

Das Web von heute hat mit dem von früher nicht mehr viel gemein. Fast jede Seite, die du aufrufst, läuft über JavaScript und lädt ihre Inhalte erst nach und nach nach – Stichwort endloses Scrollen, Pop-ups und Dashboards, die ihre Daten erst nach ein, zwei Klicks rausrücken. Inzwischen setzen stolze 98,7 % aller Websites auf JavaScript, was im Klartext heißt: Die alten Scraping-Tools, die nur statisches HTML einlesen, gehen an einem Großteil der spannenden Daten vorbei. Wer schon mal versucht hat, Produktpreise von einem modernen Onlineshop abzugreifen oder Immobilienanzeigen aus einer interaktiven Karte zu ziehen, kennt den Frust: Die gewünschten Daten stehen schlicht nicht im Quellcode.
Und genau da kommt Scraping mit Selenium ins Spiel. Nach Jahren im Bau von Automatisierungstools – und ja, einer ganzen Reihe gescrapter Websites – lässt sich sagen: Selenium zu beherrschen ist eine kleine Superkraft für alle, die aktuelle, dynamische Daten brauchen. In diesem praxisnahen Selenium-Web-Scraping-Tutorial gehen wir die wichtigsten Schritte durch – von der Einrichtung bis zur Automatisierung – und schauen, wie du Selenium mit Thunderbit kombinierst, um strukturierte, direkt exportierbare Daten zu bekommen. Egal, ob du Business-Analyst, Vertriebsprofi oder einfach neugieriger Python-Nutzer bist: Du nimmst praktisches Handwerkszeug mit und vielleicht den einen oder anderen Lacher (denn seien wir ehrlich: XPath-Selektoren zu debuggen, das baut Charakter auf).
Thunderbit KI-Web-Scraper ausprobieren
Was ist Selenium und warum sollte man es fürs Web-Scraping nutzen?
