Redfin aktualisiert , nachdem sie live gegangen sind. Diese Aktualität ist pures Gold für alle, die eine Immobilien-Datenpipeline aufbauen – und genau deshalb versuchen so viele Scraper, Redfin anzuzapfen, und werden dann innerhalb weniger Minuten blockiert.
Ich arbeite seit Jahren bei an Tools zur Datenerfassung, und ich kann Ihnen sagen: Der Unterschied zwischen „Redfin scrapen“ und „Redfin scrapen, ohne gesperrt zu werden“ ist genau die Stelle, an der die meisten Tutorials scheitern. Sie zeigen den BeautifulSoup-Code, lassen den Teil weg, in dem Cloudflare Ihre Requests gnadenlos abfängt, und Sie stehen dann vor einer 403-Seite und fragen sich, was schiefgelaufen ist. Dieser Leitfaden ist anders. Ich zeige Ihnen drei echte Wege – HTML-Parsing, die versteckte API von Redfin und einen No-Code-Ansatz mit Thunderbit – und gehe ausführlich auf die Anti-Bot-Schutzmechanismen ein, die wirklich zählen. Am Ende wissen Sie genau, welche Methode zu Ihrem Kenntnisstand, Ihrem Umfang und Ihrer Toleranz für Wartungsaufwand passt.
Was ist Redfin – und warum sind die Daten so wichtig?
Redfin ist ein technologiegetriebener Immobilienmakler mit fest angestellten Agenten, die Angebote direkt aus MLS-Feeds beziehen. Die Plattform deckt ab und hat fast 50 Millionen monatliche Besucher. Im Gegensatz zu reinen Aggregator-Portalen sind Redfin-Daten von Agenten geprüft, und die proprietäre Redfin-Estimate-AVM deckt ab – mit einem Medianfehler von nur 1,96 % bei Objekten am Markt.
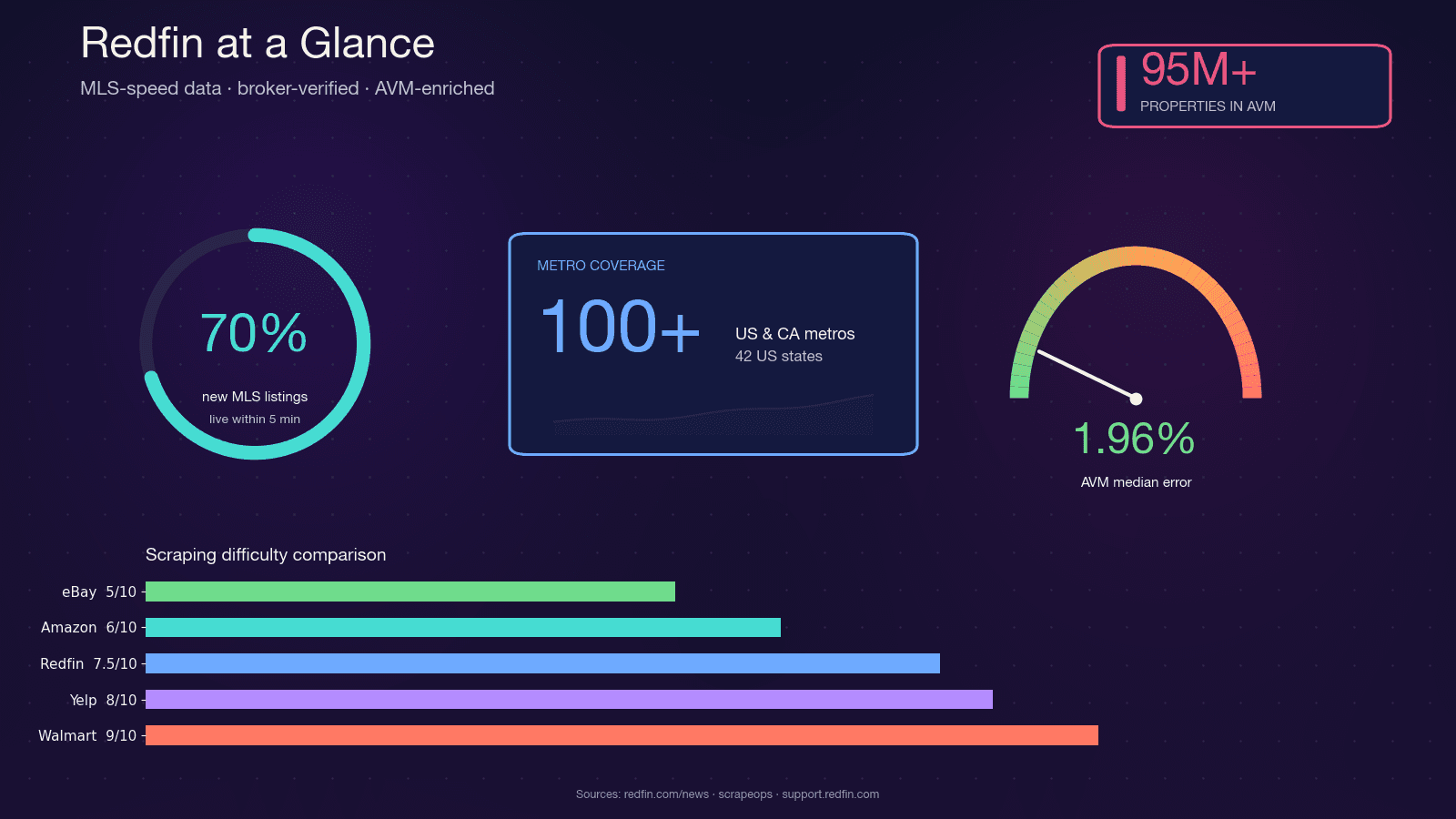
Diese Kombination aus MLS-schneller Aktualität, brokergeprüfter Qualität und einer präzisen AVM ist der Grund, warum Immobilieninvestoren, Makler, Proptech-Startups und Datenanalysten alle programmgesteuerten Zugriff auf Redfin-Daten wollen. Python ist dafür die naheliegende Wahl: Das Scraping-Ökosystem (requests, BeautifulSoup, Selenium, Playwright) ist ausgereift, die Community-Unterstützung enorm, und die Anbindung an pandas und Jupyter für Analysen funktioniert nahtlos.
