Wenn du schon einmal versucht hast, eine gezielte Vertriebsliste aufzubauen, neue Märkte zu prüfen oder Wettbewerber zu vergleichen, weißt du: Google Maps ist dafür eine echte Goldgrube. Aber genau hier liegt der Haken: Mit über 1,5 Milliarden Suchen nach „in meiner Nähe“ pro Monat und 76 % der lokalen Suchenden, die innerhalb von 24 Stunden ein Geschäft besuchen () war die Nachfrage nach aktuellen, standortbezogenen Geschäftsdaten nie höher.
Ganz gleich, ob du im Vertrieb, Marketing oder in der Operations arbeitest: Strukturierte Daten aus Google Maps zu extrahieren kann den Unterschied zwischen einem kalten Anruf und einem warmen Lead mit hoher Conversion-Rate ausmachen.
Ich arbeite seit Jahren im SaaS- und Automatisierungsumfeld und habe aus erster Hand gesehen, wie Teams Python (und inzwischen KI-gestützte Tools wie ) nutzen, um Google Maps in einen strategischen Vorteil zu verwandeln.
In diesem Leitfaden zeige ich dir Schritt für Schritt, wie du Google-Maps-Daten 2026 mit Python scrapen kannst — inklusive Code, Hinweisen zur Einhaltung von Richtlinien und einem Vergleich mit No-Code-Lösungen. Ob du Python-Profi bist oder einfach den schnellsten Weg zu verwertbaren Daten suchst: Hier bist du richtig.
Was bedeutet es, Google Maps mit Python zu scrapen?
Fangen wir ganz vorne an: Google Maps mit Python scrapen bedeutet, Geschäftsinformationen wie Namen, Adressen, Bewertungen, Rezensionen, Telefonnummern und Koordinaten per Code aus Google Maps zu extrahieren, damit du sie analysieren, filtern und für geschäftliche Zwecke exportieren kannst.

Dafür gibt es zwei Hauptwege:
- Google Maps Places API: Der offizielle, lizenzierte Weg. Du verwendest einen API-Schlüssel, um Google-Server abzufragen und strukturierte JSON-Daten zurückzubekommen. Das ist stabil, vorhersagbar und meist regelkonform, bringt aber Kontingente und Kosten mit sich.
- Web-Scraping des HTML: Du automatisierst einen Browser (mit Tools wie Playwright oder Selenium), lädst Google Maps, führst Suchen aus und parsest die gerenderte Seite. Das ist flexibler, aber auch fragiler — Google ändert die Seitenstruktur häufig, und das Scrapen des HTML kann gegen die Nutzungsbedingungen von Google verstoßen.
Typische Datenfelder, die du extrahieren kannst:
- Geschäftsname
- Kategorie/Typ
- Vollständige Adresse (inklusive Stadt, Bundesland, Postleitzahl, Land)
- Breitengrad und Längengrad
- Telefonnummer
- Website-URL
- Bewertung und Anzahl der Rezensionen
- Preisniveau
- Geschäftsstatus (offen/geschlossen)
- Öffnungszeiten
- Place ID (eindeutige Google-Kennung)
- Google-Maps-URL
Warum ist das wichtig? Weil diese Felder alles von Lead-Generierung und Gebietsplanung bis hin zu Wettbewerbsanalysen und Marktforschung antreiben. Entscheidend ist, die richtigen Daten für deine Geschäftsziele zu erfassen — also nicht blind drauflos zu scrapen.
Warum Vertriebs- und Marketingteams mit Python Daten aus Google Maps extrahieren
Werden wir praktisch. Warum sind 2026 so viele Vertriebs- und Marketingteams geradezu besessen von Google-Maps-Daten?
- Lead-Generierung: Erstelle hochpräzise Listen lokaler Unternehmen inklusive Kontaktdaten und Bewertungen für Outreach-Kampagnen.
- Gebietsplanung: Plane Vertriebsgebiete, Lieferzonen oder Servicebereiche auf Basis realer Geschäftsdichte und Branchen.
- Wettbewerbsbeobachtung: Verfolge Standorte, Bewertungen und Rezensionen von Wettbewerbern über die Zeit, um Trends und Chancen zu erkennen.
- Marktforschung: Analysiere Geschäftskategorien, Öffnungszeiten und die Stimmung in Rezensionen, um Go-to-Market-Strategien zu untermauern.
