

Wie schnell das Web wächst, lässt sich kaum in Zahlen fassen: Tag für Tag kommen Milliarden neuer Seiten, Produkte, Bewertungen und Datensätze hinzu – und sie befeuern alles Mögliche, von der Marktanalyse über das Training von KI-Modellen bis hin zu Ihrem nächsten Amazon-Kauf. Nach vielen Jahren in SaaS und Automatisierung weiß ich, wie stark eine einzige fundierte Datengrundlage über Gelingen oder Scheitern einer Geschäftsentscheidung bestimmen kann. Genau dort liegt aber auch die Krux: Diese Webdaten zu sammeln, aktuell zu halten und auszuwerten, wird von Jahr zu Jahr aufwendiger statt einfacher. Klassische Web Scraper kommen mit dem Tempo schlicht nicht mehr mit, und Unternehmen brauchen einen klügeren, schnelleren Weg, um aus dem Internet brauchbare Erkenntnisse zu ziehen. Hier setzt der Cloud Crawler an – ein Werkzeug, das im Hintergrund neu definiert, wie Organisationen Webdaten in großem Stil aufspüren und verwerten.
Bleibt die Frage: Was ist ein Cloud Crawler überhaupt? Wodurch hebt er sich von den Web Scrapern ab, die Sie womöglich schon kennen? Und weshalb verlassen sich Teams vom Vertrieb bis zu den Operations auf diese Technik, um in einer datengetriebenen Welt die Nase vorn zu behalten? Im Folgenden klären wir die Begriffe, räumen mit dem Fachjargon auf und zeigen, wie Cloud Crawler – allen voran die Lösung von Thunderbit – die Branchenregeln für moderne Unternehmen neu schreiben.
Was ist ein Cloud Crawler? Die nächste Stufe der Datenerkennung
Daten von jeder Website mit KI extrahieren Get Started Free
Ein Cloud Crawler ist mehr als ein Web Scraper, der zufällig in der Cloud läuft. Treffender ist das Bild einer Engine für Datenerkennung: ein intelligentes, cloudbasiertes System, das eigenständig riesige Datenmengen im Netz findet, extrahiert und auswertet. Ein herkömmlicher Web Scraper holt sich Informationen von einer Handvoll Seiten – meist nacheinander und oft nur auf einem einzigen Gerät. Ein Cloud Crawler spielt in einer anderen Liga: Er läuft in leistungsstarken Rechenzentren, nimmt sich Tausende oder gar Millionen Seiten parallel vor und verarbeitet alles von Text über Bilder bis zu PDFs – unabhängig davon, wie verschachtelt oder groß die Zielwebsite ist.
Ein Vergleich macht es greifbar: Der Web Scraper gleicht einem einzelnen Bibliothekar, der Passagen aus einem Buch von Hand abschreibt. Der Cloud Crawler ist eine ganze Mannschaft aus Supercomputern, die zeitgleich jedes Buch im Regal durchgeht, Inhalte markiert, ordnet und analysiert. Das Resultat: Unternehmen bekommen umfassendere, aktuellere und besser verwertbare Daten – ohne die Engpässe lokaler Hardware und ohne mühsame Handarbeit (Sitebulb, Octoparse).
Cloud Crawler vs. klassischer Web Scraper: Wo liegt der echte Unterschied?
