
Seien wir ehrlich: Wenn du schon einmal versucht hast, an Geschäftsdaten zu kommen, bist du wahrscheinlich über die Debatte „Web Scraping vs. Data Mining“ gestolpert. Ich habe Teams erlebt, die sich darin festfahren: Die einen wollen jedes noch so kleine Detail aus dem Web ziehen, die anderen wollen daraus tiefere Erkenntnisse gewinnen. Am Ende sitzen alle auf dieselbe Tabelle und fragen sich: „Moment, was machen wir hier eigentlich?“ Wenn dir das bekannt vorkommt, bist du nicht allein.
Als jemand, der jahrelang SaaS- und Automatisierungstools gebaut hat und heute Mitgründer von ist, habe ich diese Verwirrung überall gesehen – vom Vertrieb bis in den Vorstand. Also lassen wir das Fachchinesisch kurz beiseite und werden konkret: Was ist der echte Unterschied zwischen Web Scraping und Data Mining, wer nutzt was, und – noch wichtiger – wie kannst du beides zusammen einsetzen, um für dein Team Ergebnisse zu erzielen?
Web Scraping vs. Data Mining: Schnelle Definitionen für vielbeschäftigte Teams
Fangen wir einfach an, ganz ohne Techniklexikon.
- Web Scraping: Dabei werden Daten von Websites gesammelt – man kann es sich als automatisiertes Kopieren und Einfügen von Informationen aus dem Web in eine Tabelle vorstellen. Web-Scraper scannen Webseiten, extrahieren bestimmte Informationen (z. B. Produktpreise, Firmennamen oder Artikel) und bringen sie in ein strukturiertes Format (Zeilen und Spalten). In dieser Phase wird noch nicht analysiert – es geht nur darum, die Rohdaten zu bekommen, die du brauchst.
- Data Mining: Hier beginnt die eigentliche Arbeit (okay, keine Magie, aber echter Mehrwert), nachdem du die Daten bereits hast. Data Mining bedeutet, Datensätze mit Statistik, Algorithmen oder KI zu analysieren, um Trends, Muster und Erkenntnisse sichtbar zu machen. Es ist so, als würdest du diese riesige Tabelle nehmen und herausfinden, was sie bedeutet: Kunden segmentieren, Umsatz prognostizieren oder Betrug erkennen.
Die Analogie, die ich immer verwende:
Web Scraping ist das Einsammeln der Zutaten im Supermarkt; Data Mining ist das Kochen daraus. Beides brauchst du, wenn aus dem Abendessen mehr werden soll als nur ein Haufen Lebensmittel.
Wer nutzt Web Scraping vs. Data Mining – und warum?
Hier wird es interessant. Der Unterschied liegt nicht nur bei „sammeln vs. analysieren“ – es geht auch darum, wer was tut und weshalb.
Wer nutzt Web Scraping?
Typische Nutzer:
- Vertriebsteams (Lead-Listen aufbauen, Kontaktdaten sammeln)
- Marketingteams (Marktanalysen, Wettbewerbsbeobachtung)
- Operations (Preisverfolgung, Einblicke in die Lieferkette)
- Forschungsteams (Immobilien, Finanzen usw.)
Ihr Ziel:
Schnell frische, externe Daten bekommen. Ob es darum geht, tausende Produktpreise abzurufen, LinkedIn nach Leads zu durchsuchen oder Wettbewerber-Launches zu beobachten – diese Teams brauchen aktuelle Informationen, um ihre täglichen Entscheidungen zu stützen (, ).
Wer nutzt Data Mining?
Typische Nutzer:
- Datenanalysten und Business-Intelligence-(BI)-Teams
- Data Scientists
- Produktmanager und Strategieteams
Ihr Ziel:
Bedeutung in den Daten finden. Diese Teams nehmen Rohdaten – egal ob sie aus dem Web gescrapt oder aus internen Systemen gezogen wurden – und suchen nach Mustern, Trends und umsetzbaren Erkenntnissen. Ihnen ist weniger wichtig, wie die Daten gesammelt wurden, sondern vor allem, was sie aussagen ().
