Irgendwann beim fünfzigsten Mal, als ich eine Stellenbezeichnung von Indeed in eine Tabelle kopiert und eingefügt habe, habe ich angefangen, meine Berufswahl zu hinterfragen. Wenn du schon einmal versucht hast, strukturierte Daten programmgesteuert aus Indeed zu ziehen, kennst du den Witz längst: Der 403-Fehler ist kein Bug — er ist ein Feature des Verteidigungssystems von Indeed.
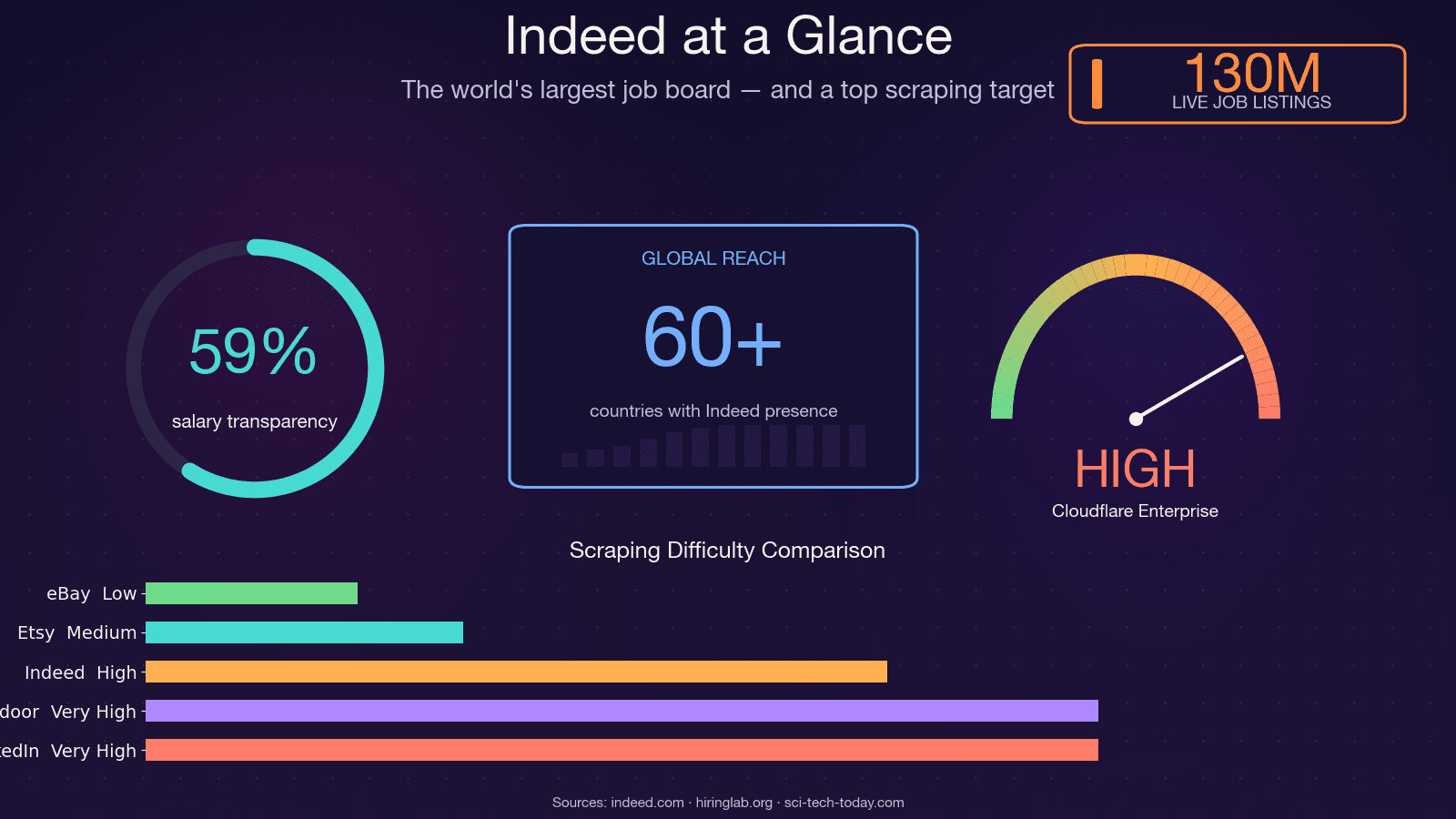
Indeed ist das weltweit größte Jobportal mit rund , zu jedem Zeitpunkt und Aktivitäten in . Damit ist die Plattform eine der reichsten Quellen für Arbeitsmarktdaten auf dem Planeten — und eine der am schwersten zu scrapenden. Der Open-Source-Scraper JobFunnel (mit Tausenden GitHub-Stars) wurde im Dezember 2025 von seinem Maintainer , nachdem der jahrelange Anti-Bot-Wettlauf verloren war. In den Worten des Maintainers: „Alle Nutzer können einige Jobs scrapen, werden aber schnell von Captchas getroffen, und das Scraping schlägt fehl, sodass keine Jobs zurückgegeben werden.“ Ein anderer Mitwirkender berichtete, dass schon ein CAPTCHA erschien. Also ja — das ist kein triviales Scraping-Ziel. In diesem Leitfaden zeige ich dir alle praktikablen Methoden, um Indeed mit Python zu scrapen, wie du die 403-Hürde tatsächlich überwindest, und — für alle, die das Debugging lieber komplett überspringen — eine No-Code-Alternative mit .
Was bedeutet es, Indeed mit Python zu scrapen?
