ist eine Chrome-Erweiterung für einen AI Web Scraper, mit der Business-User mithilfe von KI Daten von Websites extrahieren können. Der Kernpunkt dabei: Was auf der Preisübersicht von ScrapingBee erstmal günstig aussieht, kann im echten Betrieb ganz anders ausfallen, sobald Credits bei realen Workloads im 5- bis 75-fachen des Grundpreises verbraucht werden. Dieser Test beleuchtet fünf Aspekte, die in den meisten Artikeln fehlen: die tatsächlichen Kosten im großen Maßstab, selektorbasierte vs. KI-Extraktion, die Bedienbarkeit für Nicht-Entwickler, Daten-Workflows nach dem Scraping und Zuverlässigkeits-Benchmarks für 2026. Wenn du ScrapingBee für dein Team prüfst — egal ob du Entwickler bist, Leiter eines Sales-Operations-Teams oder Gründer — findest du hier die Analyse, die du brauchst.
Was ist ScrapingBee? Ein kurzer Überblick
ScrapingBee ist eine Web-Scraping-API, die Proxy-Rotation, JavaScript-Rendering und CAPTCHA-Lösungen übernimmt, damit Entwickler Daten von Websites extrahieren können, ohne ihre eigene Scraping-Infrastruktur aufzubauen. Du schickst eine HTTP-Anfrage mit Parametern ab und bekommst HTML zurück — oder bei bestimmten Endpunkten JSON. Eine visuelle Oberfläche oder ein Klick-Interface, um Scrapes zusammenzustellen, gibt es nicht.
Zu den Kernfunktionen gehören:
- Rotierende und Premium-Proxys (classic, premium, stealth, residential)
- Headless-Browser-Rendering (vollständiges Chrome, standardmäßig aktiviert)
- Automatisches Umgehen von CAPTCHA-Abfragen
- Google Search API (strukturiertes JSON: organische Ergebnisse, Anzeigen, Maps, Knowledge Graph, People Also Ask, Bilder, News)
- Screenshot-Erfassung (Standard, Full-Page oder gezielt per CSS-Selektor)
- Geografisches Targeting über den Parameter
country_code - CSS-/XPath-Extraktionsregeln (deklarativ, JSON-basiert, liefert strukturiertes JSON)
- Spezielle APIs für Amazon-, Walmart-, YouTube- und ChatGPT-Scraping
- KI-Extraktion (seit ca. 2024–2025):
ai_query,ai_extract_rules,ai_selector(+5 Credits pro Anfrage) - CLI-Tool (eingeführt ca. 2025–2026): Batch-Verarbeitung, Crawling, Sitemap-Parsing, CSV-Anreicherung, geplante Cron-Jobs, Proxy-Eskalation
ScrapingBee wurde 2019 in Frankreich gegründet und wuchs bis Anfang 2026 mit einem Team von nur 4–6 Personen auf rund und über 2.500 Kunden (SAP, Zapier, Deloitte, Zillow) — komplett gebootstrapped. Im Juni 2025 übernahm die in einem Deal im achtstelligen Bereich. Marke und Führung bleiben unabhängig, und das Support-Team wurde für eine bessere Abdeckung über verschiedene Zeitzonen hinweg.
Wichtig zu wissen: ScrapingBee hat weiterhin keinen nativen visuellen Builder, keine Point-and-Click-GUI und keinen eingebauten Scheduler im Web-Dashboard. Zeitpläne lassen sich nur über das CLI-Tool, Cron-Jobs oder Drittanbieter-Automatisierung (Zapier, Make, n8n) umsetzen. Die veröffentlichten „No-Code“-Anleitungen beziehen sich auf Integrationen mit Make und Zapier — nicht auf eine native No-Code-Oberfläche.
Für wen ist ScrapingBee wirklich gemacht?
ScrapingBee richtet sich an Entwickler, die mit Python- oder cURL-Aufrufen, HTML-Strukturen und CSS-/XPath-Selektoren vertraut sind. Die Dokumentation ist stark code-lastig und setzt vor allem auf Python- und cURL-Beispiele. Ein Rezensent auf merkte an, dass sie „keine Beispiele in JavaScript bereitstellen“, und ein anderer beschrieb die Doku als „umfangreich, man braucht von einem Tag bis zu einer Woche, um sich durchzuarbeiten“.
Doch die Zielgruppe, die 2026 nach „ScrapingBee review“ sucht, ist breiter als nur Backend-Ingenieure. Dazu gehören Marketing-Manager, die Lead-Listen aufbauen, Sales-Operations-Teams, die CRM-Daten anreichern, E-Commerce-Teams, die Konkurrenzpreise überwachen, und Gründer, die Tools für ihre Teams bewerten. In jedem Abschnitt unten markiere ich, ob eine Funktion oder Einschränkung für Entwickler, Business-User oder beide relevant ist.
ScrapingBee-Preise auf einen Blick
Hier sind die aktuellen Tarife von ScrapingBee (Stand April 2026):
| Tarif | Monatlicher Preis | API-Credits/Monat | Gleichzeitige Anfragen |
|---|---|---|---|
| Freelance | 49 $ | 250.000 | 10 |
| Startup | 99 $ | 1.000.000 | 50 |
| Business | 249 $ | 3.000.000 | 100 |
| Business+ | 599 $ | 8.000.000 | 200 |
| Enterprise | Vertrieb kontaktieren | 41 Mio.+ | Individuell |
Bei jährlicher Zahlung gibt es . Ein kostenloser Testzugang umfasst 1.000 API-Credits ohne Kreditkarte. Die Google Search API wurde nach der Übernahme kürzlich von pro Aufruf reduziert.
Diese großen Credit-Zahlen wirken großzügig. Ganz so großzügig sind sie aber nicht.
