Wenn dein Glassdoor-Scraper 2022 noch sauber gelaufen ist und heute nur noch 403-Fehler zurückwirft, bist du damit definitiv nicht allein. In Foren taucht immer wieder dieselbe Frage auf: „Weiß jemand, warum dieser Scraper nicht mehr funktioniert?“
Die kurze Antwort: Glassdoor hat sich grundlegend verändert. Recruit Holdings hat Glassdoor im Juli 2025 in Indeed integriert, und den Anti-Bot-Schutz so stark hochgeschraubt, dass einfache Selenium- und requests-basierte Scraper schon blockiert werden, bevor überhaupt das erste Byte HTML geladen ist. Seit Februar 2026 laufen Glassdoor-Logins komplett über Indeed Login — jedes Tutorial, das ein Glassdoor-spezifisches Login-Formular fest verdrahtet, ist damit technisch schon an der Quelle hinfällig. Gleichzeitig bietet die Plattform weiterhin für . Diese Daten sind enorm wertvoll für HR-Benchmarking, Wettbewerbsanalysen und Lead-Generierung im Vertrieb — vorausgesetzt, du kommst überhaupt noch heran. Dieser Leitfaden ist die Version, die nach all diesen Änderungen funktioniert. Er deckt alle drei Glassdoor-Datentypen ab — Jobs, Bewertungen und Gehälter — an einem Ort. Ich zeige dir den Python-Ansatz mit funktionierendem Code für 2025, erkläre dir genau, was dich blockiert und wie du es umgehst, und zeige einen No-Code-Shortcut für alle, die den technischen Aufwand lieber komplett überspringen möchten.
Warum Glassdoor 2025 mit Python scrapen?
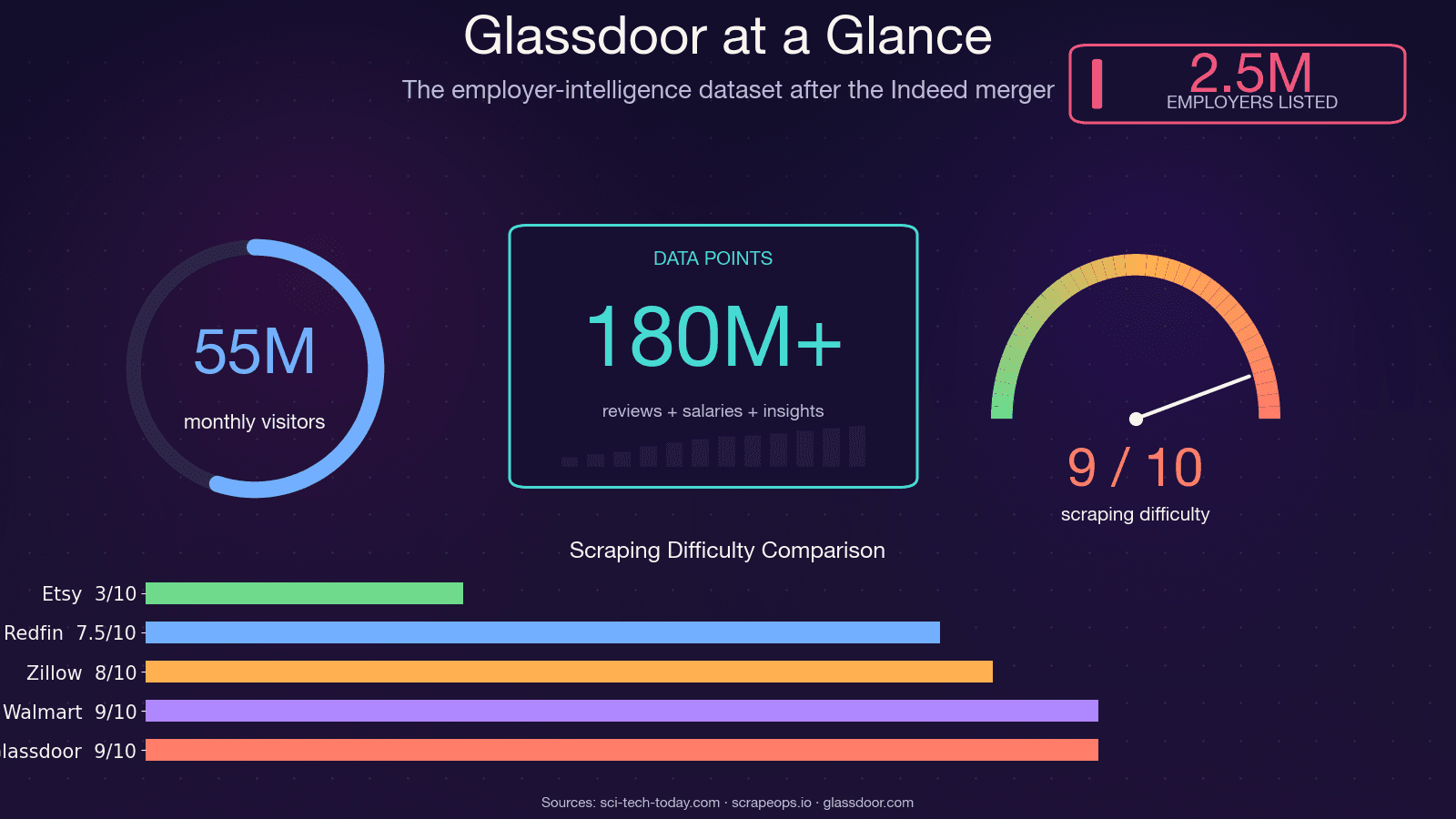
Glassdoor ist nicht einfach nur eine Jobbörse. Es ist einer der reichsten Datensätze für Arbeitgeber-Intelligence im Web — genutzt von etwa und mit rund 55 Millionen monatlich eindeutigen Besuchern. Die Daten hinter diesen Seiten fließen direkt in echte Geschäftsentscheidungen über mehrere Teams hinweg.
