Du meldest dich bei ScraperAPI an, siehst im Hobby-Plan „100.000 Credits“ und legst los. Drei Tage später zeigt dein Dashboard: 80 % davon sind weg – und du hast vielleicht 6.000 Seiten gescraped. Was ist da passiert? Die Antwort ist das Credit-Multiplikator-System, und genau das ist der entscheidendste Punkt bei ScraperAPI, den fast kein Review wirklich sauber erklärt. Ich habe wochenlang die Dokumentation von ScraperAPI durchforstet, echte Preisdaten von fünf konkurrierenden Anbietern verglichen und jeden Reddit-Thread sowie jede Capterra-Bewertung gelesen, die ich finden konnte. Dieser ScraperAPI-Testbericht ist genau der Beitrag, den ich mir gewünscht hätte, als unser Team zum ersten Mal Scraping-APIs evaluiert hat. Ich zeige dir die echte Rechnung hinter den Credits, wo ScraperAPI stark ist — und wo es komplett versagt —, fasse zusammen, was echte Nutzer auf G2, Capterra und Reddit berichten, und helfe dir ehrlich dabei herauszufinden, ob du überhaupt eine Scraping-API brauchst.
Was ist ScraperAPI und für wen ist es gedacht?
ScraperAPI ist eine Web-Scraping-API, die die komplette technische Infrastruktur hinter groß angelegtem Scraping übernimmt: Proxy-Rotation über , automatisches Lösen von CAPTCHAs, JavaScript-Rendering und automatische Retries. Du schickst einfach per API-Aufruf eine URL los und bekommst HTML zurück — oder, wenn du die Structured-Data-Endpunkte nutzt, geparstes JSON. Das Unternehmen wurde 2018 von Daniel Ni gegründet, hat seinen Hauptsitz in Las Vegas und bedient inzwischen darunter Deloitte, Sony und Alibaba — mit .
Die Hauptzielgruppe sind Entwicklerteams und technische Ops-Teams, die eigene Scraping-Pipelines aufbauen. Wenn du nicht programmierst, ist ScraperAPI nicht für dich gemacht (dazu später mehr).
Kernfunktionen: Proxy-Rotation, JavaScript-Rendering, Geotargeting, Structured-Data-Endpunkte für beliebte Websites und automatische Wiederholungen bei fehlgeschlagenen Anfragen.
Aber der Punkt, den die meisten Reviews unter den Tisch fallen lassen: Die beworbenen Credit-Zahlen auf der Preisseite von ScraperAPI sind ziemlich irreführend, wenn man die Multiplikatoren nicht versteht. Genau damit fangen wir an.
So funktioniert das Credit-System von ScraperAPI wirklich (der Teil, den die meisten Reviews überspringen)
ScraperAPI rechnet über Credits ab. Die Grundidee klingt simpel: 1 API-Anfrage = 1 Credit. In der Praxis stimmt das fast nie. Die tatsächlichen Kosten hängen von zwei Dingen ab: der Domain, die du scrapen willst, und den aktivierten Feature-Flags. Und diese Kosten addieren sich auf eine Weise, die alles andere als intuitiv ist.
Die Credit-Multiplikator-Tabelle, die jeder vor der Anmeldung sehen sollte

Schon bevor du auch nur einen einzigen Parameter aktivierst, bestimmt der Website-Typ deinen Basisverbrauch an Credits:
| Domain-Kategorie | Basis-Credits pro Anfrage | Beispiele |
|---|---|---|
| Normale Websites | 1 | Blogs, Nachrichtenseiten, einfaches HTML |
| E-Commerce | 5 | Amazon, eBay, Walmart |
| SERP (Suchmaschinen) | 25 | Google, Bing |
| Social Media | 30 |
Zusätzlich kommen für bestimmte Features weitere Credits oben drauf:
| Parameter | Zusätzliche Credits | Hinweise |
|---|---|---|
render=true (JS-Rendering) | +10 | Alle Pläne |
screenshot=true | +10 | Alle Pläne |
premium=true (Premium-Proxy) | +10 | Alle Pläne |
ultra_premium=true | +30 | Nur kostenpflichtige Pläne |
| Anti-Bot-Bypass (Cloudflare, DataDome, PerimeterX) | +10 je nach Erkennung | Wird automatisch erkannt — das wählst du nicht selbst |
premium=true + render=true kombiniert | +25 | NICHT +20 |
ultra_premium=true + render=true kombiniert | +75 | NICHT +40 |
Genau die letzte Zeile ist der Knackpunkt. Das Kombinieren von Funktionen kostet mehr als die bloße Summe der Einzelkosten. Premium-Proxy (+10) plus JavaScript-Rendering (+10) müsste logisch +20 zusätzliche Credits kosten, doch ScraperAPI berechnet . Ultra-Premium (+30) plus JavaScript-Rendering (+10) müsste +40 kosten, tatsächlich sind es aber — also fast doppelt so viel. Diese nichtlineare Staffelung ist in der Doku nicht besonders prominent erklärt und ist der Hauptgrund, warum Nutzer berichten, dass Credits schneller verschwinden als erwartet.
Parameter, die keine zusätzlichen Credits kosten: wait_for_selector, country_code, session_number, device_type, output_format, keep_headers=true, autoparse=true.
