Zillow verfügt über mehr als , und genau diese Daten in großem Umfang zu extrahieren gehört zu den gefragtesten — und frustrierendsten — Aufgaben in der Immobilien-Datenanalyse. Wenn du schon einmal versucht hast, zillow mit python scrapen und am Ende auf einer CAPTCHA-Seite statt bei den Inseraten gelandet bist, bist du damit nicht allein.
Ich habe viel Zeit damit verbracht, verschiedene Ansätze für das Scraping von Zillow zu recherchieren und zu testen — sowohl mit Python als auch mit No-Code-Tools, die wir bei Thunderbit entwickelt haben. Dieser Leitfaden deckt beide Wege ab. Egal, ob du das vollständige Python-Tutorial mit Anti-Bot-Strategien suchst oder einfach bis zum Mittag 200 Inserate in einer Tabelle brauchst, hier findest du die passende Lösung. Wir gehen darauf ein, warum Zillow-Daten so wertvoll sind, wie die Website intern aufgebaut ist, führen dich Schritt für Schritt durch ein Python-Tutorial, erklären die genauen Gründe, warum Scraper scheitern, und zeigen, wie du wiederkehrende Scrapes für die Preisüberwachung automatisierst.
Warum überhaupt Zillow-Daten scrapen?
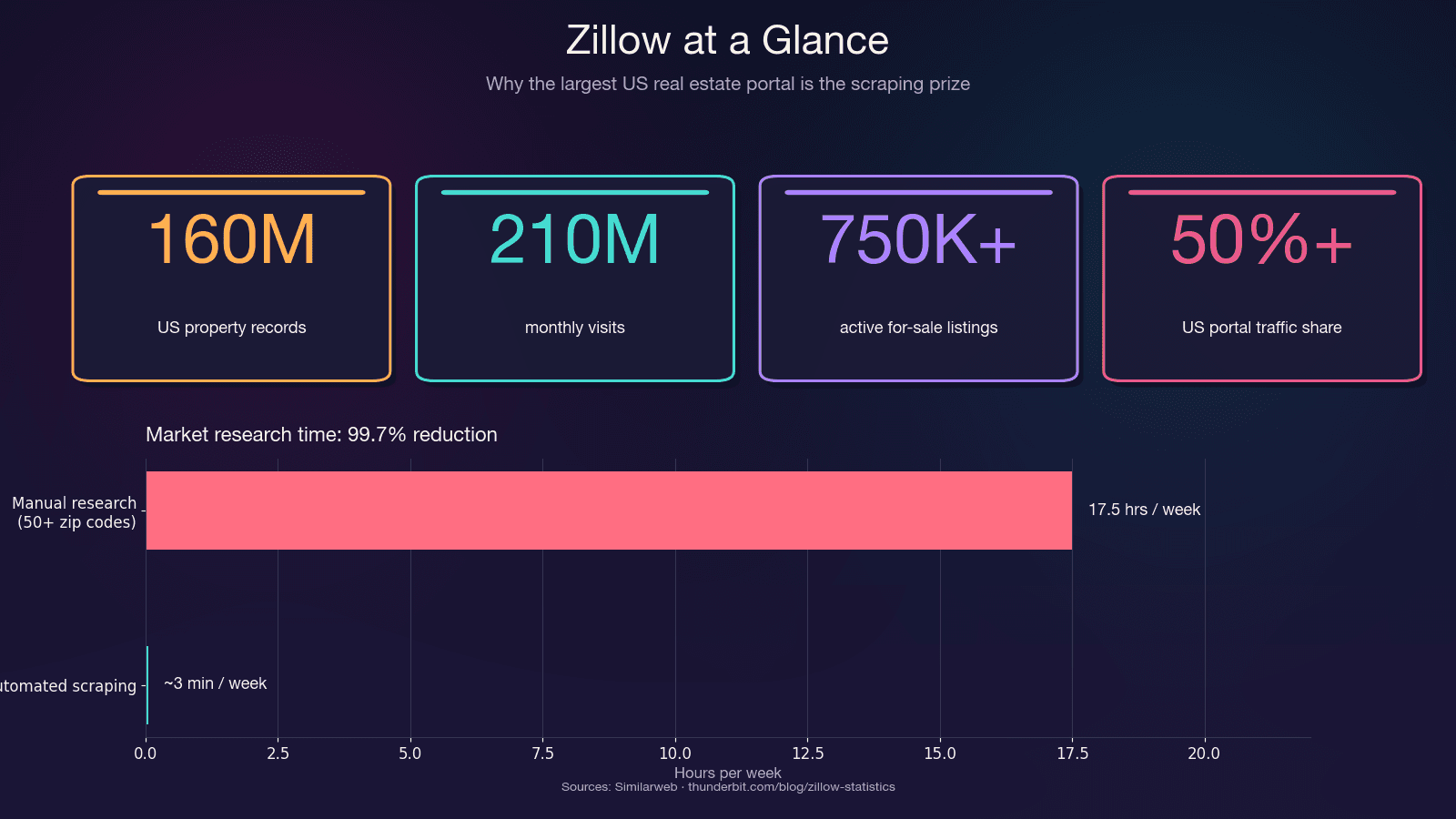
Zillow ist die größte zentrale Quelle für US-Wohnimmobiliendaten. Die Plattform verzeichnet und listet rund 750.000+ aktive Kaufangebote sowie 1,9 Millionen Mietobjekte. Mehr als 50 % des gesamten US-Traffics auf Immobilienportalen laufen über die Plattform — mehr als doppelt so viel wie beim nächsten Konkurrenten.
