Das Web quillt über vor wertvollen Daten — ob im Vertrieb, im E-Commerce oder in der Marktforschung: Web Scraping ist die Geheimwaffe für Lead-Generierung, Preisüberwachung und Wettbewerbsanalyse. Doch es gibt einen Haken: Je mehr Unternehmen Scraping nutzen, desto stärker wehren sich Websites. Tatsächlich setzen inzwischen über , und sind heute Standard. Wer schon einmal erlebt hat, wie ein Python-Skript 20 Minuten lang sauber läuft — und dann plötzlich an einer Wand aus 403-Fehlern scheitert — weiß, wie frustrierend das ist.
Ich arbeite seit Jahren im SaaS- und Automatisierungsbereich und habe aus erster Hand gesehen, wie Scraping-Projekte in kürzester Zeit von „Wow, das ist einfach“ zu „Warum werde ich überall blockiert?“ kippen können. Also gehen wir es praxisnah an: Ich zeige dir, wie du Web Scraping in Python machst, ohne blockiert zu werden, stelle die besten Techniken und Code-Snippets vor und zeige dir, wann es Zeit ist, KI-gestützte Alternativen wie in Betracht zu ziehen. Egal, ob du Python-Profi bist oder gerade so durchs Scraping kommst — du nimmst am Ende ein Werkzeugset für zuverlässiges, blockierungsfreies Datenextrahieren mit.
Was bedeutet Web Scraping in Python, ohne blockiert zu werden?
Im Kern bedeutet Web Scraping ohne Blockierung, Daten von Websites so zu extrahieren, dass ihre Anti-Bot-Abwehr nicht ausgelöst wird. In der Python-Welt geht es dabei um mehr als nur eine requests.get()-Schleife — es geht darum, unauffällig zu bleiben, echte Nutzer zu imitieren und den Erkennungssystemen immer einen Schritt voraus zu sein.
Warum Python? — dank der einfachen Syntax, des riesigen Ökosystems (denk an requests, BeautifulSoup, Scrapy, Selenium) und der Flexibilität für alles von kleinen Skripten bis zu verteilten Crawlern. Doch Popularität hat ihren Preis: Viele Anti-Bot-Systeme sind inzwischen darauf getrimmt, Python-basierte Scraping-Muster zu erkennen.
Wenn du also zuverlässig scrapen willst, musst du über die Grundlagen hinausgehen. Das heißt: Verstehen, wie Websites Bots erkennen — und wie du sie austricksen kannst, ohne ethische oder rechtliche Grenzen zu überschreiten.
Warum Blockierungen für Python-Web-Scraping-Projekte wichtig sind
Blockiert zu werden ist nicht nur ein technischer Schönheitsfehler — es kann ganze Geschäftsprozesse zum Stillstand bringen. Schauen wir es uns an:
| Anwendungsfall | Auswirkung einer Blockierung |
|---|---|
| Lead-Generierung | Unvollständige oder veraltete Interessentenlisten, entgangene Verkäufe |
| Preisüberwachung | Verpasste Preisänderungen der Konkurrenz, schlechte Preisentscheidungen |
| Content-Aggregation | Lücken in Nachrichten, Bewertungen oder Forschungsdaten |
| Marktintelligenz | Blinde Flecken beim Tracking von Wettbewerbern oder Branchen |
| Immobilienangebote | Unpräzise oder veraltete Immobiliendaten, verpasste Chancen |
Wenn ein Scraper blockiert wird, fehlen dir nicht nur Daten — du verschwendest Ressourcen, riskierst Compliance-Probleme und triffst womöglich schlechte Geschäftsentscheidungen auf Basis unvollständiger Informationen. In einer Welt, in der , ist Zuverlässigkeit alles.
Wie Websites Python-Web-Scraper erkennen und blockieren
Websites sind inzwischen ziemlich clever darin, Bots zu erkennen. Hier sind die häufigsten Anti-Scraping-Abwehrmechanismen, auf die du stoßen wirst (, ):
- IP-Adressen-Blacklisting: Zu viele Anfragen von derselben IP? Blockiert.