Szenariotabelle: Wer macht was?
| Rolle | Beispiel für Web Scraping | Beispiel für Data Mining |
|---|---|---|
| Vertrieb | Geschäftsverzeichnisse nach Leads scrapen | Analysieren, welche Leads am besten konvertieren |
| Marketing | Produktlaunches von Wettbewerbern scrapen | Kunden nach Kaufverhalten segmentieren |
| Operations | Täglich Lieferantenpreise scrapen | Nachfrage prognostizieren, Lagerbestand optimieren |
| BI/Data Science | (scrapen meist nicht selbst) | Prognosemodelle erstellen, Trends finden |
| Produktmanagement | App-Store-Bewertungen als Feedback scrapen | Funktionslücken erkennen, Roadmap priorisieren |
Web Scraping: Websites in geschäftstaugliche Daten verwandeln
Seien wir ehrlich: Das Internet ist eine Goldgrube für Geschäftsdaten, aber der Großteil davon steckt in unübersichtlichen, unstrukturierten Webseiten fest. Web Scraping ist der Schlüssel, mit dem du diese Daten freischaltest und in etwas verwandelst, das dein Team wirklich nutzen kann.
Warum Web Scraping wichtig ist – besonders für nicht-technische Teams
- Spart Zeit: Keine Praktikanten mehr, die tagelang kopieren und einfügen. Ein Scraper kann tausende Datenpunkte in Minuten ziehen.
- Skaliert: Du willst täglich 50 Wettbewerber-Websites überwachen? Scraping macht es möglich.
- Hält dich aktuell: Erhalte Echtzeit-Updates zu Preisen, Lagerbestand oder Nachrichten – ganz ohne manuelle Arbeit.
Der größere Kontext: beziffert den Web-Scraping-Markt 2026 auf 1,17 Mrd. USD; bis 2031 soll er auf 2,23 Mrd. USD wachsen. Und laut einer im Bericht zitierten BrowserCat-Umfrage von 2024 nutzten bereits 65 % der Unternehmen Web Scraping, um KI- und Machine-Learning-Projekte zu speisen – genau der Teil des Workflows, der die Nutzung aus der IT in Vertriebs-, Marketing- und Ops-Teams trägt.
Praktische Anwendungsfälle
- Lead-Generierung: Öffentliche Verzeichnisse oder soziale Netzwerke nach Namen, E-Mails und Telefonnummern durchsuchen.
- Preisüberwachung: Preise oder Produktverfügbarkeiten von Wettbewerbern in Echtzeit verfolgen. Die Nutzung ist längst Mainstream – berichtet, dass inzwischen 81 % der US-Händler automatisiertes Price Scraping für dynamische Preisgestaltung einsetzen, gegenüber 34 % im Jahr 2020 (ursprünglich erhoben von Actowiz Solutions).
- Marktforschung: Online-Bewertungen bündeln, Social Media nach Stimmungen scrapen oder Nachrichtenseiten auf Trends überwachen.
- Datenanreicherung: Dein CRM mit frischen Informationen von Unternehmenswebsites oder LinkedIn ergänzen.
- Immobilien & Finanzen: Immobilienanzeigen, Finanznachrichten oder alternative Daten für Investment-Recherchen scrapen ().
Und hier liegt der eigentliche Punkt: Du musst heute kein Entwickler mehr sein. Ein wachsender Anteil neuer Scraping-Tools – Octoparse, Browse AI, Bardeen, Thunderbit – setzt standardmäßig auf Drag-and-Drop oder Point-and-Click statt auf einen separaten „Coder-Modus“. Genau das hat Scraping aus dem Engineering-Backlog an die Schreibtische von Vertrieb und Operations gebracht.
Wie Thunderbit Web Scraping für alle vereinfacht
Ich gebe zu: Als wir mit angefangen haben, war unser Ziel simpel: Web Scraping so einfach zu machen wie einen Praktikanten zu bitten, Daten zu kopieren und einzufügen – nur ist dieser „Praktikant“ ein KI-Agent, der nie schläft, nie meckert und sich nie von Katzenvideos ablenken lässt.
So schlägt Thunderbit die Brücke zwischen Datenerfassung und Geschäftsanalyse:
- KI-Felder vorschlagen: Klicke einfach auf „KI-Felder vorschlagen“, und Thunderbits KI scannt die Seite, empfiehlt die zu extrahierenden Datenfelder und schlägt Spaltennamen vor. Kein Herumfummeln mehr an HTML oder Selektoren – einfach auswählen, was du brauchst ().