Wer schon einmal mit einem Web Scraper gearbeitet hat, kennt das Vorgehen: Seite angeben, gewünschte Daten festlegen, das Tool die Informationen herausziehen lassen. Doch je größer und vielschichtiger das Web wird, desto offensichtlicher werden die Grenzen dieses Ansatzes. So unterscheiden sich Cloud Crawler und klassische Web Scraper im direkten Vergleich:
| Merkmal/Aspekt | Klassischer Web Scraper | Cloud Crawler |
|---|---|---|
| Bereitstellung | Läuft auf Ihrem lokalen Gerät oder Server | Läuft in der Cloud (entfernte Rechenzentren) |
| Skalierung | Begrenzung durch die Leistung Ihres Computers | Massive Parallelisierung – tausende Seiten gleichzeitig |
| Geschwindigkeit | Langsamer, besonders bei großen Aufgaben | Hochgeschwindigkeits-Batch-Verarbeitung |
| Wartung | Braucht häufige Updates, bricht bei Website-Änderungen | Cloudbasiert, automatisch aktuell, deutlich robuster |
| Datentypen | Meist Text, manchmal Bilder | Text, Bilder, PDFs, komplexe Layouts |
| Zugriff | An Ihr Gerät/Ihr Netzwerk gebunden | Von überall und auf jedem Gerät nutzbar |
| Zeitplanung | Manuell oder einfache Automatisierung | Erweiterte Zeitplanung, wiederkehrende Jobs |
| Am besten geeignet für | Kleine Projekte, einfache Websites | Große, häufige oder komplexe Datenanforderungen |
Cloud Crawler sind für das Web von heute gebaut – für eine Welt, in der Daten allgegenwärtig sind und Tempo wie Skalierung nicht zur Debatte stehen (GPTBots, Octoparse).
Wie Cloud Crawler die Datenerfassung enorm beschleunigen
Jetzt wird es interessant. Cloud Crawler schöpfen die Rechenleistung der Cloud aus, um Tausende Webseiten gleichzeitig abzuarbeiten. So extrahieren Sie einen kompletten E-Commerce-Katalog, beobachten Wettbewerberpreise auf Dutzenden Portalen oder führen Immobilienangebote aus allen großen Plattformen zusammen – und das in einem Bruchteil der Zeit, die ein klassischer Scraper bräuchte.
Warum das zählt? Weil in Branchen wie E-Commerce, Finanzwesen oder Immobilien aktuelle Daten über alles entscheiden. Preise, Lagerbestände und Markttrends können sich im Minutentakt verschieben. Stunden oder gar Tage zu warten, bis ein lokaler Scraper durchläuft, ist da keine Option. Cloud Crawler hängen weder am RAM Ihres Laptops noch am Büro-WLAN – sie wachsen bei Bedarf mit und stemmen auch große Jobs ohne Stress (Zyte, Octoparse).
Besonders deutlich profitieren diese Branchen von dem Tempogewinn:
- E-Commerce: Preisüberwachung, Zusammenführung von Produktkatalogen, Analyse von Bewertungen
- Immobilien: Aggregation von Inseraten, Verfolgung von Markttrends, Objektvergleiche
- Finanzen: Nachrichten- und Sentiment-Analyse, Monitoring von Aktien und Krypto, regulatorisches Tracking
- Vertrieb & Marketing: Lead-Generierung, Wettbewerbsrecherche, Trend-Erkennung
Und das ist noch längst nicht alles. Wer Webdaten in großem Umfang braucht, findet im Cloud Crawler einen verlässlichen Verbündeten.
Thunderbits Cloud-Crawler-Lösung: Schnell, flexibel und leistungsstark
An dieser Stelle setze ich kurz meinen Thunderbit-Hut auf (zugegeben, den lege ich ohnehin selten ab). Der Cloud-Scraping-Modus von Thunderbit ist unsere Antwort auf die heutige Datenherausforderung – ein Cloud Crawler für Business-Anwender, die Ergebnisse wollen statt Frust.
Das zeichnet Thunderbits Cloud Crawler aus:
- Batch-Scraping mit hoher Geschwindigkeit: Bis zu 50 Seiten parallel, mit Cloud-Servern in den USA, der EU und Asien für globale Reichweite. Schluss mit dem Warten, bis sich Ihr Laptop durch eine endlose Liste quält.
