Google hat seine Flights API bereits 2018 eingestellt, doch Flugpreise ändern sich weiter — für eine einzige Inlandsroute sogar . Wer programmgesteht auf diese Daten zugreifen möchte, kommt praktisch ums Scrapen nicht herum.
Ich habe lange verschiedene Ansätze getestet, um Flugdaten aus Google zu ziehen, und die Lage hat sich stark verändert — vor allem seit Google im Januar 2025 SearchGuard ausgerollt hat. In diesem Leitfaden zeige ich dir, wie du mit Playwright einen funktionierenden Python-Scraper für Google Flights baust, wie du die Anti-Bot-Schutzmechanismen umgehst, an denen die meisten scheitern, und wie du das Ganze anschließend zu einem automatisierten Preis-Tracker mit Warnmeldungen ausbaust. Wenn du lieber ganz ohne Code arbeiten möchtest, zeige ich dir außerdem einen No-Code-Shortcut mit , mit dem du in etwa zwei Minuten zum gleichen Ergebnis kommst.
Warum Google Flights mit Python scrapen?
Google Flights dominiert die Flugsuche. Die Sichtbarkeit in den US-Mobil-Suchergebnissen und überholte damit alle großen OTAs. Der dahinterliegende Metasuchmarkt im Reisebereich wird 2024 auf geschätzt und wächst mit 30,2 % CAGR. Seit die QPX-Express-API am , gibt es jedoch keinen offiziellen Weg mehr, diese Daten programmgesteuert abzurufen.
Gleichzeitig schwanken Flugpreise für dieselbe Verbindung — die Spanne zwischen dem günstigsten und teuersten Tarif liegt im Schnitt bei rund 20 US-Dollar. Airlines wie Delta arbeiten mit 77 Tarifstufen für dynamische Preisgestaltung. Der durchschnittliche US-Returnflug Anfang 2026 liegt bei 408 US-Dollar, während die Flugpreise liegen.
Dominante Plattform, keine API, volatile Preise — genau deshalb gehört das Scrapen von Google Flights mit Python zu den beliebtesten Projekten auf GitHub und in Reise-Foren.
Davon profitiert vor allem Folgendes:
| Nutzertyp | Anwendungsfall | Hauptvorteil |
|---|---|---|
| Privatreisende | Preise für bestimmte Strecken über längere Zeit beobachten | Im Schnitt $50 pro Flug sparen |
| Reisebüros | Wettbewerbsfähige Preisanalysen | Preisparität in Echtzeit überwachen |
| Corporate-Travel-Teams | Kostenoptimierung über verschiedene Routen hinweg | 10–30 % Ersparnis bei Geschäftsreisen |
| Entwickler | Flugpreis-Vergleichs-Apps bauen | Programmgesteuerter Zugriff auf Preisdaten |
| Forschende | Analyse von Preisschwankungen bei Airlines | Für akademische und Marktstudien |
In Foren sagen Nutzer offen, warum sie auf Scraping umgestiegen sind: „Die Google Flights API wurde eingestellt, also sollte ich stattdessen Web Scraping verwenden“ taucht immer wieder auf. Und der Aufwand lohnt sich: und wertet täglich über 5 Milliarden Preisabfragen aus, während die Expedia-Daten von 2026 zeigen, dass eine Buchung 8–15 Tage vorher bei Inlandsflügen rund .
Welche Daten kannst du aus Google Flights scrapen?
Eine Google-Flights-Ergebnisseite enthält erstaunlich viele Datenfelder. Typischerweise verfügbar sind:
- Name der Airline (inklusive Logo)
- Abflugzeit und Flughafencode
- Ankunftszeit und Flughafencode
- Gesamtdauer des Fluges
- Anzahl der Stopps und Umstiegsdetails (Flughafen, Dauer, Übernachtung)
- Ticketpreis (je nach Währung)
- CO2-Emissionen (kg CO2e, mit prozentualem Vergleich zu typischen Flügen)
- Reiseklasse, Flugnummer, Flugzeugmodell
- Beinfreiheit
- Ausstattung (WLAN, Steckdosen, Media-Streaming)
- Preisniveau (niedrig/typisch/hoch)
- Hinweise zu Verspätungen („Oft mehr als 30 Min. verspätet“)
Die Verfügbarkeit der Daten hängt von Route, Datum und Ticketart (Einweg vs. Hin- und Rückflug) ab. So sieht ein einzelner gescrapter Flugdatensatz als JSON aus:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Python-Umgebung einrichten
Bevor wir mit dem Scraping-Code beginnen, brauchst du ein paar Grundlagen.