Warum Redfin mit Python scrapen?
Die Anwendungsfälle sind so vielfältig wie die Menschen, die diese Daten brauchen. So nutzen verschiedene Zielgruppen typischerweise gescrapte Redfin-Daten:
| Zielgruppe | Hauptziel beim Scraping | Beispielanwendung |
|---|---|---|
| Immobilienmakler | Lead-Generierung, Markt-Insights | Neue und abgelaufene Angebote im eigenen Gebiet; Agentenverzeichnis für Wettbewerbsanalysen |
| Immobilieninvestoren | Dealflow, Cap-Rate-Analyse | Screens für Mietrendite, Erkennung unterbewerteter Objekte, tägliche Benachrichtigungen für neue Angebote |
| Proptech-Startups | Produkt-Datenpipelines | Trainingsdaten für AVM, Marktdashboards, Akquise-Engines für iBuyer |
| Datenanalysten | Marktforschung, BI | Medianpreis-Trends auf ZIP-Code-Ebene, Zeitreihen für Days on Market, Verhältnis Verkaufspreis zu Angebotspreis |
| Wholesaler / Flipper | Tracking von Problemimmobilien | Erkennung von Preisreduzierungen, Zwangsversteigerungen, Off-Market-Vergleiche |
Der allgemeine Trend bestätigt das: setzen inzwischen auf Predictive Analytics, um Chancen zu erkennen und Risiken zu steuern. Der PropTech-Markt soll anwachsen – bei einer CAGR von 16,4 %. Strukturierte Immobiliendaten sind längst kein Nice-to-have mehr, sondern Grundvoraussetzung.
Alle Redfin-Datenfelder, die Sie scrapen können (vollständige Referenz)
Bevor Sie auch nur eine Zeile Code schreiben, sollten Sie wissen, was tatsächlich verfügbar ist. Ich habe Redfins Suchergebnisseiten, Objekt-Detailseiten und Agentenprofile geprüft – und mit Open-Source-Stingray-Wrappers wie den Projekten und abgeglichen. Insgesamt komme ich auf 117 unterschiedliche Felder über alle Seitentypen hinweg.
Diese Tabelle lohnt sich als Lesezeichen. Wer sein Datenschema kennt, bevor er mit dem Code beginnt, spart sich stundenlanges Probieren bei Selektoren.
Felder auf der Suchergebnisseite
Das sind die kompakten Felder auf den Karten der Angebote – oft auch ohne vollständiges JS-Rendering extrahierbar:
| Feld | Datentyp | Hinweise |
|---|---|---|
| Objekt-ID | Nummer | Interne Redfin-ID, aus /home/{id} im href geparst |
| Angebotspreis | Nummer | |
| Vollständige Adresse | Text | |
| Schlafzimmer / Badezimmer / Quadratfuß | Nummer | Drei Werte in Folge |
| Immobilientyp | Single Select | SFH, Condo, Townhouse, Multi |
| Status | Text | Active, Pending, Contingent |
| Tage am Markt | Nummer | |
| Hinweis auf Preisreduzierung | Nummer | Differenz zum ursprünglichen Angebot |
| Hauptfoto | Bild-URL | Ein Foto pro Karte |
| Hot-Home-Badge | Boolean | |
| Datum/Uhrzeit des Open House | Text | |
| Maklerzuordnung | Text |
Felder auf der Objekt-Detailseite
Auf der Detailseite steckt die eigentliche Tiefe. Viele dieser Felder erfordern JavaScript-Rendering oder die Stingray-API:
| Feld | Datentyp | Hinweise |
|---|---|---|
| Redfin Estimate (am Markt) | Nummer | Über /stingray/api/home/details/avm |
| Redfin Estimate (außerhalb des Markts) | Nummer | Über /stingray/api/home/details/owner-estimate; Medianfehler 7,52 % |
| Baujahr / renoviert | Nummer | |
| Grundstücksgröße | Nummer | |
| HOA-Gebühren | Nummer | Monatlich, falls vorhanden |
| Grundsteuer (jährlich) | Nummer | |
| Steuerlicher Schätzwert | Nummer | |
| Verkaufshistorie | Tabelle | Preis, Datum, Ereignistyp |
| Objektbeschreibung | Text | Marketing-Absatz |
| Foto-URLs (Karussell) | Bild-URLs | 20+ pro Angebot |
| Name, Telefon, E-Mail des Listing-Agenten | Text / Telefon / E-Mail | Telefonnummer oft maskiert |
| Schulbewertungen (Grundschule / Middle School / High School) | Nummer | Plus Bezirksname |
| Walk / Transit / Bike Score | Nummer | |
| Klimarisiko-Werte | Nummer | Überschwemmung, Feuer, Hitze, Wind |
| Ähnliche aktive / verkaufte / nahegelegene Objekte | URLs | Karussell-Daten |
| Parken, Garage, Heizung, Kühlung | Text | Ausstattungsgruppen |
Felder im Agentenprofil
| Feld | Datentyp | Hinweise |
|---|---|---|
| Name, Foto, Maklerbüro, Bio | Text / Bild | |
| Telefon, Kontaktformular | Telefon / Text | per Klick sichtbar |
| Anzahl aktiver Listings | Nummer | |
| Verkäufe der letzten 12 Monate / Gesamtvolumen | Nummer | |
| Durchschnittliches Verhältnis Angebot zu Verkauf | Nummer | |
| Sternebewertung / Anzahl Bewertungen | Nummer | |
| Berufserfahrung / Lizenznummer | Text / Nummer |
Wenn Sie bei einer Redfin-Seite Thunderbits Funktion AI Suggest Fields nutzen, erkennt das Tool die meisten dieser Spalten automatisch und ordnet die passenden Datentypen zu – ganz ohne manuelles CSS-Selector-Mapping. Darauf komme ich später noch zurück.
