Das Web im Jahr 2025 ist ein wilder Ort – fast die Hälfte des Traffics, den du siehst, stammt nicht einmal von Menschen. Genau: Bots und Crawler machen inzwischen über 50 % der gesamten Internetaktivität aus (), und nur ein Bruchteil davon sind die „guten“ Bots, die du willst: Suchmaschinen, Social-Media-Vorschau-Bots und Analysehelfer. Der Rest? Nun ja, sagen wir einfach, sie sind nicht immer da, um zu helfen. Als jemand, der seit Jahren Automatisierungs- und KI-Tools bei entwickelt, habe ich aus erster Hand erlebt, wie der richtige – oder falsche – Crawler deine SEO verbessern oder ruinieren, deine Analysedaten verzerren, deine Bandbreite belasten oder sogar einen ausgewachsenen Sicherheitsvorfall auslösen kann.
Wenn du ein Unternehmen führst, eine Website betreibst oder einfach nur deine digitale Infrastruktur im Griff behalten willst, ist es wichtiger denn je zu wissen, wer an deiner Server-Tür klopft. Deshalb habe ich diesen Leitfaden für 2025 zusammengestellt: zu den wichtigsten Crawlern – was sie tun, wie du sie erkennst und wie du deine Seite für die guten Bots offen hältst, während du die schlechten auf Distanz hältst.
Was macht einen Crawler „bekannt“? User-Agent, IPs und Verifizierung
Fangen wir mit den Grundlagen an: Was genau ist ein „bekannter“ Crawler? Ganz einfach gesagt ist es ein Bot, der sich mit einer konsistenten User-Agent-Zeichenfolge identifiziert (etwa Googlebot/2.1 oder bingbot/2.0) und idealerweise von veröffentlichten IP-Bereichen oder ASN-Blöcken crawlt, die du verifizieren kannst (). Die großen Anbieter – Google, Microsoft, Baidu, Yandex, DuckDuckGo – veröffentlichen Dokumentationen zu ihren Bots und stellen in vielen Fällen Tools oder JSON-Dateien mit ihren offiziellen IPs bereit (, , ).
Aber hier liegt der Haken: Sich nur auf den User-Agent zu verlassen, ist riskant. Spoofing ist weit verbreitet – bösartige Bots geben sich oft als Googlebot oder Bingbot aus, um deine Schutzmechanismen zu umgehen (). Deshalb ist der Goldstandard die doppelte Verifizierung: Prüfe sowohl den User-Agent als auch die IP-Adresse (oder das ASN), etwa per Reverse-DNS-Lookup oder anhand veröffentlichter Listen. Wenn du ein Tool wie verwendest, kannst du diesen Prozess automatisieren – Logs extrahieren, User-Agents abgleichen und IPs gegenprüfen, um eine vertrauenswürdige Echtzeitliste der Crawler auf deiner Website aufzubauen.
Wie du diese Crawler-Liste nutzen solltest
Was machst du nun konkret mit einer Liste bekannter Crawler? So würde ich sie einsetzen:
- Allowlisting: Stelle sicher, dass die Bots, die du willst (Suchmaschinen, Social-Media-Vorschau-Bots), niemals versehentlich von Firewall, CDN oder WAF blockiert werden. Nutze ihre offiziellen IPs und User-Agents für ein präzises Allowlisting.
- Filterung in der Analyse: Filtere Bot-Traffic aus deinen Analytics heraus, damit deine Zahlen echte menschliche Besucher widerspiegeln – und nicht nur Googlebot und AhrefsBot, die ihre Runden auf deiner Website drehen ().
- Bot-Management: Lege Crawl-Delay- oder Drosselungsregeln für aggressive SEO-Tools fest und blockiere oder prüfe unbekannte bzw. bösartige Bots.
- Automatisierte Log-Analyse: Nutze KI-Tools wie Thunderbit, um Crawler-Aktivitäten in deinen Logs zu extrahieren, zu klassifizieren und zu kennzeichnen – so erkennst du Trends, identifizierst Betrüger und hältst deine Richtlinien aktuell.