Voraussetzungen:
- Schwierigkeitsgrad: Mittel
- Benötigte Zeit: ca. 1–2 Stunden für das komplette Tutorial
- Was du brauchst: Python 3.7+, grundlegende Python-Kenntnisse, ein Browser auf Chromium-Basis
Benötigte Bibliotheken installieren
Wir nutzen Playwright für die Browserautomatisierung (Google Flights ist zu 100 % JavaScript-gerendert — einfache HTTP-Requests liefern nichts Brauchbares), plus ein paar Hilfsmittel:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — Browser-Automatisierung ohne GUI, verarbeitet JavaScript-Rendering, integrierte Warte-Mechanismen
- playwright-stealth — kaschiert typische Bot-Erkennungssignale
- pandas — später für Datenanalyse und CSV-Export
Warum Playwright statt Selenium oder Requests?
Google Flights funktioniert nicht nur mit requests und BeautifulSoup — der Inhalt wird komplett per JavaScript gerendert. Du brauchst einen echten Browser.
| Feature | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS-Rendering | Voll unterstützt | Voll unterstützt | Keins |
| Geschwindigkeit | Insgesamt 42 % schneller | Basiswert | Für diesen Anwendungsfall nicht geeignet |
| Async-Support | Nativ | Nur sequenziell | Nicht relevant |
| Speicherverbrauch | 30 % geringer | Höher | Minimal |
| Umgehung von Bot-Erkennung | Gut (mit Stealth) | Leichter erkennbar | Nicht relevant |
Playwright ist schneller, moderner und bietet besseren Async-Support. Für Google Flights ist es ganz klar die beste Wahl.
Schritt für Schritt: Google Flights mit Python scrapen
Das ist der Kern des Tutorials. Wir bauen den Scraper Schritt für Schritt auf.
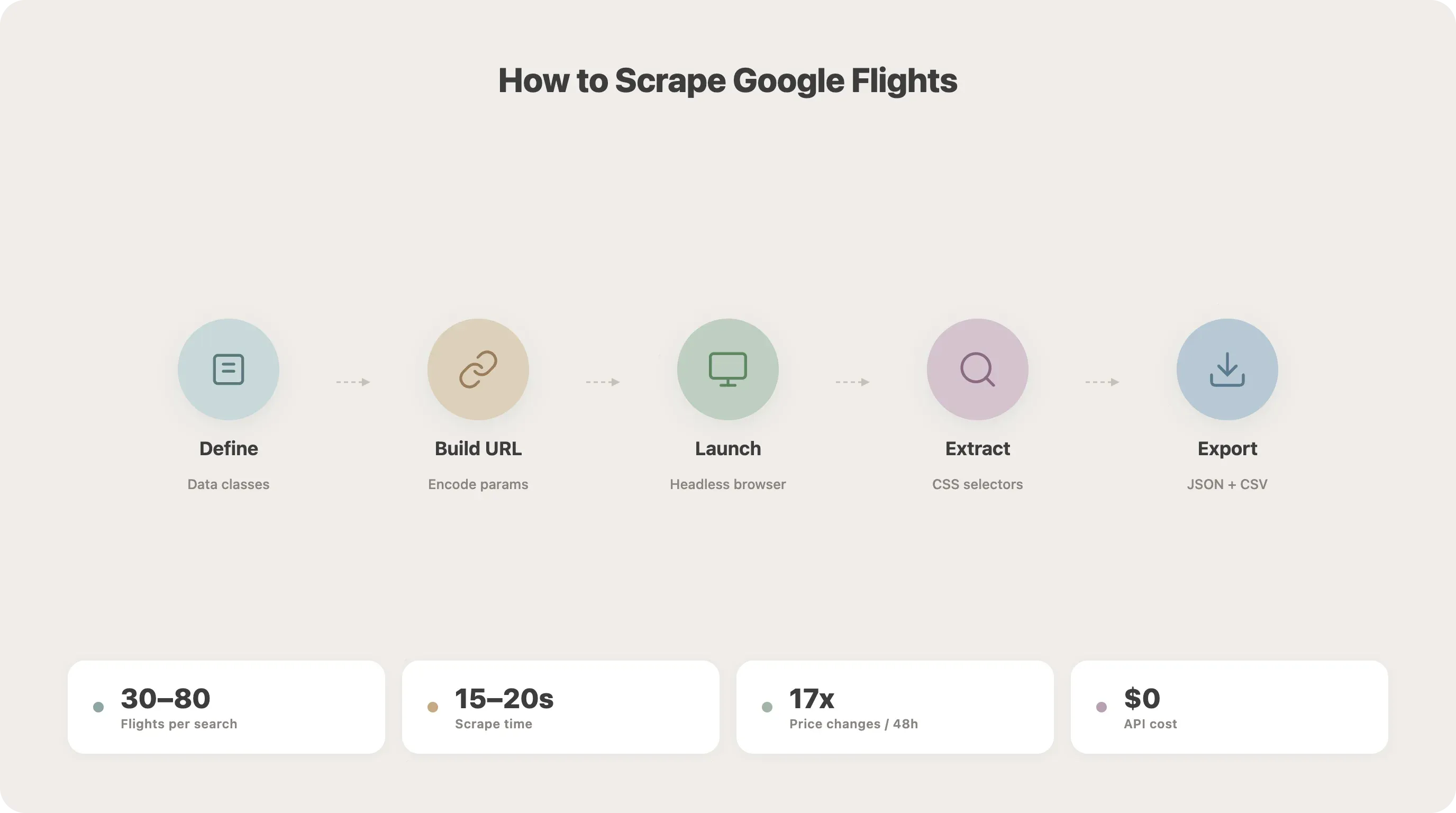
Schritt 1: Datenklassen definieren
Beginne damit, Suchparameter und Flugdaten mit Python-Dataclasses zu strukturieren. Das hält den Code sauber und macht spätere Erweiterungen einfacher.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # z. B. "SFO"
6 destination: str # z. B. "JFK"
