
Das Internet ist ein riesiger, unaufhörlich wuchernder Dschungel. Tag für Tag kommen über 252.000 neue Websites hinzu, und allein der Google-Suchindex zählt mehr als 30 Milliarden Seiten. Wie behalten Suchmaschinen in dieser Flut eigentlich noch den Überblick – und wie finden Unternehmen darin überhaupt die berühmte Nadel im Heuhaufen? Diese Fragen höre ich nach Jahren in SaaS und Automatisierung immer wieder, und fast genauso oft kommt gleich die nächste hinterher: „Was ist eigentlich der Unterschied zwischen Web Crawling und Web Scraping? Ist das nicht dasselbe?“ Die kurze Antwort lautet: nein – und wer beides in einen Topf wirft, gerät schnell ins Straucheln.
Ob du im Vertrieb nach neuen Leads suchst, als E-Commerce-Manager die Preise im Auge behältst oder beim nächsten Meeting einfach mit Fachwissen punkten willst: Klären wir, was ein Web-Crawler tatsächlich leistet, wie er sich von einem Scraper unterscheidet und warum das passende Tool (etwa Thunderbit) dir eine Menge Ärger – und im Zweifel sogar dein Wochenende – ersparen kann.
Web-Crawler-Grundlagen: Was ist ein Web-Crawler?

Denk an den gewissenhaftesten Bibliothekar, den du dir vorstellen kannst: Er sortiert nicht nur Bücher ein, sondern geht jeden Tag sämtliche Regale ab, um neue Titel aufzuspüren. Genau das tut ein Web-Crawler – bloß mit Milliarden von Webseiten statt mit Büchern. Ein Web-Crawler (auch Spider oder Bot genannt) ist ein automatisiertes Programm, das das Netz systematisch durchkämmt, Links folgt und alles katalogisiert, was ihm unterkommt. Auf diese Weise bauen Suchmaschinen wie Google und Bing ihre gigantischen Indizes auf und machen das Web für uns alle durchsuchbar.
Namen wie „Googlebot“ oder „Bingbot“ sind dir sicher schon mal begegnet – das sind bekannte Web-Crawler, die im Hintergrund ihre Runden drehen. Daneben gibt es modernere Werkzeuge wie Firecrawl, mit denen Entwickler und Unternehmen ganze Websites erfassen und als strukturierte Daten für KI oder Analysen aufbereiten.
Wichtig ist die Unterscheidung: Crawling steht für Entdecken – also Seiten finden und indexieren, nicht gezielt Daten herausziehen. Für Letzteres ist das Web Scraping zuständig (dazu gleich mehr).
Wie funktioniert Web Crawling?
Sehen wir uns an, wie ein Web-Crawler vorgeht. Stell ihn dir als digitalen Entdecker vor, mit einem Rucksack voller „Seed-URLs“ – das sind die Startpunkte. Der Ablauf sieht so aus:
- Seed-URLs: Der Crawler beginnt mit einer Liste bekannter Webadressen.
- Abrufen & Analysieren: Er steuert jede URL an, lädt die Seite und hält Ausschau nach weiteren Links.
- Links folgen: Jeder neue Link wandert auf die To-do-Liste (die sogenannte URL-Frontier).
- Indexierung: Der Crawler speichert Informationen zu jeder Seite – mal den kompletten Inhalt, mal nur die Metadaten.
- Rücksichtnahme: Er wirft einen Blick in die robots.txt der Website, prüft, ob Crawling erlaubt ist, und legt Pausen ein, um Server nicht zu überlasten.
- Ständige Aktualisierung: Weil sich das Web pausenlos verändert, kehrt der Crawler regelmäßig zu den Seiten zurück und hält den Index aktuell.
Das ist ein bisschen so, als würdest du eine Stadt kartieren: jede Straße ablaufen, neue Gassen und Geschäfte notieren und deine Karte bei jeder Veränderung nachziehen.
Wichtige Komponenten eines Web-Crawlers
Auch ohne Technik-Hintergrund lohnt sich ein kurzer Blick unter die Haube:
- URL-Frontier (Queue): Die zentrale Aufgabenliste mit allen noch offenen URLs.
- Fetcher/Downloader: Holt die jeweilige Webseite ab.
- Parser: „Liest“ die Seite, zieht Links und manchmal weitere Infos heraus.
- Duplikatprüfung & URL-Filter: Verhindert Endlosschleifen und doppelte Besuche.
- Datenspeicher/Index: Hier werden alle gefundenen Inhalte für die spätere Nutzung abgelegt.
