

Die Frage lautet 2026 nicht mehr „Lässt sich das überhaupt scrapen?", sondern „Welche Tool-Ebene liefert verwertbare Daten mit dem geringsten Aufwand für Einrichtung, Wartung und Infrastruktur?" Genau danach ist diese Seite gegliedert: KI-Web-Scraper fürs Tempo, No-Code-Tools für wiederholbare Browser-Aufgaben, APIs für Skalierung und Anti-Bot-Themen, Python-Bibliotheken für volle Kontrolle.
Die kurze Antwort
- Ein KI-Web-Scraper ist richtig, wenn Sie mit minimalem Setup so schnell wie möglich von der Seite zur Tabelle kommen wollen.
- Ein No-Code-Scraper passt, wenn Sie mehr Kontrolle über Paginierung, Zeitpläne, Login-Handling oder wiederholbare Aufgaben brauchen.
- Eine Scraping-API lohnt sich, wenn Rendering, Anti-Bot-Schutz, Parallelisierung und Entsperr-Rate wichtiger sind als eine einfache Oberfläche.
- Eine Python-Bibliothek ist die Wahl, wenn Ihr Team volle Kontrolle über Requests, Parsing, Browser-Automatisierung, Retries und Deployment behalten will.
Der häufigste Fehler in Business-Teams: zu früh tiefer in den Stack einzusteigen. Beginnen Sie mit dem leichtesten Tool, das die Aufgabe zuverlässig löst, und wechseln Sie von KI zu No-Code zu APIs zu Code erst dann, wenn der Workflow es wirklich erzwingt.
Das vollständige visuelle Paket können Sie hier herunterladen: visuelles Paket zu Website-Scraping-Tools.
Schneller Vergleich: Website-Scraping-Tools auf einen Blick
Die folgenden Preisangaben wurden am 12. Mai 2026 mit den offiziellen Produkt-, Preis- oder Dokumentationsseiten abgeglichen. Wo Anbieter individuell oder nutzungsbasiert abrechnen, beschreibe ich das Preismodell, statt eine künstliche monatliche Zahl zu erzwingen.
| Tool | Kategorie | Am besten geeignet für | Warum es in diese Liste 2026 aufgenommen wurde | Preissignal (geprüft im Mai 2026) |
|---|---|---|---|---|
| Thunderbit | KI-Web-Scraper | Vertrieb, Operations, E-Commerce, Immobilien | Schnellster nicht-technischer Weg von der Webseite zur strukturierten Tabelle | Kostenloser Plan, kostenpflichtige Stufen, Business-Preise |
| Kadoa | KI-Extraktionsplattform | Datenteams und größere, wiederkehrende Programme | Stark für selbstheilende, agentenartige Extraktions-Workflows | Kostenlose Evaluation, nutzungsbasierte und Enterprise-Pläne |