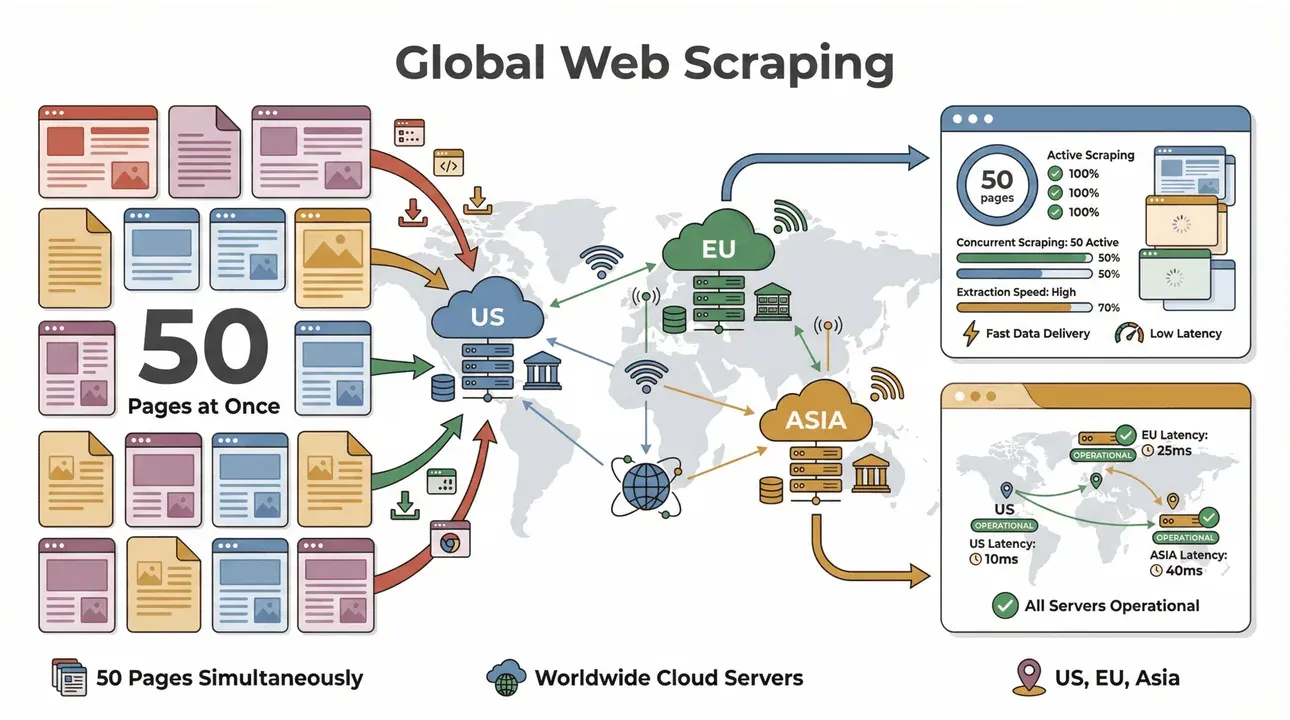
- Unterstützung komplexer Seiten: Die KI von Thunderbit meistert dynamische E-Commerce-Seiten, vertrackte PDFs und sogar die Extraktion von Bildern. Was im Web steckt, bekommt Thunderbit mit hoher Wahrscheinlichkeit heraus (Thunderbit).
- Crawling von Unterseiten: Sie möchten Ihre Daten mit Details von Unterseiten anreichern, etwa Produktangaben oder Autorenprofile? Thunderbits KI ruft jede Unterseite auf und übernimmt die Ergebnisse in Ihren Hauptdatensatz (Thunderbit).
- Intelligente Datenstrukturierung: Über „AI Suggest Fields“ analysiert Thunderbit die Website und schlägt die passenden Spalten vor – ohne Code und ohne Vorlagenarbeit.
- Export überallhin: Schicken Sie Ihre Daten direkt nach Excel, Google Sheets, Airtable oder Notion. Oder laden Sie sie als CSV bzw. JSON herunter – ganz so, wie es Ihr Workflow verlangt (Thunderbit).
- Keine Wartung nötig: Thunderbits KI stellt sich auf Website-Änderungen ein, sodass Sie keine kaputten Scraper mehr flicken müssen (Thunderbit).
