

Web Scraping klang für mich anfangs harmlos: ein bisschen HTML abgreifen, fertig. Heute sehe ich das anders. Wer im Vertrieb, E-Commerce oder in der Marktforschung arbeitet, kommt um Web Scraping kaum herum. Das Netz ist eine riesige Datenquelle – mit über einer Milliarde Websites – und Unternehmen sind ständig auf der Suche nach frischen Insights. Der Haken: Die meisten Daten stecken hinter dynamischen Seiten, JavaScript und interaktiven Elementen, an die simple Tools nicht herankommen.
Genau hier kommen Python-Web-Scraper wie Selenium ins Spiel. Mit Selenium Python steuerst du einen echten Browser fern und liest so auch komplexe, dynamische Webseiten aus. In diesem Einsteiger-Guide gehe ich mit dir Schritt für Schritt durch, wie das geht – samt Praxisbeispiel mit Produktdaten von allbirds.com. Und weil ich es gern unkompliziert mag, stelle ich dir außerdem moderne KI-Tools wie Thunderbit vor, mit denen du dasselbe in einem Bruchteil der Zeit (und fast ohne Code) erledigst.
Warum Web Scraping so wichtig ist (und warum dynamische Seiten oft nerven)
Web Scraping ist längst kein Nerd-Hobby mehr. Für Teams aus Vertrieb, Marketing, E-Commerce und Operations ist es ein unverzichtbares Werkzeug. Du willst Preise der Konkurrenz im Blick behalten? Leads generieren? Kundenbewertungen auswerten? Web Scraping macht’s möglich. Tatsächlich geben über ein Drittel der Entwickler an, dass Preisdaten ihr Hauptziel sind – und 80–90 % aller Online-Daten sind unstrukturiert. Einfach kopieren und in Excel einfügen? Fehlanzeige.
Das Problem: Moderne Websites sind dynamisch. Inhalte werden per JavaScript nachgeladen, Daten verstecken sich hinter Buttons oder erscheinen erst nach endlosem Scrollen. Einfache Scraper wie requests oder BeautifulSoup sehen nur das statische HTML – wie eine Zeitung, die nie aktualisiert wird. Tauchen die Infos erst nach Klicks, Scrollen oder Login auf, brauchst du ein Tool, das sich wie ein echter Nutzer verhält.
Was ist Selenium Python und warum eignet es sich fürs Web Scraping?
Selenium Python ist ein Tool zur Browser-Automatisierung. Du schreibst Python-Skripte, die einen echten Browser steuern – Buttons klicken, Formulare ausfüllen, Seiten scrollen und natürlich Daten auslesen, die erst nach Interaktion erscheinen.
Was unterscheidet Selenium Python von einfachen Scraping-Tools?
- Selenium Python: Steuert einen echten Browser (z. B. Chrome), führt JavaScript aus, interagiert mit dynamischen Elementen und wartet, bis Inhalte geladen sind – wie ein Mensch.
- Requests/BeautifulSoup: Holt nur das statische HTML. Schnell und schlank, kommt aber mit JavaScript oder nutzergetriebenen Inhalten nicht klar.
Stell dir Selenium wie einen Roboter-Praktikanten vor: Er kann im Browser alles erledigen, braucht aber klare Anweisungen (und manchmal etwas Geduld).
Wann solltest du Selenium einsetzen?
- Endlos-Scroll-Feeds (z. B. Social Media, Produktlisten)
- Interaktive Filter oder Dropdowns (z. B. Schuhgröße auswählen auf allbirds.com)
- Inhalte hinter Logins oder Pop-ups
- Single Page Applications (React, Vue, etc.)
Für einfache, statische Seiten reicht BeautifulSoup. Sobald es aber dynamisch wird, ist Selenium die bessere Wahl.
Selenium Python einrichten – Schritt für Schritt
Bevor wir loslegen, richten wir die nötigen Tools ein. Keine Sorge, Vorkenntnisse brauchst du keine.