Redfins Anti-Bot-Schutz entschlüsselt (nicht nur „Proxy verwenden“)
Hier möchte ich einen Punkt klar machen: Die meisten Tutorials winken das Blockierproblem einfach weg und springen direkt zu „Kaufen Sie Proxies bei unserem Sponsor“. Das hilft nicht. Wenn Sie nicht verstehen, was Redfin zur Erkennung von Scraper-Aktivitäten einsetzt, verbrennen Sie Proxy-Guthaben und werden trotzdem blockiert. , und – „weniger aggressiv als Zillows Enterprise-WAF, stattdessen mit benutzerdefiniertem Rate Limiting und JavaScript-Challenges.“
Redfin setzt auf einen mehrschichtigen Stack: Cloudflare am Rand (JS-Challenge, Turnstile, TLS/JA3-Fingerprinting) plus einen Redfin-spezifischen Rate-Limiter auf Anwendungsebene. In ihrer robots.txt gibt es kein Crawl-delay, weil die Durchsetzung auf WAF-Ebene erfolgt.
Warum einfaches requests + BeautifulSoup bei Redfin scheitert
Wenn Sie eine einfache requests.get()-Anfrage an eine Redfin-Objektseite mit Standard-Headern schicken, passiert meist Folgendes:
- HTTP 403 — Die Cloudflare-JS-Challenge wurde nicht gelöst, also erhalten Sie die Challenge-Seite statt des Listings.
- Eine Zwischen-Challenge-Seite — Im HTML steht das Cloudflare-Turnstile-Widget statt der Objektdaten.
- HTTP 200 mit teilweisem HTML — Sie erhalten nur eine Hülle mit einem großen eingebetteten JSON-Blob unter
root.__reactServerState.InitialContext, aber keine vorgerenderte Suchkarten, keine Preis-Historie, keine Schulbewertungen.
Redfin verwendet ein eigenes (nicht Next.js), und der Hydration-Key ist Redfin-spezifisch – root.__reactServerState.InitialContext mit Listing-Daten unter ReactServerAgent.cache.dataCache. Das ist weder __NEXT_DATA__ noch window.__INITIAL_STATE__.
Der häufigste Grund für stille 403er? Fehlende Sec-Fetch-*-Header. Redfin/Cloudflare prüft explizit Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest und Sec-Fetch-User. Fehlen diese, werden Sie sofort markiert.
Der Maßnahmenplan: Verzögerungen, Header, Proxies und Sessions
Hier ist die vollständige Gegenüberstellung der Schutzmechanismen und der jeweiligen Gegenmaßnahmen:
| Redfin-Schutz | Wirkung | Erkennungssignal | Gegenmaßnahme |
|---|---|---|---|
| Cloudflare JS-Challenge | Zwischenstufe, die ein cf_clearance-Cookie ausgibt | 403 + Cloudflare-HTML | curl_cffi mit impersonate="chrome120"; Session über die Startseite aufwärmen; US-Residential-Proxy |
| Cloudflare Turnstile | Interaktives CAPTCHA bei riskanten Sessions | 403 + Turnstile-Widget | Headless-Browser mit Stealth + Residential-Proxy |
| Cloudflare Error 1020 (ASN-Bann) | Sperrt auffällige IPs/ASNs auf WAF-Ebene | 403 mit „Error 1020 Access Denied“ | Auf Residential- oder Mobile-Proxy wechseln; niemals Datacenter-ASNs nutzen |
| TLS/JA3-Fingerprinting | Erkennt nicht-browsertypische TLS-Stacks | Stille 403 trotz perfekter Header | curl_cffi-Impersonation oder echter Browser |
| HTTP/2-Fingerprinting | Prüft HTTP/2-SETTINGS und HPACK-Reihenfolge | Stille Blockierung | curl_cffi spricht HTTP/2 wie Chrome |
| Header-Validierung (UA, Sec-Fetch-*) | Browser-konsistenter Header-Satz | 403 beim ersten Request | Vollständiger Chrome-Header-Satz inkl. Sec-Fetch-Site/Mode/Dest/User, realistischer Referer |
| Cookie-/Session-Kontinuität | Verfolgt cf_clearance, RF_BROWSER_ID | Challenges bei kalten Deep-URL-Aufrufen | Persistente Session; zuerst die Startseite aufrufen |
| Rate-Limit auf App-Ebene | Request-Limiter pro IP | 429 | 2–5 Sekunden Verzögerung mit Jitter; exponentielles Backoff |
| Reputation von Datacenter-IPs | Sperrt bekannte DC-ASNs | Sofort 1020/403 | Nur US-Residential- oder Mobile-Proxies |
| Erkennung von Parallelität | Mehrere parallele Requests von einer IP | Plötzliche Eskalation zu Turnstile | Max. 2 gleichzeitige Anfragen pro IP |
Praktische Schwellenwerte aus Community-Tests:
- Sichere Taktung: 1 Request alle 2–3 Sekunden pro IP
- Dauerhaft mehr als 20–30 Requests/Minute von einer einzigen Datacenter-IP lösen innerhalb weniger Minuten eine Challenge aus
- Weiche Rate-Limits heben sich nach 5–15 Minuten ohne Traffic wieder auf
- Datacenter-IP-Sperren (AWS, GCP, Azure, OVH) können Stunden bis Tage bestehen bleiben
Das Standard-Python-requests-Paket (urllib3 + OpenSSL) erzeugt einen – und wird selbst bei perfekten Headern still blockiert. Die Branchenlösung ist curl_cffi mit impersonate="chrome120", weil damit TLS und HTTP/2 wie in Chrome gesprochen werden.
