
Jedes Mal, wenn du dein CRM synchronisierst, Versand-Updates abrufst oder zwei SaaS-Tools verbindest, erledigt eine REST-API im Hintergrund die eigentliche Arbeit. Die meisten denken nie darüber nach – bis etwas kaputtgeht.
Das Lustige daran: Selbst unter Entwicklern herrscht oft Verwirrung darüber, was eine API eigentlich „RESTful“ macht. Der Begriff wird so locker benutzt, dass es in einem Reddit-Thread hieß: „Ich glaube nicht, dass ich je eine einzige wirklich RESTful API auf Basis von Roy Fieldings Definition gebaut habe.“ Und das sagt ein Entwickler, kein Business-Anwender. Das Konzept stammt aus Roy Fieldings an der UC Irvine, in der er REST als Architekturstil beschrieb – also als Satz von Designbeschränkungen, nicht als Protokoll, nicht als Produkt und nicht als Spezifikation, die man einfach herunterlädt.
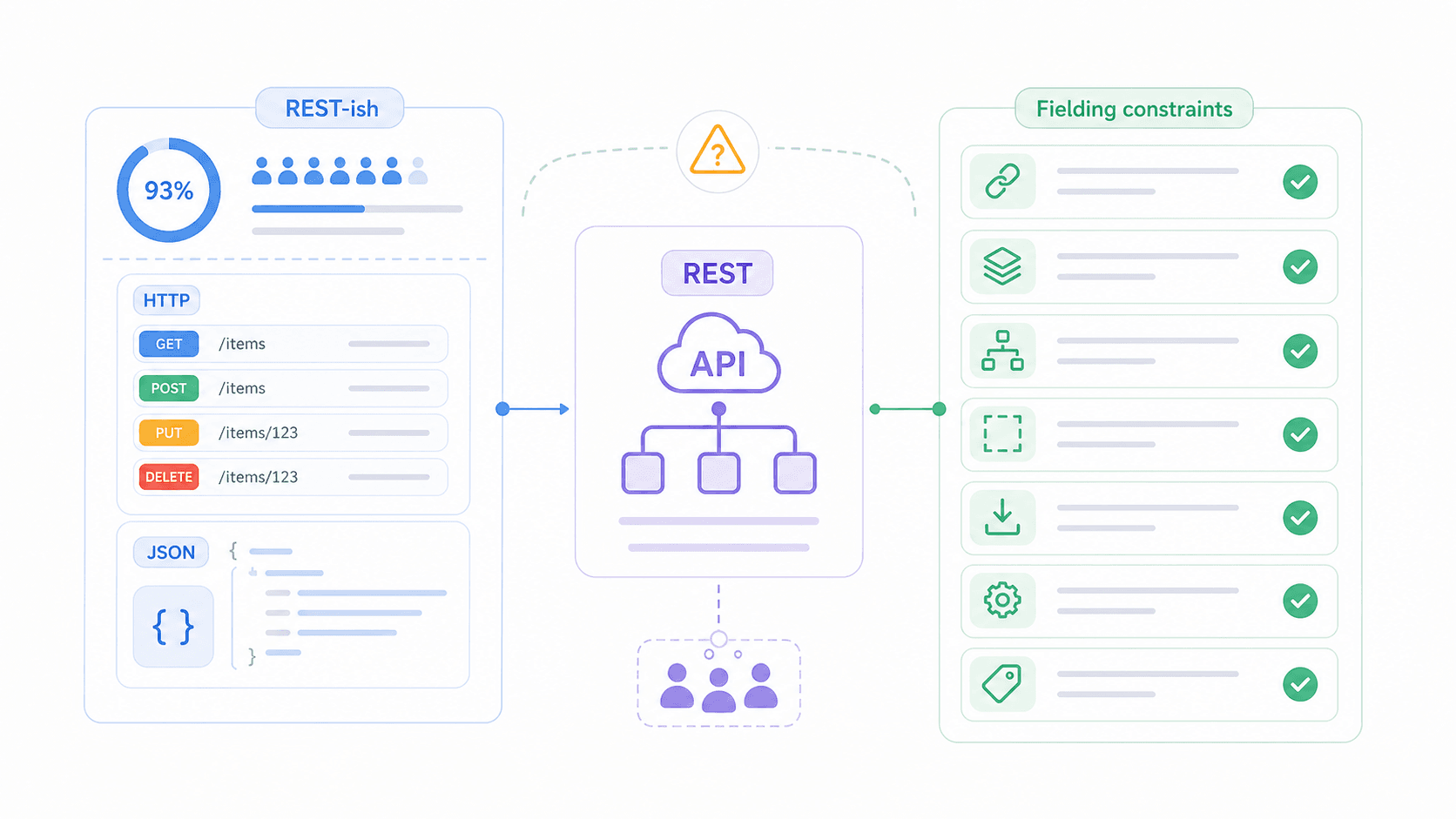
Laut dem liegt die Nutzung von REST unter API-Profis bei 93 %. Fast jeder nutzt es also, aber erstaunlich viele Teams verstehen nicht genau, was es tatsächlich verlangt. In diesem Artikel gehen wir die 6 zentralen REST-API-Eigenschaften in einfacher Sprache durch, zeigen dir, welche davon die meisten Teams falsch umsetzen, stellen ein Reifegradmodell vor, mit dem du dich selbst einordnen kannst, und vergleichen REST mit SOAP, GraphQL und gRPC.
Was ist eine REST-API? (Einfach erklärt)
REST (Representational State Transfer) ist ein Satz von Designregeln dafür, wie Softwaresysteme über ein Netzwerk miteinander kommunizieren sollen.
Genauer gesagt ist es ein Architekturstil, der Beschränkungen definiert – etwa Zustandslosigkeit, Cachebarkeit und eine einheitliche Schnittstelle –, die festlegen, wie Clients (dein Browser, eine mobile App oder ein Automatisierungstool) mit Servern interagieren (also dort, wo die Daten liegen). REST läuft typischerweise über HTTP und gibt meist JSON zurück, aber REST selbst ist an kein bestimmtes Protokoll und kein bestimmtes Datenformat gebunden.
Stell dir das wie Benimmregeln bei einem Abendessen vor. REST schreibt dir nicht vor, welches Essen du servierst oder welche Sprache du sprichst – es definiert, wie du Gerichte weiterreichst, wie du um Nachschlag bittest und wie du signalisierst, dass du fertig bist. Zwei Systeme, die nach denselben Regeln spielen, können verlässlich miteinander kommunizieren, selbst wenn sie sich vorher nie begegnet sind.