7 departure_date: str # z. B. "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" oder "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Jedes Feld bildet direkt ab, was wir von der Seite extrahieren. Mit dieser Struktur musst du später keine unübersichtlichen Dictionaries mehr durchreichen.
Schritt 2: Die URL-Struktur von Google Flights verstehen
Google Flights kodiert Suchparameter über Base64-kodierte Protobuf-Daten im URL-Parameter tfs. Du kannst diese Kodierung reverse-engineeren oder den einfacheren Weg gehen und eine URL in natürlicher Sprache bauen.
Die einfachste Variante ist dieses Suchmuster:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDFür mehr Kontrolle kannst du URLs auch programmatisch erzeugen:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"Die Alternative — das Reverse-Engineering der Protobuf-Kodierung — bietet mehr Präzision, bricht aber, sobald Google das interne Format verändert. Bibliotheken wie auf GitHub nutzen Protobuf-Dekodierung, um HTML-Parsing komplett zu umgehen, aber das ist der fortgeschrittenere Ansatz.
Schritt 3: Browser starten und zu Google Flights navigieren
Hier kommt das Playwright-Setup. Wir nutzen playwright-stealth, um das Risiko einer Erkennung von Anfang an zu senken.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Cookie für Consent vorab setzen, um das Popup zu überspringen
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Wir starten im Headless-Modus für den Produktivbetrieb (für Debugging auf headless=False umstellen), setzen ein realistisches Viewport- und User-Agent-Profil und legen das SOCS-Cookie vorab fest, damit das Consent-Popup übersprungen wird — dazu mehr im Anti-Bot-Abschnitt.
Schritt 4: Zu den Suchergebnissen navigieren
Lade die erzeugte URL und warte, bis die Flugergebnisse erscheinen:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Warten, bis die Flugdaten geladen sind
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Wenn hier ein Timeout auftritt, liegt das meist daran, dass entweder das Consent-Popup die Seite blockiert (siehe den Cookie-Fix in Schritt 3) oder Google eine CAPTCHA-Seite ausliefert. Beide Fälle behandeln wir im Anti-Bot-Abschnitt.