- Unterseiten-Scraping: Du brauchst mehr Details von Unterseiten (z. B. Produktdetails oder Stellenbeschreibungen)? Thunderbit kann automatisch durchklicken, die Zusatzinformationen einsammeln und sie deinem Datensatz hinzufügen.
- Sofortiger Datenexport: Ein Klick genügt für den Export nach Excel, Google Sheets, Airtable, Notion oder als CSV/JSON. Keine versteckten Kosten, kein Aufwand – deine Daten sind sofort einsatzbereit.
- No-Code, Point-and-Click: Thunderbit läuft in deinem Browser. Du wählst aus, was du willst, und fertig. Selbst wenn du noch nie gescrapt hast, bist du in wenigen Minuten startklar.
- KI-gestützte Robustheit: Websites ändern sich ständig, aber Thunderbits KI passt sich vielen Layoutänderungen automatisch an. Weniger Wartung, weniger Frust.
- Geplantes Scraping & KI-Autofill: Plane Scrapes zeitgesteuert oder lass die KI Formulare und Logins für dich ausfüllen. Thunderbit verarbeitet sogar PDFs, Bilder, E-Mails und Telefonnummern mit nur einem Klick.
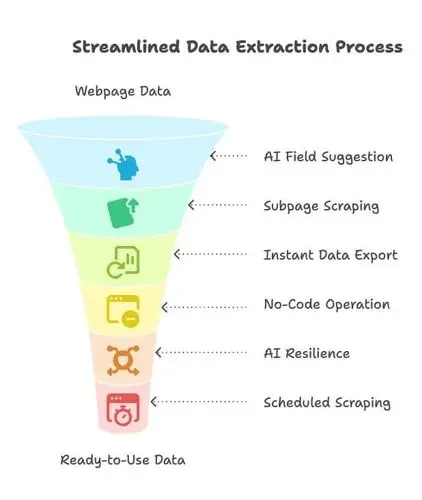
Kurz gesagt: Thunderbit schließt die Kompetenzlücke. Jetzt können Sales Ops, Marketing oder sogar dein CEO einen Scrape aufsetzen, ohne die IT anzurufen. Es ist die „Zwischenschicht“, die unstrukturierte Webdaten mit den Tools verbindet, die du tatsächlich für Analysen nutzt.
Du willst es in Aktion sehen? Schau dir unsere an oder stöbere in weiteren Anwendungsfällen auf dem .
Data Mining: Erkenntnisse aus deinen gesammelten Daten gewinnen
Okay, du hast also einen Berg an Daten gescrapt. Und jetzt? Hier kommt Data Mining ins Spiel.
Was ist Data Mining? Einfach erklärt
Data Mining ist der Prozess, große Datensätze zu analysieren, um verborgene Muster, Zusammenhänge oder Anomalien zu finden, die geschäftliche Erkenntnisse liefern können. Es geht darum, Rohdaten in umsetzbares Wissen zu verwandeln – etwa zu entdecken, dass Kunden, die Produkt A kaufen, auch oft Produkt B kaufen, oder dass bestimmte Verhaltensweisen auf ein hohes Abwanderungsrisiko hindeuten.
Häufige geschäftliche Ziele
- Trenderkennung & Prognosen: Verkaufstrends, Saisonalität oder Marktveränderungen erkennen – und vorhersagen, was als Nächstes kommt.
- Kundensegmentierung: Kunden nach Verhalten oder Demografie gruppieren, um gezieltes Marketing zu ermöglichen.
- Anomalieerkennung: Ausreißer finden, die auf Betrug, Risiken oder neue Chancen hindeuten könnten.
- Strategische Erkenntnisse: Mehrere Datensätze kombinieren (intern + gescrapt), um große Entscheidungen zu treffen – etwa den Eintritt in einen neuen Markt oder die Anpassung von Preisen.
Der Haken: Data Mining ist nur so gut wie die Daten, die du hineingibst. Das alte Sprichwort „Garbage in, garbage out“ trifft hier leider voll zu. Tatsächlich verbringen Analysten oft bis zu nur damit, Daten zu bereinigen und vorzubereiten, bevor sie sie überhaupt analysieren können.