Was REST NICHT ist: REST ist kein Produkt, das du installierst. Es ist kein Protokoll wie HTTP oder SOAP. Und wenn man eine API „RESTful“ nennt, heißt das nicht automatisch, dass sie Fieldings ursprüngliche Beschränkungen vollständig erfüllt – meist bedeutet es nur, dass die API Ressourcen-URLs und HTTP-Methoden verwendet. Die Lücke zwischen „REST-ähnlich“ und „wirklich RESTful“ ist eine der größten Fehlerquellen der Branche, und genau darauf kommen wir gleich noch zurück.
Die 6 REST-API-Eigenschaften auf einen Blick
Bevor wir ins Detail gehen, hier die Kurzfassung. Fielding definierte 6 Beschränkungen, die eine API erfüllen sollte, um als RESTful zu gelten. Fünf sind Pflicht; eine ist optional.
| Beschränkung | Kernidee | Wichtigster Vorteil | Konkretes Beispiel |
|---|---|---|---|
| Client-Server | UI und Datenspeicherung trennen | Frontend und Backend können sich unabhängig weiterentwickeln | React-SPA ruft eine REST-API auf |
| Zustandslos | Jede Anfrage enthält den gesamten nötigen Kontext | Horizontale Skalierbarkeit, keine Session-Bindung | Auth-Token wird in jedem Request-Header mitgesendet |
| Cachebar | Antworten geben an, ob sie gecacht werden dürfen | Geringere Latenz und weniger Serverlast | Cache-Control: max-age=3600 in einer GET-Antwort |
| Einheitliche Schnittstelle | Standardisierte Interaktion mit Ressourcen | Vorhersagbare, leicht erlernbare API-Oberfläche | GET /users/42, DELETE /users/42 |
| Layered System | Der Client merkt nicht, ob er direkt mit dem Server spricht | Ermöglicht CDN-, Gateway- und Load-Balancer-Schichten | Client → CDN → API-Gateway → App-Server |
| Code-on-Demand (optional) | Server kann ausführbaren Code senden, um den Client zu erweitern | Erweiterte Client-Funktionalität bei Bedarf | API liefert ein JavaScript-Widget-Snippet |
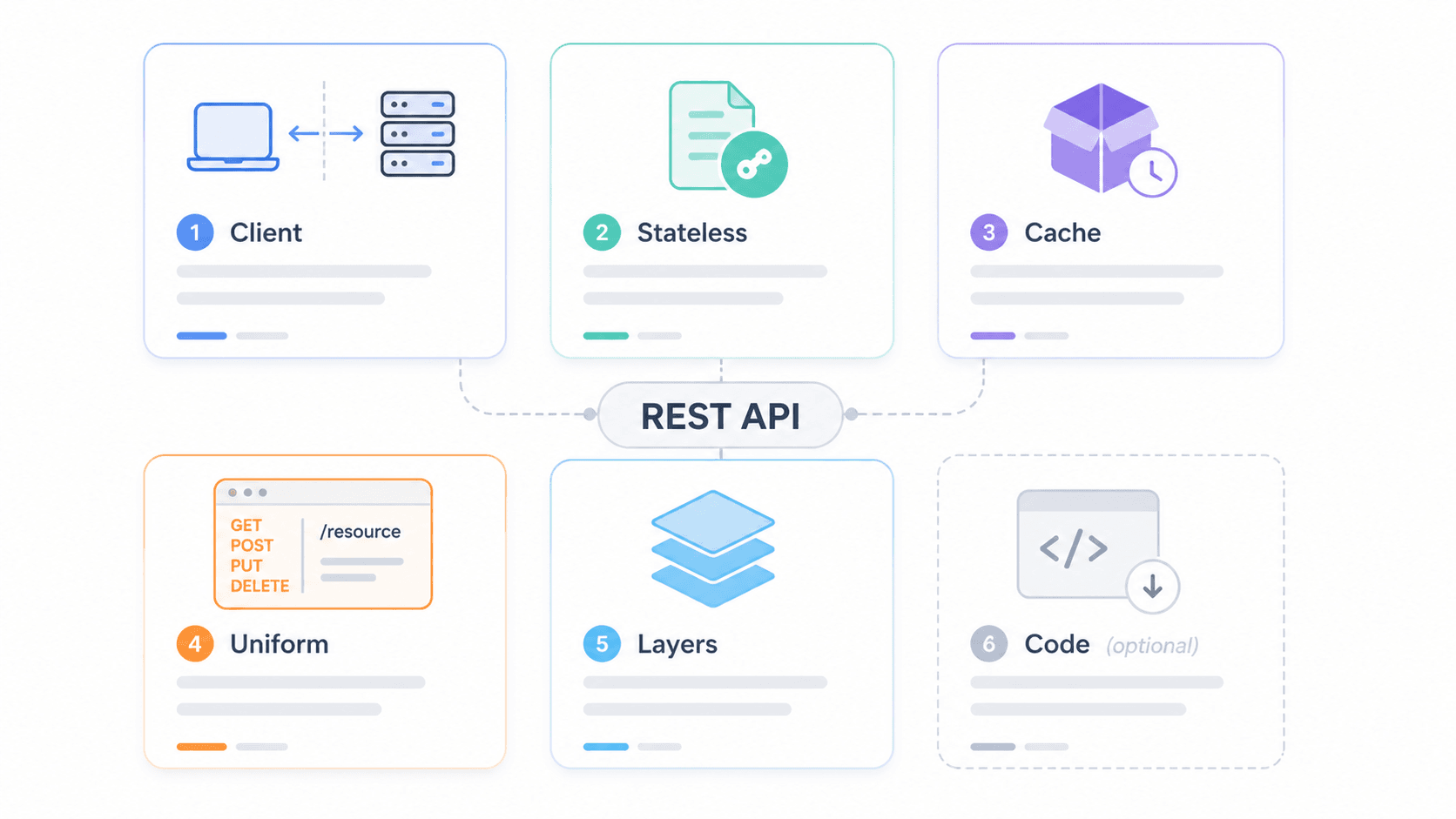
Um zu zeigen, wie diese Beschränkungen in einem echten System zusammenspielen, stell dir diese mehrschichtige Architektur vor:
1Client / Mobile App
2 ↓
3CDN / Edge Cache (z. B. Cloudflare)
4 ↓
5API-Gateway (Rate Limiting, Auth, CORS)
6 ↓
7Load Balancer
8 ↓
9Application Server
10 ↓
11Datenbank / interne DiensteDer Client spricht nur mit der CDN-Schicht. Er hat keine Ahnung, wie viele Ebenen dahinterliegen. Genau das ist die Idee des Layered-Systems – und auch der Punkt, an dem Sicherheit, Caching und Skalierung passieren, ohne dass der Client es wissen muss.
