

Du gehst mit deiner Website live, freust dich auf einen Ansturm begeisterter Kunden – und merkst dann, dass die Hälfte deines Traffics von… Maschinen kommt. Nicht aus einem Science-Fiction-Film, sondern von digitalen Crawlern: Suchmaschinen, KI-Bots, Analyse-Spider. Sie alle durchforsten deine Seite rund um die Uhr, eine endlose Prozession unsichtbarer Besucher. 2026 ist das längst keine Kuriosität mehr in den Server-Logs, sondern der Normalfall. Wer crawlt deine Seite, wie oft und wozu? Diese Frage gehört heute zum Pflichtwissen jedes Online-Geschäfts.
Ich habe viele Jahre in SaaS, Automatisierung und KI gearbeitet und dabei zugesehen, wie sich Web-Crawling vom technischen Hintergrunddetail zu einer zentralen Geschäftsfrage gewandelt hat. Die Größenordnung ist beachtlich: Bots stellen inzwischen fast die Hälfte des gesamten Internetverkehrs, mancherorts übertreffen sie den menschlichen Traffic sogar. Mit dem Aufstieg KI-gesteuerter Crawler, die Inhalte zum Training großer Sprachmodelle einsammeln, steht so viel auf dem Spiel wie nie – für deine Infrastruktur, dein Budget und deine Marke. Werfen wir einen Blick auf die aktuellen Web-Crawling-Statistiken, die Branchen-Benchmarks und darauf, was sie 2026 für dein Geschäft bedeuten.
Web-Crawling 2026: Eine Bestandsaufnahme
Daten von jeder Website mit KI extrahieren Get Started Free
Web-Crawling hat eine ganz neue Größenordnung und Komplexität erreicht. Tag für Tag rasen Milliarden automatisierter Anfragen durchs Netz, ausgelöst von einer stetig wachsenden Zahl an Crawlern. Lange Zeit gaben Suchmaschinen-Bots wie Googlebot und Bingbot den Ton an und indexierten Seiten, damit Nutzer sie in den Suchergebnissen finden. Inzwischen haben sie Gesellschaft bekommen: KI-Daten-Crawler, Social-Media-Scraper, Analyse-Bots und mehr.
Die entscheidende Zahl hängt davon ab, welchen Maßstab man anlegt. Cloudflare wies in seinem Year in Review 2025 aus, dass Bots und KI-Crawler zusammen bis Anfang Dezember 2025 für rund 53 % der HTML-Anfragen im eigenen Netzwerk standen, während der menschliche Traffic auf 47 % sank. Imperva kam in seinem Bad Bot Report 2026 (veröffentlicht am 29. April 2026) für das Kalenderjahr 2025 zum selben Schluss: 53 % Bots, 47 % Menschen – nach 51/49 im Vorjahr. Zwei sehr unterschiedliche Blickwinkel, ein und dasselbe Ergebnis: Automatisierter Traffic macht heute den größeren Teil des Webs aus. Neu ist dabei nicht nur das Volumen, sondern auch die Zusammensetzung. Früher prägten Suchindexer die Bot-Spalte. 2026 entfällt ein wachsender Anteil auf KI-Trainings-Crawler, die Chatbots und Antwortmaschinen füttern.
Die Landschaft ist vielfältiger als je zuvor:
- Gute Bots: Suchindexer, Uptime-Monitore, legitime Daten-Scraper.
- Schlechte Bots: Spam, Hacking, unbefugtes Sammeln von Daten.
- KI-Crawler: die Neulinge im Feld, die Inhalte fürs KI-Training und für Echtzeit-Antworten zusammentragen.
KI-Crawler ticken oft anders als ihre Suchmaschinen-Verwandten. Sie laden häufig ganze Seiteninhalte für semantische Analysen herunter, nicht nur Keywords für den Index, und arbeiten dabei in enormem Volumen – manchmal überschwemmen sie eine Website binnen weniger Tage mit Millionen Anfragen. Das Ergebnis? Web-Crawling ist heute allgegenwärtig, wächst und wird immer vielfältiger und verbindet das klassische Indexieren mit dem unstillbaren Datenhunger der KI.
Web-Crawling-Statistiken, die jedes Unternehmen kennen sollte
Sehen wir uns die Zahlen an, die das Web 2026 prägen. Diese Statistiken taugen nicht nur für den Quizabend – sie sind Benchmarks, die in deine Infrastruktur-, Content- und Geschäftsplanung einfließen sollten.
Bots gegen Menschen: Wer gewinnt den Kampf um den Traffic?