Genau deshalb ist strukturiertes Web Scraping – wie Thunderbit es ausgibt – so wertvoll: Du bekommst einen sauberen, analysefertigen Datensatz, sodass deine Analysten direkt mit dem Wesentlichen loslegen können.
Web Scraping vs. Data Mining: Der direkte Vergleich
Stellen wir die beiden direkt gegenüber, damit du genau siehst, worin sie sich unterscheiden – und wo sie sich überschneiden.
| Aspekt | Web Scraping | Data Mining |
|---|---|---|
| Hauptzweck | Rohdaten von Websites sammeln (Datenextraktion) | Datensätze analysieren, um Muster und Erkenntnisse zu entdecken (Datenanalyse) |
| Typische Nutzer | Vertrieb, Marketing, Operations, Forschung (oft nicht-technische Fachleute) | Datenanalysten, BI-Teams, Data Scientists, Strategiemanager (analytische/technische Rollen) |
| Datenquellen | Webseiten, Online-Quellen, öffentliche Verzeichnisse, APIs | Strukturierte Datensätze: gescrapte Daten, interne Datenbanken, CSVs, Data Warehouses |
| Prozess & Tools | Crawling, Extraktion (No-Code-Tools wie Thunderbit, Browser-Erweiterungen) | Datenanalyse (BI-Tools, Python/R, SQL, Machine-Learning-Plattformen) |
| Ergebnis | Strukturierter Datensatz (CSV, Tabellenkalkulation, Datenbanktabelle) | Erkenntnisse, Berichte, Dashboards, Prognosemodelle |
| Beispiel-Anwendungsfälle | Wettbewerberpreise zusammentragen, Social Mentions scrapen, Listings ziehen | Kunden segmentieren, Churn vorhersagen, Leads bewerten |
| Große Herausforderungen | Website-Änderungen, Anti-Scraping-Maßnahmen, Datenqualität, rechtlich/ethisch | Schmutzige/unvollständige Daten, passende Modelle wählen, Datenschutz, Ergebnisse interpretieren |
Die Kernaussage:
Web Scraping ist der „Treibstoff“ (Daten), Data Mining ist der „Motor“ (Erkenntnisse). Beides brauchst du, um irgendwohin zu fahren.
Wie Web Scraping und Data Mining im Unternehmen zusammenspielen
Hier passiert der eigentliche Zauber: Web Scraping und Data Mining sind keine Konkurrenten – sie sind Teamkollegen. Denk an sie als Upstream und Downstream deines Daten-Workflows.
Szenario 1: Marktintelligenz
- Schritt 1: Produktlisten, Preise und Bewertungen von Wettbewerbern auf mehreren Websites scrapen.
- Schritt 2: Die Daten auf Trends hin analysieren – Marktlücken erkennen, häufige Kundenbeschwerden identifizieren oder Preisänderungen im Zeitverlauf verfolgen.
- Ergebnis: Du erhältst umsetzbare Erkenntnisse für Produktstrategie oder Preisgestaltung.
Szenario 2: Lead-Bewertung im Vertrieb
- Schritt 1: LinkedIn oder Geschäftsverzeichnisse scrapen, um deine Lead-Datenbank mit Unternehmensgröße, Branche und aktuellen Nachrichten anzureichern.
- Schritt 2: Analysieren, welche Merkmale mit hohen Konversionsraten zusammenhängen, und Leads entsprechend priorisieren.
- Ergebnis: Dein Vertrieb konzentriert sich auf die passendsten Interessenten – nicht nur auf die größte Liste.
Szenario 3: Preisoptimierung
- Schritt 1: Wettbewerberpreise und Lagerbestände in Echtzeit scrapen.
- Schritt 2: Diese Daten in deine Preisalgorithmen einspeisen, um deine eigenen Preise dynamisch anzupassen.
- Ergebnis: Du bleibst wettbewerbsfähig und maximierst den Umsatz.
Das Risiko, sie als getrennte Aktivitäten zu behandeln?
Wenn du nur scrapest und nie analysierst, ertrinkst du in Daten, hungerst aber nach Erkenntnissen. Wenn du nur interne Daten analysierst, fehlt dir der breitere Marktkontext. Die besten Teams nutzen beides – Scraping für einen vollständigen Datensatz, Mining für aussagekräftige Erkenntnisse ().