Jetzt die ausführliche Erklärung.
REST-API-Eigenschaften erklärt, Schritt für Schritt
Client-Server-Trennung
Fieldings erste Beschränkung: Der Client (also das, womit Nutzer interagieren) und der Server (wo Daten liegen und Logik läuft) müssen getrennt sein. Er nannte das Aufgabentrennung.
Warum ist das in der Praxis wichtig? Weil eine Mobile-Banking-App ein komplettes visuelles Redesign bekommen kann, ohne dass die Bank ihre Kontodatenbank oder ihre Transaktions-Engine anfassen muss. Die stellt zum Beispiel Kontakte, Kampagnen, Journeys und Push-Benachrichtigungen über Ressourcenendpunkte bereit. Ob du ein individuelles Dashboard baust, eine mobile App entwickelst oder ein Drittanbieter-Tool anschließt – das Backend bleibt dasselbe.
Für Business-Teams bedeutet das schnellere Iteration. Deine Frontend-Designer und Backend-Ingenieure müssen nicht im selben Release-Zyklus arbeiten. Solange der API-Vertrag stabil ist, können beide Seiten unabhängig vorankommen.
Zustandslosigkeit
Kein Gedächtnis zwischen den Requests. Jeder Aufruf vom Client an den Server muss alle Informationen enthalten, die der Server zur Verarbeitung braucht – der Server speichert nichts aus vorherigen Interaktionen.
Ich stelle mir das gern wie eine Support-Hotline vor, bei der du dein Problem jedes Mal neu erklären musst. Nervig? Sicher. Aber der Vorteil ist enorm: Jeder verfügbare Mitarbeiter kann dir helfen, und das Callcenter kann 500 weitere Agents dazunehmen, ohne irgendetwas neu zu entwerfen. Das ist horizontale Skalierung.
Technisch bedeutet Zustandslosigkeit: keine Sticky Sessions. Ein Load Balancer kann deine nächste Anfrage an jeden gesunden Server schicken. Fällt ein Server aus, übernimmt ein anderer nahtlos. Fieldings Dissertation weist , dass Zustandslosigkeit die Sichtbarkeit verbessert (Monitoring-Tools können jede Anfrage isoliert verstehen), die Zuverlässigkeit erhöht (Fehler beschädigen keinen gemeinsamen Session-Zustand) und die Skalierbarkeit steigert (Server können zwischen den Anfragen Ressourcen freigeben).
Die praktische Einschränkung: Reale Systeme haben natürlich trotzdem Authentifizierungstoken, Warenkörbe und OAuth-Flows. Der Punkt ist nicht, dass nirgendwo Zustand existiert – sondern dass der Server keinen Client-Session-Zustand zwischen Anfragen in seinem eigenen Speicher hält. Das übernehmen stattdessen Tokens, Datenbanken und gemeinsame Caches.
Cachebarkeit
Kann diese Antwort wiederverwendet werden? Genau diese Frage beantwortet Cachebarkeit. Antworten sollten ausdrücklich angeben, ob sie gecacht werden dürfen, und wenn ja, können Clients und Vermittler (etwa CDNs) sie für gleichartige zukünftige Anfragen wiederverwenden – das reduziert die Serverlast und erhöht die Geschwindigkeit.
Der HTTP-Mechanismus ist simpel: Header wie Cache-Control, ETag, Last-Modified und Expires sagen Caches, wie lange eine Antwort gültig ist und wann sie neu geprüft werden muss. Für Business-Leser: Stell dir eine Markierung auf der Antwort vor, die sagt „Diese Antwort gilt für die nächste Stunde“ oder „Bitte immer frisch abrufen“.
Der Performance-Effekt ist real. Die Tests von meldeten eine Verbesserung der Antwortzeiten im Tail Cache Hit um 50–100 ms. Und Fieldings eigene Dissertation dokumentiert, wie Web-Traffic von 100.000 Requests pro Tag im Jahr 1994 auf 600.000.000 Requests pro Tag im Jahr 1999 wuchs – wobei Caching ein entscheidender Designfaktor war.
Typischerweise cachebar: Produktkataloge, öffentliche Blog-Inhalte, Länder-/Währungslisten, API-Dokumentation.
Typischerweise nicht cachebar: persönliche Dashboards, Checkout-Summen, Kontostände, Admin-Berichte.
Einheitliche Schnittstelle
Diese Beschränkung bezeichnete Fielding selbst als das zentrale Merkmal, das REST von anderen Architekturstilen unterscheidet. Sie standardisiert, wie Clients mit Ressourcen interagieren, und macht APIs vorhersagbar.
Unter diesem Dach gibt es vier Teilbeschränkungen:
- Ressourcenidentifikation: Jede Ressource bekommt einen stabilen URI.
/customers/123ist ein Kunde./orders/456ist eine Bestellung. - Manipulation durch Repräsentationen: Clients arbeiten mit Repräsentationen (JSON, XML, HTML) von Ressourcen, nicht mit den internen Objekten des Servers.
- Selbstbeschreibende Nachrichten: Requests und Responses enthalten genug Metadaten – Methode, Statuscode, Inhaltstyp, Fehlerdetails –, damit jeder Vermittler oder Client sie verstehen kann.
- HATEOAS (Hypermedia as the Engine of Application State): Antworten enthalten Links zu verwandten Aktionen und Ressourcen, sodass Clients herausfinden können, was als Nächstes zu tun ist, ohne jeden Endpunkt hart zu kodieren.
Die Zuordnung der HTTP-Methoden ist der sichtbarste Teil der einheitlichen Schnittstelle:
| HTTP-Methode | CRUD-Bedeutung | Sicher? | Idempotent? | Beispiel |
|---|---|---|---|---|
| GET | Lesen | Ja | Ja | GET /products/42 |
| POST | Erstellen / Aktion | Nein | Nein | POST /orders |
| PUT | Gesamte Ressource ersetzen | Nein | Ja | PUT /users/42 |
| PATCH | Teilweise Aktualisierung | Nein | Nicht garantiert | PATCH /users/42 |
| DELETE | Löschen | Nein | Ja | DELETE /sessions/abc |
Die sagen ausdrücklich, dass GET sicher sein sollte und GET, PUT sowie DELETE idempotent sein sollten. Bekannte APIs von GitHub, Stripe und Spotify folgen diesen Mustern sehr eng – deshalb können Entwickler, die eine davon gelernt haben, die nächste oft schnell verstehen.