- Standortauswahl: Im Immobilien- und Einzelhandelsbereich lassen sich potenzielle Standorte anhand von Annehmlichkeiten in der Nähe, Laufkundschaft und Konkurrenz bewerten.
Auswirkung in der Praxis: Laut dem planen 92 % der Vertriebsorganisationen, ihre Investitionen in KI und Daten auszubauen, und Teams, die gezielte lokale Daten nutzen, erzielen bis zu 8-mal höhere Conversion-Raten als jene, die auf generische Cold Lists setzen (). Eine Studie zur Lead-Generierung im Franchise-Bereich zeigte 15 US-Dollar an neuem Umsatz für jeden 1 US-Dollar, der in Lead-Listen auf Basis von Google Maps investiert wurde.
Geschäftsziele den Google-Maps-Feldern zuordnen:
| Geschäftsziel | Benötigte Google-Maps-Felder |
|---|---|
| Lokale Lead-Liste | name, address, phone, website, category |
| Gebietsplanung | name, lat/lng, business_status, opening_hours |
| Wettbewerbsbenchmarking | name, rating, userRatingCount, priceLevel, reviews |
| Standortauswahl | category, lat/lng, review density, openingDate |
| Sentiment-/Menü-Insights | reviews, editorialSummary, photos, types |
| E-Mail-/Telefon-Outreach | nationalPhoneNumber, websiteUri (danach bei Bedarf anreichern) |
Dein Python-Google-Maps-Scraper einrichten: Tools und Voraussetzungen
Bevor du mit dem Scraping beginnst, musst du deine Python-Umgebung einrichten und die passenden Tools zusammenstellen. Das brauchst du 2026:
1. Python und benötigte Bibliotheken installieren
Empfohlene Python-Version: 3.10 oder neuer.
Wichtige Bibliotheken installieren:
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromiumWas diese Pakete tun:
requests,httpx: HTTP-Anfragen (API-Aufrufe)beautifulsoup4,lxml: HTML-Parsing (für Web-Scraping)pandas: Datenbereinigung, Analyse, Exportselenium,playwright: Browser-Automatisierung (für HTML-Scraping)googlemaps,google-maps-places: Google-Maps-API-Clientsschedule,APScheduler: Aufgabenplanungpython-dotenv: API-Schlüssel sicher aus.env-Dateien ladentenacity: Wiederholungslogik für Fehlerbehandlung
2. Einen Google-Maps-API-Schlüssel erhalten (für API-basiertes Scraping)
- Gehe zur .
- Erstelle ein Projekt oder wähle ein vorhandenes aus.
- Aktiviere die Abrechnung (erforderlich, auch für die kostenlose Nutzung).
- Aktiviere „Places API (New)“ unter APIs & Dienste > Bibliothek.
- Gehe zu Anmeldedaten > Anmeldedaten erstellen > API-Schlüssel.
- Beschränke deinen Schlüssel aus Sicherheitsgründen auf bestimmte APIs und IPs.
- Speichere deinen API-Schlüssel in einer
.env-Datei (niemals im Code einchecken):
1GOOGLE_MAPS_API_KEY=dein_aktueller_api_schluessel_hierHinweis: Seit März 2025 bietet Google keinen einheitlichen kostenlosen Kredit von 200 US-Dollar pro Monat mehr an. Stattdessen gibt es kostenlose monatliche Schwellenwerte je API-Tarif (siehe ).
So extrahierst du Daten aus Google Maps mit Python: Schritt-für-Schritt-Anleitung
Schauen wir uns beide Hauptansätze an — API-basiert und HTML-Scraping — damit du den passenden Weg wählen kannst.
Ansatz 1: Die Google Maps Places API verwenden (empfohlen)
Schritt 1: Benötigte Bibliotheken installieren und importieren
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenvSchritt 2: Deinen API-Schlüssel sicher laden
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]Schritt 3: Deine Suchanfrage aufbauen
Du verwendest den Text Search-Endpunkt, um Unternehmen zu finden, die deinen Kriterien entsprechen.
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])Schritt 4: Die API-Anfrage senden
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # serverseitiger Filter
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # Immer setzen!
