Yelp enthält auf — und diese Daten in ein brauchbares Format zu bringen, war noch nie so knifflig. Die Anti-Bot-Offensive von Yelp aus den Jahren 2024 bis 2025 hat die meisten bestehenden Python-Tutorials zum Scraping still und leise obsolet gemacht.
Wenn du in letzter Zeit versucht hast, einen Yelp Scraper auszuführen und direkt auf eine Wand aus 403-Fehlern, leeren HTML-Antworten oder CAPTCHAs gestoßen bist, die es vor sechs Monaten noch nicht gab, bildest du dir das nicht ein. Yelp setzt inzwischen auf TLS-/JA3-Fingerprinting, wechselnde verschleierte CSS-Klassennamen und aggressives Scoring der IP-Reputation — das heißt, der alte requests + BeautifulSoup-Ansatz, den fast jedes Tutorial noch empfiehlt, scheitert oft schon beim ersten Request. Ich habe wochenlang verschiedene Methoden gegen den aktuellen Yelp-Stack getestet, und dieser Leitfaden deckt alles ab, was 2025 wirklich funktioniert: die offizielle Fusion API (und warum sie wahrscheinlich nicht reicht), einen vollständigen Python-Workflow mit mehrstufiger Anti-Block-Strategie sowie eine 2-Klick-No-Code-Alternative mit für alle, die einfach nur an die Daten wollen — ohne eine Debugging-Odyssee.
Warum Yelp mit Python scrapen? Und wer profitiert wirklich davon?
Bevor du auch nur eine Zeile Code schreibst: Was ist eigentlich der konkrete Business-Use-Case für Yelp-Daten? Die Plattform ist nicht nur eine Bewertungsseite für Restaurants — sie ist im Grunde eine Live-Datenbank lokaler Unternehmen mit strukturierten Kontaktdaten, Bewertungen, Kategorien, Öffnungszeiten und Hunderten Millionen Kundenmeinungen.
Hier siehst du, wer am meisten profitiert und was typischerweise extrahiert wird:
| Anwendungsfall | Wichtige Datenfelder | Warum das wichtig ist |
|---|---|---|
| Vertrieb & Lead-Generierung | Firmenname, Telefonnummer, Website, Adresse, Kategorie, Bewertung | Zielgerichtete Prospect-Listen für lokale KMU aufbauen — 4 von 5 Yelp-Nutzern sind bei Ankunft kaufbereit |
| Wettbewerbsanalyse | Bewertungen, Sternebewertungen, Anzahl der Rezensionen, Stimmungsbild | Reputation der Konkurrenz beobachten, Service-Lücken erkennen, Trends verfolgen |
| Marktforschung & NLP | Vollständiger Rezensionstext, Datum, Metadaten der Rezensenten | Sentiment-Analysen, Topic Modeling — Yelp-Bewertungen gehören zu den am häufigsten verwendeten NLP-Korpora in der Forschung |
| Immobilien & Standortwahl | Unternehmensdichte, Kategorienmix, Bewertungsqualität nach Gebiet | Standortwahl für Filialen und Handel — Yelp verkauft dafür mit Location Intelligence sogar ein lizenziertes B2B-Produkt |
| E-Commerce & Operations | Preissignale, Kundenbeschwerden, Servicezeiten | Beobachten, wie Wettbewerber bewertet werden, operative Muster erkennen |
Der gemeinsame Nenner: Das eigentliche Ziel sind strukturierte Daten, und Python ist nur ein Weg dorthin. Manche brauchen volle programmatische Kontrolle. Andere nur eine Tabelle mit den Kontaktdaten von Handwerkern in Austin. Beides wird hier abgedeckt.
Yelp Fusion API vs. Python Web Scraping: Was solltest du verwenden?
Die meisten Anleitungen überspringen diese Entscheidung komplett und springen direkt in den Code, ohne zu prüfen, ob die offizielle — inzwischen als „Yelp Places API“ neu positioniert — nicht ausgereicht hätte. Aus meiner Erfahrung spart genau diese Bewertung Stunden Arbeit, denn die API ist für manches stark, für anderes aber völlig unzureichend.
Was die Fusion API tatsächlich liefert
Die Fusion API stellt strukturierte Unternehmenssuche, Unternehmensdetails, Autovervollständigung und einen Reviews-Endpunkt bereit. Sie ist autorisiert, gut dokumentiert und erfordert keine Anti-Bot-Tricks.