| Octoparse | No-Code-Scraper | Analysten und wiederkehrende Operations-Aufgaben | Reifes Cloud-Scraping und visueller Task-Builder | Kostenloser Plan, Standard ab 69 $/Monat, höhere Stufen |
| ParseHub | Low-Code-Scraper | Technische Nicht-Programmierer und Forschende | Flexible Navigationslogik für schwierigere Websites | Kostenloser Plan, kostenpflichtige Pläne ab 189 $/Monat |
| Web Scraper | Browser-No-Code-Scraper | Einsteiger und leichte, wiederholbare Aufgaben | Einfaches Sitemap-Modell mit optionaler Cloud-Ebene | Kostenlose Erweiterung, Cloud ab 50 $/Monat |
| Browse AI | No-Code-Roboter-Scraper | Monitoring- und Spreadsheet-first-Teams | Stark für wiederholbares Monitoring und Änderungsalarme | Kostenloser Plan, kostenpflichtige Pläne, Managed-Tier |
| Bardeen | KI-Browser-Automatisierung | GTM- und RevOps-Automatisierung | Am besten, wenn Scraping nur ein Schritt in einem größeren Workflow ist | Kostenloser Plan, Basic ab 10 $/Monat, Premium und Enterprise |
| ScrapeStorm | KI-gestützter visueller Scraper | Nutzer, die ein schnelles visuelles Setup wollen | Nützliche Brücke zwischen manuellen Selektoren und KI-Unterstützung | Kostenlose Testversion, kostenpflichtige Pläne, Enterprise-Preise |
| ScraperAPI | Scraping-API | Entwickler mit wachsendem Anfragevolumen | Einfache API plus Auslagerung von Proxy, CAPTCHA und Rendering | 7-Tage-Test, kostenpflichtig ab 49 $/Monat |
| Bright Data Web Scraper | Enterprise-Scraping-Plattform | Beschaffungsintensive und compliance-orientierte Programme | Breitester Daten-Stack in dieser Gruppe | Produktbasierte und nutzungsbasierte Preise |
| Zyte | API + Anti-Bot-Stack | Entwickler- und Datenteams | Starke Browser-Aktionen, JS-Rendering und IP-Rotation | 5 $ kostenloses Testguthaben, nutzungsbasierte Pläne |
| ZenRows | Scraping-API | Startups und Entwicklerteams | Saubere Anti-Bot-API mit geringerer Einstiegshürde | Kostenlose Testversion, Developer ab 69 $/Monat |
| ScrapingBee | Scraping-API | Teams, die JS-lastige Websites scrapen | Nützlich, wenn Rendering das Hauptproblem ist | Kostenlose Testversion, kostenpflichtig ab 49 $/Monat |
| Selenium | Open-Source-Browser-Automatisierung | QA-nahe Abläufe und interactionsintensives Scraping | Weiterhin relevant, wenn exakte Nutzerinteraktion zählt | Kostenlos und Open Source |
| Beautiful Soup | Python-Parsing-Bibliothek | Leichtgewichtiges Python-Scraping | Einfachster Parser im Stack für chaotisches HTML | Kostenlos und Open Source |
