

Kurzer Rückblick in eine gar nicht so ferne Vergangenheit: Ich sitze am Schreibtisch, die Kaffeetasse in der Hand, und vor mir gähnt eine Tabelle, die noch leerer ist als mein Kühlschrank am Sonntagabend. Der Vertrieb will Wettbewerber-Preisdaten, das Marketing braucht frische Leads, und die Ops-Abteilung hätte gern Produktlisten von einem Dutzend Websites – am liebsten schon gestern. Dass die Daten irgendwo da draußen liegen, weiß ich. Aber sie auch tatsächlich zu bekommen, ist die eigentliche Kunst. Wer beim Copy-and-paste schon mal das Gefühl hatte, eine endlose Runde digitales Whack-a-Mole zu spielen, ist damit nicht allein.
Heute sieht die Sache anders aus. Web-Scraping ist vom Nerd-Hobby zur festen Säule der Geschäftsstrategie gereift. JavaScript und Node.js spielen dabei vorne mit und treiben alles an – vom kleinen Skript bis zur ausgewachsenen Datenpipeline. Der Haken: So mächtig die Werkzeuge sind, die Lernkurve fühlt sich mitunter an wie eine Everest-Besteigung in Flip-Flops. Ob du also im Business steckst, eine Schwäche für Daten hast oder einfach nie wieder etwas von Hand abtippen willst – dieser Leitfaden ist für dich. Ich gehe das Ökosystem durch, die zentralen Bibliotheken, die typischen Stolpersteine und die Frage, warum es manchmal am klügsten ist, die schwere Arbeit direkt der KI zu überlassen.
Warum Web-Scraping mit JavaScript und Node.js für Unternehmen wichtig ist
Beginnen wir beim „Warum“. 2026 sind Webdaten kein nettes Extra mehr, sondern geschäftskritisch. Aktuelle Studien zeigen: 73 % der Unternehmen schreiben öffentlichen Webdaten schnellere und präzisere Entscheidungen zu, und rund 42 % der Enterprise-Datenbudgets fließen inzwischen in die Erfassung von Webdaten. Der Markt für alternative Daten – Web-Scraping inklusive – ist bereits eine 4,9-Milliarden-Dollar-Branche und wächst munter weiter.
Was treibt diesen Goldrausch an? Hier ein Blick auf die häufigsten geschäftlichen Anwendungsfälle:
- Wettbewerbsbeobachtung & E-Commerce: Händler scrapen die Seiten ihrer Konkurrenz nach Preisen und Beständen und schrauben damit den Umsatz mitunter um 4 % oder mehr nach oben.
- Lead-Generierung & Sales Intelligence: Vertriebsteams sammeln automatisiert E-Mails, Telefonnummern und Firmendaten aus Verzeichnissen und sozialen Plattformen.
- Marktforschung & Content-Aggregation: Analysten ziehen Nachrichten, Bewertungen und Stimmungsdaten heran, um Trends zu erkennen und Prognosen zu erstellen.
- Werbung & Ad Tech: Ad-Tech-Firmen verfolgen Anzeigenplatzierungen und Kampagnen der Konkurrenz in Echtzeit.
- Immobilien & Reisen: Agenturen scrapen Inserate, Preise und Bewertungen, um Bewertungsmodelle und Marktanalysen zu füttern.
- Content- & Daten-Aggregatoren: Plattformen bündeln Daten aus vielen Quellen und betreiben damit Vergleichstools und Dashboards.
JavaScript und Node.js haben sich für solche Aufgaben zum bevorzugten Stack entwickelt – vor allem, weil immer mehr Seiten auf dynamische, per JavaScript gerenderte Inhalte setzen. Node.js glänzt bei asynchronen Operationen und eignet sich deshalb ideal für Scraping in großem Maßstab. Und dank eines lebendigen Bibliotheken-Ökosystems baust du damit alles – vom schnellen Skript bis zum robusten Scraper für den Produktionseinsatz.
