Nachdem ich mit Simplescraper weit über tausend Scrapes durchgeführt hatte, hörte ich auf, Erfolge zu zählen, und begann, Fehler zu katalogisieren. Dieser Wechsel – von „Hat es funktioniert?“ zu „Warum ist es dieses Mal kaputtgegangen?“ – hat mir mehr beigebracht als jede Dokumentationsseite je könnte.
Simplescraper ist eine solide Chrome-Erweiterung, um Daten von Websites zu ziehen, ohne Code zu schreiben. Mit im Chrome Web Store und einer wirklich zugänglichen Point-and-Click-Oberfläche hat es sich seinen Platz im No-Code-Scraping-Toolkit verdient. Aber hier ist, was dir auf der Landingpage niemand sagt: Um konsistente, zuverlässige Ergebnisse in großem Maßstab zu bekommen, musst du verstehen, wo visuelle Scraper empfindlich werden. Eine , dass Beschäftigte mehr als neun Stunden pro Woche mit wiederkehrender Dateneingabe verbringen – genau die Art von Schmerz, die Menschen zu Tools wie Simplescraper treibt. Aber wenn du die Eigenheiten des Tools nicht kennst, verbringst du diese neun Stunden mit Debugging statt mit etwas Nützlichem. Dieser Artikel behandelt die fünf Best Practices, die ich aus echter Betriebserfahrung herausgearbeitet habe: Fehler bei der Auswahl beheben, den richtigen Scraping-Modus wählen, die kostenlose Stufe optimal nutzen, Blockierungen vermeiden und erkennen, wann es Zeit ist weiterzuziehen.

Was ist Simplescraper (und warum Best Practices wichtig sind)
Simplescraper ist eine Chrome-Erweiterung, mit der du Elemente auf einer Webseite visuell auswählen kannst – Produkttitel, Preise, Bilder, Kontaktinformationen – und sie ohne eine einzige Zeile Code in strukturierte Daten umwandeln kannst. Du zeigst darauf, du klickst, und es erstellt ein „Rezept“, das auf ähnlichen Seiten wiederverwendet werden kann.
Das Kernmodell funktioniert so:
- Visuelle Elementauswahl: Klicke auf das, was du haben willst. Simplescraper erkennt automatisch wiederkehrende Muster (Produktlisten, Suchergebnisse, Stellenanzeigen).
- Rezepte: Speichere dein Extraktions-Setup, um es später erneut zu nutzen oder auf Stapel von URLs anzuwenden.
- Zwei Scraping-Modi: Browser (lokal, läuft in deinem Chrome) und Cloud (läuft auf den Servern von Simplescraper, unbeaufsichtigt).
- Integrationen: Export nach Google Sheets, Airtable, Webhooks, Zapier, Make, CSV und JSON.
- KI-Extraktion: Eine neuere , die CSS-Selektoren aus einer Schema-Aufforderung generiert.
Die Zielgruppe ist breit gefächert – Marketing-Teams, Vertriebsabteilungen, E-Commerce-Betreiber, Forschende – also alle, die strukturierte Daten von Websites ziehen müssen, ohne eine Entwicklerin oder einen Entwickler einzustellen. Und bei unkomplizierten Seiten liefert Simplescraper schnell.
Warum also sind Best Practices so wichtig? Weil in dem Moment, in dem du über eine einfache Produktliste oder eine saubere Verzeichnisseite hinausgehst, Reibung entsteht. Dynamische Inhalte, Anti-Bot-Maßnahmen, Lazy-Loaded-Bilder, verschachtelte HTML-Strukturen – genau diese realen Bedingungen trennen eine frustrierende Erfahrung von einer produktiven. Der richtige Ansatz von Anfang an spart Stunden an Versuch und Irrtum.