| Playwright | Moderne Browser-Automatisierung | Moderne Web-Apps und Entwicklerteams | Beste moderne Wahl für skriptbasiertes Browser-Scraping | Kostenlos und Open Source |
| urllib3 | Python-HTTP-Bibliothek | Entwickler, die niedrige Request-Kontrolle wollen | Nützliche Grundlage, wenn Sie Transportverhalten direkt selbst steuern möchten | Kostenlos und Open Source |
So wählen Sie das richtige Website-Scraping-Tool aus
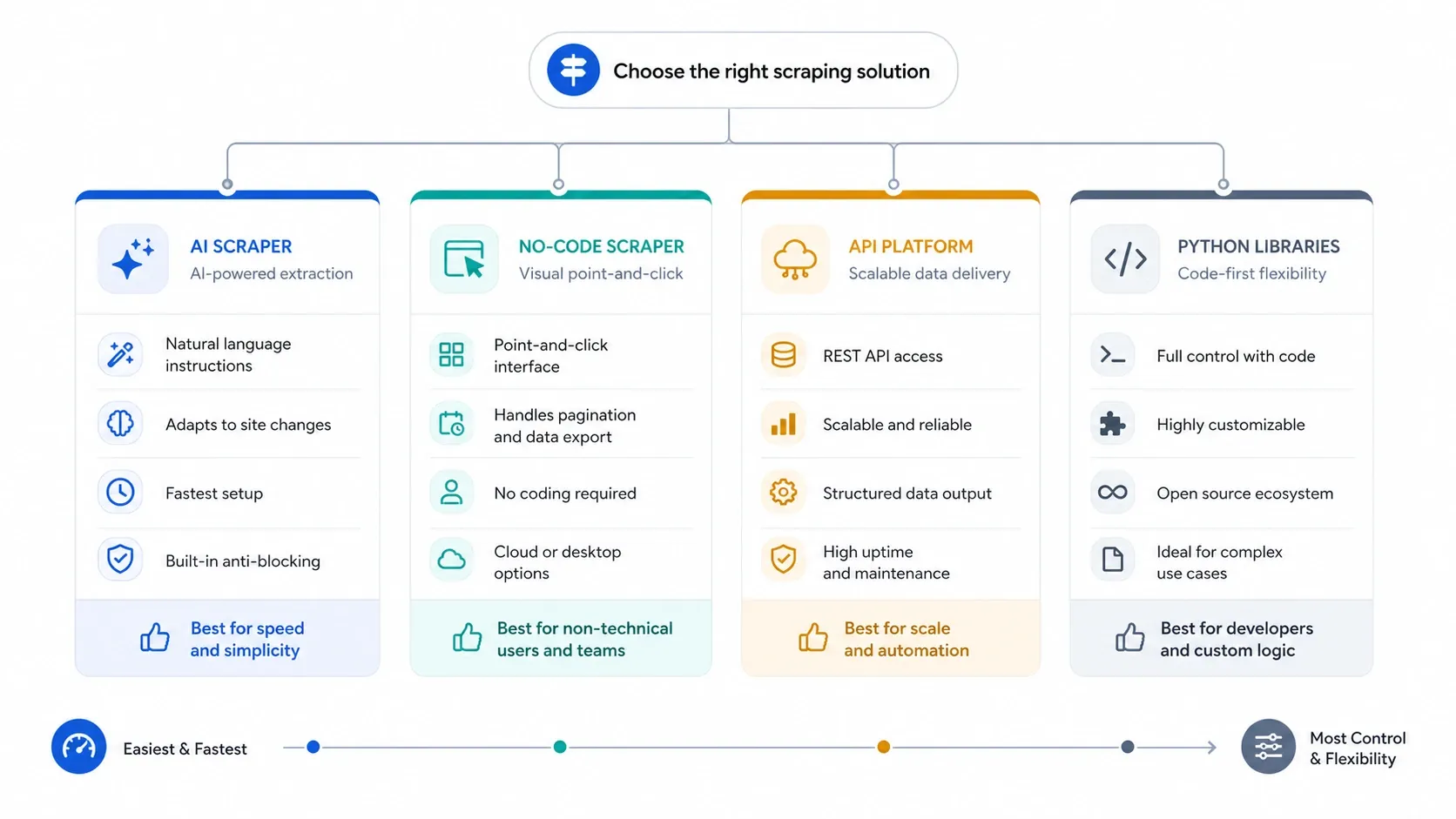
Legen Sie vor dem Markenvergleich vier Filter an:
- Zeit bis zur ersten brauchbaren Ausgabe
Liefert das Tool nicht schnell eine echte Tabelle, fällt es für die meisten Business-Anwendungsfälle schon durch. - Wartungsaufwand
Ein billiger Scraper, der bei jedem Layoutwechsel kaputtgeht, ist nicht wirklich billig. - Skalierungsgrenze
Eine Browser-Erweiterung kann für 50 Seiten pro Woche perfekt sein und bei 5 Millionen Requests pro Monat katastrophal. - Passung zum Workflow
Der beste Scraper für RevOps ist selten auch der beste für eine Plattform-Engineering-Rolle.
Der Entscheidungsrahmen ist meist einfacher, als Teams ihn machen:
- Wollen Sie Leads, Listings oder Produktseiten scrapen, ohne Selektoren anzufassen, starten Sie mit KI.
- Brauchen Sie wiederholbare Aufgaben, Cloud-Läufe und mehr explizite Steuerung, wechseln Sie zu visuellen No-Code-Buildern.
- Sind Anti-Bot-Schutz, JavaScript-Rendering und Parallelisierung das eigentliche Problem, steigen Sie auf APIs um.
- Wollen Sie jede Ebene selbst besitzen, nutzen Sie Python-Bibliotheken und nehmen den Wartungsaufwand in Kauf.
Die besten KI-Web-Scraper für schnelle Business-Workflows
Das ist die erste Kategorie, die ich testen würde, wenn die gewünschte Ausgabe direkt als Tabellenkalkulation nutzbare Daten sind – mit möglichst wenig Konfiguration.
1. Thunderbit
Thunderbit bleibt für Nicht-Programmierer der einfachste Einstieg. Der Kernvorteil ist nicht „KI" als Schlagwort, sondern der stark verkürzte Einrichtungsaufwand: Seite öffnen, Felder von der KI vorschlagen lassen, bei Bedarf über Unterseiten anreichern und das Ergebnis direkt an die Tools schicken, die Ihr Team ohnehin nutzt.
- Am besten für: Vertriebsakquise, E-Commerce-Monitoring, Immobilien-Datenerfassung und Operations-Teams, die im Browser arbeiten.