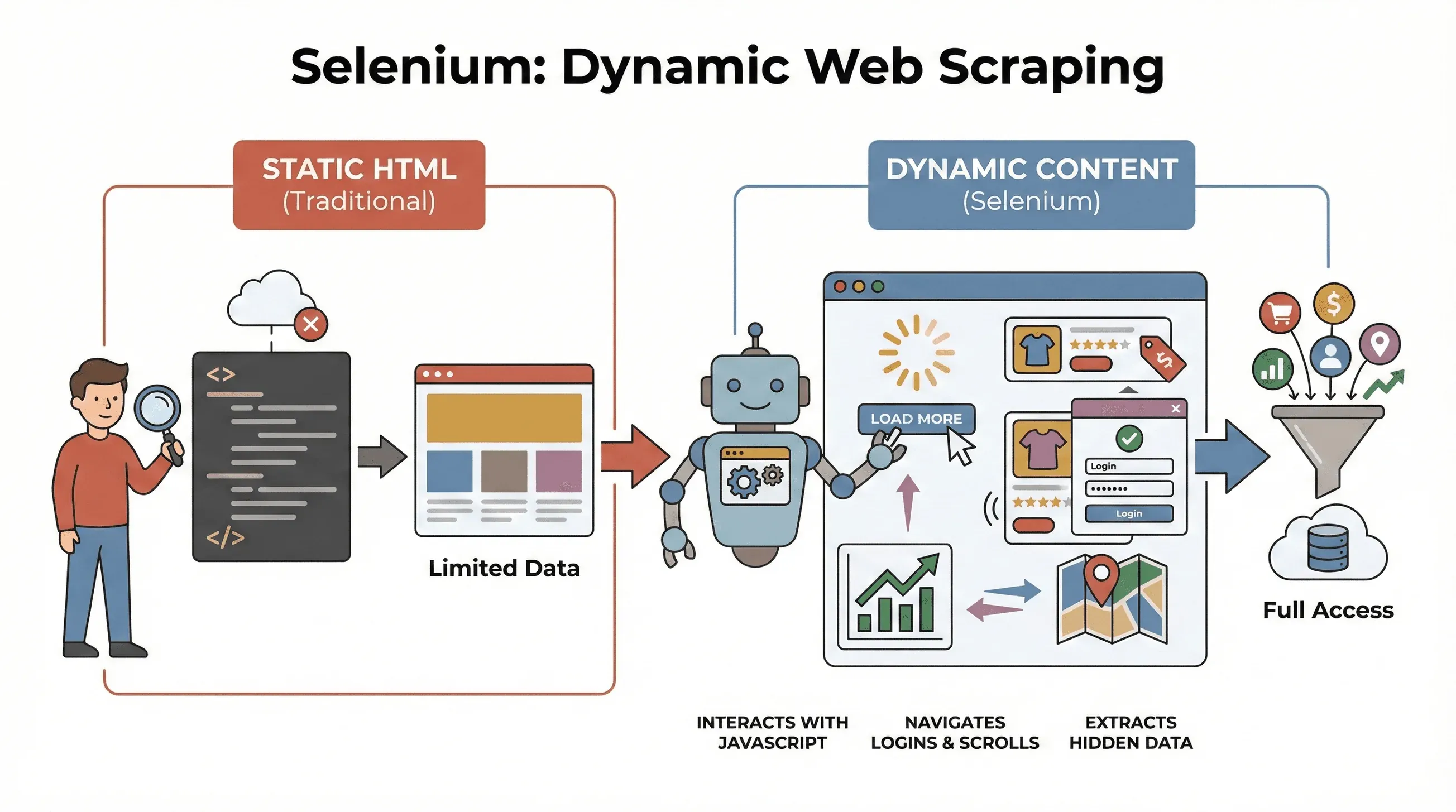 Beginnen wir bei den Grundlagen. Selenium ist ein Open-Source-Framework, mit dem du einen echten Webbrowser – etwa Chrome oder Firefox – per Code fernsteuerst. Stell dir einen Roboter vor, der Seiten öffnet, Buttons klickt, Formulare ausfüllt, scrollt und sogar JavaScript ausführt, genau wie ein Mensch vor dem Bildschirm. Und das ist entscheidend, denn die meisten modernen Websites legen ihre Daten nicht offen auf den Tisch. Stattdessen laden sie Inhalte dynamisch nach, oft erst, nachdem du mit der Seite interagiert hast.
Beginnen wir bei den Grundlagen. Selenium ist ein Open-Source-Framework, mit dem du einen echten Webbrowser – etwa Chrome oder Firefox – per Code fernsteuerst. Stell dir einen Roboter vor, der Seiten öffnet, Buttons klickt, Formulare ausfüllt, scrollt und sogar JavaScript ausführt, genau wie ein Mensch vor dem Bildschirm. Und das ist entscheidend, denn die meisten modernen Websites legen ihre Daten nicht offen auf den Tisch. Stattdessen laden sie Inhalte dynamisch nach, oft erst, nachdem du mit der Seite interagiert hast.
Was ist Data Scraping und wie macht man es 2026? Get Started Free
Was hat das mit Scraping zu tun? Klassiker wie BeautifulSoup oder Scrapy sind hervorragend für statisches HTML, aber sie „sehen" nichts, was erst nach dem ersten Laden per JavaScript erscheint. Selenium dagegen interagiert in Echtzeit mit der Seite und ist damit wie geschaffen für:
- Produktlisten, die erst nach einem Klick auf „Mehr laden" auftauchen
- Preise oder Bewertungen, die sich dynamisch aktualisieren
- Login-Formulare, Pop-ups oder endloses Scrollen
- Daten aus Dashboards, Karten oder anderen interaktiven Elementen
Kurzum: Selenium ist deine Wahl, wenn du an Daten willst, die erst nach dem Laden der Seite – oder nach einer Nutzeraktion – sichtbar werden.