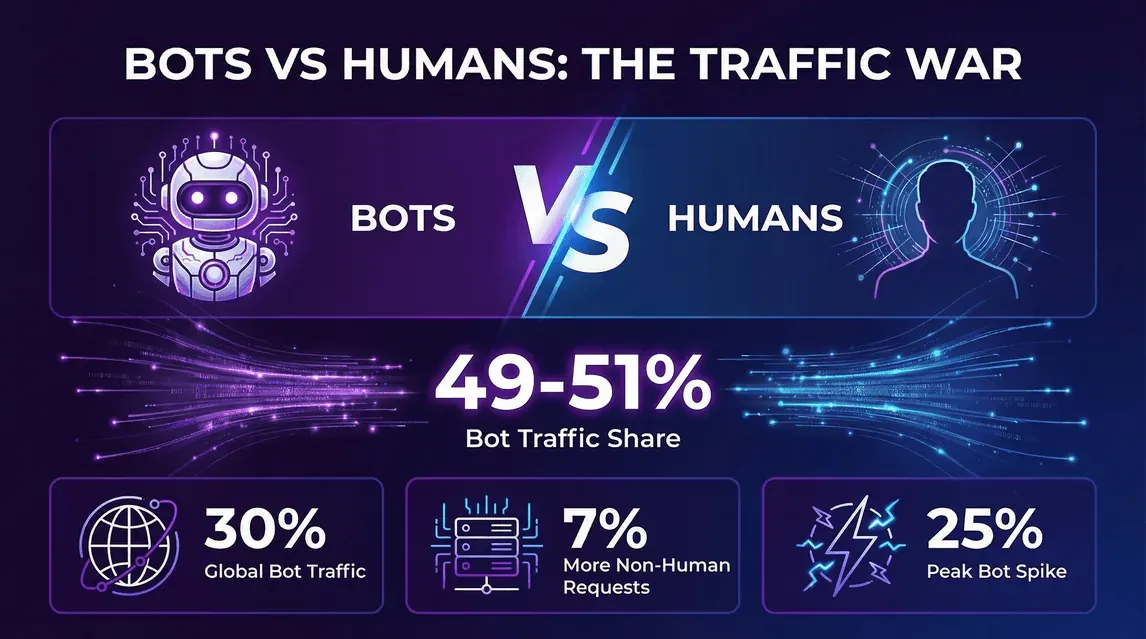
- Imperva, Bad Bot Report 2026 (April 2026): Der automatisierte Traffic erreichte 2025 53 % des gesamten Web-Verkehrs, nach 51 % im Jahr 2024. Der menschliche Anteil sank entsprechend von 49 % auf 47 %.
- Cloudflare Year in Review 2025: Am 2. Dezember 2025 stammten 47 % der HTML-Anfragen im Cloudflare-Netzwerk von Menschen, 44 % von Nicht-KI-Bots und weitere rund 9 % zusammen von KI-Bots und Googlebot.
- Der Trend ist kein Einzelquartal-Ausreißer – Imperva verzeichnet seit 2019 Jahr für Jahr einen steigenden Bot-Anteil, und der Sprung von 2024 auf 2025 ging vor allem auf KI-Trainings-Crawler zurück, nicht auf die übliche Mischung aus Scraping und Credential-Stuffing.
- Was das für Website-Betreiber heißt: Filtert deine Analytics keine Bots heraus, ist etwa die Hälfte deiner Rohanfragen keine echte Person. Wer die Infrastruktur an Roh-Logs ohne Bot-Trennung ausrichtet, überdimensioniert – und wer zu knapp für Bots plant, trifft genau die Hälfte, die tatsächlich aus Menschen besteht.
Der Boom der KI-Crawler
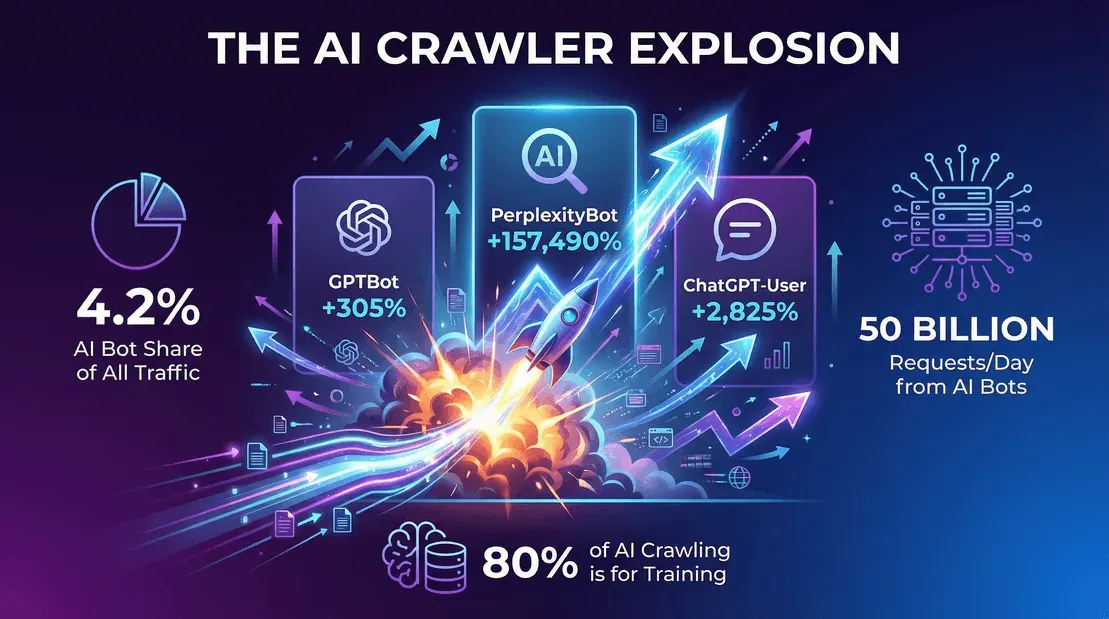
- Der Anteil des KI-Bot-Traffics steigt weiter. Laut Cloudflares Year in Review 2025 entfielen Ende 2025 rund 4,2 % der HTML-Anfragen auf KI-Bots (ohne Googlebot), während Googlebot allein weitere 4,5 % ausmachte. Eine Kategorie, die es vor drei Jahren noch gar nicht gab, ist heute fast so groß wie Googlebot selbst.