- User-Agent- und Header-Prüfungen: Anfragen mit fehlenden oder generischen Headern (wie dem Standard von Python
python-requests/2.25.1) fallen auf. - Rate Limiting: Zu viele Anfragen in kurzer Zeit lösen Drosselung oder Sperren aus.
- CAPTCHAs: „Beweise, dass du ein Mensch bist“-Rätsel, die Bots nicht (einfach) lösen können.
- Verhaltensanalyse: Websites achten auf robotische Muster — etwa wenn dieselbe Schaltfläche immer im gleichen Intervall geklickt wird.
- Honeypots: Versteckte Links oder Felder, mit denen nur Bots interagieren.
- Browser-Fingerprinting: Erfassung von Details zu Browser und Gerät, um Automatisierungstools zu erkennen.
- Cookie- und Session-Tracking: Bots, die Cookies oder Sitzungen nicht korrekt handhaben, werden markiert.
Stell es dir wie die Sicherheitskontrolle am Flughafen vor: Wenn du aussiehst, dich bewegst und verhältst wie alle anderen, kommst du problemlos durch. Wenn du im Trenchcoat und mit Sonnenbrille auftauchst, gibt es Nachfragen.
Wichtige Python-Techniken für Web Scraping ohne Blockierung
Kommen wir zum Wesentlichen: Wie du beim Scraping mit Python tatsächlich Blockierungen vermeidest. Hier sind die zentralen Strategien, die jeder Scraper kennen sollte:

Rotierende Proxys und IP-Adressen
Warum das wichtig ist: Wenn alle Anfragen von derselben IP kommen, bist du ein leichtes Ziel für IP-Sperren. Rotierende Proxys verteilen die Anfragen auf viele IPs und machen es deutlich schwerer, dich zu blockieren.
So geht’s in Python:
1import requests
2proxies = [
3 "<http://proxy1.example.com:8000>",
4 "<http://proxy2.example.com:8000>",
5 # ...weitere Proxys
6]
7for i, url in enumerate(urls):
8 proxy = {"http": proxies[i % len(proxies)]}
9 response = requests.get(url, proxies=proxy)
10 # Antwort verarbeitenFür mehr Zuverlässigkeit kannst du kostenpflichtige Proxy-Dienste nutzen (z. B. Residential Proxies oder rotierende Proxys) ().
User-Agent und benutzerdefinierte Header setzen
Warum das wichtig ist: Standard-Header in Python schreien geradezu „Bot“. Imitiere echte Browser, indem du User-Agent und andere Header setzt.
Beispielcode:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9",
4 "Accept-Encoding": "gzip, deflate, br",
5 "Connection": "keep-alive"
6}
7response = requests.get(url, headers=headers)Wechsle die User-Agents, um noch unauffälliger zu wirken ().
Anfrage-Timing und Muster zufällig variieren
Warum das wichtig ist: Bots sind schnell und vorhersehbar; Menschen sind langsam und zufällig. Baue Pausen ein und variiere deine Navigation.
Python-Tipp:
1import time, random
2for url in urls:
3 response = requests.get(url)
4 time.sleep(random.uniform(2, 7)) # 2–7 Sekunden wartenWenn du Selenium verwendest, kannst du auch Klickpfade und Scrollmuster zufällig gestalten.
Cookies und Sitzungen verwalten
Warum das wichtig ist: Viele Websites benötigen Cookies oder Session-Token, um Inhalte bereitzustellen. Bots, die diese ignorieren, werden blockiert.
So verwaltest du das in Python:
1import requests
2session = requests.Session()
3response = session.get(url)
4# session behandelt Cookies automatischFür komplexere Abläufe kannst du Selenium verwenden, um Cookies zu erfassen und wiederzuverwenden.
Menschliches Verhalten mit Headless-Browsern simulieren
Warum das wichtig ist: Manche Websites nutzen JavaScript, Mausbewegungen oder Scrollen als Signale für echte Nutzer. Headless-Browser wie Selenium oder Playwright können diese Aktionen nachahmen.
