

Mein erstes Scraping-Projekt hat mich vor allem eines gelehrt: Geduld. Ich wollte einen kleinen Preis-Tracker für Amazon bauen, hatte Python am Start, eine Kanne Kaffee daneben und das Gefühl, in einer Stunde fertig zu sein. Stattdessen saß ich am Abend immer noch über XPath-Selektoren, kaputter Paginierung und Fehlermeldungen, die ich lieber verschweige. Wer schon mal mit Code versucht hat, Webdaten einzufangen, kennt diese Mischung aus Neugier und „Warum eigentlich so umständlich?“ wahrscheinlich nur zu gut.
Genau hier liegt der Punkt: Web-Scraping ist längst kein Spezialgebiet für Data Scientists oder Entwickler mehr. Vertrieb, E-Commerce, Marketing – überall sitzen Leute, die aus dem Wildwuchs des Webs verwertbare Zahlen ziehen wollen. Der Markt für Scraping-Software hat das längst eingeholt: 2024 lag er bei 1,01 Milliarden US-Dollar (ca. 0,94 Mrd. €) und soll bis 2032 auf 2,49 Milliarden US-Dollar (ca. 2,31 Mrd. €) klettern. Python und Frameworks wie Scrapy bleiben für große, individuelle Projekte die erste Wahl – nur eben nicht für Einsteiger. Deshalb gehen wir in diesem Tutorial Scrapy Schritt für Schritt durch (am echten Amazon-Beispiel) und ich zeige dir parallel eine KI-gestützte Alternative für alle, die nicht programmieren wollen: Thunderbit.
Was ist Scrapy Python? Dein Power-Tool für Web-Scraping
Erst mal die Grundlagen. Scrapy ist ein Open-Source-Framework in Python, gebaut fürs Crawlen und Scrapen von Websites. Du kannst es dir als Werkzeugkasten vorstellen, mit dem du eigene Spider schreibst – so heißen die Crawler bei Scrapy. Diese Spider klicken sich durch Websites, folgen Links, arbeiten Paginierung ab und ziehen strukturierte Daten in großem Umfang heraus.
Und warum nicht einfach requests plus BeautifulSoup? Für schnelle Einzelabfragen sind diese Bibliotheken super. Scrapy zielt aber auf umfangreiche, vielschichtige Projekte – also genau die Situationen, in denen du:
- Tausende Seiten crawlen musst (etwa jeden Artikel in einem Shop-Katalog)
- Links automatisch verfolgen und Paginierung abarbeiten willst
- Anfragen asynchron verarbeiten möchtest, um Tempo zu gewinnen
- Daten sauber, strukturiert und reproduzierbar exportieren willst
Kurz: Scrapy ist das Allzweckwerkzeug fürs Scraping – mächtig, flexibel und für Anfänger anfangs durchaus eine Hürde.
Warum Scrapy Python für Web-Scraping verwenden?