Stell dir das wie ein Fließband vor: Einer holt die Zeitung, der Nächste markiert die Schlagzeilen, ein weiterer archiviert die Ausschnitte, und jemand behält im Blick, welche Zeitungen als Nächstes dran sind.
Wie crawlt man eine Website? Tools und Methoden
Als Anwender im Business spielt man vielleicht mit dem Gedanken, einen eigenen Crawler zu bauen. Mein Rat: lieber sein lassen. Es gibt reichlich Tools, die dir diese Arbeit abnehmen – es sei denn, du hast vor, die nächste Suchmaschine zu erfinden.
Beliebte Web-Crawling-Tools:
- Scrapy: Open Source, für Entwickler, ideal für große Projekte.
- Apache Nutch: Für Big-Data-Indexierung und Forschung.
- Heritrix: Das Tool des Internet Archive für die Web-Archivierung.
- Screaming Frog SEO Spider: Bei SEOs besonders beliebt für Website-Analysen.
- Firecrawl: Modern, API-basiert, erlaubt das Crawlen und Extrahieren strukturierter Daten von ganzen Websites.
Achtung: Die meisten dieser Tools setzen technisches Know-how voraus. Selbst „No-Code“-Lösungen bringen oft eine Lernkurve mit – etwa beim Auswählen von HTML-Elementen, bei Website-Änderungen oder dynamischen Inhalten. Wenn du nur ein paar Seiten auslesen willst, brauchst du in aller Regel keinen vollwertigen Crawler.
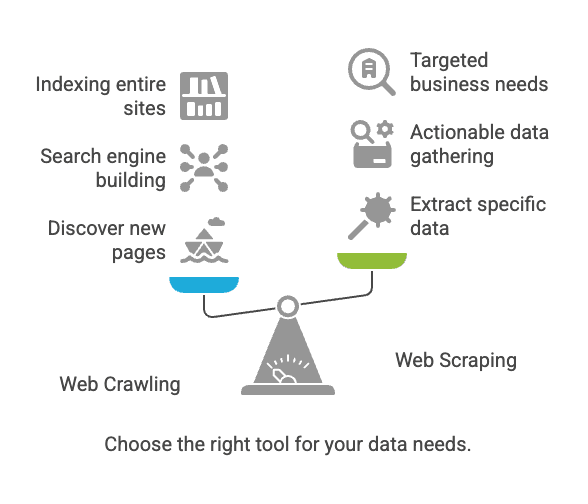
Web Crawling vs. Web Scraping: Wo liegt der Unterschied?
An dieser Stelle entsteht die meiste Verwirrung. Crawling und Scraping hängen zusammen, sind aber eben nicht dasselbe.
| Aspekt | Web Crawling | Web Scraping |
|---|---|---|
| Ziel | Webseiten entdecken und indexieren | Gezielt Daten aus Webseiten extrahieren |
| Vergleich | Bibliothekar, der jedes Buch katalogisiert | Wichtige Infos aus einzelnen Seiten kopieren |
| Ergebnis | Liste von URLs, Seiteninhalte, Sitemap | Strukturierte Daten (CSV, Excel, JSON usw.) |
| Nutzer | Suchmaschinen, SEO-Tools, Archivare | Vertrieb, E-Commerce, Analysten, Forscher |
| Typischer Umfang | Milliarden Seiten (breit angelegt) | Dutzende bis Tausende Seiten (gezielt) |
Auf den Punkt gebracht: Crawling dient dem Auffinden von Seiten, Scraping dem gezielten Sammeln von Daten (nimbleway.com).
Typische Herausforderungen und Best Practices beim Crawling und Scraping
Herausforderungen
- Website-Änderungen: Schon eine kleine Designanpassung kann dein Tool aus dem Tritt bringen (octoparse.com).
- Dynamische Inhalte: Viele Seiten laden Daten erst per JavaScript nach – etwas, das einfache Crawler nicht erfassen.
- Anti-Bot-Maßnahmen: CAPTCHAs, IP-Sperren und Logins können dich ausbremsen.
- Skalierung: Tausende Seiten zu crawlen, kann deinen Rechner (oder deine IP) an die Grenze bringen.
- Rechtliche/ethische Fragen: Öffentlich zugängliche Daten zu scrapen, ist meist erlaubt, doch prüfe immer die Nutzungsbedingungen und Datenschutzgesetze (web.instantapi.ai).
Best Practices
- Das richtige Tool wählen: Wenn du nicht programmierst, fang mit einem No-Code-Scraper an.
- Datenbedarf klar definieren: Überleg genau, welche Daten du brauchst und wofür.
- Website-Regeln respektieren: Wirf stets einen Blick in
robots.txtund die Nutzungsbedingungen. - Server schonen: Bau Pausen zwischen den Anfragen ein, damit du Websites nicht überlastest.