Deine Crawler-Liste aktuell zu halten ist nichts, was man einfach einmal einrichtet und dann vergisst. Neue Bots tauchen auf, alte ändern ihr Verhalten, und Angreifer werden jedes Jahr raffinierter. Updates zu automatisieren – etwa indem du offizielle Dokumentationen oder GitHub-Repos mit Thunderbit ausliest – kann dir Stunden und jede Menge Frust ersparen.
1. Thunderbit: KI-gestützte Crawler-Erkennung und Datenverwaltung
ist nicht nur ein KI-Web-Scraper – es ist ein Datenassistent für Teams, die Crawler-Traffic verstehen und verwalten wollen. Das zeichnet Thunderbit aus:

- Semantische Vorverarbeitung: Bevor Daten extrahiert werden, wandelt Thunderbit Webseiten und Logs in Markdown-ähnliche, strukturierte Inhalte um. Diese Vorverarbeitung auf „semantischer Ebene“ sorgt dafür, dass die KI den Kontext, die Felder und die Logik des Inhalts tatsächlich versteht. Das ist ein großer Vorteil bei komplexen, dynamischen oder JavaScript-lastigen Seiten (etwa Facebook Marketplace oder langen Kommentar-Threads), bei denen traditionelle DOM-basierte Scraper schnell an ihre Grenzen stoßen.
- Doppelte Verifizierung: Thunderbit kann offizielle Crawler-IP-Dokumente und ASN-Listen schnell sammeln und mit deinen Server-Logs abgleichen. Das Ergebnis? Eine „vertrauenswürdige Crawler-Allowlist“, auf die du dich wirklich verlassen kannst – kein manuelles Gegenprüfen mehr.
- Automatisierte Log-Extraktion: Gib Thunderbit deine Roh-Logs, und es verwandelt sie in strukturierte Tabellen (Excel, Sheets, Airtable), inklusive Kennzeichnung von Besuchern mit hoher Frequenz, verdächtigen Pfaden und bekannten Bots. Von dort aus kannst du die Ergebnisse in deine WAF oder dein CDN einspeisen, um automatisches Blockieren, Drosseln oder CAPTCHA-Prüfungen auszulösen.
- Compliance und Audit: Die semantische Extraktion von Thunderbit sorgt für eine klare Prüfkette – wer worauf zugegriffen hat, wann und wie damit umgegangen wurde. Das ist eine enorme Hilfe für GDPR, CCPA und andere Compliance-Anforderungen.
Ich habe Teams erlebt, die Thunderbit genutzt haben, um ihren Aufwand für das Crawler-Management um 80 % zu senken – und endlich klar zu sehen, welche Bots helfen, welche schaden und welche nur so tun als ob.
2. Googlebot: Der Standard der Suchmaschinen
ist der Goldstandard unter den Web-Crawlern. Er ist dafür verantwortlich, deine Website für die Google-Suche zu indexieren – sperrst du ihn aus, kannst du auch gleich ein „Geschlossen“-Schild an dein digitales Schaufenster hängen.
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verifizierung: Nutze oder die .
- Management-Tipps: Googlebot immer erlauben. Verwende robots.txt, um sein Crawling zu lenken – nicht, um es zu blockieren – und passe die Crawl-Rate bei Bedarf in der Google Search Console an.
3. Bingbot: Microsofts Web-Explorer
liefert die Suchergebnisse für Bing und Yahoo. Für die meisten Websites ist er der zweitwichtigste Crawler.
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verifizierung: Nutze und die .
- Management-Tipps: Bingbot erlauben, Crawl-Rate in Bing Webmaster Tools verwalten und robots.txt zur Feinabstimmung nutzen.
4. Baiduspider: Chinas führender Such-Crawler
ist das Tor zum chinesischen Suchverkehr.
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verifizierung: Keine offizielle IP-Liste; prüfe in Reverse DNS auf
.baidu.com, beachte aber die Grenzen dieser Methode. - Management-Tipps: Erlauben, wenn du chinesischen Traffic willst. Nutze robots.txt für Regeln, aber beachte, dass Baiduspider sie manchmal ignoriert. Wenn du kein chinesisches SEO brauchst, solltest du Drosseln oder Blockieren in Betracht ziehen, um Bandbreite zu sparen.
