

Monat für Monat laufen über Google Shopping mehr als 1,2 Milliarden Produktsuchen. Dahinter steckt ein gewaltiger Bestand an Preisdaten, Produkttrends und Händlerinfos – zusammengetragen aus Tausenden Onlineshops und direkt im Browser einsehbar.
Diese Daten aber aus Google Shopping in eine Tabelle zu bekommen, ist der Punkt, an dem es kompliziert wird. Die verfügbaren Wege reichen vom Browser-Add-on ohne eine Zeile Code bis zum kompletten Python-Skript – und die Erfahrung schwankt entsprechend zwischen „erstaunlich unkompliziert“ und „dritter Tag in Folge mit CAPTCHA-Debugging“. Viele Anleitungen setzen voraus, dass du Python-Entwickler bist. Tatsächlich brauchen Google-Shopping-Daten aber vor allem E-Commerce-Teams, Pricing-Analysten und Marketingverantwortliche, also Leute, die schlicht Zahlen wollen, ohne dafür selbst zu programmieren. Deshalb stellt dieser Leitfaden drei Methoden vor, von der einfachsten bis zur technischsten, sodass du den Weg nehmen kannst, der zu deinem Kenntnisstand und deinem Zeitbudget passt.
Was sind Google Shopping-Daten?
Google Shopping ist eine Produktsuchmaschine. Tippst du „kabellose Noise-Cancelling-Kopfhörer“ ein, listet Google Angebote aus Dutzenden Onlineshops auf – mit Produkttiteln, Preisen, Händlern, Bewertungen, Bildern und Links. Im Grunde ein laufend aktualisierter Katalog dessen, was im Netz gerade zum Verkauf steht.
Warum Google Shopping-Daten scrapen?
Eine einzelne Produktseite verrät dir herzlich wenig. Erst wenn Hunderte davon sauber in einer Tabelle nebeneinanderstehen, treten die Muster hervor.
Diese Anwendungsfälle begegnen einem in der Praxis am häufigsten:
| Anwendungsfall | Wer profitiert | Wonach wird gesucht |
|---|---|---|
| Wettbewerbsanalyse bei Preisen | Ecommerce-Teams, Pricing-Analysten | Konkurrenzpreise, Rabattmuster, Preisentwicklungen über Zeit |
| Produkttrend-Erkennung | Marketing-Teams, Produktmanager | Neue Produkte, wachsende Kategorien, Review-Dynamik |
| Ad-Intelligence | PPC-Manager, Growth-Teams | Gesponserte Listings, wer bietet mit, Anzeigenhäufigkeit |
| Händler-/Lead-Recherche | Vertriebsteams, B2B | Aktive Händler, neue Verkäufer in einer Kategorie |
| MAP-Überwachung | Brand Manager | Händler, die Mindestpreisrichtlinien verletzen |
| Bestands- und Sortimentstracking | Category Manager | Verfügbarkeit, Lücken im Produktsortiment |
Inzwischen setzen 78 % der US-Händler auf KI-gestützte Pricing-Tools, und Unternehmen, die in Preis-Wettbewerbsinformationen investieren, berichten von Renditen bis zum 29-Fachen. Amazon passt seine Preise etwa alle 10 Minuten an. Wer Konkurrenzpreise da noch von Hand abgleicht, hat die Rechnung längst verloren.
Google Shopping-Daten mit KI scrapen Get Started Free
Thunderbit ist eine KI-Web-Scraper-Chrome-Erweiterung, mit der Business-Anwender Daten von Websites mithilfe von KI extrahieren können. Besonders praktisch ist sie für Ecommerce-Teams, Pricing-Analysten und Marketingverantwortliche, die strukturierte Google-Shopping-Daten ohne Programmierung brauchen.
Welche Daten kann man aus Google Shopping eigentlich scrapen?
Bevor du dich für ein Tool entscheidest oder auch nur die erste Codezeile schreibst, solltest du wissen, welche Felder überhaupt zur Verfügung stehen – und welche etwas mehr Aufwand bedeuten.
