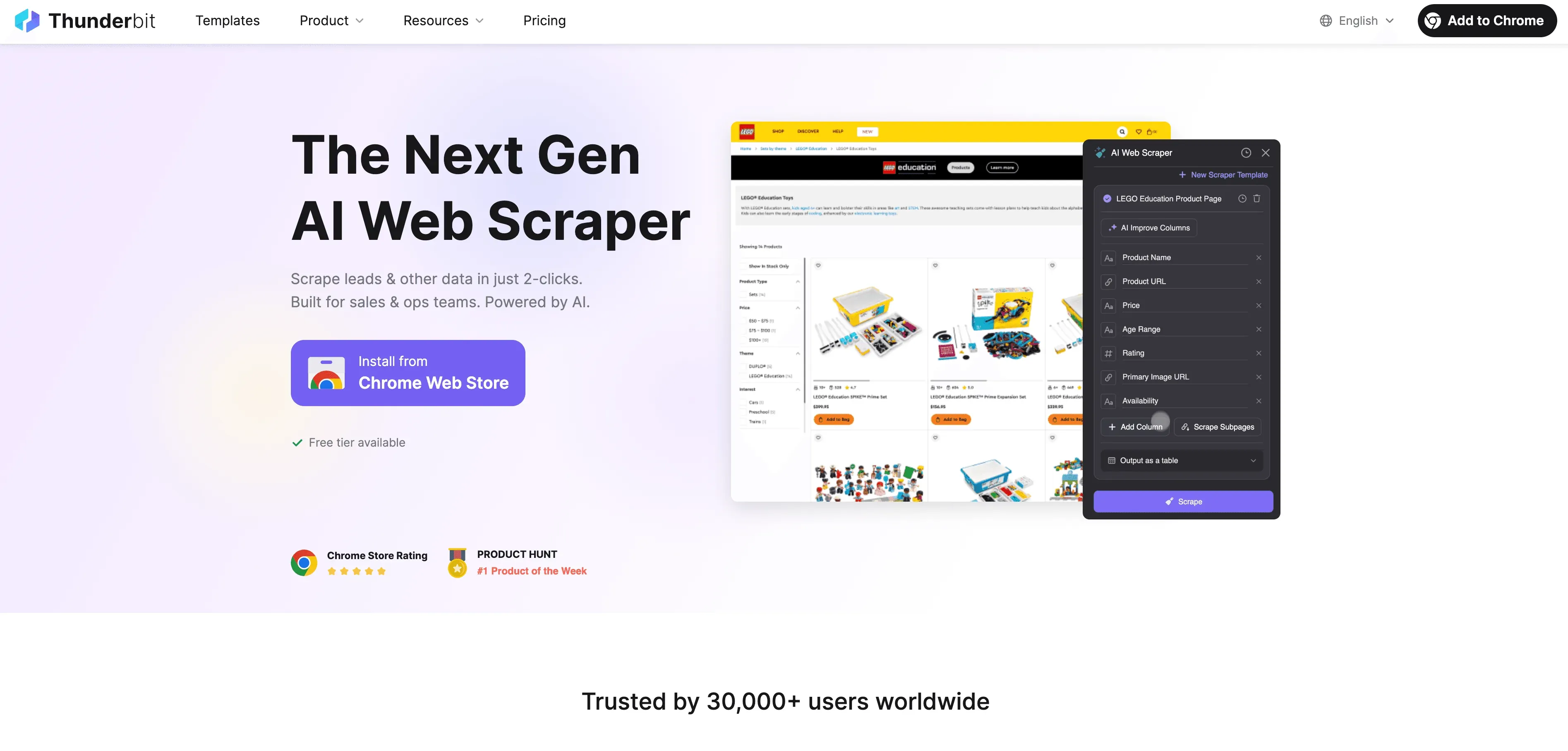
Warum Thunderbit für Business-User einen echten Wendepunkt markiert:
- Web-Scraping in 2 Klicks: von der unübersichtlichen Webseite zum strukturierten Datensatz in zwei Klicks. Auf „KI-Felder vorschlagen“ tippen, dann auf „Scrapen“ – fertig.