5. YandexBot: Der Such-Crawler für Russland
ist für den russischen Markt und die GUS-Staaten unverzichtbar.
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verifizierung: Reverse DNS sollte auf
.yandex.ru,.yandex.netoder.yandex.comenden. - Management-Tipps: Erlauben, wenn du russischsprachige Nutzer ansprichst. Nutze Yandex Webmaster zur Crawl-Steuerung.
6. DuckDuckBot: Datenschutzorientierter Such-Crawler
treibt die datenschutzorientierte Suche von DuckDuckGo an.
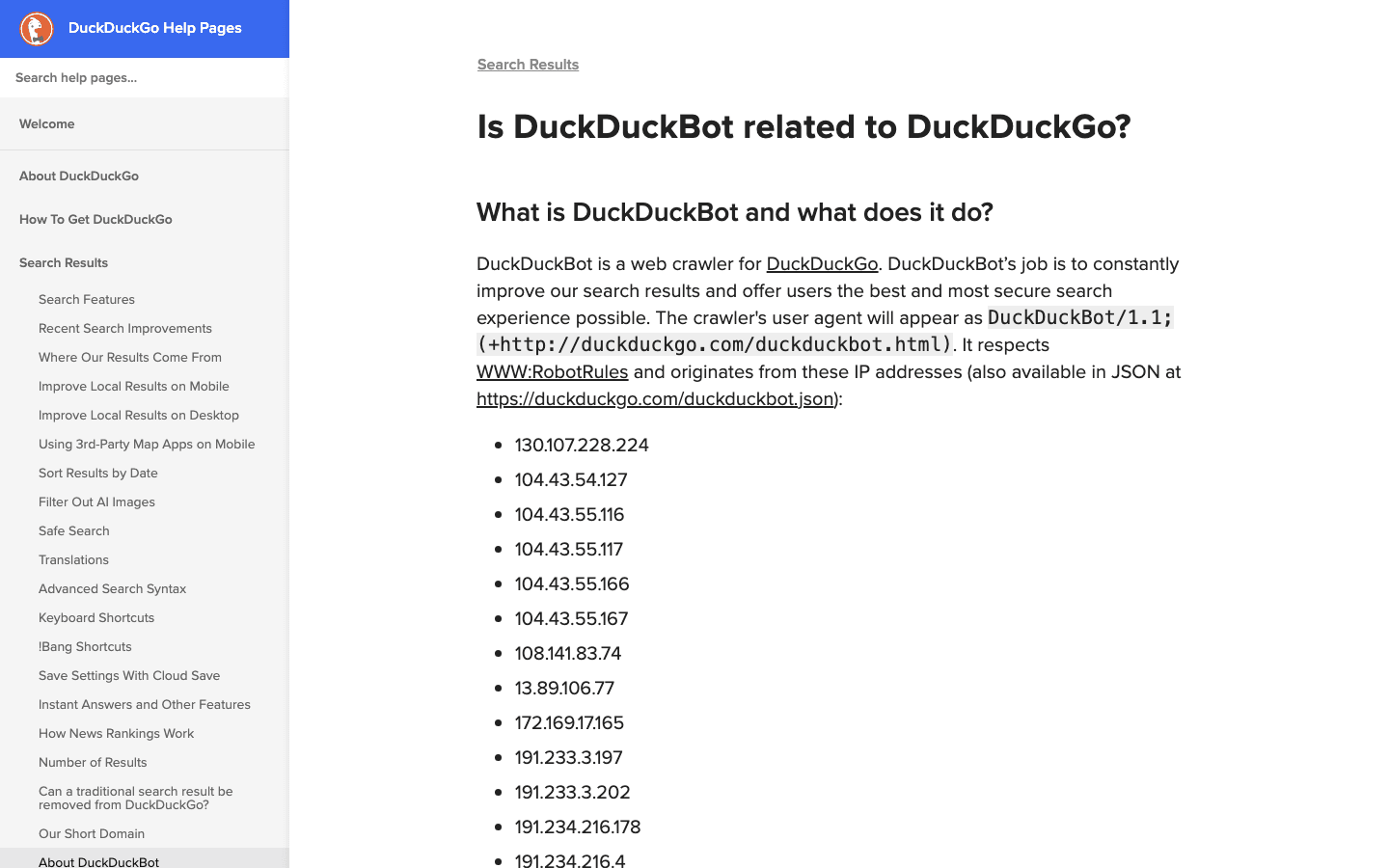
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verifizierung: .