Was ist Data Scraping und wie funktioniert es 2025 Get Started Free
Der Kern-Workflow: So funktioniert Web-Scraping mit JavaScript und Node.js
Nehmen wir dem typischen Scraping-Workflow den Schrecken. Ob du einen schlichten Blog oder eine JavaScript-schwere E-Commerce-Seite scrapst – die Schritte ähneln sich stark:
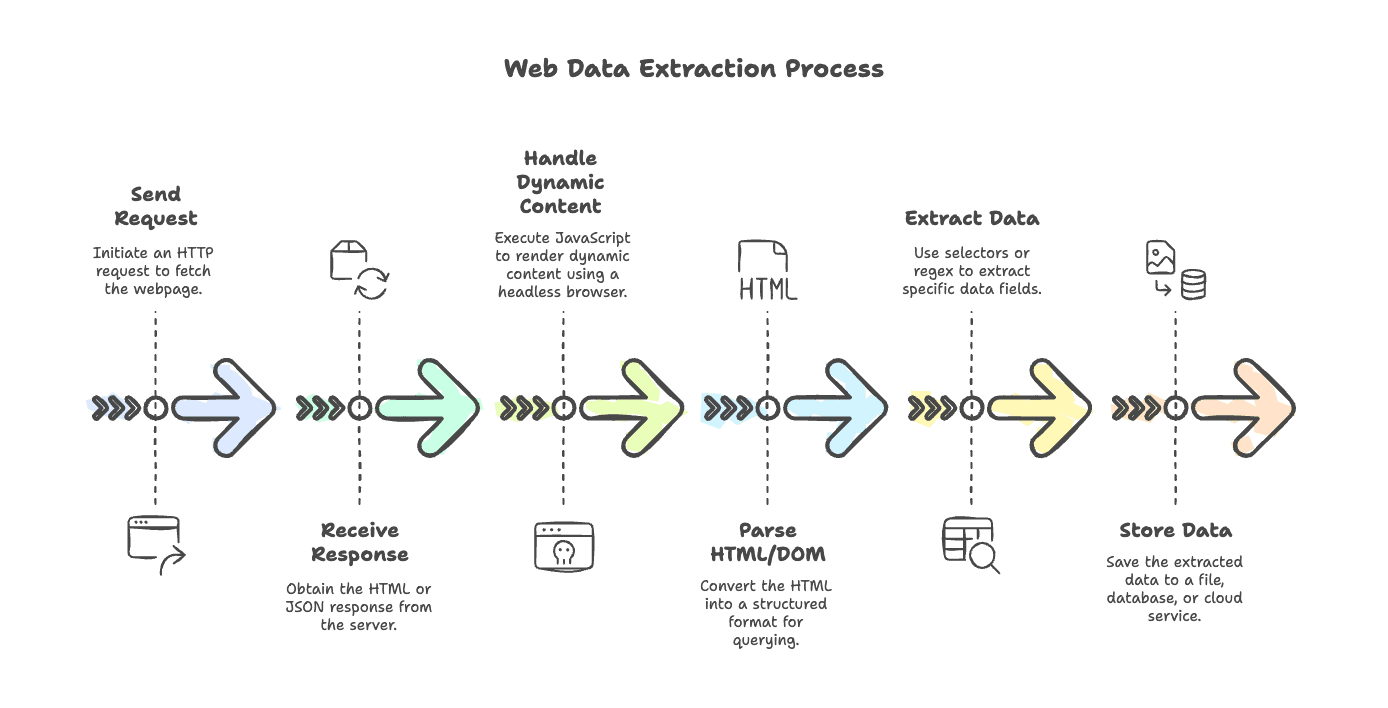
- Anfrage senden: Mit einem HTTP-Client die Seite abrufen (z. B.
axios,node-fetchodergot). - Antwort empfangen: Das HTML (oder manchmal JSON) vom Server erhalten.
- Dynamische Inhalte behandeln: Wenn die Seite per JavaScript gerendert wird, einen Headless-Browser wie Puppeteer oder Playwright verwenden, um Skripte auszuführen und den finalen Inhalt zu laden.
- HTML/DOM parsen: Mit einem Parser (
cheerio,jsdom) das HTML in eine Struktur umwandeln, die sich abfragen lässt. - Daten extrahieren: Mit Selektoren oder Regex die gewünschten Felder herausziehen.
