Das Internet ist wie ein riesiges Datenmeer – aber die wenigsten Infos lassen sich einfach so direkt weiterverwenden. Wer schon mal versucht hat, Produktpreise von einer Konkurrenzseite zu kopieren, eine Lead-Liste aus einem Online-Verzeichnis zu basteln oder die Konkurrenz im Auge zu behalten, weiß: Das ist mühsam, wiederholt sich ständig und Fehler schleichen sich schnell ein. Genau hier kommen Web-Scraper ins Spiel – und sind deshalb zum Geheimtipp für Teams in Vertrieb, Marketing und Operations geworden.
Mittlerweile nutzen fast Web-Scraping- oder Datenextraktionstools im Alltag. Egal ob für Wettbewerbsanalysen, Lead-Generierung oder Marktforschung: Scraper sind längst kein Nischenthema mehr, sondern ein echtes Must-have im Business. Aber was ist ein Scraper eigentlich genau? Wie funktioniert ein Scraper? Und wie kann man ihn nutzen, ohne IT-Studium? Lass uns das Schritt für Schritt anschauen.
Was ist ein Scraper? Einfach erklärt
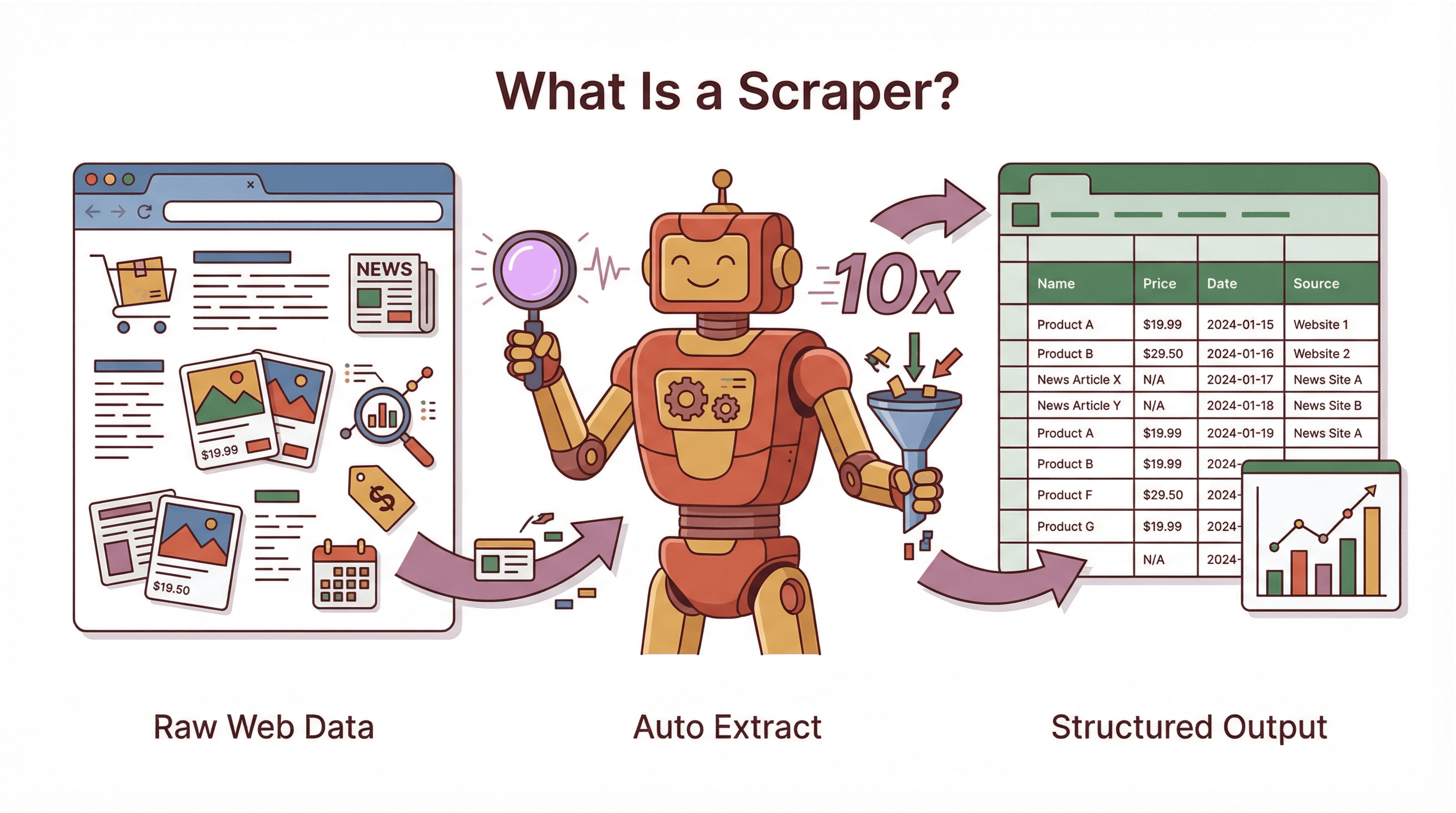 Ein Scraper ist eine Software (oder ein Skript), die automatisch Infos von Webseiten abzieht. Stell dir einen superflinken, unermüdlichen Assistenten vor: Anstatt Daten mühsam per Hand von einer Webseite in eine Tabelle zu kopieren, übernimmt der Scraper das für dich – blitzschnell und fast fehlerfrei. Wie ein Praktikant, der nie schläft, nie meckert und nie nach einer Gehaltserhöhung fragt.