- Warum es herausragt: schnellster Weg von einer unübersichtlichen Seite zu einer strukturierten Tabelle.
- Achtung: Brauchen Sie crawlerartige Logik oder sehr individuelle Engineering-Workflows, wechseln Sie irgendwann zu APIs oder Code.
- Preissignal: kostenloser Plan, Self-Service-Kostenstufen und Business-Preise.
Dieser Rundgang ist nach wie vor der schnellste Weg, um zu beurteilen, ob KI-first-Scraping für Ihren Workflow ausreicht:
Thunderbit AI Web Scraper kostenlos testen
2. Kadoa
Kadoa ist hier die stärker infrastrukturell ausgerichtete KI-Option – sinnvoll, wenn Sie selbstheilende Extraktion und wiederkehrende Jobs in einem Maßstab brauchen, den Browser-Erweiterungen nicht mehr bewältigen.
- Am besten für: Datenteams, interne Intelligence-Programme und größere wiederkehrende Extraktions-Workloads.
- Warum es herausragt: agentenartige Orchestrierung und eine überzeugendere Story zur Reduktion des Wartungsaufwands.
- Achtung: schwergewichtiger als das, was die meisten Business-User für schnelle Einmal-Scrapes brauchen.
- Preissignal: kostenlose Evaluation, nutzungsbasierte und Enterprise-Pläne.
Die besten No-Code-Website-Scraping-Tools für wiederholbare Aufgaben
Sobald die Scraping-Aufgabe regelmäßig läuft, werden visuelle Workflow-Builder und Cloud-Ausführung wichtiger als reine One-Click-Geschwindigkeit.
3. Octoparse
Octoparse bleibt eines der glaubwürdigsten No-Code-Tools, sobald die Aufgabe zu groß für eine Browser-Erweiterung, aber noch kein eigenes Engineering-Projekt ist. Der Wert liegt in der Kombination aus Cloud-Läufen, Vorlagen und einem ausgereiften visuellen Task-Builder.
- Am besten für: Analysten, Pricing-Teams und wiederkehrende Erfassungsjobs mit echter operativer Relevanz.
- Warum es herausragt: mehr Tiefe als Browser-Plugins, ohne Sie in Code zu zwingen.
- Achtung: Diese Flexibilität bezahlen Sie mit einer steileren Lernkurve als bei KI-first-Tools.
- Preissignal: kostenloser Plan, Standard ab 69 $/Monat, höhere kostenpflichtige Stufen.
Wer vor einem Kauf ein klassischeres No-Code-Workspace-Modell evaluieren möchte, findet in diesem offiziellen Octoparse-Überblick weiterhin Orientierung:
4. ParseHub
ParseHub bleibt relevant, weil viele Teams mehr schrittweise Aufgabenlogik wollen, als ein leichter KI-Scraper bietet. Optisch nicht das hübscheste Produkt der Kategorie, dafür flexibel.
- Am besten für: Forschende, Journalistinnen und Journalisten sowie technische Nicht-Programmierer, die mehr Setup tolerieren.
- Warum es herausragt: stärkere bedingte Logik und Navigationskontrolle als viele Einsteiger-Tools.
- Achtung: länger zu lernen und weniger modern wirkend als neuere Anbieter.
- Preissignal: kostenloser Plan, kostenpflichtige Pläne ab 189 $/Monat.
5. Web Scraper
Web Scraper gehört zu den saubereren Optionen, um die Grundlagen zu lernen, ohne gleich eine Plattform zu kaufen – ein sinnvoller Einstieg für alle, denen das Sitemap-Modell liegt.
- Am besten für: Einsteiger, Hobbyprojekte und kleinere browsergestützte Aufgaben.
- Warum es herausragt: unkompliziertes Setup und ein einfacher Weg von der lokalen Erweiterung zu Cloud-Plänen.
- Achtung: Es stößt schnell an Grenzen, sobald Sie anpassungsfähigere Logik oder stärkere Entsperrmechanismen brauchen.
- Preissignal: kostenlose Erweiterung, Cloud ab 50 $/Monat.
6. Browse AI
Browse AI bleibt stark, wenn Scraping und Monitoring gleichermaßen zählen. Das Roboter-Modell ist intuitiv für Business-User, die in der Logik „Beobachte diese Seite und sag mir, was sich geändert hat" denken.