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()Schritt 5: Paginierung behandeln und Ergebnisse sammeln
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return resultsSchritt 6: Daten mit Pandas exportieren
1df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)Profi-Tipps:
- Setze immer den Header
X-Goog-FieldMask, um die Kosten zu kontrollieren. Wenn du Rezensionen oder Fotos anforderst, kann der Preis pro 1.000 Anfragen von 5 auf 25 US-Dollar steigen (). - Verwende serverseitige Filter (wie
minRating,includedType,locationBias), damit keine Credits für irrelevante Ergebnisse verschwendet werden. - Speichere
place_id-Werte zwischen, um Duplikate zu vermeiden und spätere Aktualisierungen zu erleichtern.
Ansatz 2: Google-Maps-HTML scrapen (für Lernzwecke oder einmalige Nutzung)
Warnung: Google Maps ist eine Single-Page-App. Du musst Browser-Automatisierung (Playwright oder Selenium) verwenden, und das Scrapen des HTML kann gegen die Nutzungsbedingungen von Google verstoßen. Nutze diesen Ansatz für Recherche, nicht für den produktiven Einsatz.
Schritt 1: Playwright installieren und einen Browser starten
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="Search"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rowsTipps:
- Google ändert CSS-Klassen alle paar Wochen, daher muss dieser Code regelmäßig angepasst werden.
- Nutze menschlich wirkende Verzögerungen und scrape nicht zu schnell, um das Risiko einer Sperre zu senken.
- Versuche niemals, CAPTCHAs oder Googles SearchGuard-System zu umgehen — das kann rechtliche Risiken nach sich ziehen.
Blindes Scrapen vermeiden: So zielst du präzise auf die Daten, die du brauchst
Alles zu scrapen ist ein Rezept für Zeitverschwendung und aufgeblähte Datensätze. So kannst du nur die Daten erfassen, die wirklich wichtig sind:
- Gezielte URL-Listen generieren: Verwende Googles eigene Suchfilter in Maps (Kategorie, Ort, Bewertung, jetzt geöffnet), um Ergebnisse vor dem Scraping einzugrenzen.
- Phrase Matching nutzen: Suche nach exakten Geschäftstypen oder Schlüsselwörtern (z. B. „vegane Bäckerei in Austin“).
- Standortfilter: Gib Stadt, Stadtteil oder sogar Koordinaten und Radius für punktgenaue Treffer an.
- Serverseitiges Filtern (API): Verwende
minRating,includedTypeundlocationBiasim Request-Body deiner API. - Clientseitiges Filtern (Python): Nutze nach dem Scraping pandas, um Unternehmen mit Bewertungen über 4.0, mehr als 50 Rezensionen oder bestimmten Kategorien zu filtern.
Beispiel: Nur Restaurants in Manhattan mit Bewertungen über 4.0 filtern
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)Google-Maps-Daten mit Python-Bibliotheken organisieren und exportieren
Sobald du deine Daten gescrapt hast, ist es Zeit, sie zu bereinigen, zu analysieren und für dein Team zu exportieren.
Daten mit Pandas bereinigen und strukturieren
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)Daten analysieren und zusammenfassen
Beispiel: Durchschnittsbewertung nach Stadtteil
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)In Excel oder CSV exportieren
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")Große Datensätze? Verwende Parquet für mehr Geschwindigkeit und bessere Speicher-Effizienz:
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit: KI-gestützte Alternative zum Python-Google-Maps-Scraper
Wenn du jetzt denkst: „Das ist ganz schön viel Aufwand für eine einfache Lead-Liste“, bist du nicht allein. Genau deshalb haben wir entwickelt — einen KI-gestützten No-Code-Web-Scraper, mit dem sich Google-Maps-Daten (und vieles mehr) mit nur wenigen Klicks extrahieren lassen.
Warum Thunderbit?
- Kein Coding und keine API-Schlüssel erforderlich: Öffne einfach die , navigiere zu Google Maps und klicke auf „AI Suggest Fields“.
- KI-Felderkennung: Die KI von Thunderbit liest die Seite aus und schlägt die passenden Spalten vor — Name, Adresse, Bewertung, Telefon, Website und mehr.
- Scraping von Unterseiten: Möchtest du deine Tabelle mit Daten von den Websites der einzelnen Unternehmen anreichern? Thunderbit kann jede Unterseite besuchen und zusätzliche Infos automatisch ziehen.
- Export nach Excel, Google Sheets, Airtable oder Notion: Kein mühsames pandas-Gefummel mehr — einfach auf „Export“ klicken und die Daten sind bereit für dein Team.
- Geplantes Scraping: Richte wiederkehrende Jobs ein, um Wettbewerber zu überwachen oder deine Lead-Liste automatisch zu aktualisieren.