Drei Wege, Redfin mit Python zu scrapen – und wann Sie welchen wählen sollten
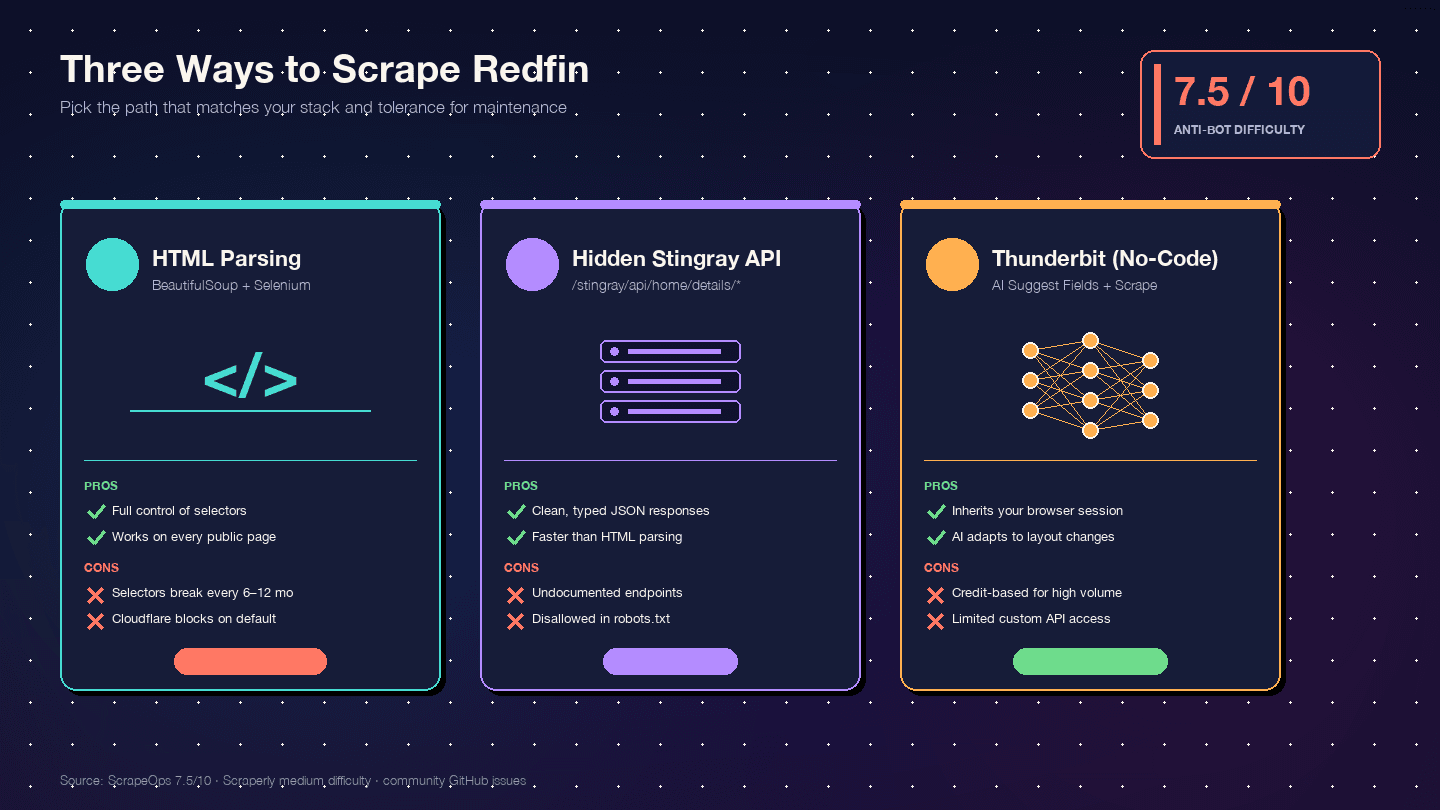
Ich habe kein einziges konkurrierendes Tutorial gefunden, das alle drei Ansätze nebeneinander vergleicht. Hier ist die Entscheidungsübersicht:
| Kriterium | HTML-Parsing (BS4 + Selenium) | Versteckte Stingray-API | Thunderbit (No-Code) |
|---|---|---|---|
| Einrichtungsaufwand | Mittel (Python-Umgebung + Browser-Driver) | Hoch (Endpunkte reverse-engineeren) | Niedrig (Chrome-Extension installieren) |
| Anti-Bot-Risiko | Hoch (DOM-Requests sind am sichtbarsten) | Mittel (API-ähnliche Requests wirken unauffälliger) | Am niedrigsten (nutzt Ihre echte Browser-Session) |
| Qualität der Datenstruktur | Mittel (unstrukturiertes HTML → manuelles Parsing) | Sehr gut (vorstrukturiertes JSON) | Hoch (KI erkennt Felder und Datentypen automatisch) |
| Wartungsaufwand | Hoch — jede Layoutänderung zerstört Selektoren | Mittel — Endpunkte können sich ohne Vorwarnung ändern | Am niedrigsten — die KI passt sich Layoutänderungen an |
| Skalierung | Niedrig bis mittel (Hunderte mit Proxies) | Mittel bis hoch (Tausende, sauberere Requests) | Mittel (50 Seiten pro Batch per Cloud-Scraping) |
| Am besten geeignet für | Entwickler mit voller Kontrolle | Entwickler, die sauberes JSON brauchen | Nicht-Entwickler, schnelle Projekte, laufende Daten ohne Dev-Ressourcen |
Der Wartungsaspekt ist wichtig. Redfin hat zwei Generationen von Karten-DOMs ausgeliefert – die ältere (homecardV2Price) und die aktuelle (span.bp-Homecard__Price--value). Die Historie von Community-GitHub-Issues zeigt, dass CSS-Selektoren etwa alle 6–12 Monate brechen. In solchen Fällen ist ein BeautifulSoup-Scraper über Nacht kaputt. Ein KI-basiertes Feld-Erkennungssystem passt sich an.