Felder aus den Google-Shopping-Suchergebnissen
Führst du eine Suche in Google Shopping aus, enthält jede Produktkarte in den Ergebnissen Folgendes:
| Feld | Typ | Beispiel | Hinweise |
|---|---|---|---|
| Produkttitel | Text | "Sony WH-1000XM5 Wireless Headphones" | Immer vorhanden |
| Preis | Zahl | 278,00 $ | Kann Rabattpreis + Originalpreis anzeigen |
| Händler/Shop | Text | "Best Buy" | Pro Produkt können mehrere Händler angezeigt werden |
| Bewertung | Zahl | 4,7 | Von 5 Sternen; nicht immer sichtbar |
| Anzahl der Bewertungen | Zahl | 12.453 | Bei neueren Produkten manchmal nicht vorhanden |
| Produktbild-URL | URL | https://... | Kann beim ersten Laden einen Base64-Platzhalter liefern |
| Produktlink | URL | https://... | Führt zur Google-Produktseite oder direkt zum Shop |
| Versandinformationen | Text | "Kostenloser Versand" | Nicht immer vorhanden |
| Gesponsert-Tag | Boolesch | Ja/Nein | Kennzeichnet bezahlte Platzierung – nützlich für Ad-Analysen |
Felder von Produktdetailseiten (Subpage-Daten)
Klickst du in Google Shopping auf eine einzelne Produktdetailseite, öffnet sich ein deutlich umfangreicherer Datensatz:
| Feld | Typ | Hinweise |
|---|---|---|
| Vollständige Beschreibung | Text | Erfordert den Besuch der Produktseite |
| Alle Händlerpreise | Zahl (mehrere) | Preisvergleich nebeneinander über verschiedene Händler hinweg |
| Spezifikationen | Text | Je nach Produktkategorie unterschiedlich (Maße, Gewicht usw.) |
| Einzelne Bewertungstexte | Text | Vollständige Rezensionen von Käufern |
| Vor- und Nachteile | Text | Wird von Google manchmal automatisch erzeugt |
Um an diese Felder zu kommen, musst du nach dem Scraping der Suchergebnisse jede einzelne Produkt-Subpage aufrufen. Tools mit Subpage-Scraping nehmen dir diesen Schritt ab – den Ablauf zeige ich weiter unten.
Drei Wege, Google Shopping-Daten zu scrapen (Wähle deinen Ansatz)

Drei Methoden, von der einfachsten bis zur technischsten. Such dir die Zeile heraus, die zu deiner Lage passt, und spring direkt dorthin:
| Methode | Kenntnisstand | Einrichtungszeit | Anti-Bot-Schutz | Am besten geeignet für |
|---|---|---|---|---|
| No-Code (Thunderbit Chrome-Erweiterung) | Anfänger | ~2 Minuten | Wird automatisch gehandhabt | Ecommerce-Teams, Marketing, einmalige Recherchen |
| Python + SERP API | Fortgeschritten | ~30 Minuten | Über die API abgewickelt | Entwickler mit Bedarf an programmgesteuertem, wiederholbarem Zugriff |
| Python + Playwright (Browser-Automation) | Fortgeschritten bis Experte | ~1 Stunde+ | Musst du selbst managen | Individuelle Pipelines, Sonderfälle |
Methode 1: Google Shopping-Daten ohne Code scrapen (mit Thunderbit)
- Schwierigkeitsgrad: Anfänger
- Benötigte Zeit: ~2–5 Minuten
- Was du brauchst: Chrome-Browser, Thunderbit Chrome-Erweiterung (kostenlose Stufe reicht), eine Google-Shopping-Suchanfrage
Der direkteste Weg von „Ich brauche Google-Shopping-Daten“ zu „Hier ist meine Tabelle“. Kein Code, keine API-Keys, keine Proxy-Konfiguration. Diesen Ablauf habe ich schon Dutzenden Kolleginnen und Kollegen ohne technischen Hintergrund gezeigt – steckengeblieben ist niemand.
Schritt 1: Thunderbit installieren und Google Shopping öffnen
Installiere den Thunderbit AI Web Scraper aus dem Chrome Web Store und leg dir ein kostenloses Konto an.
Steuere anschließend Google Shopping an. Du kannst direkt shopping.google.com öffnen oder in einer normalen Google-Suche den Shopping-Tab nutzen. Suche nach dem Produkt oder der Kategorie, die dich interessiert – etwa „kabellose Noise-Cancelling-Kopfhörer“.
Daraufhin sollte ein Raster mit Produktlisten, Preisen, Händlern und Bewertungen erscheinen.
Schritt 2: Auf „AI Suggest Fields“ klicken, um Spalten automatisch zu erkennen
Klicke auf das Thunderbit-Erweiterungssymbol, um die Seitenleiste zu öffnen, und wähle dann „AI Suggest Fields“. Die KI scannt die Google-Shopping-Seite und schlägt Spalten vor: Produkttitel, Preis, Händler, Bewertung, Anzahl der Bewertungen, Bild-URL, Produktlink.