1. Python und Selenium installieren
Stell zuerst sicher, dass Python 3 installiert ist. Download unter python.org. Prüfen mit:
python --version
Dann Selenium per pip installieren:
pip install selenium
Damit hast du das aktuelle Selenium-Paket für Python. Einfach, oder?
2. ChromeDriver herunterladen und einrichten
Selenium braucht einen „Driver“, um den Browser zu steuern. Für Chrome ist das der ChromeDriver.
- Chrome-Version herausfinden: Chrome öffnen, Menü → Hilfe → Über Google Chrome.
- Passenden ChromeDriver herunterladen: Die Version muss zu deinem Browser passen.
- Driver entpacken und ablegen:
chromedriver.exe(bzw. das Mac/Linux-Pendant) in den System-Pfad oder ins Projektverzeichnis legen.
Tipp: Es gibt Python-Pakete wie webdriver_manager, die den Driver automatisch laden. Für den Einstieg genügt aber die manuelle Variante.
3. Testen, ob alles funktioniert
Erstelle eine Datei test_selenium.py:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
print(driver.title)
driver.quit()
Öffnet sich Chrome, lädt example.com, erscheint der Titel und schließt der Browser wieder, bist du startklar!
Dein erstes Selenium Python-Skript: Produkte von allbirds.com auslesen
Jetzt wird’s praktisch: Wir holen Produktnamen und Preise von allbirds.com/collections/mens.
Schritt 1: Browser starten und Seite aufrufen
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.allbirds.com/collections/mens")
Schritt 2: Auf das Laden dynamischer Inhalte warten
Dynamische Seiten brauchen manchmal einen Moment. Wir nutzen Seleniums Wartefunktionen:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div.product-card"))
)
(Den passenden CSS-Selektor findest du per Seiten-Inspektion. Im Beispiel nehmen wir div.product-card.)
Schritt 3: Elemente finden und Daten extrahieren
products = driver.find_elements(By.CSS_SELECTOR, "div.product-card")
print(f"{len(products)} Produkte gefunden")
data = []
for prod in products:
name = prod.find_element(By.CSS_SELECTOR, ".product-name").text
price = prod.find_element(By.CSS_SELECTOR, ".price").text
data.append((name, price))
print(name, "-", price)
Die Ausgabe sieht dann etwa so aus:
24 Produkte gefunden
Wool Runner - $110
Tree Dasher 2 - $135
...
Schritt 4: Daten als CSV speichern
Ergebnisse in eine CSV-Datei schreiben:
import csv
with open("allbirds_products.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Produktname", "Preis"])
writer.writerows(data)
Und nicht vergessen, den Browser zu schließen:
driver.quit()
Öffne die CSV – und schon hast du alle Produktnamen und Preise für deine Auswertung.
Typische Stolpersteine beim Web Scraping mit Selenium Python
In der Praxis läuft selten alles auf Anhieb glatt. Ein paar Tipps für die häufigsten Hürden:
Auf das Laden von Elementen warten
Dynamische Seiten sind oft träge. Nutze explizite Wartezeiten:
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, ".product-card"))
)
So greift dein Skript nicht zu früh auf Elemente zu.
Mit Paginierung umgehen
Du willst mehr als nur die erste Seite? Dann durchlaufe die Seiten:
while True:
try:
next_btn = driver.find_element(By.LINK_TEXT, "Next")
next_btn.click()
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".product-card")))
except Exception:
break # Keine weiteren Seiten
Oder für endloses Scrollen:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Pop-ups und Logins handhaben
Pop-ups im Weg? So schließt du sie:
driver.find_element(By.CSS_SELECTOR, ".modal-close").click()
Automatischer Login? Felder ausfüllen und absenden:
driver.find_element(By.ID, "email").send_keys("user@example.com")
driver.find_element(By.NAME, "login").click()
Beachte: CAPTCHAs und Zwei-Faktor-Authentifizierung lassen sich nur schwer automatisieren.