Bevor Sie starten
- Schwierigkeit: Mittelstufe (Ansätze 1 & 2), Anfänger (Ansatz 3)
- Benötigte Zeit: ca. 30 Minuten für Ansatz 1 oder 2; ca. 5 Minuten für Ansatz 3
- Was Sie brauchen:
- Python 3.8+ mit pip (Ansätze 1 & 2)
- Chrome-Browser (alle Ansätze)
- (Ansatz 3)
- US-Residential-Proxies für Scraping im großen Umfang (Ansätze 1 & 2)
Ansatz 1: Redfin mit Python per HTML-Parsing scrapen (BeautifulSoup + Selenium)
Das ist der Weg mit „voller Kontrolle“. Sie schreiben die Selektoren, Sie verwalten den Browser, Sie kümmern sich um die Fehler.
Es ist der lehrreichste Ansatz. Er ist aber auch der fragilste.
Schritt 1: Python-Umgebung einrichten
Erstellen Sie eine virtuelle Umgebung und installieren Sie die benötigten Bibliotheken:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # Unter Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi ist hier entscheidend – damit können Ihre HTTP-Requests einen echten Chrome-TLS-Fingerprint imitieren, statt des Standard-Fingerprints von Python-requests, den Cloudflare sofort blockiert.
Schritt 2: Browser-Header und Session konfigurieren
Hier scheitern die meisten Einsteiger. Sie brauchen den vollständigen Chrome-Header-Satz, inklusive der Sec-Fetch-*-Header, die Redfin/Cloudflare explizit prüft:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Session aufwärmen — cf_clearance- und RF_BROWSER_ID-Cookies sammeln
17session.get("https://www.redfin.com/")Das Aufwärmen der Session ist kritisch – eine direkte Anfrage an eine tiefe Objekt-URL (ohne vorherige Cookies, ohne Referer) wird von Cloudflare schlechter bewertet.
Beginnen Sie immer mit der Startseite.
Schritt 3: Redfin-Suchergebnisse scrapen
Sobald die Session warm ist, können Sie eine Stadtsuche abrufen und die Karten der Angebote parsen. Aktuelle Selektoren (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Seiten 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Blockiert auf Seite {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Zufällige Pause zwischen 2 und 5 Sekunden
28 time.sleep(random.uniform(2, 5))
29print(f"{len(listings)} Listings gescrapt")Sie sollten eine wachsende Liste von Dictionaries sehen, die jeweils Preis, Adresse, Schlafzimmer/Badezimmer/Quadratfuß und die Detail-URL eines San-Francisco-Listings enthalten. Wenn Sie 0 Karten erhalten, prüfen Sie den HTTP-Statuscode – eine 403 bedeutet, dass Cloudflare Sie erkannt hat, und dass Sie wahrscheinlich Residential Proxies benötigen.
Schritt 4: Einzelne Objekt-Detailseiten scrapen
Suchergebnisse liefern die Grundlagen. Detailseiten liefern Redfin Estimate, Baujahr, HOA, Verkaufshistorie, Agenteninfos und Fotos. Diese Seiten brauchen JavaScript-Rendering, also wechseln Sie zu Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Erste 10 anreichern
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Auf JS-Rendering warten
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Nach diesem Schritt sollten Ihre ersten 10 Listings mit Redfin-Estimate-Werten und Baujahr-Daten angereichert sein. Die XPath-Selektoren sind für diese verschachtelten Ausstattungsfelder robuster als CSS, aber sie bleiben dennoch fragil – jede DOM-Umstrukturierung kann sie brechen.
Schritt 5: Blocks und Fehler behandeln
Implementieren Sie eine Retry-Logik mit exponentiellem Backoff:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Blockiert ({resp.status_code}). Neuer Versuch in {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Unerwarteter Status: {resp.status_code}")
13 break
14 return NoneAnzeichen für eine Blockierung: HTTP 403 mit Cloudflare-HTML im Body, HTTP 429 (explizites Rate Limit), leerer Response-Body oder „Error 1020 Access Denied“ im Seiteninhalt. Wenn Sie das ständig sehen, ist es Zeit für Residential Proxies oder den API-Ansatz.
Ansatz 2: Redfin mit Python über die versteckte Stingray-API scrapen
Das ist mein Lieblingsansatz. Das Frontend von Redfin spricht mit einer internen JSON-API unter /stingray/api/home/details/*, und die Antworten kommen als sauberes, typisiertes JSON zurück – HTML-Parsing ist nicht nötig.
So finden Sie Redfins versteckte API-Endpunkte
Öffnen Sie Chrome DevTools → Tab „Network“ → Filter Fetch/XHR → rufen Sie irgendeine Redfin-Objektseite auf. Sie sehen Requests an Endpunkte wie:
api/home/details/initialInfo— löst URL → propertyId, listingId aufapi/home/details/aboveTheFold— Preis, Beds, Baths, SqFt, Fotos, Status, Agent, MLS#api/home/details/belowTheFold— Ausstattung, HOA, Steuern, Parken, Baujahr, Grundstück, Historieapi/home/details/avm— Redfin Estimate am Marktapi/home/details/owner-estimate— Redfin Estimate außerhalb des Marktsapi/home/details/descriptiveParagraph— Marketingbeschreibung
Bei Mietseiten wird die rentalId (eine 36-stellige UUID) aus der URL des <meta property="og:image">-Tags extrahiert.