- Wartung einplanen: Websites ändern sich – rechne mit gelegentlichen Anpassungen.
- Daten sauber und sicher ablegen: Prüfe die Ergebnisse auf Duplikate und Fehler.
Typische Anwendungsfälle: Crawling vs. Scraping
Web Crawling
- Suchmaschinen-Indexierung: Googlebot und Bingbot crawlen das Web, um Suchergebnisse aktuell zu halten (en.wikipedia.org).
- Web-Archivierung: Das Internet Archive crawlt Seiten für die Wayback Machine.
- SEO-Audits: Tools crawlen deine Website, um etwa fehlerhafte Links aufzuspüren.
Web Scraping
- Preisüberwachung: Händler scrapen die Produktseiten der Konkurrenz für Preisanalysen (nextgeninvent.com).
- Lead-Generierung: Vertriebsteams scrapen Verzeichnisse nach Kontaktdaten.
- Content-Aggregation: News- oder Jobportale bündeln Inhalte aus verschiedenen Quellen.
- Marktforschung: Analysten scrapen Bewertungen oder Social Media für Stimmungsanalysen.
Fun Fact: Über 82 % der E-Commerce-Unternehmen setzen Web Scraping für externe Daten ein. Wer es nicht tut, dessen Konkurrenz tut es vermutlich.
Wann solltest du Crawling oder Scraping einsetzen?
Eine schnelle Entscheidungshilfe:
-
Musst du neue Seiten entdecken oder eine ganze Website indexieren?
→ Setz auf Web Crawling.
-
Weißt du bereits, wo deine Daten liegen (bestimmte Seiten oder Bereiche)?
→ Dann genügt Web Scraping.
-
Baust du eine Suchmaschine oder willst das Web archivieren?
→ Crawling ist gefragt.
-
Willst du gezielt Daten für Vertrieb, Preise oder Analysen sammeln?
→ Scraping ist die richtige Wahl.
-
Unsicher?
→ Fang mit Scraping an. Für die meisten Business-Anwendungen reicht das vollkommen.
Für die meisten Unternehmen ist Scraping die Antwort – gezielte, strukturierte Daten, mit denen du sofort weiterarbeiten kannst.
Web Scraping für Unternehmen: Die Vorteile von Thunderbit
Warum sollten sich gerade Anwender im Business – vor allem ohne Programmierkenntnisse – auf Scraping verlegen? Und warum ist Thunderbit genau dafür gebaut?
Ich habe schon zu viele Teams gesehen, die Tage (oder Wochen) mit angeblich „einfachen“ Scraping-Tools verloren haben. Deshalb haben wir Thunderbit entwickelt: damit das Extrahieren von Webdaten so leicht von der Hand geht wie zwei Klicks.
Das zeichnet Thunderbit aus:
- Zwei-Klick-Workflow: „KI-Felder vorschlagen“ antippen, dann „Scrapen“. Fertig. Kein Code, kein Herumfummeln mit Selektoren.
- Bulk-URL- & PDF-Support: Daten aus einer Liste von URLs oder sogar aus PDFs herausholen? Thunderbit kann beides.
- Export überallhin: Schick deine Daten direkt nach Google Sheets, Airtable, Notion oder lade sie als CSV/JSON herunter – ohne Zusatzkosten.
- Subpage-Scraping: Thunderbit ruft automatisch Unterseiten auf (etwa Produktdetails) und ergänzt deine Datentabelle.
- KI-Autofill: Automatisiere das Ausfüllen von Formularen und wiederkehrende Webaufgaben – wie ein digitaler Assistent für Routinejobs.
- Kostenlose E-Mail- & Telefon-Extraktoren: Mit einem Klick alle Kontaktdaten einer Seite erfassen.
- Cloud- oder Browser-Scraping: Wähle, was zu dir passt – Thunderbit scrapt blitzschnell in der Cloud oder direkt im Browser (ideal für Seiten hinter dem Login).
- Keine Lernkurve: Gebaut für Vertrieb, E-Commerce und Marketing – einfach Ergebnisse, ganz ohne IT-Abteilung.
Weitere Anwendungsbeispiele findest du in unseren Guides zum Scrapen von Amazon-Produkten, Scrapen von Google-Suchergebnissen oder Datenexport nach Excel.