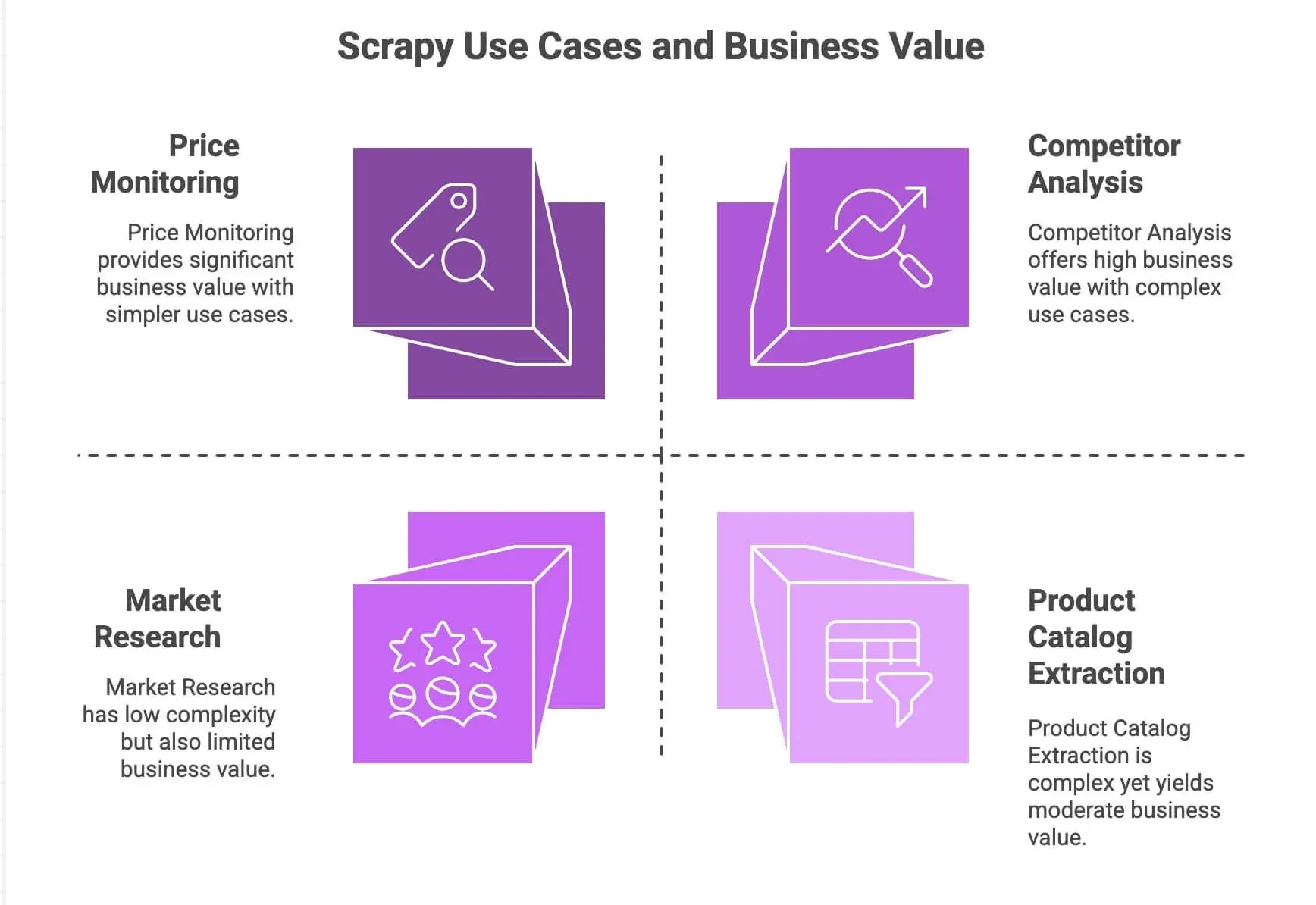
Warum landen Entwickler und Datenteams also immer wieder bei Scrapy? Ein knapper Überblick über die Stärken:
| Anwendungsfall | Stärken von Scrapy | Geschäftlicher Nutzen |
|---|---|---|
| Preisüberwachung | Handhabt Paginierung, asynchrone Anfragen, Zeitplanung | Wettbewerbsvorteile sichern, dynamische Preisgestaltung |
| Extraktion von Produktkatalogen | Folgt Links, extrahiert strukturierte Daten | Produktdatenbanken aufbauen, Analytics speisen |
| Wettbewerbsanalyse | Skalierbar, robust gegenüber Website-Änderungen | Trends, neue Produkteinführungen und Lagerbestände verfolgen |
| Marktforschung | Modulare Pipelines zur Bereinigung/Transformation von Daten | Bewertungen aggregieren, Sentiment-Analyse durchführen |
Der Motor von Scrapy arbeitet asynchron (er baut auf Twisted auf) und ruft so mehrere Seiten parallel ab – das macht das Framework schnell und gut skalierbar. Der modulare Aufbau lässt dich eigene Logik einklinken, etwa Proxies, User-Agents oder Schritte zur Datenbereinigung. Und über Pipelines verarbeitest, validierst und exportierst du deine Daten so, wie du sie brauchst – als CSV, als JSON, in eine Datenbank, ganz wie es passt.