Die Schattenseiten von Selenium Python beim Web Scraping
So mächtig Selenium ist – ein paar Nachteile bringt es mit:
- Langsam: Jeder Seitenaufruf lädt einen kompletten Browser samt Bildern und Skripten. Bei 1.000 Seiten ist Geduld gefragt.
- Ressourcenhungrig: Hoher CPU- und RAM-Bedarf. Viele Browser parallel? Da gerät selbst ein starker Rechner ins Schwitzen.
- Komplexe Einrichtung: ChromeDriver-Versionen müssen passen, Updates im Auge behalten, für jede Seite eigenen Code schreiben – das kann ausarten.
- Anfällig: Ändert sich das Layout einer Website, läuft dein Skript über Nacht ins Leere.
- Manuelle Datenaufbereitung: Für Übersetzungen oder Sentiment-Analysen brauchst du zusätzliche Bibliotheken oder APIs.
Für Nicht-Techniker oder alle, die einfach schnell strukturierte Daten brauchen, fühlt sich Selenium oft an wie mit Kanonen auf Spatzen geschossen.

Thunderbit kennenlernen: die KI-Alternative zu Selenium Python
Jetzt zu einem Tool, das gerade Business-Anwendern vieles abnimmt: Thunderbit. Thunderbit ist ein KI-Web-Scraper als Chrome-Erweiterung, mit dem du Daten von jeder Website extrahierst – ganz ohne Code, ohne knifflige Einrichtung, mit nur wenigen Klicks.
Mit KI Daten von jeder Website extrahieren Get Started Free
Was macht Thunderbit anders?
- KI-Felderkennung: Mit „AI Suggest Fields“ erkennt Thunderbits KI automatisch, welche Felder relevant sind – etwa Produktname, Preis, Bilder usw.
- Unterseiten-Scraping: Du brauchst Details von Produktseiten? Thunderbit klickt sich automatisch durch und sammelt Zusatzinfos.
- Datenanreicherung: Beschreibungen übersetzen, Texte zusammenfassen oder Sentiment-Analysen durchführen – direkt beim Scrapen.
- Export mit einem Klick: Daten direkt nach Excel, Google Sheets, Notion oder Airtable schicken. Kein Coding, kein Aufwand.
- No-Code-Oberfläche: Für alle, die nicht programmieren wollen. Wer einen Browser bedienen kann, kommt auch mit Thunderbit zurecht.
Ich bin parteiisch (ich habe an Thunderbit mitgearbeitet!), aber ich bin überzeugt: Für Vertrieb, E-Commerce und Recherche ist es der schnellste Weg zu strukturierten Webdaten.
Thunderbit vs. Selenium Python: der direkte Vergleich
Hier die wichtigsten Unterschiede auf einen Blick:
| Kriterium | Selenium Python | Thunderbit (KI, No-Code) |
|---|---|---|
| Einrichtungsaufwand | Mittel bis hoch – Python, Selenium, ChromeDriver installieren, Code schreiben | Sehr schnell – Chrome-Erweiterung installieren, in Minuten startklar |
| Erforderliche Kenntnisse | Hoch – Programmier- und HTML-Wissen nötig | Gering – Point-and-Click, KI übernimmt die Arbeit |
| Dynamische Inhalte | Hervorragend – kann JS, Klicks, Scrollen | Hervorragend – läuft im Browser, unterstützt AJAX, Endlos-Scroll, Unterseiten |
| Geschwindigkeit | Langsam – Browser-Overhead | Schnell bei kleinen/mittleren Jobs – KI erkennt Felder automatisch, direkter DOM-Zugriff |
| Skalierbarkeit | Schwer skalierbar – ressourcenintensiv | Gut für Hunderte/Tausende Einträge; nicht für Massenscraping |
| Datenverarbeitung | Manuell – Datenbereinigung, Übersetzung, Sentiment per Code | Automatisch – KI kann direkt übersetzen, zusammenfassen, kategorisieren, anreichern |
| Exportoptionen | Individueller Code für CSV, Sheets etc. | Export mit einem Klick nach Excel, Google Sheets, Notion, Airtable |
| Wartung | Hoch – empfindlich bei Website-Änderungen | Gering – KI passt sich vielen Layouts an, wenig Pflege nötig |
| Besondere Features | Vollständige Browser-Automatisierung, individuelle Workflows | KI-Insights, Vorlagen, Datenanreicherung, kostenlose Extractor-Vorlagen |
Für die meisten Business-Anwender ist Thunderbit eine echte Erleichterung – kein Stress mehr mit Code oder Browser-Treibern.