Beispiel mit Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.action_chains import ActionChains
3import random, time
4driver = webdriver.Chrome()
5driver.get(url)
6actions = ActionChains(driver)
7actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
8time.sleep(random.uniform(2, 5))Das hilft dir, Verhaltensanalysen und dynamische Inhalte zu umgehen ().
Fortgeschrittene Strategien: CAPTCHAs und Honeypots in Python umgehen
CAPTCHAs sind darauf ausgelegt, Bots sofort auszubremsen. Zwar können einige Python-Bibliotheken einfache CAPTCHAs lösen, doch die meisten professionellen Scraper setzen auf Drittanbieterdienste (wie 2Captcha oder Anti-Captcha), um sie gegen Gebühr zu lösen ().
Beispiel-Integration:
1# Pseudocode für die Nutzung der 2Captcha-API
2import requests
3captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
4# Auf die Lösung warten und dann mit der Anfrage absendenHoneypots sind versteckte Felder oder Links, mit denen nur Bots interagieren. Vermeide es, auf etwas zu klicken oder etwas abzuschicken, das in einem echten Browser nicht sichtbar wäre ().
Robuste Request-Header mit Python-Bibliotheken entwerfen
Über den User-Agent hinaus kannst du weitere Header wie Referer, Accept, Origin usw. rotieren und zufällig variieren, um noch natürlicher zu wirken.
Mit Scrapy:
1class MySpider(scrapy.Spider):
2 custom_settings = {
3 'DEFAULT_REQUEST_HEADERS': {
4 'User-Agent': '...',
5 'Accept-Language': 'en-US,en;q=0.9',
6 # Weitere Header
7 }
8 }Mit Selenium: Nutze Browser-Profile oder Erweiterungen, um Header zu setzen, oder injiziere sie per JavaScript.
Halte deine Header-Liste aktuell — als Inspiration kannst du echte Browser-Anfragen mit den DevTools des Browsers kopieren.
Wenn traditionelles Python-Scraping nicht mehr reicht: Anti-Bot-Technologie im Aufwind
Die Realität ist: Je beliebter Scraping wird, desto stärker werden auch die Anti-Bot-Verbesserungen. . KI-gestützte Erkennung, dynamische Anfragegrenzen und Browser-Fingerprinting machen es selbst für fortgeschrittene Python-Skripte immer schwerer, unentdeckt zu bleiben ().
Manchmal stößt selbst der cleverste Code an seine Grenzen. Dann ist es Zeit, einen anderen Ansatz in Betracht zu ziehen.
Thunderbit: Eine KI-Web-Scraper-Alternative zu Python-Scraping
Wenn Python an seine Grenzen stößt, springt als No-Code-KI-Web-Scraper ein, der für Business-Anwender und nicht nur für Entwickler gebaut wurde. Statt mit Proxys, Headern und CAPTCHAs zu kämpfen, liest der KI-Agent von Thunderbit die Website, schlägt die besten zu extrahierenden Felder vor und übernimmt alles — von der Unterseiten-Navigation bis zum Datenexport.
