Ich erinnere mich noch genau an meinen ersten Versuch, Produktdaten von einer Webseite zu ziehen. Vor mir eine Seite voller Laufschuhe – und ich dachte mir: „Wie schwer kann es schon sein, all die Namen und Preise in eine Tabelle zu bringen?“ Ein paar Stunden später war ich mitten in JavaScript-Fehlermeldungen, unübersichtlichen Selektoren und mein Respekt für alle, die je einen Web-Scraper selbst gebaut haben, ist ordentlich gewachsen.
Falls du dich in dieser Situation wiedererkennst – vielleicht bist du im Vertrieb, E-Commerce oder in der operativen Abteilung unterwegs und willst einfach aktuelle Daten für bessere Entscheidungen sammeln – dann bist du definitiv nicht allein. Die Nachfrage nach Web-Scraping ist in den letzten Jahren regelrecht durch die Decke gegangen. Der weltweite und wird sich bis 2030 voraussichtlich verdoppeln. Das Problem: Die meisten klassischen Scraping-Tools setzen technisches Know-how voraus. Deshalb zeige ich dir heute zwei Wege: Einmal den klassischen, codebasierten Ansatz mit Cypress – und eine schnelle, KI-gestützte No-Code-Lösung mit . Als Beispiel nehmen wir die .
Egal, ob du als Entwickler deine JavaScript-Skills ausbauen willst oder als Business-Anwender lieber einen großen Bogen um Code machst – mit dieser Anleitung kommst du an die Daten, die du brauchst, ohne dabei den Kopf (oder das Wochenende) zu verlieren.
Was ist Web Scraping und warum ist es für Unternehmen wichtig?
Kurz gesagt: Web Scraping heißt, dass du Daten automatisiert von Webseiten abgreifst. Statt Produktnamen, Preise oder Kontaktdaten mühsam per Hand zu kopieren, übernimmt eine Software diese Arbeit für dich.
Warum ist das für Unternehmen so ein großes Thema? Daten sind das neue Gold (oder Hafermilch – je nach Geschmack). Firmen aus Vertrieb, E-Commerce und Operations nutzen Web Scraping, um:
- Leads zu generieren, indem sie Kontaktdaten aus Verzeichnissen oder sozialen Netzwerken sammeln.
- Preise und Trends der Konkurrenz im Blick zu behalten – etwa .
- Kundenmeinungen zu analysieren, indem Bewertungen und Rezensionen eingesammelt werden.
- Repetitive Recherche zu automatisieren, die sonst Stunden oder Tage fressen würde.
Und der Nutzen ist messbar: sagen, dass öffentlich verfügbare Webdaten ihnen helfen, schneller und präziser zu entscheiden. Kurz gesagt: Wer kein Web Scraping nutzt, lässt wertvolle Erkenntnisse und Umsatzpotenzial liegen.
Cypress vorgestellt: Ein beliebtes Tool für Web Scraping
Kommen wir zu den Tools. Cypress ist ein Open-Source-Framework, das ursprünglich für End-to-End-Tests von Webanwendungen entwickelt wurde. Stell dir vor, ein Roboter klickt Buttons, füllt Formulare aus und prüft, ob deine Website so läuft, wie sie soll. Der Clou: Da Cypress im echten Browser läuft und mit JavaScript-lastigen Seiten umgehen kann, eignet es sich auch super (wenn auch etwas unkonventionell) fürs Web Scraping.
Wie schlägt sich Cypress im Vergleich zu anderen Scraping-Tools, zum Beispiel denen auf Python-Basis (wie BeautifulSoup oder Scrapy)? Hier ein schneller Überblick:
- Cypress: Perfekt für dynamische, JavaScript-gesteuerte Inhalte. Du solltest JavaScript und Node.js beherrschen. Sehr flexibel und leistungsstark, aber klar ein Tool für Entwickler.
- Python-Scraper: Tools wie BeautifulSoup oder Scrapy sind für das Durchsuchen großer Datenmengen und statisches HTML optimiert. Sie bieten ein riesiges Ökosystem, tun sich aber schwer mit Seiten, die erst im Browser Inhalte nachladen.