Sieh dir die vorgeschlagenen Felder an. Du kannst Spalten umbenennen, überflüssige entfernen oder eigene hinzufügen. Brauchst du es präziser – etwa „nur den numerischen Preis ohne Währungssymbol extrahieren“ –, hinterlegst du der Spalte einfach einen Field AI Prompt.
Im Thunderbit-Panel bekommst du eine Vorschau der Spaltenstruktur.
Schritt 3: Auf „Scrape“ klicken und Ergebnisse prüfen
Klicke auf den blauen Button „Scrape“. Thunderbit übernimmt alle sichtbaren Produkte und überführt sie in eine strukturierte Tabelle.
Mehrere Seiten? Die Seitennavigation regelt Thunderbit automatisch – per Klick durch die Seiten oder per Scrollen, um weitere Ergebnisse nachzuladen, je nach Layout. Bei vielen Ergebnissen hast du die Wahl zwischen Cloud Scraping (schneller, bis zu 50 Seiten gleichzeitig, läuft über Thunderbits verteilte Infrastruktur) und Browser Scraping (nutzt deine eigene Chrome-Sitzung – praktisch, wenn Google regionsabhängige Ergebnisse zeigt oder ein Login nötig ist).
In meinen Tests dauerte das Scrapen von 50 Produktlisten rund 30 Sekunden. Dieselbe Aufgabe von Hand, also jede Liste öffnen und Titel, Preis, Händler und Bewertung kopieren, hätte über 20 Minuten verschlungen.
Schritt 4: Daten mit Subpage-Scraping anreichern
Nach dem ersten Scraping klickst du im Thunderbit-Panel auf „Scrape Subpages“. Die KI ruft jede Produktdetailseite auf und ergänzt deine Tabelle um weitere Felder – vollständige Beschreibungen, alle Händlerpreise, Spezifikationen und Bewertungen.
Eine zusätzliche Konfiguration ist nicht nötig – die KI erkennt die Struktur der Detailseiten und holt die relevanten Daten heraus. Auf diese Weise hatte ich in weniger als 5 Minuten eine komplette Wettbewerbs-Matrix für 40 Produkte beisammen (Produkt + alle Händlerpreise + Spezifikationen).
Thunderbit für Google-Shopping-Scraping testen
Schritt 5: In Google Sheets, Excel, Airtable oder Notion exportieren
Klicke auf „Export“ und wähle dein Ziel – Google Sheets, Excel, Airtable oder Notion. Alles kostenlos. Auch CSV- und JSON-Downloads stehen bereit.
Zwei Klicks zum Scrapen, ein Klick zum Exportieren. Das passende Python-Skript dagegen? Rund 60 Zeilen Code, Proxy-Konfiguration, CAPTCHA-Handling und laufende Wartung.
Methode 2: Google Shopping-Daten mit Python + SERP API scrapen
- Schwierigkeitsgrad: Fortgeschritten
- Benötigte Zeit: ~30 Minuten
- Was du brauchst: Python 3.10+, die Bibliotheken
requestsundpandas, einen SERP-API-Schlüssel (ScraperAPI, SerpApi oder ähnlich)
Brauchst du programmgesteuerten, wiederholbaren Zugriff auf Google-Shopping-Daten, ist eine SERP API der verlässlichste Python-basierte Weg. Anti-Bot-Maßnahmen, JavaScript-Rendering, Proxy-Rotation – das alles läuft im Hintergrund ab. Du schickst eine HTTP-Anfrage und erhältst strukturiertes JSON zurück.
Schritt 1: Python-Umgebung einrichten
Installiere Python 3.12 (2025–2026 die sicherste Standardwahl für den Produktiveinsatz) und die nötigen Pakete:
pip install requests pandas
Melde dich bei einem SERP-API-Anbieter an. SerpApi bietet 100 kostenlose Suchanfragen pro Monat; ScraperAPI stellt 5.000 kostenlose Credits bereit. Den API-Schlüssel findest du jeweils im Dashboard.
Schritt 2: API-Anfrage konfigurieren
Hier ein minimales Beispiel mit dem Google-Shopping-Endpunkt von ScraperAPI:
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
Die API liefert strukturiertes JSON mit Feldern wie title, price, link, thumbnail, source (Händler) und rating.
