

Ein Terminal öffnen, einen einzigen Befehl eintippen und zusehen, wie rohe Webdaten hereinströmen – das hat einen ganz eigenen Reiz, fast so, als hätte man kurz hinter die Kulissen des Netzes geblickt. Für Entwickler und technische Power-User ist cURL genau dafür das Werkzeug der Wahl: ein unscheinbares Kommandozeilen-Tool, das still und leise auf Milliarden von Geräten läuft, vom Cloud-Server bis zum vernetzten Kühlschrank. Und selbst 2026, mit all den schicken No-Code- und KI-Scraping-Tools, bleibt Web-Scraping mit cURL die erste Wahl für alle, denen es auf Tempo, Kontrolle und Skriptbarkeit ankommt.
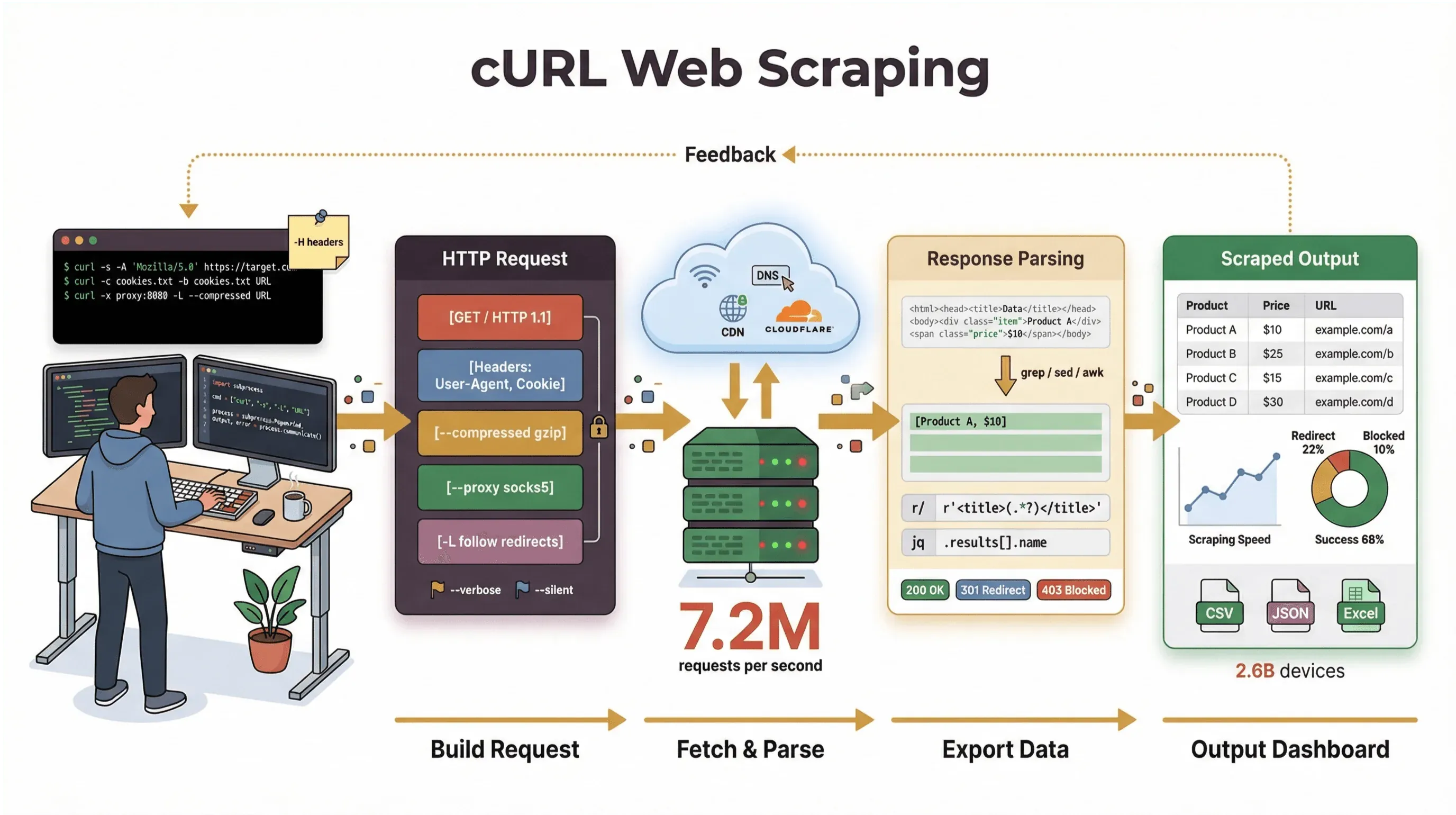 Ich baue seit Jahren Automatisierungstools und habe Teams im Umgang mit Webdaten unterstützt. Trotzdem greife ich immer noch zu cURL, wenn ich eine Seite abrufen, eine API debuggen oder einen Scraping-Workflow prototypisch zusammenstecken will. In diesem Leitfaden gehe ich mit dir Schritt für Schritt durchs Web-Scraping mit cURL, von den Grundlagen bis zu den Profi-Kniffen, mit echten Befehlsbeispielen, praxisnahen Tipps und einem klaren Blick darauf, wo cURL brilliert und wo es an Grenzen stößt. Und falls du eher ein Business-User bist und die Kommandozeile lieber meidest, zeige ich dir, wie dich Thunderbit, unser KI-gestützter Web-Scraper, in zwei Klicks von „Ich brauche diese Daten" zu „Hier ist meine Tabelle" bringt – ganz ohne Code.