Und ja, all das lässt sich in einem kostenlosen Tarif ausprobieren – Sie müssen mir also nicht aufs Wort glauben.
Thunderbit Cloud Scraper kostenlos testen
Bereitstellung von Cloud Crawlern: Cloud oder lokal – was passt besser?
Zu den größten Stärken von Cloud Crawlern zählt die Freiheit bei der Bereitstellung. Mit einem klassischen lokalen Crawler hängen Sie an einem bestimmten Gerät, einem bestimmten Netzwerk und oft genug an einem Berg Einrichtungsprobleme. Geht Ihr Rechner in den Ruhezustand oder reißt die Verbindung ab, stockt der Crawl. Mehr Skalierung bedeutet zusätzliche Hardware oder mehrere Skripte, die parallel laufen müssen.
Cloud Crawler kehren dieses Prinzip um:
- Keine Spezialhardware erforderlich: Die gesamte Rechenarbeit passiert in der Cloud. Große Crawls starten Sie auch von einem Chromebook, einem Mac oder dem Smartphone aus.
- Zugriff von überall: Unterwegs? Im Homeoffice? Kein Thema – Ihr Cloud Crawler steht jederzeit bereit.
- Einfache Skalierung: Statt 100 jetzt 10.000 Seiten crawlen? Erhöhen Sie einfach die Jobgröße – ganz ohne IT-Abteilung.
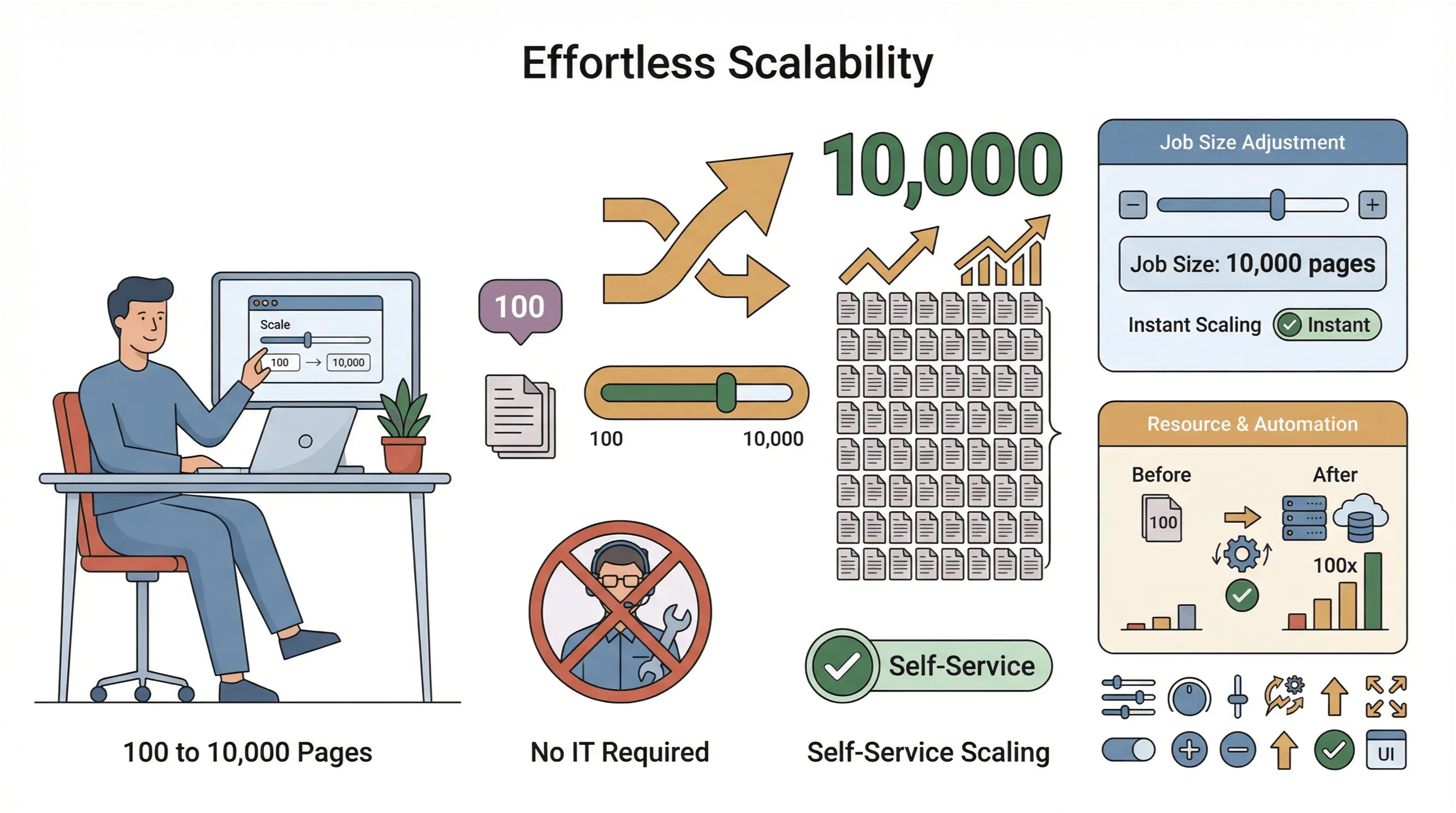
- Globale Datenerfassung: Dank Cloud-Servern in mehreren Regionen erreichen Sie geografisch eingeschränkte Inhalte und behalten die Compliance leichter im Griff (PromptCloud).
Sicherheit und Compliance bleiben dabei immer zentrale Themen. Die besten Cloud Crawler – Thunderbit eingeschlossen – setzen auf verschlüsselte Verbindungen, halten sich an die Nutzungsbedingungen der Websites und bieten Funktionen, mit denen Sie sensible Daten verantwortungsvoll handhaben. Bei datenrelevanten Vorhaben empfiehlt sich ohnehin ein Blick auf die DSGVO: Erfassen Sie nur, was Sie wirklich brauchen, und dokumentieren Sie die Rechtsgrundlage.