Schritt 3: JSON-Antwort parsen und Felder extrahieren
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
Schritt 4: Als CSV oder JSON exportieren
df.to_csv("google_shopping_results.csv", index=False)
Das Ganze ist batch-freundlich: Du kannst 50 Keywords in einer Schleife abarbeiten und in einem einzigen Skriptlauf einen vollständigen Datensatz aufbauen. Der Haken sind die Kosten – SERP APIs rechnen pro Anfrage ab, und bei Tausenden Anfragen täglich klettern die Ausgaben rasch. Mehr dazu weiter unten.
Methode 3: Google Shopping-Daten mit Python + Playwright scrapen (Browser-Automation)
- Schwierigkeitsgrad: Fortgeschritten
- Benötigte Zeit: ~1 Stunde+ (plus laufende Wartung)
- Was du brauchst: Python 3.10+, Playwright, Residential Proxies, Geduld
Der Ansatz mit „maximaler Kontrolle“. Du startest einen echten Browser, navigierst zu Google Shopping und extrahierst die Daten aus der gerenderten Seite. Sehr flexibel, aber auch reichlich anfällig – Googles Anti-Bot-Systeme greifen aggressiv durch, und die Seitenstruktur ändert sich mehrmals im Jahr.
Ein Hinweis aus der Praxis: Ich habe Nutzer erlebt, die sich wochenlang an CAPTCHAs und IP-Sperren abgearbeitet haben. Es funktioniert, aber rechne fest mit laufender Wartung.
Schritt 1: Playwright und Proxies einrichten
pip install playwright
playwright install chromium
Residential Proxies sind Pflicht. Rechenzentrums-IP-Adressen fliegen fast augenblicklich raus – ein Forennutzer brachte es drastisch auf den Punkt: „Alle AWS-IPs werden blockiert oder stoßen nach 1/2 Ergebnissen auf ein CAPTCHA.“ Dienste wie Bright Data, Oxylabs oder Decodo bieten Residential-Proxy-Pools ab etwa 1–5 $/GB.
Konfiguriere Playwright mit einem realistischen User-Agent und deinem Proxy:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
Schritt 2: Zu Google Shopping navigieren und Anti-Bot-Maßnahmen behandeln
Bau die Google-Shopping-URL zusammen und öffne sie:
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
Taucht das Cookie-Einwilligungsfenster für die EU auf, schließe es:
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
Streue menschlich wirkende Pausen zwischen die Aktionen – 2 bis 5 Sekunden zufällige Wartezeit zwischen Seitenaufrufen. Googles Erkennungssysteme reagieren empfindlich auf schnelle, gleichmäßige Anfragemuster.
Schritt 3: Scrollen, Seiten wechseln und Produktdaten extrahieren
Google Shopping lädt die Ergebnisse dynamisch nach. Scrolle, um das Lazy Loading auszulösen, und extrahiere dann die Produktkarten:
import time, random
# Scrollen, um alle Ergebnisse zu laden
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# Produktkarten extrahieren
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... weitere Felder extrahieren
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
Wichtig: Die CSS-Selektoren oben sind nur Annäherungen und werden sich ändern. Google tauscht Klassennamen häufig aus. Allein zwischen 2024 und 2026 sind drei verschiedene Selektor-Sets dokumentiert. Verlass dich lieber auf stabilere Attribute wie jsname, data-cid, <h3>-Tags und img[alt] als auf Klassennamen.
Schritt 4: Als CSV oder JSON speichern
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
Geh davon aus, dass du dieses Skript regelmäßig nachpflegen musst. Sobald Google die Seitenstruktur umbaut – und das geschieht mehrmals im Jahr –, brechen deine Selektoren und du sitzt wieder am Debugging.
Das größte Problem: CAPTCHAs und Anti-Bot-Sperren
In jedem zweiten Forum liest man im Kern dieselbe Geschichte: „Ein paar Wochen reingesteckt, dann gegen Googles Anti-Bot-Methoden aufgegeben.“ CAPTCHAs und IP-Sperren sind der Hauptgrund, warum so viele DIY-Google-Shopping-Scraper irgendwann das Handtuch werfen.