Ich baue seit Jahren Automatisierungstools und habe Teams im Umgang mit Webdaten unterstützt. Trotzdem greife ich immer noch zu cURL, wenn ich eine Seite abrufen, eine API debuggen oder einen Scraping-Workflow prototypisch zusammenstecken will. In diesem Leitfaden gehe ich mit dir Schritt für Schritt durchs Web-Scraping mit cURL, von den Grundlagen bis zu den Profi-Kniffen, mit echten Befehlsbeispielen, praxisnahen Tipps und einem klaren Blick darauf, wo cURL brilliert und wo es an Grenzen stößt. Und falls du eher ein Business-User bist und die Kommandozeile lieber meidest, zeige ich dir, wie dich Thunderbit, unser KI-gestützter Web-Scraper, in zwei Klicks von „Ich brauche diese Daten" zu „Hier ist meine Tabelle" bringt – ganz ohne Code.
Im Folgenden geht es darum, warum cURL 2026 fürs Web-Scraping noch immer relevant ist, wie du es wirksam einsetzt und wann der Moment kommt, zu einem noch stärkeren Tool zu wechseln.
Was ist cURL? Die Grundlage von Web-Scraping mit cURL
Im Kern ist cURL ein Kommandozeilen-Tool und eine Library, um Daten per URL zu übertragen. Es existiert seit fast 30 Jahren (ja, wirklich) und steckt praktisch überall – fest verbaut in Betriebssystemen, als Antrieb für Skripte und unauffällig im Einsatz bei Datenübertragungen auf mehr als zwanzig Milliarden Installationen. Wenn du jemals schnell eine Webseite abgerufen, eine API getestet oder eine Datei heruntergeladen hast, war mit hoher Wahrscheinlichkeit cURL im Spiel.