Ein Scraper ist eine Software (oder ein Skript), die automatisch Infos von Webseiten abzieht. Stell dir einen superflinken, unermüdlichen Assistenten vor: Anstatt Daten mühsam per Hand von einer Webseite in eine Tabelle zu kopieren, übernimmt der Scraper das für dich – blitzschnell und fast fehlerfrei. Wie ein Praktikant, der nie schläft, nie meckert und nie nach einer Gehaltserhöhung fragt.
Damit keine Missverständnisse entstehen, hier die Einordnung im Bereich Automatisierung:
- Bot: Jedes automatisierte Programm, das Aufgaben im Internet erledigt. Scraper sind eine Art Bot.
- Crawler: Ein Bot, der systematisch das Web durchforstet, Links folgt und Seiten indexiert (wie eine Suchmaschine).
- Scraper: Ein Bot, der gezielt bestimmte Daten von Webseiten abzieht und unstrukturierte Inhalte in strukturierte Tabellen verwandelt.
Wenn das Web eine riesige Bibliothek ist, ist der Crawler der Bibliothekar, der alle Bücher findet, während der Scraper die gewünschten Fakten rausschreibt und in dein Notizbuch überträgt.
Scraper sind längst nicht nur was für Technik-Nerds oder Hacker. Sie werden für viele legitime Business-Zwecke genutzt: Preisvergleiche, öffentliche Datensammlung für Analysen, Wettbewerbsbeobachtung und vieles mehr. Das Entscheidende: Ein Scraper macht aus Webdaten, die für Menschen gedacht sind, strukturierte Infos, die Computer und Teams direkt weiterverarbeiten können.
Wie funktioniert ein Scraper? Von der Webseite zur strukturierten Tabelle
Schauen wir mal hinter die Kulissen. Im Kern läuft ein Scraper ähnlich ab wie ein Mensch – nur eben viel schneller:
- Startpunkt: Du gibst dem Scraper eine oder mehrere Ziel-URLs, von denen du Daten brauchst.
- Seitenabruf: Der Scraper lädt die Webseite, ähnlich wie dein Browser. Bei komplexen Seiten kann er die Seite auch „rendern“, um dynamische Inhalte oder unendliches Scrollen zu verarbeiten.
- Analyse und Datenerkennung: Der Scraper liest den HTML-Code der Seite und sucht gezielt nach den gewünschten Infos – zum Beispiel Produktnamen, Preise oder Kontaktdaten. Bei klassischen Scraper-Lösungen sagst du genau, wo gesucht werden soll (über „Selektoren“ oder Muster). Moderne KI-Scraper erkennen die relevanten Daten oft automatisch.
- Extraktion: Hat der Scraper die Daten gefunden, zieht er sie raus – egal ob Text, Zahlen, Links oder Bilder. Oft werden die Daten dabei auch bereinigt oder umgewandelt (z. B. „19,99 €“ in eine Zahl).
- Wiederholung: Du brauchst Daten von mehreren Seiten? Der Scraper kann Links folgen, durch Paginierung navigieren oder ganze URL-Listen automatisch abarbeiten.