Wie Google Scraper blockiert – und was dagegen hilft
| Anti-Bot-Herausforderung | Was Google macht | Gegenmaßnahme |
|---|---|---|
| IP-Fingerprinting | Blockiert Rechenzentrums-IP-Adressen nach wenigen Anfragen | Residential Proxies oder browserbasierte Extraktion |
| CAPTCHAs | Werden durch schnelle oder automatisierte Anfragemuster ausgelöst | Rate Limiting (10–20 s zwischen Anfragen), menschlich wirkende Verzögerungen, CAPTCHA-Lösungsdienste |
| JavaScript-Rendering | Shopping-Ergebnisse laden dynamisch per JS | Headless Browser (Playwright) oder API mit JS-Rendering |
| User-Agent-Erkennung | Blockiert gängige Bot-User-Agents | Realistische, aktuelle User-Agent-Strings rotieren |
| TLS-Fingerprinting | Erkennt nicht-browsertypische TLS-Signaturen | curl_cffi mit Browser-Imitation oder ein echter Browser |
| AWS-/Cloud-IP-Blockierung | Blockiert bekannte IP-Bereiche von Cloud-Anbietern | Rechenzentrums-IPs komplett vermeiden |
Im Januar 2025 machte Google die JavaScript-Ausführung für SERP- und Shopping-Ergebnisse zur Pflicht und legte damit zahlreiche statische HTML-Scraper lahm – darunter auch Pipelines, die SemRush und SimilarWeb nutzten. Im September 2025 ersetzte Google dann die alten Produktdetailseiten-URLs durch eine neue „Immersive Product“-Oberfläche, die per asynchronem AJAX geladen wird. Jede Anleitung von vor Ende 2025 ist damit heute weitgehend Makulatur.
Wie die einzelnen Methoden mit diesen Herausforderungen umgehen
SERP APIs kümmern sich im Hintergrund um alles – Proxies, Rendering, CAPTCHA-Lösung. Damit musst du dich gar nicht erst befassen.
Thunderbit Cloud Scraping stützt sich auf verteilte Cloud-Infrastruktur in den USA, der EU und Asien und bewältigt JS-Rendering und Anti-Bot-Maßnahmen automatisch. Der Browser-Scraping-Modus nutzt deine eigene authentifizierte Chrome-Sitzung – das umgeht die Erkennung, weil es wie normales Surfen aussieht.
DIY mit Playwright legt die gesamte Verantwortung in deine Hände – Proxy-Management, Verzögerungs-Tuning, CAPTCHA-Lösung, Pflege der Selektoren und permanente Fehlerüberwachung.
Die echten Kosten für Google Shopping-Daten-Scraping: Ein ehrlicher Vergleich
„50 $ für rund 20.000 Anfragen … etwas happig für mein Hobbyprojekt.“ Solche Klagen tauchen in Foren am laufenden Band auf. Dabei bleibt meist der größte Kostenfaktor überhaupt unerwähnt.
Kostenvergleich
| Ansatz | Startkosten | Kosten pro Anfrage (geschätzt) | Wartungsaufwand | Versteckte Kosten |
|---|---|---|---|---|
| DIY Python (ohne Proxy) | Kostenlos | 0 $ | HOCH (Fehler, CAPTCHAs) | Deine Zeit fürs Debugging |
| DIY Python + Residential Proxies | Kostenloser Code | ca. 1–5 $/GB | MITTEL-HOCH | Gebühren des Proxy-Anbieters |
| SERP API (SerpApi, ScraperAPI) | Kostenloses Kontingent begrenzt | ca. 0,50–5,00 $/1K Anfragen | NIEDRIG | Skaliert bei hohem Volumen schnell |
| Thunderbit Chrome-Erweiterung | Kostenloses Kontingent (6 Seiten) | kreditbasiert, ca. 1 Kredit/Zeile | SEHR NIEDRIG | Bezahlplan bei hohem Volumen |
| Thunderbit Open API (Extract) | kreditbasiert | ca. 20 Credits/Seite | NIEDRIG | Bezahlung pro Extraktion |
Die versteckten Kosten, die alle ignorieren: deine Zeit
Eine DIY-Lösung für 0 $, die 40 Stunden Debugging frisst, ist alles andere als kostenlos. Bei 50 $ pro Stunde stehen da 2.000 $ Arbeitskosten zu Buche – für einen Scraper, der nächsten Monat schon wieder zerschossen sein kann, sobald Google sein DOM umbaut.

McKinseys Technology Outlook verortet den Break-even zwischen Eigenbau und Kauf erst jenseits von 3,6 Millionen täglichen Anfragen. Unterhalb dieser Schwelle „verbraucht Eigenentwicklung Budget, ohne ROI zu liefern“. Für die meisten Ecommerce-Teams, die pro Woche nur einige Hundert bis einige Tausend Abfragen fahren, ist ein No-Code-Tool oder eine SERP API deutlich kosteneffizienter als die Eigenlösung.
