Das Internet ist ein echter Schatz an Daten – so sehr, dass der globale Markt für Web-Scraping-Software bis . Egal, ob du als Business-Analyst, Marketer oder einfach aus Interesse unterwegs bist: Die Fähigkeit, Daten automatisiert von Webseiten zu ziehen, wird immer wichtiger. Und wenn du so tickst wie ich, willst du dir das ständige Copy-Paste sparen und direkt zu den spannenden Insights, sauberen Tabellen und vielleicht sogar ein bisschen Automatisierungsmagie kommen.
Hier kommt Python ins Spiel. Es ist das Multitool der Datenwelt – einfach genug für Einsteiger, aber auch stark genug, um von einzelnen Seiten bis zu riesigen Crawling-Projekten alles zu stemmen. In diesem praxisnahen Web Scraping Tutorial zeige ich dir die Basics, wie du mit Python daten von einer website extrahieren kannst, wie du auch dynamische Seiten knackst und stelle dir vor – unseren KI-basierten, komplett codefreien Web-Scraper, mit dem Datenerfassung so easy wird wie Essen bestellen. Egal, ob du den Code lernen oder einfach eine Abkürzung willst: Hier bist du richtig.
Was ist Web Scraping und warum ist Python dafür so beliebt?
Web-Scraping bedeutet, dass du Infos automatisiert aus Webseiten ziehst und sie in strukturierte Formate wie Tabellen, CSVs oder Datenbanken bringst – für Analysen oder Business-Zwecke (). Statt Daten mühsam per Hand zu kopieren, übernimmt ein Web-Scraper diese Aufgabe blitzschnell und in großem Stil.
Warum ist das so wertvoll? Weil datenbasierte Entscheidungen heute alles sind. verlassen sich auf Daten (oft per Scraping gewonnen), um alles von Preisstrategien über Marktforschung bis zur Lead-Generierung zu steuern. Stell dir vor, du könntest täglich Wettbewerberpreise checken, Immobilienangebote bündeln oder individuelle Lead-Listen erstellen – und das alles automatisiert.