- Daten speichern: Die Ergebnisse in einer Datei, Datenbank oder Cloud-Dienst ablegen.
Jeder dieser Schritte bringt eigene Tools und Best Practices mit – die schauen wir uns gleich genauer an.
Wichtige HTTP-Request-Bibliotheken für Web-Scraping in JavaScript
Am Anfang jedes Scrapers stehen die HTTP-Anfragen. Node.js bietet dir hier eine ganze Palette an Optionen – manche altbewährt, manche modern. Hier ein Überblick über die beliebtesten Bibliotheken:
1. Axios
Ein auf Promises basierender HTTP-Client für Node und Browser. Für die meisten Scraping-Aufgaben das Allzweckwerkzeug schlechthin.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Vorteile: Funktionsreich, unterstützt async/await, automatische JSON-Analyse, Interceptors und Proxy-Unterstützung.
Nachteile: Etwas schwergewichtiger, manchmal fast schon „magisch“ in der Art, wie er Daten verarbeitet.
2. node-fetch
Bringt die fetch-API des Browsers nach Node.js. Schlank und modern.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Vorteile: Leichtgewichtig, vertraute API für alle, die aus dem Frontend-JavaScript kommen.
Nachteile: Wenige Funktionen, Fehlerbehandlung von Hand, Proxy-Setup ist umständlich.
3. SuperAgent
Eine bewährte HTTP-Bibliothek mit verkettbarer API.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Vorteile: Ausgereift, unterstützt Formulare, Datei-Uploads und Plugins.
Nachteile: Die API wirkt etwas in die Jahre gekommen, größere Abhängigkeit.
4. Unirest
Ein einfacher, sprachneutraler HTTP-Client.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Vorteile: Einfache Syntax, gut für schnelle Skripte.
Nachteile: Weniger Funktionen, kleinere Community.
5. Got
Ein robuster, schneller HTTP-Client für Node.js mit erweiterten Funktionen.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Vorteile: Schnell, unterstützt HTTP/2, Wiederholungen und Streams.
Nachteile: Nur für Node, die API kann für Einsteiger etwas dicht wirken.
6. Node’s eingebautes http/https
Du kannst auch zur klassischen Variante greifen:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Antwortlänge:', data.length);
});
});
Vorteile: Keine Abhängigkeiten.
Nachteile: Umständlich, stark callback-lastig, keine Promises.
Hier findest du einen detaillierten Funktionsvergleich und Codebeispiele.
Die richtige HTTP-Client-Bibliothek für dein Projekt wählen
Woran erkennst du das passende Tool? Darauf achte ich:
- Einfache Nutzung: Axios und Got sind erste Wahl für async/await und eine saubere Syntax.
- Leistung: Got und node-fetch sind schlank und schnell, wenn du mit hoher Parallelität scrapst.
- Proxy-Unterstützung: Mit Axios und Got rotierst du Proxys ohne großen Aufwand.
- Fehlerbehandlung: Axios wirft bei HTTP-Fehlern standardmäßig; bei node-fetch musst du selbst prüfen.
- Community: Axios und Got haben aktive Communities und reichlich Beispiele.
Meine Schnell-Empfehlungen:
- Schnelle Skripte oder Prototypen: node-fetch oder Unirest.
- Scraping im Produktionseinsatz: Axios (wegen der Funktionen) oder Got (wegen der Performance).
- Browser-Automatisierung: Puppeteer oder Playwright übernehmen die Requests intern.
HTML-Parsing und Datenextraktion: Cheerio, jsdom und mehr
Sobald das HTML bei dir liegt, musst du es in etwas verwandeln, mit dem sich wirklich arbeiten lässt. Auftritt der Parser.
Cheerio
Cheerio ist im Grunde jQuery für den Server. Schnell, leichtgewichtig und ideal für statisches HTML.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Vorteile: Blitzschnell, vertraute API, kommt auch mit unordentlichem HTML zurecht.
Nachteile: Führt kein JavaScript aus – sieht nur, was im HTML steht.