- Management-Tipps: Erlauben, sofern du kein Problem mit datenschutzorientierten Nutzern hast. Geringe Crawl-Last, leicht zu verwalten.
7. AhrefsBot: SEO- und Backlink-Analyse
ist ein wichtiger Crawler für SEO-Tools – hervorragend für Backlink-Analysen, aber mitunter bandbreitenintensiv.
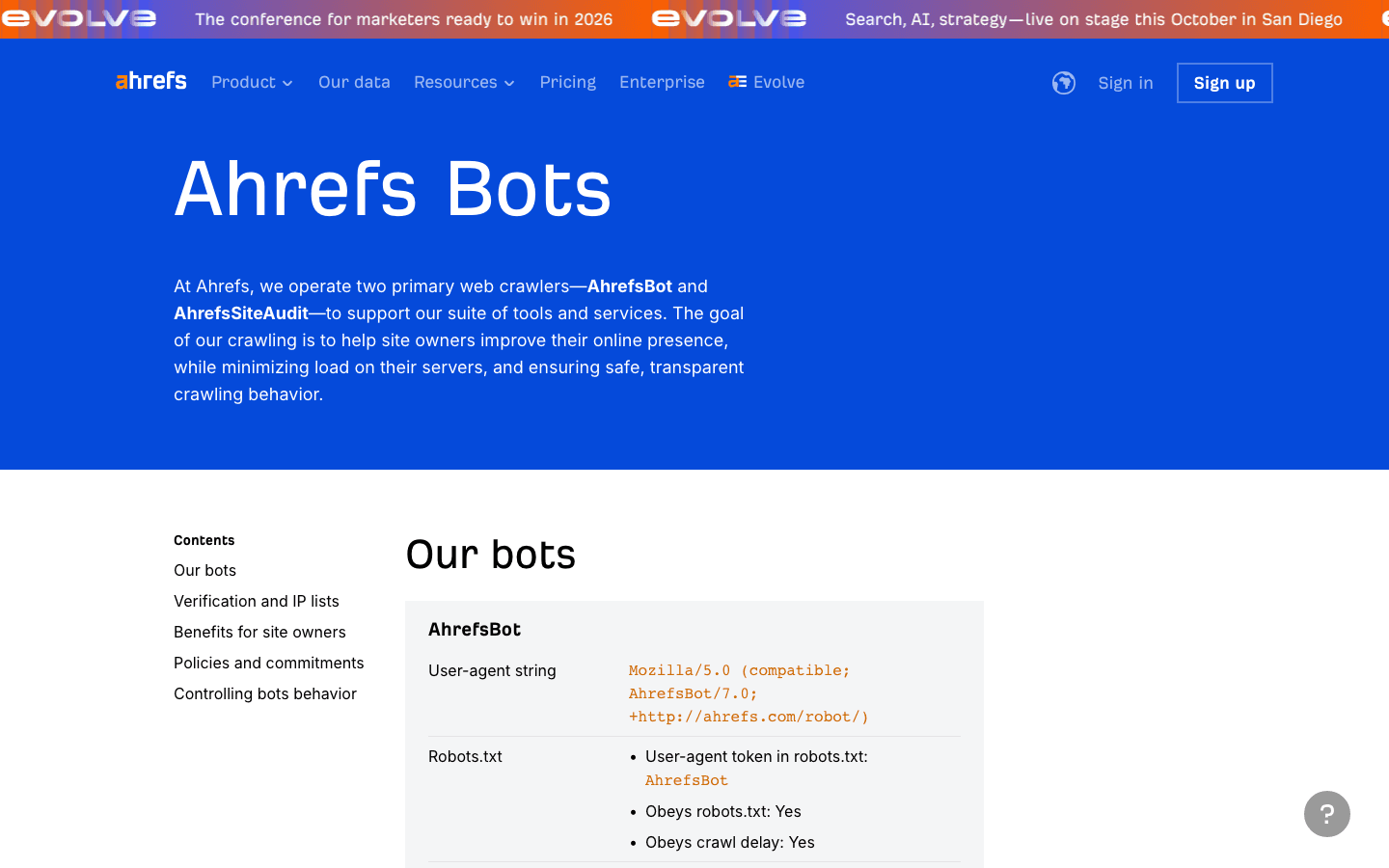
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verifizierung: Keine öffentliche IP-Liste; über User-Agent und Reverse DNS prüfen.