Für Teams mit Python-Erfahrung ist Scrapy ein echtes Arbeitstier. Ehrlich bleiben muss man trotzdem: Für die meisten Business-Anwender ist es weit von „Plug and Play“ entfernt.
So richtest du deine Scrapy-Python-Umgebung ein
Du willst es selbst ausprobieren? So baust du Scrapy von Grund auf auf:
1. Scrapy installieren
Vergewissere dich zuerst, dass Python 3.10+ installiert ist (Scrapy 2.15.x hat 2026 den Support für 3.9 fallen gelassen). Dann ab ins Terminal und ausführen:
pip install scrapy
Die Installation prüfst du mit:
scrapy version
Unter Windows oder mit Anaconda lohnt es sich, eine virtuelle Umgebung anzulegen, damit nichts kollidiert. Scrapy läuft auf Windows, macOS und Linux gleichermaßen.
2. Ein neues Scrapy-Projekt erstellen
Wir starten ein Projekt namens amazonscraper:
scrapy startproject amazonscraper
Heraus kommt eine Ordnerstruktur wie diese:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
Wozu dienen diese Dateien?
scrapy.cfg: Projektkonfiguration (anfassen musst du das selten)items.py: Hier definierst du deine Datenmodelle (etwa ein Produkt mit Name, Preis usw.)pipelines.py: Hier bereinigst, validierst und exportierst du deine Datenmiddlewares.py: Für fortgeschrittene Dinge (Proxies, eigene Header)settings.py: Hier stellst du Scrapys Verhalten ein (Concurrency, Verzögerungen usw.)spiders/: Hier wohnt deine eigentliche Scraping-Logik
Wenn dir das jetzt schon nach viel aussieht – willkommen im Club. Genau an diesem Punkt steigen viele Nicht-Programmierer innerlich aus.
Einen Python-Scraper bauen: Amazon-Produktdaten mit Scrapy scrapen
Schauen wir uns ein echtes Beispiel an: Produktdaten aus den Amazon-Suchergebnissen ziehen. (Kurzer Hinweis: Die Nutzungsbedingungen von Amazon erlauben kein Scraping, und beim Bot-Schutz ist Amazon ziemlich konsequent. Das hier dient ausschließlich zu Lernzwecken!)
1. Einen Spider erstellen
Leg im Ordner spiders/ eine Datei amazon_spider.py an:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
Was passiert hier?
- Wir starten auf einer Amazon-Suchergebnisseite für „smartphones“.
- Pro Produkt holen wir Name, Preis und Bewertung über XPath-Selektoren.
- Wir suchen den Link zur nächsten Seite und sagen Scrapy, dass es ihm folgen und weiter scrapen soll.
2. Deinen Spider ausführen
Im Projektstammverzeichnis ausführen:
scrapy crawl amazon_example -o products.json
Fertig – Scrapy crawlt die Suchergebnisse, arbeitet die Paginierung ab und schreibt deine Daten in eine JSON-Datei.
Paginierung und dynamische Inhalte verarbeiten
Dass Scrapy Links von Haus aus verfolgt und Paginierung verarbeitet, gehört zu seinen größten Stärken. Aber was ist mit dynamischen Inhalten – also Seiten, die ihre Daten per JavaScript nachladen? Standardmäßig sieht Scrapy nur statisches HTML. Sobald du Inhalte brauchst, die JavaScript erzeugt (Infinite Scroll, aufklappbare Bewertungen), musst du Tools wie Selenium oder Splash dazuholen. Und damit bist du wieder in einem ganz neuen Kaninchenbau gelandet.
Daten mit Scrapy Python verarbeiten und exportieren
Wenn die Daten erst mal gescraped sind, willst du sie meist noch aufräumen und an einen sinnvollen Ort bringen.
- Pipelines: In
pipelines.pyschreibst du Python-Klassen, die deine Daten bereinigen, prüfen oder anreichern – etwa Preise in Zahlen umwandeln, unvollständige Zeilen rauswerfen oder eine Übersetzungs-API aufrufen. - Export: Mit dem
-o-Flag schreibt Scrapy direkt nach CSV, JSON oder XML. Für aufwendigere Exporte (etwa rüber nach Google Sheets) musst du selbst Code schreiben oder Bibliotheken von Drittanbietern einbinden.