Best Practice 1: Was tun, wenn Simplescraper Elemente nicht auswählt
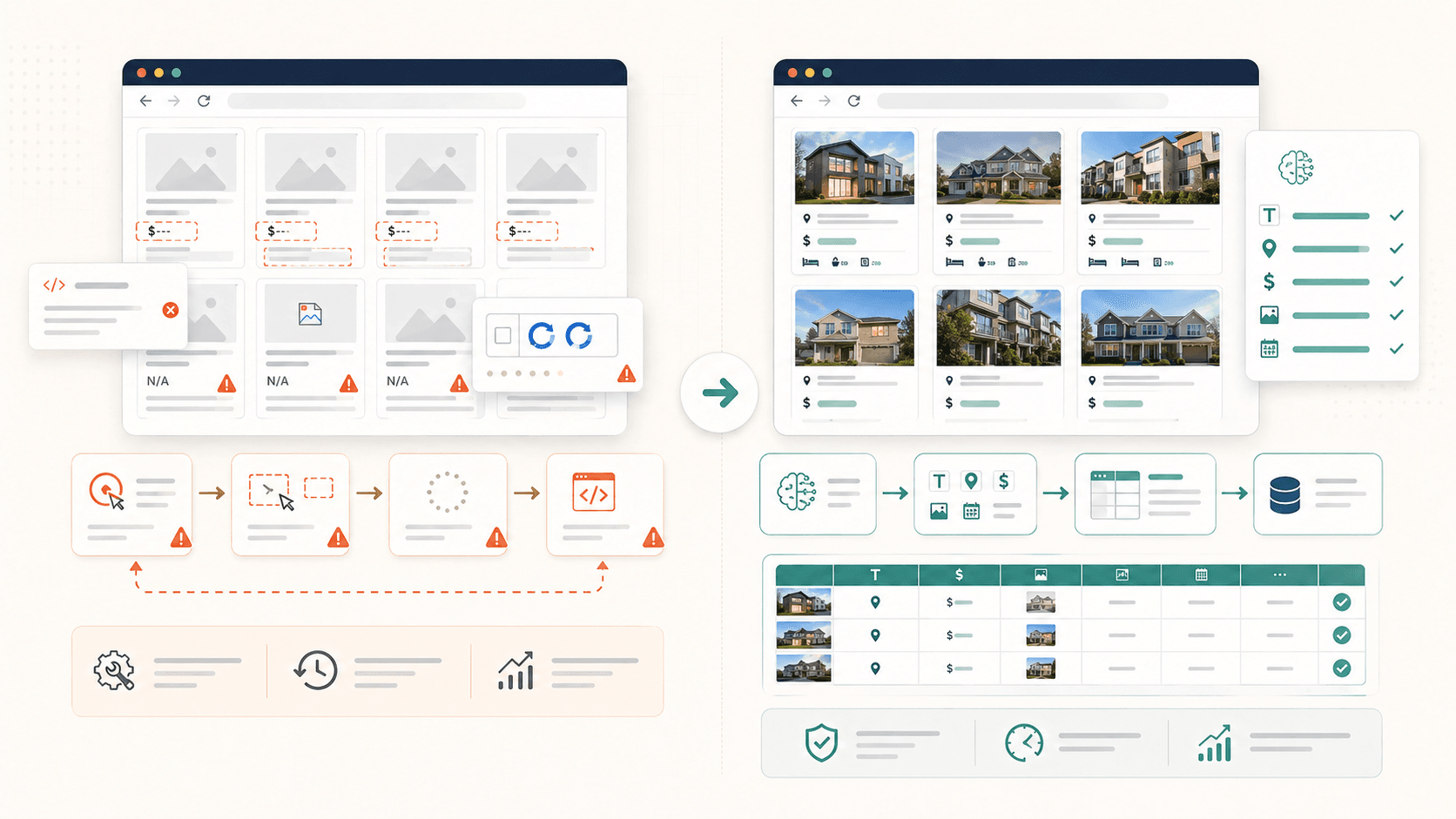
Das ist die mit Abstand häufigste Frustration, die ich erlebt habe. Du klickst ein Element an, Simplescraper hebt es hervor, alles sieht gut aus – und dann fehlt in der Ausgabe die Hälfte deiner Daten. Fotos bleiben leer. Biografien sind leer. Standorte sind verschwunden.
Der Gründer selbst hat , dass „the element/css selector still ain't 100%“. Diese Ehrlichkeit ist erfrischend, aber sie behebt nicht deinen kaputten Scrape um 23 Uhr an einem Mittwoch.