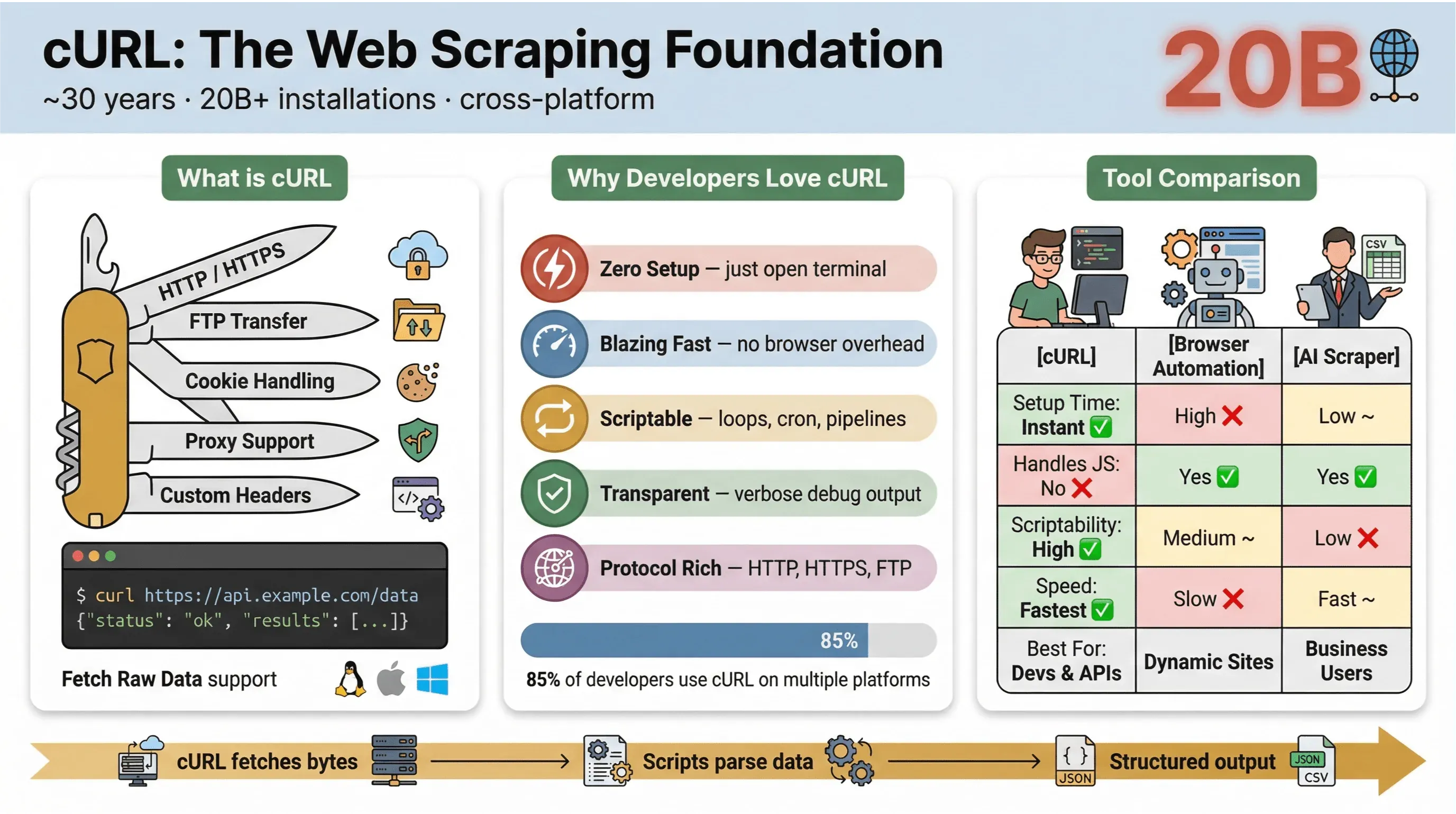 Das macht cURL fürs Web-Scraping so beliebt:
Das macht cURL fürs Web-Scraping so beliebt:
- Leichtgewichtig und plattformübergreifend: Läuft unter Linux, macOS, Windows und sogar auf Embedded-Geräten.
- Protokollunterstützung: Unterstützt HTTP, HTTPS, FTP und mehr.
- Skriptfähig: Perfekt für Automatisierung, Cron-Jobs und Glue Code.
- Keine Benutzerinteraktion nötig: Für den nicht-interaktiven Einsatz gemacht – ideal für Batch-Jobs und Pipelines.
Eines sollte aber klar sein: cURLs eigentliche Aufgabe ist das Abrufen von Rohdaten – HTML, JSON, Bilder, was auch immer. Es parst, rendert oder strukturiert diese Daten nicht für dich. Sieh cURL als den „ersten Kilometer" des Web-Scrapings: Es liefert dir die Bytes, doch für strukturierte Informationen brauchst du weitere Tools, etwa Python-Skripte, grep/sed/awk oder einen KI-Web-Scraper.