Layered System
Dein Client hat keine Ahnung, ob er mit dem Origin-Server, einem CDN-Cache, einem API-Gateway oder einem Load Balancer spricht. Genau darum geht es – jede Komponente sieht nur die unmittelbar benachbarte Schicht.
Das ermöglicht:
- CDNs wie Cloudflare vor deiner API, um Antworten zu cachen und zu beschleunigen
- API-Gateways (AWS API Gateway, Kong, Apigee), die Authentifizierung, Rate Limiting und Quotas übernehmen
- Load Balancer, die zustandslose Anfragen auf mehrere App-Server verteilen
Der nennt, dass AWS API Gateway nutzen, 26 % das Gateway von Azure und 31 % mehrere Gateways gleichzeitig. Layered Architecture ist also nicht theoretisch – so funktionieren Produktionssysteme tatsächlich.
Der Nachteil: Jede Schicht fügt etwas Latenz hinzu. Fielding argumentierte jedoch, dass gemeinsames Caching auf Vermittlerebenen diesen Overhead in den meisten realen Systemen mehr als ausgleicht.
Code-on-Demand (optional)
Das ist der Sonderfall. Code-on-Demand ist die einzige optionale REST-Beschränkung: Der Server kann ausführbaren Code – etwa JavaScript – senden, um die Client-Funktionalität dynamisch zu erweitern.
Das häufigste Praxisbeispiel ist ganz einfach: Eine Webseite lädt JavaScript von einem Server. Bei typischen JSON-REST-APIs, die von Mobile Apps, Backend-Jobs oder Automatisierungstools genutzt werden, wird Code-on-Demand jedoch fast nie eingesetzt. API-Clients wollen normalerweise keinen beliebigen Code von einem entfernten Server ausführen.
Für die meisten Leser ist diese Beschränkung eine Fußnote. Sie gehört zur Vollständigkeit in Fieldings Modell, spielt aber im Alltag bei der API-Bewertung kaum eine Rolle.
Was die meisten falsch verstehen: Sind die meisten REST-APIs überhaupt wirklich RESTful?
Hier kommt der Teil, über den niemand gern spricht: Die meisten produktiven APIs, die sich selbst „RESTful“ nennen, sind in Wirklichkeit HTTP-JSON-APIs mit REST-ähnlichen Konventionen. Sie verwenden Ressourcen-URLs, HTTP-Methoden und Statuscodes – und das war’s im Wesentlichen. Ein Reddit-Thread in r/softwarearchitecture enthielt Entwickler, die offen zugaben, noch nie eine wirklich Fielding-konforme REST-API gebaut zu haben. Eine andere Diskussion in r/learnprogramming artete in Streit darüber aus, ob sich überhaupt jemand darauf einigen könne, was „RESTful“ eigentlich bedeutet.
Eine Studie aus dem Jahr 2026, in der 16 REST-API-Experten interviewt wurden, zeigte: Obwohl Leitlinien die Nutzbarkeit verbessern, lehnen Entwickler strikte REST-Regeln deutlich ab – als Hürden nannten sie unter anderem den Umfang der Leitlinien und die mangelnde Passung zu ihrer jeweiligen Organisation.
Wo landen die Beschränkungen also in der Praxis?
| Beschränkung | Praxisverbreitung | Warum |
|---|---|---|
| Client-Server | ✅ Nahezu universell | Grundlegend für Web-Architektur; kaum zu vermeiden |
| Zustandslosigkeit | ✅ Nahezu universell | Voraussetzung für horizontale Skalierung; Standardpraxis |
| Einheitliche Schnittstelle (Basis) | ✅ Häufig | Ressourcen-URIs + HTTP-Verben sind das Standardmuster |
| Cachebarkeit | ⚠️ Inkonsistent | Viele Teams verzichten komplett auf Cache-Control-Header |
| Layered System | ⚠️ Implizit | CDNs und Gateways existieren, werden aber nicht immer bewusst entworfen |
| HATEOAS | ❌ Selten | Die meisten Clients hartkodieren Endpunkte; linkbasierte Erkennung ist komplexer |
| Code-on-Demand | ❌ Sehr selten | Per Definition optional; in JSON-APIs fast nie implementiert |
Warum Teams HATEOAS auslassen: Client-Entwickler lesen lieber OpenAPI-Dokumentationen und nutzen SDKs, statt zur Laufzeit dynamisch Links zu verfolgen. HATEOAS erfordert stabile Medientypen, definierte Link-Relationen und Workflow-Modellierung – der kurzfristige Aufwand ist hoch, und der Nutzen ist für die meisten Teams nicht eindeutig.
Die pragmatische Erkenntnis: Eine API muss nicht zu 100 % Fielding-konform sein, um nützlich zu sein. Aber zu wissen, welche Beschränkungen du weggelassen hast – und was du dadurch verlierst – hilft dir dabei, bessere Design- und Integrationsentscheidungen zu treffen.
Das Richardson-Reifegradmodell: Wie RESTful ist deine API wirklich?