- OpenAIs GPTBot fiel von 7,7 % der Crawler-Anfragen im Mai 2025 auf 3,6 % der Anfragen auf einzigartige Seiten Ende 2025 (Cloudflare YIR 2025) – die niedrigere Zahl täuscht, weil Cloudflare den Nenner auf einzigartige Seiten umgestellt hat und das Feld zugleich dichter wurde. Nach absolutem Volumen zählt GPTBot weiterhin zu den drei größten KI-Crawlern im offenen Web.
- Anthropics ClaudeBot liegt Ende 2025 zusammen mit Meta-ExternalAgent bei rund 2,4 % der Anfragen auf einzigartige Seiten. ClaudeBots relativer Anteil ging im Jahresvergleich zurück (im Cloudflare-Fenster Mai 2024 bis Mai 2025 um 46 %), erholte sich dann aber, als Anthropic das Retraining hochfuhr.
- PerplexityBot ist absolut gesehen noch winzig – Ende 2025 etwa 0,06 % der Anfragen auf einzigartige Seiten –, weist aber von allen großen KI-Bots die steilste Wachstumskurve auf.
- Googlebot bleibt mit deutlichem Abstand der größte Einzel-Crawler im offenen Web. Cloudflares Year in Review bezifferte ihn auf etwa das 200-Fache des Volumens von PerplexityBot auf einzigartigen Seiten.
Crawler-Traffic im Kontext
Ein reales Beispiel aus einem Reddit-Thread Ende 2025 – ein Entwickler, der 30 Tage Server-Logs auswertete:
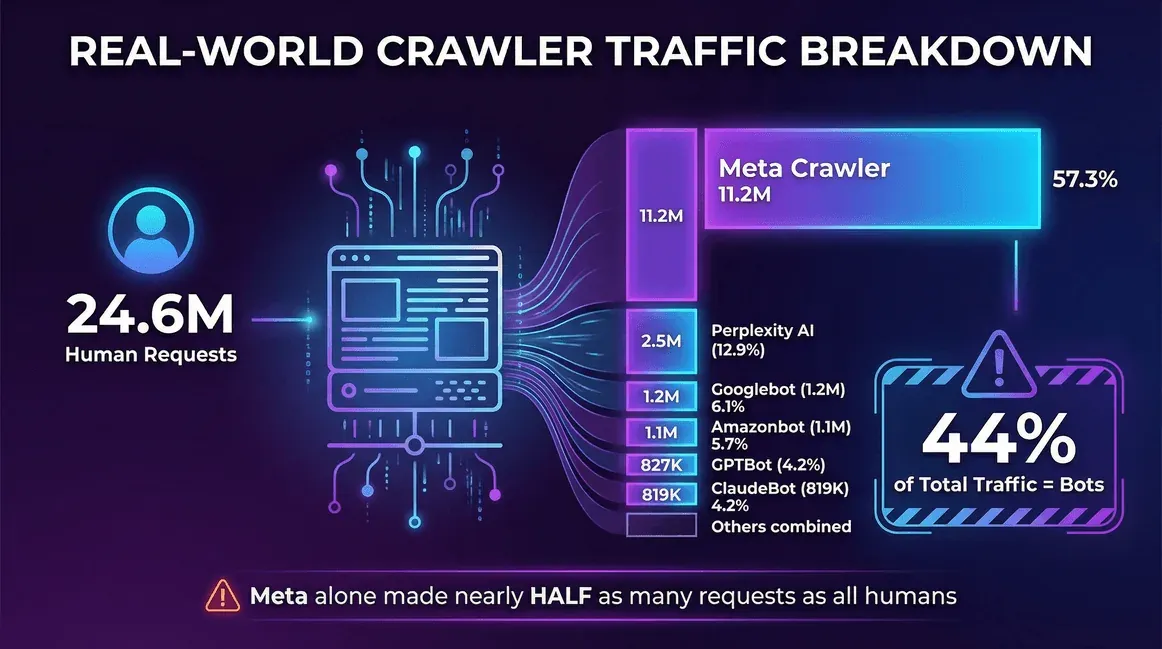
| Traffic-Quelle | Anfragen (monatlich) | Anteil an den Crawlern |
|---|---|---|
| Echte Nutzer (Menschen) | 24,647,904 | -- |
| Meta Crawler (Facebook) | 11,175,701 | 57.3% |
| Perplexity AI | 2,512,747 | 12.9% |
| Googlebot | 1,180,737 | 6.1% |
| Amazonbot | 1,120,382 | 5.7% |
| OpenAI GPTBot | 827,204 | 4.2% |
| ClaudeBot (Anthropic) | 819,256 | 4.2% |
| Bingbot | 599,752 | 3.1% |
| ChatGPT-User (OpenAI) | 557,511 | 2.9% |
| Ahrefs Crawler | 449,161 | 2.3% |
| ByteDance Spider | 267,393 | 1.4% |
Auf dieser Website machten Bots 44 % des gesamten Traffics aus – und Metas Crawler allein verursachte fast halb so viele Anfragen wie alle echten Nutzer zusammen.