- Ausgabe: Am Ende exportiert der Scraper die Ergebnisse in ein strukturiertes Format – zum Beispiel CSV, Excel, Google Sheets oder eine Datenbank. Du bekommst eine saubere, direkt nutzbare Tabelle.
Kurz gesagt: Seite besuchen → Infos finden → extrahieren → wiederholen → exportieren. Was manuell Tage dauern würde, erledigt ein Scraper in Minuten oder Stunden.
Die wichtigsten Komponenten eines Scrapers
Die zentralen Bausteine sind:
- Navigator/Crawler: Findet und lädt die gewünschten Seiten, steuert Paginierung, folgt Links oder arbeitet Listen ab.
- Parser/Extractor: Liest den HTML-Code und erkennt die zu extrahierenden Daten – per Regel, Muster oder KI.
- Data Cleaner: Bereinigt und strukturiert die Daten (entfernt HTML-Tags, vereinheitlicht Formate usw.).
- Exporter: Speichert die Ergebnisse als Datei, Tabelle oder in einer Datenbank – bereit zur Weiterverarbeitung.
Manche Scraper sind einfache Skripte, andere vollwertige Plattformen. Der Kernprozess bleibt: finden, extrahieren, strukturieren, exportieren.
Arten von Scraper-Tools: Code-basiert vs. KI-gestützt
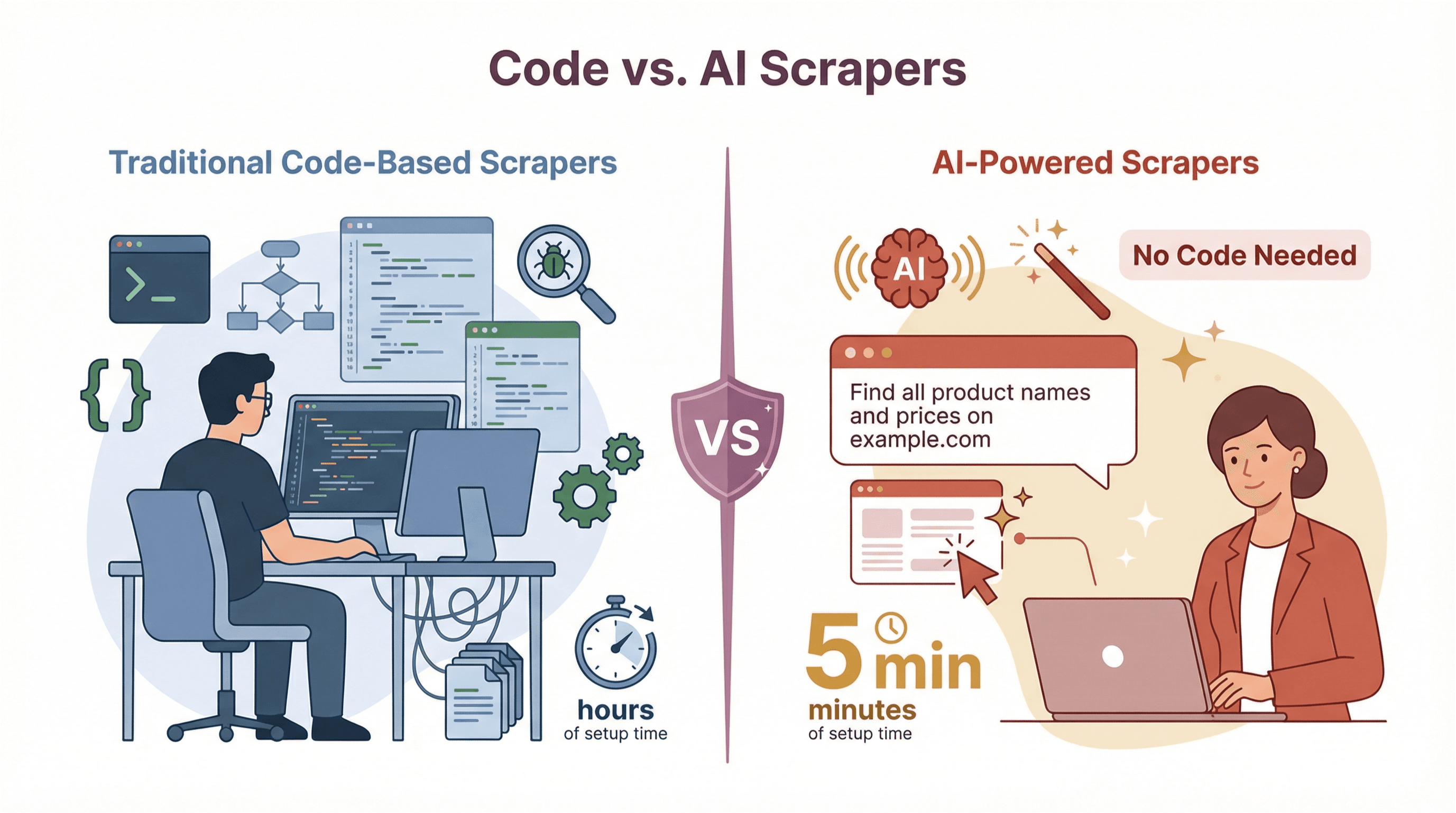 Nicht alle Scraper sind gleich. Im Laufe der Zeit haben sich zwei Haupttypen durchgesetzt:
Nicht alle Scraper sind gleich. Im Laufe der Zeit haben sich zwei Haupttypen durchgesetzt:
Klassische, code-basierte Scraper
Das sind die Oldschool-Tools im Web-Scraping. Sie brauchen Programmierkenntnisse – meist in Python, JavaScript oder einer anderen Skriptsprache. Du (oder dein Entwickler) schreibst Code, der dem Scraper genau sagt, welche Seiten besucht, welche HTML-Elemente angesprochen und wie Paginierung gehandhabt werden soll.
Vorteile:
- Maximale Flexibilität – fast jede Webseite und Datenstruktur ist möglich.
- Ideal für individuelle, komplexe oder große Projekte.
Nachteile:
- Hohe technische Hürde – Programmierkenntnisse sind Pflicht.
- Anfällig – schon kleine Layout-Änderungen auf der Webseite können das Skript aushebeln.