Immobiliendaten über die Stingray-API scrapen
Es gibt eine wichtige Besonderheit: Stingray-JSON-Antworten beginnen als Anti-CSRF-Maßnahme mit der Zeichenkette {}&&. Das müssen Sie vor dem Parsen entfernen:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Session aufwärmen
6session.get("https://www.redfin.com/")
7# Objektseite abrufen, um Cookies und property ID zu erhalten
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Jetzt die Stingray-API aufrufen
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Anti-CSRF-Präfix entfernen
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Strukturierte Daten extrahieren
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))Die Antwort enthält typisierte Felder: Preis als Integer, Beds/Baths als Zahlen, Foto-URLs als Arrays, Agenteninformationen als verschachtelte Objekte. Kein BeautifulSoup-Parsing, keine CSS-Selektoren, kein Rätselraten.
Vorteile und Grenzen des versteckten API-Ansatzes
Vorteile:
- Vorstrukturierte JSON-Daten – deutlich sauberer als HTML-Parsing
- Schneller pro Request (kleinere Payloads, kein Rendering-Overhead)
- Geringeres Blockrisiko (API-ähnliche Requests wirken natürlicher)
Grenzen:
- Endpunkte können sich ohne Vorwarnung ändern – es gibt keine offizielle Dokumentation
robots.txtverbietet/stingray/explizit für den Wildcard-User-Agent- Neue Endpunkte müssen per Reverse Engineering entdeckt werden
- Benötigt trotzdem Session-Warm-up und korrekte Header, um Cloudflare zu vermeiden
Die No-Code-Alternative: Redfin mit Thunderbit scrapen
Wenn Sie Redfin-Daten brauchen und keine Python-Skripte warten wollen – oder einfach in fünf Minuten Ergebnisse sehen möchten – beginnen Sie hier. Wir haben genau dafür gebaut: strukturierte Datenerfassung von beliebigen Websites, ganz ohne Code.
Schritt 1: Thunderbit installieren und zu Redfin gehen
Installieren Sie die aus dem Chrome Web Store. Öffnen Sie Redfin und navigieren Sie zu einer Suchergebnisseite – zum Beispiel Häuser zum Verkauf in San Francisco.
Schritt 2: Auf „AI Suggest Fields“ klicken
Klicken Sie in der Browser-Toolbar auf das Thunderbit-Symbol und dann auf „AI Suggest Fields“. Die KI liest die Redfin-Seite aus und schlägt automatisch Spalten wie „Adresse“, „Preis“, „Beds“, „Baths“, „SqFt“, „Property Type“ und „Listing Photo“ vor – die passenden Datentypen werden direkt zugewiesen.
Sie können Spalten entfernen, die Sie nicht brauchen, oder eigene hinzufügen, indem Sie auf „+ Add Column“ klicken und in normalem Englisch beschreiben, was Sie möchten (z. B. „Listing-Agentenname“ oder „Tage am Markt“).
Sie sollten eine Tabellenvorschau mit Ihren konfigurierten Spalten sehen, bereit zum Befüllen.
Schritt 3: Auf „Scrape“ klicken und die Daten einlaufen sehen
Klicken Sie auf „Scrape“. Thunderbit verarbeitet die sichtbaren Listings und füllt Ihre Tabelle. Bei paginierten Ergebnissen übernimmt es die Pagination automatisch – keine Schleifenlogik nötig.
In meinen Tests füllt sich eine Tabelle mit 50 Zeilen in etwa 45 Sekunden. Strukturierte Daten, exportbereit.
Wie Thunderbit Redfins Anti-Bot-Schutz umgeht
Da Thunderbit in Ihrem eigenen Browser läuft, übernimmt es Ihre vorhandenen Redfin-Cookies, Ihre Session und Ihren Browser-Fingerprint. Für Cloudflare sieht das aus wie ein normaler Nutzer, der Redfin besucht – weil es technisch gesehen genau das ist. Kein Headless Browser, keine Datacenter-IP, kein unpassender TLS-Fingerprint. Für öffentlich verfügbare Seiten kann der Cloud-Scraping-Modus von Thunderbit 50 Seiten auf einmal verarbeiten.
Das ist eine grundlegend andere Ausgangslage als Requests aus einem Python-Skript auf einem Server.
Ihre Browser-Session ist bereits vertrauenswürdig.
Redfin-Unterseiten mit Thunderbit scrapen
Nachdem Sie die Suchergebnisse erfasst haben, klicken Sie auf „Scrape Subpages“, damit die KI jede Objekt-Detail-URL besucht und Ihre Tabelle mit zusätzlichen Feldern anreichert – Redfin Estimate, Baujahr, HOA-Gebühren, Agenteninfos, Objektfotos und Verkaufshistorie.
Das entspricht dem 40-zeiligen Selenium-Loop aus Ansatz 1 – nur mit einem Klick und ohne Wartungsaufwand.
Wenn Redfin sein DOM von homecardV2Price auf span.bp-Homecard__Price--value ändert, passt sich die KI an. Ihre Python-Selektoren tun das nicht.
Mehr als CSV: Redfin-Daten nach Google Sheets, Airtable und Notion exportieren
Die meisten Tutorials hören bei df.to_csv() auf. Für eine einmalige Analyse ist das okay. Aber wenn Sie in einem Immobilien-Team arbeiten, brauchen Sie kollaborative, lebendige Daten – keine statischen Dateien, die auf einem Desktop verstauben.
Export mit Python (gspread + Airtable API)
Google Sheets mit gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Immobilienfotos inline über die IMAGE()-Formel darstellen
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Achtung: Google Sheets hat ein hartes Limit von 10 Millionen Zellen pro Tabelle, und die API erlaubt . Nutzen Sie ws.batch_update() statt Zell-für-Zell-Schleifen, sobald Sie mehr als ein paar Dutzend Zeilen haben.