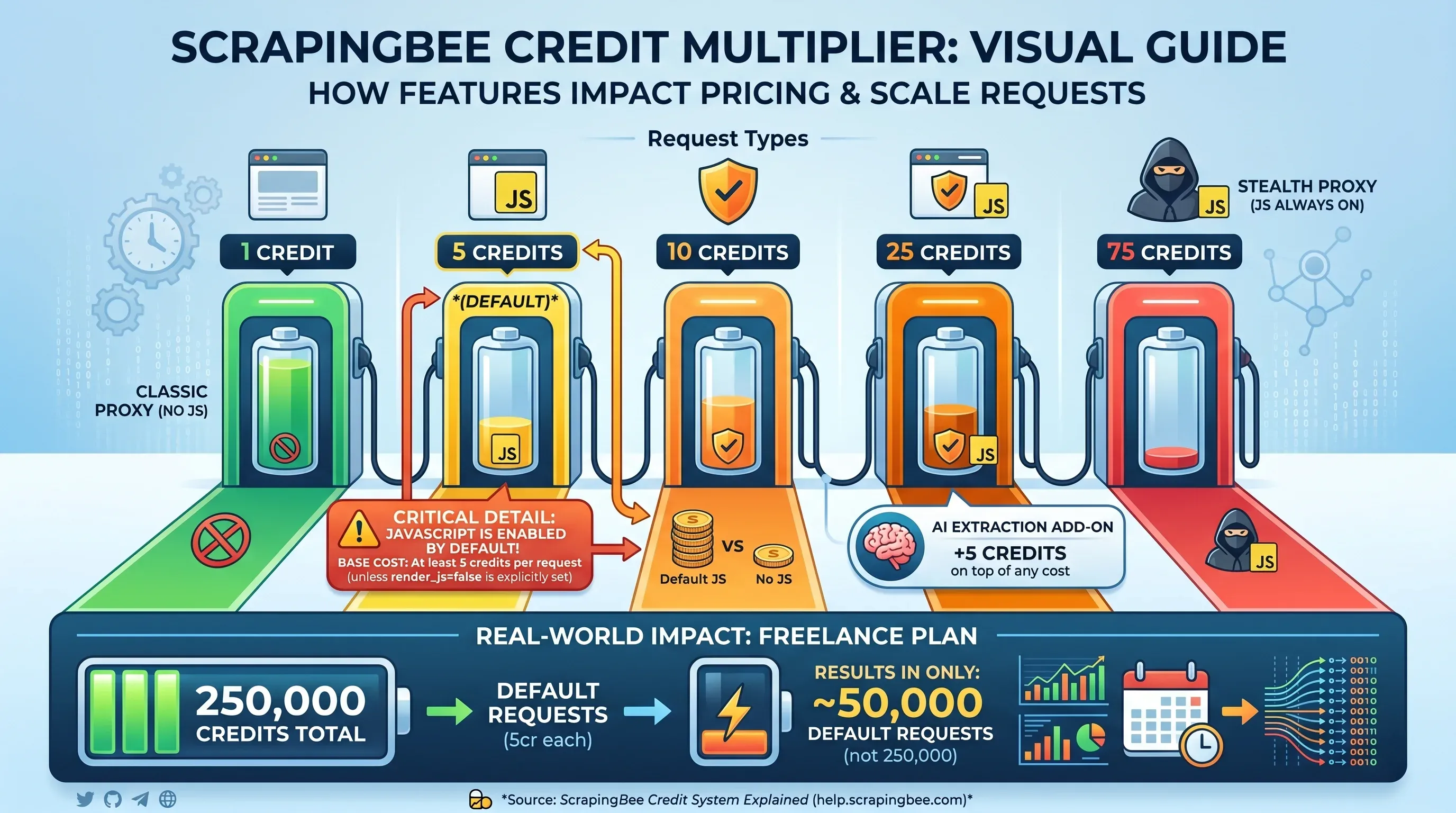
Tabelle zum Credit-Multiplikator
Hier wird es bei ScrapingBee kompliziert. Die angegebene Credit-Zahl entspricht nicht der Anzahl der Seiten, die du scrapen kannst — sie hängt davon ab, welche Funktionen du pro Anfrage aktivierst:
| Anfragetyp | Credits pro Anfrage |
|---|---|
Classic Proxy, kein JS-Rendering (render_js=false) | 1 Credit |
| Classic Proxy, JS-Rendering (Standard) | 5 Credits |
| Premium Proxy, kein JS-Rendering | 10 Credits |
| Premium Proxy, JS-Rendering | 25 Credits |
| Stealth Proxy (JS immer aktiv) | 75 Credits |
| KI-Extraktion als Add-on | +5 Credits zusätzlich |
Wichtiger Punkt: JavaScript-Rendering ist . Wenn du render_js=false nicht explizit setzt, kostet jede Anfrage mindestens 5 Credits. Das heißt: Die 250.000 Credits im Freelance-Tarif reichen in der Praxis nur für 50.000 Standardanfragen — nicht für 250.000.
Die versteckte Credit-Rechnung, die kaum jemand zeigt
So viel kostet ScrapingBee für 10.000 Seiten in unterschiedlichen Szenarien und Tarifen:
| Szenario | Benötigte Credits | Freelance (49 $/250K) | Startup (99 $/1M) | Business (249 $/3M) |
|---|---|---|---|---|
| 10K Seiten (statisches HTML, 1 Cr) | 10.000 | ✅ Abgedeckt (0,20 $/1K) | ✅ Abgedeckt (0,10 $/1K) | ✅ Abgedeckt (0,08 $/1K) |
| 10K Seiten (JS-Rendering, 5 Cr) | 50.000 | ✅ Abgedeckt (0,98 $/1K) | ✅ Abgedeckt (0,50 $/1K) | ✅ Abgedeckt (0,42 $/1K) |
| 10K Seiten (Premium Proxy + JS, 25 Cr) | 250.000 | ⚠️ Genau am Limit (4,90 $/1K) | ✅ Abgedeckt (2,48 $/1K) | ✅ Abgedeckt (2,08 $/1K) |
| 10K Seiten (Stealth Proxy, 75 Cr) | 750.000 | ❌ Weit über dem Limit | ✅ Knapp abgedeckt (7,43 $/1K) | ✅ Abgedeckt (6,23 $/1K) |
Dieselben 10.000 Seiten können je nach Proxy- und Rendering-Konfiguration zwischen 0,20 $ und 7,43 $ pro Tausend kosten. Und du weißt oft erst nach dem Testen, welche Konfiguration du wirklich brauchst.