Wenn du JavaScript oder Softwaretests kennst, ist Cypress ein überraschend effektives Werkzeug zum Scrapen. Aber falls du mit geschweiften Klammern und Semikolons nichts anfangen kannst – keine Sorge, gleich kommt die No-Code-Alternative.
Schritt-für-Schritt: Web Scraping mit Cypress (am Beispiel Adidas Herren-Laufschuhe)
Packen wir’s an und bauen einen Cypress-Scraper für die . Ziel: Produktnamen, Preise, Bilder und Links sauber in eine Datei exportieren.
1. Cypress-Umgebung einrichten
Zuerst brauchst du und npm. Dann öffnest du das Terminal und gibst ein:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-devDamit legst du ein neues Projekt an und installierst Cypress lokal. Zum Starten von Cypress:
1npx cypress openCypress erstellt ein cypress/-Verzeichnis mit Beispieltests. Die kannst du löschen und stattdessen eine eigene Datei anlegen, z. B. cypress/e2e/adidas-scraper.cy.js.
2. Website untersuchen und zu extrahierende Daten identifizieren
Jetzt wird’s detektivisch: Öffne die im Browser, mach einen Rechtsklick auf ein Produkt und wähle „Untersuchen“. Du siehst, dass jedes Produkt in einer Karte steckt, mit Elementen für Name, Preis, Bild und Link.
Zum Beispiel:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>Achte auf Klassennamen wie .gl-price für Preise und suche nach wiederkehrenden Mustern im HTML. Hier sagst du Cypress, was es abgreifen soll.
3. Cypress-Code zum Extrahieren der Daten schreiben
Ein Beispielskript für den Einstieg:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});Was passiert hier?
cy.visit()lädt die Seite.cy.get()wählt alle Produktlinks mit Adidas-typischem URL-Muster aus..each()geht jedes Produkt durch und sammelt Name, Preis, Bild und Link.- Die Daten werden in ein Array geschrieben und als JSON-Datei gespeichert.
Die Selektoren musst du ggf. anpassen, falls Adidas die Seite ändert – aber das Grundprinzip bleibt gleich.
4. Exportieren und Weiterverarbeiten der gesammelten Daten
Nach dem Ausführen des Skripts (über die Cypress-Oberfläche oder npx cypress run) findest du im Ordner cypress/output/adidas_products.json eine Liste mit Produktobjekten wie:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]Von hier aus kannst du die Daten in CSV umwandeln, in Excel analysieren oder in ein BI-Tool importieren. Wer mag, kann den Prozess sogar automatisieren, um z. B. täglich Preise zu überwachen.
Typische Herausforderungen beim Web Scraping mit Cypress
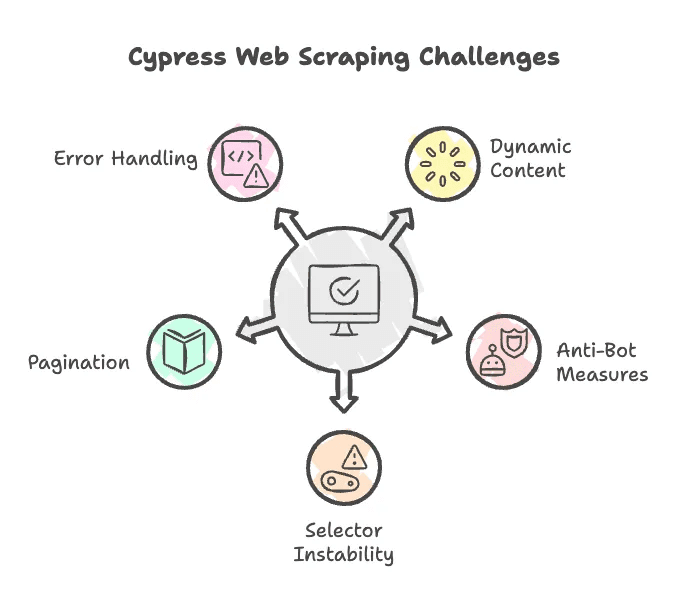
Ganz ehrlich: Web Scraping läuft selten komplett reibungslos. Hier ein paar Stolpersteine, die bei Cypress auftreten können – und Tipps, wie du sie umgehst:
- JavaScript-geladene Inhalte: Cypress kommt mit dynamischen Seiten gut klar, aber manchmal musst du auf das Laden von Elementen warten oder die Seite scrollen, um Lazy Loading auszulösen. Nutze
cy.wait()oder Scroll-Befehle. - Bot-Schutz: Manche Seiten blockieren Bots, z. B. durch User-Agent-Prüfung oder Rate-Limiting. Cypress läuft zwar im echten Browser, aber bei hartnäckigen Blockaden helfen nur fortgeschrittene Tricks wie Proxy-Wechsel oder Header-Spoofing.