So nutzen verschiedene Teams Glassdoor-Daten in der Praxis:
| Anwendungsfall | Benötigter Datentyp | Wer profitiert |
|---|---|---|
| Gehaltsbenchmarking | Gehaltsverteilungen, Stichprobengrößen | HR, Total Rewards, Operations |
| Tracking der Personalaktivität von Wettbewerbern | Stellenanzeigen, Veröffentlichungsfrequenz | Vertrieb, Strategie, VC/Corp Dev |
| Monitoring der Arbeitgebermarke | Bewertungstexte, Rating-Trends, CEO-Zustimmungswerte | HR, Marketing, Kommunikation |
| Lead-Generierung (wachsende Unternehmen) | Stellenanzeigen + Unternehmensinfos | Vertriebsteams, SDRs |
| Markt- und Hochschulforschung | Alle drei | Analysten, Berater, Forschende |
Als das BLS während des US-Regierungsstillstands im Oktober 2025 keine Arbeitsmarktdaten veröffentlichen konnte, publizierte Glassdoors eigenes Economic Research Team auf Basis seines Datensatzes. So ernst nehmen institutionelle Analysten diese Daten inzwischen.
Python ist dafür weiterhin die naheliegende Sprache, weil das Ökosystem unschlagbar ist — Playwright für Browser-Automatisierung, parsel/lxml fürs Parsen, curl_cffi zum Umgehen von TLS-Fingerprints und eine riesige Community mit funktionierenden Ansätzen. Das Problem ist nicht Python. Das Problem ist, dass Glassdoor heute deutlich schwerer zu scrapen ist.
Wenn du eine No-Code-Alternative für die Extraktion von Glassdoor-Daten suchst, kann Thunderbit dir helfen, Jobs, Bewertungen und Gehaltsseiten zu scrapen, ohne einen eigenen Python-Stack aufzubauen und zu pflegen.
Welche Glassdoor-Daten lassen sich überhaupt scrapen?
Die meisten Tutorials behandeln nur Stellenanzeigen. Aber die Nachfrage der Nutzer — gemessen an Forum-Threads, GitHub-Issues und Reddit-Fragen, die ich verfolgt habe — ist bei den zwei Datentypen am höchsten, die fast niemand erklärt: Bewertungen und Gehälter. Hier ist die vollständige Übersicht dessen, was sich in allen drei Kategorien extrahieren lässt.
Stellenanzeigen
Der am einfachsten zugängliche Datentyp. Du kannst u. a. folgende Felder auslesen: Jobtitel, Firmenname, Standort, Gehaltsschätzung, Firmenbewertung, Veröffentlichungsdatum, Easy-Apply-Kennzeichnung und den Link zur Stelle. Stellenanzeigen sind teilweise auch ohne Login verfügbar, wobei Glassdoor nach einigen Seiten eine Login-Einblendung anzeigen kann.
Unternehmensbewertungen
Hier wird es für die Analyse der Arbeitgebermarke besonders spannend. Extrahierbare Felder sind unter anderem: Gesamtbewertung, Teilbewertungen (Work-Life-Balance, Kultur & Werte, Diversität & Inklusion, Karrierechancen, Vergütung & Benefits, obere Führungsebene), Pro-Text, Contra-Text, Jobtitel der bewertenden Person, Bewertungsdatum und Beschäftigungsstatus. Der vollständige Bewertungstext ist durch einen Login geschützt — sichtbar ist nur ein Ausschnitt, der komplette Pro-/Contra-Teil erfordert Authentifizierung.
Gehaltsdaten
Der am häufigsten nachgefragte und zugleich frustrierendste Datentyp. Du kannst Jobtitel, Grundgehaltsspanne, Gesamtvergütungsspanne, Anzahl der Gehaltsmeldungen und Standort extrahieren. Gehaltsseiten sind jedoch vollständig login-geschützt, und Glassdoor nutzt teils zusätzlich einen „beitragen, um freizuschalten“-Flow, bei dem du erst dein eigenes Gehalt einreichen musst, bevor du die Daten anderer sehen kannst. Kein konkurrierendes Tutorial liefert dafür funktionierenden Code — das beheben wir hier.