Web-Scraping ist im Kern das automatisierte Extrahieren strukturierter Daten aus Webseiten. Wenn wir davon sprechen, Indeed mit Python zu scrapen, meinen wir ein Skript zu schreiben, das die Suchergebnisse und Stellen-Detailseiten von Indeed aufruft, das zugrunde liegende HTML (oder eingebettete Daten) ausliest und Felder wie Stellenbezeichnung, Unternehmen, Ort, Gehalt und Beschreibung in ein nutzbares Format überführt — etwa CSV, eine Datenbank oder ein Google Sheet.
Typische Python-Bibliotheken dafür sind Requests (für HTTP-Aufrufe), BeautifulSoup (für HTML-Parsing) und Selenium oder Playwright (für Browser-Automatisierung). Aber Indeed ist keine einfache statische Website. Es ist ein Hybrid: servergerendertes HTML mit einem eingebetteten JSON-Datenblock, abgesichert durch Cloudflare Bot Management. Das heißt, dein Scraper muss JavaScript-gerenderte Inhalte, wechselnde CSS-Klassennamen und aggressive Anti-Bot-Schutzmaßnahmen beherrschen — und das alles, bevor du überhaupt eine einzige Stellenbezeichnung parst.
Außerdem gibt es 2026 keine offizielle, kostenlose, nur lesende Indeed-API. Die alte Publisher Jobs API wurde um 2020 eingestellt, und übrig geblieben sind nur Arbeitgeber-Funktionen (Job Sync, Sponsored Jobs). Daher sind Scraping oder ein kostenpflichtiger Drittanbieter für Daten die einzigen realistischen Optionen.
Warum Indeed-Jobdaten scrapen?
Der Business-Case ist klar: Tausende Anzeigen manuell durchzusehen ist unpraktisch, und die Daten darin sind wirklich wertvoll.
| Anwendungsfall | Wer profitiert | Beispiel |
|---|---|---|
| Leadgenerierung | Sales- und Recruiting-Teams | Listen von einstellenden Unternehmen mit Kontaktdaten erstellen |
| Arbeitsmarktforschung | Analysten, HR-Teams | Trendfähigkeiten und Gehaltsbenchmarks nach Region identifizieren |
| Wettbewerbsanalyse | Arbeitgeber, Personaldienstleister | Einstellungsmuster und Gehaltsangebote von Wettbewerbern überwachen |
| Automatisierte Jobsuche für Privatpersonen | Jobsuchende | Anzeigen aus verschiedenen Regionen nach den eigenen Kriterien bündeln |
| Trainingsdaten für ML-Modelle | Data Scientists | Gehaltsprognosemodelle aus historischen Daten aufbauen |
Die Forschung des Indeed Hiring Lab selbst , dass Stellenausschreibungsdaten die BLS-JOLTS-Daten eng widerspiegeln und als nahezu Echtzeit-Indikator für den US-Arbeitsmarkt dienen können. Hedgefonds nutzen die Dynamik von Stellenanzeigen als alternatives Datensignal. HR-Teams benchmarken Vergütungen mithilfe gescrapter Gehaltsspannen. Und Recruiter erstellen Prospect-Listen aus Unternehmen, die aktiv einstellen.
Ein praktischer Hinweis: Gehaltsdaten auf Indeed werden zwar besser, sind aber weiterhin unvollständig. Mitte 2025 enthalten etwa Gehaltsangaben, aber nur rund nennen einen exakten Betrag — der Rest sind Spannen. Jede Gehaltsanalyse auf Basis von Indeed-Daten sollte diese Lücken berücksichtigen.
So wählst du deine Methode, um Indeed mit Python zu scrapen
Es gibt nicht den einen „richtigen“ Weg, Indeed zu scrapen. Der beste Ansatz hängt von deinem Kenntnisstand, der benötigten Datenmenge und dem Wartungsaufwand ab, den du akzeptieren willst. Ich habe alle vier großen Ansätze getestet, und so schneiden sie ab:
| Kriterium | BS4 + Requests | Selenium | Verstecktes JSON (window.mosaic) | No-Code (Thunderbit) |
|---|---|---|---|---|
| Schwierigkeit | Anfänger | Fortgeschrittene | Fortgeschritten bis sehr fortgeschritten | Keine (2 Klicks) |
| Geschwindigkeit | Schnell | Langsam (Browser-Rendering) | Schnell | Schnell (Cloud-Scraping) |
| JS-gerenderte Inhalte | Nein | Ja | Ja (eingebettete Daten) | Ja |
| Widerstand gegen Bot-Schutz | Niedrig | Mittel (erkennbar) | Mittel bis hoch | Hoch (automatisch gehandhabt) |
| Wartung bei HTML-Änderungen | Hoch (Selektoren brechen) | Hoch | Mittel (JSON-Struktur stabiler) | Keine (KI passt sich an) |
| Am besten geeignet für | Schnelle Prototypen | Dynamische Seiten, Login-geschützte Inhalte | Strukturierte Massendaten | Nicht-Entwickler, schnelle Ergebnisse |
Dieser Leitfaden geht jede Methode durch. Wenn du Python-Entwickler bist, solltest du die Abschnitte zu BS4, verstecktem JSON und Selenium lesen. Wenn du kein Coder bist (oder einfach genug vom 403-Debugging hast), spring direkt zum Thunderbit-Abschnitt.