Die wichtigsten Schritte für Python-Selenium-Web-Scraping
Scraping mit Selenium lässt sich auf drei zentrale Schritte eindampfen:
| Schritt | Was du tust | Warum das wichtig ist |
|---|---|---|
| 1. Umgebung einrichten | Selenium, WebDriver und Python-Bibliotheken installieren | Werkzeuge bereitstellen und Einrichtungsprobleme vermeiden |
| 2. Elemente finden | Die gewünschten Daten über IDs, Klassen, XPath usw. lokalisieren | Die richtigen Informationen finden, auch wenn sie von JavaScript verborgen werden |
| 3. Daten extrahieren & speichern | Text, Links oder Tabellen auslesen und als CSV/Excel speichern | Rohdaten aus dem Web in etwas Nutzbares verwandeln |
Gehen wir jeden Schritt mit praktischen Beispielen und Code durch, den du kopieren, anpassen und bei Gelegenheit stolz Freunden zeigen kannst.
Schritt 1: Deine Python-Selenium-Umgebung einrichten
Als Erstes brauchst du Selenium und einen Browser-Treiber (etwa ChromeDriver für Chrome). Die gute Nachricht: Das ist heute so einfach wie nie.
Selenium installieren
Öffne dein Terminal und führe aus:
pip install selenium
Einen WebDriver holen
- Chrome: Lade ChromeDriver herunter (achte darauf, dass er zu deiner Chrome-Version passt).
- Firefox: Lade GeckoDriver herunter.
Profi-Tipp: Ab Selenium 4.6 lädt der Selenium Manager die Treiber von selbst herunter. Mit dem Herumfummeln an PATH-Variablen ist also womöglich Schluss (Dokumentation).
Dein erstes Selenium-Skript
Hier ein kurzes „Hello World" für Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # Oder webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Tipps zur Fehlerbehebung:
- Erscheint die Meldung „driver not found", prüfe deinen PATH oder lass den Selenium Manager ran.
- Stelle sicher, dass Browser- und Treiberversion zusammenpassen.
- Arbeitest du auf einem Headless-Server (ohne GUI), wirf unten einen Blick auf die Tipps zum Headless-Modus.
Schritt 2: Web-Elemente für die Datenextraktion finden
Jetzt wird's spannend: Du sagst Selenium, welche Daten du haben willst. Websites bestehen aus Elementen – Divs, Spans, Tabellen und so weiter – und Selenium bietet dir mehrere Wege, sie aufzuspüren.
Häufige Strategien zum Lokalisieren
By.ID: Ein Element über seine eindeutige ID findenBy.CLASS_NAME: Elemente nach CSS-Klasse findenBy.XPATH: XPath-Ausdrücke verwenden (sehr flexibel, aber manchmal heikel)By.CSS_SELECTOR: CSS-Selektoren verwenden (ideal für komplexe Abfragen)
So setzt du sie ein:
from selenium.webdriver.common.by import By
# Nach ID finden
price = driver.find_element(By.ID, "price").text
# Nach XPath finden
title = driver.find_element(By.XPATH, "//h1").text
# Alle Produktbilder per CSS-Selektor finden
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Profi-Tipp: Nimm immer den einfachsten und stabilsten Selektor (ID > Klasse > CSS > XPath). Und wenn eine Seite ihre Daten verzögert lädt, setze auf explizite Wartezeiten:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
So bricht dein Skript nicht ab, nur weil die Daten eine Sekunde später eintrudeln.
Schritt 3: Daten extrahieren und speichern
Hast du deine Elemente gefunden, geht es ans Einsammeln und Ablegen der Daten an einem nützlichen Ort.
Text, Links und Tabellen extrahieren
Nehmen wir an, du scrapst eine Produkttabelle:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Mit Pandas als CSV speichern
import pandas as pd
df = pd.DataFrame(data, columns=["Name", "Preis", "Bestand"])
df.to_csv("products.csv", index=False)
Genauso gut speicherst du als Excel (df.to_excel("products.xlsx")) oder schiebst die Daten per API direkt in Google Sheets.
Vollständiges Beispiel: Produktnamen und Preise scrapen
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Titel", "Preis"])
df.to_csv("products.csv", index=False)
Selenium vs. BeautifulSoup und Scrapy: Was macht Selenium einzigartig?