- Am besten für: Wettbewerbsmonitoring, Preisverfolgung und Teams mit Spreadsheet-first-Arbeitsweise.
- Warum es herausragt: poliertes Onboarding, wiederkehrendes Monitoring und automationfreundliche Ausgaben.
- Achtung: Komplexe Jobs mit hohem Volumen können schneller teuer werden als API-first-Stacks.
- Preissignal: kostenloser Plan, kostenpflichtige Pläne, Managed-Tier.
Wer eher Seitenmonitoring als einmalige Extraktion evaluiert, findet in diesem kurzen offiziellen Überblick einen guten Realitätscheck:
7. Bardeen
Bei Bardeen geht es weniger um reine Scraping-Tiefe als darum, was nach dem Scrape passiert. Besonders stark ist es, wenn die Web-Extraktion nur ein Schritt innerhalb eines größeren Browser-Automatisierungs-Workflows ist.
- Am besten für: GTM-Operations, Lead-Routing, CRM-Übergaben und browsernative Automatisierung.
- Warum es herausragt: überzeugende Story zur Workflow-Automatisierung rund um das Scraping selbst.
- Achtung: nicht die sauberste Wahl, wenn nur die Extraktionsgenauigkeit zählt.
- Preissignal: kostenloser Plan, Basic ab 10 $/Monat, Premium- und Enterprise-Stufen.
8. ScrapeStorm
ScrapeStorm füllt weiterhin eine nützliche Mitte für Nutzer, die KI-Unterstützung wollen, aber auch eine klassischere visuelle Scraping-Umgebung erwarten.
- Am besten für: Verzeichnis-Scraping, E-Commerce-Seitenerfassung und visuell konfigurierte wiederkehrende Aufgaben.
- Warum es herausragt: leichter einzusteigen als viele ältere visuelle Tools.
- Achtung: weniger ausgereift als die Kategorienführer und auf schwierigeren Websites schnell enger wirkend.
- Preissignal: kostenlose Testversion, kostenpflichtige Pläne, Enterprise-Preise.

Die besten Scraping-APIs, wenn Skalierung und Anti-Bot-Themen wichtig sind
Hierhin wechseln Sie, wenn die Frage nicht mehr „Wie wähle ich die Daten aus?" lautet, sondern „Wie halte ich das unter Last zuverlässig am Laufen?"
9. ScraperAPI
ScraperAPI bleibt eines der zugänglichsten API-first-Produkte für Entwickler, die nicht länger über Proxys und Erfolgsraten von Requests nachdenken wollen.
- Am besten für: Entwickler, die schnell vom Prototyp in die Produktion skalieren müssen.
- Warum es herausragt: unkomplizierte API plus Unterstützung für Proxy, CAPTCHA und Rendering.
- Achtung: Parsing, Retries und nachgelagerte Datenqualität bleiben in Ihrer Verantwortung.
- Preissignal: 7-Tage-Test, kostenpflichtig ab 49 $/Monat.
10. Bright Data Web Scraper
Bright Data ist die Schwergewichtslösung, wenn Entsperr-Fähigkeit, Proxy-Bestand, Compliance-Ausrichtung und verwaltete Optionen wichtiger sind als Einfachheit.
- Am besten für: Datenerfassung im Enterprise-Maßstab und compliance-sensible Programme.
- Warum es herausragt: der breiteste Stack in diesem Vergleich, von Proxys bis zu verwalteten Erfassungsprodukten.
- Achtung: Man kauft schnell zu viel ein, solange der eigene Workflow noch relativ einfach ist.
- Preissignal: produktbasierte und nutzungsbasierte Preise.
11. Zyte
Zyte bleibt eine ernst zu nehmende Option für Entwicklerteams, die Browser-Aktionen, JS-Rendering, rotierende IPs und Anti-Bot-Absicherung in einer Plattformstory wollen.
- Am besten für: engineering-getriebene Scraping-Programme und wiederholbare Extraktionssysteme.
- Warum es herausragt: starker Anti-Detection-Stack und API-first-Workflows.
- Achtung: eher für Teams mit Engineering-Verantwortung als für Business-User.
- Preissignal: 5 $ kostenloses Testguthaben, nutzungsbasierte Pläne.