Mehr über Geschwindigkeit und Einsatzbereiche von Cheerio.
jsdom
jsdom bildet in Node.js ein browserähnliches DOM nach. Es kann einfache Skripte ausführen und verhält sich „browserartiger“ als Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hallo</p><script>document.querySelector('#greet').textContent += ", Welt!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Vorteile: Kann Skripte ausführen, unterstützt die komplette DOM-API.
Nachteile: Langsamer und schwergewichtiger als Cheerio, kein vollwertiger Browser.
Cheerio und jsdom im Detail vergleichen.
Wann reguläre Ausdrücke oder andere Parsing-Methoden sinnvoll sind
Regex ist beim Scraping wie scharfe Soße – in Maßen großartig, aber bitte nicht über alles kippen. Nützlich ist Regex für:
- das Extrahieren von Mustern aus Text (E-Mails, Telefonnummern, Preise),
- das Bereinigen oder Validieren von Scraped-Daten,
- das Herausziehen von Daten aus Textblöcken oder Skript-Tags.
Beispiel: Eine Zahl aus Text extrahieren
const text = "Gesamtverkäufe: 1.234 Einheiten";
const match = text.match(/([\d.]+)\s*Einheiten/);
if (match) {
const units = parseInt(match[1].replace(/\./g, ''));
console.log("Verkaufte Einheiten:", units);
}
Komplettes HTML solltest du aber nicht mit Regex parsen – dafür ist ein DOM-Parser da. Mehr Regex-Tipps fürs Scraping.
Dynamische Websites handhaben: Puppeteer, Playwright und Headless-Browser
Moderne Websites lieben JavaScript. Oft steckt die gewünschte Information gar nicht im ersten HTML, sondern wird erst nach dem Laden per Skript gerendert. Genau dafür gibt es Headless-Browser.
Puppeteer
Eine Node.js-Bibliothek von Google, die Chrome/Chromium fernsteuert. Im Grunde wie ein Roboter, der für dich durch Seiten klickt und scrollt.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Vorteile: Vollständiges Chrome-Rendering, einfache API, großartig für dynamische Inhalte.
Nachteile: Nur Chromium, ressourcenintensiver.
Mehr über die Stärken von Puppeteer lesen.
Playwright
Eine neuere Bibliothek von Microsoft. Playwright unterstützt Chromium, Firefox und WebKit – sozusagen Puppeteers cooler, browserübergreifender Cousin.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Vorteile: Browserübergreifend, parallele Kontexte, automatisches Warten auf Elemente.
Nachteile: Etwas steilere Lernkurve, größere Installation.
Warum Playwright immer stärker wird.
Nightmare
Ein auf Electron basierendes Automatisierungstool, das vor Jahren mal angesagt war. Das Repository ist inzwischen in die GitHub-Organisation segment-boneyard gewandert – Segments Ablage für Projekte, die nicht mehr gepflegt werden – und die letzte npm-Version stammt aus 2019. Für neue Projekte würde ich es 2026 nicht mehr anfassen; übernimmst du ein altes Skript, das es noch nutzt, ist das in Ordnung, aber für alles Neue greifst du besser direkt zu Playwright oder Puppeteer.
Headless-Browser-Lösungen im Vergleich
| Aspekt | Puppeteer (Chrome) | Playwright (Mehrbrowser) | Nightmare (Electron) |
|---|---|---|---|
| Browser-Unterstützung | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (alt) |
| Leistung & Skalierung | Schnell, aber schwergewichtig | Schnell, bessere Parallelisierung | Langsamer, weniger stabil |
| Dynamisches Scraping | Hervorragend | Hervorragend + mehr Funktionen | Für einfache Websites okay |
| Wartung | Gut gepflegt | Sehr aktiv | Archiviert (segment-boneyard, letzte npm-Veröffentlichung 2019) |
| Am besten geeignet für | Chrome-Scraping | Komplexe, browserübergreifende Aufgaben | Einfache Legacy-Jobs |
Mein Rat: Für neue, komplexe Projekte nimmst du Playwright. Puppeteer bleibt stark, wenn es nur um Chrome geht. Nightmare ist eher etwas für Nostalgiker oder alte Skripte.