Bevor wir in den Python-Code einsteigen, ist wichtig zu wissen: Zillow mit Python zu scrapen ist nicht die einzige Möglichkeit. Die falsche Methode kann Stunden kosten. Python-Tools wie httpx und BeautifulSoup erfordern mittlere Kenntnisse, das manuelle Handling von Headern und Proxys, arbeiten mit moderater Geschwindigkeit (1–3 Sekunden pro Seite) und brauchen laufende Wartung, sind dafür kostenlos; Selenium oder Playwright verbessern die Anti-Bot-Handhabung durch das Rendern von JavaScript, sind aber langsamer (5–15 Sekunden pro Seite) und ebenfalls wartungsintensiv; Scraping-APIs wie ScraperAPI oder ScrapFly sind dank integriertem Anti-Bot-Schutz schneller und mit moderatem Pflegeaufwand verbunden, kosten aber 30–599 US-Dollar pro Monat; die offizielle Zillow-API über Bridge Interactive ist schnell und wartungsarm, aber eingeschränkt und kostet etwa 500 US-Dollar pro Monat; und No-Code-Tools wie Thunderbit sind einsteigerfreundlich, schnell, dank KI-Anpassung wartungsfrei und bieten in der Regel ein Freemium-Modell.
Allein die Zeitersparnis ist enorm. Manuelle Recherche über 50+ Postleitzahlgebiete kann 15–20 Stunden pro Woche verschlingen. Automatisiertes Scraping erledigt dieselbe Arbeit in wenigen Minuten — eine Reduktion des Zeitaufwands um 99,7 %.
Alle Wege, Zillow zu scrapen: Python vs. API vs. No-Code im Vergleich
Bevor du in Python startest, solltest du wissen, dass „zillow mit python scrapen“ nicht die einzige Option ist. Die falsche Methode kostet unnötig Zeit. Hier ist ein direkter Vergleich zur Orientierung:
| Methode | Kenntnisstand | Anti-Bot-Schutz | Geschwindigkeit | Wartung | Kosten |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Mittelstufe | Manuell (Header, Proxys) | Mittel (1–3 s/Seite) | Hoch (Selektoren brechen) | Kostenlos |
| Python + Selenium/Playwright | Mittelstufe | Besser (rendert JS) | Langsam (5–15 s/Seite) | Hoch | Kostenlos |
| Scraping-API (ScraperAPI, ScrapFly) | Mittelstufe | Integriert | Schnell | Mittel | 30–599 $/Monat |
| Offizielle Zillow-API (Bridge Interactive) | Anfänger–Mittelstufe | N/A | Schnell | Gering | ca. 500 $/Monat, eingeschränkter Zugriff |
| No-Code-Tool (Thunderbit) | Anfänger | Integriert (KI passt sich an) | Schnell | Keine (KI liest die Seite neu) | Freemium |
Wenn du die Daten sofort brauchst, ohne Code zu schreiben, starte mit Thunderbit. Wenn du verstehen möchtest, wie alles unter der Haube funktioniert oder volle Anpassung brauchst, lies weiter für die Python-Anleitung.
Der 2-Minuten-Weg: Zillow mit Thunderbit scrapen (ohne Code)
Bevor wir in die Python-Details gehen, hier der Weg für alle, die Zillow-Daten schnell brauchen — ohne Python-Setup, ohne Proxy-Konfiguration, ohne Pflege von Selektoren. Wir haben diesen Workflow bei Thunderbit genau dafür gebaut, strukturierte Immobiliendaten ohne technischen Aufwand zu gewinnen.