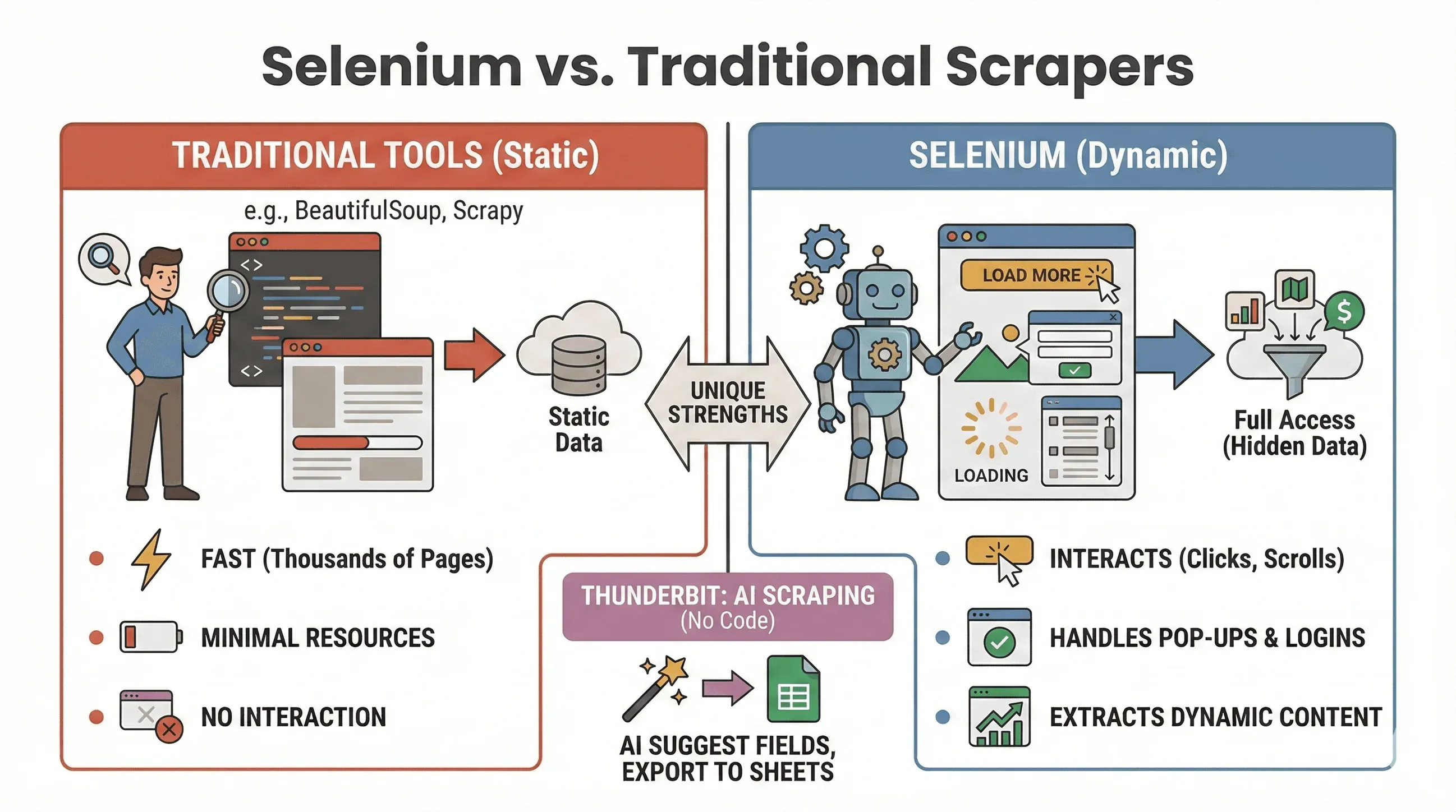 Klären wir die Gretchenfrage: Wann lohnt sich Selenium, und wann fährst du mit BeautifulSoup oder Scrapy besser? Hier ein kompakter Vergleich:
Klären wir die Gretchenfrage: Wann lohnt sich Selenium, und wann fährst du mit BeautifulSoup oder Scrapy besser? Hier ein kompakter Vergleich:
| Tool | Am besten für | Beherrscht JavaScript? | Geschwindigkeit & Ressourcenverbrauch |
|---|---|---|---|
| Selenium | Dynamische/interaktive Websites | Ja | Langsamer, braucht mehr Speicher |
| BeautifulSoup | Einfaches statisches HTML-Scraping | Nein | Sehr schnell, leichtgewichtig |
| Scrapy | Crawling statischer Seiten in großem Umfang | Eingeschränkt* | Extrem schnell, asynchron, wenig RAM |
| Thunderbit | No-Code-Business-Scraping | Ja (KI) | Schnell für kleine/mittlere Aufgaben |
*Scrapy bekommt mit Plugins zwar einige dynamische Inhalte in den Griff, aber das ist nicht seine Paradedisziplin (ScrapingBee).