Praxiswirkung: Wie Cloud Crawler datengetriebene Strategien verändern
Werden wir konkret. Warum steigen Unternehmen auf Cloud Crawler um? Weil die Ergebnisse messbar sind:
- Marktanalyse in Echtzeit: Händler überwachen mit Cloud Crawlern Preise und Bestände der Konkurrenz live und ermöglichen so dynamische Preisgestaltung und schnellere Reaktionen auf Marktbewegungen (Zyte).
- Vorhersage von Verbrauchstrends: Marken bündeln Bewertungen, Social-Media-Beiträge und Forendiskussionen, um aufkommende Trends früh zu erkennen und Kampagnen flexibel nachzujustieren.
- Vertrieb & Lead-Generierung: Vertriebsteams bauen aktuelle Lead-Listen aus Verzeichnissen, Event-Websites und sogar PDFs auf – und füttern ihre CRMs mit frischen, qualifizierten Kontakten (Thunderbit).
- Operations & Compliance: Finanzunternehmen behalten mit Cloud Crawlern regulatorische Updates, Nachrichten und Einreichungen über verschiedene Rechtsräume hinweg im Auge – das senkt Risiken und hält sie bei Änderungen auf dem Laufenden.
Der gemeinsame Nenner? Cloud Crawler verschaffen Teams die Mittel, schneller zu handeln, fundierter zu entscheiden und an Wettbewerbern vorbeizuziehen, die noch im Schneckentempo arbeiten.
Wichtige Funktionen, auf die Sie bei einem Cloud Crawler achten sollten
Thunderbit: Preise und Funktionen ansehen Get Started Free
Cloud Crawler ist nicht gleich Cloud Crawler. Wenn Sie Optionen gegeneinander abwägen, sind diese Funktionen entscheidend – und genau hier spielt Thunderbit seine Stärken aus:
- Skalierbarkeit: Verarbeitet das Tool Tausende Seiten gleichzeitig? Oder wird es langsam, sobald die Jobs wachsen?