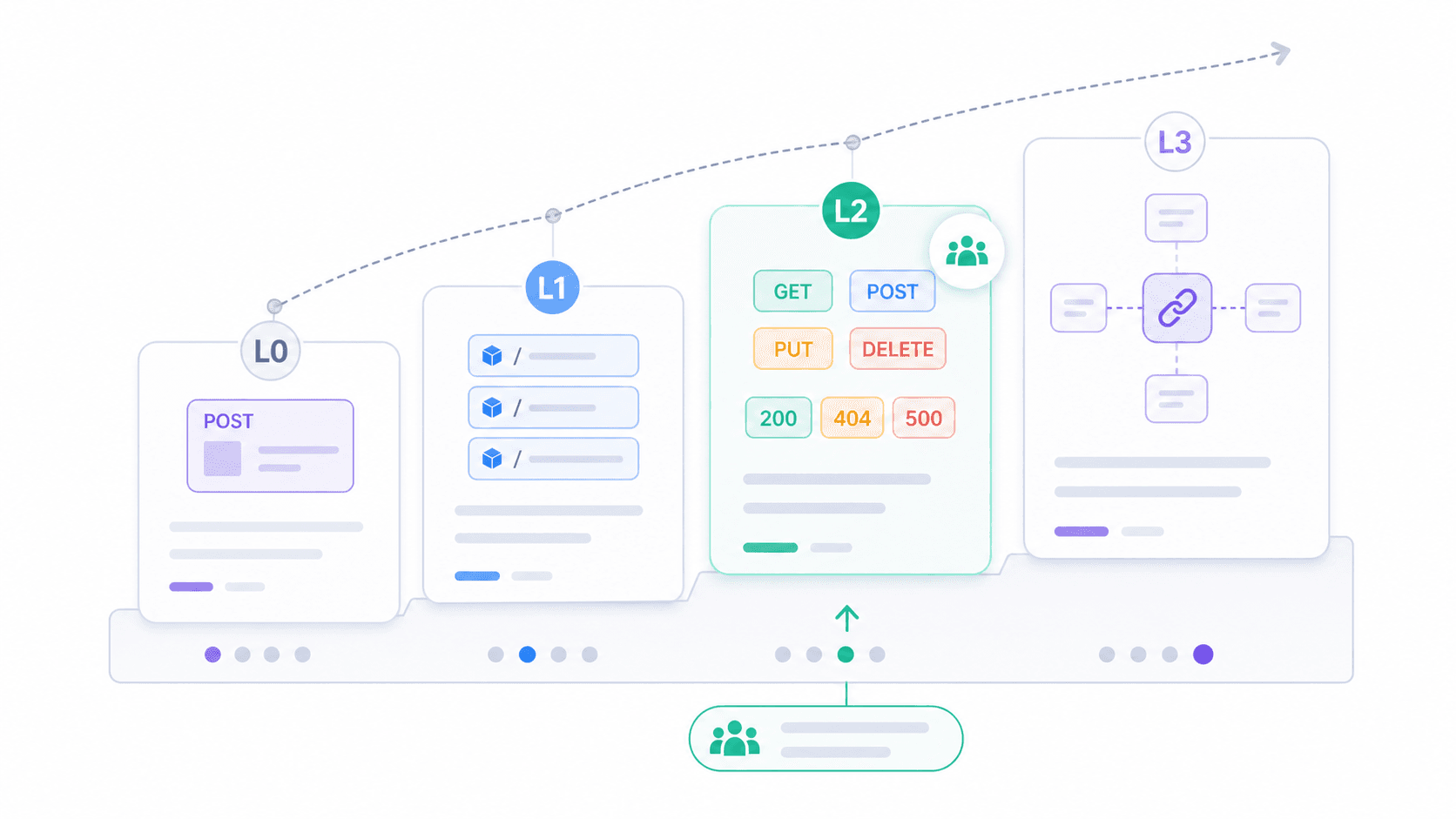
Wenn die binäre Frage „RESTful oder nicht?“ wenig hilfreich erscheint, bietet das Richardson-Reifegradmodell einen praktischeren Rahmen. Vorgeschlagen von Leonard Richardson und , teilt es die REST-Nutzung in vier Stufen ein.
| Stufe | Name | Beschreibung | Praxisbeispiel |
|---|---|---|---|
| 0 | Der Sumpf aus POX | Eine einzelne URI, ein einzelnes HTTP-Verb (meist POST) | Legacy-SOAP-over-HTTP-Endpunkte; POST /api mit { "action": "getUser" } |
| 1 | Ressourcen | Mehrere URIs (eine pro Ressource), aber immer noch meist POST | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | HTTP-Verben | Korrekte Verwendung von GET, POST, PUT, DELETE + passende Statuscodes | Die meisten produktiven „REST“-APIs heute |
| 3 | Hypermedia (HATEOAS) | Antworten enthalten Links zu verwandten Aktionen/Ressourcen | Spring Data REST, HAL-basierte APIs; in der Praxis nur wenige öffentliche APIs |
Die meisten APIs, denen du in der Praxis begegnest, liegen auf Stufe 2. Sie verwenden Ressourcen, Verben und Statuscodes korrekt. Das reicht, um praktikabel, interoperabel und gut durch Tools unterstützt zu sein. Stufe 3 ist Fieldings vollständige Vision, aber die Verbreitung bleibt gering.
Wo steht deine API? Frag dich:
- Hat die API einen einzigen Endpunkt für alles? (Stufe 0)
- Hat jedes Geschäftsobjekt eine eigene URI? (Stufe 1+)
- Werden HTTP-Methoden und Statuscodes korrekt verwendet? (Stufe 2)
- Sagen Antworten dem Client, was er als Nächstes tun kann, ohne auf externe Doku angewiesen zu sein? (Stufe 3)
Dieses Modell ist das nützlichste Werkzeug, das ich gefunden habe, um die Debatte „Ist es REST oder nicht?“ zu entwirren. Es ersetzt ein Ja-Nein-Urteil durch ein Spektrum.
Häufige REST-API-Fehler (und wie du sie vermeidest)
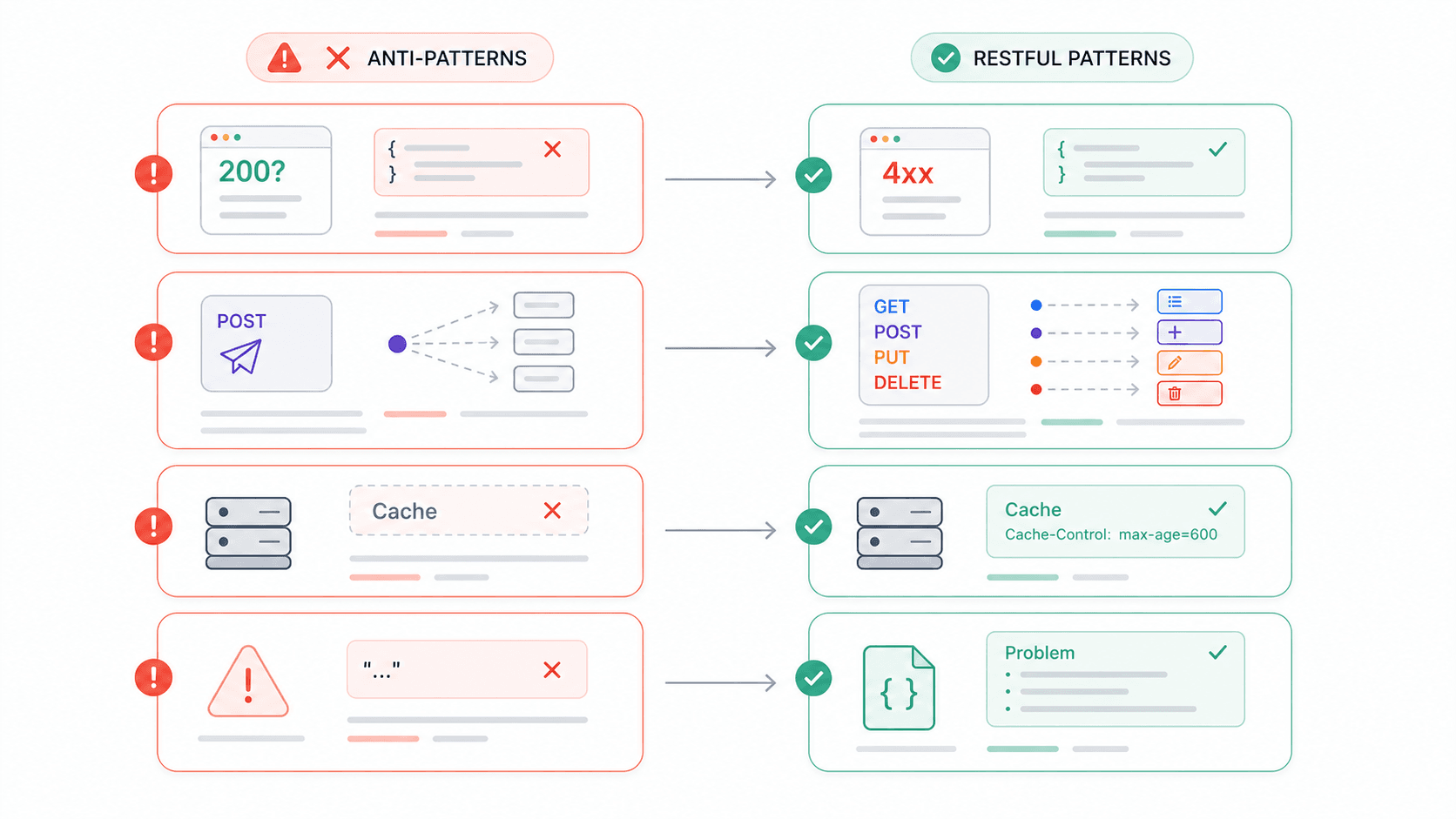
Ich habe genug Zeit mit der Integration von Drittanbieter-APIs verbracht, um eine laufende Liste von Frustpunkten zu haben. Und den Entwicklerforen zufolge bin ich damit nicht allein. Hier sind die Anti-Patterns, die am häufigsten auftauchen – und jedes einzelne verletzt direkt eine REST-Beschränkung.