Wann Selenium die richtige Wahl ist:
- Die Daten erscheinen erst nach Klick, Scrollen oder Login
- Du musst mit Pop-ups, endlosem Scrollen oder dynamischen Dashboards hantieren
- Statische Scraper reichen schlicht nicht aus
Wann BeautifulSoup/Scrapy besser passt:
- Die Daten stehen schon im ursprünglichen HTML
- Du musst Tausende Seiten im Eiltempo scrapen
- Du willst möglichst wenig Ressourcen verbrauchen
Und wer komplett auf Code verzichten will, scrapt dynamische Websites mit Thunderbit per KI – einfach auf „KI-Felder vorschlagen" klicken und nach Google Sheets, Notion oder Airtable exportieren. (Mehr dazu gleich.)
Wie du mit KI jede Website scrapen kannst Get Started Free
Web-Scraping-Aufgaben mit Selenium und Python automatisieren
Hand aufs Herz: Niemand will um 2 Uhr nachts aufstehen, nur um ein Scraping-Skript zu starten. Zum Glück lassen sich deine Selenium-Jobs mit den Scheduling-Tools von Python oder dem Scheduler deines Betriebssystems automatisieren (etwa cron unter Linux/Mac oder die Aufgabenplanung unter Windows).
Mit der schedule-Bibliothek
import schedule
import time
def job():
# Dein Scraping-Code hier
print("Scraping...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Oder mit Cron (Linux/Mac)
Trag das in deine Crontab ein, um stündlich auszuführen:
0 * * * * python /path/to/your_script.py
Tipps für die Automatisierung:
- Lass Selenium im Headless-Modus laufen (siehe unten), um GUI-Pop-ups zu umgehen.
- Protokolliere Fehler und schick dir eine Benachrichtigung, wenn etwas hakt.
- Schließe den Browser stets mit
driver.quit(), um Ressourcen freizugeben.
Effizienz steigern: Tipps für schnelleres und zuverlässigeres Selenium-Scraping
Selenium ist mächtig, aber ohne Acht kann es lahm und speicherhungrig werden. So bringst du Tempo rein und umgehst die typischen Stolperfallen:
1. Im Headless-Modus ausführen
Du musst nicht zusehen, wie Chrome hundertmal auf- und wieder zugeht. Der Headless-Modus lässt den Browser im Hintergrund werkeln:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Bilder und anderen unnötigen Ballast blockieren
Warum Bilder laden, wenn du nur Text scrapst? Blockiere sie und die Seiten laden schneller:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Effiziente Selektoren verwenden
- Setze lieber auf IDs oder einfache CSS-Selektoren statt auf verschachtelte XPaths.
- Verzichte auf
time.sleep()– nimm stattdessen explizite Wartezeiten (WebDriverWait).
4. Zufällige Verzögerungen einbauen
Streu zufällige Pausen ein, um menschliches Surfverhalten nachzuahmen und Blockaden zu entgehen:
import random, time
time.sleep(random.uniform(1, 3))
5. User-Agents und IPs rotieren lassen (falls nötig)
Wer viel scrapt, sollte seinen User-Agent-String rotieren und über Proxys nachdenken, um einfache Anti-Bot-Maßnahmen auszuhebeln.