- Wartungsintensiv – regelmäßige Anpassungen nötig.
No-Code- und KI-gestützte Scraper
Willkommen in der Zukunft. Diese Tools richten sich an Business-Anwender, nicht an Entwickler. Manche bieten visuelle Oberflächen (Point-and-Click), die neueste Generation – wie – nutzt KI, um die relevanten Daten anhand einer einfachen Beschreibung zu erkennen.
Vorteile:
- Keine Programmierung nötig – jeder kann sie nutzen.
- Schneller Start – in wenigen Minuten einsatzbereit.
- Anpassungsfähig – KI erkennt Layout-Änderungen und dynamische Inhalte.
- Geringer Wartungsaufwand – weniger Zeit für Reparaturen.
Nachteile:
- Weniger individuell anpassbar für sehr spezielle Aufgaben.
- Teilweise durch die Möglichkeiten des Tools begrenzt (diese Lücke wird aber immer kleiner).
Vergleichstabelle: Code-basiert vs. KI-gestützt
| Aspekt | Code-basierte Scraper | KI-gestützte/No-Code-Scraper |
|---|---|---|
| Benutzerfreundlichkeit | Programmierkenntnisse erforderlich | Keine Programmierung nötig |
| Einrichtungsdauer | Stunden oder Tage | Minuten |
| Anpassungsfähigkeit | Anfällig bei Webseiten-Änderungen | Anpassungsfähig – KI erkennt Änderungen |
| Wartung | Hoch – regelmäßige Updates nötig | Gering – KI aktualisiert sich selbst |
| Dynamische Inhalte | Zusätzliche Tools nötig (z. B. Selenium) | KI verarbeitet JS, Infinite Scroll etc. |
| Datenqualität | Abhängig von manueller Einrichtung | Hoch – kontextbezogene Extraktion |
| Skalierbarkeit | Eigene Skripte für Skalierung nötig | Cloud-Skalierung direkt verfügbar |
| Export/Integration | Manueller Code für Ausgabe | Ein-Klick-Export zu Sheets, Excel etc. |
| Kosten | Kostenlose Tools, aber hoher Arbeitsaufwand | SaaS-Preise, oft mit Gratis-Tarif |
Gerade für Business-Anwender sind KI-gestützte Scraper ein echter Gamechanger: Sie sind schneller, einfacher und zuverlässiger – besonders für alltägliche Datenauswertungen.