12. ZenRows
ZenRows bietet eine der saubereren Entwicklererfahrungen in der API-Kategorie, wenn Sie Anti-Bot-Handling ohne Enterprise-ähnlichen Beschaffungsprozess wollen.
- Am besten für: Startups, Entwickler und schlanke interne Tool-Teams.
- Warum es herausragt: vergleichsweise geringe Einstiegshürden plus starke Anti-Bot-Positionierung.
- Achtung: weiterhin ein API-Produkt – Anwendungslogik und QA-Aufwand bleiben also bei Ihnen.
- Preissignal: kostenlose Testversion, Developer ab 69 $/Monat.
13. ScrapingBee
ScrapingBee ergibt Sinn, wenn Sie eigentlich eine gerenderte Seite brauchen und weniger Infrastrukturarbeit – besonders bei JS-lastigen Websites.
- Am besten für: Entwickler, die dynamische Websites scrapen und Rendering auslagern wollen.
- Warum es herausragt: einfache API rund um Headless Browsing und Proxys.
- Achtung: Es reduziert Infrastrukturarbeit, nicht den Bedarf an guter Scraping-Logik.
- Preissignal: kostenlose Testversion, kostenpflichtig ab 49 $/Monat.
Die besten Python-Web-Scraping-Bibliotheken für eigene Stacks
Diese Gruppe ist die richtige Antwort, wenn Kontrolle wichtiger ist als Bequemlichkeit und Ihr Team die Wartung selbst tragen will.
14. Selenium
Selenium ist nicht das neueste Browser-Tool, bleibt aber relevant, wenn die Genauigkeit der Nutzerinteraktion wichtiger ist als reiner Scraping-Durchsatz.
- Am besten für: interactionsintensive Abläufe, QA-Überschneidungen und Websites, bei denen das Browserverhalten die Kernherausforderung ist.
- Warum es herausragt: ausgereiftes Ökosystem und breite Browser-Unterstützung.
- Achtung: für viele Scraping-Workloads schwerer und langsamer als neuere Automatisierungsstacks.
- Preissignal: kostenlos und Open Source.
15. Beautiful Soup

Beautiful Soup bleibt der einfachste Parser im Python-Scraping-Stack. Es ist keine vollständige Scraping-Plattform, aber weiterhin der einfachste Weg, aus chaotischem HTML eine nutzbare Struktur zu machen.
- Am besten für: leichte Python-Jobs, statische HTML-Seiten und schnelle Prototypen.
- Warum es herausragt: geringe kognitive Last und verzeihende Parsing-Logik.
- Achtung: Kombinieren Sie es mit
requests, einer Browser-Ebene oder einem Crawler; allein parst es nur. - Preissignal: kostenlos und Open Source.
16. Playwright
Playwright ist meine Standardempfehlung für Entwicklerteams, die robuste Browser-Automatisierung im heutigen Web brauchen.
- Am besten für: JavaScript-lastige Websites, moderne Browser-Automatisierung und Teams, die ohnehin schon komfortabel Code schreiben.
- Warum es herausragt: starkes Warten-Verhalten, Multi-Browser-Unterstützung und saubere APIs.
- Achtung: Parallelisierung, Selektoren, Browser-Infrastruktur und Datenvalidierung bleiben in Ihrer Verantwortung.
- Preissignal: kostenlos und Open Source.
17. urllib3
urllib3 gehört auf diese Liste, weil einige Teams direkte Kontrolle über das Transportverhalten wollen statt einer höheren Abstraktion. Es ist kein einsteigerfreundlicher Scraper, aber eine nützliche Basisbibliothek, wenn Sie Ihren eigenen Stack aufbauen.
- Am besten für: Entwickler, die genaue Kontrolle über Retries, Proxys, Sessions und HTTP-Verhalten wollen.
- Warum es herausragt: leichtgewichtig, zuverlässig und als Infrastruktur weit verbreitet.
- Achtung: Den Großteil des Stacks bauen Sie selbst.
- Preissignal: kostenlos und Open Source.