6. Sitzungen und Fehler im Griff behalten
- Nutze
try/except, um fehlende Elemente sauber abzufangen. - Protokolliere Fehler und mach Screenshots fürs Debugging.
Weitere Optimierungstipps findest du im Leitfaden von BrowserStack.
Fortgeschritten: Selenium mit Thunderbit für strukturierten Datenexport kombinieren
Jetzt wird es richtig interessant – vor allem, wenn du beim Aufbereiten und Exportieren von Daten Zeit sparen willst.
Hast du deine Rohdaten mit Selenium gescrapt, kannst du mit Thunderbit:
- Felder automatisch erkennen lassen: Thunderbits KI liest deine gescrapten Seiten oder CSVs und schlägt passende Spaltennamen vor („KI-Felder vorschlagen").
- Unterseiten scrapen: Hast du eine Liste von URLs (etwa Produktseiten), steuert Thunderbit jede einzelne an und reichert deine Tabelle um weitere Details an – ganz ohne zusätzlichen Code.
- Daten anreichern: Unterwegs übersetzen, kategorisieren oder analysieren.
- Überall exportieren: Mit einem Klick nach Google Sheets, Airtable, Notion, CSV oder Excel.
Workflow-Beispiel:
- Scrape mit Selenium eine Liste von Produkt-URLs und Titeln.
- Exportiere die Daten als CSV.
- Öffne Thunderbit, importiere deine CSV und lass dir von der KI Felder vorschlagen.
- Nutze Thunderbits Unterseiten-Scraping, um zu jeder Produkt-URL weitere Details wie Bilder oder Spezifikationen nachzuziehen.
- Exportiere dein fertiges, strukturiertes Dataset nach Sheets oder Notion.
Diese Kombination spart dir stundenlange Handarbeit und lässt dich dich auf die Analyse konzentrieren, statt chaotische Daten zu sortieren. Mehr zu diesem Workflow steht im Selenium-Leitfaden von Thunderbit.
Selenium-Daten mit Thunderbit AI exportieren
Best Practices und Fehlerbehebung für Selenium-Web-Scraping
Web-Scraping ist ein bisschen wie Angeln: Mal holst du den großen Fisch, mal verhedderst du dich im Gestrüpp. So bleiben deine Skripte zuverlässig – und fair:
Best Practices
- Robots.txt und Nutzungsbedingungen beachten: Prüfe stets, ob Scraping überhaupt erlaubt ist.
- Anfragen drosseln: Belaste die Server nicht über Gebühr – baue Pausen ein und achte auf HTTP-429-Fehler.
- APIs nutzen, wenn verfügbar: Stehen die Daten per API öffentlich bereit, nimm sie – das ist sicherer und stabiler.
- Nur öffentliche Daten scrapen: Lass die Finger von persönlichen oder sensiblen Informationen und halte dich an die Datenschutzgesetze (in der DACH-Region also die DSGVO).
- Pop-ups und CAPTCHAs handhaben: Mit Selenium kannst du Pop-ups schließen, aber sei vorsichtig mit CAPTCHAs – die lassen sich nur schwer automatisieren.
- User-Agents und Verzögerungen randomisieren: Das hilft, Erkennung und Blockierung aus dem Weg zu gehen.
Häufige Fehler und Lösungen
| Fehler | Bedeutung | So behebst du ihn |
|---|---|---|
NoSuchElementException | Das Element wurde nicht gefunden | Selektor prüfen; Wartezeiten verwenden |
| Timeout-Fehler | Seite oder Element hat zu lange gebraucht | Wartezeit erhöhen; Netzwerkgeschwindigkeit prüfen |
| Treiber-/Browser-Mismatch | Selenium kann den Browser nicht starten | Treiber- und Browser-Version aktualisieren |
| Sitzungsabstürze | Browser wurde unerwartet geschlossen | Headless-Modus verwenden; Ressourcen verwalten |
Weitere Tipps zur Fehlerbehebung findest du im Selenium-Tutorial von Thunderbit.