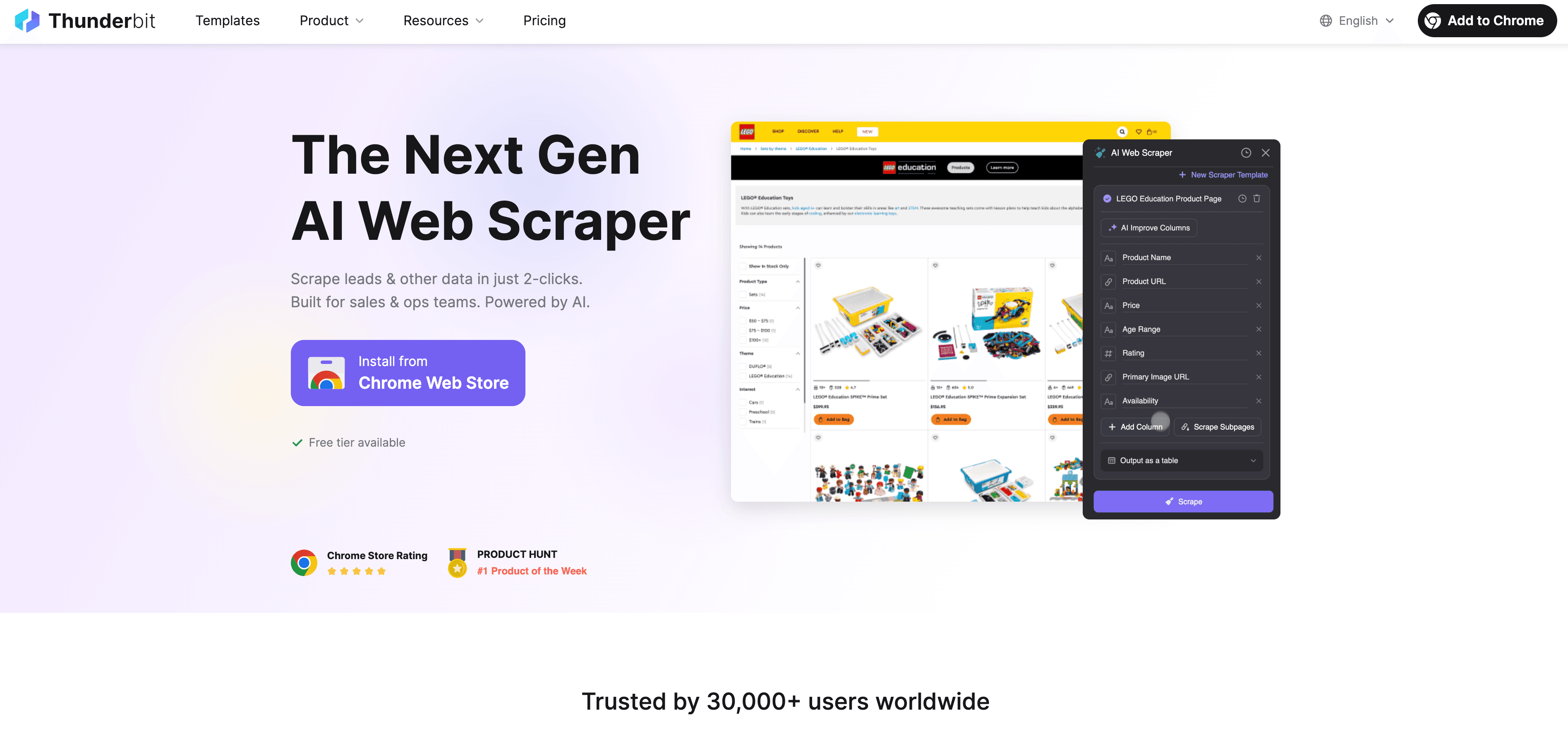
Was Thunderbit anders macht:
- KI-Feldvorschläge: Auf „KI-Felder vorschlagen“ klicken, und Thunderbit scannt die Seite, empfiehlt Spalten und erstellt sogar Extraktionsanweisungen.
- Unterseiten-Scraping: Thunderbit kann jede Unterseite besuchen (z. B. Produktdetails oder LinkedIn-Profile) und deine Tabelle automatisch anreichern.
- Cloud- oder Browser-Scraping: Wähle die schnellste Option — Cloud für öffentliche Seiten, Browser für passwortgeschützte Seiten.
- Geplantes Scraping: Einmal einrichten und vergessen — Thunderbit kann nach Zeitplan scrapen, damit deine Daten immer frisch bleiben.
- Sofort-Vorlagen: Für beliebte Seiten (Amazon, Zillow, Shopify usw.) bietet Thunderbit 1-Klick-Vorlagen — keine Einrichtung nötig.
- Kostenloser Datenexport: Exportiere nach Excel, Google Sheets, Airtable oder Notion — ohne Zusatzkosten.
Thunderbit wird von über vertraut, und du musst nicht eine einzige Zeile Code schreiben.