Was Login erfordert und was nicht
Diese Tabelle erspart dir das frustrierende Ausprobieren, welche Seiten leer zurückkommen:
| Datentyp | Ohne Login verfügbar? | Hinweise |
|---|---|---|
| Titel und Basisinfos von Stellenanzeigen | Meist ja | Popup kann nach einigen Seiten erscheinen |
| Vollständige Stellenbeschreibungen | Teilweise | Oft nach 2–3 Ansichten gesperrt |
| Unternehmensbewertungen (voller Text) | Nein — Login erforderlich | Ausschnitt sichtbar, Volltext gesperrt |
| Gehaltsdaten | Nein — Login erforderlich | Eventuell zusätzlich „beitragen, um freizuschalten“ |
Warum dein alter Glassdoor-Scraper wahrscheinlich kaputt ist
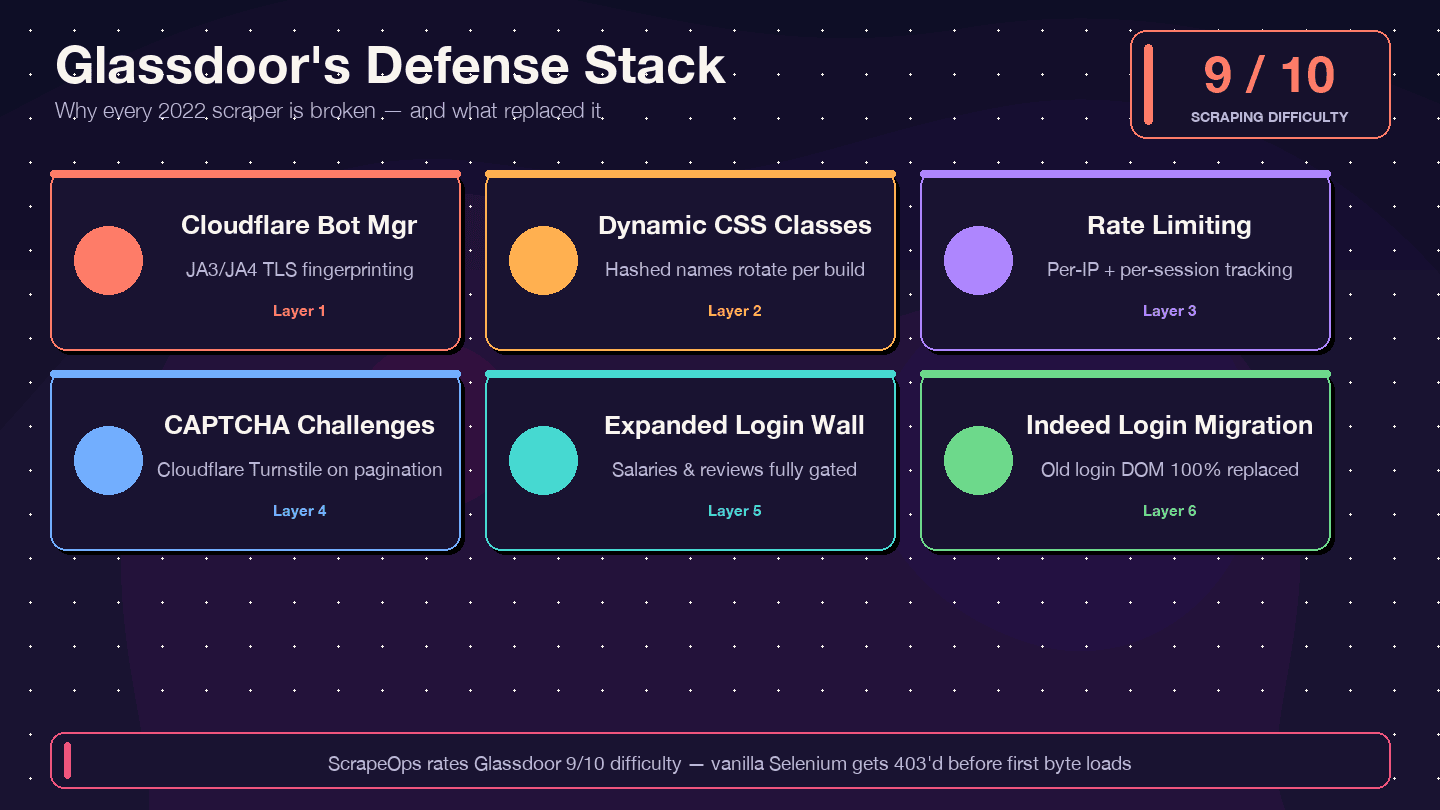
Ich sag’s offen: Wenn du Code aus einem Tutorial von 2021–2023 kopierst, wird er nicht funktionieren. Der am häufigsten mit Sternen versehene alte Glassdoor-Selenium-Scraper auf GitHub (, ca. 1,4k Sterne) hat mehr als 12 offene, ungelöste Issues — darunter „Glassdoor new UI design“, „Cloudflare anti-bot protection“ und „NoSuchElementException“. Das Repo wird faktisch nicht mehr aktiv gepflegt. . und 8/10 bei der Umgehung.
Das hat sich geändert — und deshalb bricht alter Code:
| Schutzschicht | Was sich geändert hat | Auswirkung auf alte Scraper |
|---|---|---|
| Cloudflare Bot Management | Strengere JA3/JA4-Fingerprinting-Prüfungen seit 2024 | Einfache requests-/Selenium-Skripte werden sofort mit 403 blockiert |
| Dynamische CSS-Klassennamen | Klassennamen werden bei jedem Build neu generiert | Alte CSS-Selektoren aus Tutorials funktionieren still und leise nicht mehr |
| Rate-Limiting + Session-Tracking | Strengere Limits pro IP und Sitzung | Scraper werden nach weniger Seiten blockiert |
| CAPTCHA-Hürden (vermutlich Cloudflare Turnstile) | Häufiger, vor allem bei der Seitennavigation | Headless-Browser lösen Challenges aus |
| Erweiterte Login-Schranke | Mehr Seitentypen erfordern Authentifizierung | Gehalts- und Bewertungsseiten liefern leere Daten |
| Migration zu Indeed Login (Feb. 2026) | Glassdoor-Loginformular vollständig ersetzt | Jeder Code, der das alte Login-DOM anspricht, ist hinfällig |
enthält einen klaren Hinweis: „Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked.“ Und ein sagt es noch deutlicher: „Simple HTTP requests with requests or httpx get blocked instantly.“
Die Gegenmaßnahmen, die ich dir zeige — Patchright (ein stealth-orientierter Playwright-Fork), data-test-Selektoren, rotierende Residential Proxies und authentifizierte persistente Sessions — sind genau dafür gebaut, diese Schutzschichten zu umgehen.