Mit KI jede Website in 2 Klicks scrapen
Thunderbit vs. klassischer Web-Scraper
Hier der direkte Vergleich für Anwender im Business:
| Funktion/Bedarf | Thunderbit | Klassischer Web-Scraper (z. B. Scrapy, Nutch) |
|---|---|---|
| Einrichtung | 2 Klicks, kein Code | Technische Einrichtung, oft Scripting nötig |
| Lernkurve | Minimal | Hoch (vor allem für Nicht-Programmierer) |
| Unterseiten | KI-gesteuert, automatisch | Manuelles Scripting oder komplexe Konfiguration |
| Bulk-URLs/PDFs | Integriert | Meist nicht direkt unterstützt |
| Exportformate | Google Sheets, Airtable, Notion, CSV | CSV, JSON (oft manuelle Integration) |
| Anpassungsfähigkeit | KI passt sich Website-Änderungen an | Manuelle Updates bei Änderungen nötig |
| Business-Anwendungsfälle | Vertrieb, E-Commerce, SEO, Operations | Suchmaschinen-Indexierung, Forschung, Archivierung |
| Zeitplanung | Zeitsteuerung in natürlicher Sprache | Cronjobs oder externe Scheduler |
| Preis | Ab 15 $/Monat, kostenlose Stufe verfügbar | Kostenlos/Open Source, aber höherer Aufwand |
| Support | Nutzerorientiert, moderne Oberfläche | Community-basiert, Entwicklerfokus |
Mit Thunderbit kommst du im Handumdrehen von „Ich brauche diese Daten“ zu „Hier ist meine Tabelle“ – ganz ohne IT-Ticket. (Der Einstieg liegt bei rund 15 $/Monat, also etwa 14 €/Monat, und eine kostenlose Stufe gibt es obendrein.)
Fazit: Die richtige Methode für dein Unternehmen

Kurz und bündig:
- Web Crawling dient dem Entdecken und Indexieren von Seiten – ideal für Suchmaschinen und Website-Audits.
- Web Scraping extrahiert gezielt verwertbare Daten – etwa für Leads, Preisüberwachung oder Content-Aggregation.
- Für die meisten Unternehmen ist Scraping die Antwort. Und Programmierkenntnisse brauchst du dafür nicht.
Das Web wächst und wird immer verzweigter. Mit der richtigen Strategie – und dem passenden Tool – ziehst du aus diesem Wirrwarr wertvolle Erkenntnisse. Wenn du genug von komplizierten Scraping-Tools oder endlosen IT-Wartezeiten hast, probier Thunderbit aus. Du wirst staunen, wie viel sich mit nur zwei Klicks erledigen lässt (und vielleicht bleibt dir endlich das Wochenende frei).
Du willst Thunderbit live erleben? Hol dir unsere Chrome-Erweiterung oder stöbere durch weitere Tipps und Anleitungen im Thunderbit Blog.
Thunderbit Chrome-Erweiterung installieren
Viel Spaß beim Scrapen (und nicht beim Crawlen – es sei denn, du baust gerade die nächste Suchmaschine)!
FAQs
1. Brauche ich für mein Unternehmen sowohl einen Web-Crawler als auch einen Scraper?
Nicht zwingend. Wenn du ohnehin weißt, auf welchen Seiten deine Daten liegen, genügt ein Web-Scraper wie Thunderbit vollauf. Crawler lohnen sich vor allem dann, wenn du neue Seiten entdecken willst – etwa für eine komplette Website-Übersicht oder SEO-Audits.
2. Ist Web Scraping legal?
Grundsätzlich ist das Scrapen öffentlich zugänglicher Daten erlaubt – solange du keine Logins umgehst, keine Nutzungsbedingungen verletzt und keine sensiblen Daten sammelst. Wirf aber immer einen Blick in die robots.txt und die Datenschutzrichtlinien der Website, besonders bei kommerzieller Nutzung.
3. Was unterscheidet Thunderbit von anderen Web-Scraping-Tools?
Thunderbit ist für Anwender im Business ohne Programmierkenntnisse gemacht. Anders als klassische Scraping-Tools, die HTML-Kenntnisse oder manuelle Einrichtung verlangen, setzt Thunderbit auf KI, um Felder zu erkennen, durch Unterseiten zu navigieren und Daten im gewünschten Format auszugeben – alles in nur zwei Klicks.
4. Kann Thunderbit auch dynamische Websites und Seiten hinter dem Login scrapen?
Ja. Thunderbit bietet Scraping direkt im Browser für eingeloggte Sitzungen und dynamische Inhalte sowie Cloud-Scraping für Tempo und Skalierung. Je nach Datenbedarf wählst du den passenden Modus.
Weiterführende Artikel
- Was ist Data Scraping und wie funktioniert es 2025?
- Wie viele Websites gibt es weltweit?
- Was ist ein Web-Crawler? | Wie Web-Spider arbeiten | Cloudflare
KI-Web-Scraper kostenlos testen Get Started Free