Die offizielle Dokumentation findest du im cURL HTTP-Scripting-Guide.
Warum cURL fürs Web-Scraping verwenden? (Tutorial: Web-Scraping mit cURL)
Warum kommen Entwickler und technische Nutzer trotz all der neuen Tools immer wieder auf cURL fürs Web-Scraping zurück? Das macht cURL so stark:
- Minimaler Aufwand: Keine Installation, keine Abhängigkeiten – Terminal öffnen und loslegen.
- Geschwindigkeit: Daten sofort abrufen, ohne auf einen Browser-Load zu warten.
- Skriptfähigkeit: URLs bequem in Schleifen abarbeiten, Requests automatisieren und Befehle verketten.
- Protokoll- und Feature-Support: Cookies, Proxies, Redirects, eigene Header und mehr.
- Transparenz: Mit ausführlichen Debug-Ausgaben genau nachvollziehen, was passiert.
In der cURL-Benutzerumfrage 2025 gaben 85,7 % der Befragten an, das cURL-Kommandozeilen-Tool zu nutzen, und 96,2 % sagten, sie verwendeten es unter Linux – dort ist cURL mit großem Abstand am weitesten verbreitet.
--- Es bleibt das Allzweckwerkzeug für HTTP-Requests, schnelle Datenabrufe und Fehlersuche.
Hier ein schneller Vergleich von cURL mit anderen Scraping-Methoden:
| Funktion | cURL | Browser-Automatisierung (z. B. Selenium) | KI-Web-Scraper (z. B. Thunderbit) |
|---|---|---|---|
| Einrichtungszeit | Sofort | Hoch | Niedrig |
| Skriptfähigkeit | Hoch | Mittel | Niedrig (kein Code nötig) |
| JavaScript-Unterstützung | Nein | Ja | Ja (Thunderbit: über den Browser) |
| Cookie-/Sitzungs-Support | Manuell | Automatisch | Automatisch |
| Datenstrukturierung | Manuell (später parsen) | Manuell (später parsen) | KI-/Vorlagenbasiert |
| Am besten geeignet für | Entwickler, schnelle Abrufe | Komplexe, dynamische Websites | Business-User, strukturierter Export |
Für schnelle, skriptfähige Datenabrufe ist cURL kaum zu schlagen, besonders bei statischen Seiten, APIs oder wenn du einfache Workflows automatisieren willst. Sobald du aber komplexes HTML parsen, JavaScript verarbeiten oder strukturierte Daten exportieren musst, brauchst du etwas Spezialisierteres.
Erste Schritte: Grundlegende Beispiele für Web-Scraping mit cURL
Jetzt wird es praktisch. So setzt du cURL Schritt für Schritt für grundlegende Web-Scraping-Aufgaben ein.
Rohes HTML mit cURL abrufen
Der einfachste Fall: das HTML einer Webseite abrufen.
curl https://books.toscrape.com/
Dieser Befehl ruft die Startseite von Books to Scrape ab, einer öffentlichen Demo-Website fürs Web-Scraping. In deinem Terminal erscheint die rohe HTML-Ausgabe – achte auf Tags wie <title> oder Textstellen wie „In stock".
Ausgabe in eine Datei speichern
Du willst das HTML später parsen? Dann verwende das -o-Flag:
curl -o page.html https://books.toscrape.com/
Jetzt liegt eine Datei page.html mit dem kompletten HTML-Inhalt vor. Ideal für die weitere Analyse oder das Parsen mit anderen Tools.
POST-Requests mit cURL senden
Du musst ein Formular abschicken oder mit einer API interagieren? Dann nutze das -d-Flag für POST-Requests. Hier ein Beispiel mit httpbin, einer Website für HTTP-Tests:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Du bekommst eine JSON-Antwort, die deine gesendeten Daten zurückspiegelt – ideal zum Testen und Prototyping.