Wann welches Scraper-Tool wählen?
- Code-basiert: Wenn du sehr spezielle, komplexe Anforderungen hast und Entwicklerressourcen verfügbar sind.
- KI-gestützt/No-Code: Wenn du schnell starten willst, keine Programmierkenntnisse hast oder viele verschiedene Seiten mit minimalem Aufwand auslesen möchtest.
Für die meisten Teams in Vertrieb, Marketing und Operations sind KI-Tools wie Thunderbit die beste Wahl.
Thunderbit: Die neue Scraper-Generation für Unternehmen
Schauen wir uns an, wie das Scraping revolutioniert (oder zumindest deutlich vereinfacht). Als KI-Web-Scraper Chrome-Erweiterung richtet sich Thunderbit an Business-Anwender, die Ergebnisse ohne Technikstress wollen.
Das macht Thunderbit besonders:
- KI-Feldvorschläge: Ein Klick genügt – Thunderbits KI analysiert die Seite und schlägt die wichtigsten Spalten vor (z. B. „Name“, „Preis“, „E-Mail“). Kein HTML, keine Selektoren nötig.
- 2-Klick-Scraping: Nach den KI-Vorschlägen einfach auf „Scrapen“ klicken. Thunderbit sammelt die Daten und zeigt sie übersichtlich in einer Tabelle an – bereit zum Export.
- Subseiten- & Paginierungs-Scraping: Du brauchst mehr Details? Thunderbit besucht automatisch Unterseiten (z. B. Produktdetails oder LinkedIn-Profile) und ergänzt deine Tabelle. Auch Paginierung und unendliches Scrollen werden unterstützt.
- Cloud- vs. Browser-Modus: Scrape direkt im Browser (ideal für eingeloggte Seiten) oder lass Thunderbits Cloud-Server die Arbeit übernehmen (besonders schnell für öffentliche Seiten).
- Sofort-Vorlagen: Für bekannte Seiten (Amazon, Zillow, Instagram usw.) gibt es fertige Templates – einfach laden und loslegen.
- Kostenloser, unbegrenzter Export: Exportiere deine Daten nach Excel, Google Sheets, Airtable, Notion oder als CSV/JSON – ohne Bezahlschranke, auch im Gratis-Tarif.
- KI-Autofill: Automatisiere Formulare und wiederkehrende Webaufgaben – ebenfalls kostenlos.
- Geplantes Scraping: Lass Scraper nach Zeitplan laufen (z. B. jeden Morgen) und überlass das Timing der KI.
- Spezialisierte Extraktoren: Ein-Klick-Tools für E-Mails, Telefonnummern und Bilder – ideal für schnelle Aufgaben.
- Mehrsprachigkeit: Thunderbit unterstützt 34 Sprachen und kann weltweit eingesetzt werden.
Thunderbit wird von genutzt – vom Einzelunternehmer bis zum Großunternehmen. Es ist das Tool, das ich mir früher bei manueller Datenarbeit gewünscht hätte.
Die wichtigsten Thunderbit-Features im Überblick
So profitieren Unternehmen von Thunderbit:
- KI-Feldvorschläge: Spart stundenlange Einrichtung – einfach klicken und starten.
- Subseiten-Scraping: Holt mehr Details (z. B. vollständige Produktinfos oder Kontaktdaten) ohne Mehraufwand.
- Cloud- vs. Browser-Scraping: Flexibel für jede Webseite – öffentlich oder mit Login.
- Sofort-Vorlagen: Ein-Klick-Scraping für gängige Seiten – keine Einrichtung nötig.
- Kostenloser Datenexport: Daten schnell und ohne versteckte Kosten weiterverarbeiten.
Mehr dazu findest du in den oder auf unserem .