Budget-Szenario: Lead-Generierung bei 10.000 Seiten/Monat
Ein Vertriebsteam scraped monatlich 10.000 Unternehmensseiten zur Lead-Generierung. Die meisten modernen B2B-Websites laufen auf React oder Vue, daher ist JS-Rendering nötig:
- Benötigte Credits: 50.000 (10K × 5 Credits)
- Freelance-Tarif (49 $): Deckt das ab, 200K Credits bleiben übrig
- Falls Premium-Proxys nötig sind: 250.000 Credits — exakt das Kontingent eines Freelance-Tarifs, ohne Puffer
- Falls Stealth-Proxys nötig sind: 750.000 Credits — erfordert den Startup-Tarif für 99 $/Monat
Budget-Szenario: Preisüberwachung im E-Commerce bei 100.000 Seiten/Monat
Ein E-Commerce-Team überwacht 100.000 Produktseiten auf Konkurrenzseiten:
| Konfiguration | Benötigte Credits | Erforderlicher Tarif | Monatliche Kosten |
|---|---|---|---|
| Statisches HTML (1 Cr) | 100.000 | Freelance | 49 $ |
| JS-Rendering (5 Cr) | 500.000 | Startup | 99 $ |
| Premium Proxy + JS (25 Cr) | 2.500.000 | Business | 249 $ |
| Stealth Proxy (75 Cr) | 7.500.000 | Business+ | 599 $ |
Dieselbe Aufgabe kostet also zwischen 49 $ und 599 $ pro Monat. Das ist kein Rundungsfehler — es ist ein 12-facher Kostenunterschied je nach Konfiguration.
„Der Einstiegspreis von 49 $ ist die irreführendste Zahl im Markt der Scraping-APIs.“ —
„Credits sind schnell verbraucht, wenn JavaScript-Rendering oder erweiterte Funktionen genutzt werden. Das macht das Tool für kleinere Projekte oder Teams mit unvorhersehbaren Scraping-Volumina schwerer zu rechtfertigen.“ — Nick S, Manager, Computer Software,
Und ungenutzte Credits werden von Monat zu Monat .
Wie sich die Kosten von ScrapingBee im Vergleich zu Wettbewerbern darstellen

Vergleich mit Mittelklasse-Tarifen für eine faire Gegenüberstellung:
| Szenario (pro 1K Seiten) | ScrapingBee (99 $/1M) | ScraperAPI (149 $/1M) | Scrapfly (100 $/1M) |
|---|---|---|---|
| Statisches HTML | 0,10 $ | 0,15 $ | 0,10 $ |
| JS-gerenderte Seiten | 0,50 $ | 1,64 $ | 0,60 $ |
| Premium + JS | 2,48 $ | 3,73 $ | 3,00 $ |
| Stealth/Ultra-Premium + JS | 7,43 $ | 11,18 $ | N/A |
ScrapingBee ist bei statischen und JS-gerenderten Seiten meist der günstigste Anbieter oder gleichauf. ist durchgehend der teuerste — sein JS-Rendering kostet +10 Credits gegenüber +5 bei ScrapingBee und Scrapfly. Aber unabhängige Tests von zeichnen ein anderes Bild, wenn reale Website-Komplexität berücksichtigt wird:
| Dienst | Durchschn. Kosten pro 1K Anfragen | Erfolgsrate | Durchschn. Antwortzeit |
|---|---|---|---|
| Scrape.do | 0,80 $ | 98,19 % | 4,7 s |
| ScrapingBee | 3,90 $ | 92,69 % | 11,7 s |
| Scrapfly | 4,11 $ | — | — |
| ZenRows | 4,48 $ | 92,64 % | 10,0 s |
| ScraperAPI | 8,49 $ | 92,70 % | 15,7 s |
Thunderbits Credit-Modell: ein anderer Ansatz
nutzt ein grundsätzlich einfacheres Preismodell: 1 Credit = 1 Ausgabereihe, ohne Multiplikatoren für JS-Rendering, Proxy-Typ oder Ziel-Domain. Subpage-Scraping kostet 2 Credits pro Zeile.
| Tarif | Monatlicher Preis | Credits | Kosten pro Zeile |
|---|---|---|---|
| Free | 0 $ | 6 Seiten/Monat | Kostenlos |
| Starter | 15 $ | 500 | 0,030 $ |
| Pro 1 | 38 $ | 3.000 | 0,013 $ |
| Pro 2 | 75 $ | 6.000 | 0,013 $ |
| Pro 3 | 125 $ | 10.000 | 0,013 $ |
| Pro 4 | 249 $ | 20.000 | 0,012 $ |
Ein Thunderbit-Nutzer, der 10.000 Produktlisten von stark JavaScript-basierten E-Commerce-Seiten extrahiert, zahlt 125 $/Monat — unabhängig davon, ob diese Seiten JavaScript-Rendering, Premium-Proxys oder Anti-Bot-Umgehung brauchen. Bei ScrapingBee könnte derselbe Job je nach Konfiguration zwischen 49 $ und 599 $ kosten. Planbarkeit im Budget ist hier ein echtes Thema.
CSS-Selektoren vs. KI-Extraktion: Die Wartungskosten, die du kennen solltest
Die meisten ScrapingBee-Reviews lassen diesen Punkt komplett aus. Dabei ist er wahrscheinlich der wichtigste Faktor für alle, die über Monate oder Jahre in großem Maßstab scrapen wollen.