Warum also Python? Hier die wichtigsten Gründe:
- Lesbar & easy: Die Syntax von Python ist super verständlich – perfekt, um Web Scraping Skripte zu schreiben und zu checken ().
- Riesiges Ökosystem: Bibliotheken wie
requests,BeautifulSoup,ScrapyundSeleniummachen das Abrufen, Parsen und Automatisieren von Webseiten zum Kinderspiel. - Starke Community: Python ist – es gibt unzählige Tutorials, Foren und Codebeispiele.
- Skalierbar: Von kleinen Einzelskripten bis zu großen Crawlern – Python wächst mit deinen Anforderungen.
Kurz gesagt: Python ist dein Einstiegsticket in die Welt der Webdaten – egal, ob du gerade anfängst oder schon Erfahrung hast.
Einstieg: Die Basics beim daten von einer website extrahieren mit Python
Bevor wir in den Code einsteigen, hier der typische Ablauf, wie du mit Python daten von einer website extrahieren kannst:
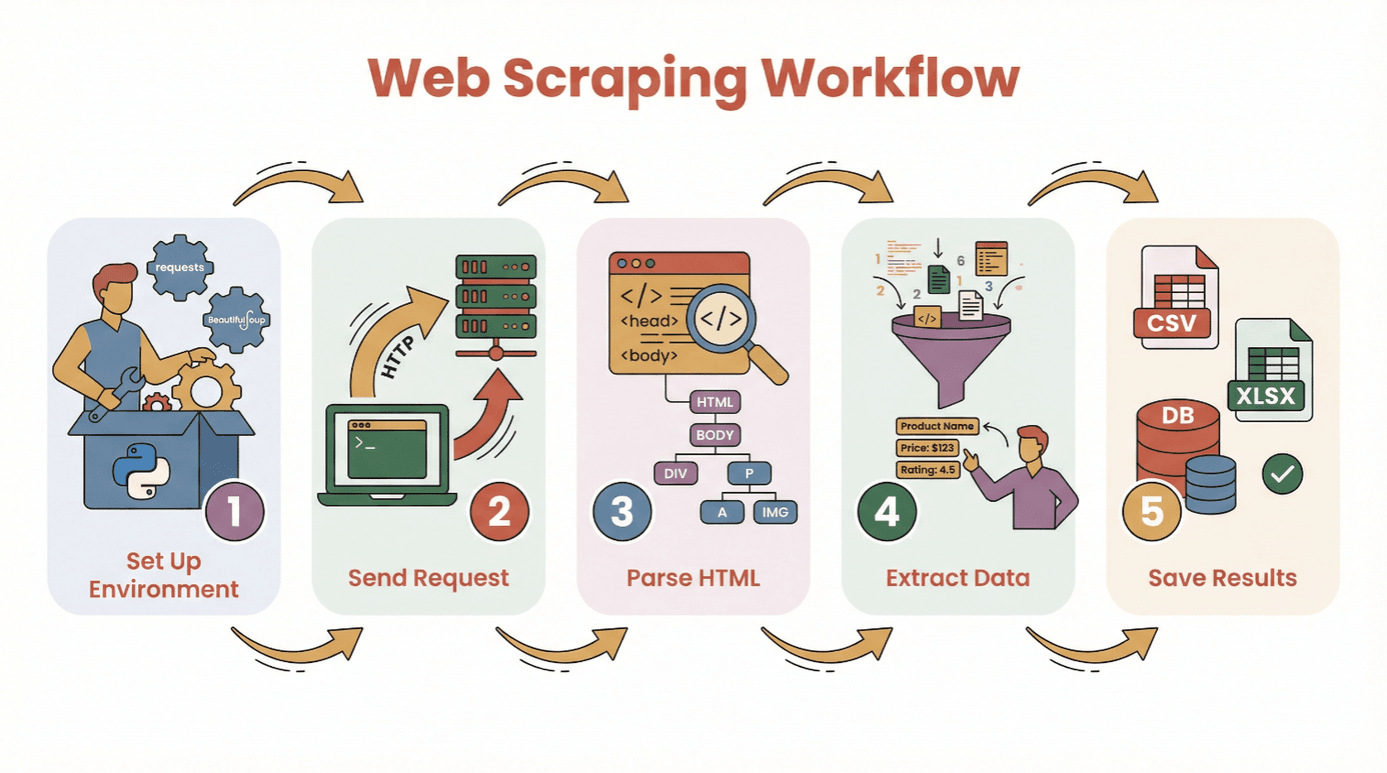
- Umgebung einrichten: Python und die nötigen Bibliotheken (
requests,BeautifulSoupetc.) installieren. - Anfrage senden: Mit Python den HTML-Inhalt der Zielseite abrufen.
- HTML parsen: Die Seitenstruktur mit einem Parser analysieren.
- Daten extrahieren: Die gewünschten Infos gezielt rausziehen.
- Ergebnisse speichern: Die Daten als CSV, Excel oder in einer Datenbank sichern.
Du musst kein Programmierprofi sein, um loszulegen. Wenn du weißt, wie man Python installiert und ein Skript ausführt, bist du schon auf dem richtigen Weg. Für Einsteiger empfehle ich eine oder ein Jupyter Notebook – aber auch ein simpler Texteditor reicht.
Wichtige Bibliotheken:
requests– um Webseiten abzurufenBeautifulSoup– um HTML zu parsenpandas– zum Speichern und Bereinigen der Daten (optional, aber sehr praktisch)
Welche Python-Bibliothek passt zu deinem Web Scraping Projekt?