Schritt 5: Alle Flugergebnisse laden
Google Flights versteckt zusätzliche Ergebnisse hinter einem Button mit der Aufschrift „More flights anzeigen“. Du musst ihn mehrfach klicken, bis alle Flüge sichtbar sind:
1 # „Show more flights“ klicken, bis alle Ergebnisse geladen sind
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakDiese Schleife klickt den Button, wartet 2 Sekunden auf das Nachladen und beendet sich, sobald der Button nicht mehr sichtbar ist. In meinen Tests haben die meisten Routen 1–3 Ergebnisseiten.
Schritt 6: Flugdaten mit CSS-Selektoren extrahieren
Jetzt lesen wir die eigentlichen Flugdaten aus der geladenen Seite aus. Hier sind die Selektoren (Stand April 2026 verifiziert — warum dieses Datum wichtig ist, erkläre ich im Wartungsabschnitt weiter unten):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Name der Airline
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Abflugzeit
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Ankunftszeit
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Dauer
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stopps
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Preis
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2-Emissionen
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsWichtiger Hinweis: Klassennamen wie pIav2d, sSHqwe und FpEdX werden vom Closure Compiler von Google erzeugt und können sich mit jedem Build ändern. Die aria-label-Selektoren sind deutlich stabiler. Eine robuste Wartungsstrategie folgt weiter unten.
Schritt 7: Ergebnisse als JSON oder CSV speichern
Zum Schluss speichern wir die gescrapten Daten mit Zeitstempel ab — wichtig für späteres Preis-Tracking:
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Zusätzlich als CSV speichern
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"{len(flights)} Flüge gescrapt")
25asyncio.run(main())Führe das aus, und du solltest flights.json und flights.csv mit deinen Ergebnissen erhalten. In meinen Tests liefert eine SFO-JFK-Suche typischerweise 30–80 Flugoptionen und dauert etwa 15–20 Sekunden.
Überlebensleitfaden gegen Bot-Erkennung beim Google Flights Scraping
Die meisten Tutorials hören hier auf. Die meisten Scraper scheitern genau hier. Google hat eingeführt und damit über Nacht fast alle SERP-Scraper ausgehebelt. Google beschreibt das System als „das Ergebnis von zehntausenden Arbeitsstunden und Investitionen in Millionenhöhe“. Google Flights wird beim Scraping mit bewertet.
Kein Konkurrenzartikel geht hier wirklich in die Tiefe, obwohl genau das der Hauptgrund ist, warum Scraper nicht mehr laufen. Hier siehst du, womit du rechnen musst und wie du damit umgehst.

Zufällige Pausen zwischen Anfragen
Der einfachste Schutz gegen Rate Limiting. Zwei Codezeilen, mittlere Wirkung:
1import time
2import random
3time.sleep(random.uniform(3, 7))Setze das zwischen Seitenaufrufen ein. Feste Intervalle (zum Beispiel immer genau 5 Sekunden) sind verdächtig — besser zufällig wählen.
User-Agent-Rotation
Bei jeder Anfrage dieselbe User-Agent-Zeichenkette zu senden, ist leicht erkennbar. Nutze eine rotierende Liste:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Headless-Erkennung umgehen
Google prüft das Flag navigator.webdriver und weitere Automatisierungssignale. Die Bibliothek playwright-stealth kaschiert viele davon, zusätzlich solltest du die in Schritt 3 gezeigten Startargumente setzen. Die wichtigsten Flags:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Damit kommst du an der einfachen Erkennung vorbei. SearchGuard geht weiter — es beobachtet Mausgeschwindigkeit, Tastatur-Timing und Scrollmuster — aber für Scraping in moderatem Umfang reicht Stealth-Modus zusammen mit realistischen Pausen oft aus.
Proxy-Rotation: Datacenter vs. Residential
Für mehr als nur ein paar Abfragen brauchst du Proxies. Der Unterschied ist wichtig:
Residential Proxies sind beim Scraping geschützter Seiten pro erfolgreicher Anfrage ungefähr . Preisbeispiele 2026: Smartproxy ab 7 $/GB, Bright Data 8,40 $/GB, Oxylabs 8 $/GB.