Unterstützende Tools: Planung, Umgebung, CLI und Datenspeicherung
Ein praxistauglicher Scraper ist mehr als nur Abrufen und Parsen. Auf diese Hilfswerkzeuge setze ich gern:
Planung: node-cron
Lass deine Scraper automatisch zu festen Zeiten laufen.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Jeden Montag um 9 Uhr wird gescrapt');
});
Node-cron ist perfekt, um wiederkehrende Aufgaben zu automatisieren.
Umgebungsverwaltung: dotenv
Halte geheime Schlüssel und Konfigurationen aus deinem Code heraus.
require('dotenv').config();
const apiKey = process.env.API_KEY;
CLI-Tools: chalk, commander, inquirer
- chalk: Konsolenausgaben einfärben.
- commander: Befehlszeilenoptionen parsen.
- inquirer: Interaktive Abfragen für Nutzereingaben.
Datenspeicherung
- fs: In Dateien schreiben (JSON, CSV).
- lowdb: Leichte JSON-Datenbank.
- sqlite3: Lokale SQL-Datenbank.
- mongodb: NoSQL-Datenbank für größere Projekte.
Beispiel: Daten als JSON speichern
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
Die Schwachstellen des klassischen Web-Scrapings mit JavaScript und Node.js
Klartext: Traditionelles Scraping ist nicht nur Sonnenschein und Regenbogen. Das sind die größten Probleme, die ich gesehen – und selbst durchlitten – habe:

- Hohe Lernkurve: Du musst DOM, Selektoren, asynchrone Logik und manchmal auch Browser-Eigenheiten durchdringen.
- Wartungsaufwand: Websites ändern sich, Selektoren brechen, und du flickst ständig am Code herum.
- Schlechte Skalierbarkeit: Jede Website braucht ihr eigenes Skript; ein Werkzeug für alle Fälle gibt es nicht.
- Komplexe Datenbereinigung: Gescrapte Daten sind oft unordentlich – Bereinigen, Formatieren und Dubletten entfernen ist ein Job für sich.
- Leistungsgrenzen: Browser-Automatisierung ist bei großen Jobs langsam und ressourcenhungrig.
- Blockierungen und Anti-Bot-Maßnahmen: Websites sperren Scraper aus, werfen CAPTCHAs ein oder verstecken Daten hinter Logins.
- Rechtliche und ethische Grauzonen: Nutzungsbedingungen, Datenschutz und Compliance wollen beachtet werden.
Mehr zu diesen Schwachstellen und echten Zahlen.
Thunderbit vs. traditionelles Web-Scraping: eine Produktivitätsrevolution
Jetzt zum Elefanten im Raum: Was, wenn du den ganzen Code, die Selektoren und die Wartung einfach überspringen könntest?
Genau da kommt Thunderbit ins Spiel. Als Mitgründer und CEO bin ich natürlich etwas voreingenommen, aber hör mir kurz zu: Thunderbit ist für Geschäftsanwender gebaut, die Daten wollen – nicht Kopfzerbrechen.
So schlägt sich Thunderbit im Vergleich
| Aspekt | Thunderbit (KI-No-Code) | Traditionelles JS/Node-Scraping |
|---|---|---|
| Einrichtung | Mit 2 Klicks, kein Code | Skripte schreiben, debuggen |
| Dynamische Inhalte | Im Browser verarbeitet | Mit Headless-Browser skripten |
| Wartung | KI passt sich an Änderungen an | Manuelle Code-Updates |
| Datenextraktion | KI schlägt Felder vor | Manuelle Selektoren |
| Subpage-Scraping | Integriert, mit 1 Klick | Schleifen und site-spezifischer Code |
| Export | Excel, Sheets, Notion | Manuelle Datei-/DB-Integration |
| Nachbearbeitung | Zusammenfassen, taggen, formatieren | Zusätzlicher Code oder weitere Tools |
| Wer es nutzen kann | Jeder mit einem Browser | Nur Entwickler |
Thunderbits KI liest die Seite, schlägt Felder vor und extrahiert die Daten in wenigen Klicks. Sie verarbeitet Unterseiten, passt sich Layout-Änderungen an und kann Daten sogar während des Scrapings zusammenfassen, taggen oder übersetzen. Der Export geht direkt nach Excel, Google Sheets, Airtable oder Notion – ganz ohne technisches Setup.