Nicht jedes Python-Tool ist für alles geeignet. Hier ein schneller Überblick über die drei beliebtesten Optionen:
| Tool | Am besten geeignet für | Stärken | Schwächen |
|---|---|---|---|
| BeautifulSoup | Einfache, statische Seiten; Einsteiger | Leicht zu nutzen, wenig Einrichtung, gute Dokumentation | Nicht ideal für große Crawls oder dynamische Inhalte |
| Scrapy | Großflächiges Crawling, viele Seiten | Schnell, asynchron, eingebaute Pipelines, automatisches Crawling & Speicherung | Höhere Einstiegshürde, zu komplex für kleine Aufgaben, kein JavaScript |
| Selenium | Dynamische/JavaScript-lastige Seiten, Automatisierung | Kann JS ausführen, simuliert Nutzeraktionen, unterstützt Logins & Klicks | Langsamer, ressourcenintensiv, komplexere Einrichtung |
BeautifulSoup: Der Favorit für einfache HTML-Analysen
BeautifulSoup ist perfekt für Einsteiger und kleine Projekte. Mit wenigen Zeilen Code kannst du HTML parsen und gezielt Elemente auslesen. Wenn deine Zielseite statisch ist (also ohne viel JavaScript), reicht BeautifulSoup zusammen mit requests völlig aus.
Beispiel:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)Wann nutzen? Für einzelne Seiten, einfache Blogs, Produktseiten oder Verzeichnisse.
Scrapy: Für große oder strukturierte Crawling-Projekte
Scrapy ist ein komplettes Framework, um ganze Websites oder tausende Seiten zu crawlen. Es arbeitet asynchron (also schnell), bietet Pipelines zum Bereinigen/Speichern und folgt automatisch Links.
Beispiel:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }Wann nutzen? Für große Projekte, geplante Crawls oder wenn Geschwindigkeit und Struktur gefragt sind.
Selenium: Für dynamische und JavaScript-lastige Webseiten
Selenium steuert einen echten Browser (z. B. Chrome oder Firefox) und kann so Seiten auslesen, die Daten erst per JavaScript nachladen, Logins erfordern oder Interaktionen wie Klicks brauchen.
Beispiel:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()Wann nutzen? Für Social Media, Börsenseiten, Infinite Scroll oder alles, was beim „Seitenquelltext anzeigen“ leer aussieht.
Schritt-für-Schritt: So extrahierst du daten von einer website mit Python (Einsteiger-Tutorial)
Gehen wir ein konkretes Beispiel mit requests und BeautifulSoup durch. Wir scrapen eine einfache Buchliste mit Titeln, Autoren und Preisen.
Schritt 1: Python-Umgebung einrichten
Zuerst die nötigen Bibliotheken installieren:
1pip install requests beautifulsoup4 pandasDann im Skript importieren:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdSchritt 2: Anfrage an die Website senden
HTML-Inhalt abrufen:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"Seite konnte nicht geladen werden: \{response.status_code\}")Schritt 3: HTML-Inhalt parsen
BeautifulSoup-Objekt erstellen:
1soup = BeautifulSoup(html, 'html.parser')Alle Buch-Container finden:
1books = soup.find_all('article', class_='product_pod')
2print(f"{len(books)} Bücher auf dieser Seite gefunden.")Schritt 4: Die gewünschten Daten extrahieren
Durch alle Bücher iterieren und Details auslesen:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Title": title, "Price": price})Schritt 5: Daten speichern und analysieren
In ein DataFrame umwandeln und speichern:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)Jetzt hast du eine saubere CSV-Datei für deine Auswertung!
Tipps zur Fehlersuche:
- Wenn du leere Ergebnisse bekommst, prüfe, ob die Daten per JavaScript nachgeladen werden (siehe nächster Abschnitt).
- Untersuche die HTML-Struktur mit den Entwicklertools deines Browsers.
- Fehlende Daten mit
get_text(strip=True)und Bedingungen abfangen.
Dynamische Inhalte meistern: daten von einer website extrahieren bei JavaScript-Seiten
Viele moderne Webseiten setzen auf JavaScript. Die gewünschten Daten sind dann nicht im ursprünglichen HTML, sondern werden erst nachgeladen. Wenn dein Web-Scraper nichts findet, hast du es vermutlich mit dynamischen Inhalten zu tun.
So gehst du vor:
- Selenium: Simuliert einen echten Browser, wartet auf das Laden der Inhalte und kann Buttons klicken oder scrollen.
- Playwright/Puppeteer: Noch leistungsfähiger, aber ähnliches Prinzip (Headless-Browser).