| Anti-Pattern | Warum es REST bricht | Was du stattdessen tun solltest |
|---|---|---|---|
| HTTP 200 mit Fehlermeldung im Body ({ "error": "Invalid username" }) | Verletzt selbstbeschreibende Nachrichten; Clients können dem Statuscode nicht vertrauen | Passende 4xx/5xx-Codes + strukturierter Fehler-Body (z. B. application/problem+json) verwenden |
| Für alles POST | Ignoriert die einheitliche Schnittstelle; sichere/idempotente Semantik geht verloren | CRUD auf GET/POST/PUT(PATCH)/DELETE abbilden |
| Keine Cache-Control-Header | Verschwendet die Cachebarkeit vollständig | Explizite Cache-Direktiven setzen – bei sensiblen Daten sogar no-store |
| Vage Fehlermeldungen („409 error“) | Menschen und Maschinen können nicht erkennen, was schiefgelaufen ist | Fehlertyp, verständliche Nachricht und einen Link zur Doku angeben |
| HTTPS nicht erzwingen | Bearer-Tokens und API-Keys reisen im Klartext | TLS überall erzwingen; Google APIs sind standardmäßig nur per HTTPS erreichbar |
| Versionierung im Request-Body | Verletzt die Ressourcenidentifikation; Gateways und Caches können nicht sauber routen | URI-Pfad-Versionierung (/v1/) oder Versionierung über den Accept-Header verwenden |
Die verlangen offizielle HTTP-Statuscodes und empfehlen Problem JSON für Fehlerantworten. Die schreiben vor, dass Problem Details nur für 4xx/5xx verwendet werden dürfen, niemals gemischt mit 2xx. Das sind keine akademischen Vorlieben – das sind Produktionsstandards von Teams, die APIs in großem Maßstab betreiben.
Ein Reddit-Thread in r/learnprogramming zeigte einen Entwickler, der ernsthaft fragte, ob es okay sei, für Fehler immer HTTP 200 zurückzugeben. Dass diese Frage 2026 immer noch auftaucht, zeigt, wie hartnäckig solche Anti-Patterns sind.
REST vs. SOAP vs. GraphQL vs. gRPC: Wie sich die REST-API-Eigenschaften vergleichen
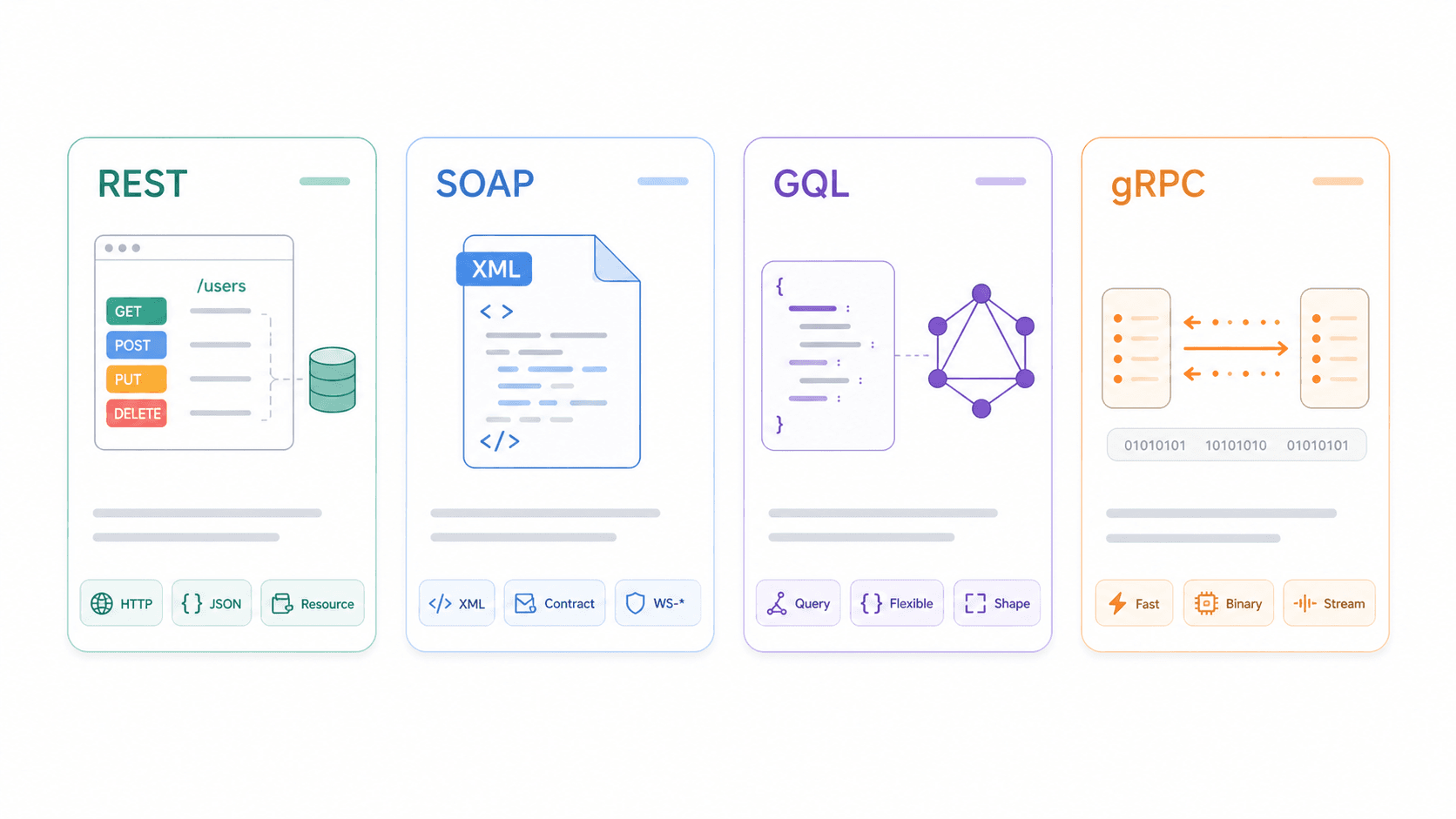
REST isoliert zu verstehen ist nützlich. Es im Verhältnis zu Alternativen zu verstehen ist besser.