Glassdoor API vs. Python-Scraping: Zuerst den richtigen Ansatz wählen
In mehreren Foren taucht die Frage auf: „Soll ich einfach die Glassdoor API verwenden?“ — die ehrliche Antwort lautet: nein, das kannst du nicht.
Die . Das Developer-Portal existiert zwar technisch noch, liefert aber . Eine öffentliche Reviews-API gab es nie — MatthewChathams Scraper wurde ausdrücklich gebaut, „weil Glassdoor keine API für Bewertungen hat“. Und unter der Indeed Publisher API gibt es keinen Migrationspfad für Bewertungen oder Gehälter.
Hier ist der ehrliche Vergleich:
| Faktor | Glassdoor Partner API v1 | Python-Scraping | Thunderbit (No-Code) |
|---|---|---|---|
| Zugriff | Für neue Anträge geschlossen | Offen (du setzt es selbst um) | Chrome-Erweiterung |
| Stellenanzeigen | Eingeschränkt/auslaufend | Mit Aufwand verfügbar | Verfügbar |
| Unternehmensbewertungen | Öffentlich nie vorhanden | Ja (Login nötig) | Ja (über Browser Mode) |
| Gehaltsdaten | Öffentlich nie vorhanden | Ja (Login nötig) | Ja |
| Rate Limits | Nicht dokumentiert | Du kontrollierst das Tempo | Credit-basiert |
| Einrichtungsaufwand | Keine neuen Apps registrierbar | Stunden bis Tage | Ca. 2 Minuten |
| Wartungsaufwand | Nicht anwendbar | Hoch (HTML-Änderungen brechen Code) | Gering (KI schlägt Felder neu vor) |
Wenn du Bewertungen oder Gehaltsdaten brauchst — und die meisten, die hier lesen, brauchen genau das — dann sind Python-Scraping oder ein No-Code-Tool deine einzigen realistischen Optionen.
Bevor du startest
- Schwierigkeit: Mittelstufe (du solltest dich mit Python und dem Terminal wohlfühlen)
- Zeitaufwand: ca. 30–60 Minuten für die komplette Einrichtung; danach etwa 10 Minuten pro Datentyp
- Was du brauchst:
- Python 3.10+ (empfohlen: 3.11 oder 3.12)
- Installierter Chrome-Browser
- Ein Glassdoor-Konto (kostenlos — nötig für Gehalts- und Bewertungsdaten)
- Rotierende Residential Proxies (für mehr als ein paar Seiten)
- Optional: , wenn du den No-Code-Weg gehen willst
Tools und Bibliotheken für Glassdoor-Scraping mit Python in 2025
Die Tool-Landschaft hat sich drastisch verändert. Das hier funktioniert tatsächlich gegen die aktuellen Schutzmechanismen von Glassdoor.
Warum Patchright die beste Wahl für Glassdoor ist
ist ein stealth-orientierter Playwright-Fork, der den Runtime.Enable-CDP-Leak behebt — genau das technische Problem, an dem Vanilla Playwright auf Cloudflare-geschützten Seiten scheitert. Die API ist identisch zu Playwright, also gilt: Wenn du Playwright kennst, kennst du auch Patchright. Version 1.58.2 (März 2026) ist aktuell und wird aktiv gepflegt.
Im Vergleich zu Alternativen:
- Vanilla Playwright: Wird auf Glassdoors Login-Seite wegen des Runtime.Enable-Leaks erkannt
- Selenium + undetected-chromedriver: Die letzte Veröffentlichung von undetected-chromedriver stammt aus Februar 2024 — faktisch Legacy. ergab, dass es „auf jeder getesteten Domain fehlgeschlagen“ ist
- requests + BeautifulSoup: Kann kein JavaScript rendern und wird durch Cloudflares TLS-Fingerprinting sofort blockiert
- : Hervorragend für den schnellen Pfad (10–20x schneller als ein Browser), wenn Seiten
__NEXT_DATA__bereits im initialen HTML mitliefern, aber ungeeignet für Login oder Zwischen-Challenges
Unterstützende Bibliotheken
- parsel (1.11.0) oder lxml (6.0.4): Schnelles HTML-/XPath-Parsen
- csv oder pandas: Datenexport
- asyncio: Asynchrones Scraping für schnellere Pagination
Proxies: nur Residential
Glassdoors Cloudflare-Schicht ist sehr aggressiv gegenüber Datacenter-ASNs. . Die Einstiegspreise liegen ungefähr bei (Aktionspreis) oder $3,00/GB bei . Für produktives Scraping solltest du je nach Volumen mit 3–8 $/GB kalkulieren.