Schwierigkeitsgrad: Anfänger Zeitaufwand: ca. 2 Minuten Benötigt: Chrome-Browser, (die kostenlose Stufe reicht)
Schritt 1: Thunderbit installieren und Zillow öffnen
Installiere die Thunderbit-Erweiterung aus dem Chrome Web Store. Öffne eine Zillow-Suchergebnisseite — zum Beispiel eine Suche nach Häusern in Houston, TX.
Schritt 2: Auf „AI Suggest Fields“ klicken
Öffne die Thunderbit-Seitenleiste und klicke auf „AI Suggest Fields“. Die KI liest die Seite aus und schlägt automatisch Spalten vor: Preis, Adresse, Schlafzimmer, Badezimmer, Wohnfläche, Zestimate, Inserats-URL und mehr. In meinen Tests erkennt sie typischerweise über 20 Felder ganz ohne manuelle Einrichtung.
Schritt 3: Auf „Scrape“ klicken
Klicke auf den Scrape-Button. Die Daten werden in einer strukturierten Tabelle in der Erweiterung angezeigt. Thunderbit verarbeitet Zillows Seitennavigation automatisch — sowohl per Klick als auch endloses Scrollen.
Schritt 4: Mit Unterseiten-Scraping anreichern
Du möchtest Daten von Detailseiten wie Steuerhistorie, Schulbewertungen oder Preisverlauf? Verwende „Scrape Subpages“, um deine Tabelle zu erweitern. Thunderbit folgt jeder Inserats-URL und extrahiert zusätzliche Felder — ganz ohne zusätzlichen Code.
Schritt 5: Exportieren
Exportiere nach Google Sheets, Excel, Airtable oder Notion. Der Export ist kostenlos.
Warum Thunderbit für Zillow besonders gut funktioniert
Der eigentliche Vorteil ist die Robustheit. Die KI von Thunderbit liest die Seitenstruktur bei jedem Scrape frisch ein. Wenn Zillow das Layout ändert (was häufig passiert), müssen keine brüchigen CSS-Selektoren repariert werden. Die KI passt sich automatisch an. Das löst tatsächlich das „inhärent fragile“ Problem klassischer Code-Scraper, das so viele Nutzer frustriert.
Welche Daten lassen sich von Zillow scrapen? (20+ Felder)
Die meisten Anleitungen holen nur Preis und Adresse und hören dann auf. Zillow-Exposés enthalten tatsächlich deutlich mehr extrahierbare Daten, als viele denken — hier ist eine Referenztabelle:
| Feld | Wo es zu finden ist | Schwierigkeitsgrad der Extraktion |
|---|---|---|
| Angebotspreis | Suche + Detailseite | Einfach |
| Adresse / PLZ | Suche + Detailseite | Einfach |
| Zestimate | Suche + Detailseite | Einfach |
| Preisverlauf (jedes Ereignis) | Detailseite | Schwer (verschachteltes JSON) |
| Steuerhistorie | Detailseite | Schwer (verschachteltes JSON) |
| Schlafzimmer / Badezimmer / Wohnfläche | Suche + Detailseite | Einfach |
| Baujahr | Detailseite | Einfach |
| HOA-Gebühr | Detailseite | Mittel |
| Walk Score / Transit Score | Detailseite (iFrame) | Schwer (erfordert JS-Rendering) |
| Schulbewertungen | Detailseite | Mittel |
| Grundstücksgröße | Detailseite | Einfach |
| Tage auf Zillow | Suche | Einfach |
| Makler / Brokerage | Suche + Detailseite | Mittel |
| MLS-Nummer | Detailseite | Einfach |
| Immobilientyp | Suche + Detailseite | Einfach |
| Breitengrad / Längengrad | JSON in __NEXT_DATA__ | Mittel |
| Beschreibungstext | Detailseite | Einfach |
| Foto-URLs | Suche + Detailseite | Mittel |
| Miet-Zestimate | Detailseite | Mittel |
| Vergleichbare Verkäufe in der Nähe | Detailseite | Schwer |
Die „schwierigen“ Felder — Preisverlauf, Steuerhistorie, vergleichbare Verkäufe — liegen auf Detailseiten in verschachteltem JSON. Der Python-Abschnitt unten zeigt genau, wie du diese extrahierst. Und wenn du den Code überspringen möchtest, erkennt Thunderbit mit „AI Suggest Fields“ die meisten dieser Spalten automatisch, und das Unterseiten-Scraping zieht die Detailseiten-Felder ebenfalls automatisch.
Python-Umgebung zum Zillow-Scraping einrichten
Schwierigkeitsgrad: Mittelstufe Zeitaufwand: ca. 5 Minuten für das Setup, ca. 30 Minuten für das vollständige Tutorial Benötigt: Python 3.8+, Chrome-Browser (zum Prüfen der Seiten), ein Texteditor oder eine IDE
Installiere die benötigten Bibliotheken:
1pip install httpx beautifulsoup4 pandas lxmlDas ist die Aufgabe der einzelnen Pakete:
- httpx — HTTP-Client mit besserer Performance als
requestsund Unterstützung für asynchrone Aufrufe - beautifulsoup4 + lxml — HTML-Parsing
- pandas — Datenexport nach CSV/Excel
- Optional: selenium oder playwright, wenn du JavaScript-lastige Seiten rendern musst
Zillows Seitenstruktur verstehen, bevor du scrapen beginnst
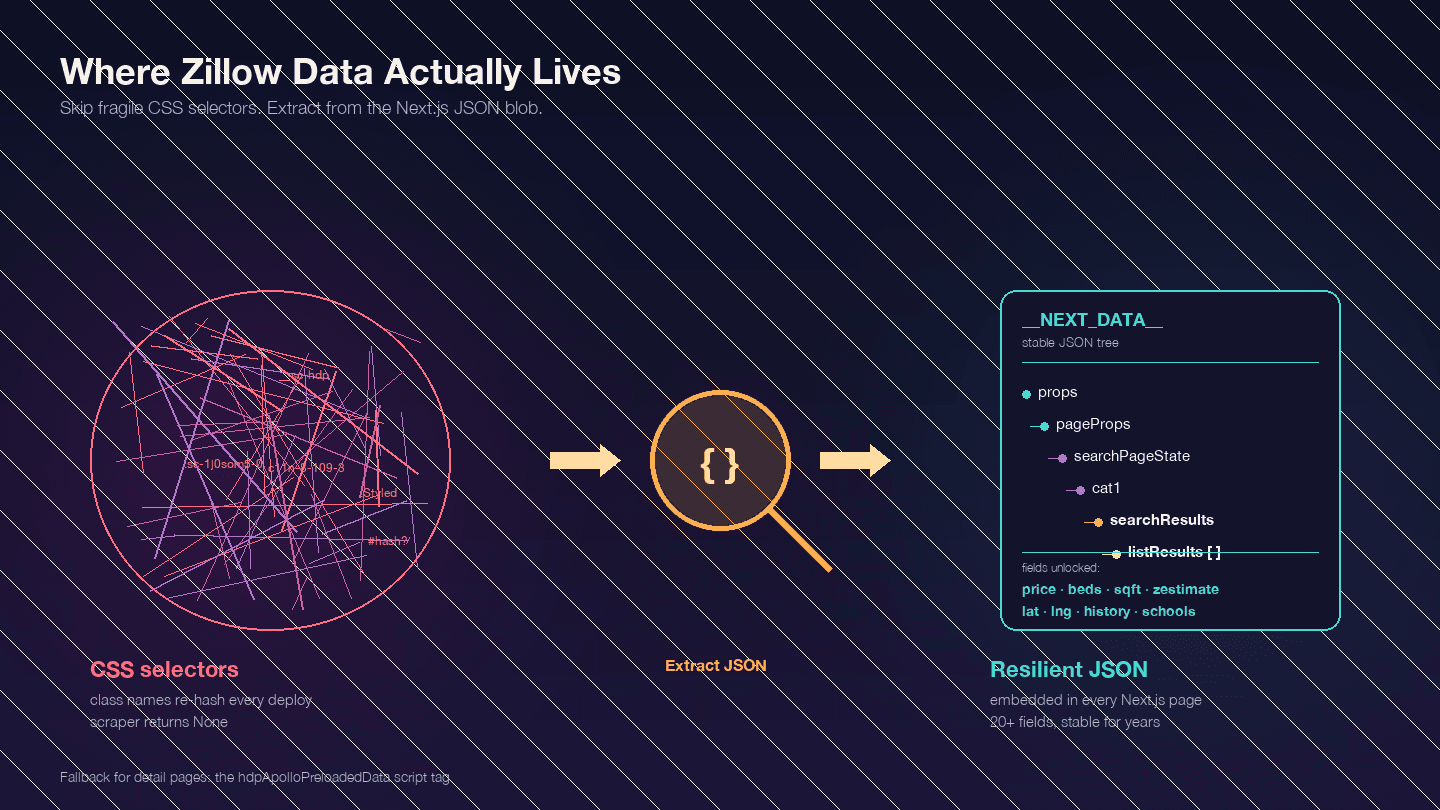
Das ist der wichtigste Punkt, bevor du irgendeinen Code schreibst. Zillow ist eine Next.js-Anwendung — bestätigt durch . Das bedeutet: Der Großteil der gewünschten Daten steckt nicht in den sichtbaren HTML-Elementen. Sie ist in einem JSON-Block im <script id="__NEXT_DATA__"> eingebettet.
Öffne eine beliebige Zillow-Immobilienseite, drücke F12, gehe zu „Elements“ und suche nach __NEXT_DATA__. Dort findest du ein riesiges JSON-Objekt mit allen Listing-Daten — Preise, Koordinaten, Objektdetails, Preisverlauf, Steuerdaten, Schulbewertungen und mehr.
Warum ist das wichtig? Zillows CSS-Klassennamen sind gehasht (von styled-components generiert) und ändern sich bei jedem Deployment. Eine Klasse wie StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 sieht nächste Woche komplett anders aus. Jeder Scraper, der auf CSS-Selektoren basiert, bricht deshalb regelmäßig.
Der JSON-Ansatz über __NEXT_DATA__ ist deutlich stabiler, weil er überhaupt nicht von der HTML-Struktur abhängt.
Wichtige JSON-Pfade für Suchergebnisse:
| Pfad | Inhalt |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Array mit Suchergebnissen |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Ergebnisse der Kartenansicht |
props.pageProps.searchPageState.cat1.searchList.totalPages | Gesamtzahl verfügbarer Seiten |
Bei Detailseiten nutzen einige __NEXT_DATA__ und andere einen alternativen Script-Tag hdpApolloPreloadedData. Der folgende Code behandelt beide Varianten.
Schritt für Schritt: Zillow mit Python scrapen
Schritt 1: HTTP-Header setzen, um sofortige Blockaden zu vermeiden
Ein einfaches httpx.get() an Zillow liefert keine Listing-Daten, sondern eine CAPTCHA-Seite. Zillow nutzt PerimeterX (HUMAN Security) zusammen mit Cloudflare — beide werden in Scraping-Benchmarks mit bewertet. Das System prüft Ihren TLS-Fingerprint, Ihre HTTP-Header und die IP-Reputation.
Hier sind die minimalen Header, die 2025 funktionieren:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Die Sec-Ch-Ua-Header sind entscheidend. Viele Anleitungen lassen sie weg — genau deshalb funktioniert deren Code gegen PerimeterX nicht.
Schritt 2: Zillow-Suchergebnisse scrapen
Zillow-Such-URLs folgen einem vorhersehbaren Muster. Für Houston, TX:
- Seite 1:
https://www.zillow.com/houston-tx/ - Seite 2:
https://www.zillow.com/houston-tx/2_p/ - Seite 3:
https://www.zillow.com/houston-tx/3_p/
Jede Seite enthält etwa 41 Inserate. Zillow begrenzt die Ergebnisse auf 20 Seiten (ca. 820 Inserate). Für größere Datensätze musst du nach Geografie aufteilen (dazu später mehr).
Hier ist der Code, um Suchergebnisse zu scrapen, indem die Daten aus dem __NEXT_DATA__-JSON extrahiert werden:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Listing-Daten von einer Zillow-Suchergebnisseite scrapen."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Status {response.status_code} für {url}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("Kein __NEXT_DATA__ gefunden — vermutlich durch CAPTCHA blockiert")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Unerwartete JSON-Struktur — Zillow hat das Format möglicherweise geändert")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listingsUm mehrere Seiten zu scrapen, laufe mit Pausen durch:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # Erste 5 Seiten
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Seite {page} wird gescrapt...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # Zufällige Pause zwischen 3 und 7 Sekunden
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Insgesamt gescrapte Inserate: {len(all_listings)}")Du solltest nun strukturierte Listing-Daten in all_listings sehen. Wenn du leere Ergebnisse erhältst, lies den Abschnitt „Warum Scraper brechen“ weiter unten.
Schritt 3: Zillow-Detailseiten scrapen
Suchergebnisse liefern die Basisdaten. Detailseiten enthalten die tieferen Informationen: Preisverlauf, Steuerhistorie, Schulbewertungen, Maklerdaten und Objektbeschreibungen. Jede Inserats-URL aus Schritt 2 führt zu einer Detailseite.