- KI-gestützte Feldvorschläge: Thunderbits KI liest die Seite und empfiehlt die passenden Spalten – egal ob Branchenverzeichnis, Produktliste oder LinkedIn-Profil.
- Automatisches Scrapen von Unterseiten: Sie brauchen mehr Tiefe? Thunderbit ruft jede Unterseite auf (etwa Produktdetails oder einzelne Profile) und reichert Ihre Tabelle automatisch an.
- Pagination im Griff: Paginierte Listen und Seiten mit Endlos-Scrollen werden mitverarbeitet, sodass Ihnen keine Daten durchrutschen.
- Fertige Vorlagen: Für beliebte Seiten wie Amazon, Zillow oder Shopify gibt es 1-Klick-Vorlagen – ganz ohne Einrichtung.
- Kostenloser Datenexport: Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren – ohne Aufpreis.
- Geplantes Scraping: Scraping-Jobs in beliebigen Intervallen automatisch laufen lassen (etwa tägliche Preischecks bei Wettbewerbern).
- KI-Autofill: auch das Ausfüllen von Formularen und wiederkehrende Webaufgaben automatisieren.
Für Vertriebsteams, die Leads ziehen, E-Commerce-Analysten, die Preise im Blick behalten, oder Maklerinnen, die Angebote bündeln, ist Thunderbit wie gemacht. Im Kern geht es darum, unstrukturierte Webdaten zügig in umsetzbare Erkenntnisse zu verwandeln.
Möchten Sie Thunderbit in Aktion erleben, schauen Sie auf unserem YouTube-Kanal vorbei oder stöbern Sie im Blog mit weiteren Anleitungen.
Thunderbit KI-Web-Scraper kostenlos testen
Data-Ingestion-Lösungen im Vergleich: klassisch vs. modern
Hier ein kompakter Vergleich nebeneinander:
| Kriterium | Traditionelle ETL-Tools | Moderne KI-/Cloud-Tools | Thunderbit (KI-Web-Scraper) |
|---|---|---|---|
| Nutzerkompetenz | Hoch (Programmierung/IT erforderlich) | Mittel (Low-Code, etwas Einrichtung) | Gering (2 Klicks, kein Code nötig) |
| Datenquellen | Strukturiert (Datenbanken, CSV) | Breit (Datenbanken, SaaS, APIs) | Beliebige Websites, unstrukturierte Daten |
| Einführungsgeschwindigkeit | Langsam (Wochen/Monate) | Schneller (Tage) | Sofort (Minuten) |
| Echtzeit-Unterstützung | Begrenzt (Batch) | Stark (Streaming/Batch) | Bei Bedarf & geplant |
| Skalierbarkeit | Anspruchsvoll | Hoch (cloud-nativ) | Mittel/Hoch (Cloud-Scraping) |
| Wartung | Hoch (fragile Pipelines) | Mittel (Managed Services) | Gering (KI passt sich Änderungen an) |
| Transformation | Starr, vorgelagert | Flexibel, nach dem Laden | Grundlegend (KI-Feldvorschläge) |
| Bester Anwendungsfall | Interne Batch-Integration | Analytics-Pipelines | Webdaten, externe Quellen |
Die Quintessenz? Wählen Sie das Werkzeug passend zur Aufgabe. Geht es um Webdaten oder unstrukturierte Quellen, ist Thunderbit meist die schnellste und unkomplizierteste Wahl.
Die Zukunft der Data Ingestion: Automatisierung und Cloud-first
Vorausgeschaut wird Data Ingestion immer intelligenter und stärker automatisiert. Diese Trends zeichnen sich ab:
- Echtzeit als Standard: Das alte Batch-Paradigma verliert an Boden. Immer mehr Pipelines entstehen für Echtzeit- und ereignisgesteuerte Daten (Cake.ai).
- Cloud-first und „Zero ETL“: Cloud-Plattformen verbinden Quellen und Ziele zunehmend ohne manuell gebaute Pipelines.
- KI-getriebene Automatisierung: Machine Learning übernimmt mehr beim Konfigurieren, Überwachen und Optimieren – erkennt Anomalien, behebt Fehler und reichert Daten direkt an.
- No-Code und Self-Service: Mehr Tools lassen Business-User Datenflüsse per natürlicher Sprache oder über visuelle Oberflächen einrichten.