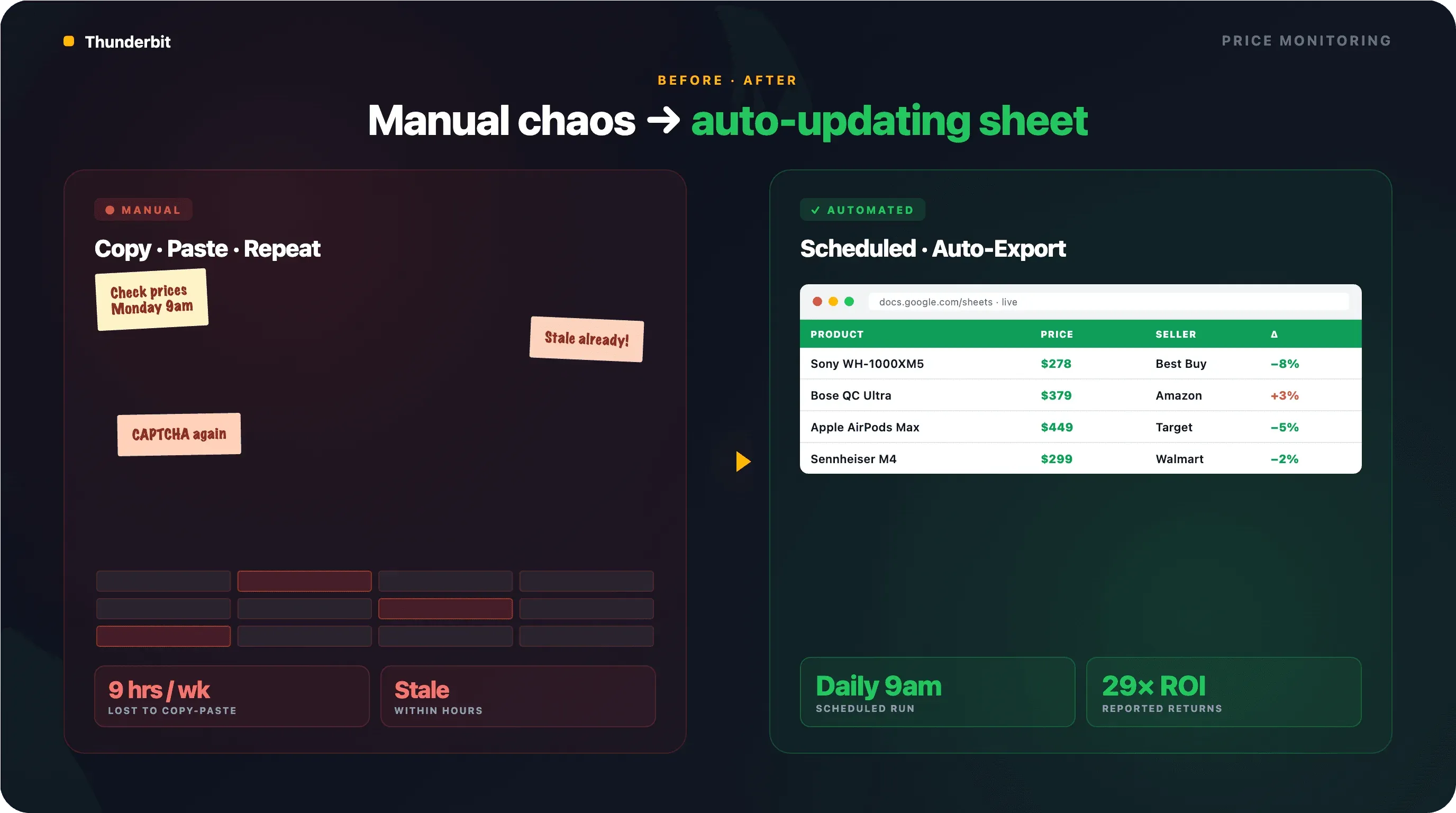
So richtest du automatisches Google-Shopping-Preis-Monitoring ein
Die meisten Anleitungen behandeln Scraping als einmalige Aufgabe. Für E-Commerce-Teams liegt der eigentliche Anwendungsfall aber im laufenden, automatisierten Monitoring. Du brauchst nicht nur die Preise von heute – sondern auch die von gestern, von letzter Woche und von morgen.
Geplantes Scraping mit Thunderbit einrichten
Mit Thunderbits Scheduled Scraper beschreibst du das Zeitintervall in normaler Sprache – „jeden Tag um 9 Uhr“ oder „jeden Montag und Donnerstag um 12 Uhr“ – und die KI übersetzt das in einen wiederkehrenden Zeitplan. Gib deine Google-Shopping-URLs ein, klicke auf „Schedule“, fertig.