Airtable mit pyairtable:
Wichtige Änderung für 2024: Airtable hat . Sie müssen jetzt Personal Access Tokens (PATs) verwenden – jedes Tutorial, das noch api_key=... zeigt, ist veraltet.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable ruft die Datei ab und hostet sie neu
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)Das Airtable-Rate-Limit liegt bei , bei Verstößen folgt eine 30-Sekunden-Sperre. Das Attachment-Feld akzeptiert Payloads der Form [{"url": ...}] – Airtables Server laden die URL ab, hosten sie auf ihrem CDN neu und erzeugen automatisch Thumbnails.
Export mit Thunderbit (1-Klick nach Sheets, Airtable, Notion)
Thunderbit bietet einen nativen 1-Klick-Export nach Google Sheets, Airtable und Notion – und darauf bin ich ehrlich gesagt besonders stolz: Immobilienfotos werden in Notion und Airtable direkt als Inline-Bilder hochgeladen und dargestellt. Keine =IMAGE()-Workarounds, keine kaputten CDN-Links. Sie klicken auf „Export to Airtable“, und Ihr Team erhält eine visuelle Immobiliendatenbank mit Thumbnails, die sich auch am Handy bequem durchsuchen lässt.
Für Immobilien-Teams, die Angebote visuell vorsortieren, ist das der Unterschied zwischen einem brauchbaren Tool und einem Haufen CSV-Zeilen.
Ist das Scrapen von Redfin legal? Was ToS, robots.txt und die Rechtsprechung sagen
Ich bin kein Anwalt, und das hier ist keine Rechtsberatung. Aber nach Jahren im Bereich Datenerfassung kann ich Ihnen sagen: „Ist das legal?“ ist die Frage, die alle stellen – und die die meisten Tutorials umgehen.
Redfins robots.txt
Redfins ist ausführlich. Die wichtigsten Punkte:
- Vollständig blockierte Bots:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent– Redfin nennt hier gezielt den populären Scraping-Dienst der LLM-Ära - Wichtige Disallows für
User-agent: *:/stingray/(der gesamte interne API-Namensraum),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - Kein
Crawl-delay:-Eintrag für irgendeinen User-Agent - Über 50 Sitemaps sind angegeben – Sitemaps sind der sauberste, WAF-schonendste Weg, URLs zu erfassen
Redfins Nutzungsbedingungen
sagt: „You may not automatedly crawl or query the Services for any purpose or by any means... unless you have received prior express written permission.“
Das ist eine Browsewrap-Vereinbarung – Zustimmung durch weitere Nutzung, nicht durch aktives Anklicken. US-Gerichte sind bei der Durchsetzung von Browsewrap gegen Nutzer ohne tatsächliche Kenntnis historisch eher skeptisch (siehe Nguyen v. Barnes & Noble, 9th Cir. 2014).
Relevante Rechtsprechung in Kurzform
- Van Buren v. United States (Supreme Court, 2021): Die CFAA-Klausel „exceeds authorized access“ folgt einem „gate open or closed“-Test. Eine offene Tür für einen unerwünschten Zweck zu nutzen, ist kein Hacking nach Bundesrecht.
- hiQ Labs v. LinkedIn (9th Cir., 2022): Das Scrapen öffentlich zugänglicher Daten verstößt nicht gegen die CFAA. hiQ zahlte am Ende jedoch 500.000 US-Dollar im Rahmen eines Vergleichs wegen Vertragsverletzung – weil hiQ LinkedIn-Konten registriert und auf „I agree“ geklickt hatte.
- Meta Platforms v. Bright Data (N.D. Cal., Jan. 2024): Das Gericht gab Bright Data im Summary Judgment recht – das ausgeloggte Scrapen öffentlicher Daten machte Bright Data nicht zu einem „user“, der an Metas ToS gebunden wäre.
- X Corp. v. Bright Data (N.D. Cal., Mai 2024): Richter Alsup wies die Ansprüche von X ab und hielt fest, dass Ansprüche nach kalifornischem Recht, die das Kopieren öffentlicher Inhalte kontrollieren sollen, durch das Copyright Act verdrängt werden.
Praktische Leitlinien
- Scrapen Sie nur öffentlich zugängliche Daten – niemals erst ein Konto anlegen und dann scrapen (das schafft zusätzliche Vertragsrisiken)
- Halten Sie Rate Limits ein – aggressive Mengen stützen Forderungen wegen trespass to chattels
- Veröffentlichen Sie Rohdaten oder Fotos nicht im großen Stil erneut – die (eingereicht im Juli 2025, potenzielle Schäden von über 1 Milliarde US-Dollar) erinnert daran, dass Urheberrecht bei Fotos ernst ist
- Thunderbits browserbasierter Ansatz – in Ihrer eigenen authentifizierten Session laufend – ist näher an „manuelles Browsing mit Maschinengeschwindigkeit“ als an einem headless Datacenter-Bot; das ist die rechtlich am ehesten vertretbare Position, abgesehen von einer lizenzierten API
Tipps und häufige Fehler
Ein paar hart erarbeitete Erkenntnisse aus dem Bau von Extraktions-Tools und aus dem Beobachten tausender Nutzer beim Scrapen von Immobilienseiten:
- Session immer aufwärmen. Rufen Sie zuerst
redfin.com/auf, bevor Sie irgendeine Deep-URL ansteuern. Kalte Deep-URL-Zugriffe sind der häufigste Auslöser für Cloudflare-Challenges. - User-Agent-Strings realistisch rotieren. Nutzen Sie nicht nur einen – rotieren Sie durch 5–10 aktuelle Chrome-/Firefox-UAs. Aber nicht zu aggressiv (bei jedem Request ein anderer UA wirkt verdächtig).