Häufige Auswahlfehler (und warum sie passieren)
Vier Muster bringen Simplescraper am häufigsten aus dem Tritt:
- Lazy-loaded Bilder: Das Bildelement , bis du dorthin scrollst. Wenn du scrapest, bevor du scrollst, erhältst du leere Bildfelder.
- Verschachtelte oder gruppierte Container: Die automatische Erkennung von Simplescraper , was manchmal dazu führt, dass nur ein Abschnitt einer Seite statt der gesamten wiederkehrenden Gruppe erfasst wird. Nutzer berichten von Tabellen, die „nicht alle Zeilen auf einmal auswählen“.
- Dynamische JavaScript-Inhalte: Elemente, die erst nach dem initialen Laden der Seite via React, Vue oder AJAX gerendert werden, sind einfach noch nicht da, wenn der Scraper zu früh zugreift.
- Infinite-Scroll-Paginierung: Die gewünschten Daten wurden noch gar nicht ins HTML geladen, weil erst gescrollt oder auf „Mehr laden“ geklickt werden muss.
Praktische Schritte zur Fehlerbehebung
Bevor du zu manuellen Selektoren greifst, probiere Folgendes:
- Scroll die gesamte Seite zuerst. So werden Lazy-Loaded Bilder und Inhalte in den DOM gezwungen.
- Nutze „Include Similar“, wenn deine Listenanzahl verdächtig niedrig wirkt. Die eigene Doku von Simplescraper empfiehlt das für gruppierte Inhalte.
- Warte auf das vollständige Rendern der Seite bei JS-lastigen Websites. Gib ihr ein paar zusätzliche Sekunden, bevor du den Scrape startest.
- Starte mit einer kleinen Stichprobe. Prüfe die Zeilenanzahl auf 2–3 Seiten, bevor du einen 500-Seiten-Job startest.
Umstieg auf manuelle CSS-Selektoren
Wenn die visuelle Auswahl immer wieder scheitert, ist es Zeit für den manuellen Weg. Das ist der Power-Move, der Gelegenheitsnutzer von effektiven Nutzern trennt.
So geht’s:
- Klicke mit der rechten Maustaste auf das gewünschte Element in Chrome → Untersuchen.
- Ermittle in den DevTools den Klassennamen oder das Datenattribut des Elements (z. B.
.product-card .priceoder[data-test="location"]). - Wechsle in Simplescraper zum Tab und füge deinen Selektor ein.
- Teste den Selektor mit einem kleinen Scrape.
Tipps für robuste Selektoren:
- Bevorzuge Klassennamen (
.listing-title) statt Positionsselektoren (div:nth-child(3)) - Nutze , wenn verfügbar – sie sind meist stabiler gegenüber Website-Updates
- Vermeide tief verschachtelte Pfade, die bei Änderungen an der HTML-Struktur der Seite brechen
Die KI-Alternative: Thunderbit Felder automatisch erkennen lassen
Ich sage es offen: Mein Team hat genau deshalb gebaut, weil wir diese Art von Problem satt hatten. Die Funktion „AI Suggest Fields“ von Thunderbit liest die Seitenstruktur und schlägt automatisch Spalten und Extraktionslogik vor. CSS-Kenntnisse sind nicht nötig. Die KI passt sich dem Layout jeder Seite an, inklusive verschachtelter Inhalte und Lazy-Loaded Bildern.
Wenn du mehr als ein paar Minuten pro Scrape mit dem Debuggen von Selektoren verbringst, lohnt es sich, einen komplett anderen Ansatz zu testen.
Best Practice 2: Zwischen Cloud Scraping und Browser Scraping wählen
Die meisten Simplescraper-Nutzer wählen den Modus standardmäßig – meist einfach den, den sie zuerst ausprobiert haben – ohne zu überlegen, welcher Modus tatsächlich zum Anwendungsfall passt. Das führt zu vermeidbaren Fehlern.
Wann Browser Scraping sinnvoll ist
- Seiten mit Login: LinkedIn, CRM-Dashboards, interne Tools – alles hinter einer Anmeldung braucht deine aktive Browser-Session.