Header prüfen und debuggen
Manchmal willst du die Response-Header sehen oder den Request debuggen:
-
Nur Header (HEAD-Request):
curl -I https://books.toscrape.com/ -
Header zusammen mit dem Body anzeigen:
curl -i https://httpbin.org/get -
Ausführliche Debug-Ausgabe:
curl -v https://books.toscrape.com/
Diese Flags zeigen dir, was unter der Oberfläche vor sich geht – unverzichtbar für die Fehlersuche.
Hier eine kurze Referenztabelle zu diesen Befehlen:
| Aufgabe | Befehlsbeispiel | Hinweise |
|---|---|---|
| HTML abrufen | curl URL | Gibt HTML im Terminal aus |
| In Datei speichern | curl -o datei.html URL | Schreibt die Ausgabe in eine Datei |
| Header prüfen | curl -I URL oder curl -i URL | -I nur für HEAD, -i inklusive Header im Body |
| Formulardaten per POST senden | curl -d "a=1&b=2" URL | Sendet formularcodierte Daten |
| Request/Response debuggen | curl -v URL | Zeigt detaillierte Infos zu Request und Response |
Weitere Beispiele findest du in der offiziellen cURL-Scripting-Dokumentation.
Eine Stufe höher: Fortgeschrittenes Web-Scraping mit cURL (web-scraping-with-curl)
Sobald du die Grundlagen beherrschst, öffnet cURL dir eine ganze Welt fortgeschrittener Funktionen für komplexere Scraping-Aufgaben.
Cookies und Sitzungen handhaben
Viele Websites brauchen Cookies, um Login-Sitzungen aufrechtzuerhalten oder Nutzer zu verfolgen. Mit cURL speicherst und verwendest du Cookies über mehrere Requests hinweg:
# Cookies nach dem Login speichern
curl -c cookies.txt https://example.com/login
# Cookies für nachfolgende Requests verwenden
curl -b cookies.txt https://example.com/account
So bildest du Browser-Sessions nach und kommst an Seiten hinter Login-Schranken – solange dir keine JavaScript-Hürde dazwischenfunkt.
User-Agent und eigene Header vortäuschen
Manche Websites liefern je nach User-Agent oder Header unterschiedliche Inhalte aus. Standardmäßig meldet sich cURL als „curl/VERSION", was zu Sperren oder abweichendem Inhalt führen kann. Um einen Browser zu imitieren:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
Du kannst auch eigene Header setzen, etwa für die Spracheinstellung:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
So erhältst du denselben Inhalt, den auch ein echter Browser angezeigt bekäme.
Proxies fürs Web-Scraping verwenden
Du musst deine Requests über einen Proxy leiten, etwa für Geo-Tests oder um IP-Sperren auszuweichen? Dann nutze das -x-Flag:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Achte nur darauf, Proxies verantwortungsvoll und im Rahmen der Nutzungsbedingungen der jeweiligen Website einzusetzen.
Mehrseitiges Scraping automatisieren
Du willst mehrere Seiten scrapen, etwa paginierte Produktlisten? Dann genügt eine einfache Shell-Schleife:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Das holt die Seiten 2 bis 5 des Books-to-Scrape-Katalogs und legt jede in einer eigenen Datei ab. (Seite 1 ist die Startseite.)
Grenzen von Web-Scraping mit cURL: Das solltest du wissen
So gern ich cURL auch nutze – ein Allheilmittel ist es nicht. Hier stößt es an seine Grenzen:
- Keine JavaScript-Ausführung: cURL kommt mit Seiten nicht zurecht, die JavaScript zum Rendern von Inhalten oder zum Lösen von Anti-Bot-Hürden brauchen (developers.cloudflare.com).
- Manuelles Parsen erforderlich: Du bekommst rohes HTML oder JSON, musst es aber selbst parsen – oft mit zusätzlichen Skripten oder Tools.
- Begrenztes Sitzungsmanagement: Komplexe Logins, Tokens oder mehrstufige Formulare werden schnell unhandlich.
- Keine eingebaute Datenstrukturierung: cURL macht aus Webseiten nicht von selbst Zeilen, Tabellen oder Tabellenkalkulationen.
- Anfällig für Anti-Bot-Erkennung: Viele Websites setzen inzwischen ausgefeilte Bot-Schutzmaßnahmen ein (JavaScript, Fingerprinting, CAPTCHAs), an denen cURL schlicht scheitert (datadome.co).