Mini-Guide für Selenium:
- Selenium und einen Browser-Treiber (z. B. ChromeDriver) installieren.
- Mit expliziten Wartezeiten sicherstellen, dass der Inhalt geladen ist.
- Das gerenderte HTML extrahieren und ggf. mit BeautifulSoup weiterverarbeiten.
Beispiel:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# Daten wie gewohnt extrahieren
13driver.quit()Wann brauchst du Selenium?
- Wenn
requests.get()zwar HTML liefert, aber keine Daten enthält, die du im Browser siehst. - Bei Infinite Scroll, Pop-ups oder Login-Pflicht.
Web Scraping mit KI vereinfachen: daten von einer website extrahieren mit Thunderbit
Mal ehrlich – manchmal willst du einfach nur die Daten, nicht den Code. Genau dafür gibt es . Thunderbit ist eine KI-basierte Chrome-Erweiterung, mit der du daten von einer website extrahieren kannst – und das in wenigen Klicks, ganz ohne Python-Kenntnisse.
So funktioniert Thunderbit:
- .
- Zielseite öffnen.
- Thunderbit-Icon anklicken und „KI-Felder vorschlagen“ wählen. Die KI analysiert die Seite und schlägt relevante Datenfelder vor (z. B. Produktnamen, Preise, E-Mails).
- Felder anpassen und auf „Scrapen“ klicken.
- Daten direkt nach Excel, Google Sheets, Notion oder Airtable exportieren.
Warum Thunderbit überzeugt:
- Kein Programmieren nötig. Sogar meine Mutter kommt damit klar (und ruft mich sonst bei jedem WLAN-Problem an).
- Unterstützt Unterseiten & Paginierung. Produktdetails von mehreren Seiten? Thunderbit klickt sich durch und bündelt alles für dich.
- Anweisungen in natürlicher Sprache. Sag einfach, was du brauchst („alle Produktnamen und Preise extrahieren“) – die KI erledigt den Rest.
- Sofort-Vorlagen für bekannte Seiten. Amazon, Zillow, LinkedIn und viele mehr – ein Klick genügt.
- Kostenloser Datenexport. Als CSV, Excel oder direkt in deine Lieblingstools.
Thunderbit wird von über genutzt. Mit dem Gratis-Tarif kannst du bis zu 6 Seiten (oder 10 mit Test-Boost) scrapen. Für Unternehmen ein echter Zeitgewinn – und für Technikfans ein perfektes Prototyping-Tool, bevor man einen eigenen Python-Web-Scraper baut.
Nach dem Scraping: Daten mit Pandas und NumPy bereinigen und analysieren
Das Extrahieren der Daten ist nur der erste Schritt. Rohdaten aus dem Web sind oft unübersichtlich – doppelte Einträge, fehlende Werte, seltsame Formate. Hier glänzen die Python-Bibliotheken pandas und NumPy.
Typische Bereinigungsaufgaben:
- Duplikate entfernen:
df.drop_duplicates(inplace=True) - Fehlende Werte behandeln:
df.fillna('Unbekannt')oderdf.dropna() - Datentypen umwandeln:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Datumsangaben parsen:
df['Date'] = pd.to_datetime(df['Date']) - Ausreißer filtern:
df = df[df['Price'] > 0]
Einfache Analysen:
- Statistische Übersicht:
df.describe() - Nach Kategorie gruppieren:
df.groupby('Category')['Price'].mean() - Schnelle Diagramme:
df['Price'].hist()oderdf.groupby('Category')['Price'].mean().plot(kind='bar')
Für komplexere Berechnungen oder schnelle Array-Operationen ist NumPy ideal. Für die meisten Business-Anwendungen reicht aber pandas völlig aus.
Tipp: Wenn du neu bei pandas bist, schau dir den Guide an.
Best Practices & Tipps für erfolgreiches Python Web Scraping
Web Scraping ist mächtig, bringt aber auch Verantwortung mit sich. Hier meine Checkliste, damit du professionell (und rechtlich sicher) scrapest:
- robots.txt und Nutzungsbedingungen beachten. Prüfe immer, ob Scraping erlaubt ist ().