- Schnelle Einmal-Exporte: Du bist ohnehin schon auf der Seite und willst die Daten jetzt sofort.
- Freie Credits schonen: Browser Scraping verbraucht keine Cloud-Credits.
Der Nachteil: Dein Computer muss eingeschaltet bleiben, und große Jobs sind deutlich langsamer als in der Cloud.
Wann Cloud Scraping sinnvoll ist
- Öffentliche Seiten (E-Commerce-Listen, Verzeichnisse, Immobilienseiten), bei denen kein Login nötig ist.
- Geplante Überwachung: Läuft unbeaufsichtigt in wiederkehrenden Intervallen.
- Batch-Jobs: in einem einzigen Cloud-Run.
- Auslieferung an Integrationen: Automatisches Pushen an Google Sheets, Airtable oder Webhooks.
Der Nachteil: Cloud Scraping – 2 pro JavaScript-fähiger Seite, 1 pro Seite ohne JS – und verbraucht die 100 Credits der kostenlosen Stufe schnell.
Entscheidungsrahmen
| Szenario | Empfohlener Modus | Warum | Risiko bei falscher Wahl |
|---|---|---|---|
| Seiten mit Login (LinkedIn, Dashboards) | Browser | Benötigt deine authentifizierte Session | Cloud-Modus stößt auf Login-Schranken |
| Öffentliche E-Commerce-Produktlisten | Cloud | Schneller, läuft unbeaufsichtigt | Browser-Modus bindet deinen Rechner |
| Geplante wiederkehrende Überwachung | Cloud | Läuft ohne dich | Browser erfordert deine Anwesenheit |
| Seiten mit starkem Anti-Bot-Schutz (Amazon, Yelp) | Browser (Fallback) oder Cloud mit Proxy | IP-Rotation oder Session-Wiederverwendung nötig | Cloud ohne Proxy wird schnell blockiert |
| Schnelle Einmal-Extraktion | Browser | Sofort, ohne Credit-Kosten | Für eine Seite ist Cloud unnötiger Aufwand |

Wie Thunderbit das vereinfacht
In ist die Wahl nur ein einfacher Schalter innerhalb derselben Oberfläche. Der Cloud-Modus verarbeitet bis zu 50 Seiten gleichzeitig – ohne separate kostenpflichtige Stufe für Cloud-Zugriff. Der Browser-Modus verarbeitet Seiten mit Login-Anforderung ohne zusätzliche Konfiguration. Der mentale Aufwand von „Welchen Modus brauche ich?“ sinkt deutlich, wenn beide Modi im selben Workflow leben.
Best Practice 3: Das Maximum aus der kostenlosen Stufe von Simplescraper holen
Verwirrung beim Pricing ist real. Ich habe Forenbeiträge gesehen, in denen Leute davon ausgehen, „kostenlose Chrome-Erweiterung“ bedeute „alles kostenlos“. Tut es nicht. Und auf der anderen Seite habe ich Leute gesehen, die Simplescraper für teuer halten, weil die kostenpflichtigen Stufen nicht prominent dargestellt sind. Keine der beiden Annahmen hilft.
Was der kostenlose Plan von Simplescraper tatsächlich enthält
Laut den :
- Browser Scraping: Unbegrenzt (läuft lokal in deinem Chrome)
- Cloud-Credits: 100 pro Monat
- Gespeicherte Rezepte: 3
- Exportformate: CSV und JSON
- Nicht enthalten: Priority Support, erweiterte Proxy-Optionen, höhere Cloud-Credit-Limits
Ein realistisches Free-Tier-Szenario
Angenommen, du musst 50 Produktseiten von einer öffentlichen E-Commerce-Seite scrapen.
- Browser-Modus (kostenlos): Das kannst du komplett kostenlos erledigen. Öffne jede Seite (oder nutze eine Liste), starte das Rezept, exportiere nach CSV. Zeitaufwand: abhängig von Geduld und Internetgeschwindigkeit, aber rechne bei 50 Seiten mit manueller Navigation mit 15–30 Minuten aktiver Arbeit.