Bevor du anfängst
- Schwierigkeitsgrad: Anfänger bis Fortgeschrittene (Python-Abschnitte); keiner (Thunderbit-Abschnitt)
- Benötigte Zeit: ca. 20–60 Minuten für das Python-Setup und den ersten Scrape; ca. 2 Minuten mit Thunderbit
- Was du brauchst: Python 3.9+, einen Code-Editor, den Chrome-Browser und (für den No-Code-Weg) die
Dein Python-Umfeld für das Indeed-Scraping einrichten
Bevor du irgendeinen Scraping-Code schreibst, richte zuerst deine Umgebung ein.
Die benötigten Bibliotheken installieren
Erstelle eine virtuelle Umgebung und installiere die Pakete, die du brauchst:
1python -m venv indeed_env
2source indeed_env/bin/activate # Unter Windows: indeed_env\Scripts\activate
3# Für den HTTP- + Parsing-Ansatz
4pip install requests beautifulsoup4 lxml httpx
5# Für den versteckten JSON-Ansatz (empfohlen)
6pip install curl_cffi parsel tenacity
7# Für den Browser-Automatisierungs-Ansatz
8pip install seleniumEin paar Hinweise:
curl_cffiist 2026 der Standard für das Scraping von Cloudflare-geschützten Seiten. Es imitiert echte Browser-TLS-Fingerprints, was einfachemrequestsundhttpxnicht möglich ist. Mehr dazu im Anti-Bot-Abschnitt.- Selenium 4.6+ bringt den Selenium Manager mit, sodass du ChromeDriver nicht mehr manuell herunterladen musst — die Browser-Binärdatei wird automatisch verwaltet.
- Verwende
lxmlals Parser-Backend für BeautifulSoup. Es ist ungefähr als der Standard-html.parser.
Deine Projektstruktur anlegen
Halte es einfach:
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/Alle Codebeispiele unten bauen auf scraper.py auf.
So scrapst du Indeed mit Python mit BeautifulSoup
Das ist der einsteigerfreundliche Ansatz: requests lädt die Seite und BeautifulSoup parst das HTML. Er ist am schnellsten eingerichtet, aber auf Indeed auch am fragilsten.
Schritt 1: Die Indeed-Such-URL zusammensetzen
Die Such-URLs von Indeed folgen einem vorhersehbaren Muster:
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>Beispiel: Suche nach „data analyst“ in „Austin, TX“ ab der ersten Seite:
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed paginiert in 10er-Schritten und hat eine harte Obergrenze von 1.000 Ergebnissen (start <= 990). Jeder Offset über 990 liefert stillschweigend dieselbe Seite zurück.
Schritt 2: Einen HTTP-Request mit passenden Headern senden
Indeed blockiert Requests mit den Standard-User-Agent-Strings von Python sofort. Du brauchst realistische Header:
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)Wenn du 200 bekommst, bist du vorerst drin. Wenn du 403 bekommst, hat Cloudflare dich erkannt. (Mehr dazu weiter unten.)
Schritt 3: Jobanzeigen aus dem HTML parsen
Verwende BeautifulSoup, um Jobkarten auszuwählen. Nutze data-testid-Attribute — sie sind stabiler als die zufälligen CSS-Klassennamen von Indeed:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"{len(jobs)} Jobs gefunden")Schritt 4: Paginierung behandeln
Gehe durch die Seiten, indem du den Parameter start erhöhst:
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # Erste 5 Seiten
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... wie oben parsen ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))Grenzen dieses Ansatzes
Ich sage es offen: BS4 + Requests ist 2026 die schwächste Methode für Indeed. Reines requests verwendet die TLS-Bibliothek der Python-Standardbibliothek, die einen erzeugt, den Cloudflare sofort als „kein Browser“ erkennt. Außerdem unterstützt es kein HTTP/2, das Indeed ausliefert. Du wirst wahrscheinlich nach ein paar Seiten blockiert. Und die CSS-Selektoren? Indeed rotiert Klassennamen wie css-1m4cuuf und jobsearch-JobComponent-embeddedBody-1n0gh5s — jeder Selektor darauf ist also eine tickende Zeitbombe.
Nutze diese Methode für schnelle Prototypen auf einer einzelnen Seite. Für alles in größerem Umfang solltest du den versteckten JSON-Ansatz verwenden.
So scrapst du Indeed mit Python mithilfe versteckter JSON-Daten
Das ist die Methode, die ich für die meisten Python-Entwickler empfehle. Statt fragile HTML-Elemente zu parsen, extrahierst du strukturierte Daten aus einer JavaScript-Variable im Seitenquelltext von Indeed: window.mosaic.providerData["mosaic-provider-jobcards"].
Jedes Feld, das dich interessiert — Stellenbezeichnung, Unternehmen, Ort, Gehalt, Job-Key, Veröffentlichungsdatum, Remote-Flag — steckt bereits in diesem JSON-Block. Kein JavaScript-Rendering erforderlich. Das Schema ist und damit deutlich robuster als DOM-Selektoren.
Schritt 1: Den Seiten-HTML abrufen
Verwende curl_cffi statt requests — es imitiert echte Browser-TLS-Fingerprints, was für das Überleben von Cloudflare entscheidend ist:
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))Warum curl_cffi? Es ist ein Python-Binding für curl-impersonate und reproduziert den exakten TLS ClientHello, den HTTP/2-SETTINGS-Frame und die Header-Reihenfolge echter Browser. Es ist der einzige aktiv gepflegte Python-HTTP-Client, der in einem einzigen Aufruf aushebelt. Unterstützte Impersonations-Ziele sind unter anderem chrome120, chrome124, chrome131, Safari- und Edge-Varianten.