Das große Bild
- Der Crawler-Traffic (Such- und KI-Bots) wuchs zwischen Mai 2024 und Mai 2025 um 18 % bei einem konstanten Set von Websites (blog.cloudflare.com).
- LLM-Trainings-Bots stellten auf manchen großen CDNs fast 80 % des gesamten „Bot"-Traffics (webscraft.org).
- Cloudflares Netzwerk zählte Ende 2025 rund 50 Milliarden Crawler-Anfragen pro Tag allein von KI-Bots (webscraft.org).
Der Aufstieg der KI-Crawler: Wie KI das Web-Crawling verändert
Reden wir über das Offensichtliche – oder genauer: über den Roboter im Raum. KI-Crawler indexieren deine Website nicht bloß für die Suche, sie saugen Inhalte auf, um große Sprachmodelle zu trainieren oder sofort KI-Antworten zu liefern. Und das in einem Ausmaß, vor dem selbst die ehrgeizigste Suchmaschine erblassen würde.
Was den Boom der KI-Crawler antreibt
- Datenhungrige KI-Modelle: Moderne LLMs brauchen riesige, vielfältige Datenbestände. Das Web ist ihr Buffet – und deine Inhalte stehen mit auf der Karte.
- Training statt Echtzeit-Antworten: Etwa 80 % des KI-Bot-Crawlings dienen Trainingszwecken und nicht nur der Beantwortung aktueller Anfragen.
- Neue Crawl-Muster: KI-Bots können Websites in gewaltigen Wellen treffen und dabei manchmal binnen weniger Tage Millionen Seiten crawlen – besonders bei einem Retraining oder Modell-Update.
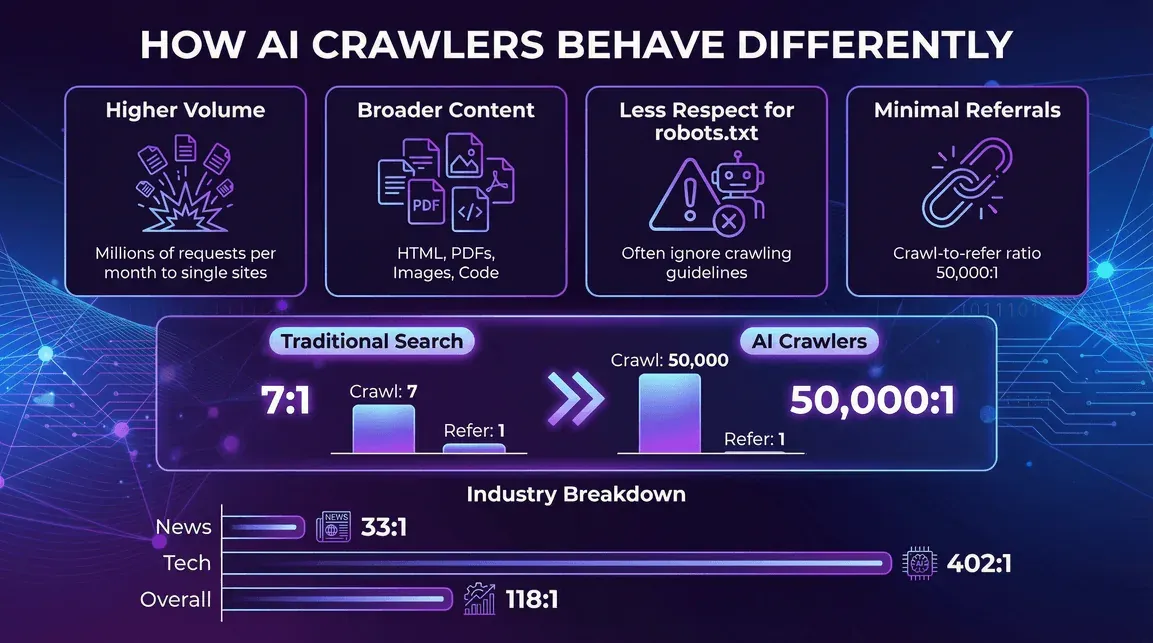
Worin sich KI-Crawler unterscheiden
- Höheres Volumen pro Crawler: Ein einzelner KI-Bot kann pro Monat Millionen Anfragen an eine einzige Website schicken (Reddit-Beispiel).
- Breiteres Spektrum an Inhalten: nicht nur HTML – auch PDFs, Bilder, Code, was immer du anbietest.
- Weniger Rücksicht auf robots.txt: Manche KI-Crawler ignorieren Crawling-Vorgaben oder halten sie nur halb ein (blog.cloudflare.com).
