Wenn Sie 2026 Web-Scraping-Tools bewerten, suchen Sie in der Regel nicht nach einer Grundsatzdebatte. Sie wollen eine belastbare Shortlist, einen schnellen Weg, Business-Tools von engineeringlastigen Stacks zu trennen, und genug echte Belege, um nicht das falsche Produkt zu kaufen. Genau das liefert diese Seite.
Ich bin Shuai Guan, Mitgründer und CEO von . Ich arbeite jeden Tag an KI-gestütztem Scraping und Browser-Automatisierung, deshalb interessieren mich weniger allgemeine Rankings als die Frage nach dem konkreten Einsatz: Welche Tools helfen einem Sales- oder Ops-Team noch diese Woche, welche gehören in einen Entwickler-Workflow, und welche machen erst dann Sinn, wenn Skalierung und Anti-Bot-Infrastruktur zum eigentlichen Problem werden.
Die Kurzantwort
Wenn Sie nur die Entscheidungslogik brauchen, dann gilt:
- Wählen Sie einen KI-Web-Scraper, wenn Sie möglichst schnell und mit minimalem Setup von der Website zur Tabelle kommen wollen.
- Wählen Sie einen No-Code-Scraper, wenn Sie mehr Kontrolle über Aufgaben, Planung oder Cloud-Ausführungen brauchen, ohne Code zu schreiben.
- Wählen Sie eine API-Plattform, wenn Ihr Team Rendering, Proxy-Rotation, Anti-Bot-Handling oder die Einbindung in ein internes Produkt braucht.
- Wählen Sie eine Open-Source-Bibliothek, wenn Sie volle Kontrolle wollen und Wartung, Selektoren, Infrastruktur und Fehler selbst verantworten können.
Dieser Artikel listet alle 20 Tools auf, aber die Empfehlung ist bewusst einfach gehalten: Beginnen Sie mit dem leichtesten Tool, das Ihren Workflow zuverlässig abbilden kann, und wechseln Sie erst dann auf einen tieferen Stack, wenn Wartung, Blockaden oder Skalierung Sie dazu zwingen.
Schneller Vergleich: Die besten Web-Scraping-Tools in 2026
Preise und Planmodelle wurden unten am 7. Mai 2026 anhand der offiziellen Produkt- oder Preisseiten geprüft. Wo Anbieter nutzungsbasierte Abrechnung oder individuelle Enterprise-Angebote verwenden, beschreibe ich das Preismodell, statt so zu tun, als gäbe es einen überall verlässlichen Listenpreis.
| Tool | Typ | Am besten geeignet für | Warum es in die Liste 2026 aufgenommen wurde | Preismodell (geprüft im Mai 2026) |
|---|---|---|---|---|
| Thunderbit | KI-Web-Scraper | Sales, Ops, E-Commerce, Immobilien | Schnellster Weg für Nicht-Programmierer; KI-Feldvorschläge, Unterseiten, Exporte, Browser- und Cloud-Workflow | Kostenloser Tarif, kostenpflichtige Pläne, individuelle Business-Preise |
| Browse AI | KI-Web-Scraper | Business-Nutzer, die Websites überwachen | Starke No-Code-Roboter, Monitoring und Ausgaben im Tabellen- oder API-Stil | Kostenloser Plan, kostenpflichtige Pläne, Premium-Managed-Tier |
| Bardeen | KI-Automatisierung + Scraping | Revenue Ops und Browser-Workflows | Besser, wenn Scraping nur ein Schritt in einem größeren Automatisierungs-Workflow ist | Kostenloser Plan und kostenpflichtige Pläne |
| Diffbot | KI-Extraktionsplattform | Enterprise- und Datenteams | Stärkste Wahl für KI-Extraktion plus strukturierte Daten-Workflows im großen Maßstab | Enterprise-Preismodell |
| Instant Data Scraper | Leichter Browser-Scraper | Gelegenheitsnutzer und schnelle Tabellenextraktion | Immer noch eine der einfachsten Möglichkeiten, eine sichtbare Liste oder Tabelle schnell nach CSV zu ziehen | Kostenlos |
| Octoparse | No-Code-Scraper | Analysten und Ops-Teams mit größeren, wiederkehrenden Jobs | Ausgereifter visueller Builder mit Cloud-Extraktion, Anti-Blocking und Vorlagen | Kostenloser Plan, kostenpflichtig ab 69 $/Monat, Enterprise individuell |
| ParseHub | Low-Code-Scraper | Analysten, die Logik und Desktop-Kontrolle brauchen | Flexible Projektlogik und verschachtelte Navigation, aber steilere Lernkurve als bei neueren KI-first-Tools | Kostenloser Plan und kostenpflichtige Pläne |