ScrapingBee nutzt CSS-/XPath-Selektoren, um Daten aus HTML zu extrahieren. Du definierst Extraktionsregeln als JSON-Objekte mit CSS-Selektoren, und ScrapingBee gibt die passenden Daten zurück. Das funktioniert am Anfang gut. Das Problem ist, was danach passiert.
Das Problem mit kaputten Selektoren
Wenn eine Zielwebsite ihr Layout ändert — Klassennamen, DOM-Struktur, Framework-Version — brechen deine CSS-Selektoren. In ausgereiften Scraping-Systemen mit 2.500+ aktiven Jobs zeigen Untersuchungen eine , was 30–35 Korrekturen pro Woche bedeutet, nur um die Extraktoren am Laufen zu halten. Für Organisationen, die 50 Websites scrapen, liegen die jährlichen Wartungsaufwände bei 850–1.300 Stunden und kosten 64.000–156.000 $ bei voll eingerechneten Engineer-Stundensätzen.
Teams unterschätzen das regelmäßig. Erste Schätzungen gehen oft von 10–15 Wartungsstunden pro Monat aus, aber die Realität liegt (40–90 Stunden/Monat). Ein einziger stiller Fehler — wenn ein Selektor bricht, aber weiter leere Daten zurückgibt, ohne Alarm auszulösen — verursacht schätzungsweise 38.000–57.000 $ an Verlusten durch entgangene Verkäufe, Wiederherstellung von Rankings und Arbeitszeit.
Typische Ursachen: Umbenennung von CSS-Klassen bei Framework-Updates, zusätzliche Container um Zielelemente, React-/Vue-/Angular-Versionen, die den DOM umstrukturieren, A/B-Tests mit dynamischen Klassennamen und Anti-Scraping-Verschleierung.
KI-gestützte Extraktion senkt den Wartungsaufwand um 60–80 %
Eine Studie von DataRobot aus 2025 ergab, dass KI-gestützte Scraper nach Website-Relaunches benötigen als traditionelle, selektorbasierte Scraper. Das Verhältnis von Aufbau zu Wartung dreht sich damit praktisch um:
| Metrik | Traditionell (CSS-Selektoren) | KI-gestützt |
|---|---|---|
| Wartung nach Redesigns | Basiswert | 70 % weniger |
| Zeitaufteilung (Einrichtung : Wartung) | 20 % : 80 % | 5 % : 95 % unter Einbezug von Daten |
| Gesamtreduktion des Wartungsaufwands | Basiswert | 60–80 % weniger |
| Geschwindigkeit bei JS-lastigen Seiten | Basiswert | 30–40 % schneller |
Einrichtungszeit: Selektoren schreiben vs. von KI vorgeschlagene Felder
ScrapingBee-Setup: Seitenquelltext prüfen → CSS-Selektoren identifizieren → Extraktionsregeln als JSON schreiben → testen und debuggen → Sonderfälle für Seitenvarianten behandeln → auf Brüche achten → kaputte Selektoren nach Website-Updates reparieren.
Thunderbit-Setup: Seite in Chrome öffnen → auf „AI Suggest Fields“ klicken → die KI liest die Seite und schlägt Spalten mit passenden Datentypen vor → auf „Scrape“ klicken. Kein Selektorschreiben, kein Blick in den Quellcode. Thunderbits KI wird von mehreren Foundation Models (ChatGPT, Gemini, Claude, DeepSeek R1) unterstützt, die Webseiten visuell wie ein Mensch lesen.
Thunderbits gehen noch einen Schritt weiter: Jede Spalte kann eine eigene KI-Anweisung erhalten, die Daten schon während der Extraktion verändert — Datumsangaben formatieren, Texte übersetzen, Produkte kategorisieren, Namen aufteilen, Telefonnummern normalisieren. Dadurch entfällt ein separater Nachbearbeitungsschritt, den ScrapingBee-Nutzer selbst bauen müssen.
Strukturiertes Ergebnis: Rohes HTML vs. direkt nutzbare Zeilen
| Aspekt | ScrapingBee (selektorbasiert) | Thunderbit (KI-gestützt) |
|---|---|---|
| Standardausgabe | Rohes HTML | Strukturierte Zeilen mit typisierten Spalten |
| Strukturierte Extraktion | Erfordert CSS-/XPath-Regeln oder KI-Add-on (+5 Credits) | KI erkennt Felder automatisch |
| Unterstützte Datentypen | Text (HTML-Parsing erforderlich) | Text, Zahl, Datum, URL, E-Mail, Telefon, Bild |
| Robustheit bei Layoutänderungen | ⚠️ Manuelle Selektor-Updates nötig | ✅ KI liest die Seite bei jedem Lauf neu |
| Erforderliches technisches Wissen | Python/cURL, CSS-Selektoren, HTML-Verständnis | Keines — Chrome-Erweiterung mit 2-Klick-Workflow |
| Wartung über Zeit | Laufend (1–2 % wöchentliche Bruchrate) | Minimal (KI passt sich automatisch an) |
ScrapingBee hat KI-Extraktionsfunktionen (ai_query, ai_extract_rules) ergänzt, die das Selektor-Wartungsproblem teilweise entschärfen. Diese kosten jedoch zusätzlich +5 Credits pro Anfrage, und das Tool bleibt im Kern API-first ohne visuelle Oberfläche.
ScrapingBee für Nicht-Entwickler: ein ehrlicher Usability-Check
ScrapingBee ist nicht für Nicht-Techniker gebaut. Es ist eine API. Du schreibst Code, um sie zu nutzen. Wenn du Marketing-Manager oder Sales-Operations-Leiter bist, ist das schon die halbe Antwort.
So sieht die Praxis für nicht-technische Nutzer mit ScrapingBee aus:
- API-Aufruf schreiben in Python, cURL oder einer anderen Sprache
- HTTP-Parameter verstehen wie
render_js=true,premium_proxy=true,country_code=us - Rohes HTML parsen mit einer Bibliothek wie BeautifulSoup
- CSS-Selektoren schreiben, um bestimmte Datenfelder zu extrahieren
- Pagination handhaben durch eigene Crawl-Logik (ScrapingBee unterstützt nur Einzelseitenanfragen)
- Datenpipeline aufbauen, um extrahierte Daten zu bereinigen, zu strukturieren und zu speichern
Es gibt keinen Drag-and-Drop-Builder. Kein Point-and-Click-Interface. Keine visuelle Vorschau dessen, was du scrapen wirst.
„Es gibt eine Lernkurve. Und die Dokumentation ist umfangreich, man braucht von einem Tag bis zu einer Woche, um sich durchzuarbeiten.“ — Arvind K, Inhaber, Financial Services,
„Ihr System ist sehr speziell, und es dauert eine Weile, bis man ihre Codes und ihre Struktur versteht.“ —
Entwickler mögen das. Ein Rezensent nannte es „vollständig API-basiert: sehr modern und elegant: Es funktioniert einfach“. Aber „einfach zu bedienen“ bedeutet für einen Entwickler, der APIs bewertet, etwas anderes als für jemanden, der ohne Code eine Lead-Liste aufbauen möchte.
Wann eine No-Code-Alternative sinnvoller ist
Die bietet ein grundlegend anderes Erlebnis:
- Webseite in Chrome öffnen mit installierter Extension
- Auf „AI Suggest Fields“ klicken — die KI scannt die Seite und schlägt Spalten vor (Product Name, Price, Rating, URL usw.) mit passenden Datentypen
- Prüfen und anpassen — Spalten hinzufügen, entfernen oder umbenennen; Field AI Prompts für Transformationen hinzufügen
- Auf „Scrape“ klicken — die Daten werden in strukturierte Zeilen extrahiert
- Exportieren — mit einem Klick nach Google Sheets, Airtable, Notion, Excel, CSV oder JSON (alle Exporte sind kostenlos)
Keine API-Aufrufe, keine Selektoren, kein Code. Thunderbit unterstützt Stand April 2026 .
Für gängige Websites bietet Thunderbit außerdem — vorgefertigte, gepflegte Vorlagen für Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo und mehr. Du musst nicht einmal warten, bis die KI Felder vorschlägt; das Template ist direkt einsatzbereit.
Zusätzlich enthält Thunderbit mehrere , für die kein Tarif nötig ist: E-Mail-Extraktor, Telefonnummern-Extraktor und Bild-Extraktor — praktisch für Sales- und Marketing-Teams, die einfach schnell Daten ziehen müssen.
Entscheidungsrahmen: Wer sollte was nutzen?
| Wenn Sie… | Am besten geeignet |
|---|---|
| Entwickler sind, der mit APIs und HTML-Parsing vertraut ist | ScrapingBee oder ScraperAPI |
| ein technischer Nutzer sind, der strukturierte Daten ohne Selektorarbeit will | Thunderbit API (Extract-Endpunkt) |
| ein Business-User (Sales, Marketing, E-Commerce-Operations) ohne Programmierkenntnisse sind | Thunderbit Chrome Extension |
| ein Team mit geplanten Monitoring-Jobs ohne DevOps brauchen | Thunderbit Scheduled Scraper (Planung in natürlicher Sprache) |
| LLM-/RAG-Pipelines bauen und sauberes Markdown benötigen | Thunderbit Distill API oder Firecrawl |
| auf Budget-Sicherheit achten und keine Credit-Multiplikatoren wollen | Thunderbit (1 Credit = 1 Zeile) |
Nach dem Scrape: Wohin gehen die Daten eigentlich?
Scraping ist nur die halbe Arbeit. Die andere Hälfte — die Daten irgendwo sinnvoll nutzbar abzulegen — ist der Teil, zu dem die meisten ScrapingBee-Reviews schweigen.
ScrapingBee: Rohes HTML raus, Pipeline selbst bauen
ScrapingBee liefert standardmäßig rohes HTML zurück. Danach musst du:
- das HTML mit BeautifulSoup oder lxml parsen
- Navigation, Footer, Skripte und Styles entfernen, die ausmachen
- konkrete Datenfelder extrahieren
- in strukturierte Formate umwandeln
- Pagination und Fehlersituationen behandeln
- Daten speichern und verteilen
„ScrapingBee liefert rohes HTML. KI-Agenten brauchen sauberes Markdown, semantische Suche und Webhooks.“ —
ScrapingBee bietet zwar return_page_markdown=true und return_page_text=true als optionale Alternativen, und die Google Search API liefert strukturiertes JSON. Aber der Standard-Workflow — und die allgemeine Scraping-Erfahrung — basiert auf rohem HTML, das du selbst weiterverarbeiten musst.
Nutzer brauchen dafür meist zusätzliche Tools: BeautifulSoup/lxml zum Parsen, Pandas zur Datenbereinigung, Cron/Airflow für Zeitpläne, eigene Crawl-Logik für mehrseitiges Scraping und . Das ist eine Menge Engineering zwischen „ich habe es gescraped“ und „ich kann es nutzen“.
Thunderbit: Strukturierte Ausgabe mit eingebautem Export
Thunderbit liefert strukturierte Zeilen mit definierten Datentypen (Text, Zahl, Datum, URL, E-Mail, Telefon, Bild), die direkt exportiert werden können. Alle Exporte sind in allen Tarifen kostenlos:
| Exportziel | Kosten |
|---|---|
| Excel (.xlsx) | Kostenlos |
| Google Sheets | Kostenlos (direkte Integration) |
| Airtable | Kostenlos (direkte Integration) |
| Notion | Kostenlos (direkte Integration) |
| CSV | Kostenlos |
| JSON | Kostenlos |
Für Teams, die Google Sheets oder Airtable bereits als CRM oder Operations-Hub nutzen, entfällt damit eine komplette Engineering-Schicht. Beim Export nach Notion oder Airtable werden Bilder in die Bildbibliothek hochgeladen, sodass sie direkt inline sichtbar sind — eine Kleinigkeit, die in der Praxis viel ausmacht.
Das Integrations-Ökosystem von ScrapingBee
ScrapingBee bietet durchaus Integrationen von Drittanbietern: (über 8.000 App-Verknüpfungen), (über 3.000 Apps), n8n und Microsoft Power Automate. Diese können die Lücke zwischen rohem HTML und deinen Zielsystemen schließen — bringen aber zusätzliche Kosten, Komplexität und eine weitere Fehlerquelle mit sich.
Für Entwickler: Thunderbits Open API
Für Leser, die programmatische Pipelines möchten, bietet Thunderbit eine Open API mit zwei wichtigen Endpunkten:
- Distill-Endpunkt — wandelt Seiten in sauberes Markdown um, ideal für LLM-/RAG-Pipelines (1 Credit pro Aufruf)
- Extract-Endpunkt — liefert strukturiertes JSON gemäß einem benutzerdefinierten Schema (20 Credits pro Aufruf)
- Batch-Verarbeitung — bis zu 100 URLs pro Anfrage
Damit bedient Thunderbit sowohl No-Code-Nutzer (Chrome Extension) als auch Entwickler (Open API) auf derselben KI-Basis. Frag also nicht nur „kann es scrapen“ — frag auch „wohin gehen die Daten?“
Zuverlässigkeitscheck 2026: Hält ScrapingBee in der Produktion stand?
Ältere Reddit-Threads (2021–2023) enthalten Beschwerden über die Zuverlässigkeit von ScrapingBee. Spiegeln sie 2026 noch die Realität wider? Ich habe Daten aus sechs unabhängigen Benchmarks ausgewertet. Das Ergebnis ist gemischt — und manchmal widersprüchlich.
Scrapeway-Benchmark im Zwei-Wochen-Takt (April 2026)
Insgesamt: — Platz 7 von 9 getesteten Diensten.
| Website | Erfolgsrate |
|---|---|
| Amazon | 48 % |
| 41 % | |
| Indeed | 38 % |
| Etsy | 21 % |
| Booking | 17 % |
| Realtor | 0 % |
| StockX | 0 % |
| Twitter/X | 0 % |
| Zillow | 0 % |
| Walmart | 0 % |
| 0 % |
Direkter Vergleich von Scrapingdog (2025)
| Website | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100 % | 100 % | 100 % |
| Glassdoor | 0 % | 100 % | 100 % |
| eBay | 100 % | 100 % | 100 % |
| Walmart | 40 % | 100 % | 100 % |
| 90 % | 100 % | 80 % |
Proxyway-Benchmark (Dezember 2025)
- 72,98 % Erfolgsrate bei 10 Anfragen/Sekunde — ein Rückgang um 12 Punkte unter Last
- 25,46 s durchschnittliche Antwortzeit — die langsamste im Benchmark-Feld
Scrape.do-Benchmark (2025–2026)
- Stark bei einzelnen Websites: Amazon 99,11 %, Indeed 99,29 %, GitHub 100 %, X/Twitter 99,6 %
- Schwach bei Capterra: nur 59 % Erfolg mit 36-Sekunden-Antwortzeiten
Das Muster
Die Daten zeigen ein klares Muster:
- ScrapingBee funktioniert gut auf gängigen, moderat geschützten Seiten — Amazon, eBay, GitHub und Indeed zeigen durchgehend Erfolgsraten von 90–100 %
- ScrapingBee scheitert vollständig an stark geschützten Seiten — durchgehend 0 % bei LinkedIn, Zillow, Realtor.com, StockX und Twitter in mehreren Benchmarks
- Die Leistung sinkt unter Last deutlich — 84 % bei 2 req/s fallen auf 73 % bei 10 req/s
- Benchmark-Ergebnisse schwanken stark je nach Methodik — von 33,3 % (Scrapeway, breite Seitenmischung) bis 92,69 % (Scrape.do, moderat geschützte Ziele)
Die (137 Bewertungen) ist ein positives Signal, aber hohe Bewertungen für die einfache Ersteinrichtung spiegeln nicht immer die langfristige Produktionszuverlässigkeit im großen Maßstab wider. Nutzer, die abwandern, nennen oft steigende Ausfallraten und höhere Kosten — nicht Schwierigkeiten beim Start.
„Sehr positiv. ScrapingBee war stabil, vorhersehbar und leicht in die Produktion zu integrieren.“ — Verifizierter Rezensent, CEO,
ScrapingBee zeigte eine „inkonsistente Zuverlässigkeit“, insbesondere eine „0-%-Erfolgsrate auf Glassdoor“ und „“.
Wie KI-gestütztes Scraping Zuverlässigkeit anders handhabt
Thunderbits KI liest die gerenderte Seite in Echtzeit und passt sich pro Sitzung an Anti-Bot-Maßnahmen und Layoutänderungen an. Zwei Scraping-Modi decken unterschiedliche Zuverlässigkeitsanforderungen ab:
- Cloud Scraping — läuft auf Thunderbits Cloud-Servern, verarbeitet bis zu 50 Seiten gleichzeitig, ideal für große öffentliche Scraping-Jobs auf Seiten wie Amazon, Zillow und Shopify
- Browser Scraping — läuft lokal im Chrome-Browser des Nutzers und nutzt die eigene angemeldete Sitzung — ideal für Login-geschützte Seiten (LinkedIn, private Dashboards, SaaS-Plattformen), auf die API-basierte Tools wie ScrapingBee hinter Authentifizierung nicht zugreifen können
Thunderbit bietet außerdem für beliebte Websites, die vorkonfiguriert und gepflegt werden, sodass sie auch dann weiter funktionieren, wenn sich die Struktur der Seiten ändert. Für die Seiten, bei denen ScrapingBee 0 % Erfolg zeigt (LinkedIn, Zillow), ist Thunderbits Browser-Scraping-Modus — mit deiner eigenen eingeloggten Sitzung — ein grundlegend anderer Ansatz.