So bindest du einen Proxy in Playwright ein:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Umgang mit dem Cookie-Consent-Popup
Nutzer berichten immer wieder, dass das Popup mit der Zustimmung zu Bedingungen blockiert: „zuerst zeigt Google das Popup ‚I agree to terms and conditions‘ an.“ Die sauberste Lösung ist das vorab gesetzte SOCS-Cookie (siehe Schritt 3). Falls das nicht reicht, klicke es einfach weg:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # Kein Popup vorhandenHinweis: Der Text des Buttons hängt von der Sprache ab — auf Deutsch heißt er etwa „Alle akzeptieren“, auf Französisch „Tout accepter“.
Schnellübersicht Anti-Bot-Techniken
| Technik | Schwierigkeitsgrad | Wirksamkeit | Code nötig? |
|---|---|---|---|
| Zufällige Pausen (2–7 Sek.) | Niedrig | Mittel | 2 Zeilen |
| User-Agent-Rotation | Niedrig | Mittel | 5 Zeilen |
| Headless-Erkennung umgehen | Mittel | Hoch | Playwright-Startargumente |
| playwright-stealth-Plugin | Mittel | 60–80 % bei einfachen Sites | pip install |
| Proxy-Rotation (Datacenter) | Mittel | Mittel | Konfiguration |
| Proxy-Rotation (Residential) | Mittel | 85–95 % Erfolg | Konfiguration |
| Consent-Cookie vorab setzen (SOCS) | Niedrig | Erforderlich | 1 Zeile |
Empfohlene sichere Raten: 10–20 Sekunden Verzögerung zwischen Anfragen bei IP-Rotation. Googles Schwellenwerte liegen ungefähr bei 100 Anfragen pro Minute und IP, bevor ein 429 auftreten kann; anhaltende Mengen über 1.000 Anfragen pro Tag und IP können zu temporären Sperren führen.
Warum deine Google-Flights-Selektoren ständig kaputtgehen – und wie du das behebst
Das mit Abstand größte Problem. Foren sind voll mit Varianten von „Ich bekomme nur 14 leere Listen zurück.“ Jeder Leitfaden gibt dir Selektoren. Kaum einer erklärt, warum sie kaputtgehen.
Warum sich Google-Flights-Selektoren ändern
Das hat drei Hauptgründe:
-
Obfuskation durch den Closure Compiler. Google nutzt , um per
goog.setCssNameMapping()Klassennamen wieBVAVmfundYMlIzzu erzeugen. Diese ändern sich mit jedem Build — manchmal wöchentlich. -
A/B-Tests. Unterschiedliche Nutzer sehen gleichzeitig unterschiedliche HTML-Strukturen. Dein Scraper kann auf deinem Rechner funktionieren, bei jemand anderem in einer anderen Region aber versagen.
-
Lokale Unterschiede. Nutzer in der EU sehen andere Begriffe, Layouts und sogar andere Datenfelder als Nutzer in den USA.
Robuste Selektoren schreiben
Bevorzuge Selektoren, die an Bedeutung statt an Optik gekoppelt sind:
1# Fragil — bricht bei jedem Build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# Robuster — an Accessibility-Labels gebunden
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Ebenfalls robust — textbasierte Suche
6more_btn = page.locator('button:has-text("Show more flights")')Hierarchie der Selektor-Stabilität (von stabil nach instabil):
aria-label-Attribute — für Barrierefreiheit gedacht, selten geändertdata-*-Attribute — explizit für Funktionen ergänztrole-Attribute — ARIA-Rollen sind semantisch- textbasierte Selektoren — passen auf sichtbaren Inhalt
- Teilstring-Matching bei Klassen — z. B.
[class*="price"] - Vollständig obfuskierte Klassennamen — wenn möglich vermeiden
Eine Validierungsfunktion hinzufügen
Lass kaputte Selektoren nicht stillschweigend leere Daten erzeugen. Fang das früh ab:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Fehlendes Feld '{field_name}' — Selektoren müssen möglicherweise aktualisiert werden"
11 )
12 valid = False
13 return validLass das bei jedem gescrapten Flug laufen. Wenn Warnungen auftauchen, solltest du die Seite prüfen und deine Selektoren aktualisieren.