- Server nicht überlasten. Pausen zwischen Anfragen einbauen (
time.sleep(2)) und in menschlichem Tempo scrapen. - Realistische Header setzen. Mit User-Agent einen echten Browser simulieren.
- Fehler abfangen. Mit try/except und Wiederholungen auf Fehler reagieren.
- Proxies rotieren. Bei großem Umfang IP-Sperren durch Proxy-Pools vermeiden.
- Ethik & Recht einhalten. Keine persönlichen Daten oder geschützte Inhalte ohne Erlaubnis scrapen.
- Dokumentation führen. Notiere, was du wann und wo gescraped hast.
- Offizielle APIs nutzen, wenn möglich. Oft gibt es bessere Wege als HTML-Scraping.
Mehr Tipps findest du im .
Fazit & wichtigste Erkenntnisse
Web Scraping mit Python ist ein echtes Super-Tool, um aus dem Datenchaos des Internets strukturierte, nutzbare Infos zu machen. Egal, ob du mit Code (requests, BeautifulSoup, Scrapy, Selenium) arbeitest oder ein No-Code-Tool wie nutzt – du hast alles, was du brauchst, um daten von einer website zu extrahieren und neue Erkenntnisse zu gewinnen.
Wichtige Punkte:
- Starte einfach – erst eine Seite scrapen, dann größere Projekte angehen.
- Wähle das passende Tool (BeautifulSoup für Basics, Scrapy für große Projekte, Selenium für dynamische Seiten, Thunderbit für No-Code).
- Daten mit pandas und NumPy bereinigen und analysieren.
- Immer verantwortungsvoll und ethisch scrapen.
Bereit für den ersten Versuch? Starte mit einem kleinen Projekt – zum Beispiel die heutigen Schlagzeilen oder eine Produktliste – und erlebe, wie schnell du von der Webseite zur sauberen Tabelle kommst. Und wenn du den Code überspringen willst, und lass die KI für dich arbeiten.
Mehr Anleitungen, Tipps und Web Scraping Know-how findest du im .
Häufige Fragen (FAQ)
1. Was ist Web Scraping und warum ist Python dafür so beliebt?
Web Scraping ist das automatisierte Auslesen von Daten aus Webseiten. Python ist dafür besonders beliebt, weil es eine leicht verständliche Syntax, leistungsstarke Bibliotheken (wie BeautifulSoup, Scrapy und Selenium) und eine große Community bietet ().
2. Welche Python-Bibliothek sollte ich fürs Web Scraping nutzen?
Für einfache, statische Seiten eignet sich BeautifulSoup; für große oder mehrseitige Crawls Scrapy; und für dynamische oder JavaScript-lastige Seiten Selenium. Je nach Anwendungsfall hat jede Bibliothek ihre Stärken ().
3. Wie gehe ich mit Webseiten um, die Daten per JavaScript laden?
Für Inhalte, die erst durch JavaScript erscheinen, nutze Selenium (oder Playwright), um einen Browser zu simulieren und auf das Laden der Daten zu warten. Manchmal findest du auch eine zugrundeliegende API, wenn du den Netzwerkverkehr untersuchst.
4. Was ist Thunderbit und wie vereinfacht es Web Scraping?
ist eine KI-basierte Chrome-Erweiterung, mit der du ohne Programmierkenntnisse daten von einer website extrahieren kannst. Die KI schlägt Felder vor, unterstützt Unterseiten und Paginierung und exportiert die Daten direkt nach Excel, Google Sheets, Notion oder Airtable.
5. Wie kann ich gescrapete Daten in Python bereinigen und analysieren?
Mit pandas kannst du Duplikate entfernen, fehlende Werte behandeln, Datentypen umwandeln und Analysen durchführen. Für numerische Berechnungen ist NumPy ideal. Für Visualisierungen kannst du mit pandas und Matplotlib schnell Diagramme erstellen ().
Viel Erfolg beim Scrapen – und möge deine Datenbasis immer sauber, strukturiert und einsatzbereit sein.
Mehr erfahren