Was du in jedem Plan tatsächlich bekommst: Von Free bis Enterprise
Hier sind ScraperAPIs :
| Plan | Monatspreis | Jahrespreis (pro Monat) | API-Credits | Gleichzeitige Threads | Geotargeting |
|---|---|---|---|---|---|
| Free | $0 | — | 1.000 | 5 | Nein |
| Hobby | $49 | $44 | 100.000 | 20 | Nur USA & EU |
| Startup | $149 | $134 | 1.000.000 | 50 | Nur USA & EU |
| Business | $299 | $269 | 3.000.000 | 100 | Länder-Level (50+ Länder) |
| Scaling | $475 | $427 | 5.000.000 | 200 | Länder-Level |
| Enterprise | Individuell | Individuell | 5.000.000+ | 200+ | Länder-Level |
Und hier die effektiven Kosten pro 1.000 Anfragen auf jeder Stufe, inklusive Multiplikatoren:
| Plan | Standard (1×) | JS-Rendering (10×) | E-Commerce (5×) | SERP (25×) | Ultra-Premium + JS (75×) |
|---|---|---|---|---|---|
| Hobby ($49) | $0.49 | $4.90 | $2.45 | $12.25 | $36.75 |
| Startup ($149) | $0.15 | $1.49 | $0.75 | $3.73 | $11.18 |
| Business ($299) | $0.10 | $1.00 | $0.50 | $2.49 | $7.48 |
| Scaling ($475) | $0.10 | $0.95 | $0.48 | $2.38 | $7.13 |
Ein 49-Dollar-Plan, der mit „100.000 Credits“ beworben wird, liefert beim Scraping geschützter Websites mit Ultra-Premium plus JavaScript-Rendering nur 1.333 tatsächliche Anfragen. Das entspricht etwa — teurer als viele vollständig verwaltete Scraping-Dienste.
Warum Credits schneller verschwinden, als du erwartest
Drei Dinge überraschen Nutzer immer wieder.
Erstens: Domain-basierte Preise werden automatisch angewendet. Du entscheidest nicht selbst, ob Amazon mit dem 5×-Multiplikator oder Google mit dem 25×-Multiplikator abgerechnet wird. Sobald ScraperAPI die Domain erkennt, wird er angewendet. Gleiches gilt für Anti-Bot-Bypass-Credits (+10 für Cloudflare, DataDome, PerimeterX) — auch die kommen automatisch dazu, wenn sie erkannt werden.
Zweitens: Credits werden NICHT übertragen. Nicht verbrauchte Credits . Kein Ansparen.
Und drittens — besonders schmerzhaft — Pay-as-you-go gibt es erst ab dem Scaling-Plan ($475/Monat). Wenn du im Hobby-, Startup- oder Business-Plan deine Credits vor Monatsende verbrauchst, wirst du einfach bis zur nächsten Abrechnungsperiode ausgesperrt. Deine einzige Option ist ein Upgrade auf die nächsthöhere Stufe.
Ein Reddit-Nutzer berichtete, dass ihm 3.600 Dollar für 60 Millionen Credits bei 1 Credit pro Amazon-Anfrage genannt wurden. Nach der Zahlung wurde jedoch ohne klare Vorabinfo ein 5-facher Multiplikator angewendet. Der 60M-Plan entsprach damit effektiv nur 12M Anfragen — also einer gegenüber den Erwartungen.
Die Credit-Falle von DataPipeline
ScraperAPIs No-Code-Funktion DataPipeline (geplantes Scraping mit Webhook-Auslieferung) nutzt einen separaten und deutlich höheren Credit-Tarif. Eine einfache normale Anfrage kostet in DataPipeline über die Standard-API:
| Anfragetyp | Standard-API | DataPipeline | Verhältnis |
|---|---|---|---|
| Einfache normale Anfrage | 1 | 6 | 6× |
| Einfache E-Commerce-Anfrage | 5 | 10 | 2× |
| Einfache SERP-Anfrage | 25 | 30 | 1,2× |
| Ultra-Premium + JS (normal) | 75 | 80 | 1,07× |
Nutzer, die No-Code-Pipelines aufsetzen und mit Standard-Credits rechnen, merken schnell, dass selbst einfache Anfragen 6× so viele Credits verbrauchen. Das steht in der Doku — man muss es aber erst mal finden.
Echte Kosten pro Anfrage: ScraperAPI im Vergleich zur Konkurrenz
Die Listenpreise sind ohne Multiplikatoren praktisch wertlos. Ich habe aktuelle Preise von fünf Anbietern gesammelt und den Vergleich auf die etwa 300-Dollar-Monatsstufe für drei typische Szenarien standardisiert.