- Management-Tipps: Erlauben, wenn du Ahrefs nutzt. Verwende robots.txt für Crawl-Delay oder Blockierung. Du kannst dich .
8. SemrushBot: Einblicke in die Konkurrenz-SEO
ist ein weiterer großer SEO-Crawler.
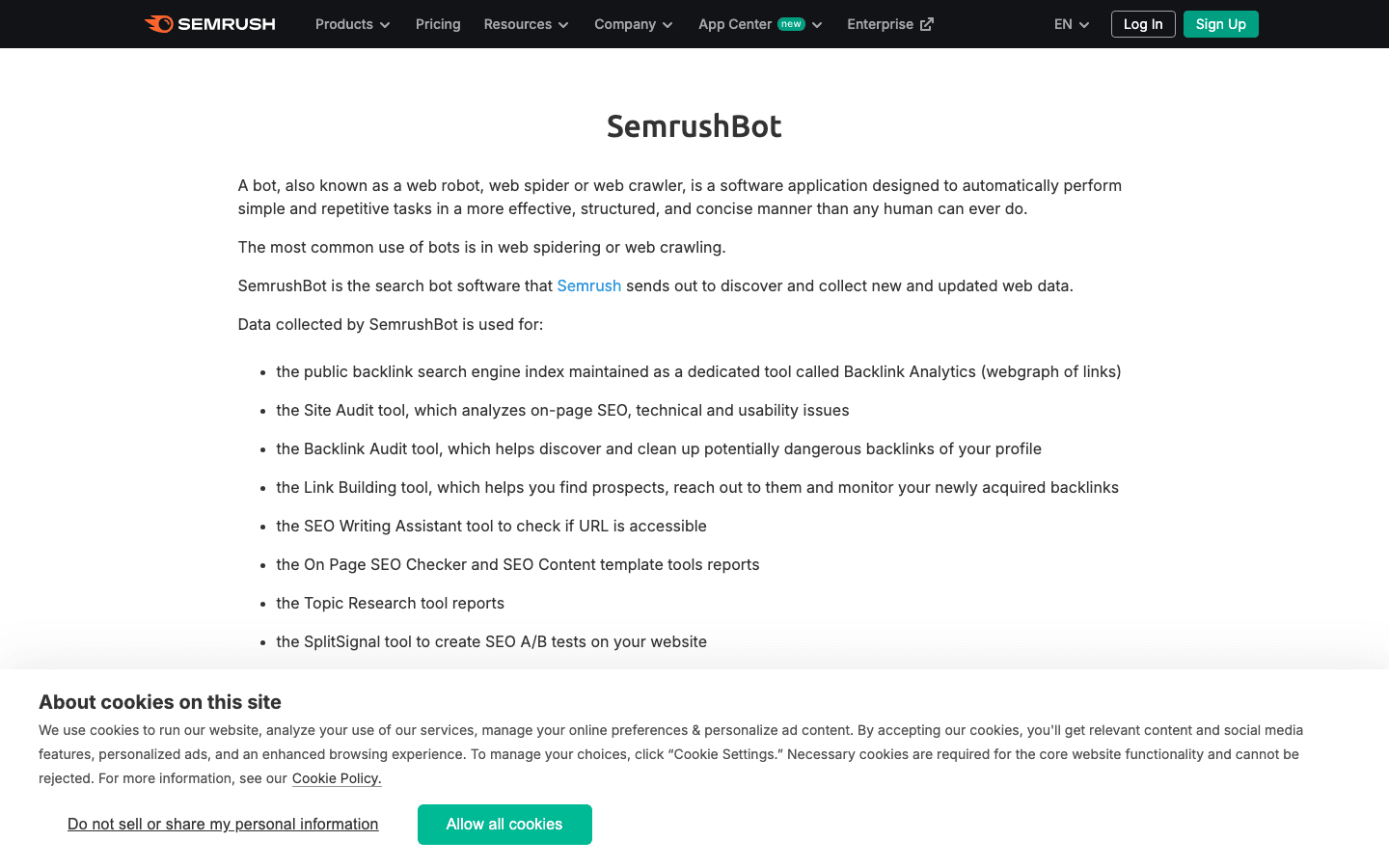
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(plus Varianten wieSemrushBot-BA,SemrushBot-SIusw.) - Verifizierung: Über den User-Agent; keine öffentliche IP-Liste.