Anwendungsfälle, in denen Thunderbit besonders stark ist:
- E-Commerce-Teams, die Wettbewerber-SKUs und Preise beobachten
- Vertriebsteams, die Leads und Kontaktdaten scrapen
- Marktforscher, die Nachrichten oder Bewertungen bündeln
- Immobilienmakler, die Inserate und Objektinformationen ziehen
Für häufiges, geschäftskritisches Scraping ist Thunderbit ein enormer Zeitgewinn. Für maßgeschneiderte, groß angelegte oder tief integrierte Projekte hat klassisches Scripting weiterhin seine Berechtigung – aber für die meisten Teams ist Thunderbit der schnellste Weg von „Ich brauche Daten“ zu „Ich habe Daten“.
Sieh dir die Thunderbit Chrome Extension in Aktion an oder entdecke weitere Anwendungsfälle im Thunderbit Blog.
Thunderbit KI-Web-Scraper testen
Schnellübersicht: Beliebte JavaScript- und Node.js-Bibliotheken für Web-Scraping
Hier dein Spickzettel für das JavaScript-Scraping-Ökosystem im Jahr 2026:
HTTP-Anfragen
- Axios: Funktionsreicher HTTP-Client auf Promises-Basis.
- node-fetch: Fetch-API für Node.js.
- Got: Schneller, fortgeschrittener HTTP-Client.
- SuperAgent: Ausgereifte, kettefähige HTTP-Anfragen.
- Unirest: Einfacher, sprachneutraler Client.
HTML-Parsing
Dynamische Inhalte
- Puppeteer: Headless-Chrome-Automatisierung.
- Playwright: Browserübergreifende Automatisierung.
- Nightmare: Elektronbasierte, veraltete Browser-Automatisierung.
Planung
- node-cron: Cron-Jobs in Node.js.
CLI & Utilities
- chalk: Terminal-Textformatierung.
- commander: Parser für CLI-Argumente.
- inquirer: Interaktive CLI-Abfragen.
- dotenv: Loader für Umgebungsvariablen.
Speicherung
- fs: Eingebautes Dateisystem.
- lowdb: Winzige lokale JSON-Datenbank.
- sqlite3: Lokale SQL-Datenbank.
- mongodb: NoSQL-Datenbank.
Frameworks
- Crawlee: Hochentwickeltes Crawling- und Scraping-Framework von Apify. Die JavaScript-/TypeScript-Version ist Stand Mai 2026 bei v3.16 und damit der reifere Track (der Python-Port ist neuer). Es kapselt Puppeteer, Playwright, Cheerio und JSDOM hinter einer API und bringt Proxy-Rotation sowie Queueing direkt mit – praktisch, wenn du immer wieder dieselbe Grundstruktur um deine Scraper herum neu bauen würdest.
(Prüfe immer die aktuellen Dokumentationen und GitHub-Repositories auf Updates.)
Empfohlene Ressourcen, um Web-Scraping in JavaScript zu meistern
Du willst noch tiefer einsteigen? Hier eine kuratierte Liste an Ressourcen, mit denen du deine Scraping-Fähigkeiten ausbaust:
Offizielle Dokus & Leitfäden
- MDN Web Docs: Web Scraping
- Puppeteer-Dokumentation
- Playwright-Dokumentation
- Crawlee-Dokumentation
- Apify Web Scraping Academy
Tutorials & Kurse
- freeCodeCamp: Der ultimative Leitfaden für Web-Scraping mit Node.js
- YouTube: Web-Scraping mit Node.js (freeCodeCamp)
- DigitalOcean: So scrapst du eine Website mit Node.js und Puppeteer
Open-Source-Projekte & Beispiele
Community & Foren
Bücher & umfassende Leitfäden
- O’Reilly: „Web Scraping with Python“ (für sprachübergreifende Konzepte)
- Udemy/Coursera: Kurse zu „Web Scraping in Node.js“
(Achte immer auf die neuesten Ausgaben und Updates.)