Du willst Sentiment-Analysen fahren oder Produktbeschreibungen übersetzen? Dann hängst du externe APIs oder Python-Bibliotheken dran – mitgeliefert ist das nicht.
Die versteckten Kosten: Herausforderungen von Scrapy Python für Business-User
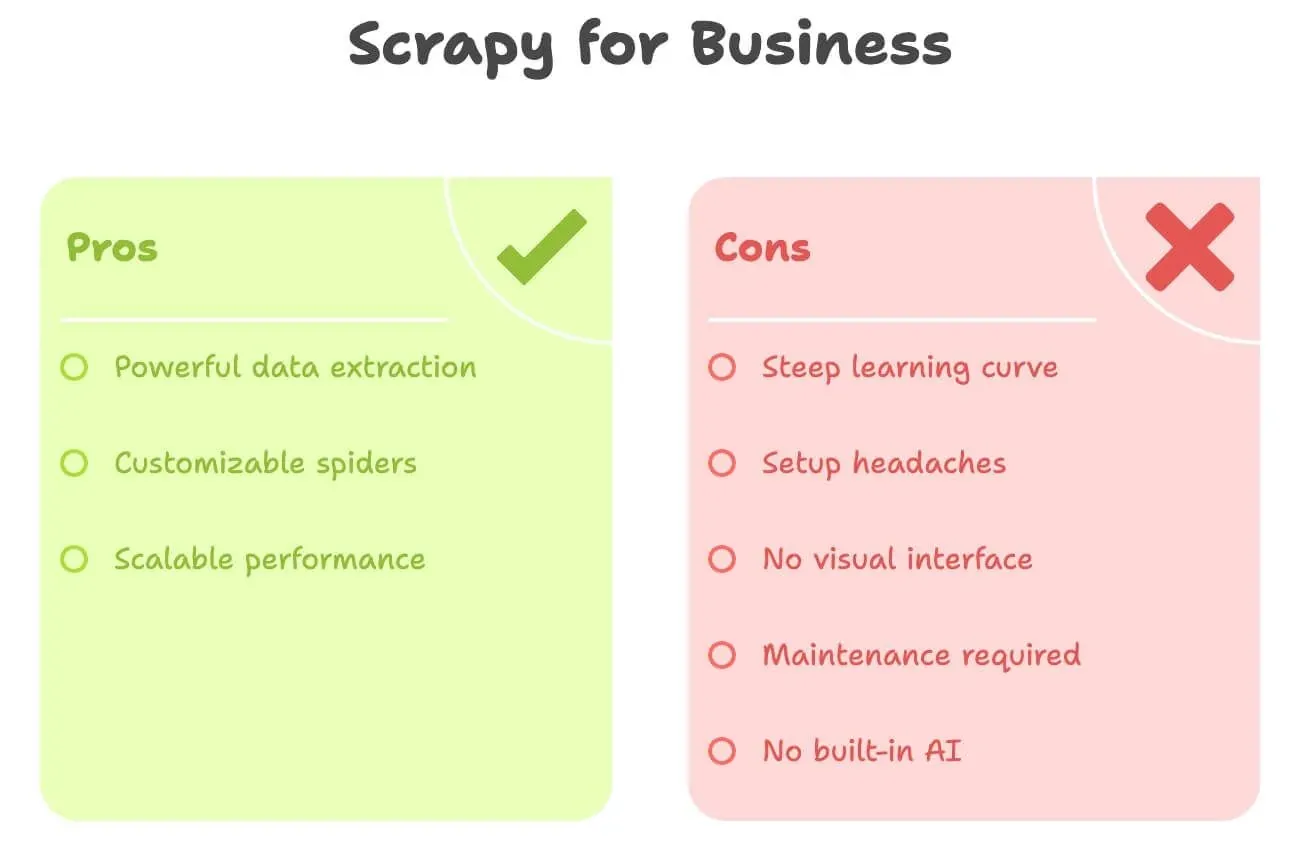
Bleiben wir ehrlich: Scrapy ist mächtig, aber für Nicht-Entwickler alles andere als einladend. Diese Punkte bremsen die meisten Business-Anwender aus:
- Steile Lernkurve: Du brauchst Python, HTML, XPath-/CSS-Selektoren und musst die Projektstruktur von Scrapy verstehen. Bis sich das routiniert anfühlt, vergehen schnell Tage oder Wochen.