Schritt 2: Das JSON mit einem regulären Ausdruck extrahieren
Der JSON-Block ist in einem <script>-Tag eingebettet. Ziehe ihn mit einem Regex heraus:
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"{len(results)} Jobs im versteckten JSON gefunden")
11else:
12 print("Verstecktes JSON nicht gefunden — möglicher Block oder Seitenänderung")Schritt 3: Job-Felder aus dem JSON parsen
Jeder Eintrag in results enthält mehr Daten als das, was auf der Seite sichtbar ist:
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })Das JSON enthält häufig auch Gehaltsschätzungen, Taxonomie-Attribute (Skill-Tags) und Unternehmensbewertungen, die im gerenderten HTML nicht immer sichtbar sind.
Schritt 4: Mehrere Seiten scrapen
Nutze tierSummaries im JSON, um die Gesamtzahl der Ergebnisse zu verstehen, und iteriere dann:
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # Erste 5 Seiten
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"Insgesamt: {len(all_jobs)} Jobs gescrapt")Warum verstecktes JSON robuster ist
Die Struktur window.mosaic.providerData ändert sich deutlich seltener als CSS-Klassennamen. Du bekommst saubere, strukturierte Daten, ohne unübersichtliches HTML zu parsen. Trotzdem brauchst du weiterhin Anti-Bot-Maßnahmen (Header, Pausen, Proxys) — darauf gehen wir als Nächstes ein.
So scrapst du Indeed mit Python mit Selenium
Selenium ist der Ansatz über Browser-Automatisierung. Er ist nützlich, wenn du mit der Seite interagieren musst — etwa um in Job-Detail-Panels zu klicken, Login-geschützte Inhalte zu verarbeiten oder dynamisch geladene Beschreibungen zu erfassen, die im ursprünglichen HTML nicht enthalten sind.
Wann du Selenium statt HTTP-Clients verwenden solltest
- Indeed lädt einige Inhalte dynamisch nach (vollständige Stellenbeschreibungen im rechten Seitenpanel)
- Du musst Seiten scrapen, die Session-State oder Login erfordern
- Du scrapest in kleinem Umfang, bei dem Geschwindigkeit nicht kritisch ist
Schneller Rundgang
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # Headless ist leichter erkennbar — mit Vorsicht verwenden
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()Grenzen
Selenium ist langsam — jede Seite muss vollständig im Browser gerendert werden. Headless Chrome ist (Cloudflare prüft navigator.webdriver, WebGL-Vendor-Strings, die Anzahl der Plugins und mehr). Selbst undetected-chromedriver verzögert die Erkennung nur; er verhindert sie nicht dauerhaft. Und wie bei BS4 brechen deine Selektoren, wenn Indeed seine UI aktualisiert.
Für die meisten Anwendungsfälle liefert der versteckte JSON-Ansatz dieselben Daten schneller und mit weniger Wartungsaufwand. Hebe Selenium für Randfälle auf, bei denen du wirklich einen Browser brauchst.
Wie du 403-Fehler beim Scrapen von Indeed mit Python vermeidest
Das ist der Abschnitt, der am wichtigsten ist. Wenn du über eine frustrierte Google-Suche hier gelandet bist, bist du genau richtig.
Warum Indeed deinen Scraper blockiert
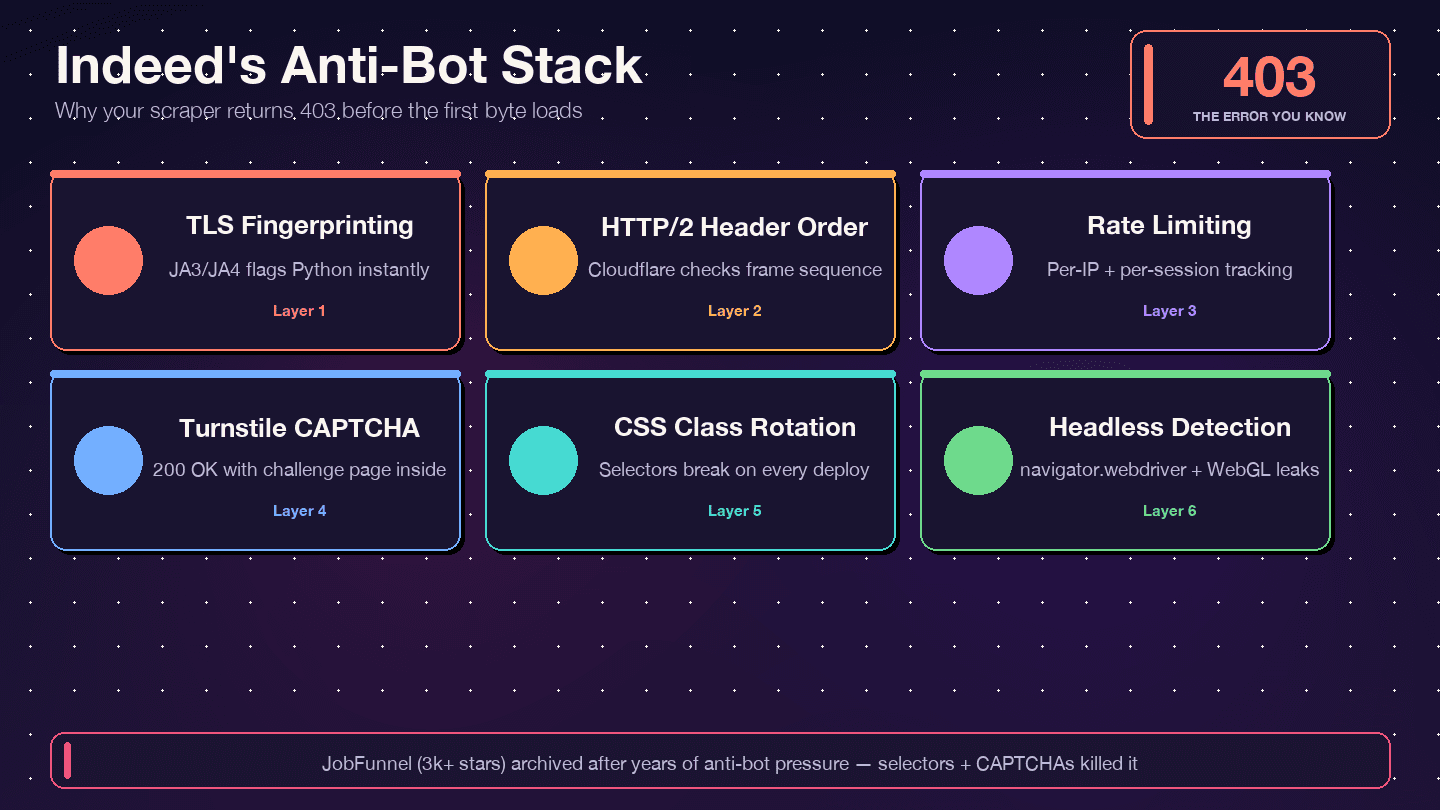
Indeed verwendet — nicht DataDome, nicht PerimeterX. Die Response-Header bestätigen das: server: cloudflare, cf-ray und das Bot-Management-Cookie __cf_bm. Cloudflare prüft deinen TLS-Fingerprint (JA3/JA4), die Reihenfolge der HTTP/2-Header, Request-Muster und Browsersignale. Wenn etwas davon unnatürlich wirkt, bekommst du einen 403, 429, 503 oder — im heimtückischsten Fall — ein 200 OK mit einer Turnstile-Herausforderungsseite statt echter Jobdaten.