Wie Thunderbit Nutzern hilft, Blockierungen zu vermeiden und die Datenextraktion zu automatisieren
Die KI von Thunderbit ahmt nicht nur menschliches Verhalten nach — sie passt sich jeder Website in Echtzeit an und verringert so das Risiko einer Blockierung. So funktioniert’s:
- KI passt sich Layout-Änderungen an: Keine kaputten Skripte mehr, wenn eine Website ihr Design aktualisiert.
- Unterseiten- und Pagination-Verarbeitung: Thunderbit folgt automatisch Links und paginierten Listen, genau wie ein echter Nutzer.
- Cloud-Scraping in großem Umfang: Scrape bis zu 50 Seiten gleichzeitig, blitzschnell.
- Kein Coding, keine Wartung: Konzentriere dich auf Analyse statt auf Debugging.
Für einen tieferen Einblick schau dir an.
Python-Scraping vs. Thunderbit im Vergleich: Was solltest du wählen?
Stellen wir beide direkt gegenüber:
| Funktion | Python-Scraping | Thunderbit |
|---|---|---|
| Einrichtungszeit | Mittel bis hoch (Skripte, Proxys usw.) | Niedrig (2 Klicks, der Rest läuft per KI) |
| Technisches Know-how | Programmierung erforderlich | Kein Coding nötig |
| Zuverlässigkeit | Variiert (leicht kaputt zu machen) | Hoch (KI passt sich Änderungen an) |
| Blockierungsrisiko | Mittel bis hoch | Niedrig (KI imitiert Nutzer und passt sich an) |
| Skalierbarkeit | Benötigt eigenen Code/Cloud-Setup | Integriertes Cloud-/Batch-Scraping |
| Wartung | Häufig (Änderungen, Blockierungen) | Minimal (KI passt sich automatisch an) |
| Exportoptionen | Manuell (CSV, DB) | Direkt zu Sheets, Notion, Airtable, CSV |
| Kosten | Kostenlos, aber zeitintensiv | Kostenloser Tarif, kostenpflichtige Pläne für größere Mengen |
Wann Python sinnvoll ist:
- Du brauchst volle Kontrolle, eigene Logik oder die Integration in andere Python-Workflows.
- Du scrapest Websites mit wenig Anti-Bot-Schutz.
Wann Thunderbit sinnvoll ist:
- Du willst Geschwindigkeit, Zuverlässigkeit und null Einrichtung.
- Du scrapest komplexe oder häufig veränderte Websites.
- Du willst dich nicht mit Proxys, CAPTCHAs oder Code herumschlagen.
Schritt-für-Schritt-Anleitung: Web Scraping in Python ohne Blockierung einrichten
Gehen wir ein praktisches Beispiel durch: Produktdaten von einer Beispiel-Website scrapen und dabei Best Practices gegen Blockierungen anwenden.
1. Benötigte Bibliotheken installieren
1pip install requests beautifulsoup4 fake-useragent2. Skript vorbereiten
1import requests
2from bs4 import BeautifulSoup
3from fake_useragent import UserAgent
4import time, random
5ua = UserAgent()
6urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Mit deinen URLs ersetzen
7for url in urls:
8 headers = {
9 "User-Agent": ua.random,
10 "Accept-Language": "en-US,en;q=0.9"
11 }
12 response = requests.get(url, headers=headers)
13 if response.status_code == 200:
14 soup = BeautifulSoup(response.text, "html.parser")
15 # Hier Daten extrahieren
16 print(soup.title.text)
17 else:
18 print(f"Blockiert oder Fehler bei \{url\}: \{response.status_code\}")
19 time.sleep(random.uniform(2, 6)) # Zufällige Pause3. Proxy-Rotation hinzufügen (optional)
1proxies = [
2 "<http://proxy1.example.com:8000>",
3 "<http://proxy2.example.com:8000>",
4 # Weitere Proxys
5]
6for i, url in enumerate(urls):
7 proxy = {"http": proxies[i % len(proxies)]}
8 headers = {"User-Agent": ua.random}
9 response = requests.get(url, headers=headers, proxies=proxy)
10 # ...restlicher Code4. Cookies und Sitzungen handhaben
1session = requests.Session()
2for url in urls:
3 response = session.get(url, headers=headers)
4 # ...restlicher Code5. Tipps zur Fehlerbehebung
- Wenn du viele 403-/429-Fehler siehst, verlangsame deine Anfragen oder teste neue Proxys.