Zufällige Verzögerungen zwischen Requests (mindestens 3–8 Sekunden, bei längeren Läufen 5–15 Sekunden) sind unabhängig von der Proxy-Qualität unverzichtbar.
Schritt 1: Python-Umgebung einrichten
Erstelle den Projektordner und installiere den empfohlenen Stack:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Core stack
6pip install patchright==1.58.2 parsel==1.11.0
7# Browser-Binaries installieren
8patchright install chromium
9# Optional: schneller Pfad für __NEXT_DATA__-Extraktion
10pip install "curl_cffi==0.15.0"Patchright sollte nun ein Chromium-Binary herunterladen. Wenn patchright install chromium fehlschlägt, prüfe, ob genug Speicherplatz vorhanden ist (ca. 300 MB) und ob deine Python-Version 3.10+ ist.
Schritt 2: Patchright starten und zu Glassdoor navigieren
So sieht der grundlegende Start aus, der mit Glassdoors Cloudflare-Schicht funktioniert:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # Headless ist weiterhin leichter erkennbar
6 channel="chrome", # echtes Chrome statt mitgeliefertem Chromium verwenden
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Login-Overlay ausblenden — der Inhalt ist trotzdem noch im DOM vorhanden
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Seite geladen — Stellenanzeigen sichtbar.")Zwei Dinge sind hier wichtig. Das Flag channel="chrome" sorgt dafür, dass Patchright dein lokal installiertes Chrome-Binary verwendet statt des mitgelieferten Chromium — das erzeugt einen deutlich authentischeren Browser-Fingerprint. Der add_style_tag-Trick blendet Glassdoors Login-Modal (#HardsellOverlay) aus, ohne etwas anklicken zu müssen. , dass „der gesamte Inhalt noch da ist, nur vom Overlay verdeckt wird“ — das HTML enthält die Daten unabhängig davon, ob das Modal sichtbar ist.
Du solltest ein Chrome-Fenster sehen, das zur Glassdoor-Jobsuche navigiert und Jobkarten anzeigt, ohne dass das Login-Popup die Ansicht blockiert.
Schritt 3: Glassdoor-Stellenanzeigen scrapen
Stabile Selektoren finden
Glassdoor randomisiert CSS-Klassennamen bei jedem Build — der Selektor .jobCard_xyz123 aus einem Tutorial von 2023 liefert heute daher still und leise nichts mehr. Verwende stattdessen data-test-Attribute, die Glassdoor intern für QA nutzt und die über Deployments hinweg stabil bleiben.
Hier ist die Selektor-Referenz für die Felder in Stellenanzeigen:
| Feld | Selektor |
|---|---|
| Jobkarten-Container | [data-test="jobListing"] |
| Jobtitel | [data-test="job-title"] |
| Job-Link | a[data-test="job-link"] |
| Firmenname | [data-test="employer-name"] |
| Standort | [data-test="emp-location"] |
| Gehaltsspanne | [data-test="detailSalary"] |
| Firmenbewertung | [data-test="rating"] |
| Veröffentlichungsdatum | [data-test="job-age"] |
| Nächste Seite | [data-test="pagination-next"] |
Jobdaten extrahieren
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Seite {page_num}: Keine Karten gefunden — möglicher Block oder Selektorwechsel.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Seite {page_num}: {len(cards)} Jobs extrahiert")
26 # Pagination
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsAls CSV speichern
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("Keine Jobs zum Speichern vorhanden.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"{len(jobs)} Jobs in {filename} gespeichert")Ein Hinweis zu Pagination-Limits: Glassdoor begrenzt Suchergebnisse unabhängig von der Gesamtanzahl auf ungefähr 30 Seiten. Wenn du mehr Abdeckung brauchst, arbeite mit Filtern (Ort, Jobtyp, Gehaltsspanne), um jede Suche enger zu fassen, statt über das Limit hinaus zu paginieren.
In meinen Tests dauerte das Scrapen von 5 Seiten mit Stellenanzeigen (etwa 75 Jobs) mit zufälligen Verzögerungen rund 45 Sekunden. Dasselbe manuell zu erledigen würde mindestens 20 Minuten Copy-Paste kosten.
Schritt 4: Glassdoor-Unternehmensbewertungen scrapen
Das ist der Abschnitt, für den dir in keinem anderen Tutorial funktionierender Code geboten wird. Bewertungen sind der Ort, an dem die eigentliche Arbeitgeber-Intelligenz steckt — Sentiment-Analyse, Kultur-Signale, Warnsignale beim Management.
Zur Bewertungsseite navigieren
Bewertungs-URLs folgen diesem Muster: /Reviews/{Company}-Reviews-E{id}.htm. Die Employer-ID findest du, indem du ein Unternehmen auf Glassdoor suchst und die URL prüfst.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)Der versteckte BFF-Endpunkt (der sauberste Weg)
Die wichtigste Erkenntnis aus meiner Recherche: Glassdoor-Bewertungen haben eine funktionierende interne JSON-API, die HTML-Parsen komplett umgeht. Das dokumentiert diesen Endpunkt, und er ist deutlich zuverlässiger als DOM-Scraping.