- Instabile Selektoren: Ändert Adidas das HTML oder die Klassennamen, funktioniert dein Skript nicht mehr. Halte die Selektoren aktuell.
- Paginierung: Viele Produktseiten haben mehrere Seiten. Du musst also Logik einbauen, um „Weiter“-Buttons zu klicken und alle Ergebnisse zu sammeln.
- Fehlerbehandlung: Cypress ist auf Tests ausgelegt und bricht bei Fehlern oft ab. Baue Prüfungen ein, um fehlende Elemente abzufangen.
Falls du das Gefühl hast, für eine einfache Produktliste ein Informatikstudium zu brauchen – keine Sorge, genau dafür gibt es Thunderbit.
Zu kompliziert? Mit Thunderbit in 2 Klicks zum Web Scraping
Du willst dich nicht mit Node.js, Selektoren oder JavaScript-Fehlersuche herumärgern? Dann ist , unsere KI-basierte Web-Scraper-Chrome-Erweiterung, genau das Richtige. Entwickelt für Business-Anwender, die einfach nur Daten brauchen – ohne Code, ohne Setup, ohne Stress.
Das macht Thunderbit besonders:
- Kein Coding, keine Selektoren: Einfach Seite öffnen, klicken, und die KI erledigt den Rest.
- Ein Template, viele Seiten: Thunderbits KI erkennt verschiedene Layouts automatisch – du musst nicht für jede Seite neu konfigurieren.
- Browser- und Cloud-Scraping: Wähle den Modus, der zu deinem Tempo und Genauigkeitsbedarf passt.
- Paginierung und Unterseiten inklusive: Thunderbit klickt sich durch mehrere Seiten und kann sogar Produktdetailseiten besuchen, um deine Daten zu vervollständigen.
- Kostenloser Export: Lade deine Daten direkt in Excel, Google Sheets, Airtable oder Notion – ohne versteckte Kosten.
So funktioniert das Scraping der Adidas-Seite mit Thunderbit.
Schritt-für-Schritt: Web Scraping mit Thunderbit (Adidas-Beispiel)
1. Thunderbit Chrome-Erweiterung installieren
Installiere zuerst . Das dauert weniger als eine Minute – schneller als ich morgens meine Kaffeetasse finde.
Registriere dich kostenlos – Thunderbit bietet eine Gratis-Testphase (10 Seiten) und einen Free-Plan (6 Seiten pro Monat), damit du direkt echte Aufgaben ausprobieren kannst, ohne Kreditkarte.
2. Daten mit KI-Feldvorschlägen extrahieren
- Öffne die .
- Klicke auf das Thunderbit-Icon im Browser. Die Seitenleiste öffnet sich.
- Wähle „KI-Felder vorschlagen“. Thunderbits KI scannt die Seite und erkennt automatisch Produktname, Preis, Bild und Link. Du siehst eine Vorschau-Tabelle mit den ersten Zeilen.
- Spalten anpassen? Kein Problem – du kannst sie umbenennen oder neue Felder hinzufügen. Wer es genauer will, kann Thunderbit sogar per natürlicher Sprache anweisen, z. B. „extrahiere auch die Anzahl der verfügbaren Farben“.