Fazit und wichtigste Erkenntnisse
Dynamisches Web-Scraping ist schon lange kein Hexenwerk mehr, das nur Hardcore-Entwicklern vorbehalten bleibt. Mit Python Selenium automatisierst du jeden Browser, kommst auch mit den vertracktesten JavaScript-Seiten klar und ziehst genau die Daten, die dein Unternehmen braucht – sei es für Vertrieb, Recherche oder reine Neugier. Behalte im Kopf:
- Selenium ist das Werkzeug der Wahl für dynamische, interaktive Websites.
- Die drei Kernschritte: Einrichten, finden, extrahieren & speichern.
- Automatisiere deine Skripte für regelmäßige Datenaktualisierungen.
- Optimiere auf Tempo und Zuverlässigkeit mit Headless-Modus, klugen Wartezeiten und effizienten Selektoren.
- Kombiniere Selenium mit Thunderbit, um Daten einfach zu strukturieren und zu exportieren – besonders dann, wenn du dir den Tabellen-Stress sparen willst.
Bereit für den Selbstversuch? Starte mit den Codebeispielen von oben, und wenn du dein Scraping aufs nächste Level heben willst, probiere Thunderbit für die sofortige, KI-gestützte Datenbereinigung und den Export. Wer noch tiefer einsteigen will, schaut im Thunderbit Blog vorbei – dort gibt es ausführliche Analysen, Tutorials und das Neueste rund um Web-Automatisierung.
Viel Spaß beim Scrapen – und mögen deine Selektoren immer finden, wonach du suchst.
Thunderbit KI-Web-Scraper kostenlos ausprobieren Get Started Free
FAQs
1. Warum sollte ich für Web-Scraping Selenium statt BeautifulSoup oder Scrapy verwenden?
Selenium ist ideal für dynamische Websites, bei denen Inhalte erst nach Nutzeraktionen oder JavaScript-Ausführung geladen werden. BeautifulSoup und Scrapy sind bei statischem HTML schneller, können aber nicht mit dynamischen Elementen umgehen oder Klicks und Scrollen simulieren.
2. Wie mache ich meinen Selenium-Scraper schneller?
Nutze den Headless-Modus, blockiere Bilder und unnötige Ressourcen, setze auf effiziente Selektoren und streu zufällige Verzögerungen ein, um menschliches Browsing nachzuahmen. Weitere Tipps stehen im Leitfaden von BrowserStack.
3. Kann ich Selenium-Scraping-Aufgaben so planen, dass sie automatisch laufen?
Ja! Nutze die schedule-Bibliothek von Python oder den Scheduler deines Betriebssystems (cron oder Aufgabenplanung), um Skripte in festen Intervallen auszuführen. Automatisiertes Scraping hält deine Daten aktuell.
4. Was ist der beste Weg, mit Selenium gescrapte Daten zu exportieren?
Speichere die Daten mit Pandas als CSV oder Excel. Für anspruchsvollere Exporte (Google Sheets, Notion, Airtable) importierst du sie in Thunderbit und nutzt die Exportfunktionen mit einem Klick.
5. Wie gehe ich in Selenium mit Pop-ups und CAPTCHAs um?
Pop-ups schließt du, indem du ihre Schließen-Buttons findest und anklickst. CAPTCHAs sind deutlich zäher – stößt du darauf, denke über einen manuellen Workaround oder einen CAPTCHA-Lösungsdienst nach und halte dich immer an die Nutzungsbedingungen der Website.
Du willst mehr Scraping-Tutorials, KI-Automatisierungstipps oder die neuesten Infos zu Business-Daten-Tools? Abonniere den Thunderbit Blog oder schau dir unseren YouTube-Kanal für praxisnahe Demos an.
Mehr erfahren
- Erste Schritte mit Selenium Python für Web-Scraping
- Beautiful Soup vs. Selenium: Detaillierter Vergleich 2025
- Umfassender Leitfaden für Web-Scraping in Python: Schritt für Schritt
- Schritt-für-Schritt-Python-Scraping-Tutorial für Anfänger
- Schritt-für-Schritt-Anleitung: Web-Scraping in Python-Tutorial