- Benutzerfreundlichkeit: Verstehen auch Nicht-Techniker die Oberfläche? Lässt sich ein Scrape mit wenigen Klicks aufsetzen?
- Unterstützung verschiedener Datentypen: Text, Bilder, PDFs, Unterseiten – kann das Tool all das verarbeiten?
- Integration: Exportiert es in Ihre bevorzugten Tools (Excel, Sheets, Notion, Airtable)?
- Zeitplanung: Lassen sich wiederkehrende Jobs für stets aktuelle Daten einrichten?
- KI-Unterstützung: Gibt es intelligente Feldvorschläge, Datenanreicherung und Anpassung an Website-Änderungen?
- Sicherheit & Compliance: Sind Ihre Daten und Zugänge geschützt? Hilft das Tool dabei, Datenschutzvorgaben einzuhalten?
Thunderbit deckt jeden dieser Punkte ab und ist damit eine starke Wahl für Teams, die Leistung ohne unnötigen Ballast suchen.
Der Einstieg: So nutzen Sie einen Cloud Crawler für Ihr Unternehmen
Sie wollen direkt loslegen? So sieht ein typischer Start mit einem Cloud Crawler wie Thunderbit für Business-Anwender aus:
- Installieren Sie die Thunderbit Chrome Extension: Schnell eingerichtet, ganz ohne IT-Aufwand.
- Wählen Sie Ihr Ziel: Öffnen Sie die Website, Liste oder das Dokument, das Sie auslesen möchten.
- Klicken Sie auf „AI Suggest Fields“: Lassen Sie Thunderbits KI die Seite scannen und die besten Spalten für die Extraktion vorschlagen.
- Bei Bedarf anpassen: Felder hinzufügen, entfernen oder umbenennen – ganz nach Ihrem Bedarf.
- Cloud-Scraping-Modus auswählen: Bei großen Jobs oder komplexen Websites wechseln Sie in den Cloud-Modus für maximale Geschwindigkeit.
- Scrape starten: Thunderbit verarbeitet bis zu 50 Seiten gleichzeitig in der Cloud.
- Prüfen und exportieren: Sichten Sie die Ergebnisse und exportieren Sie sie nach Excel, Google Sheets, Notion oder Airtable.
- Wiederkehrende Jobs planen: Für laufende Anforderungen richten Sie geplante Scrapes ein – Ihre Daten aktualisieren sich automatisch (Thunderbit Docs).
Ein Tipp: Starten Sie mit einem kleinen Auftrag, um ein Gefühl zu bekommen, und skalieren Sie dann hoch, sobald Sie sich sicherer fühlen. Und scheuen Sie sich nicht, Support oder Dokumentation von Thunderbit zu nutzen – genau dafür sind sie da.
Mit Thunderbit Cloud Crawling starten
Die Zukunft der Datenerfassung: Wohin entwickeln sich Cloud Crawler?
Die Cloud-Crawler-Revolution steht erst am Anfang. Auf diese Entwicklungen achte ich in den kommenden Jahren besonders:
- Intelligentere KI-Extraktion: Cloud Crawler erfassen Kontext, Zusammenhänge und sogar Stimmungen immer besser – und steigern damit den Wert der gesammelten Daten (GPTBots).
- Unterstützung neuer Datentypen: Rechnen Sie mit besserer Verarbeitung von Video, Audio und interaktiven Inhalten – nicht mehr nur von statischem Text und Bildern.
- Tiefere Automatisierung: Von automatisierter Planung bis zu Echtzeit-Benachrichtigungen werden Cloud Crawler für Business-Anwender zunehmend zum Selbstläufer.
- Mehr Compliance-Funktionen: Während sich die Datenschutzgesetze weiterentwickeln, bauen Cloud Crawler mehr Werkzeuge ein, um Teams regelkonform zu halten.
- Integration mit BI- und KI-Tools: Direkte Datenpipelines von Cloud Crawlern hin zu Analyseplattformen, Dashboards und Machine-Learning-Systemen.