Kostenlose Website-Scraping-Tools, die sich zuerst zu testen lohnen
Zum Ausprobieren vor dem Kauf eignen sich aus dieser Liste am besten Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright und urllib3. Die kostenlose Variante reicht völlig, um herauszufinden, welche Art von Scraper Sie wirklich brauchen – das ist wichtiger, als sich am ersten Tag auf eine perfekte Feature-Checkliste zu versteifen.
Meine Kurzliste nach Teamtyp

- Sales-, Ops- und E-Commerce-Teams: starten mit Thunderbit und vergleichen dann Browse AI, wenn Monitoring wichtiger ist als Unterseiten-Anreicherung.
- Analysten und wiederkehrende manuelle Operatoren: zuerst Octoparse, dann ParseHub, wenn Sie mehr individuelle Aufgabenlogik brauchen.
- GTM-Automation-Teams: Bardeen, wenn das Scraping direkt in CRM, Sheets oder Browser-Workflows fließen soll.
- Entwicklungsteams, die interne Tools bauen: ScraperAPI, ZenRows, Zyte oder Playwright – je nachdem, wie viel Kontrolle Sie über den Stack wollen.
- Enterprise-Datenprogramme: Bright Data und Zyte sind hier die ernsthafteren Infrastrukturgespräche, mit Kadoa als KI-geführter Alternative, wenn die Reduktion des Wartungsaufwands das Hauptziel ist.
Wann Sie tiefer in den Stack gehen sollten
Nutzen Sie diesen Upgrade-Pfad:
- Bleiben Sie bei KI-Web-Scrapern, bis Sie an Grenzen bei Wiederholbarkeit oder Sonderfällen stoßen.
- Wechseln Sie zu No-Code-Buildern, wenn Zeitplanung, Paginierung und Cloud-Ausführung wichtiger werden als One-Click-Einfachheit.
- Wechseln Sie zu APIs, wenn Entsperr-Rate, Rendering und Parallelisierung zum Engpass werden.
- Wechseln Sie zu Python-Bibliotheken, wenn die Kosten der Anbieter-Abstraktion höher sind als der Vorteil, das ganze System selbst zu besitzen.
Die meisten Teams gehen diese Schritte in der falschen Reihenfolge. Sie bauen zuerst zu viel und merken erst später, dass ein leichteres Tool das eigentliche Workflow-Problem längst gelöst hätte.
Fazit
Das beste Website-Scraping-Tool 2026 ist nicht das mit der längsten Funktionsliste, sondern das, das genaue Daten mit dem geringsten Wartungsaufwand in den nächsten Workflow Ihres Teams bringt. Deshalb gewinnen KI-first-Tools bei Operatoren, bleiben No-Code-Tools für wiederholbare Browser-Aufgaben wertvoll, dominieren APIs bei Skalierung und Blockaden, und Python-Bibliotheken halten das hochkontrollierte Ende des Stacks.
Wer diese Woche brauchbare Daten braucht, beginnt einfach. Zeigt der Workload schon, dass Entsperr-Rate, Browser-Rendering und Engineering-Kontrolle das eigentliche Problem sind, gehen Sie bewusst tiefer – nicht aus Gewohnheit.
Beginnen Sie mit dem leichtesten Scraper, der die Aufgabe wirklich erledigen kann Get Started Free
FAQs
1. Was ist 2026 das beste Website-Scraping-Tool für nicht-technische Nutzer?
Für die meisten nicht-technischen Teams sind KI-first-Tools wie Thunderbit und Browse AI weiterhin der schnellste Weg, weil sie Setup-Zeit, Selektorenarbeit und Wartungsaufwand reduzieren.
2. Was sollte ich für JavaScript-lastige oder durch Anti-Bot-Schutz geschützte Websites wählen?
Dafür sind ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright oder Selenium meist sinnvoller als Browser-Erweiterungen.
3. Sind No-Code-Scraping-Tools noch relevant, jetzt wo KI-Scraper besser sind?
Ja. Octoparse, ParseHub, Web Scraper und Browse AI bleiben wichtig, wenn Sie mehr explizite Aufgabenkontrolle, wiederkehrende Läufe oder browser sichtbares Debugging brauchen.
4. Welche Tools passen am besten für Entwicklerteams?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup und urllib3 sind die natürlichsten Optionen, wenn das Engineering den Workflow verantwortet.
Weiterführende Lektüre