- Management-Tipps: Erlauben, wenn du Semrush nutzt, ansonsten mit robots.txt oder Serverregeln drosseln oder blockieren.
9. FacebookExternalHit: Bot für Social-Media-Vorschauen
holt Open-Graph-Daten für Link-Vorschauen auf Facebook und Instagram.
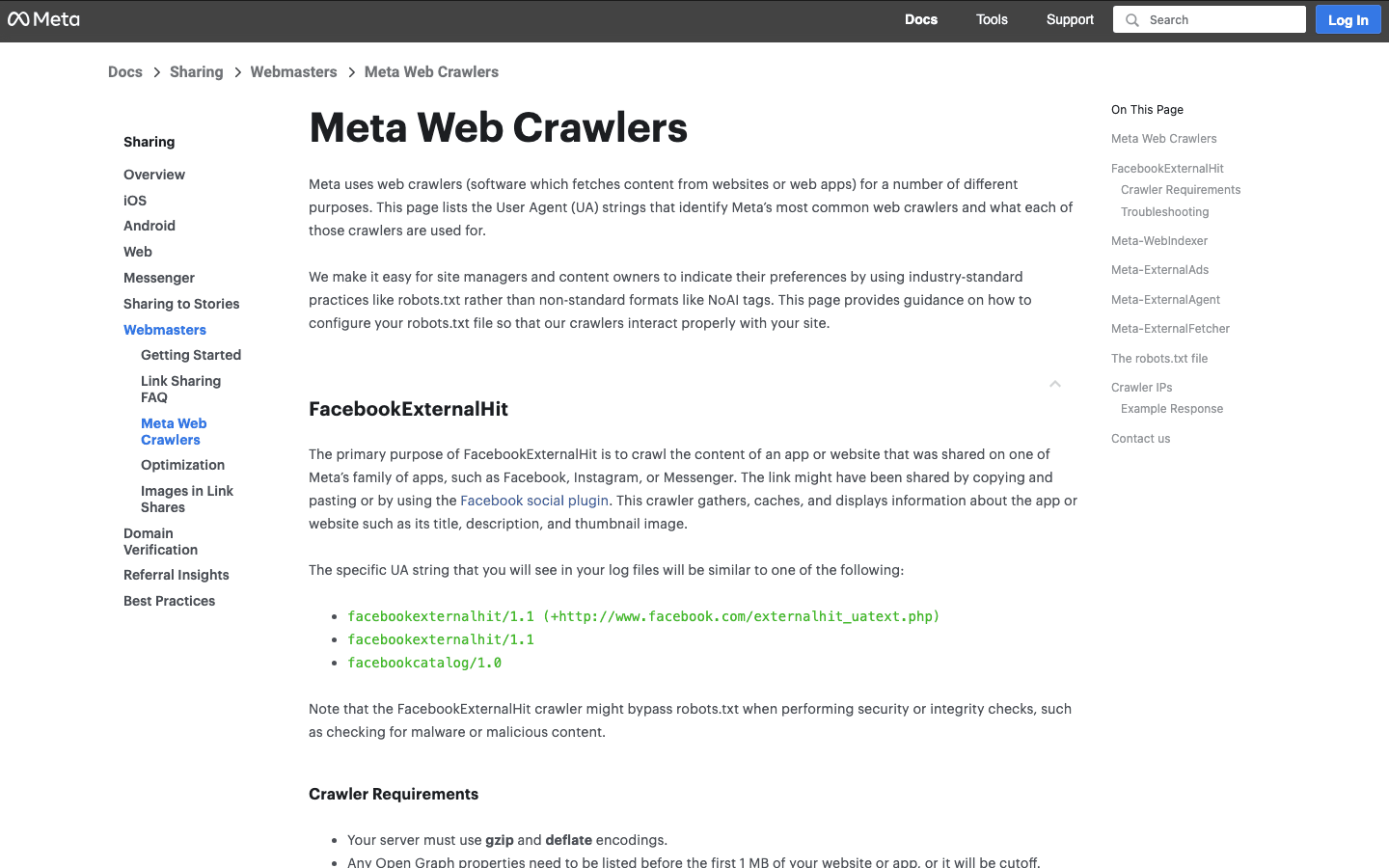
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verifizierung: Über den User-Agent; die IPs gehören zum ASN von Facebook.