User-Agent und Request-Header rotieren
Ein einzelner, statischer User-Agent ist der schnellste Weg zur Sperre. Rotiere aus einem Pool aktueller, realistischer Strings. Wichtig: Die Minor-Versionen von Chrome sind seit der User-Agent-Reduktion — erfinde also keine nicht-null Minor-Versionen, sonst schlagen Anti-Bots Alarm.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}Stelle außerdem sicher, dass deine sec-ch-ua Client Hints zur UA-Version passen. Ein sec-ch-ua: "Chrome";v="131" zusammen mit einem User-Agent, der Chrome 145 behauptet, ist ein sofortiges Warnsignal.
Zufällige Pausen zwischen den Requests einbauen
Feste Intervalle fallen durch Mustererkennung auf. Nutze stattdessen zufälligen Jitter:
1import time, random
2# Zwischen jedem Request
3time.sleep(random.uniform(3, 6))
4# Beim erneuten Versuch nach einer Blockade
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))Der Feldkonsens aus und liegt bei 3–6 Sekunden zwischen Requests pro IP, mit einer harten Obergrenze von etwa 100 Requests pro IP und Session, bevor rotiert wird.
Proxy-Rotation einsetzen
Das ist der größte einzelne Erfolgsfaktor. Datacenter-Proxys aus AWS-/GCP-Bereichen erreichen bei Cloudflare-Enterprise-Zielen nur etwa 5–15 % Erfolgsrate — auf Indeed praktisch unbrauchbar. Residential Proxys plus korrekte TLS-Fingerprints steigern das auf 80–95 %.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)Die Preise für Residential Proxys liegen 2026 je nach Anbieter und Bindung ungefähr bei . Für Indeed solltest du speziell mit einem kleinen Pool beginnen und bei Bedarf skalieren.
403-, 429- und 503-Statuscodes sauber behandeln
Versuche nicht einfach blind erneut. Verschiedene Statuscodes bedeuten Verschiedenes:
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # Prüfe den heimtückischen Fall „200 mit Challenge“
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — blockiert. Proxy wird rotiert, Versuch {attempt + 1}")
18 elif r.status_code == 429:
19 print(f"429 — Rate-Limit erreicht. Verlangsamen.")
20 elif r.status_code == 503:
21 print(f"503 — Server überlastet oder JS-Challenge.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"Request-Fehler: \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"Nach \{max_retries\} Versuchen fehlgeschlagen: \{url\}")Der Fall „200 mit Challenge“ ist der kniffligste. Prüfe den Response-Body immer auf cf-turnstile- oder Just a moment-Marker, bevor du einen 200er als Erfolg wertest.
Die einfachere Alternative: Lass Thunderbit den Anti-Bot-Schutz übernehmen
Für Nutzer, die keine Proxy-Pools, Header-Rotation und TLS-Fingerprint-Imitation bauen und pflegen wollen, übernimmt das Cloud-Scraping von CAPTCHAs, Proxy-Rotation und Anti-Bot-Schutz automatisch. Kein Proxy-Setup, keine curl_cffi-Konfiguration, keine CAPTCHA-Solving-Bibliotheken. Das ist der Weg des geringsten Widerstands, wenn du einfach nur die Daten brauchst.
Warum dein Indeed-Scraper ständig kaputtgeht (und wie du das behebst)
Die 403-Mauer ist der akute Schmerz. Der chronische Schmerz ist die Wartung — Scraper, die heute funktionieren, sind nächste Woche kaputt und liefern stillschweigend leere Daten oder veraltete Ergebnisse.