- Null Wartung: Die KI von Thunderbit passt sich an Website-Änderungen an, sodass du nicht ständig kaputte Skripte reparieren musst.
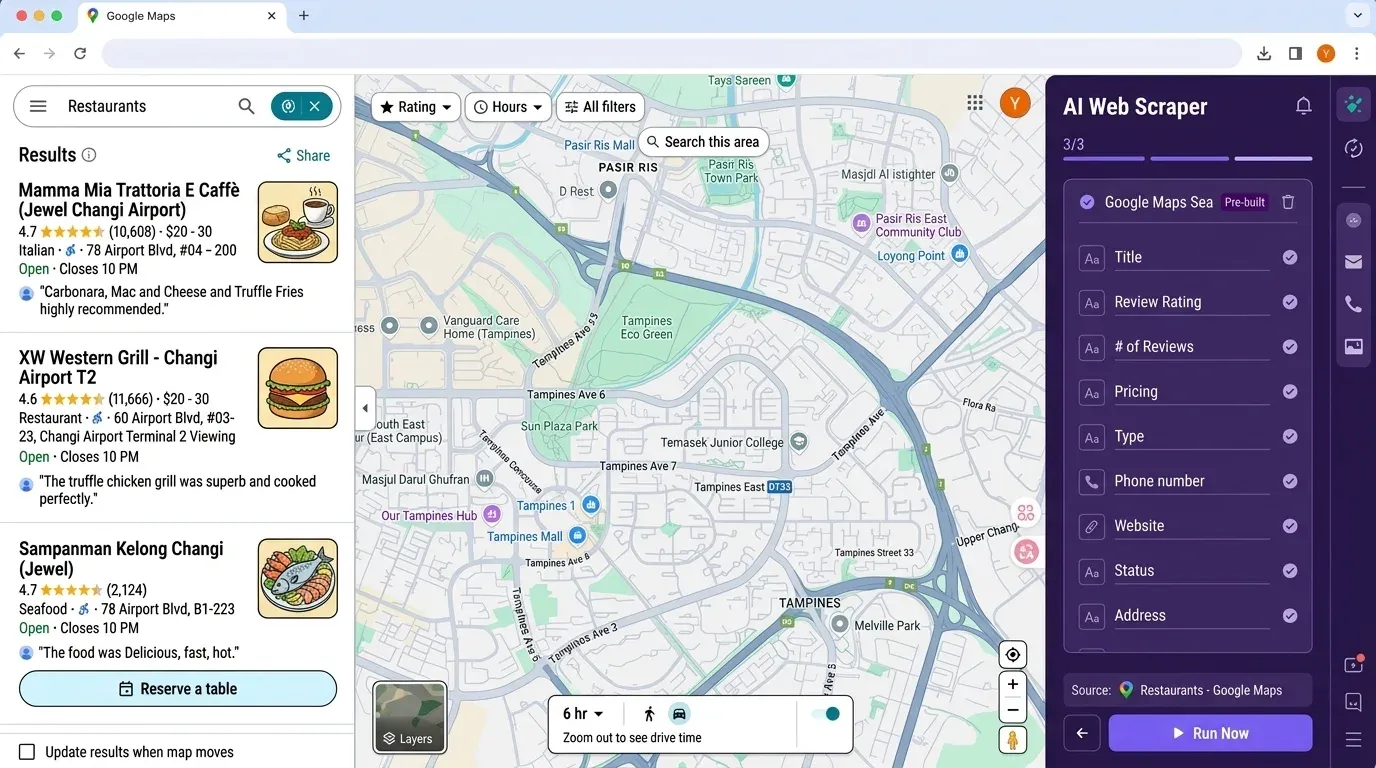
Thunderbit vs. Python-Workflow:
| Schritt | Python-Scraper | Thunderbit |
|---|---|---|
| Tools installieren | 30–60 Min. (Python, pip, Bibliotheken) | 2 Min. (Chrome-Erweiterung) |
| API-Schlüssel einrichten | 10–30 Min. (Cloud Console) | Nicht nötig |
| Feldauswahl | Manueller Code, Field Masks | AI Suggest Fields (1 Klick) |
| Datenextraktion | Skripte schreiben/ausführen, Fehler behandeln | Auf „Scrape“ klicken |
| Export | pandas nach CSV/Excel | Export nach Excel/Sheets/Notion |
| Wartung | Manuelle Updates bei Website-Änderungen | KI passt sich automatisch an |
Bonus: Thunderbit wird von über vertraut, und der kostenlose Tarif ermöglicht es dir, bis zu 6 Seiten (oder 10 mit einem Test-Boost) ohne Kosten zu scrapen.