- Management-Tipps: Erlauben, um ansprechende Social Previews zu ermöglichen. Blockieren bedeutet keine Thumbnails oder Zusammenfassungen auf Facebook/Instagram.
10. Twitterbot: Link-Preview-Crawler für X (Twitter)
holt Twitter-Card-Daten für X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verifizierung: Über den User-Agent; Twitter-ASN (AS13414).
- Management-Tipps: Für Twitter-Vorschauen erlauben. Verwende Twitter-Card-Meta-Tags für beste Ergebnisse.
Vergleichstabelle: Crawler auf einen Blick
| Crawler | Zweck | User-Agent-Beispiel | Verifizierungsmethode | Geschäftliche Auswirkung | Management-Tipps |
|---|---|---|---|---|---|
| Thunderbit | KI-Analyse von Logs/Crawlern | N/A (Tool, kein Bot) | N/A | Datenverwaltung, Bot-Klassifizierung | Für Log-Extraktion, Aufbau von Allowlists nutzen |
| Googlebot | Google-Suche indexieren | Googlebot/2.1 | DNS- & IP-Liste | Kritisch für SEO | Immer erlauben, über die Search Console verwalten |
| Bingbot | Bing-/Yahoo-Suche | bingbot/2.0 | DNS- & IP-Liste | Wichtig für Bing-/Yahoo-SEO | Erlauben, über Bing Webmaster Tools verwalten |
| Baiduspider | Baidu-Suche (China) | Baiduspider/2.0 | Reverse DNS, UA-Zeichenfolge | Entscheidend für China-SEO | Erlauben, wenn du China ansprichst, Bandbreite überwachen |
| YandexBot | Yandex-Suche (Russland) | YandexBot/3.0 | Reverse DNS auf .yandex.ru | Entscheidend für Russland/Osteuropa | Erlauben, wenn du RU/GUS ansprichst, Yandex-Tools nutzen |
| DuckDuckBot | DuckDuckGo-Suche | DuckDuckBot/1.1 | Offizielle IP-Liste | Datenschutzorientierte Zielgruppe | Erlauben, geringe Auswirkung |
| AhrefsBot | SEO-/Backlink-Analyse | AhrefsBot/7.0 | UA-Zeichenfolge, Reverse DNS | SEO-Tool, kann bandbreitenintensiv sein | Erlauben/drosseln/blockieren via robots.txt |
| SemrushBot | SEO-/Konkurrenzanalyse | SemrushBot/1.0 (plus Varianten) | UA-Zeichenfolge | SEO-Tool, kann aggressiv sein | Erlauben/drosseln/blockieren via robots.txt |
| FacebookExternalHit | Social-Link-Vorschauen | facebookexternalhit/1.1 | UA-Zeichenfolge, Facebook-ASN | Social-Media-Engagement | Für Vorschauen erlauben, OG-Tags nutzen |
| Twitterbot | Twitter-Link-Vorschauen | Twitterbot/1.0 | UA-Zeichenfolge, Twitter-ASN | Twitter-Engagement | Für Vorschauen erlauben, Twitter-Card-Tags nutzen |
Deine Crawler-Liste verwalten: Best Practices für 2025
- Regelmäßig aktualisieren: Die Crawler-Landschaft verändert sich schnell. Plane vierteljährliche Überprüfungen ein und nutze Tools wie Thunderbit, um offizielle Listen zu scrapen und zu vergleichen ().