| Dimension | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protokoll / Transport | Architekturstil, meist HTTP | XML-basiertes Messaging-Protokoll; HTTP, SMTP usw. | Abfragesprache/-runtime, meist über HTTP | RPC-Framework über HTTP/2 |
| Datenformat | JSON (typischerweise), auch XML/HTML | Nur XML (WSDL-Verträge) | JSON passend zur Abfragestruktur | Protocol Buffers (binär) |
| Caching | ✅ Natives HTTP-Caching bei guter Auslegung | ❌ Komplex; schlecht für HTTP-Caches geeignet | ⚠️ Schwerer (POST + ein Endpunkt + variierende Queries) | ❌ Nicht auf HTTP-Caching ausgerichtet |
| Echtzeit-Unterstützung | ❌ Polling/Webhooks | ❌ Enterprise-Messaging-Muster | ✅ Subscriptions | ✅ Streaming, geringe Latenz |
| Lernkurve | Niedrig bis mittel | Hoch | Mittel | Mittel bis hoch |
| Am besten geeignet für | Öffentliche APIs, CRUD, Web-/Mobile-Integrationen | Enterprise/Legacy, strikte Verträge, Compliance | Komplexe Abfragen, flexible Frontends, mobile Apps | Microservice-zu-Microservice, intern mit hoher Performance |
empfiehlt, die Wahl von Kompatibilität, Datenform, Operationen und eingesetzten Tools abhängig zu machen.
Wann was wählen:
- REST gewinnt, wenn du breite Kompatibilität, einfache CRUD-Operationen und HTTP-Caching brauchst. Es ist der Standard für öffentliche APIs und Web-/Mobile-Integrationen.
- SOAP ist weiterhin sinnvoll für Enterprise-Systeme mit strengen Verträgen, WS-Security-Anforderungen oder Legacy-Integrationen, die nicht verschwinden werden.
- GraphQL glänzt, wenn dein Frontend flexible, verschachtelte Abfragen braucht und du Overfetching oder Underfetching vermeiden willst – typisch bei komplexen Mobile-Apps.
- gRPC ist für die interne Kommunikation zwischen Microservices gebaut, bei der niedrige Latenz und binäre Serialisierung wichtiger sind als Browser-Kompatibilität.
Als echtes REST-Beispiel: Die verwendet einfache POST-Endpunkte (/distill und /extract), JSON für Request und Response, Bearer-Token-Authentifizierung und standardisierte HTTP-Statuscodes (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Sie zeigt REST-Eigenschaften in einem produktiven KI-Produkt, ohne SOAP-Verträge oder gRPC-Komplexität zu erfordern. Kein HATEOAS-Schaukasten – aber eine praktische API auf Level 2, die sich für Business-Teams und Entwickler leicht integrieren lässt.
Warum REST-API-Eigenschaften für Business-Teams wichtig sind
Sales, Operations, E-Commerce – keines dieser Teams schreibt API-Code. Aber ihr wählt Anbieter aus, verbindet Tools und baut Automatisierungs-Workflows – und die Qualität einer REST-API wirkt sich direkt darauf aus, wie schmerzhaft diese Integrationen sind.
Tools integrieren: Wenn dein CRM mit einer Marketing-Automation-Plattform synchronisiert wird, entscheidet das REST-API-Design darüber, ob diese Synchronisierung zuverlässig oder fragil ist. Die verwaltet Kontakte, Kampagnen, Journeys und Push-Benachrichtigungen über vorhersagbare Ressourcenendpunkte. Folgen diese Endpunkte REST-Konventionen, kann dein RevOps-Team automatisieren, ohne eigene Workarounds bauen zu müssen.
E-Commerce-Operations: verwalten Fulfillment-Bestellungen, Trackingnummern und Versandstatus. Versand-Apps und Fulfillment-Tools hängen von dieser Schicht ab. Ist die API gut designt – also mit passenden Statuscodes, cachebaren Katalogdaten und klaren Fehlermeldungen –, läuft deine Logistikkette reibungslos. Ist sie es nicht, bekommst du um 2 Uhr morgens rätselhafte Ausfälle.
Anbieter bewerten: Die 6 Beschränkungen liefern dir eine praktische Checkliste:
- Nutzt die API standardisierte Statuscodes, oder sieht jeder Fehler wie ein 200 OK aus?
- Sind Fehler spezifisch genug, damit dein Automatisierungstool sich davon erholen kann?
- Gibt es klare Dokumentation zu Rate Limits, Pagination und Authentifizierung?
- Lassen sich häufige Antworten cachen, um Last zu reduzieren?
Datenextraktion und Automatisierung: Tools wie nutzen eine REST-basierte Architektur, damit Business-Anwender strukturierte Daten aus Websites, PDFs und Bildern extrahieren und dann nach Google Sheets, Airtable, Notion oder Excel exportieren können. Thunderbits übernimmt die Komplexität hinter einer 2-Klick-Oberfläche, aber unter der Haube sind es REST-Prinzipien – zustandslose Requests, JSON-Antworten, standardisierte Fehler –, die die Integrationsschicht zuverlässig machen.