Jeder Lauf landet automatisch in Google Sheets, Airtable oder Notion. Das Resultat: eine Tabelle, die sich täglich mit Konkurrenzpreisen füllt und sofort für Pivot-Tabellen oder Alarme bereitliegt.
Keine Cron-Jobs. Kein Server-Management. Kein Lambda-Stress. (Ich habe Forenposts von Entwicklern gesehen, die tagelang versucht haben, Selenium in AWS Lambda ans Laufen zu bekommen – genau diesen Aufwand spart Thunderbit.)
Mehr zum Aufbau von Preis-Monitoring-Workflows findest du in unserem separaten Deep Dive.
Zeitpläne mit Python erstellen (für Entwickler)
Setzt du auf den SERP-API-Ansatz, kannst du Läufe per Cron-Job (Linux/Mac), Windows Task Scheduler oder Cloud-Scheduler wie AWS Lambda oder Google Cloud Functions takten. Python-Bibliotheken wie APScheduler leisten dasselbe.
Der Haken: Jetzt liegt alles bei dir – Monitoring, Fehlerbehandlung, das planmäßige Rotieren der Proxies und das Nachziehen der Selektoren, wenn Google die Seite umstellt. Für die meisten Teams übersteigt der Engineering-Aufwand zur Pflege eines geplanten Python-Scrapers die Kosten eines spezialisierten Tools.
Tipps und Best Practices für Google Shopping-Daten-Scraping
Egal, für welche Methode du dich entscheidest – ein paar Dinge ersparen dir viel Ärger.
Rate Limits respektieren
Überrenne Google nicht mit Hunderten schnellen Anfragen – du wirst blockiert, und deine IP kann noch eine Weile markiert bleiben. Bei DIY-Methoden gilt: Anfragen mit 10–20 Sekunden Abstand und zufälliger Streuung absetzen. Tools und APIs nehmen dir das ab.
Methode an dein Volumen anpassen
Eine kurze Entscheidungshilfe:
- < 10 Anfragen/Woche → Thunderbit Free-Tier oder SerpApi-Free-Tier
- 10–1.000 Anfragen/Woche → Bezahlplan einer SERP API oder Thunderbit-Bezahlplan
- 1.000+ Anfragen/Woche → Enterprise-Plan einer SERP API oder Thunderbit Open API
Daten bereinigen und validieren
Preise kommen mit Währungssymbolen, länderspezifischer Formatierung (1.299,00 € vs. 1,299.00 $) und gelegentlichem Sonderzeichen-Müll. Normalisiere sie mit Thunderbits Field AI Prompts schon beim Extrahieren oder bereinige sie im Anschluss mit pandas:
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
Prüfe auf Dubletten zwischen organischen und gesponserten Listings – sie überschneiden sich oft. Dedupliziere über das Tupel (Titel, Preis, Händler).
Die rechtliche Lage kennen
Das Scrapen öffentlich zugänglicher Produktdaten gilt grundsätzlich als legal, doch die Rechtslage ist in raschem Wandel. Die wichtigste jüngere Entwicklung: Google verklagte SerpApi im Dezember 2025 nach DMCA § 1201 wegen Umgehung des Anti-Scraping-Systems „SearchGuard“. Das ist ein neuer Durchsetzungsansatz, der an den Verteidigungsargumenten früherer Fälle wie hiQ v. LinkedIn und Van Buren v. United States vorbeizielt.
Praktische Leitlinien:
- Nur öffentlich verfügbare Daten scrapen – kein Login für geschützte Inhalte
- Keine personenbezogenen Informationen extrahieren (Namen von Rezensenten, Kontodetails)
- Bedenke, dass Googles Nutzungsbedingungen automatisierten Zugriff untersagen – SERP API oder Browser-Erweiterung verkleinern die rechtlichen Grauzonen, schaffen sie aber nicht ganz ab
- Bei EU-Projekten die DSGVO mitdenken, auch wenn Produktlisten überwiegend nicht-personenbezogene Geschäftsdaten enthalten
- Baust du ein kommerzielles Produkt auf gescrapten Daten auf, hol dir juristischen Rat
Einen tieferen Blick auf rechtliche Aspekte des Web Scrapings haben wir in einem eigenen Beitrag zusammengetragen.
Welche Methode sollten Sie zum Scrapen von Google Shopping-Daten verwenden?