- Kaum Referral-Traffic. Das sollte Publisher am stärksten umtreiben. Cloudflares Crawl-to-Click-Analyse vom Juli 2025 bezifferte das Verhältnis auf rund 38.000 gecrawlte Seiten je weitergeleitetem Besuch bei Anthropic, 1.091:1 bei OpenAI und 194:1 bei Perplexity. Zum Vergleich: Googles klassischer Suchcrawler schickt nach wie vor alle paar gecrawlten Seiten einen Besucher zurück. KI-Crawler nehmen viel und geben wenig zurück – und die Schere öffnet sich weiter, weil immer mehr Antworten direkt in der Chatbot-Oberfläche erscheinen, statt dass Nutzer weiterklicken.
KI-Crawler-Traffic nach Branche
Nicht jede Branche wird gleich stark gecrawlt. Ein paar Beispiele:
- News & Publikationen: rege KI-Crawler-Aktivität, aber etwas bessere Referral-Quoten (Perplexitys Crawl-to-Refer-Verhältnis liegt auf News-Seiten etwa bei 33:1, gegenüber 118:1 insgesamt) (blog.cloudflare.com).
- Technologie & Elektronik: GPTBot und Amazonbot dominieren, die Crawl-to-Refer-Verhältnisse bleiben aber hoch (OpenAIs Verhältnis liegt im Tech-Bereich bei 402:1) (blog.cloudflare.com).
- Finanzen, Wissenschaft und andere Bereiche: Jeder Sektor hat seine eigene Mischung aus Bots und Referral-Quoten, doch der Trend ist eindeutig: KI-Crawler sind überall, und die meisten schicken kaum Traffic zurück.
Die größten Web-Crawler 2026: Wer crawlt das Web am meisten?
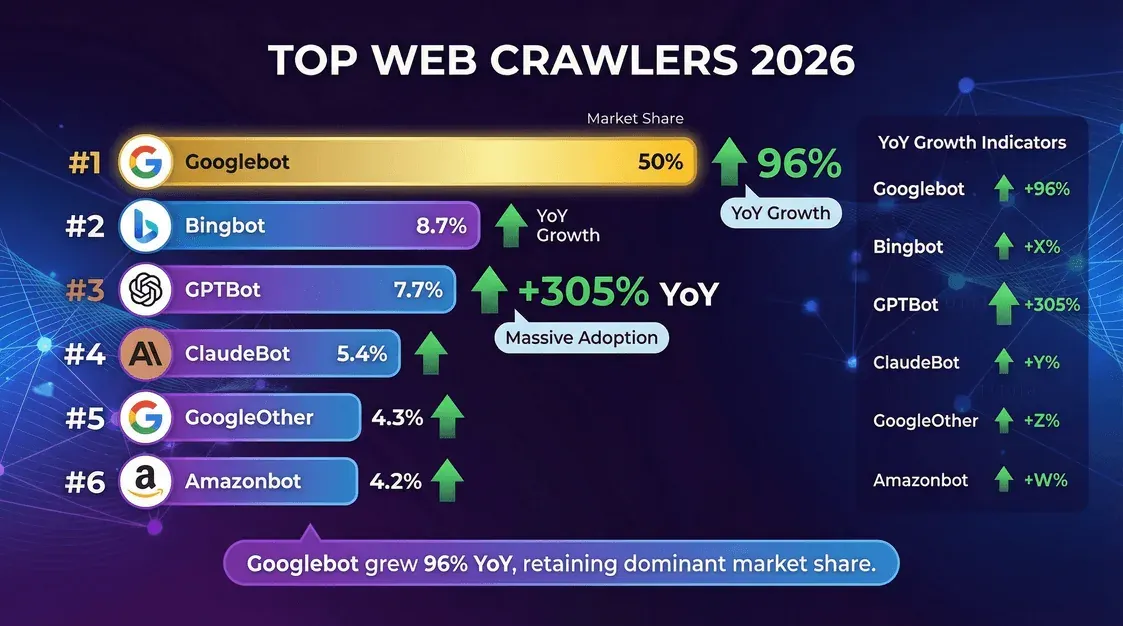
Wer sind die Hauptakteure in diesem Crawling-Schauspiel? Das Ranking auf Basis von Cloudflares Daten aus der Mitte des Jahres 2025:
| Crawler (Anbieter) | Anteil an Anfragen auf einzigartigen Seiten (Okt.–Nov. 2025) | Hinweise |
|---|---|---|
| Googlebot (Google) | 11.6% | Immer noch der größte einzelne Crawler. Cloudflare YIR 2025: etwa das 200-Fache von PerplexityBot. |
| GPTBot (OpenAI) | 3.6% | Der größte dedizierte KI-Trainings-Crawler. Nach Cloudflares Nennerwechsel und dem dichter werdenden KI-Bot-Feld unter dem Mai-2025-Anteil. |
| Bingbot (Microsoft) | 2.6% | Treibt sowohl Bing-Suche als auch die Grounding-Funktionen von Copilot an. |
| Meta-ExternalAgent | 2.4% | Metas Content-Ingestion-Crawler für das Llama-Training. Sprang 2025 in die Top 5. |
| ClaudeBot (Anthropic) | 2.4% | Erholte sich Ende 2025 nach einem starken Rückgang im Jahresvergleich zuvor. |
| Applebot (Apple) | stark steigend | Laut Sekundäranalyse der Cloudflare-Daten in Q1 2026 in die Spitzengruppe aufgestiegen. |
| PerplexityBot | 0.06% | Winziger absoluter Anteil, aber das schnellste relative Wachstum unter den großen KI-Bots. |
Quelle: Cloudflare Year in Review 2025, gemessen am Anteil der gecrawlten einzigartigen Seiten im Oktober–November 2025. Hinweis: Das ist ein anderer Nenner als die frühere Kennzahl „Anteil aller Crawler-Anfragen" aus Mai 2025 – die Rangfolge ist vergleichbar, die Prozentwerte jedoch nicht direkt.