Einfaches HTML-Scraping (kein JS, kein Premium-Proxy)
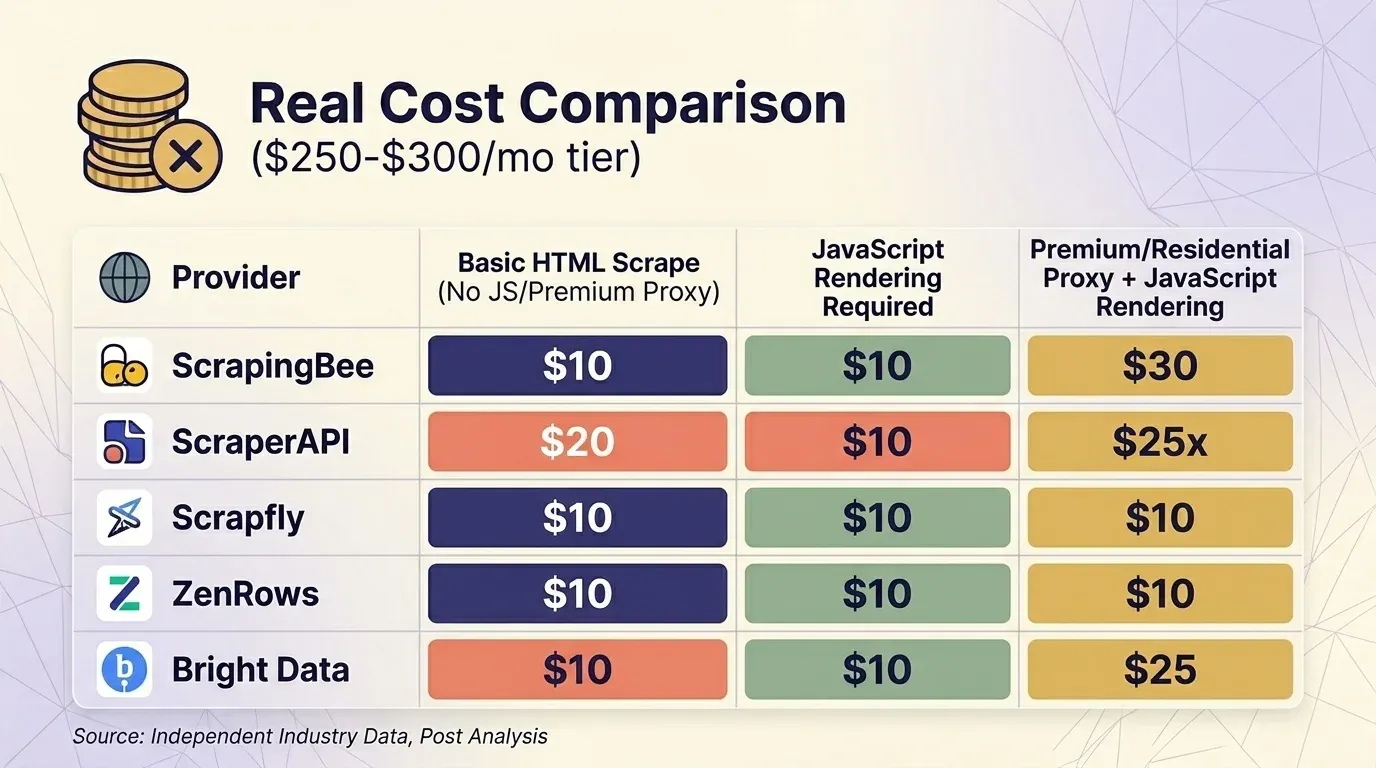
| Anbieter | Plan | Credits pro Anfrage | Tatsächliche Anfragen | Kosten pro 1.000 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 1 | 3.000.000 | $0.08 |
| ScraperAPI | Business $299 | 1 | 3.000.000 | $0.10 |
| Scrapfly | Startup $250 | 1 | 2.500.000 | $0.10 |
| ZenRows | Business $300 | $0.28/1K | ~1.071.000 | $0.28 |
| Bright Data | PAYG | $1.50/1K | ~200.000 | $1.50 |
JavaScript-Rendering erforderlich
| Anbieter | Plan | Credits pro Anfrage | Tatsächliche Anfragen | Kosten pro 1.000 |
|---|---|---|---|---|
| ScrapingBee | Business $249 | 5 (standardmäßig aktiv) | 600.000 | $0.42 |
| Scrapfly | Startup $250 | 6 | 416.667 | $0.60 |
| ScraperAPI | Business $299 | 10 | 300.000 | $1.00 |
| ZenRows | Business $300 | 5× | ~214.000 | $1.40 |
| Bright Data | PAYG | Pauschal | ~200.000 | $1.50 |
Premium-/Residential-Proxy + JavaScript-Rendering (geschützte Websites)
| Anbieter | Plan | Credits pro Anfrage | Tatsächliche Anfragen | Kosten pro 1.000 |
|---|---|---|---|---|
| Bright Data | PAYG | Pauschal | ~200.000 | $1.50 |
| ScrapingBee | Business $249 | 25 | 120.000 | $2.08 |
| ScraperAPI | Business $299 | 25 | 120.000 | $2.49 |
| Scrapfly | Startup $250 | 31 | 80.645 | $3.10 |
| ZenRows | Business $300 | 25× | ~42.857 | $7.00 |
Bright Data Web Unlocker ist der einzige Anbieter, der — alle Anfragen kosten denselben Pauschalpreis. Auf der etwa 300-Dollar-Stufe sind ScrapingBee und ScraperAPI beim Scraping geschützter Seiten konkurrenzfähig, während ZenRows am teuersten ist.
Ein wichtiger Hinweis: ScrapingBee und berechnet dafür 5×. Wenn du ScrapingBee und ScraperAPI direkt vergleichst, achte darauf, dass die Rendering-Einstellungen identisch sind.
Eine unabhängige Analyse von Scrape.do kam zu dem Ergebnis, dass ScraperAPI im Durchschnitt — „mehr als jeder andere getestete Anbieter“ — bei einer durchschnittlichen Antwortzeit von , was ihn zu „einem der langsamsten verfügbaren Anbieter“ macht. Das sollte man wissen, bevor man sich festlegt.
Erfolgsraten nach Website-Typ: Wo ScraperAPI glänzt und wo es schwächelt
Keine Scraping-API funktioniert auf jeder Website gleich gut. Unabhängige Benchmarks von Scrapeway (April 2026) zeichnen ein klar zweigeteiltes Bild.
Performance nach Website-Kategorie
| Zielseite | Erfolgsrate | Durchschn. Geschwindigkeit | Kosten pro 1.000 (Business-Plan) |
|---|---|---|---|
| Zillow | 100 % | 10,5 s | $0.49 |
| Etsy | 99 % | 4,8 s | $4.90 |
| Amazon | 98 % | 6,5 s | $2.45 |
| 95 % | 17,8 s | $14.70 | |
| Walmart | 93 % | 11,4 s | $2.45 |
| Indeed | 90 % | 15,8 s | $4.90 |
| StockX | 84 % | 3,9 s | $4.90 |
| Realtor.com | 12 % | 11,8 s | $0.49 |
| 0 % | — | — | |
| Booking.com | 0 % | — | — |
| Twitter/X | 0 % | — | — |
Gesamtdurchschnittliche Erfolgsrate: , leicht über dem Branchendurchschnitt von 58,2–59,5 %. Durchschnittliche Antwortzeit: 5,2–7,3 Sekunden, besser als der Branchendurchschnitt von 9,8 Sekunden.
Wo ScraperAPI gut performt
ScraperAPI ist wirklich stark bei E-Commerce (Amazon, Walmart, Etsy) und Immobilien (Zillow). Die Structured-Data-Endpunkte für diese Websites liefern geparstes JSON mit hoher Zuverlässigkeit. Wenn dein Hauptanwendungsfall das Scraping von Amazon-Produktseiten oder Google-SERPs ist, ist ScraperAPI eine vernünftige Wahl.
Wo ScraperAPI an seine Grenzen stößt
Social Media ist eine tote Zone. Instagram, Twitter/X und Booking.com erreichen in unabhängigen Tests alle 0 % Erfolgsrate. LinkedIn funktioniert mit 95 %, ist mit 30 Credits pro Anfrage aber teuer.
Login-pflichtige Seiten sind ausdrücklich ausgeschlossen. ScraperAPI unterstützt zwar Sitzungserhalt über den Parameter session_number, aber es . Formulare, Zwei-Faktor-Authentifizierung oder komplexe Auth-Flows kann es nicht verarbeiten.
Veraltete Daten bei geschützten Zielen. Auf schwierigen Targets setzt ScraperAPI einen ein. Das bedeutet: Wenn du zeitkritische Daten wie Preise oder Lagerbestände scrapen willst, können die Ergebnisse bis zu 10 Minuten alt sein.
Im Benchmark von Proxyway 2025 hatte ScraperAPI bei Google die mit 81,72 %.
Zusammenfassung der Performance nach Website-Kategorie
| Website-Kategorie | ScraperAPI-Performance | Bekannte Probleme | Mögliche Alternative |
|---|---|---|---|
| Amazon / E-Commerce | ✅ Stark (SDP-Endpunkte) | Bei Scale kreditintensiv | Thunderbit-Vorlagen (1 Klick, keine Credits pro Zeile für die Vorlage) |
| Google SERPs | ✅ Stark | Geotargeting kostet extra; in einem Benchmark die niedrigste Google-Erfolgsrate | — |
| Immobilien (Zillow) | ✅ Hervorragend (100 %) | — | — |
| Instagram / Social Media | ❌ 0 % Erfolg | Komplettausfall | Playwright + Proxies (DIY) |
| JS-lastige SPAs | ⚠️ Mittelmäßig | Benötigt 10× teures Headless-Rendering | Scrapfly, ZenRows |
| Websites mit Login | ❌ Laut AGB verboten | Keine Session-/Auth-Unterstützung | Thunderbit Browser Scraping (nutzt deine Login-Session) |
| Booking.com / Travel | ❌ 0 % Erfolg | Komplettausfall | Bright Data |
Was echte Nutzer sagen: Stimmungsbild aus G2, Capterra und Reddit
Ich habe Feedback von drei Plattformen ausgewertet. Hier sind die aktuellen Bewertungen:
| Plattform | Bewertung | Bewertungen |
|---|---|---|
| G2 | 4.4/5 | 16 |
| Capterra | 4.6/5 | 62 |
| Trustpilot | 4.5/5 | 43 |
Capterra-Teilbewertungen: Bedienbarkeit 4.9/5, Kundenservice 4.6/5, Funktionen 4.5/5, Preis-Leistungs-Verhältnis 4.5/5.
Stimmungsbild nach Themen
| Thema | Positive Signale | Negative Signale |
|---|---|---|
| Einrichtung / Doku | „Super einfach einzurichten. Man kann in Minuten mit dem Scrapen beginnen.“ — Latenode-Community; Capterra Bedienbarkeit 4.9/5 | — |
| Preistransparenz | „Einstiegsstufe erschwinglich“ (mehrere Capterra-Reviews) | „Die Aufschlüsselung der Credit-Kosten kann verwirrend sein“ — John S., Gründer, Capterra (Feb. 2025); „Preise wurden um 1000 % erhöht und die Qualität verschlechterte sich“ — CTO, Online Media, Capterra (Sep. 2022) |
| Zuverlässigkeit | „Funktioniert super für Amazon/Google“ (G2, Capterra) | „ScraperAPI wird bei großen Jobs wackelig“ — emcarter, Latenode; „80 % Fehlerrate bei manchen Zielen“ (Reddit) |
| Kundensupport | „Reaktionsschnelles Team“ (Capterra) | Ein Nutzer berichtete, dass ihm ein Preis genannt und dann 5× so viel berechnet wurde — ohne Vorabhinweis (Reddit) |
| Langfristiger Nutzen | Es werden nur erfolgreiche Anfragen (200/404) berechnet | „Wenn du im großen Stil arbeitest, summieren sich die Kosten schnell“ und eine eigene Infrastruktur sei „auf lange Sicht kosteneffizienter“ — mikezhang, Latenode |
Fazit: ScraperAPI wird für die einfache Einrichtung geschätzt und funktioniert zuverlässig bei populären, gut unterstützten Zielseiten. Die Kritik dreht sich vor allem um Preisüberraschungen (Multiplikatoren, unerwartete Erhöhungen) und die Zuverlässigkeit bei schwierigeren Targets.
Die Structured-Data-Endpunkte von ScraperAPI: Sind die Premium-Credits das wert?
ScraperAPI bietet über 5 Plattformen hinweg an und liefert geparstes JSON statt rohem HTML:
- Amazon (3 Endpunkte): Produktdetails per ASIN, Suchergebnisse, Konkurrenzangebote. Liefert 18+ Felder, darunter Preis, Bewertungen, Beschreibungen, Rezensionen, BSR, Bilder und Verkäuferdaten. Unterstützt .
- Google (5 Endpunkte): (organische Ergebnisse, Knowledge Graph, Videos, verwandte Fragen, Pagination), Shopping, Maps, News, Jobs.
- Walmart (4 Endpunkte): Produkt, Suche, Kategorie, Bewertungen.
- eBay (2 Endpunkte): Produkt, Suche.
- Redfin (4 Endpunkte): Suche, Agentendetails, Mietobjekte, Kaufobjekte.
SDEs sind in allen Plänen verfügbar, auch im Free-Plan. ScraperAPI bewirbt für unterstützte SDE-Domains eine — unabhängige Benchmarks zeichnen je nach Website jedoch ein differenzierteres Bild.
Datenvollständigkeit
Das Amazon-SDP ist das stärkste Angebot von ScraperAPI. Es liefert einen sehr umfassenden Datensatz: Preis, Bewertungen, BSR, Varianten, Bilder, Verkäuferinfos und mehr. Das Google-SERP-SDP liefert organische Treffer, Anzeigen, Featured Snippets und People Also Ask. Die Datenabdeckung ist für diese beiden Plattformen wirklich gut.
Krediteffizienz: SDP vs. eigenes Parsing
Im Business-Plan ($299/Monat, 3 Mio. Credits) kostet das Scraping von 10.000 Amazon-Produkten über das SDE 50.000 Credits (je 5 Credits) — also ungefähr 5 Dollar des Plans. Ein eigener Parser mit Standardanfragen (je 1 Credit) würde nur 10.000 Credits verbrauchen, dafür müsstest du aber Entwicklerzeit in Aufbau und Wartung investieren.
Für kleine Teams ohne Entwickler sparen SDEs echte Zeit.
Für Teams mit Engineering-Kapazität und Scraping in großem Umfang ist der 5×-Aufpreis schwer zu rechtfertigen.
Wie SDEs im Vergleich zu No-Code-Scraper-Vorlagen abschneiden
Dieser Vergleich ist wichtiger, als viele Reviews zugeben. bietet sofort einsetzbare Scraper-Vorlagen für Amazon, Shopify, Zillow und — ganz ohne Code und ohne zusätzliche Credit-Kosten pro Zeile für die Vorlage selbst.
| Faktor | ScraperAPI SDP (Amazon) | Thunderbit Amazon-Vorlage |
|---|---|---|
| Einrichtungszeit | 30–60 Min. (Code + API-Integration) | ~2 Min. (Extension installieren, Amazon öffnen, Vorlage anklicken) |
| Kosten pro 1.000 Produkte (Business-Plan) | ~5 $ (50.000 Credits bei 0,10 $/Credit) | ~16,50 $ (1.000 Zeilen × 1 Credit bei 0,0165 $/Credit im Pro-Plan) |
| Gelieferte Felder | 18+ (umfangreich) | Produktname, Preis, Bewertung, Rezensionen, Bilder, URL und mehr |
| Exportoptionen | JSON (zum Parsen Code nötig) | Excel, CSV, Google Sheets, Airtable, Notion — 1 Klick |
| Wartung | ScraperAPI pflegt das SDP | Thunderbit-Team pflegt die Vorlagen |
| Technische Kenntnisse | Python/Node.js erforderlich | Keine |
Für Entwicklerteams, die Amazon in hoher Frequenz scrapen, ist ScraperAPIs SDP pro Produkt bei Scale kosteneffizienter. Für Business-Nutzer, die Amazon-Daten ohne Code direkt in einer Tabelle brauchen, ist Thunderbit deutlich schneller einzurichten und zu benutzen.
Brauchst du überhaupt eine Scraping-API? Der No-Code-Weg, den die meisten Reviews ignorieren
Viele Menschen, die nach einem „Scraper API Review“ suchen, haben sich noch gar nicht für einen API-basierten Workflow entschieden. Sie prüfen erst einmal, ob sie überhaupt eine brauchen.
Überraschend viele brauchen keine. Der Markt für Web-Scraping-APIs ist eine mit 14–18 % CAGR, aber dieses Wachstum wird vor allem von Enterprise-Engineering-Teams getragen — nicht von dem Sales-Ops-Manager, der 500 Leads von einer Website braucht.