Praxisbeispiel: allbirds.com mit Thunderbit auslesen
So einfach geht’s mit Thunderbit:
- Thunderbit Chrome-Erweiterung installieren
- Zu allbirds.com/collections/mens navigieren
- Thunderbit-Icon anklicken und „AI Suggest Fields“ wählen
- Thunderbits KI erkennt automatisch Spalten wie „Produktname“, „Preis“, „Produkt-URL“ usw.
- (Optional) Spalte für „Beschreibung (Japanisch)“ oder „Sentiment“ hinzufügen
- Thunderbit übersetzt oder analysiert direkt beim Scrapen.
- Auf „Scrape“ klicken
- Thunderbit sammelt alle Produktdaten in einer Tabelle.
- Mit einem Klick nach Google Sheets, Notion oder Excel exportieren
Kein Code, kein Warten auf Browser, kein CSV-Gefrickel. Einfach strukturierte Daten, sofort einsatzbereit.
Thunderbit KI-Web-Scraper kostenlos testen
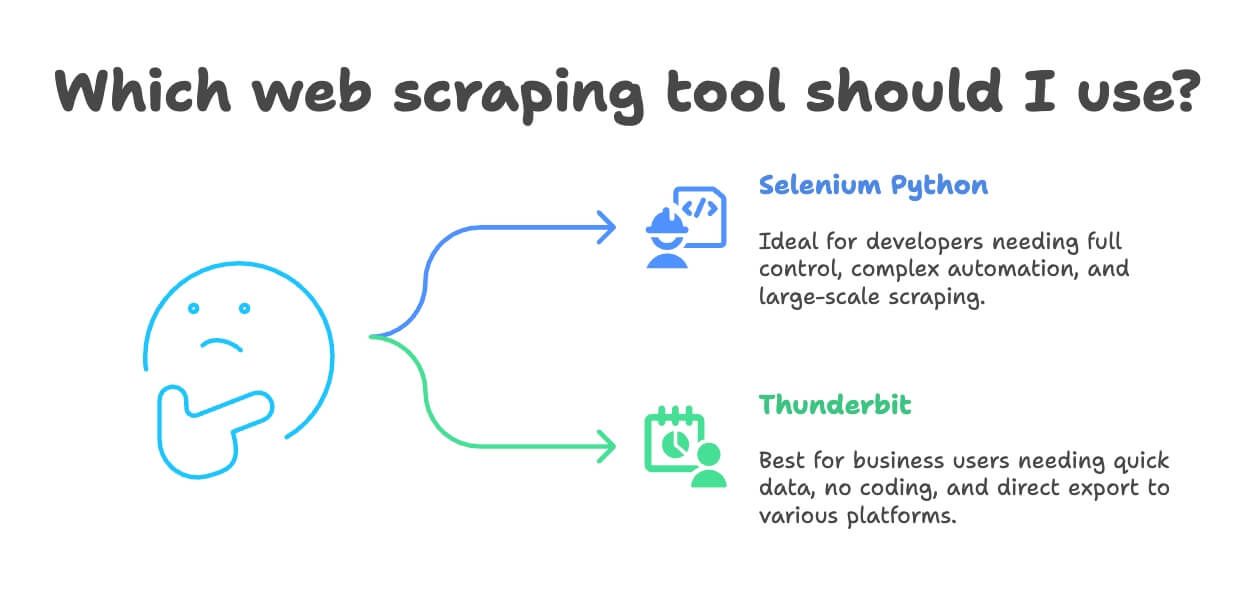
Wann Selenium Python und wann Thunderbit fürs Web Scraping?