Ein paar zentrale Punkte:
- Googlebot bleibt der König und steht für die Hälfte aller Crawling-Aktivität.
- GPTBot und Metas Crawler wachsen am schnellsten, wobei sich GPTBots Anteil binnen eines Jahres verdreifacht hat.
- PerplexityBot und die ChatGPT-User-Agenten haben in der Summe einen kleinen Anteil, legen aber rasant zu.
Web-Crawling-Benchmarks: Crawl-Raten, Durchsatz und Leistung
 Beim Web-Crawling geht es nicht nur um die Menge, sondern auch um Tempo und Effizienz. Das solltest du 2026 über Crawl-Raten und Performance-Benchmarks wissen.
Beim Web-Crawling geht es nicht nur um die Menge, sondern auch um Tempo und Effizienz. Das solltest du 2026 über Crawl-Raten und Performance-Benchmarks wissen.
Crawl-Rate: Wie schnell rufen Crawler Seiten ab?
- Die Crawl-Rate wird üblicherweise in Seiten pro Sekunde (oder Anfragen pro Sekunde) angegeben (IBM).
- Threads/parallele Verbindungen: Mehr Threads bedeuten potenziell eine höhere Crawl-Rate. Beispiel: 200 Threads mit 2 Sekunden Verzögerung pro Website erreichen etwa 100 Seiten pro Sekunde (IBM).
- Werte aus der Praxis: 100 bis 200 Seiten pro Sekunde sind für einen gut optimierten Crawler auf einem soliden Server-Cluster typisch.
- Google und Bing: Sie rufen global vermutlich tausende Seiten pro Sekunde ab, verteilt über Millionen Websites.
Faktoren, die die Crawl-Rate beeinflussen
- Zahl der Threads/parallelen Fetcher: mehr Threads, mehr Tempo – bis andere Engpässe greifen.
- Zahl der aktiven Websites: Mehrere Domains parallel zu crawlen vervielfacht den Durchsatz.
- Crawl-Delay/Wartezeit: Längere Verzögerungen senken die Crawl-Rate.
- Ressourcengrenzen: Bandbreite, CPU und Schreibgeschwindigkeit der Datenbank können allesamt zum Flaschenhals werden.
- Leistung der Zielseite: Langsame Seiten oder solche mit Rate-Limits bremsen die Crawl-Geschwindigkeit.
Hat dein Crawler etwa 100 Threads und eine Verzögerung von 1 Sekunde pro Website, kommst du auf rund 100 Seiten pro Sekunde – es sei denn, deine Datenbank kommt nicht hinterher; dann wird der Speicher zum Engpass, nicht das Netzwerk.
Was Web-Crawling fürs Geschäft bedeutet: Kosten, Chancen und Risiken
Web-Crawling ist nicht bloß technische Spielerei – es ist ein Geschäftsthema mit realen Kosten und realen Chancen.
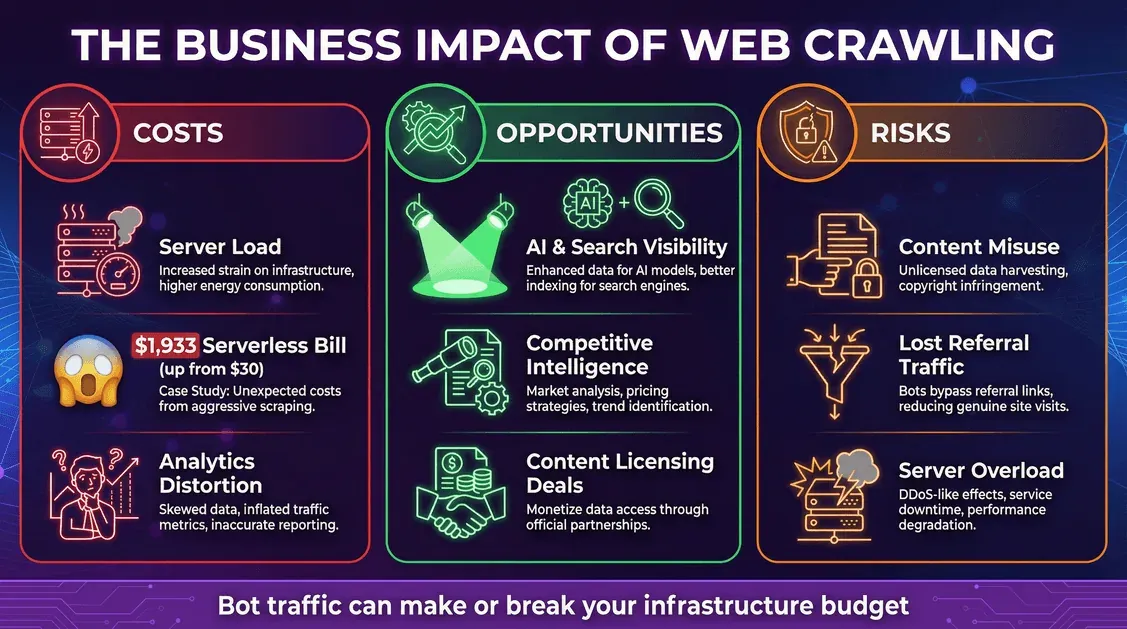
Kosten: Infrastruktur und überraschende Rechnungen
- Serverlast: Jede Bot-Anfrage frisst CPU, Speicher und Bandbreite.