Strategie zur Wartung von Selektoren
- Selektoren monatlich prüfen oder sofort, wenn die Ausgabequalität sinkt
- Selektoren in einem separaten Konfigurations-Dictionary speichern, damit Updates leichter sind
- Die Selektoren in diesem Artikel wurden zuletzt im April 2026 verifiziert
- Als Alternative kannst du die in Betracht ziehen — sie nutzt Protobuf-Dekodierung statt CSS-Selektoren und umgeht dieses Problem komplett (ist aber ebenfalls anfällig, wenn Google interne Datenformate ändert)
Vom einmaligen Scrape zum automatisierten Google-Flights-Preis-Tracker
Die meisten Tutorials enden bei „als JSON speichern“. Der Titel dieses Artikels spricht von „Preisalarmen“. Zeit, das zu liefern.
![]()
Den Scraper automatisch planen
Option 1: Python-Bibliothek schedule (am einfachsten, plattformübergreifend):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Option 2: Cron-Job (Linux/Mac):
1# Täglich um 6:00 und 18:00 ausführen
20 6,18 * * * cd /path/to/scraper && python scraper.pyOption 3: Windows Aufgabenplanung — erstelle eine einfache Aufgabe, die python scraper.py nach deinem gewünschten Zeitplan ausführt.
Der Nachteil: Alle drei Varianten brauchen einen Rechner, der dauerhaft läuft. Wenn du das auf einem Laptop machst, der in den Standby geht, verpasst du Läufe.
Historische Preisdaten speichern
Statt eine JSON-Datei immer zu überschreiben, kannst du Daten an eine SQLite-Datenbank anhängen:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Nach einer Woche mit zwei Scrapes pro Tag hast du genug Daten, um Trends zu erkennen.
Preistrends analysieren und Alarme setzen
Finde die günstigste Option aus deinen historischen Daten:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Am günstigsten: ${cheapest['price_usd']:.0f} am "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Löse eine E-Mail-Benachrichtigung aus, wenn ein Preis unter deinen Schwellenwert fällt:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Preisalarm! {route}: ${price:.0f} "
6 f"(unter deinem Schwellenwert von ${threshold:.0f})"
7 )
8 msg["Subject"] = f"Flugangebot: {route} für ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# Nach jedem Scrape nach günstigen Angeboten prüfen
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Empfohlene Frequenz fürs Scraping: zweimal täglich reicht für das private Preis-Monitoring völlig aus (zufällige Zeitpunkte senken das Erkennungsrisiko). Für geschäftliche Überwachung alle 4–6 Stunden. Stündliches Scraping nur während kurzer Rabattaktionen und nur vorübergehend.
Der einfache Weg: Thunderbits geplanter Scraper
Wenn Cron-Jobs, ein laufender Server und Proxy-Konfigurationen nach mehr Infrastruktur klingen, als du pflegen möchtest, erledigt Thunderbits denselben Anwendungsfall ohne diesen Aufwand. Du beschreibst das Intervall in natürlicher Sprache, gibst deine Google-Flights-URLs ein, und der Scraper läuft automatisch in Thunderbits Cloud-Infrastruktur — inklusive integrierter Anti-Bot-Behandlung und direktem Export nach . Er ersetzt den vollständigen Python-Ansatz nicht, weil du weniger Freiheiten hast, aber für den konkreten Fall „Ich will eine Preis-Tracking-Tabelle“ ist er der schnellste Weg. Testen kannst du ihn mit dem .
Wenn Python überdimensioniert ist: No-Code-Wege, um Google Flights zu scrapen
Nach all dem Ehrlichsein: Das ist ziemlich viel Technik. Nicht jeder braucht so viel Kontrolle. Selektoren brechen, Proxies müssen rotiert werden, Cron-Jobs müssen überwacht werden. Wenn dein Ziel einfach ist, „Flugpreise regelmäßig in eine Tabelle zu bekommen“, gibt es schnellere Optionen.