Regelkonform bleiben: Google-Maps-Nutzungsbedingungen und Scraping-Ethik
Hier werden die meisten Python-Tutorials gefährlich veraltet. Das solltest du 2026 wissen:
- Google Maps Platform ToS §3.2.3 verbietet das Scrapen, Cachen oder Exportieren von Daten außerhalb der offiziellen APIs strikt (). Die einzige Ausnahme: Breiten-/Längengradwerte dürfen bis zu 30 Tage gecacht werden; Place IDs dürfen unbegrenzt gespeichert werden.
- API-Nutzer sind vertraglich gebunden: Wenn du einen API-Schlüssel verwendest, hast du den Nutzungsbedingungen von Google zugestimmt — selbst wenn du nur öffentliche Daten scrapest.
- Das Umgehen technischer Schutzmaßnahmen (CAPTCHAs, SearchGuard) ist inzwischen möglicherweise ein Verstoß gegen DMCA §1201 und kann strafrechtliche Folgen haben ().
- DSGVO und Datenschutzgesetze: Wenn du personenbezogene Daten (E-Mails, Telefonnummern, Namen von Rezensenten) aus Google Maps sammelst, brauchst du eine rechtmäßige Grundlage und musst Löschanfragen respektieren. Die französische CNIL verhängte 2024 gegen KASPR eine Geldbuße von 200.000 € wegen des Scrapings von LinkedIn-Kontakten ().
- Best Practices:
- Wenn möglich immer die Places API verwenden.
- Anfragen drosseln (≤10 QPS für die API, 1–2 Anfragen/Sek. für HTML-Scraping).
- Niemals CAPTCHAs oder technische Sperren umgehen.
- Gescrapte personenbezogene Daten nicht weiterverbreiten.
- Opt-out- und Löschanfragen beachten.
- Immer lokale Gesetze prüfen — DSGVO, CCPA und andere werden aktiv durchgesetzt.
Kurz gesagt: Wenn Compliance ein Thema ist, bleib bei der API und sammle nur so viele Daten wie nötig. Für die meisten Business-Anwender senkt ein No-Code-Tool wie Thunderbit das Risiko deutlich (kein API-Schlüssel, keine Weiterverbreitung).
Dein Google-Maps-Scraping mit Python planen und automatisieren
Wenn du deine Daten aktuell halten musst — etwa für wöchentliches Wettbewerbsmonitoring oder monatliche Aktualisierungen deiner Lead-Liste — ist Automatisierung dein bester Freund.
Einfache Zeitplanung mit schedule
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
4schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
5while True:
6 schedule.run_pending()
7 time.sleep(30)Zeitplanung auf Produktionsniveau mit APScheduler
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 3:15 Uhr ± 10 Min.
7 kwargs={"query": "restaurants in Brooklyn"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()Tipps für sichere Automatisierung
- Füge deiner Zeitplanung zufällige Verzögerungen hinzu, um vorhersehbare Muster zu vermeiden.
- Beim HTML-Scraping niemals mehr als 1–2 Anfragen pro Sekunde senden.
- Bei der API-Nutzung dein Kontingent überwachen und Abrechnungswarnungen einrichten.
- Fehler immer protokollieren und eine „Dead-Letter“-Datei für fehlgeschlagene Anfragen führen.
Thunderbit-Bonus: Mit Thunderbit kannst du wiederkehrende Scrapes direkt in der Benutzeroberfläche planen — kein Code, keine Cron-Jobs, kein Server-Setup.
Wichtige Erkenntnisse: Effiziente, gezielte und regelkonforme Google-Maps-Datenextraktion
Fassen wir das Wesentliche zusammen:
- Google Maps ist die wichtigste Quelle für Standortdaten von Unternehmen und treibt alles von Lead-Generierung bis Marktforschung an.
- Python-Scraping bietet Flexibilität und Kontrolle, bringt aber Aufwand bei Einrichtung, Wartung und Compliance mit sich — besonders, da Googles Anti-Bot-Maßnahmen und rechtliche Durchsetzung zunehmen.
- API-basierte Extraktion ist für die meisten Teams der sicherste und skalierbarste Weg. Nutze immer Field Masks und serverseitige Filter, um Kosten zu kontrollieren.