Nachdem ich alle drei Ansätze an denselben Produktkategorien durchgetestet habe, fällt mein Fazit so aus:
Wenn du nicht aus der Technik kommst und schnell Daten brauchst – nimm Thunderbit. Google Shopping öffnen, zweimal klicken, exportieren. In unter 5 Minuten hast du eine saubere Tabelle. Das Free-Tier erlaubt einen risikofreien Einstieg, und das Subpage-Scraping liefert oft mehr Daten, als die meisten Python-Skripte zusammenbringen.
Wenn du Entwickler bist und programmgesteuerten, wiederholbaren Zugriff brauchst – greif zur SERP API. Die Zuverlässigkeit rechtfertigt die Kosten pro Anfrage, und du sparst dir den ganzen Anti-Bot-Stress. SerpApi punktet mit der besten Dokumentation, ScraperAPI mit dem großzügigsten Free-Tier.
Wenn du maximale Kontrolle willst und eine eigene Pipeline bauen möchtest – Playwright funktioniert, aber nur mit realistischer Erwartung. Plane reichlich Zeit für Proxy-Management, Selektorpflege und CAPTCHA-Handling ein. Der Minimal-Stack zur Umgehung lautet 2025–2026: curl_cffi mit Chrome-Imitation + Residential Proxies + 10–20 Sekunden Taktung. Ein simples requests-Skript mit rotierenden User-Agents reicht heute nicht mehr.
Die beste Methode ist letztlich die, mit der du verlässliche Daten bekommst, ohne deine ganze Woche dafür zu verbrennen. Für die meisten Menschen ist das kein 60-Zeilen-Python-Skript – sondern zwei Klicks.
Für größere Mengen findest du die Konditionen unter Thunderbits Preise, und die Tutorials auf dem Thunderbit YouTube-Kanal zeigen den Workflow in Aktion.
Thunderbit für Google-Shopping-Scraping testen Get Started Free
FAQs
Ist es legal, Google Shopping-Daten zu scrapen?
Das Scrapen öffentlich verfügbarer Produktdaten ist nach Präzedenzfällen wie hiQ v. LinkedIn und Van Buren v. United States grundsätzlich legal. Allerdings untersagen die Google-Nutzungsbedingungen automatisierten Zugriff, und Googles Klage gegen SerpApi im Dezember 2025 brachte eine neue DMCA-§1201-Umgehungstheorie ins Spiel. Wer auf seriöse Tools und APIs setzt, senkt das Risiko. Für kommerzielle Anwendungsfälle solltest du juristischen Rat einholen.
Kann ich Google Shopping scrapen, ohne blockiert zu werden?
Ja, aber es kommt auf die Methode an. SERP APIs übernehmen Anti-Bot-Maßnahmen automatisch. Thunderbits Cloud Scraping nutzt verteilte Infrastruktur, um Sperren zu umgehen, während der Browser-Scraping-Modus deine eigene Chrome-Sitzung verwendet und dadurch wie normales Surfen wirkt. DIY-Python-Skripte brauchen Residential Proxies, menschlich wirkende Verzögerungen und TLS-Fingerprint-Management – und selbst dann sind Sperren keine Seltenheit.
Was ist der einfachste Weg, Google Shopping-Daten zu scrapen?
Thunderbits Chrome-Erweiterung. Geh auf Google Shopping, klicke auf „AI Suggest Fields“, dann auf „Scrape“ und exportiere nach Google Sheets oder Excel. Kein Programmieren, keine API-Keys, keine Proxy-Konfiguration. Der ganze Vorgang dauert etwa 2 Minuten.
Wie oft kann ich Google Shopping für Preis-Monitoring scrapen?
Mit Thunderbits Scheduled Scraper richtest du tägliches, wöchentliches oder frei definierbares Monitoring in normaler Sprache ein. Bei SERP APIs hängt die Frequenz von den Kreditlimits deines Plans ab – die meisten Anbieter erlauben tägliches Monitoring für einige Hundert SKUs. DIY-Skripte laufen so oft, wie deine Infrastruktur es zulässt, aber höhere Frequenz bedeutet auch mehr Anti-Bot-Ärger.
Kann ich Google Shopping-Daten nach Google Sheets oder Excel exportieren?
Ja. Thunderbit exportiert kostenlos direkt nach Google Sheets, Excel, Airtable und Notion. Python-Skripte können als CSV oder JSON exportieren, die du anschließend in jedes beliebige Tabellenwerkzeug importierst. Für laufendes Monitoring erzeugen Thunderbits geplante Exporte nach Google Sheets einen lebenden, automatisch aktualisierten Datensatz.
- Mehr erfahren