Vergleich: Python selbst bauen vs. API-Dienste vs. Thunderbit
| Ansatz | Einrichtungszeit | Programmierung nötig | Anti-Bot abgedeckt | Planung | Kosten |
|---|---|---|---|---|---|
| DIY mit Playwright (dieses Tutorial) | 1–2 Stunden | Python (Mittelstufe) | Manuelle Konfiguration | Manuell (Cron) | Kostenlos + Proxy-Kosten |
| SerpApi Google Flights Endpoint | 15 Min. | Nur API-Aufrufe | Inbegriffen | Über API | ca. 50 $/Monat oder mehr |
| Thunderbit Chrome Extension | 2 Min. | Keine | Cloud-Scraping | Integrierter Scheduler | Kostenloser Tarif verfügbar |
Ein Hinweis zu SerpApi: Google und behauptete, dass deren Anfragen innerhalb von zwei Jahren um 25.000 % gestiegen seien. Diese rechtliche Unsicherheit solltest du berücksichtigen, wenn du API-Anbieter bewertest.
So scrapt Thunderbit Google Flights
Öffne deine Google-Flights-Suchergebnisse in Chrome, klicke auf Thunderbits Schaltfläche „AI Suggest Fields“ — die KI liest die Seite aus und schlägt Spalten wie Airline, Preis, Abflugzeit und Stopps vor — prüfe die Vorschläge und klicke dann auf „Scrape“. Die Ergebnisse erscheinen in einer Tabelle, die du nach Excel, Google Sheets, Airtable oder Notion exportieren kannst — alles im .
Für genau den Anwendungsfall Preis-Tracking ersetzen Thunderbits Scheduled Scraper und (mit bis zu 50 Seiten parallel) die komplette Cron-/Proxy-/Server-Infrastruktur.
Python gibt dir volle Kontrolle und unbegrenzte Anpassbarkeit. Thunderbit bietet Geschwindigkeit und keinen Wartungsaufwand. Wähle das, was zu deinem echten Ziel passt. Wenn du mehr über No-Code-Scraping erfahren möchtest, lies unseren Leitfaden zu den .

Ist das Scrapen von Google Flights legal? Das solltest du wissen
Das kommt in Foren regelmäßig auf: „Google Flights direkt zu scrapen verstößt gegen Googles AGB.“ Ein berechtigter Punkt — besonders, weil die API eingestellt wurde und es keine offiziell abgesegnete Alternative gibt.
AGB-Verstoß vs. rechtliche Haftung
Googles Nutzungsbedingungen (aktualisiert am 22. Mai 2024) besagen, dass Nutzer die Dienste oder Inhalte nicht „mithilfe automatisierter Mittel (z. B. Roboter, Spider oder Scraper) abrufen oder verwenden“ dürfen. Ein Verstoß gegen die AGB ist eine Vertragsverletzung (zivilrechtlich) — das ist nicht dasselbe wie ein Gesetzesverstoß.
Der wichtigste juristische Präzedenzfall ist hiQ v. LinkedIn (Ninth Circuit, 2022): Das Scraping öffentlich zugänglicher Daten verstößt demnach nicht gegen den Computer Fraud and Abuse Act (CFAA). Der Fall endete jedoch mit einem Vergleich, und Googles Klage gegen SerpApi aus dem Dezember 2025 stützt sich auf eine andere juristische Theorie — DMCA Section 1201 (Umgehung technischer Schutzmaßnahmen) — und ist potenziell ernster.
Best Practices für verantwortungsvolles Scraping
- Anfragen drosseln — 10–20 Sekunden Verzögerung mit IP-Rotation
- Keine personenbezogenen Daten scrapen — Flugpreise sind öffentlich angezeigte, aggregierte Daten
- CAPTCHAs nicht programmgesteuert umgehen (genau hier liegt das DMCA-Risiko)
- Daten für persönliche Recherche nutzen, nicht für ein konkurrierendes kommerzielles Produkt ohne passende Lizenz
- Offizielle APIs prüfen, wenn verfügbar
Alternative Datenquellen
Wenn Scraping für deinen Anwendungsfall zu riskant wirkt, gibt es legale API-Optionen:
| Anbieter | Kosten | Kostenloser Tarif | Hinweise |
|---|---|---|---|
| SerpApi | 75–3.750 $/Monat oder mehr | 250 Suchen/Monat | Direktes Google-Flights-JSON (rechtlich umstritten) |
| Kiwi Tequila | Kostenlos (Affiliate-Modell) | Unbegrenzt | Gut für Startups und Tests |
| Amadeus | Pay-as-you-go | 2.000 Anfragen/Monat | 400+ Airlines, Buchungsfunktionen |
| Skyscanner | Individuell | Genehmigung erforderlich | 52 Märkte, 30 Sprachen |
Wir haben außerdem einen ausführlicheren Artikel zu den , wenn du das Thema komplett aufdröseln möchtest.