Hier eine kurze Vergleichstabelle:
| Einschränkung | Nur cURL | Moderne Scraping-Tools (z. B. Thunderbit) |
|---|---|---|
| JavaScript-Unterstützung | Nein | Ja |
| Datenstrukturierung | Manuell | Automatisch (KI/Vorlage) |
| Sitzungsverwaltung | Manuell | Automatisch |
| Umgehung von Bot-Schutz | Begrenzt | Fortgeschritten (browserbasiert/KI) |
| Benutzerfreundlichkeit | Technisch | Nicht-technisch |
Für statische Seiten und APIs ist cURL großartig. Bei allem Dynamischeren oder Geschützten lohnt sich der Griff zu einem mächtigeren Werkzeug im Tool-Stack.
Thunderbit vs. cURL: Der beste Web-Scraping-Ansatz für nicht-technische Nutzer
Kommen wir zu Thunderbit, unserer KI-gestützten Chrome-Erweiterung fürs Web-Scraping. Wenn du im Vertrieb, Marketing oder Operations arbeitest und Daten von einer Website einfach in Excel, Google Sheets oder Notion holen willst – ohne die Kommandozeile anzufassen – dann ist Thunderbit genau für dich gemacht.
So schlägt sich Thunderbit gegen cURL:
| Funktion | cURL | Thunderbit |
|---|---|---|
| Benutzeroberfläche | Kommandozeile | Point-and-Click (Chrome-Erweiterung) |
| KI-Feldvorschläge | Nein | Ja (KI liest die Seite und schlägt Spalten vor) |
| Umgang mit Paginierung/Unterseiten | Manuelles Skripting | Automatisch (KI erkennt und extrahiert) |
| Datenexport | Manuell (parsen + speichern) | Direkt nach Excel, Google Sheets, Notion, Airtable |
| JavaScript/geschützte Seiten | Nein | Ja (browserbasiertes Scraping) |
| Kein Code erforderlich | Nein (Skripting nötig) | Ja (für alle nutzbar) |
| Kostenloses Kontingent | Immer kostenlos | Kostenlos für bis zu 6 Seiten (10 mit Test-Boost) |
Bei Thunderbit öffnest du einfach die Erweiterung, klickst auf „KI-Felder vorschlagen" und überlässt der KI die Entscheidung, welche Daten extrahiert werden sollen. Tabellen, Listen, Produktdetails und sogar Unterseiten lassen sich automatisch ansteuern. Anschließend exportierst du die Daten direkt in deine bevorzugten Business-Tools – ohne Parsen, ohne Stress.
Thunderbit genießt das Vertrauen von über 100.000 Nutzern weltweit und ist besonders bei Vertriebs-, E-Commerce- und Immobilien-Teams gefragt, die schnell strukturierte Daten brauchen.
Thunderbit Chrome-Erweiterung fürs Web-Scraping ausprobieren
Du willst es ausprobieren? Lade die Chrome-Erweiterung hier herunter.
cURL und Thunderbit kombinieren: Flexible Web-Scraping-Strategien
Bist du technisch versiert, musst du dich gar nicht auf ein einziges Tool festlegen. Viele Teams nutzen cURL und Thunderbit nämlich nebeneinander, um maximal flexibel zu bleiben:
- Mit cURL prototypen: Nutze cURL, um Endpunkte schnell zu testen, Header zu prüfen und zu verstehen, wie eine Website reagiert.
- Mit Thunderbit skalieren: Sobald du strukturierte Daten, mehrseitiges Scraping oder einen wiederholbaren Workflow brauchst, wechselst du für Point-and-Click-Extraktion und direkte Exporte zu Thunderbit.
Hier ein Beispiel-Workflow für die Marktforschung:
- Hol dir mit cURL ein paar Seiten und prüfe die HTML-Struktur.
- Bestimme die gewünschten Datenfelder, etwa Produktnamen, Preise oder Bewertungen.
- Öffne Thunderbit, klicke auf „KI-Felder vorschlagen" und lass die KI den Scraper einrichten.