- Cloud-Modus (kostenlose Stufe): Mit aktivem JavaScript-Rendering kostet jede Seite 2 Credits. 50 Seiten = 100 Credits. Damit ist dein gesamtes monatliches Cloud-Kontingent in einem einzigen Job verbraucht. Kein Scheduling, keine Wiederholungen, falls etwas scheitert.
Die kostenlose Stufe ist für kleine, gelegentliche Scrapes wirklich nützlich. Aber sie ist schnell aufgebraucht, sobald du Cloud-Automatisierung oder Skalierung brauchst.
Vergleich der kostenlosen Stufe: Simplescraper vs. Thunderbit
| Funktion | Simplescraper kostenlos | Thunderbit kostenlos |
|---|---|---|
| Seiten/Credits | Unbegrenzter Browser + 100 Cloud-Credits | 6 Seiten mit vollständigen KI-Funktionen |
| KI-gestützte Extraktion | Eingeschränkt (Smart Extract verbraucht Credits) | Vollständige AI Suggest Fields inklusive |
| Export-Ziele | CSV, JSON | Excel, Google Sheets, Airtable, Notion — alles kostenlos |
| Gespeicherte Konfigurationen | 3 Rezepte | Vorlagen verfügbar |
| Subpage-Scraping | Manuelle Rezept-Einrichtung | In der Seitenanzahl enthalten |
Die Modelle unterscheiden sich wirklich. Simplescraper gibt dir unbegrenztes lokales Scraping mit begrenzter Cloud-Nutzung. gibt dir weniger Seiten, packt dafür aber pro Seite volle KI-Fähigkeiten hinein – plus kostenlose Exporte in die Tools, die die meisten Teams tatsächlich nutzen. Die kostenlose Stufe von Simplescraper funktioniert, wenn du einfaches lokales Scraping brauchst und manuelle Arbeit akzeptierst. Wenn du aber KI-gestützte Extraktion mit flexiblen Exporten willst, bietet die kostenlose Stufe von Thunderbit pro Seite mehr Leistung.
Best Practice 4: Wie du beim Scraping Blockierungen vermeidest
Niemand denkt an Anti-Bot-Maßnahmen, bis plötzlich eine CAPTCHA-Mauer oder ein leeres Dataset vor ihnen steht. Dann hast du bereits Zeit und womöglich auch Credits verbrannt.
Vorbeugung ist immer günstiger als nachträgliches Debugging.
Rate Limits setzen und Anfragen dosieren
Der häufigste Grund für Blockierungen: eine Website mit zu vielen schnellen Anfragen bombardieren. Für einen Webserver sehen 50 Anfragen in 10 Sekunden von einer IP nicht nach Neugier aus, sondern nach einem Angriff.
Faustregeln:
- Füge zwischen Seitenanfragen 2–5 Sekunden ein, bei den meisten kommerziellen Seiten.
- Bei sensiblen Zielen (Marktplätze, Bewertungsseiten) langsamer gehen – 5–10 Sekunden.
- Wenn du die API von Simplescraper nutzt, kann der Parameter helfen sicherzustellen, dass Seiten vor der Extraktion vollständig geladen sind, was das Tempo natürlich ebenfalls verlangsamt.
Wann Proxy-Rotation aktiviert werden sollte
Proxy-Rotation ändert zwischen Anfragen deine IP-Adresse, sodass du wie mehrere verschiedene Nutzer aussiehst. Das brauchst du für:
- Amazon, Yelp, TripAdvisor, LinkedIn (aggressive Anti-Bot-Systeme)
- Jede Website, die pro IP Rate Limits setzt
- Große Batch-Jobs (Hunderte Seiten von derselben Domain)
Die Plattform von Simplescraper einschließlich Standard-, Premium- und Residential-Optionen. Allerdings ist die genaue Verfügbarkeit auf Planebene in den öffentlichen Dokus nicht immer kristallklar – prüfe das, bevor du annimmst, die kostenlose Stufe decke harte Ziele ab. Residential Proxies kosten typischerweise mehr, werden aber seltener markiert.
Umgang mit JavaScript-lastigen Seiten
Moderne Seiten, die mit React, Vue oder Angular gebaut sind, rendern Inhalte erst nach dem initialen Laden der Seite. Wenn dein Scraper zugreift, bevor JavaScript fertig ausgeführt wurde, erhältst du leere Felder.