- Edge- und IoT-Ingestion: Da immer mehr Daten am Edge entstehen, rückt die Aufnahme näher an die Quelle – mit intelligenter Filterung und Aggregation.
- Governance und Metadaten: Automatisches Tagging, Lineage-Tracking und Compliance werden in jeden Schritt eingewoben. Bei personenbezogenen Daten gehört der DSGVO-konforme Umgang von Anfang an mitgedacht.
Unterm Strich läuft die Zukunft darauf hinaus, Data Ingestion schneller, zugänglicher und verlässlicher zu machen – damit Sie sich um Insights kümmern können statt um Infrastruktur.
Fazit: Das Wichtigste für Business-User
Wie Sie automatisiertes Data Scraping mit Thunderbit meistern Get Started Free
- Data Ingestion ist der entscheidende erste Schritt jeder datengetriebenen Initiative. Wer Erkenntnisse will, muss die Daten zuerst hereinholen – schnell und verlässlich.
- Moderne, KI-gestützte Tools wie Thunderbit öffnen Data Ingestion für alle, nicht nur für IT-Profis. Mit Scraping in 2 Klicks, KI-Feldvorschlägen und geplanten Jobs wird aus chaotischen Webdaten geschäftlicher Nutzen.
- Die richtige Tool-Wahl zählt: klassisches ETL für stabile, strukturierte interne Daten; moderne Cloud-Tools für breite Analytics-Anforderungen; Thunderbit für Web- und unstrukturierte Daten.
- Bleiben Sie am Ball: Automatisierung, Cloud und KI machen Data Ingestion schlauer und einfacher. Verharren Sie nicht in der Vergangenheit – entdecken Sie neue Lösungen und stellen Sie Ihre Datenstrategie zukunftssicher auf.
Beginnen Sie mit Thunderbit Webdaten aufzunehmen
FAQs
1. Was ist Data Ingestion, einfach erklärt?
Data Ingestion ist der Vorgang, Daten aus verschiedenen Quellen (etwa Websites, Datenbanken oder Dateien) einzusammeln und in ein zentrales System zu importieren, damit sie sich analysieren oder für Entscheidungen nutzen lassen. Es ist der allererste Schritt jeder Datenpipeline.
2. Wie unterscheidet sich Data Ingestion von Data Integration und Data Transformation?
Data Ingestion bedeutet, Rohdaten hereinzuholen. Data Integration führt Daten verschiedener Quellen zusammen und gleicht sie ab, während Data Transformation sie für die Analyse bereinigt und formatiert. Merksatz: Ingestion = sammeln, Integration = organisieren, Transformation = vorbereiten und kochen.
3. Was sind die größten Schwächen klassischer Data-Ingestion-Methoden?
Klassische Verfahren wie ETL sind langsam aufzusetzen, verlangen viel Programmierung, tun sich mit unstrukturierten Daten schwer und kommen mit heutigen Echtzeitanforderungen nicht mit. Hinzu kommen hoher Wartungsaufwand und mangelnde Flexibilität, sobald sich Quellen ändern.
4. Wie vereinfacht Thunderbit die Data Ingestion?
Thunderbit nutzt KI, damit jeder Webdaten in nur zwei Klicks scrapen und strukturieren kann – ganz ohne Programmierung. Es verarbeitet Unterseiten, Pagination und sogar wiederkehrende Jobs und exportiert die Daten direkt nach Excel, Google Sheets, Airtable oder Notion.
5. Wie sieht die Zukunft der Data Ingestion aus?
Sie dreht sich um Automatisierung, Cloud-first-Strategien und KI-gestützte Pipelines. Rechnen Sie mit mehr Echtzeit-Datenflüssen, klügerem Fehlerhandling und Tools, mit denen Business-User Data Ingestion per natürlicher Sprache oder über visuelle Oberflächen einrichten.
Mehr erfahren:
- Wie Sie mit KI jede Website scrapen
- Wie Sie automatisiertes Data Scraping mit Thunderbit meistern
- Was ist Data Ingestion?
- Data Ingestion: 7 Herausforderungen und 4 Best Practices
KI-Web-Scraper ausprobieren Get Started Free