Häufige Herausforderungen bei Web Scraping und Data Mining überwinden
Seien wir realistisch: Sowohl Web Scraping als auch Data Mining bringen ihre eigenen Kopfschmerzen mit. So gehst du die größten Probleme an – und so hilft Thunderbit:
1. Datenqualität und Bereinigung
- Problem: Gescrapte Daten können chaotisch sein – fehlende Felder, uneinheitliche Formate, Dubletten.
- Lösung: Nutze Tools, die eine Bereinigung schon während der Extraktion ermöglichen. Thunderbit kann Daten mit KI im laufenden Prozess formatieren und kategorisieren, sodass deine Ausgabe direkt analysebereit ist (). Prüfe deine Daten immer stichprobenartig, bevor du mit der Analyse startest.
2. Website-Änderungen und Anti-Scraping-Maßnahmen
- Problem: Websites ändern Layouts, fügen CAPTCHAs hinzu oder blockieren Bots.
- Lösung: Nutze KI-gestützte Scraper wie Thunderbit, die sich automatisch an Layoutänderungen anpassen. Halte dich an
robots.txt, belaste Websites nicht übermäßig und nutze bei Bedarf Proxies ().
3. Rechtliche und ethische Fragen
- Problem: Öffentlich zugängliche Daten zu scrapen ist grundsätzlich legal, aber Datenschutzgesetze und Nutzungsbedingungen sind relevant.
- Lösung: Prüfe immer die Nutzungsbedingungen, konzentriere dich auf öffentliche Daten, anonymisiere wann immer möglich und halte dich an DSGVO/CCPA. Sei ein „ethischer Datenbürger“ – dein Ruf ist mehr wert als jeder Datensatz ().
4. Von Daten zu umsetzbaren Erkenntnissen
- Problem: Teams sammeln Daten, haben aber Mühe, daraus Entscheidungen abzuleiten.
- Lösung: Beginne mit klaren Geschäftsfragen, nutze Visualisierung und beziehe Fachexperten in die Interpretation ein. Integriere Erkenntnisse in deine Workflows (z. B. indem du gefährdete Kunden im CRM markierst).
5. Tooling- und Skill-Lücke
- Problem: Nicht jedes Team hat Entwickler oder Data Scientists.
- Lösung: Setze auf benutzerfreundliche No-Code-Tools wie Thunderbit fürs Scraping und moderne BI-Plattformen fürs Mining. Investiere in grundlegende Datenkompetenz – manchmal reicht schon eine einfache Pivot-Tabelle.
Die richtige Vorgehensweise wählen: Web Scraping, Data Mining oder beides?
Wie entscheidest du also, was du brauchst? Hier ist ein kurzer Entscheidungsleitfaden:
- Hast du die Daten, die du brauchst?
- Nein: Starte mit Web Scraping, um sie zu sammeln.
- Ja: Wechsle zu Data Mining, um Erkenntnisse zu gewinnen.
- Geht es bei deinen Fragen um die externe Welt oder um interne Muster?
- Extern (Wettbewerber, Markt, Leads): Web Scraping.
- Intern (Kundenverhalten, Umsatztrends): Data Mining.
- Brauchst du beides?
- Die meisten echten Projekte tun das! Scrape externe Daten und minte sie dann zusammen mit deinen internen Daten für das vollständige Bild.
- Teamfähigkeiten:
- Keine Programmierkenntnisse? Nutze No-Code-Scraping-Tools wie Thunderbit.
- Keine Data Scientists? Nutze benutzerfreundliche BI-Tools oder starte mit grundlegender Analyse.
- Zeitkritik:
- Echtzeitbedarf? Richte fortlaufendes Scraping und Analyse ein.
- Einmaliges Projekt? Mache einen einmaligen Scrape und analysiere die Daten.
Checkliste:
- „Habe ich intern alle Daten, die ich brauche?“ Wenn nicht, scrapen.
- „Verstehe ich die Daten, die ich habe?“ Wenn nicht, minen.
- „Ist das Problem groß genug, um beide Ansätze zu kombinieren?“ Wenn ja, beides tun.
- „Verfügt mein Team über die nötigen Fähigkeiten?“ Wenn nicht, No-Code-Tools nutzen oder Hilfe holen.