Strategien:
- Nutze den Cloud-Scraping-Modus für besseres Rendering (die Cloud von Simplescraper kann JavaScript ausführen).
- Scroll die Seite manuell, bevor du einen Browser-Scrape startest, um Lazy-Loaded Inhalte auszulösen.
- Nutze
waitForSelectorin API-basierten Workflows, um zu warten, bis Ziel-Elemente erscheinen. - Akzeptiere, dass manche stark dynamischen Single-Page-Apps für einen visuellen Scraper schlicht außerhalb des zuverlässig Machbaren liegen können.
Die hands-off-Alternative
übernimmt Anti-Bot-Schutz, CAPTCHAs und JavaScript-Rendering automatisch – keine Proxy-Konfiguration, kein Feintuning von Wartezeiten, kein manuelles Scrollen. Für Nutzer, die nicht erst Amateur-DevOps-Engineer werden wollen, nur um einen Produktkatalog zu scrapen, ist das wichtig. Die Probleme verschwinden nicht – sie werden nur jemand anderem überlassen.
Best Practice 5: Erkennen, wann Simplescraper an seine Grenzen stößt
Ich wünschte, jemand hätte diesen Abschnitt vor zwei Jahren für mich geschrieben.
Es gibt einen Punkt, an dem das Tool aufhört, Zeit zu sparen, und anfängt, Zeit zu fressen. Diese Schwelle früh zu erkennen, bewahrt dich vor der Sunk-Cost-Falle von „Ich habe schon 15 Rezepte gebaut, jetzt kann ich nicht mehr wechseln.“
Praktische Grenzen von Simplescraper
- Dynamische Single-Page-Applications, die Inhalte per AJAX laden, ohne klassische Seitennavigation
- Infinite Scroll, das kontinuierliches Scrollen erfordert, um alle Elemente zu laden (keine standardmäßige Klick-Paginierung)
- Subpage-Anreicherung: Eine Listen-Seite scrapen und anschließend jede Detailseite für zusätzliche Daten besuchen. Simplescraper kann das mit , aber die Komplexität der Einrichtung steigt schnell.
- Layout-Änderungen, die bestehende Rezepte brechen. Wenn eine Website ihre HTML-Struktur aktualisiert, funktionieren deine sorgfältig abgestimmten CSS-Selektoren nicht mehr.
Anzeichen dafür, dass du das Tool überwachsen hast
Du hast wahrscheinlich die Grenze erreicht, wenn:
- Du bei jedem Scrape manuell CSS-Selektoren anpassen musst, weil die automatische Erkennung ständig scheitert
- Rezepte nach Website-Updates brechen und neu aufgebaut werden müssen
- Du Dutzende oder Hunderte Seiten gleichzeitig scrapen willst, aber immer wieder auf Credit- oder Geschwindigkeitsgrenzen stößt
- Subpage-Daten komplexe mehrstufige Rezeptketten erfordern
- Du mehr Zeit mit der Pflege der Scrapes verbringst als mit der tatsächlichen Nutzung der extrahierten Daten
Das letzte ist das klarste Signal. Wenn Wartung zur eigentlichen Arbeit wird, ist der Komfortvorteil von No-Code verschwunden.
Der Wechsel zu einem KI-gestützten Workflow
Hier spreche ich darüber, was mein Team mit gebaut hat, weil es genau für die oben beschriebenen Fehlermodi entwickelt wurde:

- Die KI liest jede Seite jedes Mal neu – keine fragilen Rezepte oder CSS-Selektoren, die gepflegt werden müssen. Wenn eine Website ihr Layout ändert, passt sich die KI beim nächsten Lauf an.
- Subpage-Scraping reichert deine Datentabelle mit einem Klick an. Scrape eine Liste und besuche dann automatisch jede Detailseite für zusätzliche Felder.
- Geplantes Scraping per natürlicher Sprache („jeden Montag um 9 Uhr“) statt über Timing-Presets.
- Cloud Scraping mit 50 Seiten gleichzeitig für Geschwindigkeit auf öffentlichen Seiten.