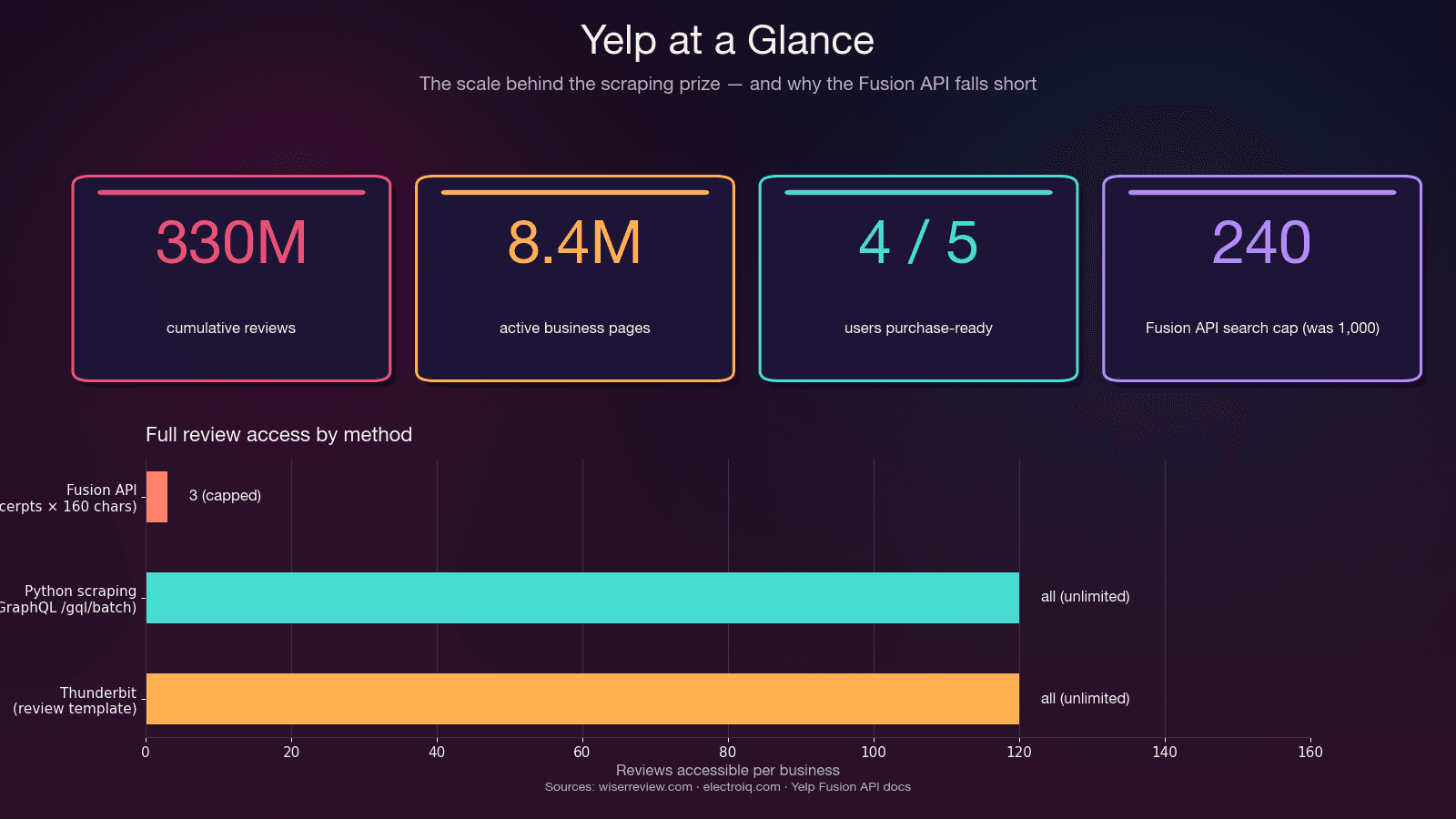
Aber genau beim Reviews-Endpunkt bricht das Modell zusammen. Das hat Yelp-Personal auf GitHub bestätigt:
„Die Yelp API liefert keinen vollständigen Rezensionstext. Standardmäßig werden drei Rezension-Auszüge mit jeweils 160 Zeichen bereitgestellt." —
Das ist kein Bug — das ist Absicht. Die API ist physisch auf 3 Auszüge pro Unternehmen begrenzt (7 im Premium-Tarif), und jeder Auszug ist auf rund 160 Zeichen gekürzt. Keine Review-Metadaten (Votes wie useful/funny/cool), keine Historie des Rezensenten, keine Antworten des Unternehmens. Und das — vorher waren es 5.000. Der Einstiegspreis beginnt bei .
Die Entscheidungsgrundlage
| Faktor | Yelp Fusion API | Python Web Scraping | Thunderbit (No-Code) |
|---|---|---|---|
| Vollständige Reviews | ❌ Nur 3 Auszüge (~160 Zeichen je Auszug) | ✅ Alle Reviews über GraphQL | ✅ Alle sichtbaren Reviews |
| Rate Limits | 300–500/Tag (neu); 5.000 (Legacy) | Selbst verwaltet (Proxy-Budget) | Credit-basiert |
| Einrichtungsaufwand | ~15 Min. (API-Key + SDK) | Stunden bis Tage | ~2 Min. |
| Geschäftsdaten | ~20 strukturierte Felder | Unbegrenzt (HTML/JSON parsen) | KI-empfohlene Felder |
| Anti-Bot-Handling | N/A (autorisiert) | Muss selbst gebaut werden | Automatisch abgedeckt |
| Rechtliches Risiko | ✅ Autorisiert | ⚠️ Graubereich der ToS | ⚠️ Gleich wie Scraping |
| Kosten | Ab $29/Monat | Kostenlos (+ Proxy-Kosten von $0,75–$4/GB) | Kostenloser Tarif verfügbar |
| Wartung | Niedrig (API stabil) | Hoch (Selektoren brechen, Anti-Bot wird härter) | Niedrig (KI passt sich neu an) |
Die Fusion API ist sinnvoll, wenn: du grundlegende Unternehmensinfos, kleine Abfragen oder eine autorisierte Integration brauchst — und 3 Review-Auszüge pro Unternehmen reichen.
Python Scraping ist sinnvoll, wenn: du vollständige Review-Texte, alle Bewertungen eines Unternehmens, Review-Metadaten, mehr als 240 Ergebnisse pro Suche oder ein Budget unter 29 US-Dollar im Monat brauchst.
Thunderbit ist sinnvoll, wenn: du die Daten schnell haben willst, ohne Code zu schreiben oder zu warten. Mehr dazu unten im No-Code-Abschnitt.
Der No-Code-Shortcut: Yelp mit Thunderbit scrapen, ganz ohne Python
Bevor wir tief in Python einsteigen: Hier ist der schnellste Weg für alle, deren eigentliches Ziel die Daten sind — nicht das Programmieren. Bei konkurrierenden Anleitungen wird fast immer Python-Know-how vorausgesetzt, aber in meiner Arbeit bei Thunderbit sehe ich immer wieder, dass ein großer Teil der Leute, die nach „scrape Yelp“ suchen, Vertriebsmitarbeiter, Operations-Manager und kleine Unternehmen sind, die einfach eine Tabelle mit lokalen Firmen wollen — keinen Crashkurs in TLS-Fingerprinting.
bringt bereits vorgefertigte Yelp-Vorlagen mit:
- — extrahiert Firmenname, Bewertung, Kontaktdaten, Adresse, Öffnungszeiten, Kategorie
- — extrahiert Benutzername des Rezensenten, Rezensionstext, Bewertung, Datum, Standort des Rezensenten
So funktioniert es in der Praxis
- Öffne in Chrome eine Yelp-Suchergebnisseite oder eine Unternehmensseite
- Klicke in der auf KI-Felder vorschlagen — die KI liest die Seite und schlägt Spalten vor (Firmenname, Bewertung, Anzahl der Rezensionen, Preisniveau, Kategorie, Adresse, Telefonnummer, URL)
- Klicke auf Scrape — fertig
Bei den vorgefertigten Yelp-Vorlagen ist es noch einfacher: Vorlage öffnen, auf Scrape klicken.
Subpage-Scraping übernimmt den Anreicherungs-Loop automatisch — starte auf einer Yelp-Suchergebnisseite, aktiviere Subpage-Scraping, und Thunderbit besucht jede Unternehmensseite, um Öffnungszeiten, vollständige Reviews, Website, Fotos und Ausstattungsmerkmale zu ziehen. Keine zusätzliche Einrichtung nötig.
Pagination ist automatisch — sowohl per Klick als auch per Scrollen, direkt eingebaut. (Mehr dazu in unserem .)
Exports sind in jedem Tarif kostenlos — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Kein pandas, kein Code zum Schreiben von CSV-Dateien.
Zeitvergleich
| Zeit | Python Scraper | Thunderbit |
|---|---|---|
| Erster Lauf | Stunden bis Tage (Selektoren schreiben, Pagination, Proxies, Retry-Logik) | ~30 Sekunden mit der fertigen Yelp-Vorlage |
| Wenn Yelp das Markup ändert | Selektoren manuell neu schreiben | KI-Felder erneut vorschlagen klicken — passt sich automatisch an |
| Wenn die IP gesperrt wird | Debuggen, Proxy-Pools rotieren, erneut testen | Cloud-Modus übernimmt die IP-Rotation |
| Export nach Google Sheets | OAuth + pandas-Integration schreiben | Ein Klick, kostenlos |
Wenn du Thunderbit zuerst ausprobierst und es deine Anforderungen erfüllt, kannst du den Rest des Artikels überspringen. Wenn du volle programmatische Kontrolle, individuelle Felder oder Skalierung über ein paar tausend Datensätze pro Monat brauchst — lies weiter.
Python-Bibliotheken fürs Yelp-Scraping: Welche solltest du wählen?
„Soll ich Scrapy, BS4+requests oder Selenium verwenden?“ ist eine der häufigsten Fragen in r/webscraping-Threads zu Yelp. Und doch nimmt fast jedes Tutorial einfach die Lieblingsbibliothek und geht weiter, ohne zu erklären, warum. Hier ist die ehrliche Einordnung.
Die Realität 2025: requests + BeautifulSoup ist für Yelp kaputt
Der Stack, den jedes klassische Yelp-Tutorial empfiehlt — pip install requests beautifulsoup4 — führt 2025 schon beim ersten Request zur Blockierung. Nicht beim 50. Beim ersten.
Der Grund: Die Python-requests-Bibliothek bringt einen TLS-/JA3-Fingerprint mit, der zu keinem echten Browser passt. Die Anti-Bot-Schicht von Yelp erkennt das schon auf Ebene des TLS-Handshakes, bevor dein User-Agent-Header überhaupt gelesen wird. Ich habe das mehrfach getestet — frische IP, realistische Header, zufällige Pausen — und trotzdem sofort einen 403 Forbidden mit normalem requests erhalten.
Die Bibliotheks-Matrix
| Bibliothek | Am besten für | JS-fähig? | Anti-Bot? | Lernkurve | Geschwindigkeit |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Sehr gering | Schnell (bis zur Blockade) | |
httpx async + parsel | Groß angelegtes asynchrones Scraping | ❌ | ❌ | Gering | Sehr schnell |
curl_cffi + parsel | Yelp-spezifisch: TLS-Impersonation | ❌ | ✅ TLS/JA3/HTTP2 | Gering | Sehr schnell |
Scrapy 2.14 | Komplette Crawl-Pipelines mit Pagination | Teilweise (via scrapy-playwright) | AutoThrottle, Retry-Middleware | Mittel bis hoch | Schnell |
Selenium 4.43 / Playwright 1.58 | JS-lastige Seiten, CAPTCHA-Workarounds | ✅ | Teilweise | Mittel | Langsam (~10–30 Seiten/Min.) |
| Thunderbit | Nicht-Techniker, schnelle Extraktion | ✅ (Browser) | Integriert (Cloud-Modus) | Sehr gering | Schnell |
Die curl_cffi-Erkenntnis
Die Bibliothek, die meinen Yelp-Scraping-Workflow verändert hat, ist — ein Python-Binding für curl-impersonate. Sie erzeugt exakt denselben TLS-/JA3- und HTTP/2-Fingerprint wie echter Chrome, und die API ist ein Drop-in-Ersatz für requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Diese eine Änderung — from curl_cffi import requests plus impersonate="chrome131" — umgeht Yelps , ohne einen Browser zu starten. In meinen Tests ist das der Unterschied zwischen sofortigen 403s und sauberen 200-Antworten.
Mein empfohlener Stack für Yelp 2025: curl_cffi + parsel + jmespath + Residential Proxies. Wenn du eine vollständige Crawl-Pipeline mit Scheduling brauchst, binde das Ganze in Scrapy 2.14 mit einer curl_cffi-basierten Downloader-Middleware ein.
So richtest du deine Python-Umgebung für Yelp-Scraping ein
- Schwierigkeitsgrad: Mittel
- Benötigte Zeit: ~15 Minuten für die Einrichtung, 1–2 Stunden für einen funktionierenden Scraper
- Was du brauchst: Python 3.10+ (empfohlen: 3.12), ein Terminal und optional einen Anbieter für Residential Proxies
Schritt 1: Virtuelle Umgebung erstellen und Pakete installieren
1python3.12 -m venv .venv
2source .venv/bin/activate # Unter Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasWas die einzelnen Pakete machen:
curl_cffi— sendet HTTP-Requests mit Chromes TLS-Fingerprint (der Anti-Bot-Bypass)parsel— CSS-/XPath-Selektoren zum Parsen von HTML (die gleiche Engine wie Scrapy, nur leichter)jmespath— deklarative JSON-Abfragen (sauberer als verschachtelter Dict-Zugriff für eingebettetes Yelp-JSON)pandas— Datenexport nach CSV/Excel
Optional, aber hilfreich:
1pip install fake-useragent # Hinweis: Repo im April 2026 archiviert, aber noch installierbarSchritt für Schritt: So scrapest du Yelp mit Python
Das ist das Kern-Tutorial. Der wichtigste Hebel für mehr Robustheit: CSS-Selektoren überspringen und stattdessen verstecktes JSON auslesen. Yelp randomisiert seine CSS-Klassennamen beim Build (y-css-14xwok2 in einer Woche, y-css-hcq7b9 in der nächsten), daher bricht jeder Scraper, der darauf fest verdrahtet ist, innerhalb weniger Wochen. Die eingebetteten JSON-Payloads — application/ld+json-Schema und react-root-props — sind dagegen stabil.
Schritt 2: Yelp-Suchergebnisse scrapen
Yelp-Such-URLs folgen einem vorhersehbaren Muster: https://www.yelp.com/search?find_desc={term}&find_loc={location}. Die Suchergebnisdaten liegen in einem <script data-id="react-root-props">-Tag als JSON — nicht in einem CSS-Klassen-Matsch.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Blocked on page {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"No react-root-props found on page {page} — possible soft block")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsDu solltest eine Liste von Dicts mit Firmennamen, URLs, Bewertungen und Review-Anzahlen zurückbekommen. Wenn react-root-props in der Antwort fehlt, hast du eine Block-Seite erwischt — IP wechseln und erneut versuchen.
Der Header Cookie: intl_splash=false ist ein Standard-Workaround für Yelps Länder-Splash-Redirect. Ohne ihn landen Nicht-US-IPs auf einer Splash-Seite, die wie ein Soft-Block aussieht, aber keiner ist.
Schritt 3: Yelp-Unternehmensseiten scrapen
Jede Unternehmens-URL aus den Suchergebnissen führt zu einer Detailseite mit reicheren Daten. Das stabilste Ziel für die Extraktion ist der <script type="application/ld+json">-Block — er enthält strukturierte schema.org-Daten, die Yelp für SEO pflegt und nicht verschleiert.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}Der Wert von meta[name="yelp-biz-id"] ist die kodierte Unternehmens-ID, die du für den Reviews-Endpunkt brauchst. Hol sie dir hier — im nächsten Schritt verwendest du sie.
Schritt 4: Yelp-Reviews mit Pagination scrapen
Hier zeigt sich der Vorteil des Scrapings gegenüber der Fusion API. Yelps interner GraphQL-Batch-Endpunkt liefert vollständige Rezensionstexte, Rezensenteninformationen, Daten, Bewertungen und Vote-Zahlen — all das, was die API nicht herausgibt.
Der Endpunkt lautet https://www.yelp.com/gql/batch und nutzt eine statische documentId für die Operation GetBusinessReviewFeed. Pagination funktioniert über einen base64-kodierten Cursor.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Review fetch failed at offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Zur Extraktion der Reviews die Antwortstruktur durchlaufen
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsJede Seite liefert 10 Reviews. Erhöhe im base64-Cursor den offset, um zu paginieren. Der Parameter sortBy akzeptiert DATE_DESC (neueste zuerst), RATING_ASC, RATING_DESC und weitere.
Schritt 5: Deine gescrapten Yelp-Daten exportieren
1import pandas as pd
2# Angenommen, du hast businesses und reviews bereits gesammelt
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Oder als JSON speichern, wenn du mehr Flexibilität willst
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Für Leser auf dem No-Code-Pfad exportiert Thunderbit dieselben Daten direkt nach Excel, Google Sheets, Airtable oder Notion — ohne pandas und ohne Code zum Schreiben von Dateien.
Das Anti-Blocking-Playbook: So scrapest du Yelp, ohne geblockt zu werden
Dieser Abschnitt ist der eigentliche Grund, warum es diesen Artikel gibt. Yelps Anti-Bot-Maßnahmen sind seit Ende 2024 deutlich härter geworden — kommen alle zum Einsatz. Die meisten bestehenden Guides sind veraltet, weil sie vor dieser Verschärfung geschrieben wurden.
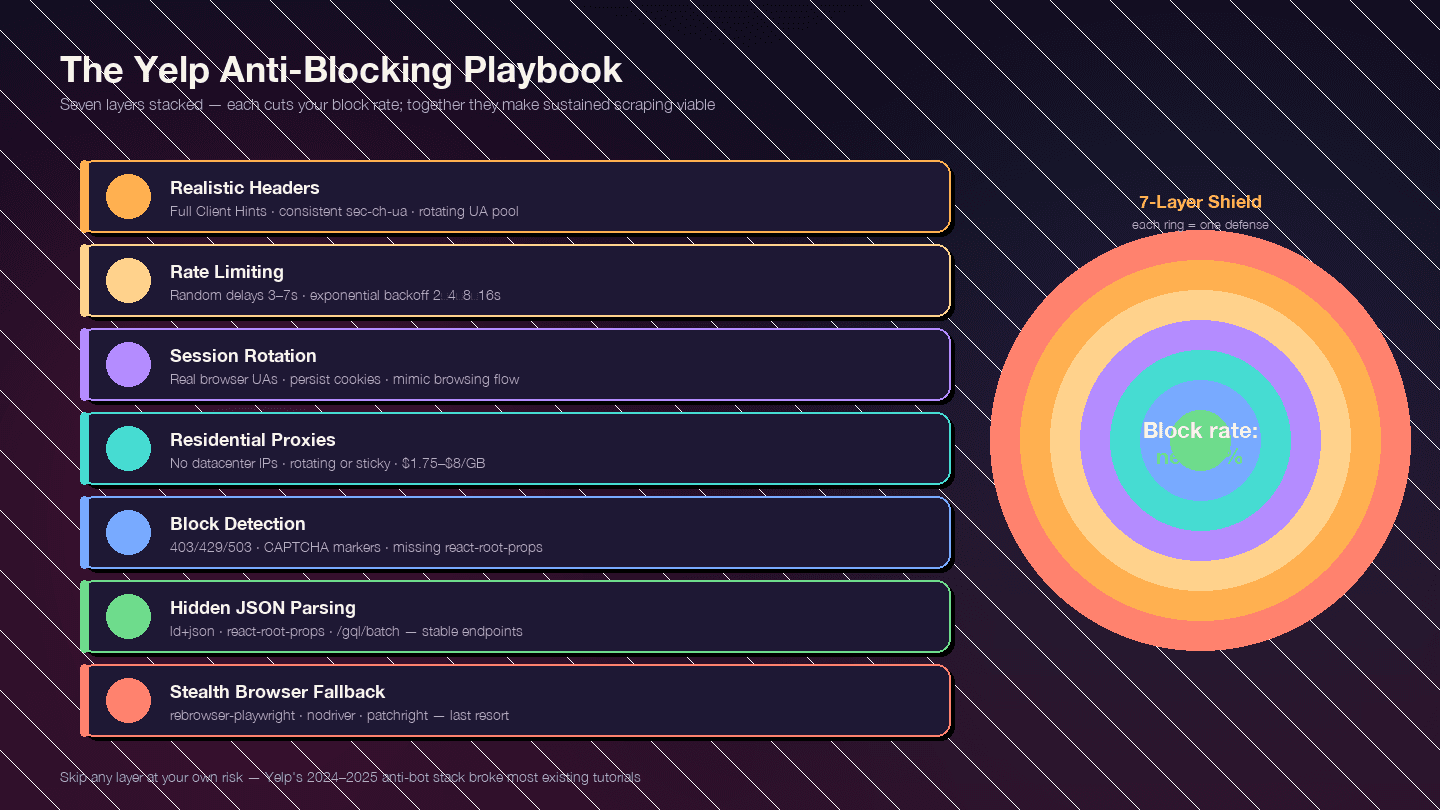
Die Strategie ist mehrschichtig. Jede Ebene senkt deine Blockrate; zusammen machen sie dauerhaftes Scraping erst praktikabel.