1import json, re, requests
2def get_review_ids(page):
3 """Extrahiert employerId und dynamicProfileId aus dem HTML der Bewertungsseite."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Ruft Glassdoors internen BFF-Endpunkt für strukturierte Bewertungsdaten auf."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF lieferte auf Seite {pg} Status {resp.status_code}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Bewertungsseite {pg}/{total_pages}: {len(reviews)} Bewertungen erhalten")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsDer BFF-Endpunkt liefert sauberes JSON mit allen Bewertungsfeldern — kein HTML-Parsen, keine kaputten CSS-Selektoren. Du brauchst dafür Session-Cookies aus einem authentifizierten Playwright-Kontext (siehe Schritt 6 unten) und musst zuerst die employerId sowie die dynamicProfileId aus dem HTML der Bewertungsseite extrahieren.
HTML-Fallback-Selektoren für Bewertungen
Falls sich der BFF-Endpunkt ändert oder du lieber DOM-basiert arbeitest, hier die stabilen data-test-Selektoren:
| Feld | Selektor |
|---|---|
| Bewertungs-Container | [data-test="review"] |
| Überschrift | [data-test="review-title"] |
| Gesamtbewertung | [data-test="overall-rating"] |
| Pro | [data-test="pros"] |
| Contra | [data-test="cons"] |
| Datum | [data-test="review-date"] |
| Rolle der Autorin/des Autors | [data-test="author-jobTitle"] |
Schritt 5: Glassdoor-Gehälter scrapen
Gehaltseiten sind vollständig login-geschützt. Du brauchst zwingend eine authentifizierte Sitzung (Schritt 6), bevor dieser Code echte Daten zurückliefert.
Zur Gehaltsseite navigieren
Gehalts-URLs folgen diesem Muster: /Salary/{Company}-Salaries-E{id}.htm, paginiert als _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Gehaltseite {pg}: Keine Einträge — mögliches Login-Gate oder Block.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Gehaltseite {pg}: {len(items)} Einträge extrahiert")
25 return all_salariesBeachte das Muster [class*="SalaryItem_jobTitle__"]. Auf der Gehaltsseite von Glassdoor werden CSS-Module-Hashes verwendet, zum Beispiel SalaryItem_jobTitle__XWGpT, wobei der Hash-Teil bei jedem Deploy wechselt. Der Präfix bleibt stabil — der Hash nicht. Hardcode niemals den vollständigen Klassennamen.
Schritt 6: Die Login-Schranke von Glassdoor überwinden
Das ist der entscheidende Schritt, um Gehaltsdaten und vollständige Bewertungstexte freizuschalten. Der Ansatz: Einmal manuell in einem sichtbaren Browser einloggen, den authentifizierten Sitzungszustand speichern und ihn dann für alle weiteren Scraping-Läufe wiederverwenden.
Deine authentifizierte Sitzung speichern
Führe dieses Skript einmal aus. Es öffnet ein Chrome-Fenster, navigiert zur Glassdoor-Login-Seite (die inzwischen zu Indeed Login weiterleitet) und wartet darauf, dass du dich manuell anmeldest:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Melde dich im Browserfenster an und drücke dann hier Enter...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Sitzung gespeichert unter {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Nachdem du dich eingeloggt und Enter gedrückt hast, speichert Patchright alle Cookies und den Local Storage in glassdoor_state.json. Diese Datei enthält deine gdId, GSESSIONID, cf_clearance und Auth-Tokens.
Sitzung für das Scraping wiederverwenden
Jeder weitere Scraping-Lauf lädt den gespeicherten Zustand — manuelles Einloggen ist dann nicht mehr nötig:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlDie gespeicherte Sitzung hält in der Regel 20–30 Minuten aktiver Nutzung, bevor Glassdoor erneut prüft. Für längere Scraping-Läufe solltest du einen Check einbauen: Wenn eine Seite, die Daten enthalten müsste, null Ergebnisse liefert, führe das Login-Skript erneut aus, um den State zu erneuern.
Login-Popup erkennen und ausblenden
Bei teilweise geschützten Seiten (z. B. Stellenanzeigen, bei denen Daten sichtbar sind, aber ein Overlay darüberliegt) funktioniert der CSS-Injection-Ansatz aus den vorherigen Schritten:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Das funktioniert nur, wenn das HTML die Daten bereits unter dem Overlay enthält. Bei vollständig serverseitig geschützten Seiten (Gehälter, tiefere Bewertungsseiten) ist die authentifizierte Sitzung aus Schritt 6 der einzige Weg.
Tipps, damit dein Glassdoor-Scraper stabil läuft
Glassdoor aktualisiert das Frontend häufig. So baust du Robustheit in deinen Scraper ein.
data-test-Attribute statt Klassennamen verwenden
Glassdoor randomisiert CSS-Klassennamen, behält data-test-Attribute aber meist bei. Nutze immer [data-test="jobListing"] statt .jobCard_abc123. Wenn kein data-test verfügbar ist, wie bei Gehaltsfeldern, verwende den Präfix-Match-Ansatz: [class*="SalaryItem_jobTitle__"].
Proxies rotieren und Verzögerungen zufällig gestalten
Nutze rotierende Residential Proxies — Datacenter-IPs werden fast sofort geprüft. Baue zwischen Seitenaufrufen zufällige Pausen von 3–8 Sekunden ein, bei längeren Läufen eher 5–15 Sekunden. Vermeide nach Möglichkeit Scraping während der US-Geschäftszeiten, wenn Cloudflares Verhaltensanalyse am strengsten ist.