Wie du jede Website mit KI scrapst Get Started Free
Fazit: Den richtigen Ansatz für dein Team wählen
Unterm Strich: JavaScript und Node.js geben dir beim Web-Scraping enorm viel Power und Flexibilität an die Hand. Du baust damit alles – vom schnellen, pragmatischen Skript bis zum robusten, skalierbaren Crawler. Aber mit großer Macht kommt große… Wartung. Klassisches Scripting passt am besten zu maßgeschneiderten, technisch anspruchsvollen Projekten, bei denen du volle Kontrolle brauchst und laufende Pflege kein Problem ist.
Für alle anderen – Business-Anwender, Analysten, Marketer und alle, die einfach nur Daten wollen – sind moderne No-Code-Lösungen wie Thunderbit ein echter Frischekick. Mit der KI-gestützten Chrome Extension von Thunderbit scrapst, strukturierst und exportierst du Daten in Minuten statt Tagen. Kein Code, keine Selektoren, kein Frust.
Was ist also der richtige Ansatz? Verfügt dein Team über Engineering-Power und besondere Anforderungen, dann tauch ins Node.js-Toolset ein. Willst du Geschwindigkeit, Einfachheit und die Freiheit, dich auf Erkenntnisse statt auf Infrastruktur zu konzentrieren, probier Thunderbit aus. So oder so: Das Web ist deine Datenbank – hol dir die Daten.
Und falls du mal feststeckst, denk daran: Selbst die besten Scraper haben mit einer leeren Seite und einer starken Tasse Kaffee angefangen. Viel Erfolg beim Scraping.
Du möchtest mehr über KI-gestütztes Scraping erfahren oder Thunderbit in Aktion sehen?
- Offizielle Thunderbit-Website
- Thunderbit Chrome Extension herunterladen
- Thunderbit Blog
- Wie du jede Website mit KI scrapst
- Was ist Data Scraping und wie funktioniert es 2025
Wenn du Fragen, Geschichten oder deine schlimmsten Scraping-Horrorstorys hast, schreib sie in die Kommentare oder melde dich direkt bei mir. Ich höre gern, wie Menschen das Web in ihren eigenen Daten-Spielplatz verwandeln.
Bleib neugierig, bleib koffeiniert und scrappe klüger – nicht härter.
Thunderbit Chrome Extension herunterladen
KI-Web-Scraper testen Get Started Free
FAQ:
1. Warum sollte man 2025 JavaScript und Node.js für Web-Scraping verwenden?
Weil die meisten modernen Websites mit JavaScript gebaut sind. Node.js ist schnell, gut für asynchrone Abläufe geeignet und bietet ein reiches Ökosystem (z. B. Axios, Cheerio, Puppeteer), das alles von einfachen Abrufen bis hin zum Scraping dynamischer Inhalte im großen Maßstab unterstützt.
2. Wie sieht der typische Workflow für das Scrapen einer Website mit Node.js aus?
Er sieht meistens so aus:
Anfrage → Antwort verarbeiten → (optionale JS-Ausführung) → HTML parsen → Daten extrahieren → Speichern oder Exportieren
Jeder Schritt kann von spezialisierten Tools wie axios, cheerio oder puppeteer übernommen werden.
3. Wie scrapt man dynamische, per JavaScript gerenderte Seiten?
Verwende Headless-Browser wie Puppeteer oder Playwright. Sie laden die komplette Seite inklusive JavaScript und machen es möglich, das zu scrapen, was Nutzer tatsächlich sehen.
4. Was sind die größten Herausforderungen beim klassischen Scraping?
- Änderungen an der Website-Struktur
- Anti-Bot-Erkennung
- Ressourcenverbrauch durch Browser
- Manuelle Datenbereinigung
- Hoher Wartungsaufwand über die Zeit
Das macht Scraping in großem Maßstab oder ohne Entwicklerunterstützung schwer dauerhaft betreibbar.
5. Wann sollte ich statt Code etwas wie Thunderbit verwenden?
Nutze Thunderbit, wenn du Geschwindigkeit und Einfachheit brauchst und keinen Code schreiben oder pflegen willst. Es ist ideal für Teams aus Vertrieb, Marketing oder Research, die Daten schnell extrahieren und strukturieren möchten – besonders von komplexen oder mehrseitigen Websites.