- Nach Objekt-ID deduplizieren. Redfins Pagination überlappt gelegentlich. Parst die
/home/{id}aus jeder Listing-URL und dedupliziert vor dem Anreichern. - Wenn möglich nicht zu Stoßzeiten scrapen. Nachts bzw. früh morgens US-Zeit ist die WAF-Prüfung meiner Erfahrung nach geringer.
- Bei 429 sofort mit exponentiellem Backoff reagieren. Nicht direkt neu versuchen – so eskalieren Sie von einem weichen Rate-Limit zu einem harten IP-Bann.
- Für große Projekte (1.000+ Seiten) Residential Proxies einplanen. Datacenter-IPs (AWS, GCP, Azure, OVH) sind im ASN-Reputationssystem von Cloudflare oft gesperrt. Sie laufen fast sofort in Error 1020.
Den richtigen Weg zum Redfin-Scraping wählen
Welchen Ansatz sollten Sie also wählen? Das hängt davon ab, wer Sie sind und was Sie brauchen.
HTML-Parsing (BeautifulSoup + Selenium): Am besten für Entwickler, die volle Kontrolle wollen, CSS-Selektoren pflegen können und es nicht stört, bei DOM-Änderungen von Redfin nachzubessern. Rechnen Sie damit, Ihren Code alle 6–12 Monate zu überarbeiten.
Versteckte Stingray-API: Ideal für Entwickler, die sauberes, strukturiertes JSON brauchen und mit dem Reverse Engineering undokumentierter Endpunkte umgehen können. Weniger Wartungsaufwand als HTML-Parsing, aber Endpunkte können sich ohne Vorwarnung ändern. Denken Sie daran: /stingray/ ist in robots.txt explizit verboten.
Thunderbit (No-Code): Am besten für Nicht-Entwickler, schnelle Projekte und Teams, die kontinuierlich Redfin-Daten brauchen, ohne Entwicklungsressourcen zu binden. Die KI passt sich Layoutänderungen an, das Scrapen von Unterseiten reichert Daten mit einem Klick an, und der Export nach , Airtable oder Notion ist integriert. Wenn Sie als Immobilien-Team eine lebendige Immobiliendatenbank brauchen – nicht einen einmaligen CSV-Dump – ist das der Weg mit dem geringsten Widerstand.
Egal, welchen Weg Sie wählen: Verstehen Sie Redfins Anti-Bot-Schutz, bevor Sie loslegen, wissen Sie, welche Felder Sie brauchen, wählen Sie ein Exportformat, das zu Ihrem Workflow passt, und bleiben Sie auf der richtigen Seite der .
Bereit für den No-Code-Weg? Der erlaubt es Ihnen, Redfin-Scraping auszuprobieren und innerhalb weniger Minuten Ergebnisse zu sehen. Für die Python-Ansätze sind die Code-Snippets oben ein funktionierender Startpunkt – Sie brauchen nur Proxies und Geduld.
FAQs
Gibt es für Redfin eine öffentliche API?
Nein. Redfin bietet keine offizielle öffentliche API an. Die versteckte Stingray-API (/stingray/api/home/details/*) liefert strukturiertes JSON und wird vom eigenen Frontend von Redfin genutzt, ist aber inoffiziell, undokumentiert, kann sich jederzeit ändern und ist in Redfins robots.txt ausdrücklich verboten. Open-Source-Wrappers wie auf PyPI bieten Python-Zugriff, aber nutzen Sie sie mit Blick auf die Risiken.
Kann ich Redfin ohne Python scrapen?
Ja. ist eine KI-gestützte Chrome-Extension, die Ihre Browser-Session für eine hohe Anti-Bot-Resilienz nutzt – installieren, Redfin aufrufen, auf „AI Suggest Fields“ klicken und nach Excel, Google Sheets, Airtable oder Notion exportieren. Es gibt außerdem weitere No-Code-Scraping-Tools und vorgefertigte Datensätze auf dem Markt, falls Sie Alternativen prüfen möchten.
Wie oft ändert Redfin sein Website-Layout?
Die Community-Historie auf GitHub zeigt, dass CSS-Selektoren etwa alle 6–12 Monate brechen. Redfin hat zwei Generationen von Karten-DOMs ausgeliefert – die ältere (homecardV2Price, homeAddressV2) und die aktuelle (bp-Homecard__Price--value, bp-Homecard__Address). Reife Scraper testen beide Varianten nacheinander.
KI-basierte Tools wie Thunderbit , weil sie Felder anhand des Inhalts erkennen und nicht über CSS-Selektoren.
Welcher Proxy-Typ ist für Redfin am besten?
Für groß angelegtes Scraping sind US-Residential-Proxies am besten – Community-Benchmarks sehen die Erfolgsquote bei etwa 80 %. Datacenter-Proxies laufen fast sofort in Cloudflare Error 1020; AWS-, GCP-, Azure- und OVH-IP-Bereiche sind gesperrt. Mobile Proxies haben die höchste Erfolgsquote, sind aber 5–10x teurer.
Für kleines, persönliches Scraping (<100 Seiten) können korrekte Header + curl_cffi-Impersonation + 2–5 Sekunden Verzögerung auch ganz ohne Proxies funktionieren.
Kann ich verkaufte oder Off-Market-Immobiliendaten von Redfin scrapen?
Ja. Verkaufte Objektdaten und der Off-Market-Redfin-Estimate (Medianfehler ) sind auf Detailseiten mit denselben Scraping-Methoden verfügbar. Die Felder unterscheiden sich von aktiven Listings: Off-Market-Seiten zeigen Verkaufspreis, Verkaufsdatum, Objekt-Historie und den owner-estimate-Endpunkt, enthalten aber keinen aktuellen Angebotspreis, keine Tage am Markt und keine Open-House-Infos. Der Stingray-API-Endpunkt für Off-Market-Schätzungen lautet api/home/details/owner-estimate statt api/home/details/avm.
Mehr erfahren