- Native kostenlose Exporte zu Google Sheets, Airtable, Notion und Excel ohne Webhook-Konfiguration.
Simplescraper vs. Thunderbit: Direktvergleich
Hier ist alles an einem Ort:

| Fähigkeit | Simplescraper | Thunderbit |
|---|---|---|
| Feld-Einrichtung | Manuelle CSS-Selektoren / visuelle Auswahl | AI Suggest Fields (einfaches Englisch) |
| Subpage-Anreicherung | Über Batch-Workflows möglich (komplexe Einrichtung) | Auto-Anreicherung mit 1 Klick |
| Automatische Anpassung an Layout-Änderungen | Bricht (manuelle Korrektur nötig) | KI liest die Seitenstruktur jedes Mal neu |
| Cloud-Seitenparallelität | Batch bis zu 5.000 URLs (variiert je nach Plan) | 50 Seiten gleichzeitig |
| Export nach Notion/Airtable | Über Webhook (kostenpflichtige Stufen) | Nativ, kostenlos |
| Planung | Voreinstellungen + benutzerdefinierte Zeitsteuerung | Beschreibung in natürlicher Sprache |
| Anti-Bot-/CAPTCHA-Behandlung | Proxy-Modi verfügbar (planabhängig) | Automatisch, keine Konfiguration |
| Kostenlose Stufe | 100 Cloud-Credits + unbegrenzter Browser + 3 Rezepte | 6 Seiten mit vollständigen KI-Funktionen + kostenlose Exporte |
Kurz gesagt: Simplescraper glänzt bei einfacher, visueller Extraktion mit wenig Einrichtung, bei der gelegentliches manuelles Nachjustieren akzeptabel ist. Thunderbit übernimmt dort, wo dieses Modell an seine Grenzen stößt – bei Seiteninterpretation, Layout-Anpassung und Workflow-Komplexität, damit du das nicht musst.
Keines der beiden Tools ist universell besser. Sie liegen an unterschiedlichen Punkten auf der Komplexitätskurve – und das ist völlig in Ordnung.
Schnellreferenz: Checkliste für Simplescraper-Best-Practices
Setze dir ein Lesezeichen für deine nächste Scraping-Session:
- Teste immer zuerst an einer kleinen Stichprobe. Prüfe Zeilenanzahl und Vollständigkeit der Felder auf 2–3 Seiten, bevor du skalierst.
- Scroll die Seite vor dem Scraping, um Lazy-Loaded Inhalte auszulösen.
- Nutze „Include Similar“, wenn die Listenerkennung zu eng wirkt.
- Wähle deinen Scraping-Modus bewusst. Browser für Seiten mit Login; Cloud für öffentliche Seiten und geplante Jobs.
- Setze Verzögerungen zwischen Anfragen – mindestens 2–5 Sekunden bei kommerziellen Seiten, länger bei Zielen mit starkem Anti-Bot-Schutz.
- Kennt die Mathematik deiner kostenlosen Stufe. 100 Cloud-Credits = 50 JavaScript-fähige Seiten. Plane entsprechend.
- Speichere Rezepte nur für stabile Seiten. Wenn eine Website häufig aktualisiert wird, brechen Rezepte.
- Lerne grundlegende CSS-Selektoren als Fallback. Klassennamen und Datenattribute sind besser als Positionsselektoren.
- Überwache Blockierungen proaktiv. Wenn du leere Ergebnisse oder CAPTCHAs bekommst, verlangsame oder wechsle den Modus.
- Erkenne die Grenze. Wenn Wartungszeit die Nutzungszeit der Daten übersteigt, prüfe Alternativen.
Fazit: Mach aus jedem Scrape etwas Wertvolles
Die übergreifende Lehre aus mehr als tausend Scrapes dreht sich nicht um ein einzelnes Tool. Sie lautet, dass der Ansatz wichtiger ist als die Software. Zu verstehen, warum ein Scrape scheitert – Lazy Loading, falscher Modus, aggressiver Anti-Bot-Schutz, fragile Selektoren – ist wertvoller als jede Funktionsliste.