- Verifizieren, nicht vertrauen: Prüfe immer sowohl User-Agent als auch IP/ASN. Lass keine Betrüger durchrutschen, die deine Analysedaten verfälschen oder deine Daten scrapen ().
- Gute Bots auf die Allowlist setzen: Stelle sicher, dass Such- und Social-Crawler niemals durch Anti-Bot-Regeln oder Firewalls blockiert werden.
- Aggressive Bots drosseln oder blockieren: Nutze robots.txt, Crawl-Delay oder Serverregeln für SEO-Tools, die zu viel Last erzeugen.
- Log-Analyse automatisieren: Nutze KI-gestützte Tools wie Thunderbit, um Crawler-Aktivitäten zu extrahieren, zu klassifizieren und zu kennzeichnen – das spart Zeit und deckt Trends auf, die dir sonst entgehen könnten.
- SEO, Analytics und Sicherheit ausbalancieren: Blockiere nicht die Bots, die dein Geschäft voranbringen, aber lass die schlechten auch nicht unkontrolliert gewähren.
Fazit: Deine Crawler-Liste aktuell und handlungsfähig halten
Im Jahr 2025 ist die Verwaltung deiner Crawler-Liste nicht nur eine IT-Aufgabe – sie ist geschäftskritisch und betrifft SEO, Analytics, Sicherheit und Compliance. Da Bots inzwischen die Mehrheit des Web-Traffics ausmachen, musst du wissen, wer deine Website besucht, warum und was du dagegen tun solltest. Halte deine Liste aktuell, automatisiere, wo es geht, und nutze Tools wie , um einen Schritt voraus zu bleiben. Das Web wird nur noch voller – und eine kluge, umsetzbare Crawler-Strategie ist deine beste Verteidigung und dein stärkster Hebel in einer von Bots geprägten Welt.
FAQs
1. Warum ist es wichtig, eine aktuelle Crawler-Liste zu pflegen?
Weil Bots inzwischen für über die Hälfte des Web-Traffics verantwortlich sind und nur ein kleiner Teil davon nützlich ist. Eine aktuelle Liste stellt sicher, dass du die guten Bots für SEO und Social Previews zulässt und die schlechten blockierst oder drosselst – zum Schutz deiner Analytics, deiner Bandbreite und deiner Datensicherheit.
2. Woran erkenne ich, ob ein Crawler echt oder gefälscht ist?
Vertraue nicht nur dem User-Agent – verifiziere immer die IP-Adresse oder das ASN über offizielle Listen oder Reverse-DNS-Lookups. Tools wie Thunderbit können diesen Prozess automatisieren, indem sie Logs mit veröffentlichten Bot-IPs und User-Agents abgleichen.
3. Was sollte ich tun, wenn ein unbekannter Bot meine Website crawlt?
Untersuche den User-Agent und die IP. Wenn er nicht auf deiner Allowlist steht und nicht zu einem bekannten Bot passt, solltest du ihn drosseln, prüfen oder blockieren. Nutze KI-Tools, um neue Crawler zu klassifizieren und zu überwachen, sobald sie auftauchen.
4. Wie hilft Thunderbit beim Crawler-Management?
Thunderbit nutzt KI, um Crawler-Aktivitäten aus Logs zu extrahieren, zu strukturieren und zu klassifizieren. So lassen sich Allowlists leicht aufbauen, Betrüger erkennen und Richtlinien automatisieren. Die semantische Vorverarbeitung ist besonders robust für komplexe oder dynamische Websites.
5. Was ist das Risiko, einen großen Crawler wie Googlebot oder Bingbot zu blockieren?
Das Blockieren von Suchmaschinen-Crawlern kann deine Website aus den Suchergebnissen entfernen und deinen organischen Traffic vernichten. Prüfe daher immer doppelt Firewall, robots.txt und Anti-Bot-Regeln, damit du nicht versehentlich die wichtigsten Bots aussperrst.
Mehr erfahren: