Walmart ändert bei manchen Artikeln die Preise. Wer das schon einmal programmatisch nachverfolgen wollte, kennt das Problem: Das Skript läuft 20 Minuten lang problemlos und liefert dann plötzlich still und heimlich CAPTCHA-Seiten zurück, die sich als normale 200-OK-Antworten tarnen.
Ich habe bei unserer Arbeit an der Datenerfassung bei viel Zeit damit verbracht, mich durch Walmarts Anti-Bot-Verteidigung zu arbeiten, und möchte alles teilen, was ich gelernt habe — die Methoden, die 2025 tatsächlich funktionieren, die stillen Fehler, die Daten unbrauchbar machen, und die ehrlichen Abwägungen zwischen einem eigenen Scraper, einer Scraping-API und einem No-Code-Tool. Dieser Leitfaden behandelt drei Extraktionsmethoden (HTML-Parsing, __NEXT_DATA__-JSON und das Abfangen interner APIs), produktionsreife Fehlerbehandlung, die die meisten Tutorials komplett auslassen, sowie einen nüchternen Entscheidungsrahmen für die richtige Vorgehensweise. Egal, ob du in Python codest oder einfach nur bis zum Mittag eine Tabelle mit Preisen haben willst, hier ist etwas für dich.
Warum Walmart mit Python scrapen?
Walmart ist gemessen am Umsatz der größte Einzelhändler der Welt — im Geschäftsjahr 2025 und seit . Die Website beherbergt rund , und Walmarts CFO spricht von auf dem Marktplatz. Etwa , was den Katalog extrem dynamisch macht — Verkäufer wechseln, Varianten ändern sich und der Bestand kippt täglich.
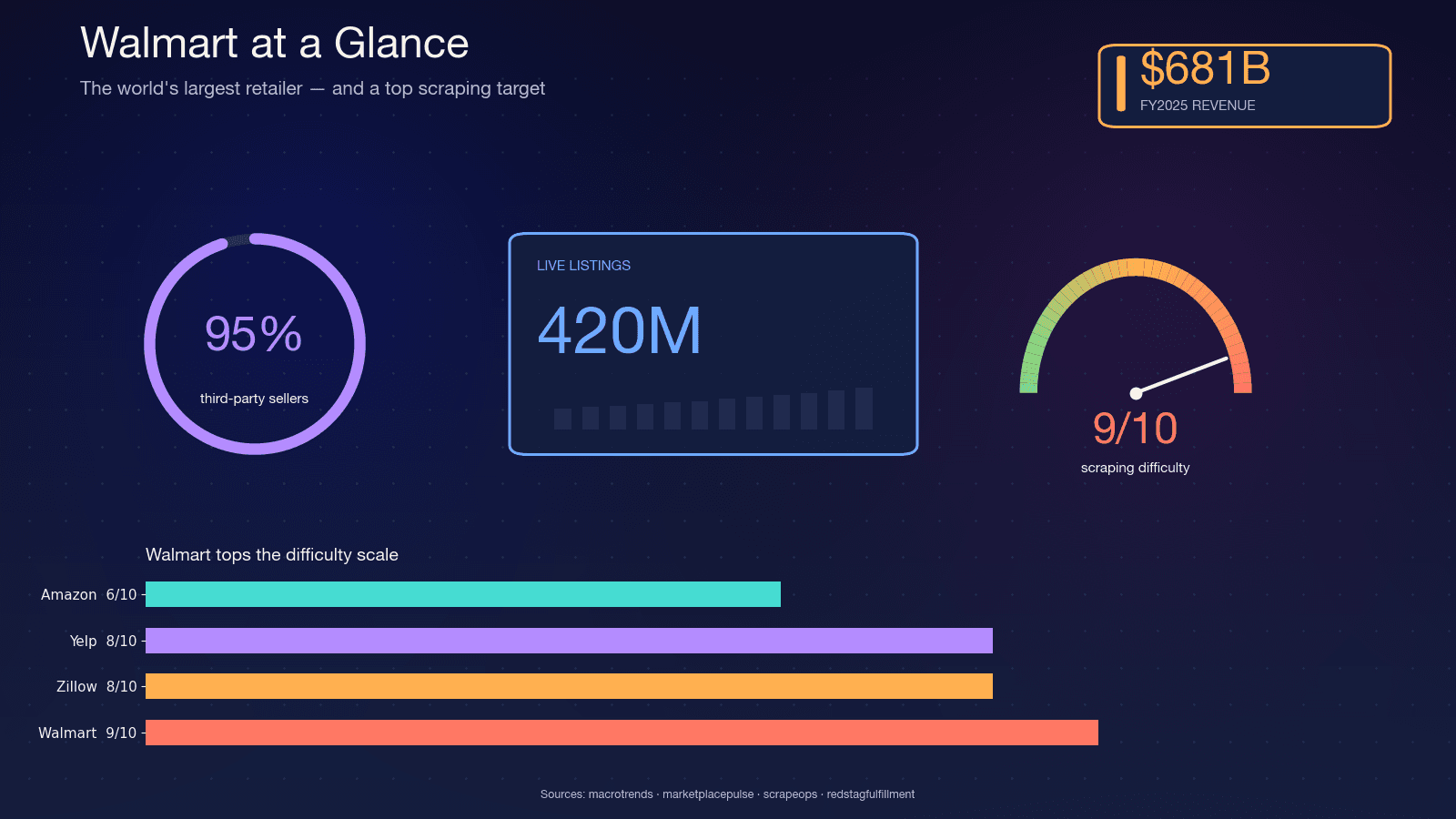
Genau diese Dynamik macht Scraping so wichtig. Ein Quartalsbericht kann nicht das erfassen, was ein nächtlicher Scrape liefert. Hier sind die häufigsten Anwendungsfälle, die ich sehe:
| Anwendungsfall | Wer ihn braucht | Was extrahiert wird |
|---|---|---|
| Wettbewerbs-Preisüberwachung | E-Commerce-Teams, Repricing-Tools | Preise, Aktionen, MAP-Compliance |
| Anreicherung des Produktkatalogs | Vertriebs- und Merchandising-Teams | Beschreibungen, Bilder, Spezifikationen, Varianten |
| Lagerbestands-Tracking | Lieferkette, Dropshipper | Bestandsstatus, Verkäuferinformationen |
| Marktforschung & Trendanalyse | Marketing, Produktmanager | Bewertungen, Rezensionen, Kategoriesortiment |
| Lead-Generierung | Vertriebsteams | Verkäufernamen, Produktanzahl, Kategorien |
Der und soll bis 2033 auf 5,09 Milliarden US-Dollar wachsen. Das Verbraucherverhalten treibt die Ausgaben: , und 83 % vergleichen auf mehreren Websites.
Python ist die Standard-Sprache für diese Arbeit. Apifys Infrastructure Report 2026 beziffert , und die Kernbibliothek (requests) wird . Wer in irgendeinem Umfang scraped, macht das mit ziemlich hoher Wahrscheinlichkeit in Python.
Warum Walmart eine der schwersten Websites zum Scrapen ist
Walmart ist besonders schwierig, weil zwei kommerzielle Anti-Bot-Produkte hintereinander geschaltet sind: als Edge-WAF- und TLS-Fingerprinting-Schicht sowie als verhaltensbasierte JavaScript-Challenge-Schicht. Scrape.do nennt diese Kombination „selten und extrem schwer zu umgehen“.
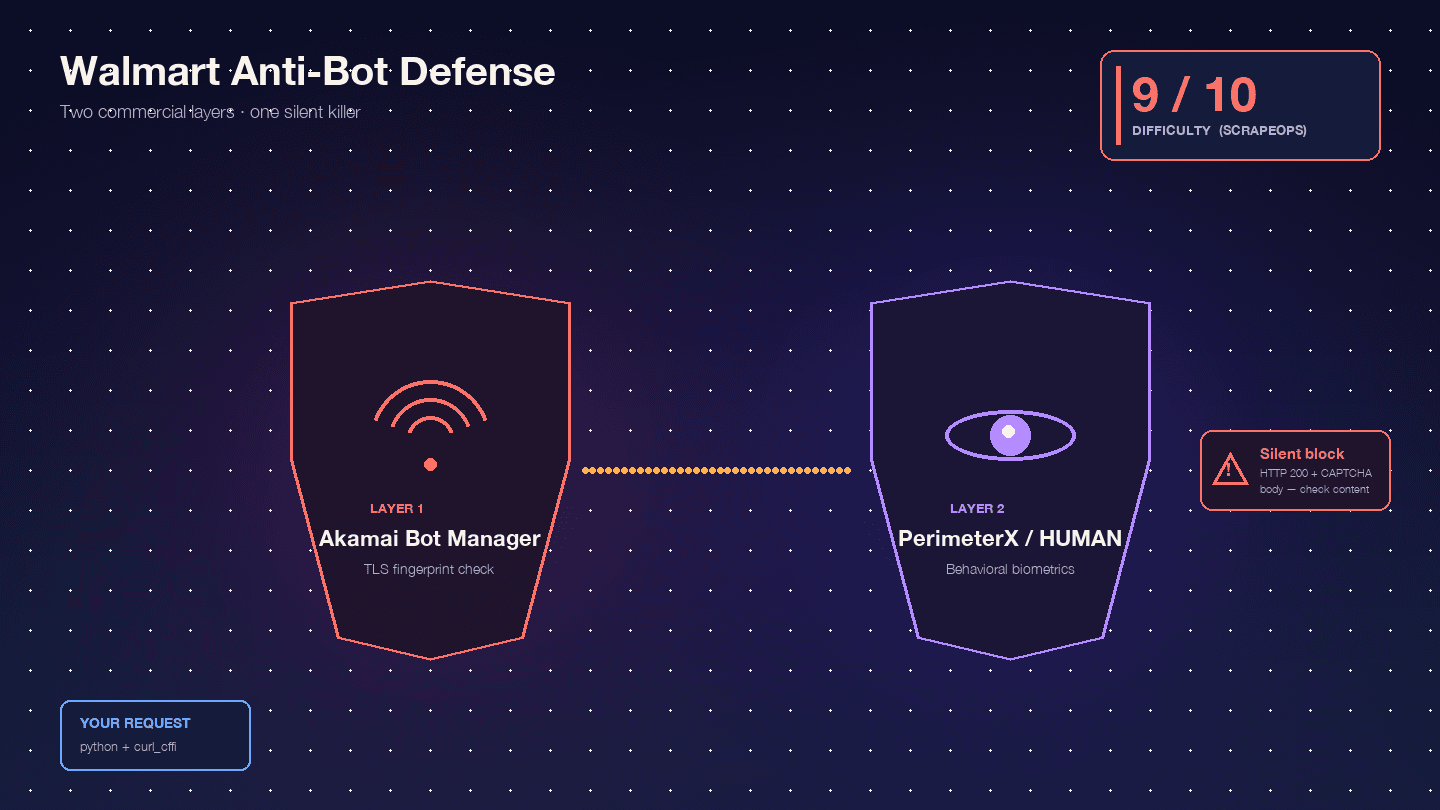
, wobei allein Akamai bei 9/10 liegt. Nach meiner Erfahrung passt das ziemlich gut.
Das ist die echte Gegenwehr:
Akamai Bot Manager prüft dein TLS-Fingerprinting (JA3/JA4-Hash), die HTTP/2-Frame-Reihenfolge, Header-Reihenfolge und Groß-/Kleinschreibung sowie Sitzungscookies (_abck, ak_bmsc). Ein gewöhnlicher Python-requests-Aufruf sendet einen TLS-Fingerprint, den kein echter Browser erzeugt — Akamai blockiert ihn, bevor deine Anfrage überhaupt Walmarts Server erreicht.
PerimeterX/HUMAN läuft nach Akamai und führt JavaScript-Fingerprinting (px.js) aus, das Navigator-Eigenschaften, Canvas-Rendering, WebGL, Audio-Kontext und Verhaltensbiometrie (Mausbewegungen, Scrollgeschwindigkeit, Tastenanschläge) prüft. Das sichtbare Scheitern ist die berüchtigte — ein Button, den du etwa 10 Sekunden gedrückt halten musst, während Verhaltenssignale gemessen werden. Oxylabs sagt es offen: „Walmart verwendet das ‚Press & Hold‘-CAPTCHA-Modell von PerimeterX, das bekanntermaßen nahezu unmöglich per Code zu lösen ist.“
Wirklich gefährlich ist das stille Blockieren. Walmart liefert HTTP 200 mit einem CAPTCHA-Body statt eines 403 zurück. : „Walmart gibt einen 200-OK-Statuscode zurück, selbst wenn eine CAPTCHA-Seite ausgeliefert wird. Man kann sich nicht allein auf den Statuscode verlassen, um zu wissen, ob die Anfrage erfolgreich war.“ Dein Skript parst das CAPTCHA-HTML fröhlich als „Produkt nicht gefunden“ und macht weiter. Die Hälfte deines Datensatzes ist Müll, und du merkst es nicht.
Dazu kommt das store-gebundene Datenthema. Walmarts Preise und Bestände hängen vom Standort ab und werden durch Cookies wie locDataV3 und assortmentStoreId gesteuert. Ohne die richtigen Cookies erhältst du „standardmäßige nationale“ Daten, die vollständig aussehen, aber nicht dem entsprechen, was echte Käufer sehen. Fehlende Cookies erzeugen keine Blockseite — sie erzeugen falsche Daten ohne sichtbaren Fehler, und das ist noch schlimmer.
Drei Methoden, um Daten von Walmart zu extrahieren (und wie sie sich vergleichen)
Vor der Schritt-für-Schritt-Anleitung hier die drei wichtigsten Extraktionsansätze. Die meisten Konkurrenz-Tutorials behandeln nur einen oder zwei. Ich gehe alle drei durch, damit du den passenden für deine Situation wählen kannst.
| Methode | Zuverlässigkeit | Vollständigkeit der Daten | Schwierigkeit für Anti-Bot | Wartungsaufwand |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Niedrig (Selektoren brechen bei jedem Deploy) | Mittel | Hoch | Hoch |
__NEXT_DATA__-JSON | ✅ Gut | Hoch | Mittel bis hoch | Mittel |
| Abfangen interner API-Aufrufe | ✅ Am besten | Höchste (Varianten, Bestand, Bewertungen) | Mittel bis hoch | Niedrig (strukturiertes JSON) |
| Thunderbit (No-Code) | ✅ Gut | Hoch | Niedrig (von KI übernommen) | Keine |
HTML-Parsing ist für Walmart die schlechteste Wahl — die Seite liefert Next.js-Bundles mit gehashten CSS-Klassennamen aus, die sich bei jedem Deploy ändern. Die __NEXT_DATA__-JSON-Methode ist die pragmatische Wahl, die jeder ernsthafte Open-Source-Walmart-Scraper von 2024–2026 nutzt. Das Abfangen interner APIs ist am leistungsfähigsten, bringt aber Vorbehalte mit sich, über die die meisten Tutorials hinweggehen. Und Thunderbit ist die richtige Wahl, wenn du überhaupt keine eigene Pipeline brauchst.
Deine Python-Umgebung für Walmart-Scraping einrichten
Das brauchst du:
- Schwierigkeit: Mittel
- Benötigte Zeit: ca. 30 Minuten für das Setup, plus Entwicklungszeit
- Was du brauchst: Python 3.10+, pip, einen Code-Editor und (für den produktiven Einsatz) einen Proxy-Dienst oder eine Scraping-API
Erstelle deinen Projektordner und deine virtuelle Umgebung:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # Unter Windows: venv\Scripts\activateInstalliere die benötigten Bibliotheken:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi ist 2025 der Standard für schwierige Ziele. Es ist ein libcurl-Binding, das exakte Browser-TLS-Fingerprints imitieren kann. : „Walmart verwendet TLS-Fingerprinting als Teil seiner Bot-Erkennung, und selbst das Setzen des User-Agent, um einen echten Browser zu simulieren, umgeht das nicht.“ Einfaches requests oder httpx kommt unabhängig von den gesetzten Headern nicht an Akamai vorbei. curl_cffi mit impersonate="chrome124" macht den Unterschied.
Außerdem brauchst du später für die produktionsreifen Muster noch json (integriert), csv (integriert), time, random und logging.
Schritt für Schritt: Walmart-Produktseiten mit Python scrapen
Schritt 1: Die Walmart-Produktseite abrufen
Deine erste Aufgabe ist eine HTTP-Anfrage, die nicht sofort blockiert wird. Hier ist der kanonische Header-Satz, der 2024–2026 bei Scrapfly, Scrapingdog, Oxylabs und ScrapeOps verwendet wird:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)Der Parameter impersonate="chrome124" übernimmt hier die Schwerarbeit. Er sagt curl_cffi, dass es Chromes exakten TLS ClientHello von Version 124, die HTTP/2-Frame-Reihenfolge und die Pseudo-Header-Sequenz nachbilden soll. Ohne ihn sieht Akamai einen Python-spezifischen JA3-Hash und blockiert dich, bevor deine Anfrage überhaupt die Anwendungsschicht von Walmart erreicht.
So sieht eine blockierte Antwort aus: Wenn du "Robot or human?" im HTML-Titel der Antwort siehst oder die Antwort zu walmart.com/blocked weiterleitet, wurdest du erwischt. Der Haken: Walmart liefert oft einen 200-Statuscode mit dem CAPTCHA-Body zurück — deshalb reicht es nicht aus, nur response.ok zu prüfen.
Für jeden produktiven oder wiederholten Einsatz brauchst du Residential Proxies. Rechenzentrums-IPs werden vom IP-Reputationssystem von Akamai sofort verbrannt. Ich gehe unten im Produktionsabschnitt auf die komplette Fehlerbehandlung und Proxy-Strategie ein.
Schritt 2: Produktdaten aus der __NEXT_DATA__-JSON parsen
Walmart.com ist eine Next.js-Anwendung, und das serverseitig gerenderte HTML bettet die komplette Hydration-Payload in ein einziges Script-Tag ein: <script id="__NEXT_DATA__" type="application/json">. Das ist die Goldgrube.
: „Im Jahr 2026 verwendet Walmart Next.js mit strukturiertem JSON in __NEXT_DATA__-Script-Tags, wodurch die Extraktion versteckter Daten zuverlässiger ist als das klassische CSS-Selector-Parsing.“ Jeder prominente Open-Source-Walmart-Scraper — , , — nutzt diese Methode.
So extrahierst du die Daten:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})Die meisten Tutorials hören hier auf. Unten findest du eine vollständige JSON-Pfadkarte für die Felder, die dich wirklich interessieren — verifiziert anhand live laufender Walmart-Seiten von 2024–2026:
| Datenfeld | JSON-Pfad (unter initialData) | Typ | Hinweise |
|---|---|---|---|
| Produktname | data > product > name | String | — |
| Marke | data > product > brand | String | — |
| Aktueller Preis (Zahl) | data > product > priceInfo > currentPrice > price | Float | Kann je nach Store-Cookie abweichen |
| Aktueller Preis (String) | data > product > priceInfo > currentPrice > priceString | String | Formatiert, z. B. "$9.99" |
| Kurzbeschreibung | data > product > shortDescription | HTML-String | Mit BeautifulSoup in Text umwandeln |
| Lange Beschreibung | data > idml > longDescription | HTML-String | Liegt auf idml, NICHT in product — genau hier irren ältere Tutorials |
| Alle Bilder | data > product > imageInfo > allImages | Array | Liste von {id, url}-Objekten |
| Durchschnittliche Bewertung | data > product > averageRating | Float | Der Schlüssel heißt averageRating, nicht das ältere rating |
| Anzahl der Bewertungen | data > product > numberOfReviews | Integer | — |
| Varianten | data > product > variantCriteria | Array | Optionsgruppen (Größe, Farbe) |
| Verfügbarkeit | data > product > availabilityStatus | String | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Verkäufer | data > product > sellerDisplayName | String | — |
| Hersteller | data > product > manufacturerName | String | — |
Der Pfad longDescription ist die eine Falle, in die viele tappen. Ein ScrapeHero-Beitrag von 2023 setzte ihn unter product.longDescription, aber Quellen ab 2024 legen ihn konsistent auf den Schwester-Schlüssel idml. Lies immer zuerst idml.longDescription und falle bei älteren Seiten auf product.longDescription zurück.
Hier ist das sichere Extraktionsmuster mit .get()-Ketten:
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Für Nutzer, die sich gar nicht mit JSON-Pfadnavigation befassen möchten, identifiziert und strukturiert diese Felder automatisch — ganz ohne manuelles Mapping. Du klickst auf „KI-Felder vorschlagen“, die Seite wird gelesen und du bekommst eine Tabelle. Wenn du aber eine eigene Pipeline baust, ist die obige Karte deine Referenz.
Schritt 3: Walmarts interne API-Endpunkte für reichhaltigere Daten abfangen
Kein Konkurrenzartikel behandelt diese Methode richtig. Es ist der leistungsstärkste Extraktionsweg — und der komplizierteste.
Walmarts Frontend ruft ein auf. Die Endpunkte liegen unter www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— Produktdetail-Hydration + Variantenwechsel/orchestra/snb/graphql/...— Such- und Browse-Paginierung/orchestra/reviews/graphql/...— paginierte Bewertungen
Diese Endpunkte liefern sauberes, strukturiertes JSON mit Daten, die __NEXT_DATA__ manchmal abschneidet — Variantenpreise, Echtzeit-Bestände, vollständige Review-Paginierung.
Der Haken, um den sich Blogposts herumdrücken: Walmart nutzt . Im Request-Body wird nur ein SHA-256-Hash (persistedQuery.sha256Hash) gesendet, nicht der Query-Text. Ist der Hash dem Server unbekannt, bekommst du PersistedQueryNotFound. Walmart rotiert diese Hashes bei Deployments. Deshalb veröffentlichen keine der bekannten Open-Source-Walmart-Scraper direkt kopierbaren /orchestra/-Code.
Die praktische, ehrliche Version dieser Methode ist eine DevTools-Übung:
- Öffne eine Walmart-Produktseite in Chrome
- Öffne DevTools → Reiter „Network“, filtere nach „Fetch/XHR“
- Nutze die Seite ganz normal — klicke auf Varianten, scrolle zu den Bewertungen, ändere den Store-Standort
- Achte auf Anfragen an
/orchestra/*-Endpunkte, die JSON mit Produktdaten zurückgeben - Rechtsklick auf die Anfrage → „Copy as cURL“
- Wandle den cURL-Befehl mit
curl_cffiin Python um
So sieht ein wiedergegebenes API-Call aus:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Zuerst die Sitzung durch einen Besuch der Produktseite aufwärmen
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Dann den internen API-Aufruf wiedergeben (aus DevTools kopiert)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Den exakten Request-Body aus DevTools einfügen
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()Der Schritt zum Aufwärmen der Sitzung ist entscheidend. Walmarts PerimeterX-Cookies (_px3, _pxhd, ACID) müssen durch den ersten HTML-Abruf gesetzt werden, bevor der API-Aufruf funktioniert. Ohne sie erhältst du ein 412 oder 403.
Wann diese Methode sinnvoll ist: Wenn du Daten brauchst, die __NEXT_DATA__ nicht enthält — tiefe Variantenpreise, paginierte Bewertungen über den ersten Batch hinaus oder Echtzeit-Bestandszahlen. Für die meisten Anwendungsfälle reicht __NEXT_DATA__ und ist deutlich einfacher.
Walmart-Suchergebnisse und mehrere Seiten scrapen
Suchergebnisse folgen einem ähnlichen __NEXT_DATA__-Muster, aber mit einem anderen JSON-Pfad:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Gesponserte Produkte herausfiltern
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))Die Paginierung funktioniert, indem der page-Parameter erhöht wird: &page=1, &page=2 usw. Es gibt aber eine undokumentierte Begrenzung: Walmart beschränkt Suchergebnisse unabhängig von der tatsächlichen Gesamtzahl auf 25 Seiten. : „Walmart setzt die maximale Anzahl zugänglicher Ergebnis-Seiten auf 25 fest, unabhängig von der Gesamtzahl verfügbarer Seiten.“
Um tiefer zu kommen, helfen diese Umgehungen:
- Sortierreihenfolge wechseln: Führe dieselbe Suche mit
&sort=price_lowund anschließend mit&sort=price_highaus, um etwa 50 Seiten Abdeckung zu erhalten - Preisbereich aufteilen: Ergänze
&min_price=X&max_price=Y, um den Katalog in kleinere Fenster zu zerlegen - Kategorien aufteilen: Suche innerhalb konkreter Kategorien statt auf der gesamten Website
Beachte, dass itemStacks ein Array ist. Scrapfly verwendet in seinem Repo hart codiert [0], aber Kategorie- und Browse-Seiten enthalten manchmal mehrere Stacks („Top Picks“, „Weitere Ergebnisse“). Das robuste Muster iteriert über alle Stacks:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # Artikel verarbeiten
5 passAuch wichtig: Walmarts robots.txt . Produktdetailseiten (/ip/...) und die meisten Kategorieseiten (/cp/...) sind nicht verboten. Wenn dir Compliance wichtig ist, beginne mit Produktseiten und Kategoriestrukturen statt mit der Suche.
Lass stille Blocks nicht deine Daten ruinieren: produktionsreife Fehlerbehandlung
Die meisten Tutorials scheitern genau hier. Sie zeigen dir, wie du eine Seite abrufst, ein Produkt parst und es dabei belässt. In der Produktion rufst du Tausende von Seiten ab, und Walmart versucht aktiv, dich zu stoppen. Der Unterschied zwischen einem Demo-Scraper und einem Scraper, der wirklich funktioniert, liegt darin, wie er mit Fehlern umgeht.
Stille Blocks erkennen, bevor sie deine Daten verfälschen
Die wichtigste Funktion in einem Walmart-Scraper ist der Block-Detektor. Basierend auf dem Konsens der Anbieter , , und brauchst du vier unabhängige Prüfungen:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Weiterleitung zum dedizierten Block-Endpunkt
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Harte Statuscodes
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK mit CAPTCHA-Body (der stille-Block-Fall)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Plausibilitätscheck der Antwortlänge — echte PDPs sind 300–900 KB groß
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseDiese vierte Prüfung — die Antwortlänge — fängt die Fälle ab, in denen Walmart eine abgespeckte Seite liefert, die weder offensichtliche CAPTCHA-Marker noch die Produktdaten enthält, die du brauchst.
Wiederholungslogik mit exponentiellem Backoff und Jitter
Wenn eine Anfrage fehlschlägt, solltest du Walmart nicht sofort erneut bombardieren. Das Standardmuster nutzt exponentiellen Backoff mit Jitter, um Wiederholungen zu entkoppeln:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Throttled: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Stiller Block erkannt")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"Versuch {attempt + 1} fehlgeschlagen: \{e\}. Erneuter Versuch in {wait:.1f} s")
20 time.sleep(wait)
21 return NoneDer Jitter (random.uniform(0, 3)) ist nicht nur Kosmetik — er entkoppelt Worker, damit ein Scraper-Verbund nicht im selben Sekundenfenster erneut feuert und Akamais Geschwindigkeitsdetektoren auslöst.
Rate-Limiting
Sowohl als auch empfehlen für Walmart eine zufällige Verzögerung von 3–6 Sekunden pro Anfrage: „Drossele deine Anfragen, indem du zwischen Seitenaufrufen 3–6 Sekunden wartest und die Verzögerungen randomisierst.“
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseBei größerem Umfang solltest du für asynchrone Rate-Limits aiolimiter in Betracht ziehen:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 Anfragen pro MinuteDatenvalidierung
Selbst wenn die Antwort nicht blockiert ist, können die geparsten Daten falsch sein (falscher Store, degradiertes Payload). Validieren, bevor du in die Ausgabe schreibst:
1def validate_product(product):
2 """Gibt True zurück, wenn die Produktdaten plausibel aussehen."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueSitzungs-Logging
Verfolge deine Erfolgsquote pro Sitzung. Wenn sie 10 Minuten lang unter 80 % fällt, hat sich etwas geändert — entweder ist deine IP verbrannt, deine Cookies sind abgelaufen oder Walmart hat eine neue Anti-Bot-Regel ausgerollt.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"Erfolgsquote ist auf {self.success_rate:.1f}% gefallen — Proxies rotieren oder pausieren")Nicht glamourös. Aber genau das hält deine Daten sauber.
DIY-Python vs. Scraping-API vs. No-Code: der richtige Weg für Walmart
Viele Entwickler springen direkt in den Bau eines eigenen Scrapers, ohne zu fragen, ob das überhaupt die richtige Entscheidung ist. . Nutzer in Foren beschreiben es als „im Grunde 9/10“ und fragen sich, „ob eine dedizierte Web-Scraping-API nicht übertrieben wäre“. Die Antwort hängt von Volumen, Budget und Engineering-Kapazität ab.
| Faktor | DIY-Python (requests + Proxies) | Scraping-API (Oxylabs, Bright Data usw.) | No-Code-Tool (Thunderbit) |
|---|---|---|---|
| Setup-Zeit bis zur ersten Zeile | Stunden | 15–60 Min. | ~2 Min. |
| Setup-Zeit bis zur Produktion | 40–80 Std. | 4–16 Std. | ~30 Min. |
| Anti-Bot-Behandlung | Du verwaltest sie selbst (schwierig) | Vom Anbieter übernommen | Automatisch übernommen |
| Kosten bei kleinem Umfang (<1K Seiten/Monat) | Niedrig (Proxy-Kosten ca. 4–8 $/GB) | Einstiegstarife 40–49 $/Monat | Kostenlos–15 $/Monat |
| Kosten bei großem Umfang (100K+ Seiten/Monat) | Niedrigere Kosten pro Anfrage | Höhere Kosten pro Anfrage | Variiert |
| Anpassbarkeit | Volle Kontrolle | API-Parameter | Durch UI/Felder begrenzt |
| Laufende Wartung | 4–8 Std./Monat | Nahezu null | Keine (KI passt sich an) |
| Am besten geeignet für | Entwickler mit eigenen Pipelines | Mittelgroßes produktives Scraping | Business-Anwender, schnelle Einmal-Extraktionen |
Wann DIY-Python Sinn ergibt
DIY gewinnt, wenn du bereits einen Proxy-Vertrag hast, strikte Kontrolle über Header, Postleitzahl-Ziele oder Verkäufergruppen brauchst, du Millionen Seiten pro Monat indexierst, bei denen API-Gebühren pro Datensatz sich summieren, oder du On-Premise- bzw. Compliance-Garantien benötigst. Der Preis ist echter Engineering-Aufwand: Ein produktionsreifer Scrapy-Spider mit Paginierung, Retries, Proxy-Rotation, TLS-Impersonation und mehreren Seitentyp-Schemata braucht , plus 4–8 Stunden Wartung pro Monat, wenn Walmart Fingerprints ändert.
Wann eine Scraping-API dir Zeit spart
Scraping-APIs übernehmen die Anti-Bot-Schicht, damit du es nicht musst. zeigen Erfolgsraten von und 98 % für Scrape.do bei Walmart. Die Einstiegspreise liegen bei 40–49 $/Monat für Tools wie , und . Wenn ihr ein Team aus 2–5 Entwicklern seid und euer Scraping-Volumen zwischen 10K und 1M Seiten pro Monat liegt, ist eine API fast immer die richtige Wahl. Du tauschst Kosten pro Anfrage gegen null Wartungsaufwand.
Wann No-Code die richtige Wahl ist
passt zu einem ganz anderen Profil. Wenn du PM, Analyst oder E-Commerce-Operator bist und heute Nachmittag Walmart-Produktdaten in einer Tabelle brauchst — nicht erst im nächsten Sprint — dann ist ein No-Code-Tool die ehrliche Antwort.
Der Ablauf: Installiere die , öffne eine Walmart-Produkt- oder Suchseite, klicke auf „KI-Felder vorschlagen“, und Thunderbits KI liest die Seite und schlägt Spalten vor (Produktname, Preis, Bewertung usw.). Klicke auf „Scrapen“, und die Daten werden in eine Tabelle übernommen. Export nach Excel, Google Sheets, Airtable oder Notion — alles kostenlos, ohne Paywall.
Thunderbit übernimmt die Anti-Bot-Behandlung in der Cloud, sodass du dich nicht mit CAPTCHAs, Proxies oder TLS-Fingerprinting herumschlagen musst. Die KI passt sich Layout-Änderungen automatisch an, Wartung fällt also keine an. Für Nutzer, die sich überhaupt nicht mit JSON-Pfadnavigation befassen wollen, ist das der Weg mit dem geringsten Widerstand.
Ehrliche Einschränkungen: Thunderbit ist nicht für 100K+ Seiten pro Tag gebaut. Kreditbudgets und Cloud-Limits machen High-Volume-Ingest im Vergleich zu Roh-APIs unwirtschaftlich. Außerdem kannst du nicht ohne Weiteres eine bestimmte Postleitzahl oder ASN fest verdrahten, sofern das Tool das nicht unterstützt. Für laufende Pipelines mit hohem Volumen sind DIY oder eine Scraping-API weiterhin die bessere Wahl.
Grobe Preisabschätzung: 1.000 Walmart-Produktzeilen kosten mit Thunderbit ungefähr 2.000 Credits (etwa 0,60–1,10 $ im Starter-/Pro-Tarif). Das ist vergleichbar mit der Walmart-API von Oxylabs und bei geringem Volumen günstiger als die meisten Hobby-Scraping-APIs. .
Deine gescrapten Walmart-Daten exportieren
Sobald du die Daten hast, brauchst du sie an einem nützlichen Ort. Drei Formate decken die meisten Anforderungen ab:
CSV — das kleinste gemeinsame Format, das Analysten tatsächlich öffnen:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Verwende utf-8-sig, damit Excel die Datei korrekt öffnet. Das BOM-Markierungselement verhindert, dass Excel Sonderzeichen verhunzt.
JSONL — das Produktionsformat für Scraping-Pipelines:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(ein unterbrochener Schreibvorgang verliert nur die letzte Zeile), streambar bei konstantem Speicherverbrauch und bewahrt verschachtelte Daten wie Varianten und Bewertungen intakt.
Excel — für einmalige Übergaben an Analysten:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Produkte")
5 ws.append(["Name", "Preis", "Verfügbarkeit", "Bewertung", "Rezensionen", "Verkäufer"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit deckt den Export-Teil für Nicht-Python-Nutzer ab: Ein-Klick-Export nach Google Sheets, Airtable, Notion, Excel, CSV und JSON — alles im Basistarif kostenlos. Für laufende Überwachung kann Thunderrbits geplante Scraper-Funktion wiederkehrende Extraktionen automatisch ausführen.
Ein Hinweis zum Scheduling: . GitHub-Actions-Runner sitzen in Azure-IP-Bereichen, die Walmarts Anti-Bot sofort blockiert. Verwende APScheduler auf einem VPS oder leite den gesamten Traffic über Residential Proxies.
Rechtliche und ethische Leitlinien für Walmart-Scraping
Nutzer in Foren formulieren das sehr direkt: „Ich habe nichts dagegen, Katz und Maus mit den Entwicklern zu spielen, aber ich möchte ungern mit ihrem Legal-Team spielen.“
Walmarts Nutzungsbedingungen die Verwendung von „Robotern, Spidern … oder anderen manuellen oder automatisierten Mitteln, um Materialien abzurufen, zu indizieren, zu ‚scrapen‘, zu ‚data minen‘ oder anderweitig zu sammeln“, ohne „vorherige ausdrückliche schriftliche Zustimmung“.
Walmarts robots.txt /search, /account, /api/ und Dutzende interne Endpunkte. Produktdetailseiten (/ip/...) und Bewertungen (/reviews/product/) sind nicht verboten.
Der Präzedenzfall hiQ v. LinkedIn (9. Bezirk, ) stellte fest, dass das Scrapen öffentlich zugänglicher Daten den bundesrechtlichen CFAA vermutlich nicht verletzt. Im selben Fall entschied das Gericht später jedoch, dass und verhängte ein gegen das Unternehmen. Neuere Entscheidungen von 2024 (, ) haben CFAA weiter eingegrenzt und Verteidigungsmöglichkeiten über Copyright-Preemption geschaffen, doch diese Urteile hingen von spezifischer ToU-Sprache ab, die sich nicht sauber auf Walmart übertragen lässt.
Praktische Leitlinien: Server nicht überlasten. Rate Limits respektieren. Keine personenbezogenen oder Nutzerdaten scrapen. Daten verantwortungsvoll verwenden. Öffentliche Walmart-Produktseiten in moderatem Umfang für eigene Recherchen zu scrapen ist ein völlig anderes Risikoprofil als kommerzielles Scraping im Widerspruch zu Walmarts Bedingungen. Wenn du ein Produkt auf Basis von Walmart-Daten baust, sprich mit einer Anwältin oder einem Anwalt und prüfe Walmarts offizielle .
Hinweis: Das hier sind Bildungsinformationen, keine Rechtsberatung.
Fazit und wichtigste Erkenntnisse
Walmart mit Python zu scrapen ist dank des doppelten Anti-Bot-Stacks aus Akamai und PerimeterX eine . Nicht unmöglich — aber du brauchst die richtigen Werkzeuge und Muster.
Wichtigste Erkenntnisse:
- Die Extraktion aus
__NEXT_DATA__-JSON ist für die meisten Anwendungsfälle die pragmatische Wahl. Sie wird von jedem ernsthaften Open-Source-Walmart-Scraper von 2024–2026 verwendet. Der Basispfad istprops.pageProps.initialData.data.productfür PDPs undsearchResult.itemStacksfür Suche/Browse. curl_cffimitimpersonate="chrome124"ist Pflicht. Einfachesrequestsoderhttpxkann Akamais TLS-Fingerprinting unabhängig von den Headern nicht passieren.- Stille Blocks sind die eigentliche Gefahr. Walmart gibt 200 OK mit CAPTCHA-Body zurück. Prüfe den Response-Content, nicht nur den Statuscode.
- Produktions-Scraper brauchen mehr als Happy-Path-Code. Exponentieller Backoff mit Jitter, Block-Erkennung über vier Signale, Rate-Limits von 3–6 Sekunden pro Anfrage, Datenvalidierung und Session-Health-Monitoring sind alle essenziell.
- Das Abfangen interner APIs über
/orchestra/*ist stark, aber fragil. Nutze es als DevTools-Übung für konkrete Datenbedürfnisse, nicht als primäre Extraktionsmethode. - Walmart begrenzt Suchergebnisse auf 25 Seiten. Mit Sortierreihenfolge-Wechsel und Preisbereich-Slicing kommst du breiter voran.
- Wähle deinen Ansatz ehrlich: DIY-Python für Entwickler mit Sonderanforderungen und hohem Volumen. Scraping-APIs für mittelgroße Teams ohne eigenen Scraping-Engineer. für Business-Anwender, die heute Nachmittag Daten in Google Sheets wollen.
Wenn du den No-Code-Weg testen willst, hat die einen kostenlosen Tarif — du kannst ein paar Walmart-Seiten scrapen und die Ergebnisse selbst sehen. Wenn du den Python-Weg gehst, sind die Code-Muster in diesem Artikel produktionsgetestet. So oder so hast du jetzt eine Karte von Walmarts Abwehrmechanismen und drei Wege hindurch.
Mehr zu Web-Scraping-Techniken findest du in unseren Anleitungen zu , und . Außerdem kannst du Tutorials auf dem ansehen.
FAQs
Ist es legal, Walmart-Produktdaten zu scrapen?
Walmarts Nutzungsbedingungen verbieten automatisiertes Scraping ohne schriftliche Zustimmung. Das Urteil des 9. Bezirks in hiQ v. LinkedIn (2022) stellte fest, dass der bundesrechtliche CFAA auf das Scrapen öffentlicher Seiten wahrscheinlich nicht anwendbar ist, aber derselbe Fall endete mit einem gegen den Scraper. Das Scrapen öffentlicher Produktseiten in moderatem Umfang für eigene Recherchen hat ein ganz anderes Risikoprofil als die kommerzielle Extraktion im großen Stil. Konsultiere eine Anwältin oder einen Anwalt, wenn du auf Walmart-Daten ein Geschäft aufbauen willst.
Warum wird mein Walmart-Scraper ständig blockiert?
Die häufigsten Ursachen sind: die Verwendung von einfachem requests oder httpx (die einen Python-spezifischen TLS-Fingerprint senden, den Akamai sofort erkennt), fehlende oder falsche Header, keine Proxy-Rotation, zu schnelle Anfragen mit weniger als 3–6 Sekunden Abstand und fehlende Sitzungscookies (_px3, _abck, locDataV3). Wechsle zu curl_cffi mit impersonate="chrome124", verwende Residential Proxies und setze die in diesem Artikel beschriebenen Block-Erkennungs- und Retry-Muster um.
Welche Daten kann ich mit Python von Walmart scrapen?
Produktnamen, Preise (aktuell und reduziert), Bilder, kurze und lange Beschreibungen, Bewertungen, Anzahl der Rezensionen, Verfügbarkeitsstatus, Verkäufernamen, Herstellerinformationen, Variantenoptionen (Größe, Farbe) und die Kategorisierung. Mit der __NEXT_DATA__-Methode sind all diese Daten als strukturiertes JSON verfügbar. Das Abfangen interner APIs kann zusätzlich Variantenpreise, Echtzeit-Bestände und paginierte Bewertungsdaten liefern.
Brauche ich Proxies, um Walmart zu scrapen?
Ja, für jeden produktiven oder wiederholten Einsatz. — selbst bei perfekten Headern wird eine Nicht-Residential-IP vom IP-Reputationssystem von Akamai markiert. Residential- oder Mobile-Proxies sind erforderlich. Rechenzentrums-IPs sind fast sofort verbrannt. Rechne grob mit 3–17 US-Dollar pro 1.000 Seiten, abhängig vom Proxy-Anbieter und Tarif.
Kann ich Walmart scrapen, ohne Code zu schreiben?
Ja. ist eine KI-gestützte Chrome-Erweiterung, die Walmart in zwei Klicks scrapt: Erst „KI-Felder vorschlagen“, um Produktdatenspalten automatisch zu erkennen, dann „Scrapen“, um die Daten zu extrahieren. Sie übernimmt Anti-Bot-Herausforderungen in der Cloud und exportiert direkt nach Excel, Google Sheets, Airtable oder Notion — alles kostenlos. Sie eignet sich am besten für Analysten, PMs und Business-Anwender, die schnell Daten brauchen, ohne eine eigene Pipeline zu bauen. Für starkes oder sehr individuell angepasstes Scraping sind Python oder eine Scraping-API weiterhin die bessere Wahl.
Mehr erfahren