ScrapingBee vs. Top-Alternativen: Direktvergleich
| Aspekt | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| Typ | Nur API | Chrome-Erweiterung + API | Nur API | Nur API |
| Einstiegspreis | 49 $/Monat | Kostenlos (0 $) | 49 $/Monat | 30 $/Monat |
| Credit-Modell | Multiplikatoren (1×–75×) | 1 Credit = 1 Zeile (keine Multiplikatoren) | Multiplikatoren (1×–75×) | Multiplikatoren (1×–30×) |
| KI-Extraktion | Ja (+5 Credits/Anfrage) | Integriert (AI Suggest Fields) | Keine native KI | Ja |
| No-Code-Option | Nein (nur API) | Ja (Chrome-Erweiterung) | Nein (nur API) | Nein (nur API) |
| Strukturierte Ausgabe | Erfordert CSS-Regeln oder KI-Add-on | Standard (typisierte Spalten) | Strukturierte Endpunkte für bestimmte Websites | Variiert |
| Exportziele | Rohes HTML/JSON (selbst bauen) | Excel, Sheets, Airtable, Notion, CSV, JSON (alles kostenlos) | Rohes HTML/JSON | Rohes HTML/JSON |
| Subpage-Scraping | Manuell (eigene Crawl-Logik schreiben) | Integriert (2 Credits/Zeile) | Manuell | Manuell |
| Geplantes Scraping | Nur CLI (kein Dashboard-Scheduler) | Integriert (natürliche Sprache) | Nicht integriert | Nicht integriert |
| Kostenloser Tarif | 1.000-Credit-Testzugang | 6 Seiten/Monat (für immer) | 5.000 Credits (7-Tage-Test) | 1.000 Credits |
| Standardmäßiges JS-Rendering | EIN (5× Kosten) | Enthalten (keine Zusatzkosten) | AUS | AUS |
| Lernkurve | Hoch (API + Selektoren) | Niedrig (2-Klick-Workflow) | Hoch (API + Selektoren) | Hoch (API) |
| Am besten für | Entwickler mit Wunsch nach Proxy-Kontrolle | Business-User + Entwickler | Entwickler + strukturierte Endpunkte | Entwickler, die ASP umgehen wollen |
| Capterra-Bewertung | 4,9/5 (137 Bewertungen) | — | 4,6/5 (62 Bewertungen) | 4,9/5 (221 Bewertungen) |
ScrapingBee vs. Thunderbit: Die wichtigsten Unterschiede
Die größten Unterschiede liegen in Architektur und Zielgruppe:
- Nur API vs. Chrome-Erweiterung + API: ScrapingBee erfordert für jede Interaktion Code. Thunderbit bietet eine für No-Code-Nutzer und eine Open API für Entwickler — dieselbe KI, zwei Oberflächen.
- Selektorbasiert vs. KI-gestützte Extraktion: Bei ScrapingBee musst du CSS-/XPath-Selektoren schreiben und pflegen. Thunderbits KI schlägt Felder automatisch vor und passt sich an, wenn sich Websites ändern.
- Rohes HTML vs. strukturierte Zeilen mit kostenlosem Export: ScrapingBee liefert HTML, das du selbst parsen musst. Thunderbit liefert typisierte, beschriftete Zeilen, die du mit einem Klick nach kannst.
- Subpage-Scraping: Thunderbits KI besucht jede Detailseite und ergänzt die Haupttabelle — eingebaut, ohne eigene Crawl-Logik. ScrapingBee verlangt, dass du diese Logik selbst schreibst.
- Sofort einsatzbereite Templates: Thunderbit bietet vorgefertigte Templates für beliebte Websites (Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay), die sofort funktionieren. ScrapingBee hat spezielle APIs für Amazon und Walmart, aber du musst sie dennoch per Code nutzen.
Weitere erwähnenswerte Alternativen
- — niedrigste unabhängige Kosten mit 0,80 $ pro 1K Anfragen und 98,19 % Erfolgsrate; Start ab 29 $/Monat
- Apify — Actor-basierte Plattform mit über 415 G2-Bewertungen (4,7/5), wobei „Pricing Issues“ die häufigste Beschwerde ist
- — KI-/LLM-nativ, liefert Markdown mit 67 % weniger Tokens als rohes HTML; Open-Source-Kern; Start ab 16 $/Monat
- — Enterprise-tauglich mit über 72 Mio. IPs, Start ab 499 $/Monat; Flat-Rate-Preismodell
- ZenRows — 55 Mio. Residential IPs, vorgefertigte Scraper für Amazon/Walmart/Zillow, Start ab 69 $/Monat
Welches Scraping-Tool passt zu deinem Team?
Empfehlungen nach Szenario:
- Wenn du Entwickler bist und eine eigene Scraping-Pipeline mit granularer Proxy-Kontrolle baust → ScrapingBee oder ScraperAPI. Du bekommst fein steuerbare HTTP-Parameter, Proxy-Typ-Auswahl und volle Kontrolle über das Rendering. Kalkuliere aber die Credit-Multiplikatoren ein.
- Wenn du ein Sales- oder Marketing-Team bist und Leads von Websites ohne Programmieren brauchst → . Zwei Klicks zu strukturierten Daten, ein Klick zu Google Sheets. Keine API, keine Selektoren, kein Parsing.
- Wenn du schnell strukturierte Daten aus beliebten Websites brauchst → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn — vorgefertigt und gepflegt, kein KI-Setup nötig.