Fazit und wichtigste Erkenntnisse
Das war eine Menge. Entscheidend ist Folgendes:
- Python + Playwright ist der flexibelste Ansatz für Google Flights Scraping, erfordert aber laufende Wartung
- Anti-Bot-Maßnahmen wie Verzögerungen, User-Agent-Rotation und Residential Proxies sind nicht optional — sie sind für Stabilität essenziell, besonders nach SearchGuard
- Selektoren brechen häufig — nutze nach Möglichkeit
aria-label- und textbasierte Selektoren, prüfe deine Ergebnisse und halte Wartungsintervalle ein - Automatisiere mit
scheduleoder Cron, um aus einem einmaligen Scrape einen echten Preis-Tracker mit historischen Daten und E-Mail-Warnungen zu machen - bietet eine No-Code-Alternative mit integrierter Planung, Cloud-Scraping und Anti-Bot-Unterstützung — ideal, wenn du eine Preis-Tracking-Tabelle statt eines Programmierprojekts willst
- Halte dich an rechtliche Grenzen — drossele Anfragen, scrape nur öffentliche Daten und prüfe für kommerzielle Nutzung API-Alternativen
Nimm den Code aus diesem Tutorial oder installiere die für den schnellen Weg. So oder so verfolgst du künftig Flugpreise, statt Google Flights ständig manuell zu aktualisieren.
Für weitere Python-Scraping-Techniken schau dir unsere Leitfäden zu und den an.
FAQs
1. Kann ich Google Flights ohne Python scrapen?
Ja. API-Dienste wie SerpApi und Kiwi Tequila liefern strukturierte Flugdaten über API-Aufrufe (ohne Browser-Automatisierung). Für einen komplett No-Code-Ansatz kann die Google-Flights-Ergebnisse direkt aus dem Browser scrapen — mit KI-gestützten Feldern und Export per Klick.
2. Blockiert Google das Scraping von Flugdaten?
Google setzt Bot-Erkennung (SearchGuard), CAPTCHAs und Rate Limiting ein. Mit den richtigen Anti-Bot-Maßnahmen — zufällige Verzögerungen, User-Agent-Rotation, Residential Proxies und Stealth-Browser-Einstellungen — lässt sich Scraping in moderatem Umfang zuverlässig betreiben. Sieh dir den Anti-Bot-Abschnitt oben für konkrete Techniken und Schwellenwerte an.
3. Wie oft sollte ich Google Flights für Preis-Tracking scrapen?
Zweimal täglich zu zufälligen Zeiten reicht für privates Preis-Monitoring und hält das Erkennungsrisiko niedrig. Für geschäftliche Überwachung alle 4–6 Stunden mit Proxy-Rotation. Stündliches Scraping solltest du nur während kurzfristiger Tarifaktionen nutzen — sonst steigt die Blockierwahrscheinlichkeit deutlich.
4. Gibt es eine kostenlose Google-Flights-API?
Die offizielle Google QPX Express API wurde . Es gibt keinen kostenlosen offiziellen Ersatz. Die nächstliegende kostenlose Option ist die (Affiliate-Modell, unbegrenzte Suchen). SerpApi bietet 250 kostenlose Suchen pro Monat. Für die meisten Nutzer ist Scraping oder ein No-Code-Tool wie Thunderbit der praktikabelste Weg.
5. Warum liefern meine Google-Flights-CSS-Selektoren immer wieder leere Daten?
Google nutzt den Closure Compiler, um obfuskierte Klassennamen zu erzeugen, die sich mit jedem Build ändern. A/B-Tests und lokale Unterschiede sorgen außerdem dafür, dass die HTML-Struktur zwischen Nutzern variiert. Die Lösung: aria-label-Attribute und textbasierte Selektoren statt Klassennamen verwenden, eine Validierungsfunktion einbauen, um Probleme früh zu erkennen, und die Selektoren monatlich prüfen. Sieh dir den Abschnitt zur Selektor-Wartung für eine ausführliche Strategie an.
Mehr erfahren