Noch ein Datenpunkt, der erwähnenswert ist: Der Postman-Report 2025 fand heraus, dass nur APIs aktiv mit Blick auf KI-Agenten designen, während 51 % sich vor unbefugten oder übermäßigen API-Aufrufen durch KI-Agenten sorgen. Da Automatisierung und KI-gestützte Workflows in Business-Teams zum Standard werden, sind vorhersagbare REST-Muster, API-Keys mit Minimalrechten und Rate Limits nicht nur Entwickler-Themen – sondern operative Risikofaktoren.
Wie Thunderbit REST-Prinzipien für Business-Anwender umsetzt
Wir haben mit der Annahme gebaut, dass die meisten unserer Nutzer nie eine REST-Spezifikation lesen werden – und das auch nicht müssen. Aber die Designentscheidungen, die Thunderbit einfach machen, basieren auf denselben REST-Eigenschaften, die dieser Artikel behandelt.
Hier ein kurzer Überblick, wie das in der Praxis funktioniert:
- Installiere die Chrome-Erweiterung aus dem und öffne irgendeine Website, PDF oder ein Bild, aus dem du Daten extrahieren möchtest.
- Klicke auf „AI-Felder vorschlagen“ und Thunderbits KI liest die Seite aus und schlägt eine strukturierte Tabelle mit Spalten vor – Produktnamen, Preise, E-Mails oder was immer auf der Seite steht.
- Passe die Spalten bei Bedarf an und klicke dann auf „Scrapen“. Thunderbit übernimmt Pagination, Unterseiten und dynamische Inhalte automatisch.
- Exportiere deine Daten nach Google Sheets, Airtable, Notion, CSV oder Excel – kostenlos, ohne Paywall.
Für Entwickler und Automatisierungs-Workflows stellt Thunderbits /distill (saubere Markdown-Extraktion) und /extract (strukturierte Datenextraktion) als REST-artige POST-Endpunkte mit JSON-Body und standardisierten HTTP-Fehlercodes bereit. Im Richardson-Reifegradmodell ist das eine solide Stufe 2 – Ressourcen, korrekte Methoden, aussagekräftige Statuscodes.
Wenn du Web Scraping oder Datenextraktion allgemein tiefer erkunden möchtest, haben wir ausführlichere Leitfäden zu , und veröffentlicht.
Wichtige Erkenntnisse
- REST ist ein Architekturstil, kein Protokoll. Er definiert 6 Beschränkungen – Client-Server, zustandslos, cachebar, einheitliche Schnittstelle, Layered System und optional Code-on-Demand –, die das API-Design leiten.
- Die meisten „RESTful“ APIs sind nicht vollständig RESTful. Der Großteil liegt auf Richardson Level 2 (Ressourcen + HTTP-Verben + Statuscodes). HATEOAS und Code-on-Demand werden selten umgesetzt.
- Das Richardson-Reifegradmodell ist das beste Werkzeug zur Selbsteinschätzung. Es ersetzt die binäre Frage „REST oder nicht?“ durch ein praktikables Spektrum (Level 0–3).
- Häufige Fehler – 200 OK bei Fehlern, für alles POST, fehlende Cache-Header – sind immer noch weit verbreitet. Wer die Beschränkungen kennt, erkennt und behebt diese Anti-Patterns leichter.
- REST vs. SOAP vs. GraphQL vs. gRPC ist keine Frage von „besser“, sondern von Passung. REST dominiert öffentliche APIs und CRUD-Integrationen. GraphQL eignet sich für komplexe Frontends. gRPC glänzt bei internen Microservices. SOAP bleibt in Enterprise-/Legacy-Kontexten relevant.
- Business-Teams profitieren vom Verständnis der REST-Eigenschaften, wenn sie Anbieter bewerten, Tools verbinden und Automatisierungs-Workflows bauen. Tools wie setzen REST-Prinzipien ein, um Datenextraktion zugänglich zu machen – ganz ohne technisches Spezialwissen.
FAQs
Was sind die 6 Eigenschaften einer REST-API?
Die 6 REST-Beschränkungen sind: (1) Client-Server-Trennung, (2) Zustandslosigkeit, (3) Cachebarkeit, (4) einheitliche Schnittstelle, (5) Layered System und (6) Code-on-Demand (optional). Die ersten fünf sind nach Fieldings ursprünglicher Definition Pflicht, damit eine API als RESTful gilt.
Was ist der Unterschied zwischen REST und RESTful?
REST ist der Architekturstil – also der Satz von Designbeschränkungen, den Roy Fielding definiert hat. „RESTful“ beschreibt eine API, die diese Beschränkungen befolgt. In der Praxis erfüllen viele als „RESTful“ bezeichnete APIs nur einen Teil davon und implementieren meist Ressourcen, HTTP-Methoden und Statuscodes, verzichten aber auf HATEOAS und Code-on-Demand.
Folgen alle REST-APIs jeder REST-Beschränkung?
Nein. Die meisten Produktions-APIs folgen der Client-Server-Trennung, Zustandslosigkeit und einer grundlegenden einheitlichen Schnittstelle (Ressourcen + HTTP-Verben). Cachebarkeit und Layered Systems werden uneinheitlich umgesetzt. HATEOAS ist selten, und Code-on-Demand wird in JSON-APIs fast nie verwendet.
Was ist der Unterschied zwischen REST und GraphQL?
REST stellt Ressourcen über mehrere Endpunkte mit standardisierten HTTP-Methoden (GET, POST, PUT, DELETE) bereit. GraphQL nutzt typischerweise einen einzigen Endpunkt, an dem Clients in einer Query genau festlegen, welche Felder sie möchten. REST bietet stärkeres natives HTTP-Caching; GraphQL ist flexibler für komplexe, verschachtelte Datenanforderungen und reduziert Overfetching.
Was ist HATEOAS, und nutzt das überhaupt jemand?
HATEOAS (Hypermedia as the Engine of Application State) bedeutet, dass API-Antworten Links enthalten, die dem Client zeigen, welche Aktionen als Nächstes verfügbar sind – so kann der Client die API navigieren, ohne jeden Endpunkt hart zu kodieren. Es ist zentral für Fieldings REST-Vision (Richardson Level 3), aber in der Praxis implementieren nur sehr wenige öffentliche APIs das. Die meisten Teams bleiben bei Level 2 und verlassen sich stattdessen auf Dokumentation und SDKs.
Mehr erfahren