- Cloud-Rechnungen: Wer pro Nutzung abrechnet (etwa bei Serverless), bei dem können Bots ernsthaft ins Geld gehen. Ein Entwickler sah, wie Metas Crawler in einem Monat 11 Millionen Anfragen auslöste und damit aus einer Serverless-Rechnung von 30 US-Dollar plötzlich 1.933 US-Dollar machte.
- Verzerrte Analysen: Bots können deine Web-Analytics verfälschen und es schwer machen, echtes Nutzerverhalten herauszulesen.
Chancen: Sichtbarkeit und Datenhebel
- Sichtbarkeit in KI und Suche: In Trainingsdaten oder Suchindizes aufgenommen zu werden, kann die Reichweite deiner Marke steigern (blog.cloudflare.com).
- Wettbewerbsbeobachtung: Unternehmen setzen Crawler für Marktforschung, Preisbeobachtung und mehr ein.
- Monetarisierung: Manche Publisher lizenzieren ihre Inhalte inzwischen an KI-Unternehmen.
Risiken: Inhaltsmissbrauch und Traffic-Verlust
- Inhaltsmissbrauch: KI-Crawler können deine Inhalte in ihre Modelle übernehmen, mitunter ohne klare Zustimmung oder Vergütung.
- Verlorener Referral-Traffic: KI-Antworten können Nutzer zufriedenstellen, ohne sie auf deine Website zu schicken – eine Form der „Disintermediation".
- Sicherheit und Ausfälle: Aggressive Crawler können Server überlasten und für Verlangsamungen oder Ausfälle sorgen.
Crawler-Traffic steuern: bewährte Vorgehensweisen
Wie hältst du die Bots also davon ab, dir die Butter vom Brot – oder dein Cloud-Budget – wegzunehmen?
1. Optimiere deine robots.txt
- Über
robots.txterlaubst oder verbietest du einzelnen Bots den Zugriff. Die meisten seriösen Crawler (etwa Googlebot) halten sich daran, viele KI-Bots jedoch nicht (blog.cloudflare.com). - Mitte 2025 hatten etwa 14 % der Top-Websites begonnen, ausdrückliche Regeln für KI-Bots zu ergänzen (blog.cloudflare.com).
2. Setze Bot-Management-Tools ein
- Web Application Firewalls (WAFs) und Bot-Management-Dienste können verdächtigen Traffic blockieren oder drosseln.
- Cloudflare und andere Anbieter stellen Funktionen zur Bot-Abwehr und sogar „AI Audit"-Tools für Content-Ersteller bereit (blog.cloudflare.com).
3. Führe Rate-Limiting und Caching ein
- Drossele schnelle Anfrageserien eines einzelnen Bots.
- Liefere Bots nach Möglichkeit zwischengespeicherte Inhalte aus – lass sie nicht teure Serverless-Funktionen oder Datenbankabfragen anstoßen (Reddit-Beispiel).
4. Überwache und analysiere den Bot-Traffic
- Behalte deine Server-Logs im Auge. Wisse, welche Bots dich treffen, wie oft und wann.
- Richte Warnmeldungen für ungewöhnliche Traffic-Spitzen ein.
5. Bleib bei neuen Standards vorn
- Achte auf neue Meta-Tags oder HTTP-Header für KI-Nutzungsrechte, etwa
<meta name="ai:allow" content="no">. - Verfolge Brancheninitiativen wie ContentSignals.org und Bezahlprotokolle wie x402.
Web-Crawling-Trends, die du 2026 und darüber hinaus im Blick behalten solltest
Was Data Scraping ist und wie man es 2025 macht Get Started Free
Die Web-Crawling-Landschaft bewegt sich schnell. Darauf achte ich – und das solltest du auch tun:
- KI-gesteuertes Crawling nimmt weiter zu: Rechne mit noch mehr KI-Bots, die immer mehr Inhaltstypen crawlen (Text, Bilder, Video).