Auf den Punkt gebracht: Cloud Crawler werden sich voraussichtlich zum Rückgrat digitaler Geschäftsstrategien entwickeln – und alles antreiben, von Produkteinführungen bis zu KI-gestützten Prognosen (Thunderbit Blog).
Fazit: Warum Cloud Crawler für moderne Unternehmen unverzichtbar sind
Kurz zusammengefasst: Das Web platzt vor Daten aus allen Nähten, und die altbewährten Methoden der Datenerfassung halten damit nicht mehr Schritt. Cloud Crawler sind die nächste Entwicklungsstufe – sie liefern Geschwindigkeit, Skalierung und Intelligenz, mit denen klassische Scraper schlicht nicht mithalten. Tools wie Thunderbit öffnen jedem Team, unabhängig vom technischen Hintergrund, den Zugang zum vollen Potenzial von Webdaten – für bessere Entscheidungen, schnellere Reaktionen und einen echten Wettbewerbsvorteil.
Wenn Sie manuelles Scraping und träge Daten hinter sich lassen wollen, ist jetzt der richtige Moment, herauszufinden, was ein Cloud Crawler für Ihr Unternehmen leisten kann. Probieren Sie den Cloud-Scraping-Modus von Thunderbit aus und erleben Sie, wie unkompliziert – und kraftvoll – moderne Datenerkennung sein kann. Wer tiefer einsteigen möchte, findet im Thunderbit Blog weitere Anleitungen, Tipps und Praxisbeispiele.
FAQs
1. Was ist ein Cloud Crawler in einfachen Worten?
Ein Cloud Crawler ist ein cloudbasiertes Tool, das große Datenmengen automatisch im Web findet, extrahiert und analysiert. Anders als klassische Scraper, die auf Ihrem lokalen Gerät laufen, arbeiten Cloud Crawler in leistungsstarken Rechenzentren und ermöglichen dadurch enorme Skalierung und Geschwindigkeit.
2. Worin unterscheidet sich ein Cloud Crawler von einem normalen Web Scraper?
Cloud Crawler laufen in der Cloud, verarbeiten tausende Seiten gleichzeitig, unterstützen komplexe Datentypen wie Bilder und PDFs und benötigen weder Wartung noch lokale Hardware. Herkömmliche Scraper sind durch die Leistung Ihres Geräts begrenzt und eignen sich am besten für kleinere, einfachere Aufgaben.
3. Was sind die wichtigsten Vorteile eines Cloud Crawlers?
Cloud Crawler ermöglichen schnelle Datenerfassung im großen Maßstab, unterstützen komplexe Websites, sind von überall aus zugänglich und bieten fortgeschrittene Funktionen wie Zeitplanung und KI-gestützte Extraktion. Sie sind ideal für Unternehmen, die schnell frische, verwertbare Daten benötigen.
4. Wie funktioniert Thunderbits Cloud Crawler für Business-Anwender?
Mit Thunderbits Cloud Crawler richten Sie einen Scrape mit wenigen Klicks ein – ganz ohne Code. Sie extrahieren Daten aus Websites, PDFs und Bildern, reichern sie per KI an und exportieren sie direkt nach Excel, Google Sheets, Notion oder Airtable. Das Tool ist für Nicht-Techniker gemacht, die Ergebnisse statt Komplexität wollen.
5. Ist Cloud Crawling sicher und mit Datenschutzgesetzen vereinbar?
Ja, führende Cloud Crawler wie Thunderbit verwenden verschlüsselte Verbindungen und bewährte Sicherheitsstandards. Achten Sie immer darauf, nur öffentlich zugängliche Daten zu erfassen und die Nutzungsbedingungen der Websites sowie Datenschutzvorgaben einzuhalten.
Bereit zu sehen, was ein Cloud Crawler leisten kann? Thunderbit herunterladen und noch heute mit der Welt der großskaligen, cloudbasierten Datenerfassung starten.
Thunderbit Cloud Crawler heute testen Get Started Free
Mehr erfahren