- Klicke auf „Scrapen“. Thunderbit sammelt alle Daten, klickt sich bei Bedarf durch mehrere Seiten und kann mit der Subpage-Funktion auch Details von Produktseiten ergänzen.
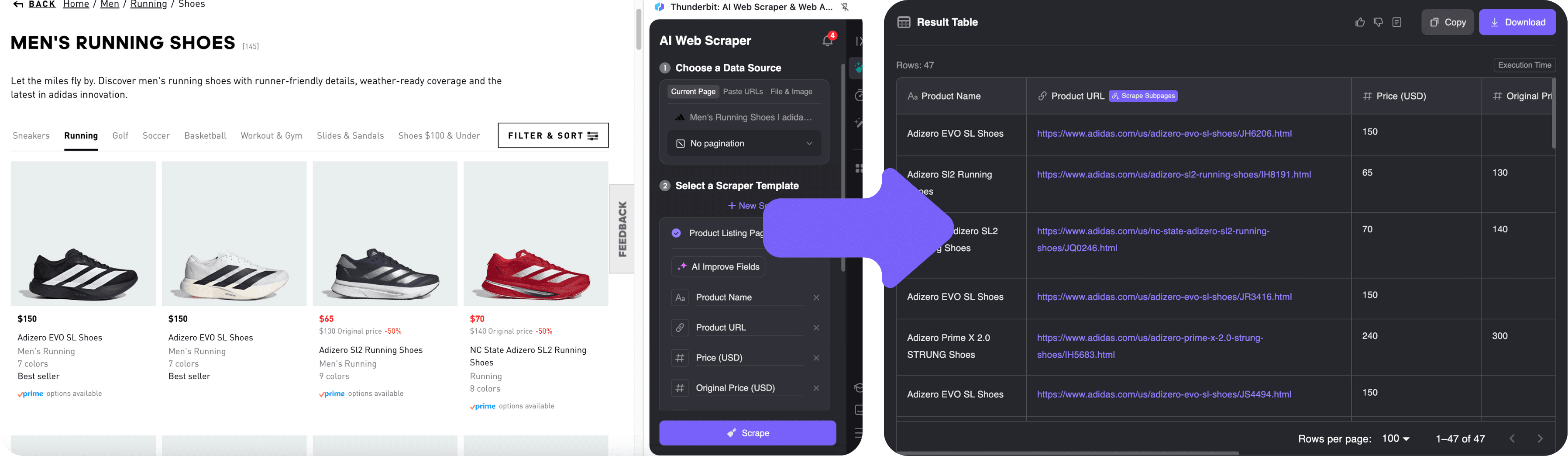
3. Daten exportieren und weiterverwenden
Nach dem Scraping prüfst du die Tabelle in der Thunderbit-Seitenleiste. Du kannst:
- Mit einem Klick nach Excel, Google Sheets, Airtable oder Notion exportieren
- Als CSV oder JSON herunterladen
- Bilder, E-Mails, Telefonnummern und mehr exportieren – Thunderbit unterstützt alle gängigen Datentypen.
Und ja, der Export ist komplett kostenlos. Keine bösen Überraschungen.
Weitere Tipps findest du in unserem oder im mit vielen weiteren Scraping-Anleitungen.
Cypress vs. Thunderbit: Welches Web Scraping Tool passt zu dir?