- Wenn du Preise oder Bestände nach Zeitplan überwachen willst, ohne DevOps → Thunderbit Scheduled Scraper. Beschreibe das Intervall in normaler Sprache („jeden Montag um 9 Uhr“) und lass es laufen.
- Wenn du LLM-/RAG-Pipelines baust und sauberes Markdown im großen Maßstab brauchst → Thunderbit Distill API oder Firecrawl. Beide liefern Markdown, das für KI-Verarbeitung optimiert ist.
- Wenn Budgetplanbarkeit wichtig ist und du keine Credit-Multiplikatoren willst → Thunderbit. 1 Credit = 1 Zeile, unabhängig von JS-Rendering oder Proxy-Typ.
Die Total Cost of Ownership besteht nicht nur aus dem API-Preis. Dazu kommen Einrichtungszeit, Wartungsaufwand, Parsing-Engineering und der Export-Workflow. Der Listenpreis von ScrapingBee ist konkurrenzfähig; das Gesamtbild der Kosten ist es nicht.
Wichtige Erkenntnisse aus diesem ScrapingBee-Test
Fünf Punkte, die du dir merken solltest:
- Credit-Kosten steigen bei großem Volumen schnell an. Der Einstiegspreis von 49 $ kann auf 599 $+ steigen, wenn JS-Rendering und Premium-Proxys nötig sind. Thunderbits flaches Modell mit 1 Credit pro Zeile eliminiert diese Unsicherheit.
- CSS-Selektoren bringen laufenden Wartungsaufwand mit sich, den KI-Extraktion vermeidet. Erwarten Sie mit KI-gestützten Tools und keine Selektorbrüche bei Website-Updates.
- Nicht-Entwickler haben mit ScrapingBee eine steile Lernkurve. Das Tool ist API-only und erfordert Code, HTML-Analyse und Selektoren. Business-User sollten No-Code-Alternativen prüfen.
- Datenexport erfordert eigene Engineering-Arbeit. ScrapingBee liefert rohes HTML; die Pipeline baust du selbst. Thunderbit exportiert strukturierte Daten kostenlos nach .
- Die Zuverlässigkeit ist auf manchen Websites gut, auf anderen inkonsistent. ScrapingBee funktioniert gut bei Amazon und eBay, zeigt aber 0 % bei LinkedIn, Zillow und mehreren anderen stark geschützten Zielen.
ScrapingBee bleibt ein leistungsfähiges Tool für Entwickler, die proxy-verwalteten HTTP-Zugriff mit feingranularer Kontrolle wollen. Doch der Web-Scraping-Markt hat sich 2026 in Richtung KI-gestützter No-Code-Tools verschoben — und ist genau für diesen Wandel gebaut. Probier den kostenlosen Tarif aus (6 Seiten gratis oder mehr über den Testzugang), um den Unterschied selbst zu sehen.
FAQs
Lohnt sich ScrapingBee im Jahr 2026?
Das hängt von deinen technischen Fähigkeiten und vom Umfang ab. Für Entwickler, die statische Seiten in moderatem Volumen scrapen, bietet ScrapingBee eine solide, gut dokumentierte API mit reaktionsschnellem Support und einer . Für Business-User, hohe Volumina oder Teams, die strukturierte Daten ohne Programmierung wollen, bieten KI-gestützte Alternativen wie Thunderbit einen besseren Gegenwert und deutlich niedrigere Total Cost of Ownership.
Funktioniert ScrapingBee ohne Programmierung?
Nein. ScrapingBee ist ein reines API-Tool, das Code (Python, cURL oder Ähnliches) und das Verständnis von HTTP-Parametern erfordert. Es gibt keine visuelle Oberfläche zum Erstellen von Scrapes. Nicht-technische Nutzer sollten No-Code-Optionen wie die in Betracht ziehen, mit der du Daten scrapen und exportieren kannst, ohne eine einzige Codezeile zu schreiben.
Was kostet ScrapingBee wirklich pro Seite?
Das hängt von den aktivierten Funktionen ab. Eine statische HTML-Seite kostet 1 Credit. Eine JS-gerenderte Seite (Standard) kostet . Eine Seite mit Premium-Proxy + JS kostet 25 Credits. Eine Seite mit Stealth-Proxy kostet 75 Credits. KI-Extraktion kommt mit weiteren +5 Credits hinzu. Im Freelance-Tarif (49 $/250K Credits) entspricht das 0,20 $ pro 1.000 statische Seiten oder 14,70 $ pro 1.000 Stealth-Proxy-Seiten. Die detaillierten Kostentabellen oben zeigen die vollständige Aufschlüsselung.
Was sind die besten ScrapingBee-Alternativen im Jahr 2026?
Zu den besten Alternativen gehören (KI-gestützt, No-Code-Chrome-Erweiterung + API, 1 Credit = 1 Zeile), (Entwickler-API mit strukturierten Endpunkten für bestimmte Websites), (Entwickler-API mit starkem Anti-Bot-Bypass), (niedrigste Kosten pro Anfrage in unabhängigen Tests) und (KI-/LLM-nativ, liefert sauberes Markdown). Jede Lösung hat ihren Sweet Spot — Thunderbit für Business-User und planbare Kosten, ScraperAPI und Scrapfly für Entwickler mit Proxy-Kontrolle, Firecrawl für LLM-Pipelines.
Kann ScrapingBee JavaScript-lastige Websites scrapen?
Ja, aber das kostet mit rotierendem Proxy das 5-Fache der Basis-Credits oder mit Premium-Proxy das 25-Fache. JavaScript-Rendering ist , du zahlst also bereits den 5-fachen Satz, sofern du es nicht ausdrücklich deaktivierst. Thunderbit übernimmt JavaScript-Rendering automatisch ohne Credit-Multiplikatoren — 1 Credit pro Zeile, unabhängig davon, wie die Seite aufgebaut ist.
Mehr erfahren