- Installationsfrust: Python einrichten, Abhängigkeiten verwalten, Fehler beheben – das kann zäh werden, vor allem unter Windows.
- Keine visuelle Oberfläche: Alles läuft über Code. Du kannst nicht einfach auf der Seite anklicken, was du haben willst.
- Wartung: Ändert sich die Website, bricht dein Spider. Dann heißt es reparieren.
- Keine eingebaute KI: Übersetzen, zusammenfassen, Sentiment auswerten? Jedes Mal zusätzlicher Code.
Hier ein schneller Vergleich:
| Herausforderung | Scrapy (Python) | Bedarf von Business-Usern |
|---|---|---|
| Programmieren erforderlich | Ja | Lieber ohne Code |
| Einrichtungszeit | Stunden (oder Tage) | Minuten |
| Wartung | Laufend (bei Website-Änderungen) | Minimal |
| Datenexport | CSV/JSON (manuelle Integration) | Direkt nach Excel/Sheets/Notion |
| KI-Funktionen | Keine (DIY-Integration) | Integrierte Übersetzung/Sentiment |
Wenn du als Solo-Marketer, im Vertrieb oder im Operations-Team arbeitest, fühlt sich Scrapy schnell an, als würdest du mit einer Bazooka auf Wasserballons zielen.
Thunderbit kennenlernen: Die No-Code-Alternative zu Scrapy Python
An dieser Stelle kommt Thunderbit ins Spiel. Ich baue seit Jahren Automatisierungstools, und eines ist klar: Die meisten Business-Anwender wollen gar nicht programmieren – sie wollen schnell an ihre Daten.
Thunderbit ist ein KI-gestützter Web-Scraper, der als Chrome-Erweiterung läuft. Gedacht ist er für nicht-technische Nutzer, die:
- mit ein paar Klicks Daten von jeder Website ziehen wollen
- in normaler Sprache beschreiben möchten, was sie brauchen („Produktname, Preis, Bewertung“)
- Paginierung und Unterseiten automatisch abgearbeitet haben wollen
- Daten direkt nach Excel, Google Sheets, Airtable oder Notion schicken möchten
- Übersetzungen, Zusammenfassungen oder Sentiment-Analysen gleich im Arbeitsfluss erledigen wollen
Kein Python. Keine Selektoren. Kein Wartungsstress.
Wie du mit KI jede Website scrapest Get Started Free
Thunderbit ist für Business-Anwender gemacht, die schnell vorankommen und die mühsame Arbeit der KI überlassen wollen.