Welches Tool passt zu dir? Hier meine Empfehlung:
- Selenium Python nutzen, wenn:
- Du Entwickler bist oder volle Kontrolle über die Browser-Automatisierung brauchst
- Die Aufgabe sehr individuell ist oder Teil eines größeren Softwareprojekts
- Du komplexe Workflows automatisieren willst (Logins, Downloads, mehrstufige Formulare)
- Du im großen Stil scrapen willst (mit passender Infrastruktur)
- Thunderbit nutzen, wenn:
- Du Business-Anwender, Analyst oder Marketer bist und schnell an Daten kommen willst
- Du keine Lust auf Coding und Einrichtung hast
- Du Übersetzungen, Sentiment-Analysen oder Datenanreicherung direkt beim Scrapen brauchst
- Dein Projekt klein bis mittelgroß ist (Hunderte bis wenige Tausend Einträge)
- Du direkt nach Excel, Google Sheets, Notion oder Airtable exportieren willst
Ich habe schon erlebt, wie Teams tagelang an Selenium-Skripten feilen, während Thunderbit dieselbe Aufgabe in 10 Minuten erledigt. Wenn du keine tiefe Anpassung oder Massenscraping brauchst, ist Thunderbit meist der schnellere und angenehmere Weg.
Bonus: Tipps für verantwortungsvolles und effektives Web Scraping
Bevor du loslegst, ein paar wichtige Hinweise:
- robots.txt und Nutzungsbedingungen beachten: Prüfe immer, was erlaubt ist. Verbietet eine Seite Scraping, halte dich daran.
- Anfragen drosseln: Überlaste den Server nicht – baue Pausen ein oder nutze eingebaute Limits.
- User-Agents/IPs rotieren, falls nötig: Hilft gegen einfache Sperren, aber trickse nicht, wo es gegen die Regeln verstößt.
- Keine persönlichen oder sensiblen Daten scrapen: Bleib bei öffentlichen Infos und halte dich an Datenschutzgesetze wie die DSGVO.
- APIs nutzen, wenn vorhanden: Bietet eine Seite eine API, nimm sie – das ist sicherer und stabiler.
- Nicht ohne Erlaubnis hinter Logins oder Paywalls scrapen: Das ist rechtlich und ethisch heikel.
- Aktivitäten protokollieren und Fehler abfangen: Bei Blockaden lieber pausieren und die Strategie anpassen.
Mehr zu Ethik und Recht beim Scrapen findest du in diesem Leitfaden.
Fazit: das richtige Tool für deine Web-Scraping-Projekte
Web Scraping hat sich enorm gewandelt – von manuellen Skripten bis zu KI-gestützten No-Code-Tools. Selenium Python ist für Entwickler, die komplexe, dynamische Seiten auslesen wollen, eine starke Option – aber mit Lernkurve und Wartungsaufwand. Für die meisten Business-Anwender bietet Thunderbit einen schnelleren, einfacheren Weg zu strukturierten Webdaten – inklusive Übersetzung, Sentiment-Analyse und Export mit einem Klick.
Mein Rat: Probier beide Ansätze aus. Bist du Entwickler, schreib ein Selenium-Skript für eine Seite wie allbirds.com und sieh, wie aufwendig es ist. Willst du schnelle Ergebnisse (oder dir den Aufwand sparen), teste Thunderbit – es gibt eine kostenlose Version, mit der du direkt loslegst.
Und denk dran: Scrape verantwortungsvoll, nutze deine Daten sinnvoll – und möge deine IP nie gesperrt werden.
Du willst tiefer einsteigen? Hier ein paar weiterführende Ressourcen:
- Beautiful Soup vs Selenium: Detaillierter Vergleich 2025
- Die besten Web Scraping Tools & Software 2025
- Website-Daten mit KI nach Excel extrahieren – so geht’s
- Thunderbit Chrome Extension Download-Seite
Thunderbit KI-Web-Scraper kostenlos testen Get Started Free