Wie Indeed deine Selektoren kaputtmacht
Indeed rotiert CSS-Klassennamen aggressiv. Der Leitfaden von Bright Data , dass Klassen wie css-1m4cuuf und css-1rqpxry „scheinbar zufällig generiert werden — vermutlich zur Build-Zeit“. A/B-Tests sorgen dafür, dass verschiedene Sessions unterschiedliche Seitenlayouts sehen. Und DOM-Umstrukturierungen passieren ohne Vorwarnung.
Die JobFunnel-Geschichte ist lehrreich. Ein Mitwirkender berichtete: „CaptchaBuster hat das CAPTCHA erfolgreich entschärft, und der Grund, warum die Seite weiterhin nicht erfolgreich gescrapt wurde, [liegt] in veralteten Beautiful-Soup-Selektoren.“ Der Scraper war nicht blockiert — er griff nur auf die falschen Elemente zu.
Strategie: Verstecktes JSON statt DOM-Parsing bevorzugen
Der window.mosaic.providerData-Block ist seit mindestens 2023 schema-stabil. Der Pfad metaData.mosaicProviderJobCardsModel.results[] ist . DOM-Selektoren brechen monatlich. JSON-Extraktion bricht höchstens jährlich — wenn überhaupt.
Strategie: Datenattribute statt Klassennamen verwenden
Wenn du doch ins DOM musst, wähle funktionale Attribute:
| Selektor | Zweck |
|---|---|
[data-testid="slider_item"] | Container jeder Jobkarte |
[data-testid="job-title"] oder h2.jobTitle > a | Link zur Stellenbezeichnung |
[data-testid="company-name"] | Name des Arbeitgebers |
[data-testid="text-location"] | Ortsangabe |
data-jk="<jobkey>" auf jeder Karte | Der stabilste Hook überhaupt — seit 2019 unverändert |
Assertion-Checks hinzufügen, um veraltete Selektoren zu erkennen
Lass deinen Scraper niemals stillschweigend mit null Ergebnissen laufen. Füge nach jedem Abruf eine Prüfung hinzu:
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed hat bei start=\{start\} einen leeren Ergebnisdatensatz zurückgegeben — "
4 "möglicher Block, CAPTCHA oder Drift der Selektoren. "
5 f"Die ersten 500 Zeichen der Antwort: {html[:500]}"
6)Protokolliere im Fehlerfall die ersten 500 bis 2000 Zeichen der Rohantwort. So erkennst du sofort, ob du eine Turnstile-Challenge, eine Login-Sperre oder eine Schemaänderung erhalten hast. Führe außerdem täglich einen CI-Smoke-Test gegen eine feste Suche aus (z. B. q=python&l=remote), der auf nicht-null Ergebnisse prüft.
Die KI-Alternative: Scraper, die nie brechen
Die KI von Thunderbit liest die Seitenstruktur jedes Mal neu — sie verlässt sich nicht auf fest codierte Selektoren oder Regex-Muster. Wenn Indeed sein HTML ändert, passt sich Thunderbit automatisch an. Das löst genau den Wartungsaufwand, den Forennutzer immer wieder als ihr größtes Ärgernis nennen. Wenn du schon einmal mit einer Slack-Nachricht aufgewacht bist, die sagte: „Der Scraper liefert schon wieder leere Zeilen“, dann kennst du den Wert davon, es nicht selbst reparieren zu müssen.
Indeed scrapen, ohne Python zu schreiben: Die No-Code-Alternative
Jeder konkurrierende Leitfaden setzt voraus, dass du Python-Code schreiben wirst. Doch die Forendaten erzählen eine andere Geschichte. Nutzer sagen Dinge wie „Es ist einfach so schwierig mit ständigen Bugs und Fehlern“, und manche empfehlen sogar, jemanden auf Fiverr zu beauftragen, nur um an die Daten zu kommen. Wenn dir das bekannt vorkommt, ist dieser Abschnitt dein Ausweg.
So scrapst du Indeed mit Thunderbit (Schritt für Schritt)
Schritt 1: Installiere die aus dem Chrome Web Store. Der Einstieg ist kostenlos.
Schritt 2: Öffne in deinem Browser eine Indeed-Suchergebnisseite — zum Beispiel https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Schritt 3: Klicke auf das Thunderbit-Symbol in deiner Browser-Toolbar und dann auf „KI-Felder vorschlagen“. Thunderbits KI scannt die Seite und erkennt automatisch Spalten wie Stellenbezeichnung, Unternehmen, Ort, Gehalt, Job-URL und Veröffentlichungsdatum. Du kannst die vorgeschlagenen Felder prüfen und anpassen — nicht benötigte Spalten entfernen oder eigene hinzufügen, indem du in einfachem Deutsch beschreibst, was du willst.
Schritt 4: Klicke auf „Scrape“. Thunderbit extrahiert die Daten von der Seite und zeigt sie in einer strukturierten Tabelle an. Du solltest Zeilen mit Jobanzeigen und den von dir konfigurierten Feldern sehen.
Mit Subpage-Scraping anreichern
Nach dem Scrapen der Übersichtsseite klicke auf „Subpages scrapen“, damit Thunderbit jede einzelne Stellen-Detailseite aufruft. Es zieht die vollständige Stellenbeschreibung, Qualifikationen, Benefits und Bewerbungslinks — ohne zusätzliche Einrichtung. Das entspricht funktional einem zweiten Python-Scraper, der jede /viewjob?jk=<jobkey>-URL besucht, nur eben mit einem Klick.