- HTML-Scraping ist fragil und riskant — setze es nur für einmalige Recherchen ein und umgehe niemals technische Barrieren.
- Ziele deine Daten genau: Nutze Phrase Matching, Standortfilter und pandas-Workflows, um nur das zu extrahieren, was du wirklich brauchst.
- Thunderbit ist der schnellste Weg für Nicht-Programmierer: KI-gestützt, kein Setup, sofortiger Export und integrierte Planung.
- Compliance zählt: Respektiere Googles Bedingungen, Datenschutzgesetze und Ratenbegrenzungen, um rechtliche Probleme zu vermeiden.
Für weitere Tutorials und Tipps schau im und auf unserem vorbei.
FAQs
1. Ist es 2026 legal, Google-Maps-Daten mit Python zu scrapen?
Das Scrapen von Google Maps über die offizielle API ist im Rahmen der Google-Nutzungsbedingungen erlaubt, solange du Kontingente einhältst und keine eingeschränkten Daten weiterverbreitest. HTML-Scraping von Google Maps ist in Googles ToS ausdrücklich verboten und birgt rechtliche Risiken, insbesondere wenn du technische Schutzmaßnahmen umgehst oder personenbezogene Daten ohne Einwilligung sammelst. Prüfe immer lokale Gesetze (DSGVO, CCPA usw.) und halte dich an bewährte Compliance-Praktiken.
2. Was ist der Unterschied zwischen der Google-Maps-API und dem Web-Scraping des HTML?
Die API ist stabil, lizenziert und für die Datenextraktion gedacht, erfordert aber einen API-Schlüssel und unterliegt Kontingenten und Kosten. HTML-Scraping nutzt Browser-Automatisierung, um Daten aus der gerenderten Seite zu extrahieren, ist aber fragil (die Website ändert sich häufig), kann gegen die Nutzungsbedingungen verstoßen und ist rechtlich riskanter. Für die meisten geschäftlichen Anwendungsfälle ist die API der empfohlene Weg.
3. Was kostet es 2026, mit Python Daten aus Google Maps zu extrahieren?
Die Preise der Google Places API werden pro 1.000 Anfragen berechnet und liegen je nach angeforderten Feldern zwischen 5 US-Dollar (Essentials) und 25 US-Dollar (Enterprise+Atmosphere). Es gibt kostenlose monatliche Schwellenwerte (10.000 für Essentials, 5.000 für Pro, 1.000 für Enterprise), aber Scraping im großen Maßstab kann schnell teuer werden. Verwende immer Field Masks und serverseitige Filter, um die Kosten im Griff zu behalten.
4. Wie schneidet Thunderbit im Vergleich zu Python-basierten Google-Maps-Scrapern ab?
Thunderbit ist ein No-Code-, KI-gestützter Web-Scraper, mit dem du Google-Maps-Daten (und vieles mehr) ohne Programmierung, API-Schlüssel oder Wartungsaufwand extrahieren kannst. Er ist ideal für Vertriebs- und Marketingteams, die schnelle, zuverlässige Exporte nach Excel, Google Sheets, Airtable oder Notion benötigen. Für technische Nutzer mit individuellem Logikbedarf bietet Python mehr Flexibilität, erfordert aber auch mehr Setup und Compliance-Management.
5. Wie kann ich wiederkehrende Google-Maps-Datenextraktionen automatisieren?
Mit Python kannst du Planungsbibliotheken wie schedule oder APScheduler verwenden, um deinen Scraper in festen Intervallen auszuführen (täglich, wöchentlich usw.). Füge zufällige Verzögerungen hinzu, um Erkennung zu vermeiden, und überwache dein API-Kontingent. Mit Thunderbit kannst du wiederkehrende Scrapes direkt in der Benutzeroberfläche planen — ganz ohne Code oder Server-Setup.
Bereit, Google Maps in deine Vertriebs- und Marketing-Superkraft zu verwandeln? Egal, ob du Python-Fan bist oder die schnellste No-Code-Lösung suchst: 2026 stehen dir die passenden Tools zur Verfügung. Probiere für sofortiges, KI-gestütztes Scraping aus — oder krempel die Ärmel hoch und tauche in die API ein. So oder so: Mögen deine Lead-Listen frisch, deine Exporte sauber und deine Kampagnen voller hochkonvertierender lokaler Interessenten sein. Viel Erfolg beim Scrapen!
Mehr erfahren