Auf Brüche achten
Baue eine einfache Prüfung in deinen Scraper ein: Wenn eine Seite, die Daten enthalten sollte, null extrahierte Datensätze liefert, behandle das als Selektorproblem und nicht als leeres Ergebnis — und lasse dich benachrichtigen. Führe wöchentlich einen kleinen Testlauf aus, um Brüche früh zu erkennen — Glassdoor veröffentlicht Frontend-Änderungen ohne Vorankündigung.
Den __NEXT_DATA__-Schnellpfad nutzen, wenn möglich
Glassdoor ist eine Next.js- und Apollo-GraphQL-App. Viele Seiten liefern ein <script id="__NEXT_DATA__">-Tag, das den vollständigen GraphQL-Cache als JSON enthält. Das zu parsen ist deutlich robuster als DOM-Scraping und :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneDas liefert den strukturierten Apollo-Cache mit allen Job-, Bewertungs- und Gehaltsfeldern — ganz ohne CSS-Selektoren. Das ist die robusteste verfügbare Extraktionsstrategie, weil es dieselben Daten sind, die auch Glassdoors React-Frontend antreiben.
Ohne Code: Glassdoor mit Thunderbit scrapen
Nicht jeder, der das hier liest, ist Entwickler. HR-Teams, Recruiter, Sales-Ops-Analysten und Marktforscher brauchen Glassdoor-Daten genauso — und sollten dafür nicht Playwright-Kontexte und Proxy-Rotation verwalten müssen.
ist eine AI-Web-Scraper-Chrome-Erweiterung, die dieselben Job-, Bewertungs- und Gehaltsdaten ohne eine einzige Zeile Code extrahieren kann. Ich arbeite im Thunderbit-Team, deshalb sage ich das offen — aber der Grund, warum ich es hier nenne, ist, dass es die beiden schwierigsten Probleme beim Glassdoor-Scraping tatsächlich löst.
So funktioniert Thunderbit auf Glassdoor
Der Ablauf besteht aus zwei Klicks:
- Öffne eine beliebige Glassdoor-Seite in Chrome (Jobsuche, Unternehmensbewertungen, Gehaltsseite)
- Klicke in der Thunderbit-Seitenleiste auf AI Suggest Fields — die KI liest den DOM der Seite und schlägt Spalten vor (Jobtitel, Unternehmen, Bewertung, Gehaltsspanne, Pro, Contra usw.)
- Klicke auf Scrape — die Daten werden ohne CSS-Selektoren oder Browser-Automatisierungscode in eine Tabelle extrahiert
Thunderbit bietet ein , das pro Unternehmen in einem Lauf mehr als 23 Felder extrahiert. Für Stellenanzeigen, Bewertungen oder Gehälter funktioniert der allgemeine AI-Suggest-Fields-Workflow für jede Glassdoor-URL.
Die Login-Schranke ohne Code umgehen
Das ist Thunderbits struktureller Vorteil bei Glassdoor. Der Browser Mode läuft in deiner eigenen Chrome-Sitzung — wenn du in Chrome bei Glassdoor eingeloggt bist, übernimmt Thunderbit diese Cookies automatisch. Die Login-Schranke für Gehälter und Bewertungen, die serverseitige Scraper blockiert, spielt dann keine Rolle mehr. Kein Cookie-Management, keine persistenten Kontexte, kein Session-Code.
Unterseiten-Scraping zur Anreicherung
Starte mit einer Listenansicht (z. B. 30 Unternehmen aus einer Suche), lasse Thunderbit die Zeilen erfassen und aktiviere dann , um jede Unternehmensseite mit Bewertungen oder Gehaltsinfos zu besuchen und die Tabelle mit vollständigen Beschreibungen, Bewertungstexten oder Gehaltsdetails anzureichern.
Export in Business-Tools
Anders als Python-Skripte, die CSV oder JSON ausgeben, exportiert Thunderbit direkt nach Google Sheets, Airtable, Notion oder Excel — in jedem Plan kostenlos. Besonders praktisch für Teams, die Daten gemeinsam teilen und analysieren müssen.
Python vs. Thunderbit: Wann du was nutzen solltest
| Situation | Empfohlener Ansatz |
|---|---|
| Wiederkehrende Datenpipeline bauen | Python + Patchright |
| Einmalige Recherche oder kleines Teamprojekt | Thunderbit |
| Programmgesteuerte Kontrolle über jedes Feld nötig | Python |
| Kein Entwickler, aber heute Glassdoor-Daten nötig | Thunderbit |
| 1.000+ Seiten in einem Lauf scrapen | Python + Proxies |
| 30 Unternehmen mit Anreicherung scrapen | Beides möglich — Thunderbit ist schneller eingerichtet |
Thunderbit startet kostenlos (6 Seiten/Monat); der für 3.000 Credits. Bei 1 Credit pro Ausgabezeile (2 Credits bei Subpage Scraping) reicht das für ungefähr 33 Läufe mit je 30 angereicherten Unternehmen pro Monat.
Ist Glassdoor-Scraping legal?
Ich halte es kurz und sachlich. Glassdoors verbieten automatisiertes Scraping ausdrücklich: „You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission.”