- Lizenzierung von Inhalten und Bezahlstandards: Die Erzählung vom „rechtsfreien Raum" wirkt mittlerweile überholt. Anthropic kündigte Ende 2025 einen Vergleich über 1,5 Milliarden US-Dollar mit Autoren wegen Trainingsdaten an – die bislang größte Einigung zwischen Publishern und einem KI-Anbieter. Meta schloss mehrjährige Lizenzdeals mit CNN, Fox News, People Inc. und USA Today; die Abkommen AP–Google und Axios–OpenAI vom Jahresanfang 2025 gelten inzwischen eher als Vorbild denn als Ausnahme. Trotzdem werden weiter neue Klagen eingereicht – fünf Verlagshäuser verklagten Meta am 5. Mai 2026 in Manhattan –, die Rechtslage ist also keineswegs geklärt. Die Richtung ist aber klar: Inhalte werden bewertet, bezahlt und vor Gericht verhandelt – nicht einfach abgegriffen. Auf Protokollebene entwickeln sich x402 und ContentSignals.org zu ernstzunehmenden Kandidaten für die maschinelle Bezahl- bzw. Berechtigungsebene.
- Regulierung kommt: Rechne mit mehr rechtlicher Klarheit darüber, was Bots dürfen und was nicht, gerade bei Trainingsdaten für KI (reuters.com).
- Technische Standards für die Nutzung von Inhalten: Achte auf neue Meta-Tags, Erweiterungen der robots.txt und maschinenlesbare Bot-Deklarationen.
- Zusammenspiel von Publishern und KI: Statt passive Ziele zu bleiben, werden mehr Publisher strukturierte Datenfeeds oder APIs mit KI-Unternehmen aushandeln.
Fazit: Was diese Web-Crawling-Statistiken für dein Unternehmen heißen
Letztlich gilt: Web-Crawling ist 2026 eine prägende Kraft – und sie verliert nicht an Fahrt. Automatisierte Bots, allen voran KI-Crawler, verursachen heute einen riesigen Teil deines Traffics, und ihr Einfluss auf Infrastruktur, Budget und Content-Strategie wächst weiter.
Was solltest du tun?
- Mit viel Bot-Traffic rechnen: Plane Infrastruktur, Budget und Monitoring entsprechend.
- Deine Crawler kennen: Nicht alle Bots sind gleich – stell deinen Umgang auf jeden Einzelnen ein.
- Deine Kennzahlen beobachten: Verfolge den Bot-Traffic genauso wie die menschlichen Besucher.
- Inhalte und Budget schützen: Setze auf technische Kontrollen, rechtliche Vereinbarungen und neue Standards.
- Die Vorteile nutzen: In KI- und Suchindizes aufgenommen zu werden, kann deiner Marke helfen – wichtig ist nur, dass auch etwas für dich dabei abfällt.
- Informiert bleiben und nachjustieren: Die Crawling-Landschaft wandelt sich schnell. Behalte neue Standards, Regulierung und Geschäftsmodelle im Blick.
Als jemand, der jahrelang Automatisierungs- und KI-Tools gebaut hat – und heute bei Thunderbit arbeitet –, kann ich dir sagen: Die Unternehmen, die in dieser neuen Ära vorankommen, behandeln Web-Crawling als strategische Priorität und nicht bloß als technisches Ärgernis. Ob Vertrieb, E-Commerce, Marketing oder Immobilien: Web-Crawling-Statistiken und Branchen-Benchmarks zu verstehen, gehört heute zum Pflichtprogramm.
Wenn du also das nächste Mal deine Server-Logs öffnest und eine Prozession von Bots siehst, seufz nicht bloß und scroll weiter. Nutze die Daten. Miss deine Website an den Benchmarks. Passe deine Taktik an. Und denk daran: Im Zeitalter der KI kommen die Bots nicht erst noch – sie sind längst da. Lass sie für dich arbeiten, nicht umgekehrt.
Bleib wachsam, bleib neugierig, und mögen deine Server-Logs stets zu deinen Gunsten ausfallen.
Thunderbit KI-Web-Scraper kostenlos testen
Du willst mehr über Web-Scraping, Automatisierung und KI-gestützte Produktivität erfahren? Schau im Thunderbit-Blog vorbei – dort findest du ausführliche Analysen, Anleitungen und die neuesten Trends. Und wenn du bereit bist, die Kontrolle über deine eigenen Daten zu übernehmen, teste die Thunderbit Chrome-Erweiterung für KI-gestütztes Web-Scraping – kein Code, kein Aufwand, nur Ergebnisse.
KI-Web-Scraper testen Get Started Free
Quellen und weiterführende Lektüre:
- From Googlebot to GPTBot: Who’s Crawling Your Site in 2025 (Cloudflare)
- Cloudflare Report Reveals Global Internet Traffic Grew 19% in 2025—but a Lot of It Was Just Bots (TechRadar)
- How Crawling Works in the AI Era 2025 (Webscraft)
- Meta’s Crawler Made 11 Million Requests to My Site in 30 Days (Reddit)
- Monitoring - Web Crawler Crawl Rate (IBM)
- A Timeline of the Major Deals Between Publishers and AI Tech Companies in 2025 (Digiday)
- Launching the x402 Foundation with Coinbase (Cloudflare)