Scraping-API vs. No-Code-Tool: Ein Entscheidungsschema im Direktvergleich
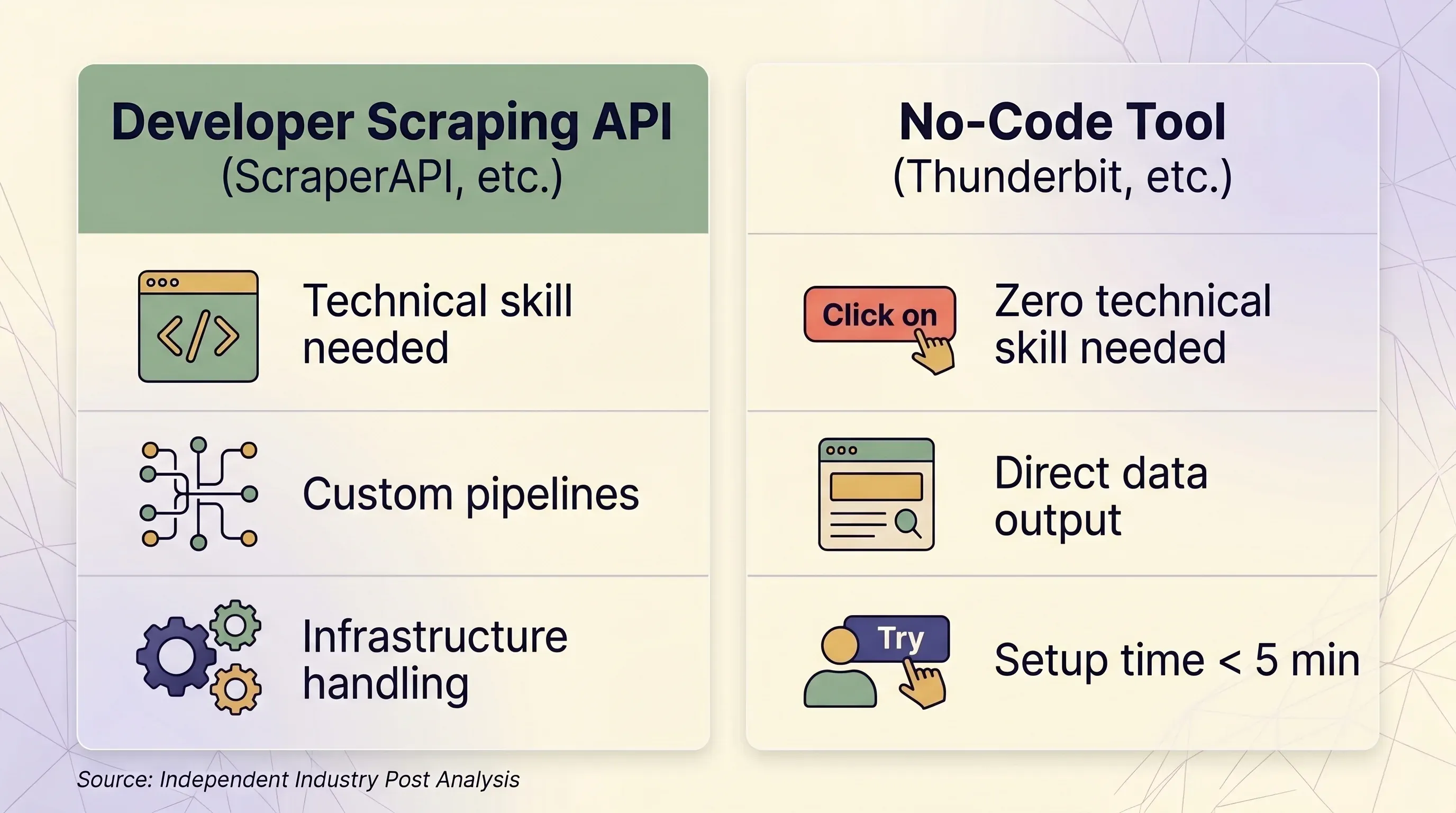
| Faktor | Scraping-API (ScraperAPI usw.) | No-Code-Tool (Thunderbit usw.) | |---|---|---|---| | Am besten geeignet für | Entwickler, die Datenpipelines in großem Maßstab bauen | Business-User, Marketer, Sales-Teams, Researcher | | Technische Kenntnisse | Python/Node.js, HTTP-Grundlagen, JSON-Parsing | Keine — Klick und Ziehen im Browser | | Einrichtungszeit | Mindestens 1–2 Stunden (Code + Test + Debugging) | Unter 5 Minuten | | Anti-Bot-Handling | Premium-Proxies (10–75 Credits/Anfrage) | Echter Browser-Session — umgeht Fingerprinting natürlich | | Websites mit Login | ❌ Laut ScraperAPI-AGB verboten | ✅ Browser Scraping nutzt deine bestehende Session | | Skalierung (Seiten/Tag) | 100.000–3 Mio.+ Anfragen/Monat | Ad hoc, typischerweise unter 1.000 Seiten/Tag | | Datenoutput | Rohes HTML oder JSON (Code zum Parsen nötig) | Strukturierte Zeilen/Spalten — sofort nutzbar | | Export | JSON, CSV (per Code) | Excel, CSV, Google Sheets, Airtable, Notion, Word, JSON | | Wartung | Selektoren, Retry-Logik und Infrastruktur müssen aktualisiert werden | Keine — die KI liest die Seitenstruktur jedes Mal neu ein | | Preiseinheit | Pro-Anfrage-Credits (variabel: 1–75 Credits/Anfrage) | Pro-Zeile-Credits (1 Credit = 1 Zeile, 2 für Unterseiten) | | Einstiegspreis | $49/Monat für 100K Credits | $9/Monat für 5.000 Credits (jährlich) | | Free-Tier | 1.000 Credits/Monat, 5 parallel | 6 Seiten/Monat, 30 Credits/Seite | | Preisvorhersagbarkeit | Niedrig — Multiplikatoren führen zu Überraschungskosten | Hoch — 1 Zeile = immer 1 Credit |
Wann eine Scraping-API Sinn ergibt
- Du hast ein Developer- oder Engineering-Team
- Du musst 100K+ Seiten pro Tag programmatisch scrapen
- Du brauchst tiefe Anpassung von Headern, Sessions und Retry-Logik
- Deine Zielseiten werden gut unterstützt (Amazon, Google, Walmart, Zillow)
Wann ein No-Code-Tool wie Thunderbit mehr Sinn macht
- Du arbeitest im Sales-, E-Commerce-, Marketing- oder Immobilienbereich — nicht im Engineering
- Du brauchst Daten von Dutzenden verschiedenen Websites, ohne für jede eigene Parser zu bauen
- Du willst direkt nach Excel, Google Sheets, Airtable oder Notion exportieren
- Du musst Seiten mit Login scrapen (Thunderbits nutzt deine Session)
- Du willst, dass KI die Seite jedes Mal frisch liest — kein Wartungsaufwand, wenn Layouts sich ändern
- Du brauchst Unterseiten-Scraping: Thunderbit kann jede Detailseite besuchen und Zeilen automatisch anreichern
Der -Workflow ist wirklich simpel: Extension installieren, eine beliebige Seite öffnen, auf „AI Suggest Fields“ klicken, auf „Scrape“ klicken und exportieren. Die KI erkennt automatisch, welche Daten auf der Seite vorhanden sind, und schlägt Spalten vor — du musst keine Selektoren oder Code schreiben. Mehr dazu findest du in unserem .
erlebten 2024 Cloud-Kostenüberschreitungen, und Firmen, die nutzungsbasierte Preise ohne geeignete Schutzmechanismen einsetzen, sehen wegen Preis-Schocks. Die Vorhersagbarkeit eines Credit-Modells pro Zeile ist daher durchaus einen Blick wert, wenn dich variable API-Kosten schon einmal überrascht haben.
ScraperAPI: Vor- und Nachteile auf einen Blick
| Vorteile | Nachteile |
|---|---|
| Starke Proxy-Infrastruktur (40M+ IPs, 50+ Länder) | Verwirrendes Credit-Multiplikator-System — das Kombinieren von Features kostet mehr als die Summe |
| Sehr gute Dokumentation und einfache Ersteinrichtung (Capterra Bedienbarkeit: 4.9/5) | Credits werden nicht von Monat zu Monat übertragen |
| Zuverlässig bei Amazon, Google, Zillow, Etsy | 0 % Erfolg bei Instagram, Twitter/X, Booking.com |
| Berechnet nur erfolgreiche Anfragen (200/404) | 404-Antworten verbrauchen trotzdem Credits |
| 18 Structured-Data-Endpunkte mit geparstem JSON | Websites mit Login sind ausdrücklich verboten |
| In allen Plänen verfügbar, auch im Free-Plan | Pay-as-you-go erst ab Scaling ($475/Monat) |
| 7-Tage-Geld-zurück-Garantie ohne Fragen | 10-Minuten-Zwangscache bei schwierigen Targets — Risiko veralteter Daten |
| 30–35 % Umsatzwachstum pro Jahr spricht für aktive Entwicklung | DataPipeline kostet bis zu 6× so viele Credits wie die Standard-API |
| — | Geotargeting über USA & EU hinaus erfordert den Business-Plan ($299/Monat) |
| — | Keine proaktiven Nutzungswarnungen — Dashboard muss manuell geprüft werden |
Praktische Tipps, um das Maximum aus ScraperAPI herauszuholen (wenn du dich dafür entscheidest)
Verfolge deinen Credit-Verbrauch täglich
Das von ScraperAPI bietet Nutzungsstatistiken wie durchschnittliche Latenz, gescrapte Domains und Parallelitätsmetriken. Allerdings gibt es keine proaktiven Nutzungswarnungen — also keine E-Mail oder SMS, wenn die Credits zur Neige gehen. Du musst selbst nachsehen. Die Historie der Analysen ist im Hobby-/Startup-Plan auf 2 Wochen und im Business+ auf 6 Monate begrenzt.
Setz dir im ersten Monat eine tägliche Erinnerung, um ins Dashboard zu schauen. Du musst erst ein Gefühl dafür bekommen, wie schnell Credits bei deinen konkreten Zielen verbraucht werden.
Starte mit dem Free-Tier, um deine Zielseiten zu testen
Nutze die 1.000 kostenlosen Credits plus die 7-tägige Testphase mit 5.000 Credits, um die Erfolgsraten auf deinen Zielseiten zu testen, bevor du dich für einen kostenpflichtigen Plan entscheidest. Dokumentiere, welche Websites JavaScript-Rendering oder Premium-Proxies benötigen, damit du die realistischen Monatskosten inklusive Multiplikatoren abschätzen kannst.
Deaktiviere Premium-Features, wenn das Ziel sie nicht braucht
ScraperAPI aktiviert Premium-Proxies oder JavaScript-Rendering nicht automatisch — du musst render=true, premium=true oder ultra_premium=true ausdrücklich setzen. Die domainbasierte Preislogik ist jedoch automatisch: Amazon kostet immer 5 Credits, Google immer 25, LinkedIn immer 30. Anti-Bot-Bypass-Credits (+10 für Cloudflare, DataDome, PerimeterX) werden ebenfalls automatisch hinzugefügt, wenn sie erkannt werden. Das solltest du vor einem Batch-Lauf wissen.
Nutze Structured-Data-Endpunkte für unterstützte Websites
Wenn du Amazon oder Google scrapen willst, sparen die SDEs Entwicklungszeit, selbst wenn sie mehr Credits kosten. Für nicht unterstützte Websites solltest du prüfen, ob ein schneller und günstiger ist als ein eigener Parser.
Halte einen Plan B für unzuverlässige Ziele bereit
Wenn die Erfolgsrate von ScraperAPI auf einer bestimmten Website unter 90 % liegt, solltest du diese Anfragen eventuell über einen anderen Anbieter oder ein browserbasiertes Tool routen. Für Websites mit Login funktioniert ScraperAPI schlicht nicht — dafür brauchst du ein Tool wie , das innerhalb deiner Browser-Session arbeitet.
Kenne die Fallstricke
- 404-Antworten verbrauchen Credits — ScraperAPI berechnet sowohl 200- als auch 404-Statuscodes
- Abgebrochene Anfragen werden berechnet, wenn du vor Ablauf des 70-Sekunden-Verarbeitungsfensters abbrichst
- 10-Minuten-Zwangscache bei schwierigen Targets — du kannst veraltete Daten erhalten
- Pay-as-you-go gibt es nur ab Scaling ($475/Monat) — Nutzer niedrigerer Pläne werden bei Verbrauchsende gesperrt
- Geotargeting außerhalb von USA & EU erfordert den Business-Plan ($299/Monat)
Zentrale Erkenntnisse: Ist ScraperAPI das richtige Tool für dich?
Hier ist mein Fazit nach all der Recherche:
- ScraperAPI ist eine solide Wahl für Entwicklerteams, die große Mengen auf gut unterstützten Zielen wie Amazon, Google, Walmart und Zillow scrapen. Die Structured-Data-Endpunkte sind wirklich nützlich, die Proxy-Infrastruktur ist groß, und die Dokumentation ist überdurchschnittlich gut.
- Das Credit-Multiplikator-System ist das größte Risiko. Wer nicht versteht, wie sich Multiplikatoren addieren, wird zu viel ausgeben. Die Lücke zwischen beworbenen Credits und tatsächlichen Anfragen kann 5–75× betragen. Rechne dein konkretes Szenario vor dem Wechsel in einen kostenpflichtigen Plan durch.
- Zuverlässigkeit hängt stark von der Website ab. ScraperAPI ist hervorragend bei E-Commerce und Immobilien, mittelmäßig bei Jobbörsen und Social Media und praktisch nutzlos bei Instagram, Twitter/X und Booking.com. Geh nicht von gleichbleibender Performance aus.
- Für nicht-technische Teams ist ScraperAPI das falsche Werkzeug. Wenn du im Sales, Marketing oder Operations arbeitest und strukturierte Daten ohne Code brauchst, bringt dich ein No-Code-Tool wie mit zwei Klicks ans Ziel — inklusive KI-gestützter Felderkennung, direktem Spreadsheet-Export, Unterseiten-Anreicherung und ohne Wartungsaufwand. Schau dir die an oder sieh dir Tutorials auf dem an.
- Für Entwickler mit kleinem Budget: Teste ScraperAPIs Free-Tier auf deinen konkreten Zielseiten und vergleiche dann die effektiven Kosten pro Anfrage mit ScrapingBee, Scrapfly und Bright Data, bevor du dich entscheidest. Die günstigste Option hängt vollständig von deinem Anwendungsfall und deinen Feature-Anforderungen ab.
Willst du sehen, wie sich die Zahlen für deinen konkreten Scraping-Bedarf verhalten? Starte mit dem Free-Tier von ScraperAPI, um deine Zielseiten zu testen, oder , um zu sehen, wie weit dich zwei Klicks bringen. Mehr zu findest du in unseren Tarifen.
FAQs
Ist ScraperAPI kostenlos?
Ja, ScraperAPI bietet einen Free-Tier mit und eine 7-tägige Testphase mit 5.000 Credits. Allerdings bedeuten Credit-Multiplikatoren für JavaScript-Rendering, Premium-Proxies oder teure Domains (Amazon = 5×, Google = 25×, LinkedIn = 30×), dass deine reale Kapazität weit unter 1.000 Anfragen liegen kann. Im Free-Tier sind Ultra-Premium-Proxies nicht verfügbar.
Wie viel kostet ScraperAPI pro Anfrage?
Das hängt stark von den aktivierten Features und der Ziel-Domain ab. Eine Standardanfrage an eine einfache HTML-Website kostet 1 Credit. Eine Amazon-Anfrage kostet 5 Credits. Eine Google-SERP-Anfrage kostet 25 Credits. JavaScript-Rendering kostet zusätzlich 10 Credits. Die Kombination aus Ultra-Premium-Proxy und JavaScript-Rendering kostet 75 Credits pro Anfrage. Im Hobby-Plan ($49/Monat, 100K Credits) liegt das also irgendwo zwischen $0.00049 pro Anfrage (Standard) und $0.0368 pro Anfrage (Ultra-Premium + JS). Siehe die vollständigen Kostentabellen weiter oben.
Ist ScraperAPI gut zum Scrapen von Amazon?
Der Amazon-Structured-Data-Endpunkt von ScraperAPI gehört zu den stärksten Funktionen des Produkts und erreicht in unabhängigen Benchmarks eine sowie umfassend geparstes JSON (18+ Felder). Allerdings kostet jede Amazon-Anfrage mindestens 5 Credits, sodass die Kosten bei Scale schnell steigen. Für kleinere Teams, die Amazon-Daten ohne Code direkt in einer Tabelle haben wollen, bietet eine 1-Klick-Alternative mit Direkt-Export.
Was sind die besten Alternativen zu ScraperAPI?
Für Entwickler: (am günstigsten für einfaches HTML), (gut für JavaScript-Rendering), (am besten für geschützte Seiten — Pauschalpreis unabhängig vom Rendering) und . Für nicht-technische Nutzer: — eine No-Code-, KI-gestützte Chrome-Extension mit Direkt-Export nach Excel, Google Sheets, Airtable und Notion. Sieh dir unseren für einen tieferen Einblick an.
Kann ScraperAPI Websites mit Login scrapen?
ScraperAPI unterstützt Sitzungserhalt über den Parameter session_number (gleiche IP über mehrere Anfragen hinweg), aber es . Formulareingaben, Zwei-Faktor-Authentifizierung oder komplexe Auth-Flows kann es nicht verarbeiten. Für Login-pflichtige Websites sind browserbasierte Tools wie — das deine bestehende Browser-Session nutzt, um das zu scrapen, was du sehen kannst — die zuverlässigere Option.
Mehr erfahren