Die rechtliche Lage ist aber nuancierter als nur eine einzelne ToS-Klausel:
- (N.D. Cal., Jan. 2024): Das Gericht entschied, dass man den AGB nicht zustimmen kann, wenn man sich nie eingeloggt hat — öffentliches Scraping ohne Login verstößt daher nicht dagegen
- hiQ Labs v. LinkedIn (9th Cir.): Das CFAA-Gesetz greift nicht bei der automatisierten Sammlung öffentlich zugänglicher Daten — Fake-Accounts und Scraping im eingeloggten Zustand sind jedoch ein anderes Thema
- Van Buren v. United States (Supreme Court, 2021): Hat den Begriff „exceeds authorized access“ im CFAA eingegrenzt
Die praktische Schlussfolgerung: Das Scrapen öffentlicher Stellenanzeigen ohne Login bewegt sich in einer vergleichsweise sichereren rechtlichen Zone. Wer mit eingeloggter Sitzung scrapt, hat bei der Anmeldung den AGB zugestimmt, und dort wird es ausdrücklich verboten. Das gilt gleichermaßen für Python-Skripte und Thunderbits Browser Mode.
Unabhängig davon solltest du folgende ethische Leitlinien beachten:
- Deutlich langsamer als menschliches Surfverhalten arbeiten
- Keine personenbezogenen Daten von Bewertenden scrapen oder weiterverkaufen
- robots.txt-Anweisungen respektieren
- Nur die Felder extrahieren, die du tatsächlich brauchst
Fazit: Welche Methode passt zu dir?
Dieser Leitfaden hat alle drei Glassdoor-Datentypen abgedeckt — Jobs, Bewertungen und Gehälter — mit funktionierendem Code für 2025, der die Indeed-Login-Migration, Cloudflare Bot Management und die Rotation der CSS-Module-Klassennamen berücksichtigt, die alle älteren Tutorials kaputt gemacht hat.
So triffst du die Entscheidung:
| Deine Situation | Bester Weg |
|---|---|
| Entwickler baust eine Datenpipeline | Python + Patchright (folge der Schritt-für-Schritt-Anleitung oben) |
| Einmalige Recherche oder regelmäßige kleine Abrufe | Thunderbit (ohne Code, browserbasiert) |
| Du brauchst nur einfache Stellenanzeigen in kleinem Umfang | Prüfe zuerst, ob Glassdoor-API-Zugriff noch verfügbar ist (wahrscheinlich nicht) |
| Du brauchst ausdrücklich Gehalts- oder Bewertungsdaten | Du musst Python-Scraping oder Thunderbit nutzen — die API deckte das nie ab |
| Team ohne Entwickler, das gemeinsame Daten benötigt | Thunderbit → Export nach Google Sheets |
Glassdoors Schutzmechanismen werden sich weiterentwickeln. Selektoren werden brechen. Neue Challenges werden auftauchen. Setze dir ein Lesezeichen für diesen Leitfaden — und wenn du tiefer in Web-Scraping-Tools und -Techniken eintauchen willst, sieh dir unsere Beiträge zu , und an. Du kannst dir außerdem Walkthroughs auf dem ansehen.
FAQs
1. Kann man Glassdoor ohne Login scrapen?
Ja, für die meisten Stellenanzeigen-Daten und die wichtigsten Unternehmensbewertungen. Nein, für vollständige Gehaltsaufstellungen oder den kompletten Bewertungstext über die ersten Seiten hinaus. Das #HardsellOverlay ist ein reines CSS-Modal — der zugrunde liegende HTML-Code enthält die Daten der ersten Seite weiterhin — aber tiefergehende Inhalte sind serverseitig hinter Glassdoors „give-to-get“-Sperre geschützt.
2. Welche Python-Bibliothek eignet sich 2025 am besten für Glassdoor-Scraping?
Patchright (ein stealth-orientierter Playwright-Fork) ist die Standardempfehlung. Es behebt den Runtime.Enable-CDP-Leak, den Vanilla Playwright hat und den Cloudflare explizit prüft. Für Listen-Seiten, die __NEXT_DATA__ bereits im initialen HTML ausliefern, ist curl_cffi mit impersonate="chrome124" 10–20x schneller, kann aber keine login-geschützten Seiten verarbeiten.
3. Wie vermeide ich Blockierungen beim Scrapen von Glassdoor?
Nutze Patchright oder rebrowser-playwright (nicht Vanilla Playwright oder Selenium). Wechsle Residential Proxies — Datacenter-IPs werden sofort geprüft. Baue zufällige Pausen von 3–8 Sekunden zwischen Seiten ein. Behalte Cookies (gdId, cf_clearance, GSESSIONID) über Requests hinweg. Rechne damit, dass die Sitzung nach 20–30 Minuten erneut geprüft wird.
4. Gibt es eine Glassdoor-API als Alternative zum Scraping?
Praktisch nein. Die alte Partner API ist , eine öffentliche Reviews-API gab es nie, und unter der Indeed Publisher API existiert kein Migrationspfad. Für Bewertungen und Gehaltsdaten ist Scraping oder ein No-Code-Tool wie Thunderbit die einzige praktikable Option.
5. Wie oft brechen Glassdoor-Scraper?
Häufig. Glassdoor spielt Frontend-Änderungen ohne Ankündigung aus, und die Hashes der CSS-Module-Klassennamen wechseln bei jedem Build. Die stabilsten Extraktionsstrategien sind: (1) data-test-Selektoren, (2) der __NEXT_DATA__-JSON-Blob und (3) der interne BFF-Endpunkt für Bewertungen. Baue eine Null-Ergebnisse-Prüfung ein und führe wöchentlich einen kleinen Testlauf aus, um Brüche früh zu erkennen.
Mehr erfahren