Zillow-Detailseiten verwenden zwei mögliche Datenformate. Hier ist Code, der beide abdeckt:
1def scrape_zillow_detail(url):
2 """Detaillierte Immobiliendaten von einer Zillow-Inseratsseite scrapen."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # Zuerst __NEXT_DATA__ versuchen (am häufigsten)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # Fallback: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Strukturierte Felder aus einem Zillow-Property-JSON-Objekt extrahieren."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }Gehe mit Verzögerungen durch deine Inserats-URLs:
1detail_data = []
2for listing in all_listings[:10]: # Erst 10 zum Testen
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Detailseite wird gescrapt: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))Nach diesem Schritt solltest du eine Liste von Dictionaries haben, die sowohl Suchdaten als auch Detaildaten für jede Immobilie enthalten.
Schritt 4: Pagination für mehrere Seiten handhaben
Für Gebiete mit mehr als 820 Inseraten (dem 20-Seiten-Limit) musst du nach Geografie aufteilen. Zillows interne API akzeptiert mapBounds-Parameter. Die Strategie: Teile die Karte in Quadranten auf und scrapen Sie jeden Bereich separat.
1def split_bounds(bounds):
2 """Kartengrenzen in 4 Quadranten aufteilen."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]Für die meisten Anwendungsfälle — etwa die Überwachung von 50–200 Inseraten in einem bestimmten Gebiet — reicht die normale URL-Pagination aus. Der Quadranten-Ansatz ist eher für stadtweite oder landesweite Scrapes gedacht.
Schritt 5: Gescrapte Zillow-Daten exportieren
Speichere alles mit pandas als CSV:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"{len(df)} Inserate nach zillow_houston_listings.csv exportiert")Für JSON-Export:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)Wenn du den Export ganz überspringen möchtest, exportiert Thunderbit kostenlos nach Google Sheets, Airtable und Notion — praktisch, wenn du die Daten sofort in einem kollaborativen Format benötigst.
Warum Zillow-Scraper kaputtgehen — und wie man robuste baut
Das ist der Überlebensleitfaden.
Aus meiner Erfahrung brechen Scraper bei Zillow aus drei konkreten Gründen — und für jeden gibt es eine klare Lösung.
PerimeterX und CAPTCHAs: Warum deine Requests leere Daten zurückgeben
Die PerimeterX-Integration von Zillow prüft mehrere Signale gleichzeitig: TLS-Fingerprint, HTTP-Header, IP-Reputation und Request-Muster. Erkennt das System Automatisierung, liefert es eine „Press & Hold“-CAPTCHA-Seite statt der Listing-Daten.
Der genaue Fehlerfall: Du sendest eine Anfrage mit Standard-Python-Headern. Das Antwort-HTML enthält PerimeterX-Challenge-Skripte statt Immobiliendaten — und dein BeautifulSoup-Parse findet kein __NEXT_DATA__-Tag.
Die Lösung: Verwende die vollständigen Browser-ähnlichen Header aus Schritt 1. Wenn du mehr als ein paar Dutzend Anfragen stellst, brauchst du zusätzlich Proxy-Rotation (siehe unten). Für umfangreiches Scraping empfiehlt sich eine Bibliothek wie curl_cffi mit impersonate="chrome" — sie ist der einzige Python-HTTP-Client, der einen echten Chrome-TLS-Fingerprint annähernd nachbilden kann.
Dynamische CSS-Selektoren: Warum BeautifulSoup None zurückgibt
Wenn du CSS-Selektoren wie .list-card-price oder Klassennamen mit Hashes verwendest, bricht dein Scraper jedes Mal, wenn Zillow neuen Code ausrollt.
Zillow nutzt styled-components, die Klassennamen wie StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 erzeugen. Der Hash-Anteil ändert sich mit jedem Build.
Die Lösung: Verwende überhaupt keine CSS-Selektoren. Extrahiere die Daten aus dem __NEXT_DATA__-JSON-Block, wie im Code oben gezeigt. Dieser Ansatz ist seit Jahren stabil, weil sich die JSON-Struktur deutlich seltener ändert als das HTML-Markup.
Wenn du HTML-Parsing unbedingt brauchst, achte auf data-test-Attribute (z. B. data-test="property-card") oder verwende Teilstring-Matching bei Klassen wie [class*="PropertyCard"]. Doch die JSON-Extraktion ist der zuverlässigere Weg.
Proxy-Rotation und exponentielles Backoff: Code, der IP-Sperren überlebt
Rechenzentrums-IPs werden von Zillow . Für zuverlässigen Zugriff brauchst du Residential Proxies. Sichere Rate: 1 Request alle 3–8 Sekunden pro IP, also unter etwa 500 Requests pro Stunde.
Hier ist ein Retry-Dekorator mit exponentiellem Backoff und Jitter:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """AWS-ähnliches exponentielles Backoff mit vollem Jitter."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Blockiert ({response.status_code}). Neuer Versuch in {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return NoneUnd ein einfaches Proxy-Rotation-Pool:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# Nutzung:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])Bei Proxy-Anbietern bietet Residential Proxies ab ca. 1 $/GB an (die günstigste Option), während IPRoyal und Smartproxy solide Mittelklasse-Optionen bei 4–7 $/GB sind.
Die wartungsfreie Alternative
Wenn du regelmäßig Zillow scrapen und keine Lust mehr hast, kaputte Selektoren oder Proxy-Pools zu pflegen, liest Thunderbits KI die Seitenstruktur bei jedem Scrape frisch ein. Keine Selektoren, die man warten müsste, keine Proxy-Konfiguration. Das löst wirklich das Fragilitätsproblem, das klassische Scraper so oft zum Dauerschmerz macht.
Zillow-Scraping automatisieren: Planung und Preisüberwachung
Jeder Immobilieninvestor, mit dem ich gesprochen habe, will genau das — und kein anderer Zillow-Scraping-Guide behandelt es: wiederkehrende automatisierte Scrapes für Preis-Tracking.
Für Python-Nutzer: Cron-Jobs und Erkennung von Preisänderungen
Richte einen Cron-Job ein, der deinen Scraper wöchentlich ausführt und Preisänderungen markiert:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """Neuen Scrape mit historischen Daten vergleichen und Änderungen > Schwellenwert markieren."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("Erster Lauf — Basisdaten gespeichert.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # Neue Daten mit Zeitstempel anhängen
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsFüge das deiner Crontab hinzu, damit es jeden Montag um 6 Uhr läuft:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.pyEin praktisches Beispiel: Überwache wöchentlich 50 Listings in Austin, TX. Jeden Montag scrapt das Skript die aktuellen Preise, vergleicht sie mit der Vorwoche und erzeugt eine CSV mit allen Preisrückgängen von mehr als 5 %.
Für Nicht-Programmierer: Thunderbit Scheduled Scraper
Mit Thunders „Scheduled Scraper“ kannst du das Intervall in natürlicher Sprache angeben („jeden Montag um 9 Uhr“), deine Zillow-Such-URLs einfügen und auf „Schedule“ klicken. Die Daten werden bei jedem Lauf automatisch an Google Sheets exportiert. Kein Python, kein Cron, kein Server, den du betreuen musst. Das ist besonders nützlich für Makler oder Operations-Teams, die verlässliches Preis-Monitoring ohne technische Unterstützung brauchen.
Tipps für verantwortungsvolles Zillow-Scraping
Ein paar Hinweise, um auf der sicheren Seite zu bleiben:
- Scrape nur öffentlich zugängliche Daten. Greife nicht auf Seiten hinter Login- oder Authentifizierungswänden zu.
- Nutze angemessene Request-Raten. 3–8 Sekunden zwischen Anfragen. Den Server nicht mit Requests fluten.
- Scrape keine persönlichen oder privaten Nutzerdaten. Maklernamen und Brokerage-Infos in Inseraten sind öffentlich; Kontodaten von Nutzern nicht.
- Speichere und nutze Daten ethisch. Marktanalysen, Investment-Research und Lead-Generierung sind legitime Anwendungsfälle. Spam nicht.
- Rechtlicher Kontext: Das Urteil stellte klar, dass das Scrapen öffentlich zugänglicher Daten nicht gegen den CFAA verstößt. Das Urteil Meta v. Bright Data (2024) bestätigte ähnliche Grundsätze. Dennoch schränkt Zillows ToS automatisierten Zugriff ein, und die Plattform setzt dies über IP-Bans und CAPTCHAs durch, nicht primär über Klagen. Prüfe immer die aktuelle Rechtslage und beachte .
Die richtige Methode zum Scrapen von Zillow mit Python wählen
Der beste Weg hängt von deiner Situation ab:
Du brauchst schnell Daten, ohne Code? bringt dich von einer Zillow-Suchergebnisseite in etwa 2 Minuten zu einer strukturierten Tabelle. Die KI passt sich an Layout-Änderungen an, verarbeitet Pagination und exportiert kostenlos. Installiere die und teste sie auf einer Zillow-Suchergebnisseite.
Du möchtest volle Kontrolle? Verwende den Python-Code aus diesem Leitfaden. Extrahiere die Daten aus dem __NEXT_DATA__-JSON (nicht aus CSS-Selektoren), um Stabilität zu gewährleisten. Setze passende Browser-ähnliche Header. Verwende Residential Proxies und exponentielles Backoff für mehr Zuverlässigkeit.
Du skalierst hoch? Scraping-APIs wie (99 % Erfolgsrate bei Zillow) oder ScraperAPI übernehmen die Proxy- und CAPTCHA-Infrastruktur für dich, je nach Volumen für 30–599 $/Monat.
Du willst Preise über die Zeit verfolgen? Richte einen Cron-Job mit dem Skript zur Erkennung von Preisänderungen ein oder nutze Thunders Scheduled Scraper für einen wartungsfreien Ansatz.
Die Daten sind da. Die einzige Frage ist, wie viel Entwicklungszeit du investieren möchtest, um sie herauszuholen. Weitere Infos dazu, wie du Webdaten in Tabellen bringst, findest du in unserem Leitfaden zum oder in unserem mit den neuesten Plattformdaten. Außerdem kannst du Tutorials auf dem ansehen.
FAQs
Kann man Zillow mit Python kostenlos scrapen?
Ja — httpx, BeautifulSoup und pandas sind alle kostenlos und Open Source. Der Kompromiss ist die Zeit: Du musst Header, Proxy-Rotation und die Pflege der Selektoren selbst übernehmen. Rechne mit 4–8 Stunden für das erste Setup und 4–10 Stunden pro Monat für Wartung, wenn Zillow seine Website ändert. Thunderbit bietet ebenfalls einen kostenlosen Tarif, wenn du den gesamten Programmieraufwand vermeiden möchtest.
Hat Zillow eine offizielle API?
Zillow hat seine kostenlose öffentliche API im September 2021 eingestellt. Der Zugriff läuft jetzt über Bridge Interactive, erfordert eine Freigabe, kostet ungefähr 500 US-Dollar pro Monat und richtet sich an lizenzierte Immobilienprofis. Für die meisten Nutzer — Investoren, Forscher, Makler für Marktanalysen — ist Scraping die praktische Alternative. Zillow veröffentlicht allerdings weiterhin kostenlose Forschungsdaten als CSV-Downloads unter , darunter den Zillow Home Value Index und den Zillow Observed Rent Index.
Wie vermeide ich Blockierungen beim Scrapen von Zillow?
Drei Dinge: (1) verwende realistische Browser-Header inklusive Sec-Ch-Ua — das ist der Header, den die meisten Anleitungen vergessen, und genau darauf prüft PerimeterX zuerst; (2) rotiere Residential Proxies — Rechenzentrums-IPs werden sofort blockiert; (3) extrahiere Daten aus dem __NEXT_DATA__-JSON statt aus HTML-Selektoren, um Fehler durch Layout-Änderungen zu vermeiden. Halte die Request-Rate bei 1 Anfrage pro 3–8 Sekunden und IP. Oder nutze ein Tool wie Thunderbit, das den Anti-Bot-Schutz automatisch übernimmt.
Was ist der beste Weg, Zillow ohne Programmieren zu scrapen?
Thunderbits AI Web Scraper ist der schnellste Weg. Installiere die , öffne eine Zillow-Suchergebnisseite, klicke auf „AI Suggest Fields“, um die Spalten automatisch zu erkennen, und dann auf „Scrape“. Exportiere danach ohne Code nach Google Sheets, Excel, Airtable oder Notion. Die KI liest die Seite jedes Mal neu ein und bricht deshalb nicht, wenn Zillow das Layout ändert.
Wie oft ändert Zillow seine Website-Struktur, und was bedeutet das für Scraper?
Zillow spielt häufig Updates aus — manchmal wöchentlich. Da dort styled-components eingesetzt werden, ändern sich CSS-Klassennamen mit jedem Deployment, und Scraper auf Basis von CSS-Selektoren brechen regelmäßig. Der robusteste Ansatz in Python ist die Extraktion aus dem __NEXT_DATA__-JSON-Block, dessen Struktur sich deutlich seltener ändert. Für einen wartungsfreien Ansatz liest Thunderbits KI die Seitenstruktur bei jedem Scrape neu ein und passt sich automatisch an Layout-Änderungen an.
Mehr erfahren