Praxisbeispiele: Wie Unternehmen Scraper nutzen
Scraper sind nicht nur was für Datenprofis – sie bringen in vielen Branchen echten Mehrwert. So setzen Teams sie ein:
| Branche/Funktion | Scraper-Anwendungsfall | Business-Nutzen |
|---|---|---|
| Vertrieb & Lead-Gen | Verzeichnisse für Leads scrapen, CRM-Daten anreichern | Größere, aktuellere Lead-Listen, schnellere Ansprache |
| Marketing | Wettbewerber-Blogs, Bewertungen, Social Media auslesen | Datenbasierte Kampagnen, Wettbewerbsvorteile |
| E-Commerce | Preise der Konkurrenz überwachen, Produktkataloge aktualisieren | Dynamische Preisgestaltung, besseres Sortiment |
| Immobilien | Immobilienangebote aggregieren, Markttrends analysieren | Schnellere Analysen, bessere Deals |
| Finanzen/Investments | News, Meldungen, alternative Daten scrapen | Informationsvorsprung, breitere Analysen |
| Forschung/Journalismus | Öffentliche Daten sammeln, Trends auswerten | Größere Stichproben, tiefere Einblicke |
Vertrieb, Marketing und E-Commerce: Beispiele aus der Praxis
Vertrieb:
Ein Vertriebsteam braucht eine Liste aller Einzelhändler in seiner Region. Statt stundenlang zu googeln, nutzt es Thunderbit, um ein Online-Verzeichnis zu scrapen – Namen, Adressen, Telefonnummern landen in Minuten in einer Tabelle. Mit Subseiten-Scraping werden sogar E-Mail-Adressen der Inhaber direkt von den Webseiten ergänzt.
Marketing:
Ein Marketingmanager will Wettbewerber-Blogthemen und Kundenstimmen verfolgen. Thunderbit extrahiert Überschriften und Veröffentlichungsdaten aus den Blogs der Konkurrenz und sammelt Bewertungen oder Tweets zur eigenen Marke. Das Team erkennt: 30 % der Bewertungen der Konkurrenz bemängeln den Support – und startet eine Kampagne, die den eigenen Service hervorhebt.
E-Commerce:
Ein E-Commerce-Manager richtet Thunderbit so ein, dass die Preise von 100 Top-Produkten bei der Konkurrenz alle 6 Stunden überwacht werden. So erkennt das Team Preisabweichungen sofort und kann schnell reagieren – das steigert den Umsatz. Auch Lieferantenseiten werden gescrapt, um den eigenen Produktkatalog aktuell zu halten.
Das Ergebnis? Weniger Zeitaufwand, präzisere Daten, bessere Entscheidungen.
Strategischer Nutzen und Compliance: Scraper verantwortungsvoll einsetzen
Mit großer Scraping-Power kommt auch Verantwortung (und ein paar rechtliche Aspekte). Das sollten Unternehmen beachten:
- Datenschutz: Wer personenbezogene Daten (z. B. E-Mails, Social-Profile) scrapt, muss Datenschutzgesetze wie DSGVO oder CCPA beachten. Am besten nur öffentliche, nicht sensible Daten erfassen – oder eine klare Rechtsgrundlage haben.
- Nutzungsbedingungen: Viele Webseiten verbieten Scraping in ihren AGB. Gerichte haben zwar teils zugunsten von Scraper-Anbietern entschieden (vor allem bei öffentlichen Daten), trotzdem sollte man die Bedingungen prüfen und vorsichtig vorgehen.
- robots.txt: Diese Datei gibt an, welche Bereiche einer Seite von Bots besucht werden dürfen. Sie ist zwar nicht rechtlich bindend, aber ein Gebot der Fairness.
- Rate Limiting: Webseiten nicht überlasten – Scraping sollte in menschlichem Tempo erfolgen und Server nicht überfordern.
- Urheberrecht: Daten zu extrahieren ist das eine, sie zu veröffentlichen das andere. Bleib bei Fakten (z. B. Preisen, Spezifikationen), nicht bei ganzen Artikeln oder geschützten Inhalten.
Best Practices:
- Offizielle APIs nutzen, wenn verfügbar.
- robots.txt und AGB prüfen.
- Nur öffentliche, nicht sensible Daten scrapen.
- Gescrapte Daten sicher speichern.
- Bei großen oder sensiblen Projekten rechtlichen Rat einholen.
Mehr dazu im .
Scraper-Tools: So findest du die passende Lösung
Bei der Auswahl eines Scraper-Tools solltest du Folgendes bedenken:
- Benutzerfreundlichkeit: Kann dein Team das Tool ohne Programmierkenntnisse nutzen?
- Skalierbarkeit: Kommt es mit deinem Datenvolumen klar?