Paginierung automatisch behandeln
Thunderbit verarbeitet die klickbasierte Paginierung von Indeed automatisch. Du musst keine Offset-URLs manuell zusammenbauen und keine Paginierungsschleifen schreiben. Es klickt sich durch die Seiten und fasst die Ergebnisse zusammen.
In deine bevorzugten Tools exportieren
Exportiere die gescrapten Daten kostenlos in CSV, Excel, Google Sheets, Airtable oder Notion — . Du musst keinen csv.writer()- oder pandas.to_csv()-Code schreiben.
Wann du Python und wann Thunderbit verwenden solltest
| Szenario | Bestes Tool |
|---|---|
| Eigene Datenpipelines, geplante Automatisierung per Cron/Airflow | Python |
| Integration in eine größere Codebasis | Python |
| Hochgradig angepasste Parsing-Logik | Python |
| Einmalige Recherche oder Marktanalyse | Thunderbit |
| Nicht-technische Teammitglieder brauchen Daten | Thunderbit |
| Daten jetzt sofort, ohne 403-Debugging | Thunderbit |
| Anreicherung von Unterseiten ohne Setup | Thunderbit |
Zeitvergleich: Python-Setup plus Anti-Bot-Debugging = Stunden bis Tage (besonders beim ersten Mal). Thunderbit = unter 2 Minuten für dieselben Daten. Ich sage nicht, dass Python falsch ist — ich sage, es hängt davon ab, was du brauchst.
Ist das Scrapen von Indeed legal? Das solltest du wissen
Keine der gut platzierten Indeed-Scraping-Anleitungen geht auf die Legalität ein, was überrascht, denn die Frage „Ist das Scrapen von Indeed legal?“ taucht in Foren ständig auf. Das ist keine Rechtsberatung, aber hier ist die Lage.
Die Nutzungsbedingungen von Indeed
In den AGB von Indeed () gibt es keine pauschale Klausel „kein Scraping“. Das einzige ausdrückliche Automatisierungsverbot ist Abschnitt A.3.5, der die „Verwendung von Automatisierung, Skripten oder Bots zur Automatisierung des Indeed-Apply-Prozesses“ verbietet. Das ist eng auf den Bewerbungsprozess beschränkt, nicht auf das passive Lesen öffentlicher Stellenanzeigen. Das wichtigste Durchsetzungsinstrument von Indeed ist technisch — Cloudflare-Challenges, IP-Sperren, Device-Fingerprinting — nicht der Gerichtssaal.
Relevante Rechtsprechung
Der meistzitierte US-Fall ist hiQ Labs v. LinkedIn. Der 9th Circuit , dass das Scrapen öffentlich zugänglicher Daten „wahrscheinlich nicht gegen den CFAA“ (Computer Fraud and Abuse Act) verstößt. Allerdings wurde hiQ später wegen , weil Mitarbeiter gefälschte LinkedIn-Profile erstellt und den AGB zugestimmt hatten.
Noch jüngst führte Meta v. Bright Data (N.D. Cal., Jan. 2024) zu einer noch klareren Entscheidung. Richter Chen , dass die Nutzungsbedingungen von Facebook und Instagram das ausgeloggte Scraping öffentlicher Daten nicht verbieten. Meta zog die übrigen Ansprüche im folgenden Monat freiwillig zurück.
Indeeds robots.txt
Indeed untersagt dem Standard-User-agent: * den Zugriff auf /jobs/ und /job/, erlaubt aber Googlebot und Bingbot ausdrücklich den Zugriff auf /viewjob? — also die einzelnen Job-Detailseiten. KI-Trainings-Crawler (GPTBot, CCBot, anthropic-ai) sind stark eingeschränkt. robots.txt ist in den USA nicht rechtlich bindend, aber ihre Beachtung ist Best Practice und ein Zeichen guten Willens.
Praktische Leitlinien für verantwortungsvolles Scraping
- Scrape nur öffentlich zugängliche Daten — niemals einloggen, niemals Fake-Konten erstellen
- Beachte Rate Limits: 1 Request alle 3–6 Sekunden pro IP, nur geringe Parallelität
- Veröffentliche gescrapte Daten nicht als dein eigenes Jobportal neu
- Nutze die Daten für persönliche oder interne Recherche, nicht für kommerziellen Weiterverkauf ohne Erlaubnis
- Verwirf oder hashe personenbezogene Daten, die du nicht brauchst; setze eine Aufbewahrungsgrenze für personenbezogene Randdaten
- Wenn du in großem Umfang oder in der EU/im Vereinigten Königreich arbeitest, konsultiere einen Anwalt — die Transparenzpflichten aus Artikel 14 der DSGVO gelten für gescrapte personenbezogene Daten
Das Risikospektrum: Automatisierte Jobsuche für den persönlichen Gebrauch liegt am unteren Ende. Der groß angelegte kommerzielle Weiterverkauf von Indeed-Daten liegt am oberen Ende.
Fazit und wichtigste Erkenntnisse
Indeed mit Python zu scrapen ist machbar, aber kein Wochenendprojekt, das man einfach laufen lässt und dann vergisst. Der Cloudflare-Schutz von Indeed, wechselnde Selektoren und aggressive Anti-Bot-Maßnahmen bedeuten, dass du mit den richtigen Werkzeugen und den richtigen Erwartungen herangehen musst.
Das würde ich aus all dem mitnehmen:
- Indeed ist die reichhaltigste Quelle für Arbeitsmarktdaten im Web — 350 Mio. monatliche Besucher, 130 Mio. Anzeigen — wehrt sich aber sehr stark gegen Scraper.