- Scrape alle Seiten, einschließlich Unterseiten oder paginierter Listen, und exportiere nach Google Sheets.
- Auswerten, teilen, nutzen – ganz ohne manuelles Parsen.
Hier eine kurze Entscheidungstabelle:
| Szenario | cURL verwenden | Thunderbit verwenden | Beide verwenden |
|---|---|---|---|
| Schneller Abruf einer API oder statischen Seite | ✅ | ||
| Strukturierte Daten in einer Tabelle brauchen | ✅ | ||
| Header/Cookies debuggen | ✅ | ||
| Dynamische/JS-lastige Seiten scrapen | ✅ | ||
| Einen wiederholbaren No-Code-Workflow bauen | ✅ | ||
| Prototypen und dann skalieren | ✅ | ✅ | Hybrider Workflow |
Typische Hürden und Stolpersteine beim Web-Scraping mit cURL
Bevor du mit cURL loslegst, lohnt ein Blick auf die realen Herausforderungen, die dir unterkommen können:
- Anti-Bot-Systeme: Viele Websites setzen inzwischen ausgefeilte Schutzmechanismen ein (JavaScript-Challenges, CAPTCHAs, Fingerprinting), die cURL nicht aushebeln kann (developers.cloudflare.com).
- Probleme mit der Datenqualität: HTML-Änderungen, fehlende Felder oder inkonsistente Layouts können deine Skripte aus dem Tritt bringen.
- Pflegeaufwand: Jedes Mal, wenn sich eine Website ändert, musst du deine Parsing-Logik nachziehen.
- Rechtliche und Compliance-Risiken: Prüfe vor jedem Scrape die Nutzungsbedingungen der Website, die robots.txt und die geltenden Gesetze. Nur weil Daten öffentlich sind, darfst du sie nicht automatisch frei verwenden (calawyers.org, polsinelli.com).
- Grenzen beim Skalieren: Für kleine Aufgaben ist cURL großartig, doch beim Scraping in großem Maßstab musst du Proxies, Rate Limits und Fehlerbehandlung selbst im Griff haben.
Tipps zur Fehlersuche und für die Compliance:
- Starte immer mit Seiten, für die du eine Erlaubnis hast, oder mit Demo-Seiten wie Books to Scrape.
- Beachte Rate Limits – überlastete Endpunkte sind keine gute Idee.
- Verzichte aufs Scrapen personenbezogener Daten, solange du keine rechtmäßige Grundlage dafür hast.
- Triffst du auf JavaScript- oder CAPTCHA-Hürden, wechsle zu einem browserbasierten Tool wie Thunderbit.
Schritt-für-Schritt-Zusammenfassung: Websites mit cURL scrapen
Hier deine Schnell-Checkliste fürs Web-Scraping mit cURL:
- Ziel-URL(s) bestimmen: Beginne mit einer statischen Seite oder einem API-Endpunkt.
- Seite abrufen:
curl URL - Ausgabe in Datei speichern:
curl -o file.html URL - Header prüfen/debuggen:
curl -I URL,curl -v URL - POST-Daten senden:
curl -d "a=1&b=2" URL - Cookies/Sitzungen handhaben:
curl -c cookies.txt ...,curl -b cookies.txt ... - Eigene Header/User-Agent setzen:
curl -A "..." -H "..." URL - Redirects folgen:
curl -L URL - Proxies verwenden (falls nötig):
curl -x proxy:port URL - Mehrseitiges Scraping automatisieren: Shell-Schleifen oder Skripte verwenden.
- Daten parsen und strukturieren: Bei Bedarf zusätzliche Tools/Skripte einsetzen.
- Für strukturiertes No-Code-Scraping oder dynamische Seiten zu Thunderbit wechseln.
Fazit und wichtigste Erkenntnisse: das richtige Web-Scraping-Tool wählen
Daten von jeder Website mit KI scrapen Get Started Free
Web-Scraping mit cURL bleibt 2026 eine starke Fähigkeit für technische Nutzer – gerade für schnelle Datenabrufe, Prototyping und Automatisierung. Tempo, Skriptfähigkeit und Allgegenwart machen cURL zum festen Bestandteil jedes Entwickler-Toolkits. Doch je dynamischer und geschützter das Web wird und je stärker Business-User strukturierte Daten ohne Code verlangen, desto mehr verschieben Tools wie Thunderbit die Grenzen des Möglichen.