- Anpassungsfähigkeit: Funktioniert es auch, wenn sich Webseiten ändern?
- Integration: Lassen sich die Daten einfach weiterverarbeiten?
- Compliance: Unterstützt das Tool dich bei rechtlichen Anforderungen?
- Support: Gibt es Hilfe, wenn du sie brauchst?
- Kosten: Passt das Preismodell zu deinen Anforderungen?
Eine schnelle Entscheidungshilfe:
| Bedarf/Szenario | Empfohlener Tool-Typ |
|---|---|
| Keine Programmierkenntnisse, schneller Start | KI-gestützt/No-Code (Thunderbit) |
| Individuelle, komplexe oder große Projekte | Code-basiert (Python, Scrapy) |
| Häufige Webseiten-Änderungen | KI-gestützt/No-Code |
| Großvolumige, automatisierte Workflows | Cloud-basierte, skalierbare Tools |
| Strenge Compliance-Anforderungen | Tools mit Compliance-Features |
Teste dein Wunsch-Tool am besten mit einem Pilotprojekt – so siehst du, wie es mit deinen echten Datenanforderungen umgeht, bevor du es im Unternehmen ausrollst.
Fazit: Die Zukunft von Scraper-Tools in der Unternehmensautomatisierung
Web-Scraper sind heute ein zentraler Baustein moderner Geschäftsprozesse. Sie machen versteckte Webdaten nutzbar und liefern wertvolle Erkenntnisse für Vertrieb, Marketing, E-Commerce und mehr. Dank KI-gestützter Tools wie kann heute jeder – nicht nur Entwickler – diese Möglichkeiten mit wenigen Klicks nutzen.
Da das Web immer komplexer wird und datenbasierte Entscheidungen zum Standard gehören, werden Scraper noch intelligenter, schneller und stärker in den Arbeitsalltag integriert. Die Zukunft? Scraper werden zu KI-Assistenten, die nicht nur Daten sammeln, sondern auch zusammenfassen, kategorisieren und direkt Insights liefern.
Du hast noch keinen modernen Scraper ausprobiert? Jetzt ist der perfekte Zeitpunkt. Starte klein, bleib compliant und erlebe, wie viel mehr du erreichst, wenn Webdaten dir direkt zur Verfügung stehen. Mehr Tipps, Anleitungen und Praxisbeispiele findest du im .
Häufige Fragen (FAQ)
1. Was ist der Unterschied zwischen einem Scraper und einem Crawler?
Ein Crawler durchsucht das Web systematisch, um Seiten zu finden und zu indexieren (wie eine Suchmaschine). Ein Scraper extrahiert gezielt bestimmte Daten von diesen Seiten. Viele Scraper haben Crawler-Funktionen, aber nicht jeder Crawler ist ein Scraper.
2. Ist Web-Scraping legal?
Web-Scraping ist legal, wenn es verantwortungsvoll gemacht wird – also nur öffentliche Daten genutzt, Datenschutzgesetze beachtet und die Nutzungsbedingungen der Webseiten geprüft werden. Sensible oder urheberrechtlich geschützte Inhalte sollten nicht ohne Erlaubnis gescrapt werden.
3. Muss ich programmieren können, um einen Scraper zu nutzen?
Nicht mehr! Moderne KI-Tools wie ermöglichen Scraping ohne Programmierung – mit wenigen Klicks oder einer einfachen Beschreibung.
4. Welche Daten kann ich mit einem Scraper extrahieren?
Du kannst Texte, Zahlen, Preise, E-Mails, Bilder, Links und vieles mehr extrahieren – praktisch alles, was auf einer Webseite sichtbar ist. Manche Scraper verarbeiten sogar PDFs, Bilder oder Unterseiten für noch mehr Details.
5. Wie finde ich den passenden Scraper für mein Unternehmen?
Schau auf die Fähigkeiten deines Teams, die Komplexität der Zielseiten, das Datenvolumen, Compliance-Anforderungen und Integrationsmöglichkeiten. Für die meisten Unternehmen bieten KI-Tools wie Thunderbit die beste Mischung aus Einfachheit, Geschwindigkeit und Zuverlässigkeit.
Neugierig, was ein moderner Scraper kann? und verwandle Webdaten in Geschäftserfolge – ganz ohne Code.
Mehr erfahren