| Web Scraper | No-Code-Scraper | Einsteiger und leichte Cloud-Jobs | Guter Einstieg, wenn Sie Sitemap-basiertes Scraping und Browser-first-Setup mögen | Kostenlose Erweiterung, kostenpflichtige Cloud-Pläne |
| Data Miner | Browser-Scraper | Forschende und Growth-Teams | Weiterhin nützlich für schnelle, rezeptbasierte Extraktion direkt im Browser | Kostenloser Plan und kostenpflichtige Pläne |
| Apify | API- + Actor-Plattform | Technische Teams und hybride Operatoren | Hervorragendes Actor-Ökosystem plus Custom Runtime, wenn Browser-Erweiterungen nicht mehr reichen | Kostenloser Plan, Starter ab 29 $/Monat plus Nutzung, größere Tarife |
| ScrapingBee | Scraping-API | Entwickler, die JS-lastige Seiten scrapen | Gute Wahl, wenn Sie Rendering und Proxy-Handling wollen, ohne die Browserverarbeitung selbst aufzubauen | Kostenlose Testphase und kostenpflichtige Pläne |
| ScraperAPI | Scraping-API | Entwickler, die schnell skalieren wollen | Einfache API, Testguthaben, strukturierte Produkte und leichteres Auslagern der Infrastruktur | 7-Tage-Test mit 5.000 Credits, kostenpflichtig ab 49 $/Monat |
| Bright Data | Enterprise-API + Proxy-Plattform | Hochvolumige, compliance-sensible Programme | Breiterste Daten-Stack-Lösung, wenn Unblocking, Proxies und Managed Acquisition wichtiger sind als Einfachheit | Nutzungsbasierte und produktbasierte Preise |
| Oxylabs | Enterprise-API + Proxy-Plattform | Teams, die Scraping als Infrastruktur einkaufen | Stark für groß angelegte Datenerhebung, besonders bei Preis-, SEO- und Marktforschung | Web Scraper API ab 49 $/Monat; breitere Proxy-Preise variieren |
| Zyte | API + Anti-Bot-Stack | Entwickler- und Datenteams | Gute Wahl für API-first-Extraktion mit starken Browser-, Rotations- und Anti-Detection-Mechanismen | Test mit 5 $ Gratisguthaben, nutzungsbasierte Verpflichtungen |
| Selenium | Open-Source-Browser-Automatisierung | QA-artige Automatisierung und komplexe Interaktionsabläufe | Weiterhin nützlich, wenn die Genauigkeit der Benutzerinteraktion wichtiger ist als der Durchsatz | Kostenlos und Open Source |
| BeautifulSoup4 | Open-Source-Parser | Einsteiger und leichtgewichtige Parsing-Aufgaben | Am besten als Parser in einem einfachen Stack, nicht als vollständige Scraping-Plattform | Kostenlos und Open Source |
| Scrapy | Open-Source-Crawling-Framework | Produktionsreife, individuelle Crawler | Beste Balance aus Leistung und Reife, wenn Sie die Pipeline selbst betreiben wollen | Kostenlos und Open Source |
| Puppeteer | Open-Source-Browser-Automatisierung | Node-orientiertes Scraping und Browser-Scripting | Ideal, wenn Ihr Team ohnehin im Chrome-/Node-Ökosystem zu Hause ist | Kostenlos und Open Source |
| Playwright | Open-Source-Browser-Automatisierung | Moderne Automatisierung über mehrere Browser | Oft die sauberste Wahl für moderne Browser-Automatisierung mit starker Developer-Ergonomie | Kostenlos und Open Source |
Wie ich diese Tools bewertet habe
Ich habe vier Kriterien verwendet:
- Zeit bis zum ersten erfolgreichen Scrape
Wenn ein nicht-technischer Anwender schnell keine brauchbaren Daten bekommt, ist das relevant. - Wartungsaufwand
Schnelles Setup ist wertlos, wenn der Workflow bei jeder Website-Änderung bricht. - Skalierungsgrenze
Manche Tools sind ideal für 50 Seiten pro Woche und schlecht für 5 Millionen Requests pro Monat. - Workflow-Fit
Das beste Tool für ein Revenue-Ops-Team ist selten das beste Tool für ein Data-Platform-Team.
Das Ergebnis ist kein allgemeines Ranking. Es ist eine Entscheidungsseite, um zuerst die richtige Tool-Klasse zu wählen und erst dann das passende Produkt innerhalb dieser Klasse.
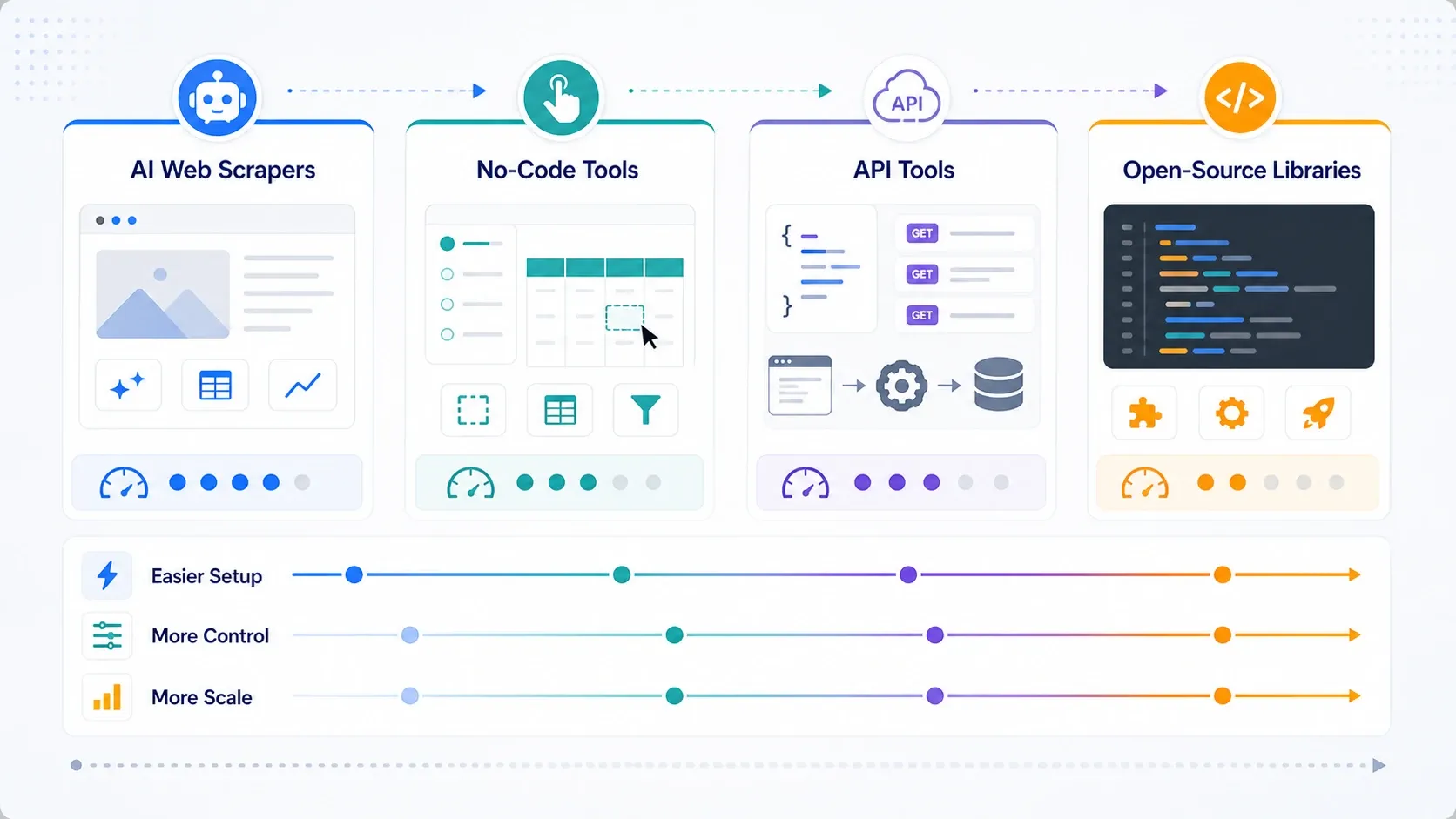
Welche Art von Web-Scraping-Tool brauchen Sie eigentlich?
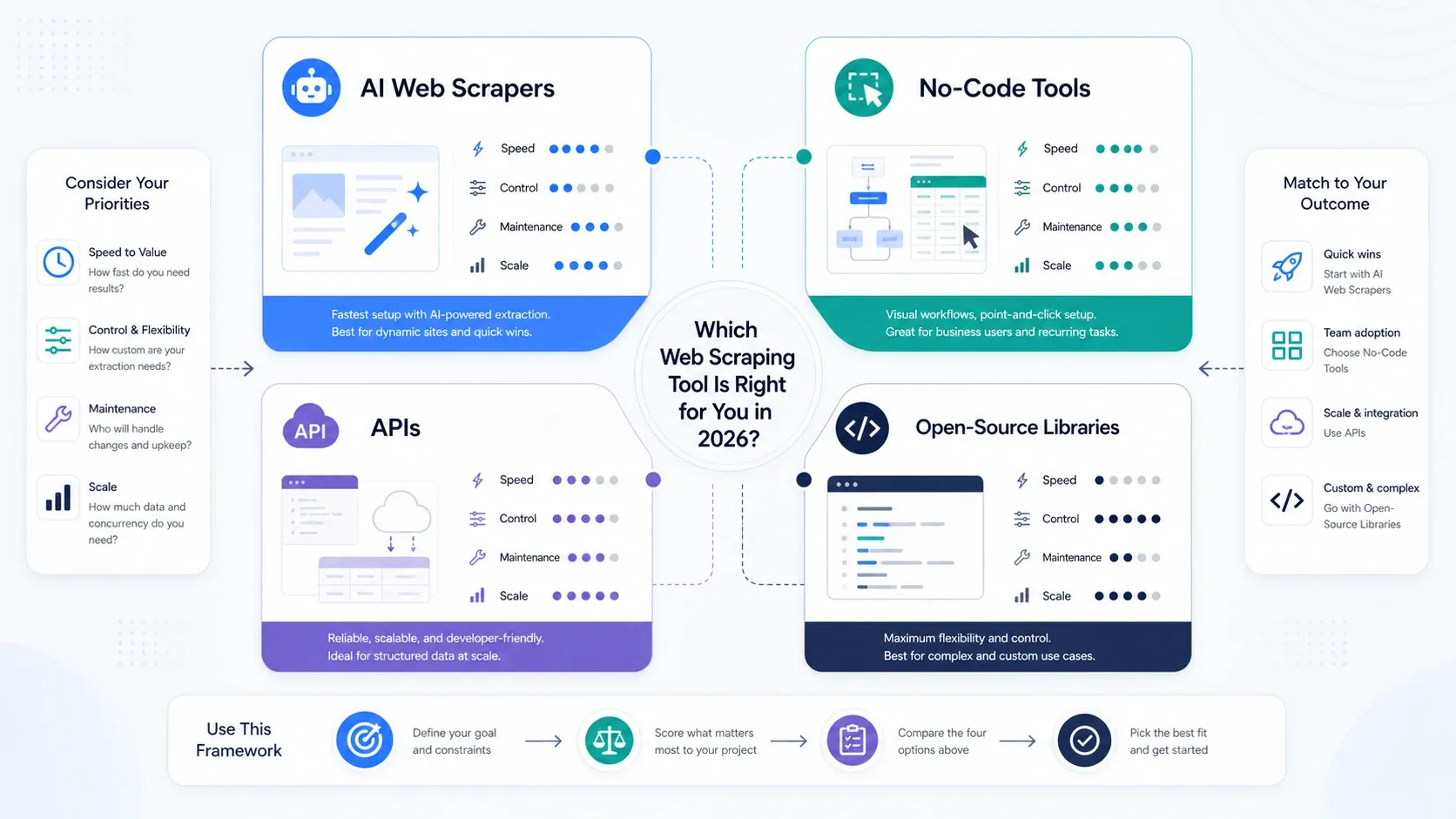
- Wählen Sie KI-Web-Scraper, wenn Ihr Hauptziel operative Geschwindigkeit ist.
- Wählen Sie No-Code-Tools, wenn Sie mehr Paginierung, Planung und wiederholbare Kontrolle über Aufgaben brauchen.
- Wählen Sie APIs und Scraping-Plattformen, wenn Rendering, Rotation und Unblocking inzwischen der Engpass sind.
- Wählen Sie Open-Source-Bibliotheken, wenn Ihrem Team Kontrolle wichtiger ist als Bequemlichkeit und Sie den Stack intern unterstützen können.
Wenn Ihr Team noch zwischen Ops und Engineering für das Scraping entscheidet, starten Sie zunächst mit einem KI- oder No-Code-Tool. Sie lernen schneller, worauf es ankommt, wenn Sie echte Jobs laufen lassen, statt den Stack von Anfang an zu überarchitekturieren.
Die besten KI-Web-Scraper für Business-Teams
Das sind die Tools, die ich mir zuerst ansehen würde, wenn das Ziel möglichst datenfertige Tabellen bei minimalem Setup ist.
1. Thunderbit
Thunderbit ist hier die einfachste Option, wenn Ihr Team strukturierte Daten extrahieren will, ohne Selektoren, Browser-Scripting oder Scraping-Infrastruktur lernen zu müssen. Der Workflow basiert auf KI-Feldvorschlägen, Anreicherung über Unterseiten und dem direkten Export in die Tools, in denen Business-Nutzer ohnehin arbeiten.
- Am besten für: Sales, Ops, E-Commerce, Immobilien und andere browserlastige Teams.
- Warum es heraussticht: Es verkürzt die Einrichtungszeit für Nicht-Programmierer besser als jedes andere Tool auf dieser Liste.
- Achtung: Wenn Sie tiefe benutzerdefinierte Crawler-Logik oder hochspezialisierte technische Kontrolle brauchen, werden Sie später auf einen tieferen Stack wechseln.
- Preismodell: kostenloser Tarif, Self-Service-Paid-Pläne und Business-Preise.
2. Browse AI
Browse AI bleibt eine starke Wahl für Business-Nutzer, die Point-and-Click-Setup plus wiederkehrendes Monitoring wollen. Das Robotermodell ist besonders nützlich, wenn Scraping und Änderungsdetektion gleichermaßen wichtig sind.
- Am besten für: Preisseiten, Wettbewerberseiten und wiederholbare Listenextraktion.
- Warum es heraussticht: gelungenes Onboarding, vorgefertigte Roboter und ein klarer Weg von der Website zur Tabelle oder zu einem API-ähnlichen Output.
- Achtung: komplexe, hochvolumige Jobs können schneller teuer oder organisatorisch umständlich werden als bei API-first-Stacks.
- Preismodell: kostenloser Plan, kostenpflichtige Pläne, Premium-/Managed-Tier.
3. Bardeen
Bardeen ist am überzeugendsten, wenn Scraping nur eine Aktion innerhalb eines größeren Browser-Automatisierungsflusses ist. Wenn Sie Daten in CRMs, Tabellen oder Outbound-Workflows verschieben, zählt der Automatisierungsaspekt mehr als die reine Scraping-Tiefe.
- Am besten für: Revenue Ops, Lead-Workflows und browsernative Aufgabenautomatisierung.
- Warum es heraussticht: stärkere Workflow-Automatisierung als reine Extraktions-Tools.
- Achtung: Es ist nicht die sauberste Wahl, wenn das Scraping selbst komplex und geschäftskritisch ist.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
4. Diffbot
Diffbot ist für Teams gedacht, die KI-Extraktion in Enterprise-Größe brauchen, nicht für Nutzer, die den günstigsten oder einfachsten Weg suchen. Es ergibt vor allem dann Sinn, wenn Qualität strukturierter Daten und große Ingest-Mengen wichtiger sind als manuelle Kontrolle.
- Am besten für: Enterprise-Datenteams, Content Intelligence und große Extraktionsprogramme.
- Warum es heraussticht: Computer-Vision-ähnliche Extraktion und starke Ausrichtung auf strukturierte Ausgaben.
- Achtung: überdimensioniert für kleine Teams und sperrig, wenn der Anwendungsfall eher leichtgewichtig ist.
- Preismodell: Enterprise-Tarife und individueller Vertriebsprozess.
5. Instant Data Scraper
Instant Data Scraper gehört trotzdem auf die Liste, weil es viele Situationen gibt, in denen man einfach die sichtbare Tabelle, das Verzeichnis oder die Liste sofort braucht. Es ist keine Plattform, aber oft reicht es völlig aus.
- Am besten für: einmalige Extraktion, schnelle Lead-Listen, einfache Verzeichnisse und sichtbare Tabellen.
- Warum es heraussticht: nahezu keine Reibung auf den passenden Seiten.
- Achtung: begrenzte Automatisierung, begrenzte Tiefe und schwacher Fit für fortgeschrittene Workflows.
- Preismodell: kostenlos.
Die besten No-Code-Web-Scraping-Tools für wiederholbare Jobs
Sobald es mehr ist als ein gelegentliches Scrape, werden visuelle Builder und Cloud-Ausführung wichtig.
6. Octoparse
Octoparse bleibt eine der stärksten No-Code-Plattformen, wenn Sie Cloud-Runs, Vorlagenabdeckung und ein anspruchsvolleres Aufgabenmanagement brauchen, als es eine Browser-Erweiterung bieten kann.
- Am besten für: Analysten, Preis-Teams und Operatoren mit wiederkehrenden Datenerhebungsjobs.
- Warum es heraussticht: ausgereifter Task-Builder, Cloud-Extraktion, Anti-Blocking-Funktionen und ein großes Vorlagen-Ökosystem.
- Achtung: leistungsfähiger als KI-first-Browser-Tools, aber dadurch auch mit mehr Einrichtungsaufwand verbunden.
- Preismodell: kostenloser Plan, kostenpflichtig ab 69 $/Monat, Enterprise individuell.
7. ParseHub
ParseHub ist weiterhin relevant für Nutzer, die mehr Kontrolle als bei einem KI-Scraper wollen, aber keine Codebasis aufbauen möchten. Es belohnt Geduld, nicht Geschwindigkeit.
- Am besten für: Analysten und technisch neugierige Operatoren, die eine steilere Lernkurve akzeptieren können.
- Warum es heraussticht: flexible Navigationslogik und mehr Kontrolle als leichte Browser-Tools.
- Achtung: Das Produktgefühl wirkt schwerer als bei neueren Anbietern, besonders für schnell arbeitende Business-Teams.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
8. Web Scraper
Web Scraper ist weiterhin ein vernünftiger Einstieg, wenn Ihnen das Sitemap-Modell gefällt und Sie etwas wollen, das im Browser startet und später in Cloud-Planung hineinwächst.
- Am besten für: Einsteiger, Hobbyprojekte und kleinere wiederholbare Jobs.
- Warum es heraussticht: zugänglicher Sitemap-Workflow und einfache Browser-first-Einführung.
- Achtung: wird einschränkend, sobald Sie adaptivere Extraktionslogik brauchen.
- Preismodell: kostenlose Browser-Erweiterung und kostenpflichtige Cloud-Pläne.
9. Data Miner
Data Miner versteht sich am besten als schnelles Extraktionswerkzeug und nicht als vollständige Scraping-Plattform. Es verdient dennoch einen Platz, weil rezeptbasierte Arbeit für viele Recherche- und Prospecting-Aufgaben nützlich ist.
- Am besten für: Forschende, Growth-Teams und schnelle Exporte direkt aus dem Browser.
- Warum es heraussticht: Rezeptmodell, wenig Reibung und einfacher Browser-Export.
- Achtung: nicht das richtige Tool für ernsthaftes Scraping auf Plattformniveau.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
Die besten API-Plattformen, wenn Skalierung und Blockaden zum echten Problem werden
Das ist die Ebene, auf der Engineering-Teams aufhören zu fragen: „Wie scrape ich diese Seite?“ — und anfangen zu fragen: „Wie mache ich das in groß zuverlässig?“
10. Apify
Apify ist in dieser Gruppe die flexibelste Plattform, wenn Sie sowohl einen Marktplatz wiederverwendbarer Scraper als auch einen Ort zum Ausführen eigenen Codes wollen. Sie verbindet No-Code-Entdeckung und Entwicklerausführung besser als die meisten Wettbewerber.
- Am besten für: hybride Teams, entwicklergetriebenes Scraping und wiederverwendbare Automatisierungs-Workflows.
- Warum es heraussticht: Actor-Ökosystem plus Custom Runtime verschaffen ungewöhnliche Bandbreite.
- Achtung: Sobald Sie individuell entwickeln, sind Sie wieder in der Engineering-Welt und der Einfachheitsvorteil schrumpft.
- Preismodell: kostenloser Plan, Starter ab 29 $/Monat plus Nutzung, größere Nutzungstiers und Enterprise.
11. ScrapingBee
ScrapingBee ist eine gute Wahl, wenn Ihr eigentliches Bedürfnis lautet: „Gib mir eine gerenderte Seite und nimm mir die hässliche Infrastruktur ab.“ Es passt gut zu JS-lastigen Zielen.
- Am besten für: Entwickler, die dynamische Seiten scrapen und wenig Infrastrukturarbeit wollen.
- Warum es heraussticht: einfache API für Rendering, Proxies und Browser-Automatisierung.
- Achtung: Es ist ein Infrastrukturdienst, daher bleiben Parsing, Retry-Logik und nachgelagerte Datenqualität bei Ihnen.
- Preismodell: Testphase und kostenpflichtige Pläne.
12. ScraperAPI
ScraperAPI ist weiterhin eine der einfachsten Möglichkeiten, Proxy-Management und Erfolgsraten bei Requests auszulagern, wenn Sie schnell skalieren wollen.
- Am besten für: Entwickler, die schnell vom Prototypen zum Volumen kommen müssen.
- Warum es heraussticht: einfache API, Testguthaben, strukturierte Produkte und Skalierungsstufen.
- Achtung: Wie bei allen API-first-Produkten entfällt nicht die Notwendigkeit technischer Entscheidungen zu Parsing und Datenvalidierung.
- Preismodell: 7-Tage-Test mit 5.000 Credits, kostenpflichtig ab 49 $/Monat.
13. Bright Data
Bright Data ist die Schwergewichtslösung, wenn Unblocking-Fähigkeit, Proxy-Inventar und Managed Acquisition wichtiger sind als Tool-Einfachheit.
- Am besten für: Enterprise-Programme, compliance-sensitive Datenerhebung im großen Maßstab und Managed Data Acquisition.
- Warum es heraussticht: Breite an Proxy-, Scraper-, Browser- und Datensatz-Produkten.
- Achtung: teuer und leicht zu überkaufen, wenn Ihr Kernworkflow noch relativ einfach ist.
- Preismodell: nutzungsbasierte und produktbasierte Preise für APIs, Proxies und Managed Services.
14. Oxylabs
Oxylabs bleibt eine starke Wahl für Teams, die Scraping als Infrastruktur einkaufen und nicht als Browser-Tool. Besonders relevant ist das, wenn Zuverlässigkeit und Reife im Einkauf entscheidend sind.
- Am besten für: Enterprise-Erhebung, Preisüberwachung, SEO-Monitoring und Marktforschung.
- Warum es heraussticht: robuste Infrastruktur, große Proxy-Tiefe und ein klareres Enterprise-Beschaffungsmodell.
- Achtung: nicht ideal, wenn Ihr Team einen lockeren Self-Service-Workflow möchte.
- Preismodell: Web Scraper API ab 49 $/Monat; andere Produkte variieren nach Einheit und Nutzung.
15. Zyte
Zyte verdient weiterhin ernsthafte Beachtung von Entwickler- und Datenteams, die Anti-Detection, Browser-Aktionen, JS-Rendering und rotierende IPs in einem einzigen API-first-Ansatz wollen.
- Am besten für: technische Teams, die wiederholbare Extraktionssysteme aufbauen.
- Warum es heraussticht: Browser-Aktionen, JS-Rendering, IP-Rotation und Anti-Bot-Strategie in einem Stack.
- Achtung: besser für Teams mit Engineering-Verantwortung als für nicht-technische Operatoren.
- Preismodell: Test mit 5 $ Gratisguthaben und nutzungsbasierten monatlichen Verpflichtungen.
Die besten Open-Source-Bibliotheken für Entwickler mit vollem Kontrollanspruch
Wenn Sie den Scraper-Stack von Anfang bis Ende selbst besitzen wollen, sind das 2026 die nützlichsten Bausteine.
16. Selenium
Selenium ist weiterhin nützlich, wenn Sie Interaktionsgenauigkeit im QA-Stil, ältere Browser-Automatisierungs-Workflows oder sehr explizite Kontrolle über Benutzerabläufe brauchen.
- Am besten für: interaktionslastige Automatisierung, QA-Überschneidungen und Websites, bei denen Browserverhalten wichtiger ist als Crawling-Durchsatz.
- Warum es heraussticht: ausgereiftes Ökosystem und breite Browserunterstützung.
- Achtung: für viele Scraping-Workloads schwerer und langsamer als neuere Browser-Tools.
- Preismodell: kostenlos und Open Source.
17. BeautifulSoup4

BeautifulSoup ist keine vollständige Scraping-Plattform, bleibt aber eine der einfachsten Möglichkeiten, unsauberes HTML in leichten Workflows zu parsen.
- Am besten für: Einsteiger, kurze Skripte und Parser-first-Aufgaben.
- Warum es heraussticht: einfache API und geringe kognitive Last.
- Achtung: Mit Request-, Browser- oder Crawler-Tools kombinieren; allein ist es nur ein Parser.
- Preismodell: kostenlos und Open Source.
18. Scrapy
Scrapy ist weiterhin die beste Antwort, wenn Sie ein echtes Crawler-Framework brauchen statt ein paar Skripte.
- Am besten für: produktionsreife individuelle Crawler und intern verantwortete Datenpipelines.
- Warum es heraussticht: hohe Performance, Pipelines, Middleware und langfristige Erweiterbarkeit.
- Achtung: echter Engineering-Overhead, und JS-lastige Ziele brauchen oft ergänzende Tools.
- Preismodell: kostenlos und Open Source.
19. Puppeteer
Puppeteer bleibt eine starke Wahl für Node-first-Teams, die direkte Kontrolle über Chromium und Browser-Scripting wollen.
- Am besten für: Node-basiertes Scraping, Screenshots und Browser-Automatisierungsaufgaben.
- Warum es heraussticht: direkte, leistungsstarke Kontrolle über das Verhalten von Chromium.
- Achtung: engere Browser-Abdeckung als Playwright und in großem Maßstab weiterhin ressourcenhungrig.
- Preismodell: kostenlos und Open Source.
20. Playwright
Playwright ist meine Standardempfehlung für moderne Browser-Automatisierung, wenn Ihr Team Code schreibt und eine neuere Abstraktion als Selenium möchte.
- Am besten für: moderne Browser-Automatisierung, JS-lastige Seiten und Teams, denen Developer-Ergonomie wichtig ist.
- Warum es heraussticht: starkes Multi-Browser-Modell, zuverlässiges Warten und saubere APIs.
- Achtung: Browser-Infrastruktur, Parallelisierung, Selector-Drift und Datenvalidierung bleiben trotzdem Ihre Verantwortung.
- Preismodell: kostenlos und Open Source.
Meine Shortlist nach Teamtyp
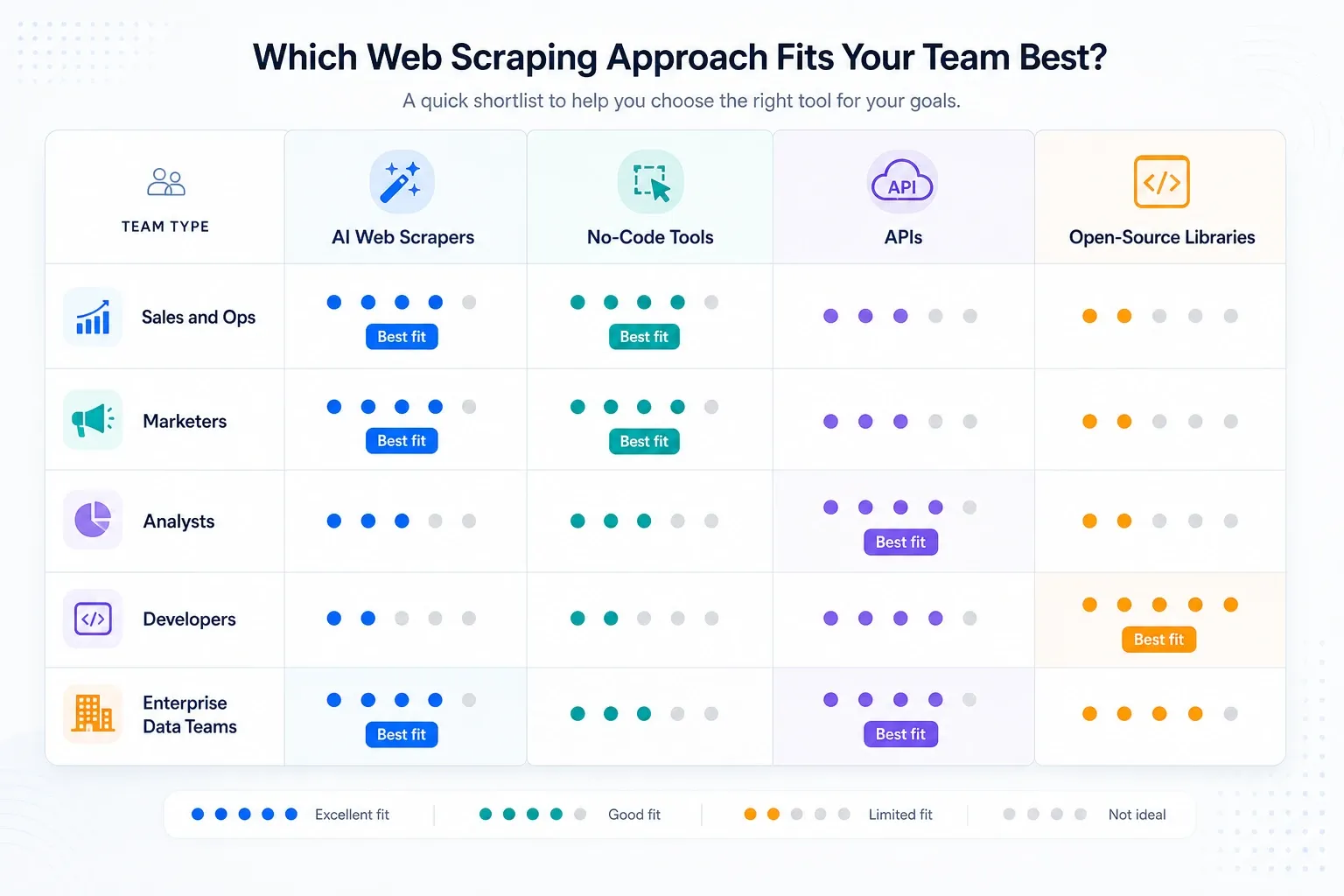
- Sales- und Ops-Teams: Starten Sie mit Thunderbit und schauen Sie sich dann Browse AI an, wenn Monitoring wichtiger ist als Unterseiten-Anreicherung.
- Analysten und Research-Teams: Octoparse zuerst, wenn wiederkehrende Jobs größer sind, als Browser-Erweiterungen bequem abdecken können.
- Automatisierungsstarke GTM-Teams: Bardeen, wenn Scraping nur ein Schritt in einem größeren Workflow ist.
- Entwicklerteams, die interne Tools bauen: Apify, Zyte, ScraperAPI oder Playwright, je nachdem, wie viel Stack-Verantwortung Sie übernehmen wollen.
- Enterprise-Datenprogramme: Bright Data, Oxylabs, Diffbot und Zyte sind die ernsthaften Infrastrukturgespräche.
Wann Sie auf einen tieferen Stack wechseln sollten
Nutzen Sie diese Regel:
- Bleiben Sie bei KI-Tools, bis Sie an Grenzen bei Wiederholbarkeit oder Sonderfällen stoßen.
- Wechseln Sie zu No-Code-Tools, wenn Planung, Paginierung, Anti-Blocking oder Cloud-Runs wichtiger werden als Ein-Klick-Einfachheit.
- Wechseln Sie zu APIs, wenn Unblocking-Rate, JS-Rendering und Parallelisierung zum echten Engpass werden.
- Wechseln Sie zu Open-Source-Bibliotheken, wenn die Kosten für Herstellerabstraktion höher sind als die Kosten, den gesamten Stack selbst zu besitzen.
Die meisten Teams wechseln zu früh auf einen tieferen Stack. Das ist einer der häufigsten Fehler, die ich sehe.
Fazit
Für die meisten nicht-technischen Teams lautet die richtige Antwort 2026 nicht „der stärkste Scraper“. Es ist das Tool, das präzise Daten mit möglichst wenig Wartung in den nächsten Workflow bringt. Deshalb gewinnen KI-first-Tools weiterhin bei Operatoren, während APIs und Open-Source-Stacks für technische Teams mit klaren Skalierungsanforderungen besser passen.
Wenn Sie den kürzesten Weg von der Seite zur strukturierten Ausgabe wollen, starten Sie mit Thunderbit. Wenn Sie schon wissen, dass Ihr Job schwere Infrastruktur braucht, springen Sie direkt auf die API- und Entwickler-Ebene. Verwechseln Sie nur nicht Komplexität mit Raffinesse.
FAQs
1. Was ist 2026 das beste Web-Scraping-Tool für nicht-technische Nutzer?
Für die meisten nicht-technischen Nutzer bieten KI-first-Tools wie Thunderbit und Browse AI den schnellsten Weg zu brauchbaren Daten, weil sie Selektorenarbeit, Setup-Reibung und Wartungsaufwand reduzieren.
2. Was sollte ich wählen, wenn meine Websites stark auf JavaScript setzen oder Anfragen aggressiv blockieren?
Gehen Sie je nach gewünschtem Grad an Managed Service oder direkter technischer Kontrolle in Richtung ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright oder Selenium.
3. Sind No-Code-Tools noch relevant, jetzt wo KI-Web-Scraper besser sind?
Ja. No-Code-Tools wie Octoparse und ParseHub sind weiterhin wichtig, wenn Sie mehr explizite Kontrolle über Aufgabenlogik, Cloud-Ausführung und wiederholbares Job-Management brauchen.
4. Welche Tools passen für Engineering-Teams am besten?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer und Selenium sind die naheliegendsten Optionen, wenn Entwickler den Workflow besitzen.
5. Wie stelle ich schnell eine Shortlist zusammen, ohne zu viel zu recherchieren?
Wählen Sie zuerst die Tool-Klasse, nicht den Anbieter. Entscheiden Sie, ob Sie KI-Einfachheit, No-Code-Kontrolle, API-Infrastruktur oder Open-Source-Verantwortung brauchen. Vergleichen Sie dann die Produkte innerhalb dieser Ebene.
Weiterlesen