Thunderbit vs. Scrapy Python: Direktvergleich
Stellen wir beide direkt gegenüber:
| Aspekt | Scrapy (Python) | Thunderbit (KI-Tool) |
|---|---|---|
| Erforderliche Kenntnisse | Python, HTML, Selektoren | Keine — klicken statt codieren, natürliche Sprache |
| Einrichtungszeit | Stunden (installieren, programmieren, debuggen) | Minuten (Chrome-Erweiterung installieren, anmelden) |
| Datenstrukturierung | Manuell (Items, Pipelines definieren) | KI erkennt Spalten automatisch und schlägt Felder vor |
| Paginierung/Unterseiten | Code erforderlich | 1 Klick (KI übernimmt) |
| Übersetzung | Benutzerdefinierter Code oder API-Integration | Integriert — einfach „Übersetzen“ aktivieren |
| Sentiment-Analyse | Externe Bibliothek/API | Integriert — Spalte „Sentiment“ hinzufügen |
| Exportoptionen | CSV/JSON (manueller Import nach Sheets/Excel) | 1-Klick-Export nach Excel, Google Sheets, Airtable, Notion |
| Wartung | Manuell (Code bei Website-Änderungen aktualisieren) | KI passt sich kleineren Website-Änderungen automatisch an |
| Skalierung | Am besten für große, laufende Projekte | Am besten für schnelle Aufgaben, mittlere Größenordnung (Hunderte/Tausende Zeilen) |
| Kosten | Kostenlos (kostet aber Zeit und Entwicklerressourcen) | Kostenloser Tarif + kostenpflichtige Pläne (ab 9 $/Monat bzw. ca. 9 €/Monat, spart aber enorm viel Zeit und Ärger) |
Wann du Scrapy Python und wann Thunderbit für Web-Scraping wählen solltest
Meine Faustregel sieht so aus:
- Scrapy verwenden, wenn:
- Du Entwickler bist oder einen im Team hast
- Du Zehntausende Seiten scrapen oder eine maßgeschneiderte, dauerhafte Pipeline aufbauen musst
- Die Website sehr komplex ist oder anspruchsvolle Logik verlangt
- Du volle Kontrolle willst (und Wartung dich nicht stört)
- Thunderbit verwenden, wenn:
- Du nicht programmierst (oder schlicht nicht willst)
- Du Daten schnell brauchst, für eine einmalige oder wiederkehrende Aufgabe
- Du integrierte Übersetzung, Sentiment oder Data Enrichment willst
- Dir Tempo und Flexibilität wichtiger sind als maximale Anpassbarkeit
Hier ein kurzer Entscheidungsfluss:
- Kannst du in Python programmieren?
- Ja → Scrapy oder Thunderbit (für schnelle Erfolge)
- Nein → Thunderbit
- Ist dein Projekt groß und dauerhaft?
- Ja → Scrapy
- Nein → Thunderbit
- Brauchst du Übersetzung oder Sentiment-Analyse?
- Ja → Thunderbit
- Nein → Beides möglich
Schritt für Schritt: Amazon-Produktdaten mit Thunderbit scrapen (ohne Code)
Machen wir unser Amazon-Beispiel noch einmal – diesmal auf die bequeme Art.
1. Thunderbit installieren
- Lade die Thunderbit-Chrome-Erweiterung herunter
- Registriere dich (kostenloser Tarif verfügbar)
Thunderbit-Chrome-Erweiterung kostenlos testen
2. Zu Amazon gehen und nach deinem Produkt suchen
- Öffne Amazon.com und suche nach „Laptops“ (oder einem beliebigen anderen Produkt)
3. Thunderbit auf der Seite starten
- Klicke auf das Thunderbit-Symbol im Browser
- Das Seitenpanel öffnet sich und erkennt die Amazon-Seite
4. KI-Vorschläge für Felder verwenden
- Klicke auf „KI-Felder vorschlagen“
- Thunderbits KI scannt die Seite und schlägt Spalten wie „Produktname“, „Preis“, „Bewertung“ und „Anzahl der Bewertungen“ vor
- Ergänze oder entferne Spalten nach Bedarf (du willst „Produkt-URL“ oder „Prime-Berechtigung“? Einfach eintippen)
5. Paginierung und Unterseiten-Scraping aktivieren
- Schalte Paginierung ein: Thunderbit klickt selbst auf „Weiter“ und scrapt alle Seiten
- Schalte Unterseiten-Scraping ein: Thunderbit öffnet die Detailseite jedes Produkts und holt Zusatzinfos wie Beschreibungen oder ASIN-Nummern
6. Das Scraping starten
- Klicke auf Scrapen
- Sieh zu, wie Thunderbit die Daten Seite für Seite in Echtzeit einsammelt
7. Übersetzen und Sentiment analysieren (optional)
- Produktbeschreibungen übersetzen? Aktiviere für diese Spalte „Übersetzen“
- Bewertungen auf Stimmung prüfen? Füge eine Spalte „Sentiment“ hinzu – Thunderbits KI füllt sie automatisch
8. Daten exportieren
- Klicke auf Exportieren
- Wähle Excel, Google Sheets, Airtable oder Notion
- Deine Daten sind sofort einsatzbereit – kein manueller Import, kein CSV-Gefummel
9. Wiederkehrende Scrapes planen (optional)
- Lege einen Zeitplan fest (z. B. täglich um 8 Uhr)
- Thunderbit scrapt automatisch und aktualisiert dein gewähltes Ziel
Das war's. Kein Code, keine Selektoren, keine Wartung. Nur Daten, fertig fürs Geschäft.