- Wenn du auf CAPTCHAs stößt, ziehe Selenium oder einen CAPTCHA-Lösungsdienst in Betracht.
- Prüfe immer die
robots.txtund die Nutzungsbedingungen der Website.
Fazit und wichtigste Erkenntnisse
Web Scraping in Python ist mächtig — aber mit der Weiterentwicklung der Anti-Bot-Technologie bleibt Blockierung ein ständiges Risiko. Der beste Weg, Blockierungen zu vermeiden? Kombiniere technische Best Practices (rotierende Proxys, intelligente Header, zufällige Pausen, Session-Handling und Headless-Browser) mit einem gesunden Respekt für Website-Regeln und Ethik.
Aber manchmal reichen selbst die besten Python-Tricks nicht aus. Genau hier glänzen KI-gestützte Tools wie — sie bieten eine No-Code-, blockierungsresistente und businessfreundliche Möglichkeit, die Daten zu extrahieren, die du brauchst, und zwar schnell.
Willst du sehen, wie einfach Scraping sein kann? und probiere es selbst aus — oder schau dir unseren für weitere Scraping-Tipps und Tutorials an.
FAQs
1. Warum blockieren Websites Python-Web-Scraper?
Websites blockieren Scraper, um ihre Daten zu schützen, Serverüberlastung zu verhindern und automatisierte Bots davon abzuhalten, ihre Dienste zu missbrauchen. Python-Skripte sind leicht zu erkennen, wenn sie Standard-Header verwenden, Cookies nicht korrekt behandeln oder zu viele Anfragen in zu kurzer Zeit senden.
2. Was sind die wirksamsten Methoden, um beim Scraping mit Python nicht blockiert zu werden?
Nutze rotierende Proxys, setze realistische User-Agents und Header, variiere das Anfrage-Timing, verwalte Cookies/Sitzungen und simuliere menschliches Verhalten mit Tools wie Selenium oder Playwright.
3. Wie hilft Thunderbit im Vergleich zu Python-Skripten dabei, Blockierungen zu vermeiden?
Thunderbit nutzt KI, um sich an Seitenlayouts anzupassen, menschliches Surfen zu imitieren und Unterseiten sowie Pagination automatisch zu verarbeiten. Das senkt das Blockierungsrisiko, weil sich das Tool unauffällig verhält und seinen Ansatz in Echtzeit aktualisiert — ganz ohne Code oder Proxys.
4. Wann sollte ich Python-Scraping und wann ein KI-Tool wie Thunderbit verwenden?
Nutze Python, wenn du eigene Logik brauchst, andere Python-Codes integrieren willst oder einfache Websites scrapest. Nutze Thunderbit für schnelles, zuverlässiges und skalierbares Scraping — besonders dann, wenn Websites komplex sind, sich häufig ändern oder Skripte aggressiv blockieren.
5. Ist Web Scraping legal?
Web Scraping ist für öffentlich zugängliche Daten legal, aber du musst die Nutzungsbedingungen, Datenschutzrichtlinien und geltenden Gesetze der jeweiligen Website respektieren. Scrape niemals sensible oder private Daten und gehe immer ethisch und verantwortungsvoll vor.
Bereit, smarter statt härter zu scrapen? Probier Thunderbit aus und lass die Blockierungen hinter dir.
Mehr erfahren:
- Google News mit Python scrapen: Eine Schritt-für-Schritt-Anleitung
- Mit Python ein Best-Buy-Tool zur Preisverfolgung erstellen
- 14 Wege für Web Scraping ohne Blockierung
- 10 beste Tipps, wie du beim Web Scraping nicht blockiert wirst