Und denk daran: Du musst nicht alles auf einmal machen. Fang klein an, starte mit einem Pilotprojekt und skaliere, wenn du Ergebnisse siehst.
Zentrale Erkenntnisse: Daten für dein Team nutzbar machen
Fassen wir das Wesentliche zusammen:
- Web Scraping und Data Mining sind zwei Schritte derselben Reise. Scraping sammelt die Daten (vor allem aus externen Quellen), Mining analysiert sie für Erkenntnisse.
- Unterschiedliche Rollen, unterschiedliche Ziele: Vertrieb, Marketing und Operations nutzen Scraping, um Daten zu bekommen; Analysten und BI-Teams minen sie, um Bedeutung herauszulesen.
- Sie ergänzen sich, statt zu konkurrieren: Die besten Ergebnisse entstehen, wenn beides kombiniert wird – Scraping für einen reichhaltigen Datensatz, Mining für umsetzbare Erkenntnisse.
- No-Code-Tools und KI haben die Einstiegshürde gesenkt: Thunderbit und ähnliche Tools machen Scraping für alle zugänglich. Moderne BI-Plattformen erleichtern auch das Mining.
- Datenqualität und Ethik sind wichtig: Bereinige deine Daten, respektiere die Privatsphäre und handle immer ethisch.
- Lass deinen Anwendungsfall den Weg bestimmen: Starte mit deiner Geschäftsfrage und entscheide dann, welche Daten du brauchst und wie du sie analysierst.
- Klein anfangen, dann skalieren: Nutze Free-Tiers, Pilotprojekte und schnelle Erfolge, um Momentum aufzubauen.
Am Ende des Tages geht es darum, dein Team zu befähigen, mit Daten bessere Entscheidungen zu treffen. Vielleicht bedeutet das, dass dein Vertrieb weniger Zeit mit manueller Recherche verbringt (dank Scraping), oder dass eure Strategie-Meetings auf echten Erkenntnissen basieren (dank Mining). So oder so: Die Kombination beider Ansätze ist der Weg, wie moderne Teams sich einen Wettbewerbsvorteil verschaffen.
Also: Sammle diese Web-Datenzutaten, koche daraus Erkenntnisse und serviere deinem Team die umsetzbare Intelligenz, die es braucht. Und wenn du in der Küche Hilfe brauchst, macht dir die Vorarbeit leicht.
Neugierig, es auszuprobieren? Lade die herunter und sieh selbst, wie einfach Web Scraping sein kann. Weitere Tipps und Geschichten direkt aus der Datenpraxis findest du im .
FAQs
1. Was ist der Hauptunterschied zwischen Web Scraping und Data Mining?
Web Scraping ist der Prozess, Rohdaten von Websites zu sammeln, während Data Mining diese Daten analysiert, um Muster, Erkenntnisse oder Trends aufzudecken. Stell dir Scraping als das Sammeln der Zutaten und Mining als das Kochen der Mahlzeit vor.
2. Wer nutzt typischerweise Web Scraping und wer Data Mining?
Web Scraping wird vor allem von Vertriebs-, Marketing-, Operations- und Forschungsteams genutzt, die schnell frische externe Daten brauchen. Data Mining wird von Analysten, Data Scientists und Produktteams eingesetzt, die aus Daten strategische Erkenntnisse gewinnen wollen.
3. Brauche ich Programmierkenntnisse für Web Scraping?
Nicht mehr. Tools wie bieten No-Code-, KI-gestützte Oberflächen, mit denen jeder – unabhängig vom technischen Hintergrund – per Point-and-Click Daten scrapen und sofort exportieren kann.
4. Wie arbeiten Web Scraping und Data Mining zusammen?
Web Scraping liefert die rohen, strukturierten Daten, auf denen Data Mining aufbaut. Zusammen bilden sie eine Pipeline: erst externe Daten per Scraping sammeln, dann mit Mining analysieren, um Geschäftsentscheidungen zu unterstützen.
5. Welche realen Anwendungsfälle gibt es für beide?
Web Scraping wird für Aufgaben wie Lead-Generierung, Preisüberwachung und Wettbewerbsbeobachtung eingesetzt. Data Mining unterstützt Kundensegmentierung, Trendprognosen, Betrugserkennung und strategische Planung auf Basis der gescrapten Daten.