Simplescraper funktioniert für unkomplizierte Extraktionsaufgaben tatsächlich gut. Wenn deine Seiten sauber sind, dein Bedarf überschaubar ist und du gelegentliches manuelles Nachjustieren nicht scheust, liefert es.
Aber wenn du merkst, dass du mehr mit dem Tool kämpfst als es zu nutzen – Selektoren debuggen, kaputte Rezepte neu bauen, Proxies konfigurieren, Seiten manuell scrollen – dann ist das ein Signal, kein persönliches Versagen. Es bedeutet, dass du das erreicht hast, was visuelles Scraping allein zuverlässig leisten kann.
Wenn dir das bekannt vorkommt, probiere die aus – sechs Seiten mit vollen KI-Funktionen, kostenlose Exporte zu Sheets, Airtable und Notion. Vergleiche es mit deinem aktuellen Workflow und schau, was besser passt. Manchmal besteht die beste Praxis darin, zu wissen, wann man ein anderes Tool einsetzen sollte.
FAQs
Ist Simplescraper kostenlos nutzbar?
Ja, Simplescraper hat einen kostenlosen Plan, der unbegrenztes lokales Browser Scraping, , 3 gespeicherte Rezepte und CSV/JSON-Export umfasst. Cloud-Seiten mit JavaScript-Unterstützung kosten jeweils 2 Credits, sodass diese 100 Credits etwa 50 Seiten im Cloud-Modus abdecken. Bezahlpläne beginnen bei 39 $/Monat (Plus) für 6.000 Credits und 70 $/Monat (Pro) für 15.000 Credits.
Kann Simplescraper JavaScript-lastige Websites verarbeiten?
Manchmal. Der Cloud-Modus von Simplescraper kann JavaScript rendern, und das Tool wirbt mit Unterstützung für Single-Page-Apps. Komplexe SPAs mit stark dynamischem Rendering, Infinite Scroll oder aggressiven Anti-Bot-Systemen können jedoch trotzdem unvollständige Ergebnisse liefern. Cloud-Modus mit passenden Wartezeiten verbessert die Zuverlässigkeit, aber stark dynamische Seiten bleiben für jeden visuellen Scraper eine Herausforderung.
Was ist der Unterschied zwischen Cloud- und Browser-Scraping in Simplescraper?
Browser Scraping läuft lokal in deinem Chrome-Browser – es nutzt deine aktive Session (ideal für Seiten mit Login), kostet keine Credits, erfordert aber, dass dein Computer eingeschaltet bleibt. läuft auf den Servern von Simplescraper – es ist schneller, läuft unbeaufsichtigt, unterstützt Scheduling und Integrationen, kostet aber pro Seite Credits und kann nicht auf Seiten hinter deinem persönlichen Login zugreifen.
Wann sollte ich von Simplescraper zu einer Alternative wie Thunderbit wechseln?
Das deutlichste Signal ist, wenn Wartungszeit die Nutzungszeit der Daten übersteigt. Wenn du regelmäßig kaputte Selektoren nach Website-Updates reparierst, Proxies manuell konfigurierst, Rezepte neu erstellst oder mehr Zeit mit Fehlerbehebung als mit der Analyse deiner extrahierten Daten verbringst, bist du über das hinausgewachsen, was manuelles visuelles Scraping effizient leisten kann. Tools wie , die mit KI bei jedem Lauf die Seitenstruktur interpretieren, beseitigen den Großteil dieses Wartungsaufwands.
Wie vermeide ich Blockierungen beim Scraping mit Simplescraper?
Drei zentrale Praktiken: Erstens, drossele deine Anfragen mit 2–5 Sekunden Verzögerung zwischen den Seiten (bei starkem Anti-Bot-Schutz wie Amazon oder Yelp länger). Zweitens, nutze den Browser-Modus als Fallback für Seiten, die Cloud-IPs aggressiv blockieren – deine Browser-Session wirkt mehr wie normaler Traffic. Drittens, aktiviere Proxy-Rotation für große Batch-Jobs auf sensiblen Zielen, prüfe aber vorher, welche Proxy-Optionen in deinem Plan enthalten sind, bevor du dich darauf verlässt.
Mehr erfahren