- Die Extraktion des versteckten JSONs (
window.mosaic.providerData) ist der robusteste Python-Ansatz. Das Schema ist seit Jahren stabil, während CSS-Selektoren monatlich brechen. curl_cffimit Browser-Imitation ist 2026 der Standard-HTTP-Client für Cloudflare-geschützte Seiten. Reinesrequestsundhttpxwerden schon an ihrem TLS-Fingerprint geblockt.- Verwende immer rotierende Header, zufällige Pausen und Residential Proxys, um 403-Fehler zu vermeiden. Datacenter-Proxys sind gegen Cloudflare Enterprise nahezu nutzlos.
- Füge Assertion-Checks hinzu, damit du sofort merkst, wenn Selektoren brechen oder dir statt Jobdaten eine Challenge-Seite ausgeliefert wird.
- Für nicht-technische Nutzer oder alle, die einfach schnell Ergebnisse wollen, bietet einen No-Code-, KI-gestützten Weg, der sich automatisch an Seitenänderungen anpasst — keine Proxys, kein Debugging, keine Wartung.
Wenn du den No-Code-Weg ausprobieren willst, bietet , sodass du es ohne Verpflichtung auf Indeed testen kannst. Und wenn du den Python-Weg gehst, sind die obigen Codebeispiele ein solider Startpunkt — behandle Anti-Bot-Resilienz aber bitte als erstklassige Anforderung und nicht als nachträglichen Gedanken.
Für mehr zu Web-Scraping-Ansätzen und -Tools schau dir unsere Leitfäden zu , und an. Du kannst dir außerdem Tutorials auf dem ansehen.
FAQs
Welche Python-Bibliotheken eignen sich am besten zum Scrapen von Indeed?
Für HTTP-Requests ist curl_cffi 2026 die stärkste Wahl — es imitiert echte Browser-TLS-Fingerprints, was zum Umgehen von Cloudflare essenziell ist. httpx mit HTTP/2 ist eine brauchbare Alternative für weniger geschützte Ziele. Für das HTML-Parsing bleibt BeautifulSoup4 mit lxml der Standard. Für Browser-Automatisierung funktionieren Playwright (mit playwright-stealth) oder undetected-chromedriver, auch wenn beide zunehmend erkennbar sind. Der Regex-Ansatz mit verstecktem JSON (window.mosaic.providerData) umgeht aufwendiges Parsing vollständig.
Warum bekomme ich beim Scrapen von Indeed ständig 403-Fehler?
Indeed nutzt Cloudflare Bot Management, das deinen TLS-Fingerprint (JA3/JA4), die Reihenfolge der HTTP/2-Header, Request-Muster und das Browserverhalten prüft. Wenn du einfach requests verwendest, erkennt der TLS-Fingerprint dich sofort als Python-Skript — der 403 kommt, bevor deine Header überhaupt gelesen werden. Beheben kannst du das mit curl_cffi und Browser-Imitation, rotierenden realistischen User-Agent-Strings, zufälligen Pausen (3–6 Sekunden) und Residential Proxys. Prüfe außerdem den Fall „200 mit Turnstile-Challenge“ — suche in den Response-Bodies nach cf-turnstile-Markern.
Kann ich Indeed ohne Programmierung scrapen?
Ja. Tools wie ermöglichen es dir, Indeed-Jobanzeigen mit wenigen Klicks zu extrahieren — Chrome-Erweiterung installieren, eine Indeed-Suchseite öffnen, auf „KI-Felder vorschlagen“ klicken und dann auf „Scrape“. Thunderbits KI erkennt Felder wie Stellenbezeichnung, Unternehmen, Ort und Gehalt automatisch. Es übernimmt Paginierung, die Anreicherung von Unterseiten (vollständige Stellenbeschreibungen) und Anti-Bot-Schutz automatisch. Exportiere kostenlos nach CSV, Google Sheets, Airtable oder Notion.
Wie oft ändert Indeed seine HTML-Struktur?
Indeed rotiert regelmäßig CSS-Klassennamen (z. B. css-1m4cuuf, zufällig gehashte Strings) und strukturiert DOM-Elemente ohne Ankündigung um. A/B-Tests bedeuten, dass unterschiedliche Nutzer gleichzeitig unterschiedliche Layouts sehen können. Der Ansatz mit verstecktem JSON (window.mosaic.providerData) ist deutlich stabiler — das Schema ist seit mindestens 2023 konsistent. Wenn du DOM-Selektoren verwenden musst, ziele lieber auf data-testid-Attribute und data-jk (Job-Key) als auf CSS-Klassen.
Ist es legal, Indeed zu scrapen?
Das ausgeloggte Scraping öffentlich zugänglicher Indeed-URLs dürfte in den USA nach dem 9th-Circuit-Urteil hiQ v. LinkedIn (2022) und der Entscheidung Meta v. Bright Data (2024) wahrscheinlich keine CFAA-Haftung auslösen. In den AGB von Indeed ist speziell die Automatisierung des Bewerbungsprozesses verboten, nicht das passive Lesen öffentlicher Anzeigen. Trotzdem gilt: immer verantwortungsvoll scrapen — nicht einloggen, keine Fake-Konten erstellen, Rate Limits beachten, Daten nicht als eigenes Jobportal neu veröffentlichen und personenbezogene Daten (z. B. Namen von Recruitern, E-Mails) unter DSGVO/CCPA sorgfältig behandeln. Bei kommerziellen Großprojekten solltest du einen Anwalt konsultieren.
Mehr erfahren