Wichtigste Erkenntnisse:
- Nutze cURL für statische Seiten, APIs und schnelles Prototyping – vor allem, wenn du die volle Kontrolle willst.
- Wechsle zu Thunderbit (oder ähnlichen KI-Web-Scrapern), wenn du strukturierte Daten brauchst, dynamische/JavaScript-lastige Seiten verarbeiten musst oder einen No-Code-Workflow für Business-Anwender suchst.
- Kombiniere beides für maximale Flexibilität: mit cURL prototypen, mit Thunderbit skalieren und strukturieren.
- Scrape immer verantwortungsvoll – beachte die Nutzungsbedingungen, Rate Limits und rechtlichen Grenzen.
Neugierig, wie einfach Web-Scraping sein kann? Teste die kostenlose Chrome-Erweiterung von Thunderbit und erlebe KI-gestützte Datenextraktion selbst. Und wenn du tiefer einsteigen willst, schau im Thunderbit-Blog vorbei – dort warten weitere Tutorials, Tipps und Branchen-Insights. Das könnte dich auch interessieren:
- Wie man jede Website mit KI scrapt
- So scrapest du Website-Daten nach Excel
- Was ist Data Scraping und wie funktioniert es
Mit dem richtigen Werkzeug sind deine Daten am Ende sauber, strukturiert und nur einen Befehl oder Klick entfernt.
Thunderbit-Pläne für skalierbares Web-Scraping entdecken
FAQs
1. Kann cURL JavaScript-gerenderte Webseiten verarbeiten?
Nein, cURL führt kein JavaScript aus. Es ruft nur das rohe HTML ab, so wie es der Server ausliefert. Braucht eine Seite JavaScript, um Inhalte zu rendern oder Anti-Bot-Hürden zu lösen, kommt cURL nicht an die Daten heran. Greife in solchen Fällen zu browserbasierten Tools wie Thunderbit.
2. Wie speichere ich die cURL-Ausgabe direkt in einer Datei?
Verwende das -o-Flag: curl -o dateiname.html URL. Damit landet der Response-Body in einer Datei, statt im Terminal zu erscheinen.
3. Was ist der Unterschied zwischen cURL und Thunderbit beim Web-Scraping?
cURL ist ein Kommandozeilen-Tool zum Abrufen roher Webdaten – ideal für technische Nutzer und Automatisierung. Thunderbit ist eine KI-gestützte Chrome-Erweiterung für Business-User, die strukturierte Daten von jeder Website extrahieren, dynamische Seiten verarbeiten und direkt in Tools wie Excel oder Google Sheets exportieren wollen – ganz ohne Code.
4. Ist es legal, Websites mit cURL zu scrapen?
Das Scrapen öffentlicher Daten ist in den USA nach jüngeren Gerichtsurteilen im Allgemeinen erlaubt, doch prüfe immer die Nutzungsbedingungen der Website, die robots.txt und die geltenden Gesetze. Verzichte ohne Erlaubnis aufs Scrapen personenbezogener oder geschützter Daten und beachte Rate Limits sowie ethische Richtlinien (calawyers.org, polsinelli.com).
5. Wann sollte ich von cURL zu einem fortgeschritteneren Tool wie Thunderbit wechseln?
Sobald du dynamische/JavaScript-lastige Seiten scrapen musst, strukturierte Daten in einer Tabelle willst oder einen No-Code-Workflow bevorzugst, ist Thunderbit die bessere Wahl. Nutze cURL für schnelle, technische Aufgaben und Thunderbit für business-freundliche, wiederholbare Datenerfassung.
Weitere Web-Scraping-Tipps und Tutorials findest du im Thunderbit-Blog oder auf unserem YouTube-Kanal.
Thunderbit AI Web-Scraper ausprobieren Get Started Free