Bonus-Tipps: Mehr aus deinen Web-Scraping-Projekten herausholen
Egal ob Scrapy, Thunderbit oder ein anderes Tool – hier ein paar Best Practices, die ich mir auf die harte Tour beigebracht habe:
- Daten prüfen: Achte immer auf fehlende oder seltsame Werte (Preise von 0 $ oder leere Namen)
- Regeln einhalten: Wirf einen Blick in die Nutzungsbedingungen, respektiere
robots.txtund überlaste keine Server - Automatisierung mit Augenmaß: Nutze Zeitpläne, um Daten frisch zu halten, aber scrappe nicht öfter als nötig
- Kostenlose Tools mitnehmen: Thunderbit bringt kostenlose E-Mail-, Telefon- und Bild-Extraktoren mit – praktisch für Lead-Generierung oder Content-Kuratierung
- Für die Analyse strukturieren: Exportiere direkt nach Sheets/Excel, damit du filtern, Pivot-Tabellen bauen und visualisieren kannst
Mehr Tipps gibt's im Thunderbit-Blog oder im Leitfaden zum Scrapen jeder Website mit KI.
Wie du Website-Daten mit KI nach Excel scrapest Get Started Free
Mehr Tipps gibt's im Thunderbit-Blog oder im Leitfaden zum Scrapen jeder Website mit KI.
Fazit: Web-Scraping leicht gemacht — wähle das richtige Tool für dein Team
Letztlich gilt: Scrapy ist ein Kraftpaket für Entwickler, aber für die meisten Business-Anwender schlicht überdimensioniert. Wenn du dich mit Python wohlfühlst und einen maßgeschneiderten Scraper für große Datenmengen brauchst, ist Scrapy eine ausgezeichnete Wahl. Willst du dagegen schnell vorankommen, auf Code verzichten und Daten samt eingebauter Übersetzung und Sentiment-Analyse bekommen, dann führt der Weg über Thunderbit.
Ich habe aus nächster Nähe miterlebt, wie viel Zeit und Frust Thunderbit nicht-technischen Teams abnimmt. Du kommst in Minuten – nicht in Stunden oder Tagen – von „Hätte ich diese Daten doch nur“ zu „Sie stehen schon in meiner Tabelle“. Und mit Funktionen wie KI-Felder vorschlagen, Unterseiten-Scraping und Export per Klick war es nie einfacher, das Web in nutzbare Erkenntnisse zu verwandeln.
Wenn du also das nächste Mal Produktdaten scrapen, Preise überwachen oder eine Lead-Liste aufbauen willst, frag dich: Willst du Python schreiben oder Ergebnisse sehen? Teste Thunderbits kostenlosen Tarif und sieh selbst, wie viel leichter Web-Scraping sein kann.
Neugierig geworden? Schau dir die offizielle Thunderbit-Website an, lade die Chrome-Erweiterung herunter oder tauche tiefer in Best Practices für Web-Scraping im Thunderbit-Blog ein.
Weiterführende Lektüre:
- Was ist Data Scraping und wie macht man es 2026?
- Wie du Website-Daten mit KI nach Excel scrapest
- Die besten Web-Scraping-Tools und -Software 2026
- State of Web Scraping Report
Hinweis: Stelle immer sicher, dass deine Web-Scraping-Aktivitäten mit den Website-Nutzungsbedingungen und den lokalen Gesetzen übereinstimmen. Im Zweifel solltest du rechtlichen Rat einholen — niemand will der „Scraper“ sein, der wegen einer Tabelle eine Unterlassungsaufforderung bekommt.
Geschrieben von Shuai Guan, Mitgründer und CEO bei Thunderbit. Ich habe jahrelange Erfahrung in SaaS, Automatisierung und KI — damit du sie nicht haben musst.
KI-Web-Scraper ausprobieren Get Started Free