Hier der direkte Vergleich zwischen Cypress und Thunderbit:
| Aspekt | Cypress (Code-Scraper) | Thunderbit (No-Code KI-Web-Scraper) |
|---|---|---|
| Einrichtungsaufwand | Erfordert Node.js, npm und JavaScript-Kenntnisse. Für Nicht-Entwickler aufwendig. | Chrome-Erweiterung installieren, einloggen – in wenigen Minuten startklar. Kein Coding nötig. |
| Technische Kenntnisse | JavaScript und DOM/CSS-Selektoren sind Pflicht. Hohe Einstiegshürde für Laien. | Kein Coding erforderlich. Natürliche Sprache und Point-and-Click-Bedienung. |
| Geschwindigkeit | Skripte schreiben und debuggen kann Stunden dauern, besonders bei komplexen Seiten oder Paginierung. | Scraping in wenigen Klicks starten. Paginierung und Unterseiten werden automatisch gehandhabt. |
| Flexibilität | Extrem flexibel – beliebige Logik, Logins, Captchas, API-Integration möglich. | Für Standardmuster optimiert. KI deckt die meisten Seiten ab, sehr spezielle Workflows erfordern ggf. manuelle Anpassung. |
| Robustheit bei Änderungen | Skripte sind anfällig – ändert sich das HTML, muss der Code angepasst werden. | Robuster – KI passt sich kleinen Layout-Änderungen an. Thunderbit wird laufend weiterentwickelt. |
| Skalierbarkeit | Mittlere Datenmengen möglich, browserbasiertes Scraping ist bei großen Volumen langsamer. | Cloud-Scraping kann hunderte Seiten verarbeiten. Creditsystem sorgt für planbare Nutzung im Business. |
| Ideal für | Entwickler oder technisch versierte Nutzer, die Präzision und individuelle Logik brauchen. Perfekt für einmalige Datensammlungen oder komplexe Workflows. | Business-Anwender, die schnell und ohne Code wiederkehrende Aufgaben wie Preisüberwachung, Lead-Generierung oder das Extrahieren von Listen erledigen wollen. Ideal für Prototyping und Standardseiten im E-Commerce, Verzeichnisse oder Bewertungsportale. |
Kurz gesagt: Cypress bietet maximale Kontrolle, Thunderbit maximale Einfachheit und Geschwindigkeit. Entwickler, die gerne tüfteln, werden Cypress lieben. Wer einfach nur schnell an Daten kommen will (und vielleicht noch eine Deadline im Nacken hat), ist mit Thunderbit bestens beraten.
Fazit: So findest du den besten Web Scraping Ansatz für dich
- Web Scraping ist heute unverzichtbar – egal ob du Wettbewerber beobachtest, Leads generierst oder Markttrends analysierst.
- Cypress ist ein mächtiges, flexibles Tool für Entwickler, die eigene Scraper programmieren wollen. Perfekt für dynamische Seiten und individuelle Workflows, aber mit Lernkurve und Wartungsaufwand.
- Thunderbit richtet sich an alle anderen: Die macht Scraping so einfach wie zwei Klicks – ohne Code, ohne Setup, ohne Kopfschmerzen. Paginierung, Unterseiten und Export zu deinen Lieblingstools sind inklusive und kostenlos.
- Cypress ist die richtige Wahl, wenn du maximale Flexibilität brauchst und dich mit Code wohlfühlst.
- Thunderbit ist ideal, wenn du Zeit sparen, technische Hürden vermeiden und schnell saubere Daten willst – besonders in Vertrieb, E-Commerce, Marketing oder Operations.
Neugierig auf mehr? Im findest du Anleitungen zum , und vieles mehr.
Und falls du mal wieder vor einer Seite voller Laufschuhe sitzt und dich fragst, wie du all diese Daten in eine Tabelle bekommst – denk dran: Es gibt Lösungen. Viel Erfolg beim Scrapen!
Häufige Fragen (FAQ)
1. Was ist Cypress und wie kann man es fürs Web Scraping nutzen?
Cypress ist ein JavaScript-basiertes Test-Tool, das mit dynamischen Webseiten interagieren kann – ideal, um Inhalte zu extrahieren, die erst im Browser geladen werden.
2. Welche Herausforderungen gibt es beim Scraping mit Cypress?
Typische Probleme sind sich ändernde HTML-Strukturen, Lazy Loading, Bot-Schutzmechanismen sowie die Handhabung von Paginierung oder fehlenden Elementen auf komplexen Seiten.
3. Gibt es eine einfachere Möglichkeit, Webseiten ohne Programmierung zu scrapen?
Ja, Thunderbit ist eine KI-gestützte Chrome-Erweiterung, mit der du Daten in wenigen Klicks extrahierst – ganz ohne Code, Setup oder Selektoren.
Mehr erfahren: