Das Web quillt über vor Daten – aber der Haken ist: Sie manuell zu erfassen macht ungefähr so viel Spaß wie beim Trocknen von Farbe zuzusehen und ist ebenso wenig produktiv. 2025 schwimmen Unternehmen in mehr Webinhalten als je zuvor; der tägliche Webdatenverbrauch eines durchschnittlichen Unternehmens ist von 1,2 TB im Jahr 2020 auf 8 TB im Jahr 2025 gestiegen (). Ob Vertrieb, Marketing, E-Commerce oder Operations: Der Bedarf an schnellen, strukturierten und präzisen Webdaten ist nicht einfach nur „nice to have“ – er ist operativ unverzichtbar. Und seien wir ehrlich: Niemand hat Zeit für endlose Copy-Paste-Marathons.
Genau deshalb sind Content-Crawling-Tools so stark im Kommen. Diese Tools – von KI-gestützten Chrome-Erweiterungen bis hin zu Enterprise-Plattformen – automatisieren den gesamten Prozess und verwandeln chaotische Webseiten in saubere Tabellen, Datenbanken oder Echtzeit-Dashboards. Ich arbeite seit Jahren in SaaS und Automatisierung und kann Ihnen sagen: Das richtige Tool spart nicht nur Zeit, sondern kann die Arbeitsweise Ihres Teams grundlegend verändern. Schauen wir uns also die Top 18 Content-Crawling-Tools für effizientes Web-Scraping 2025 an – mit Fokus darauf, was jedes Tool einzigartig macht, wie es zu unterschiedlichen Geschäftsanforderungen passt und wie Sie die beste Lösung für Ihren Workflow auswählen.
Warum Unternehmen Top-Content-Crawling-Tools brauchen
Wer schon einmal per Hand eine Lead-Liste aufgebaut, Wettbewerberpreise überwacht oder die Marktstimmung beobachtet hat, weiß, wie schnell manuelle Datenerfassung zum Albtraum wird. Sie ist langsam, fehleranfällig, und bis Sie fertig sind, sind Ihre Daten womöglich schon veraltet. Deshalb haben über 70 % der Unternehmen bis 2025 automatisierte Web-Extraktion eingeführt und den manuellen Aufwand um rund 60 % gesenkt ().
Content-Crawling-Tools automatisieren die Extraktion strukturierter Daten von Websites und machen Folgendes möglich:
- Frische Leads direkt ins CRM einspeisen (kein Copy-Paste mehr aus Verzeichnissen)
- Wettbewerberpreise und Lagerbestände in Echtzeit überwachen
- Bewertungen, Nachrichten und Social-Media-Erwähnungen bündeln für Marketing-Insights
- Individuelle Datensätze für Research oder Analytics aufbauen
- Wiederkehrende Datenabrufe planen für laufendes Reporting
Und der ROI ist real: Unternehmen, die Web-Scraping einsetzen, meldeten zwischen 2020 und 2025 gemeinsame Einsparungen von über 500 Millionen US-Dollar, bei gleichzeitig 20–40 % mehr operativer Effizienz (). Die Quintessenz? Content-Crawling-Tools entlasten Ihr Team, damit es sich auf Strategie statt auf Fleißarbeit konzentrieren kann.
Wie wir die Top-Content-Crawling-Tools ausgewählt haben
Nicht alle Web-Scraper sind gleich. Bei dieser Liste habe ich die Tools durch die Brille echter Business-User betrachtet – Vertriebs-, Marketing-, Ops- und Research-Teams, die Ergebnisse brauchen und keine Kopfschmerzen. Darauf kam es mir am meisten an:
- Einfache Bedienung: Können auch Nicht-Techniker schnell loslegen? Gibt es eine Point-and-Click-Oberfläche oder KI-Unterstützung?
- Automatisierung & Funktionen: Unterstützt das Tool Pagination, Unterseiten, Zeitplanung und dynamische Inhalte? Läuft es in der Cloud für mehr Tempo und Skalierung?
- Datenexport & Integration: Kann man nach Excel, CSV, Google Sheets, Airtable, Notion exportieren oder per API anbinden?
- Skalierbarkeit: Eignet es sich für einmalige Aufgaben oder große, laufende Projekte?
- Anpassbarkeit: Lässt sich die Extraktionslogik anpassen, kann man eigene Felder hinzufügen oder knifflige Websites verarbeiten?
- Compliance & Datenschutz: Hilft das Tool dabei, GDPR, CCPA und die Nutzungsbedingungen der Websites einzuhalten?
- Support & Community: Gibt es Dokumentation, Support oder eine Nutzer-Community zur Fehlerbehebung?
- Kosten: Gibt es einen kostenlosen Tarif oder eine Testphase? Passt die Preisgestaltung zu Umfang und Budget?
Und natürlich habe ich Thunderbit besonders hervorgehoben – das Tool, das mein Team und ich entwickelt haben – weil ich wirklich glaube, dass es für Business-User der einfachste Einstieg ins KI-gestützte Web-Scraping ist.
Top 18 Content-Crawling-Tools für effizientes Web-Scraping
Schauen wir uns die Besten der Besten an – von KI-gestützter Einfachheit über Entwickler-Powerhouses bis hin zu allem dazwischen.
1. Thunderbit
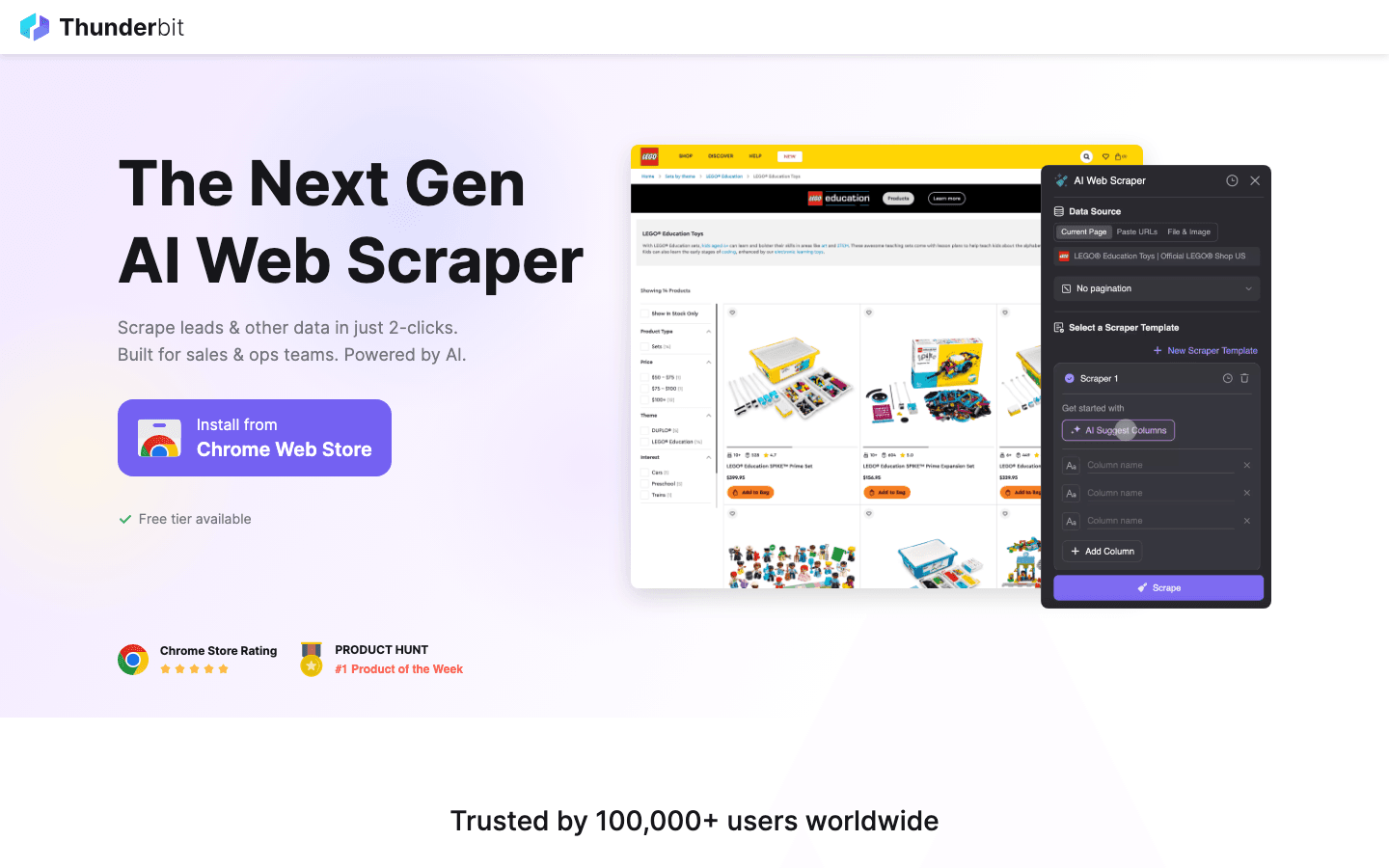 ist eine KI-Web-Scraper-Chrome-Erweiterung für Business-User, die schnell Ergebnisse wollen. Das herausragende Feature ist AI Suggest Fields: einfach eine Webseite öffnen, auf „AI Suggest“ klicken, und die KI von Thunderbit liest die Seite, schlägt zu extrahierende Felder vor und richtet den Scraper für Sie ein. Kein Code, kein Herumprobieren mit Selektoren – einfach klicken, scrapen und exportieren.
ist eine KI-Web-Scraper-Chrome-Erweiterung für Business-User, die schnell Ergebnisse wollen. Das herausragende Feature ist AI Suggest Fields: einfach eine Webseite öffnen, auf „AI Suggest“ klicken, und die KI von Thunderbit liest die Seite, schlägt zu extrahierende Felder vor und richtet den Scraper für Sie ein. Kein Code, kein Herumprobieren mit Selektoren – einfach klicken, scrapen und exportieren.
- Unterseiten-Scraping: Thunderbit kann automatisch jede Unterseite besuchen (z. B. Produkt- oder Profildetails) und Ihren Datensatz anreichern – perfekt für Lead-Generierung oder E-Commerce-Recherche.
- Pagination & Vorlagen: Verarbeitet Listen über mehrere Seiten und bietet sofort nutzbare Vorlagen für Websites wie Amazon, Zillow und Instagram.
- Kostenloser Datenexport: Export nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON – ohne Paywall.
- KI-Autofill: Automatisiert das Ausfüllen von Online-Formularen mit KI und geht damit über Scraping hinaus in Richtung Workflow-Automatisierung.
- Cloud- und Browser-Scraping: Wählen Sie schnelles Cloud-Scraping für öffentliche Websites oder den Browser-Modus für eingeloggte Sitzungen.
- Preis: Kostenlos für bis zu 6 Seiten (oder 10 mit Testversion), kostenpflichtige Pläne ab nur 15 $/Monat.
Thunderbit ist ideal für Vertriebs-, Marketing- und Operations-Teams, die Datenerfassung ohne technische Hürden automatisieren wollen. Es ist das Tool, das ich mir schon vor Jahren gewünscht hätte – heute kann jeder in Minuten eine Lead-Liste erstellen oder Wettbewerber überwachen.
2. Scrapy
 ist das Open-Source-Kraftpaket für Entwickler. Es handelt sich um ein Python-basiertes Framework, mit dem Sie eigene Spider schreiben können, um Daten in großem Maßstab zu crawlen und zu extrahieren. Scrapy ist auf Geschwindigkeit und Flexibilität ausgelegt und unterstützt asynchrones Crawling, eigene Pipelines, Proxy-Rotation sowie Integrationen mit Datenbanken oder APIs.
ist das Open-Source-Kraftpaket für Entwickler. Es handelt sich um ein Python-basiertes Framework, mit dem Sie eigene Spider schreiben können, um Daten in großem Maßstab zu crawlen und zu extrahieren. Scrapy ist auf Geschwindigkeit und Flexibilität ausgelegt und unterstützt asynchrones Crawling, eigene Pipelines, Proxy-Rotation sowie Integrationen mit Datenbanken oder APIs.
- Am besten für: Entwickler und Data Engineers, die große, komplexe oder wiederkehrende Scraping-Projekte aufbauen.
- Stärken: Volle Kontrolle, Erweiterbarkeit, große Community und bewährte Zuverlässigkeit.
- Nachteile: Hohe Einstiegshürde für Nicht-Programmierer; keine visuelle Oberfläche.
Wenn Sie Python beherrschen und robuste, skalierbare Crawler bauen möchten, ist Scrapy der Goldstandard.
3. Octoparse
 ist ein No-Code-Web-Scraper auf Cloud-Basis mit visueller Drag-and-Drop-Oberfläche. Sie können per Point-and-Click Daten auswählen, Pagination einrichten und sogar KI-gestützte Mustererkennung nutzen, um das Setup zu beschleunigen.
ist ein No-Code-Web-Scraper auf Cloud-Basis mit visueller Drag-and-Drop-Oberfläche. Sie können per Point-and-Click Daten auswählen, Pagination einrichten und sogar KI-gestützte Mustererkennung nutzen, um das Setup zu beschleunigen.
- Vorlagen: Extrahiert in Minuten Daten von beliebten Websites wie Amazon, Twitter und Google Maps.
- Cloud-Scraping & Zeitplanung: Läuft auf den Servern von Octoparse, unterstützt wiederkehrende Aufgaben und große Projekte.
- Exportoptionen: CSV, Excel, JSON, API-Integration.
- Preis: Kostenloser Tarif mit Einschränkungen; kostenpflichtige Pläne ab etwa 75 $/Monat.
Octoparse ist ideal für Business-Analysten und Nicht-Programmierer, die leistungsstark scrapen wollen, ohne Code zu schreiben.
4. ParseHub
 ist ein visueller Web-Scraper, der besonders gut mit dynamischen Inhalten und komplexen Website-Strukturen zurechtkommt. Mit der Point-and-Click-Oberfläche können Sie Workflows mit bedingter Logik, Schleifen und mehrstufiger Navigation erstellen.
ist ein visueller Web-Scraper, der besonders gut mit dynamischen Inhalten und komplexen Website-Strukturen zurechtkommt. Mit der Point-and-Click-Oberfläche können Sie Workflows mit bedingter Logik, Schleifen und mehrstufiger Navigation erstellen.
- Dynamische Inhalte: Verarbeitet Dropdowns, unendliches Scrollen und interaktive Elemente.
- Cloud- und lokale Läufe: Projekte in der Cloud (kostenpflichtig) oder lokal für kleinere Aufgaben ausführen.
- Export: CSV, Excel, JSON, API.
- Preis: Großzügiger kostenloser Tarif; kostenpflichtige Pläne ab 49 $/Monat.
ParseHub ist ideal für Nicht-Programmierer, die Flexibilität und Leistung für knifflige Websites brauchen.
5. Data Miner
 ist eine Chrome-/Edge-Erweiterung für schnelles, vorlagenbasiertes Scraping. Mit über 50.000 öffentlichen Extraktions-Rezepten für mehr als 15.000 Websites lässt sich eine Seite oft mit einem Klick scrapen.
ist eine Chrome-/Edge-Erweiterung für schnelles, vorlagenbasiertes Scraping. Mit über 50.000 öffentlichen Extraktions-Rezepten für mehr als 15.000 Websites lässt sich eine Seite oft mit einem Klick scrapen.
- Google-Sheets-Integration: Scraped Daten direkt in Sheets hochladen.
- Eigene Rezepte: Eigene Extraktionslogik per Point-and-Click oder XPath erstellen.
- Pagination & Automatisierung: Verarbeitet mehrseitiges Scraping und geplante Läufe.
- Preis: Kostenloser Tarif; kostenpflichtige Pläne ab 19 $/Monat.
Perfekt für Analysten und Marketer, die schnell kleine bis mittelgroße Datenmengen direkt aus dem Browser erfassen wollen.
6. WebHarvy
 ist eine Windows-Desktop-App mit Point-and-Click-Oberfläche und automatischer Mustererkennung. Einfach ein Element anklicken, und WebHarvy hebt alle ähnlichen Elemente zur Extraktion hervor.
ist eine Windows-Desktop-App mit Point-and-Click-Oberfläche und automatischer Mustererkennung. Einfach ein Element anklicken, und WebHarvy hebt alle ähnlichen Elemente zur Extraktion hervor.
- Unterstützt Bilder, Text, Pagination: Produktfotos, E-Mails, URLs und mehr scrapen.
- Desktop-Zeitplanung: Scrapes auf Ihrem PC planen.
- Einmallizenz: Rund 199 $ pro PC.
Gut geeignet für kleine Unternehmen, die ein einfaches Tool ohne Abo für gelegentliches Scraping suchen.
7. Import.io
 ist eine Enterprise-Plattform auf Cloud-Basis für groß angelegte Datenextraktion. Sie bietet KI-gestützte Datenbereinigung, Echtzeit-Monitoring und robuste Compliance-Funktionen.
ist eine Enterprise-Plattform auf Cloud-Basis für groß angelegte Datenextraktion. Sie bietet KI-gestützte Datenbereinigung, Echtzeit-Monitoring und robuste Compliance-Funktionen.
- API-Integrationen: Daten direkt an Datenbanken, BI-Dashboards oder Anwendungen liefern.
- Compliance: Unter Berücksichtigung von GDPR und CCPA entwickelt.
- Preis: Enterprise-Verträge; gehobenes Preissegment.
Am besten für große Organisationen, die zuverlässige, compliance-konforme und skalierbare Webdaten-Pipelines benötigen.
8. Apify
 ist eine Cloud-Automatisierungsplattform und ein Marktplatz für Web-Scraping-„Actors“ (Bots). Sie können vorgefertigte Actors für gängige Websites nutzen oder eigene in JavaScript oder Python bauen.
ist eine Cloud-Automatisierungsplattform und ein Marktplatz für Web-Scraping-„Actors“ (Bots). Sie können vorgefertigte Actors für gängige Websites nutzen oder eigene in JavaScript oder Python bauen.
- Marktplatz: Hunderte sofort einsetzbare Scraper für Websites wie LinkedIn, Amazon und mehr.
- Zeitplanung & API: Actors ausführen, planen und per API integrieren.
- Preis: Kostenloser Tarif; kostenpflichtige Nutzung ab 49 $/Monat.
Ideal für Entwickler und technikaffine Teams, die Automatisierung, Flexibilität und Community-getriebene Lösungen wollen.
9. Visual Web Ripper
 ist ein Desktop-Tool für fortgeschrittene, großvolumige Datenextraktion. Mit dem Workflow-Builder können Sie mehrstufige Crawls entwerfen und große Projekte automatisieren.
ist ein Desktop-Tool für fortgeschrittene, großvolumige Datenextraktion. Mit dem Workflow-Builder können Sie mehrstufige Crawls entwerfen und große Projekte automatisieren.
- Zeitplanung & Automatisierung: Projekte in festen Intervallen ausführen.
- Datenbank-Integration: Direkt nach SQL, Excel, CSV, XML oder JSON exportieren.
- Einmallizenz: Rund 349 $.
Am besten für IT-Teams oder Power-User, die große Datensätze intern extrahieren müssen.
10. Dexi.io
 ist eine Cloud-basierte Plattform für kollaborative Webdaten-Projekte. Sie bietet Workflow-Automatisierung, Zeitplanung und Funktionen für Teammanagement.
ist eine Cloud-basierte Plattform für kollaborative Webdaten-Projekte. Sie bietet Workflow-Automatisierung, Zeitplanung und Funktionen für Teammanagement.
- Workflow-Automatisierung: Datenpipelines teamübergreifend erstellen und teilen.
- API & Export: Mit Datenbanken, Cloud-Speicher oder BI-Tools verbinden.
- Preis: Individuell; auf Teams und Unternehmen ausgerichtet.
Gut für Organisationen, die laufende, kollaborative Datenprojekte managen.
11. Content Grabber
 ist ein professionelles Scraping-Tool für Agenturen und Unternehmen. Es bietet fortgeschrittene Automatisierung, Fehlerbehandlung und sogar White-Label-Optionen.
ist ein professionelles Scraping-Tool für Agenturen und Unternehmen. Es bietet fortgeschrittene Automatisierung, Fehlerbehandlung und sogar White-Label-Optionen.
- Scripting & Anpassung: Mit C# oder VB.NET für tiefe Kontrolle arbeiten.
- Fehlerbehebung & Logging: Für zuverlässige große Jobs ausgelegt.
- Enterprise-Preis: Oberes Preissegment; kostenlose Testversion verfügbar.
Am besten für Agenturen oder Unternehmen, die für Kunden individuelle, wiederholbare Scraping-Lösungen bauen.
12. Helium Scraper
 ist ein Desktop-Tool, das visuelle Extraktion mit der Flexibilität von Scripting verbindet. Für die meisten Aufgaben nutzen Sie Point-and-Click, bei fortgeschrittener Logik können Sie auf eigenes JavaScript zurückgreifen.
ist ein Desktop-Tool, das visuelle Extraktion mit der Flexibilität von Scripting verbindet. Für die meisten Aufgaben nutzen Sie Point-and-Click, bei fortgeschrittener Logik können Sie auf eigenes JavaScript zurückgreifen.
- Verarbeitet dynamische Inhalte: AJAX-lastige Websites scrapen.
- Datenbereinigung & Transformation: Integriertes Scripting für individuelle Workflows.
- Einmallizenz: Rund 99 $.
Perfekt für Power-User, die Flexibilität ohne Abo wollen.
13. Web Scraper
 ist eine kostenlose Chrome-Erweiterung, die viele überhaupt erst ans Web-Scraping heranführt. Sitemap definieren, Elemente per Klick auswählen und nach CSV oder JSON exportieren.
ist eine kostenlose Chrome-Erweiterung, die viele überhaupt erst ans Web-Scraping heranführt. Sitemap definieren, Elemente per Klick auswählen und nach CSV oder JSON exportieren.
- Mehrstufiges Crawling: Links folgen, Pagination verarbeiten und verschachtelte Daten scrapen.
- Kostenlos für die lokale Nutzung: Kostenpflichtige Cloud-Version für Zeitplanung und Skalierung verfügbar.
Ideal für Einsteiger, Studierende oder alle, die eine schnelle, kostenlose Lösung für kleinere Aufgaben brauchen.
14. Mozenda
 ist eine Enterprise-Cloud-Plattform mit Fokus auf Compliance, Skalierbarkeit und Managed Services. Mit der Point-and-Click-Oberfläche können Sie „Agents“ für die Datenextraktion erstellen.
ist eine Enterprise-Cloud-Plattform mit Fokus auf Compliance, Skalierbarkeit und Managed Services. Mit der Point-and-Click-Oberfläche können Sie „Agents“ für die Datenextraktion erstellen.
- Managed Services: Das Mozenda-Team kann Scraper für Sie bauen und betreiben.
- Compliance & Support: Starker Fokus auf GDPR, CCPA und Enterprise-Anforderungen.
- Preis: Ab etwa 500 $/Monat.
Am besten für große Organisationen, die eine schlüsselfertige, skalierbare Webdaten-Lösung mit starkem Support suchen.
15. SimpleIndex
 ist ein Automatisierungstool für Dokumenten- und Webdatenextraktion mit Schwerpunkt auf OCR und Indexierung.
ist ein Automatisierungstool für Dokumenten- und Webdatenextraktion mit Schwerpunkt auf OCR und Indexierung.
- Screen-Scraping-OCR: Daten aus gescannten Dokumenten, PDFs oder sogar sichtbaren Webformularen extrahieren.
- Integration: Ausgabe an Datenbanken oder Dokumentenmanagementsysteme.
- Einmallizenz: Einige hundert Dollar pro Arbeitsplatz.
Gut für Organisationen, die Dokumenten- und Webdaten-Workflows kombinieren.
16. Spinn3r
 ist eine Echtzeit-Content-Crawling-Plattform für Blogs, Nachrichten und Social Media. Die Firehose API liefert einen kontinuierlichen Strom neuer Inhalte aus Millionen von Quellen.
ist eine Echtzeit-Content-Crawling-Plattform für Blogs, Nachrichten und Social Media. Die Firehose API liefert einen kontinuierlichen Strom neuer Inhalte aus Millionen von Quellen.
- Spam-Filterung & Sprachverarbeitung: Saubere, strukturierte Datenfeeds.
- API-Zugriff: Direkt in Ihre Systeme integrieren.
- Abo-Preismodell: Nutzungbasiert.
Am besten für Medien-Monitoring, News-Aggregation oder Forschungsteams, die Echtzeit-Content-Streams brauchen.
17. FMiner
 ist ein visueller Workflow-Builder für komplexe Web-Crawls. Mit der Drag-and-Drop-Oberfläche lassen sich mehrstufige, bedingte Scraping-Routinen entwerfen.
ist ein visueller Workflow-Builder für komplexe Web-Crawls. Mit der Drag-and-Drop-Oberfläche lassen sich mehrstufige, bedingte Scraping-Routinen entwerfen.
- Python-Scripting: Eigenen Code für fortgeschrittene Logik einfügen.
- Plattformübergreifend: Für Windows und Mac verfügbar.
- Einmallizenz: Ab etwa 168 $.
Perfekt für Analysten oder Data Scientists, die anspruchsvolle Workflows visuell abbilden wollen.
18. G2 Webscraper
 (gemeint sind hoch bewertete Tools auf G2) wird für seine Einfachheit und Effektivität gelobt. Nutzer lieben Tools, die kostenlos, einfach und extrem zeitsparend sind – etwa die Web Scraper Chrome-Erweiterung oder Data Miner.
(gemeint sind hoch bewertete Tools auf G2) wird für seine Einfachheit und Effektivität gelobt. Nutzer lieben Tools, die kostenlos, einfach und extrem zeitsparend sind – etwa die Web Scraper Chrome-Erweiterung oder Data Miner.
- Starke Nutzerbewertungen: Hohe Bewertungen für einfache Bedienung und Zuverlässigkeit.
- Schnelles Setup: Kaum Lernaufwand für einfache bis mittlere Aufgaben.
Wenn Sie ein Tool wollen, das für einfaches Scraping „einfach funktioniert“, sind die Favoriten der G2-Nutzer eine sichere Wahl.
Vergleichstabelle: Die Top-Content-Crawling-Tools auf einen Blick
| Tool | Einfache Bedienung | Automatisierung & Funktionen | Exportformate | Compliance & Datenschutz | Preis | Am besten für |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | KI-Felder, Unterseiten, Cloud | Excel, CSV, Sheets, Notion, Airtable, JSON | Nutzergeführt | Kostenlos, ab 15 $/Monat | Nicht-Techniker, Vertrieb, Ops |
| Scrapy | ⭐ | Voller Code, Async, Plugins | CSV, JSON, DB | Nutzerverwaltet | Kostenlos, Open Source | Entwickler, große Projekte |
| Octoparse | ⭐⭐⭐⭐ | Visuell, Vorlagen, Cloud | CSV, Excel, JSON, API | Nutzergeführt | Kostenlos, ab 75 $/Monat | Analysten, E-Commerce, No-Coder |
| ParseHub | ⭐⭐⭐⭐ | Visuell, dynamisch, Cloud | CSV, Excel, JSON, API | Nutzergeführt | Kostenlos, ab 49 $/Monat | Nicht-Techniker, komplexe Websites |
| Data Miner | ⭐⭐⭐⭐⭐ | Vorlagen, Browser, Sheets | CSV, Excel, Sheets | Nutzergeführt | Kostenlos, ab 19 $/Monat | Schnelle Browser-Jobs |
| WebHarvy | ⭐⭐⭐⭐⭐ | Visuell, Mustererkennung | Excel, CSV, XML, JSON | Nutzergeführt | 199 $ einmalig | Windows-Nutzer, kleine Unternehmen |
| Import.io | ⭐⭐⭐⭐ | KI, Cloud, Monitoring | CSV, API, DB | GDPR, CCPA | Enterprise | Große Unternehmen, Compliance |
| Apify | ⭐⭐⭐ | Cloud, Marktplatz, API | JSON, API, Sheets | Nutzerverwaltet | Kostenlos, ab 49 $/Monat | Entwickler, Automatisierung, Integrationen |
| Visual Web Ripper | ⭐⭐⭐ | Workflow, Zeitplanung | CSV, Excel, DB | Nutzergeführt | 349 $ einmalig | IT-Teams, große Datenmengen |
| Dexi.io | ⭐⭐⭐ | Cloud, Team, Workflow | CSV, API, DB, Storage | Nutzergeführt | Individuell | Teams, laufende Projekte |
| Content Grabber | ⭐⭐⭐ | Scripting, Automatisierung | CSV, XML, DB | Nutzergeführt | Enterprise | Agenturen, individuelle Lösungen |
| Helium Scraper | ⭐⭐⭐ | Visuell + Scripting | CSV, DB | Nutzergeführt | 99 $ einmalig | Power-User, individuelle Logik |
| Web Scraper | ⭐⭐⭐⭐⭐ | Sitemap, Browser | CSV, JSON | Nutzergeführt | Kostenlos (lokal) | Einsteiger, kleine Jobs |
| Mozenda | ⭐⭐⭐ | Cloud, Managed, Compliance | CSV, API, DB | GDPR, CCPA | 500 $+/Monat | Enterprise, Managed Service |
| SimpleIndex | ⭐⭐⭐ | OCR, Web, Doku | DB, DMS | Nutzergeführt | 500 $ einmalig | Doku + Webdaten |
| Spinn3r | ⭐⭐ | Echtzeit, API | JSON, API | Nutzergeführt | Abo | Medien, Nachrichten, Research |
| FMiner | ⭐⭐⭐ | Visueller Workflow, Python | CSV, DB | Nutzergeführt | 168 $ einmalig | Komplexe, visuelle Workflows |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | Einfach, Browser | CSV, JSON | Nutzergeführt | Kostenlos/variabel | Einfachheit, schnelle Erfolge |
So wählen Sie das richtige Content-Crawling-Tool für Ihr Unternehmen
Das richtige Tool zu wählen, heißt vor allem: Ihre Anforderungen mit den Stärken des Tools abzugleichen. Hier ist meine kurze Checkliste:
- Anwendungsfall definieren: Einmalig oder laufend? Klein oder groß? Öffentliche oder eingeloggte Daten?
- Mit dem Kenntnisstand abgleichen: Nicht-Programmierer sollten mit Thunderbit, Octoparse, ParseHub oder WebHarvy starten. Entwickler können mit Scrapy oder Apify einsteigen.
- Export-Anforderungen prüfen: Benötigen Sie Excel, Sheets oder API-Integration? Stellen Sie sicher, dass das Tool das unterstützt.
- Compliance berücksichtigen: Wenn Sie in einer regulierten Branche arbeiten oder personenbezogene Daten scrapen, priorisieren Sie Tools mit Compliance-Funktionen (Import.io, Mozenda).
- Klein anfangen: Nutzen Sie kostenlose Tarife oder Testphasen, um mit echten Daten zu testen, bevor Sie sich festlegen.
- Vorausschauend denken: Werden Ihre Anforderungen wachsen? Wählen Sie ein Tool, mit dem Sie skalieren können.
Und denken Sie daran: Manchmal ist das einfachste Tool die beste Wahl. Machen Sie es nicht unnötig kompliziert, wenn Sie nur schnell eine Tabelle brauchen.
Datenschutz und Compliance: Worauf Sie achten sollten
Web-Scraping eröffnet viele Möglichkeiten – aber auch Verantwortung. So bleiben Sie auf der sicheren Seite und arbeiten sauber:
- robots.txt und Website-Richtlinien respektieren: Prüfen Sie immer, ob Scraping erlaubt ist, und halten Sie sich an die Vorgaben.
- Personenbezogene Daten nur scrapen, wenn Sie einen legitimen Grund und Einwilligung haben: GDPR und CCPA sind kein Spaß.
- Server nicht überlasten: Nutzen Sie eingebaute Drosselung, Verzögerungen und Zeitplanung, um nicht blockiert zu werden und ein guter Internet-Bürger zu bleiben.
- Bei sensiblen Branchen Tools mit Compliance-Funktionen verwenden: Import.io und Mozenda sind mit Blick auf GDPR/CCPA gebaut.
- Ihr Vorgehen dokumentieren: Halten Sie fest, was Sie scrapen und warum – besonders bei geschäftlichen oder regulierten Anwendungsfällen.
Ethical Scraping ist nachhaltiges Scraping – und hält Ihr Unternehmen aus Schwierigkeiten heraus.
Fazit: Stärken Sie Ihr Team mit dem richtigen Content-Crawling-Tool
Das Web ist die größte und chaotischste Datenbank Ihres Unternehmens – und mit dem richtigen Content-Crawling-Tool können Sie sie endlich produktiv nutzen. Ob Sie Lead-Listen aufbauen, Wettbewerber verfolgen oder Echtzeit-Dashboards füttern: Diese 18 Tools decken jedes Szenario, jedes Kompetenzniveau und jedes Budget ab.
Wenn Sie den schnellsten Weg zu Ergebnissen suchen, ist meine Top-Empfehlung für Business-User: KI-gestützt, No-Code und bereit, jede Website in Minuten in einen strukturierten Datensatz zu verwandeln. Aber ganz gleich, was Sie brauchen: Starten Sie mit einer kostenlosen Testversion, experimentieren Sie und finden Sie heraus, was am besten zu Ihrem Workflow passt.
Bereit, dem Copy-Paste-Kram den Rücken zu kehren? Laden Sie die herunter und sehen Sie, wie einfach Webdaten sein können. Und wenn Sie tiefer ins Web-Scraping eintauchen möchten, besuchen Sie den für weitere Anleitungen, Tipps und Tutorials.
FAQs
1. Was ist ein Content-Crawling-Tool, und worin unterscheidet es sich von einem normalen Web-Scraper?
Ein Content-Crawling-Tool ist eine Art Web-Scraper, der darauf ausgelegt ist, die Extraktion strukturierter Daten von Websites zu automatisieren. Während alle Web-Scraper Daten sammeln, bieten Content-Crawling-Tools oft Funktionen wie Zeitplanung, Unterseiten-Navigation, KI-Felderkennung und Integration in Geschäfts-Workflows – und sind damit leistungsfähiger und benutzerfreundlicher für Business-Teams.
2. Welches Content-Crawling-Tool ist am besten für nicht-technische Nutzer geeignet?
Thunderbit, Octoparse, ParseHub, Data Miner und WebHarvy sind alle sehr gut für Nicht-Programmierer geeignet. Thunderbit sticht durch seine KI-gestützte Einfachheit und den sofortigen Export nach Excel, Sheets, Airtable oder Notion hervor.
3. Wie stelle ich sicher, dass mein Web-Scraping legal und compliant ist?
Respektieren Sie immer die Website-Bedingungen, robots.txt und Datenschutzgesetze wie GDPR und CCPA. Vermeiden Sie das Scraping personenbezogener Daten, außer Sie haben einen legitimen Grund und eine Einwilligung. Für sensible Branchen wählen Sie Tools mit integrierten Compliance-Funktionen (z. B. Import.io, Mozenda).
4. Können diese Tools dynamische Websites mit JavaScript oder Infinite Scroll verarbeiten?
Ja – Tools wie Thunderbit, Octoparse, ParseHub, Apify und FMiner können dynamische Inhalte, Infinite Scroll und mehrstufige Navigation verarbeiten. Bei komplexen Websites kann zusätzlicher Setup-Aufwand oder ein Cloud-Run nötig sein.
5. Worauf sollte ich achten, wenn ich ein Content-Crawling-Tool für mein Unternehmen auswähle?
Berücksichtigen Sie die technischen Fähigkeiten Ihres Teams, den Umfang Ihres Datenbedarfs, Export-/Integrationsanforderungen, Compliance-Aspekte und das Budget. Starten Sie mit einem kostenlosen Tarif oder einer Testphase und testen Sie das Tool an Ihrem echten Anwendungsfall, bevor Sie sich festlegen.
Viel Erfolg beim Scraping – und mögen Ihre Daten immer frisch, strukturiert und einsatzbereit sein.
Mehr erfahren