Ebene 1: Realistische Request-Header
Die Standard-Header von Python requests senden User-Agent: python-requests/2.x — und werden sofort blockiert. Aber selbst ein realistischer User-Agent reicht nicht. Yelp prüft auch die vollständigen auf Konsistenz.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Drei Fehler, die dich auffliegen lassen:
- Der UA behauptet Chrome, aber
sec-ch-uafehlt oder widerspricht der UA-Version sec-ch-ua-platformsagt „Windows“, obwohl die UA macOS vorgibt- Derselbe UA für Tausende Requests von einer IP — rotiere stattdessen einen Pool aus 10–20 aktuellen Chrome-/Firefox-/Safari-Strings
Ebene 2: Rate-Limiting und Zufallspausen
Vorhersagbare Timing-Muster sind ein Warnsignal. Füge zufällige Schlafintervalle hinzu und implementiere exponentielles Backoff bei Fehlern.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Blocked after {attempt + 1} attempts on {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Got {r.status_code}, backing off {backoff:.1f}s (attempt {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parameter | Empfohlener Wert |
|---|---|
| Zufällige Pause zwischen Requests | random.uniform(3, 7) Sekunden |
| Backoff bei 429/403/503 | 2 → 4 → 8 → 16 s, maximal 5 Versuche |
| Gleichzeitige Worker pro IP | 1 (pro IP serialisieren; für Parallelität Proxies nutzen) |
| Maximale nachhaltige Rate pro Residential IP | ca. 1 Req / 5 s (≈ 12 rpm) |
Ebene 3: User-Agent- und Session-Rotation
Wechsle zwischen realen Browser-User-Agents. Bewahre Sessions und Cookies auf, um echtes Surfverhalten zu imitieren — Yelp nutzt cookie-basierte Erkennung, daher ist es schon verdächtig, für jeden Request eine frische Session zu erzeugen.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Füge 5–10 weitere aktuelle Strings hinzu
8]Ebene 4: Proxy-Rotation
Bei ernsthaftem Volumen brauchst du Residential Proxies. Datacenter- und Free-Proxies funktionieren bei Yelp nicht — Yelps IP-Reputation-Layer blockiert AWS-, GCP- und DigitalOcean-IP-Bereiche präventiv mit 403.
| Anbieter | Einstiegspreis pro GB | Hinweise |
|---|---|---|
| IPRoyal | $1,75/GB | Am günstigsten; betreibt das meistzitierte Yelp-Tutorial |
| Decodo (ehem. Smartproxy) | $3,20–$3,50 | Bestes GB/$-Verhältnis bei größerem Volumen |
| Bright Data | $4,00 (PAYG) | 150M+ IP-Pool; dedizierte Yelp-Proxies-Seite |
| Oxylabs | $6,00–$8,00 | Premium; 10M+ IPs |
| Aluvia (mobile SIM) | $3,00 | Echte US-Mobilfunk-IPs, explizit für Yelp positioniert |
Rotierende Residential Proxies (neue IP pro Request) funktionieren am besten für große Such-Crawls. Sticky Sessions (eine IP für 10 Minuten halten) sind besser, wenn du Cookies über einen Flow von Unternehmensseite → Reviews → Pagination hinweg beibehalten willst.
Ebene 5: Blocks erkennen und behandeln
Nicht jeder Block sieht gleich aus. Yelp liefert oft eine generische „Seite nicht verfügbar“-Hülle statt eines CAPTCHAs aus — deshalb glauben naive Scraper, sie hätten Daten, obwohl sie in Wirklichkeit nur leere Antworten bekommen.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Wenn es sich um eine Such-/Unternehmensseite handelt, aber react-root-props fehlt,
12 # hat Yelp eine abgespeckte Block-Antwort geliefert
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Signal | Bedeutung |
|---|---|
| HTTP 403 | Harter Block — IP/Header/TLS verbrannt |
| HTTP 429 | Rate-Limit — oft mit Backoff behebbar |
| HTTP 503 | Generischer Block oder Lastabwurf |
Weiterleitung zu /error oder Body mit „page not available“ | Weicher Block |
| Leerer mit nur | Challenge-Seite wartet auf JS |
captcha / g-recaptcha / px-captcha im Body | Eskaliert — CAPTCHA erforderlich |
Fehlendes react-root-props auf einer Listing-Seite | Abgespeckte Block-Antwort |
Ebene 6: Der robuste Parsing-Trick — verstecktes JSON statt CSS-Selektoren
Noch einmal, weil es wichtig ist: Yelp randomisiert seine CSS-Klassennamen beim Build. Ein Scraper, der auf h3.y-css-14xwok2 fest verdrahtet ist, bricht innerhalb weniger Wochen, sobald Yelp mit h3.y-css-hcq7b9 neu ausrollt.
Die Payloads, die sich nicht ändern:
<script type="application/ld+json">— strukturierte schema.org-Daten (Name, Adresse, Telefon, Bewertung, Öffnungszeiten)<script data-id="react-root-props">— vollständige Suchergebnisse als JSONhttps://www.yelp.com/gql/batch— GraphQL-Reviews-Endpunkt mit stabilerdocumentId
Wenn du CSS-Klassen parsest, baust du auf Sand. Parse stattdessen das JSON.
Ebene 7: Der Stealth-Browser als Fallback
Greife nur dann auf einen Headless-Browser zurück, wenn curl_cffi + Residential Proxies nicht durchkommen — typischerweise dann, wenn Yelp eine JavaScript-Challenge-Seite oder ein CAPTCHA ausliefert.
Für 95 % der Business-/Search-/Review-Extraktionen sind curl_cffi + verstecktes JSON + Residential Proxies schneller, günstiger und zuverlässiger als ein Browser. Wenn du aber wirklich einen Browser brauchst:
| Tool | Status (2025) | Hinweise |
|---|---|---|
| rebrowser-playwright | Empfohlener Einstieg | Drop-in-Playwright mit Patches gegen CDP-Leaks |
| nodriver | Best-in-Class für Chrome-Stealth | Nachfolger von undetected-chromedriver; umgeht das WebDriver-Protokoll komplett |
| patchright | Aktiv gepflegter Playwright-Fork | Besteht moderne Detection-Tests |
| playwright-stealth | Ausgereift | Patcht navigator.webdriver, entfernt HeadlessChrome aus dem UA |
Verzichte bei Yelp auf normales Selenium. Es ist zu leicht zu fingerprinten.
Yelp Fusion API vs. Python Scraping vs. Thunderbit: Vollständiger Vergleich
| Dimension | Yelp Fusion API | Python Scraping | Thunderbit |
|---|---|---|---|
| Vollständiger Rezensionstext | ❌ 3 Auszüge × ~160 Zeichen | ✅ Unbegrenzt (GraphQL) | ✅ Integrierte Review-Vorlage |
| Review-Metadaten (Votes, Antworten des Betreibers) | ❌ | ✅ | ✅ Über KI-vorgeschlagene Felder |
| Fotos | ❌ (0 im Base-Tarif) | ✅ Unbegrenzt | ✅ |
| Max. Ergebnisse pro Suche | 240 (vor 2024 waren es 1.000) | Unbegrenzt (paginiert) | Unbegrenzt |
| Tägliches Rate Limit | 300–500 (neu) / 5.000 (Legacy) | Nur durch Proxy-Budget begrenzt | Credit-basiert (3.000/Monat im Pro-Tarif) |
| Einrichtungsaufwand | ~15 Min. | Stunden bis Tage | ~2 Min. |
| Anti-Bot-Handling | N/A | Dein Problem | Abgedeckt (Cloud-Modus) |
| Rechtliches Risiko | Niedrig (autorisiert) | Mittel (ToS-Graubereich) | Mittel (gleich wie Scraping) |
| Kosten (Einstieg) | Ab $29/Monat | ~ $0,75–$4/GB für Proxies + Entwicklungszeit | Kostenloser Tarif |
| Kosten bei hoher Nutzung | $643+/Monat | $50–$500/Monat für Proxies + Entwicklungszeit | $38–$49/Monat |
| Datenexport | JSON | CSV/JSON (musst du selbst bauen) | Excel / Sheets / Airtable / Notion — kostenlos |
| Wartung | Niedrig | Hoch (Selektoren brechen, Anti-Bot wird härter) | Niedrig (KI passt sich neu an) |
Rechtliche und ethische Hinweise zum Scraping von Yelp
Ich bin kein Anwalt, und das ist keine Rechtsberatung. Aber die rechtliche Lage hat sich in den letzten zwei Jahren so deutlich verschoben, dass du die Grundlagen kennen solltest, bevor du Zeit in ein Yelp-Scraping-Projekt investierst.
Was die Yelp-Nutzungsbedingungen sagen: Das verbietet ausdrücklich die Verwendung von „Robots, Spider ... oder anderen automatisierten Mitteln“, um „Teile des Dienstes zuzugreifen, abzurufen, zu kopieren, zu scrapen oder zu indexieren“. Neu hinzugekommen ist außerdem eine Formulierung zu „AI Technologies und/oder anderen automatisierten Tools“.
Der : „Yelp erlaubt kein Scraping der Website.“
Was die robots.txt sagt: Yelps enthält ein generelles User-agent: * / Disallow: / und blockiert ausdrücklich GPTBot, ClaudeBot, PerplexityBot, CCBot und Meta-ExternalAgent. Nur Googlebot, Bingbot und einige Social-Media-Crawler sind freigegeben.
Der relevante Rechtspräzedenzfall: In (N.D. Cal., Jan. 2024) entschied das Gericht, dass das Scraping öffentlich zugänglicher, ausgeloggter Daten nicht gegen die Nutzungsbedingungen von Meta verstieß. Der entscheidende Unterschied: öffentlich zugängliche, ausgeloggte Daten vs. eingeloggte Daten. Der Fall zeigte, dass Scraping öffentlich zugänglicher Daten wahrscheinlich nicht gegen den CFAA verstößt, aber hiQ verlor dennoch bei zivilrechtlichen Ansprüchen nach Landesrecht (trespass to chattels, misappropriation) und erhielt ein Urteil über 500.000 US-Dollar.
Praktische Leitlinien:
- Scrape nur öffentlich zugängliche, ausgeloggte Seiten
- Rate-Limit für Requests einhalten (die Verzögerungen in diesem Leitfaden sind zugleich ethische Limits)
- Rohe Review-Texte nicht mit Klarnamen weiterverkaufen — respektiere die Privatsphäre der Rezensenten
- Lokale Datenschutzgesetze einhalten (CCPA, GDPR)
- Nicht zum Scrapen einloggen — damit überschreitest du die Autorisierungslinie
- Behandle Unternehmensdaten (Name/Adresse/Telefon/Bewertung) als öffentliche Faktendaten; Review-Texte sind sensibler
Zieh für deine konkrete Situation eine juristische Fachperson hinzu.
Fazit
Drei Wege, ein Ziel.
Die Yelp Fusion API ist die autorisierte, wartungsarme Option — aber sie begrenzt dich auf 3 Review-Auszüge und startet bei 29 US-Dollar im Monat. Python Scraping gibt dir die volle Kontrolle über jeden Datenpunkt auf Yelp, erfordert aber echte Investitionen: curl_cffi für TLS-Impersonation, Residential Proxies, Zufallspausen, Parsing von verstecktem JSON und laufende Wartung, wenn Yelps Abwehrmechanismen sich weiterentwickeln. Thunderbit bringt dich in etwa 30 Sekunden von „Ich brauche Yelp-Daten“ zu „Hier ist meine Tabelle“ — ohne Code und ohne Proxy-Konfiguration.
Die Anti-Block-Grundlagen, die 2025 tatsächlich funktionieren: realistische Header mit vollständigen Client Hints, curl_cffi für TLS-Fingerprint-Impersonation, zufällige Verzögerungen mit exponentiellem Backoff, Rotation von Residential Proxies und — vor allem — das Parsen von verstecktem JSON (application/ld+json und react-root-props) statt fragiler CSS-Selektoren.
Unsicher, welcher Weg passt? Probiere zuerst die . Wenn sie deine Anforderungen abdeckt, sparst du dir Stunden. Wenn du mehr Kontrolle brauchst — vollständige programmatische Pipelines, individuelle Felder, enge CRM-Integration — hilft dir der Python-Leitfaden oben weiter. Und für einen tieferen Blick auf die Landschaft der Scraping-Tools schau dir unseren Überblick über die oder unseren Leitfaden zum an.
FAQs
Kann ich Yelp mit Python kostenlos scrapen?
Ja — mit kostenlosen Bibliotheken wie curl_cffi, parsel und jmespath. Bei realem Volumen (mehr als ein paar Dutzend Seiten) brauchst du jedoch kostenpflichtige Residential Proxies, die laut starten. Thunderbit bietet außerdem einen kostenlosen Tarif mit 6 Seiten pro Monat für schnelle No-Code-Extraktion.
Blockiert Yelp Scraper?
Ja, sehr aggressiv. Yelp nutzt . Normales requests wird sofort beim ersten Treffer geblockt. Die mehrschichtige Anti-Block-Strategie in diesem Leitfaden — curl_cffi für TLS-Impersonation, realistische Header, zufällige Pausen und Residential Proxies — ist das, was 2025 funktioniert.
Ist die Yelp Fusion API besser als Scraping?
Kommt auf deinen Bedarf an. Die API ist autorisiert und risikoarm, liefert aber nur , begrenzt Suchergebnisse auf 240 und startet bei 29 US-Dollar pro Monat. Wenn du vollständige Rezensionstexte, Review-Metadaten oder mehr als ein paar hundert Datensätze pro Tag brauchst, bleibt Scraping die einzige Option.
Wie scrape ich Yelp-Reviews mit Python?
Verwende curl_cffi mit impersonate="chrome131", um die Unternehmensseite abzurufen, zieh dann die kodierte Unternehmens-ID aus <meta name="yelp-biz-id"> und sende anschließend einen POST an https://www.yelp.com/gql/batch mit der Operation GetBusinessReviewFeed. Pagination läuft über einen base64-kodierten after-Cursor. Der Schritt-für-Schritt-Code steht oben im Tutorial-Abschnitt. Das ist ebenfalls eine solide Referenzimplementierung.
Kann ich Yelp ohne Programmieren scrapen?
Ja — bringt vorgefertigte Vorlagen für und mit. Yelp-Seite öffnen, auf KI-Felder vorschlagen klicken, dann auf Scrape. Exporte nach Google Sheets, Excel, Airtable und Notion sind in jedem Tarif kostenlos, auch im Gratisplan.
Mehr erfahren