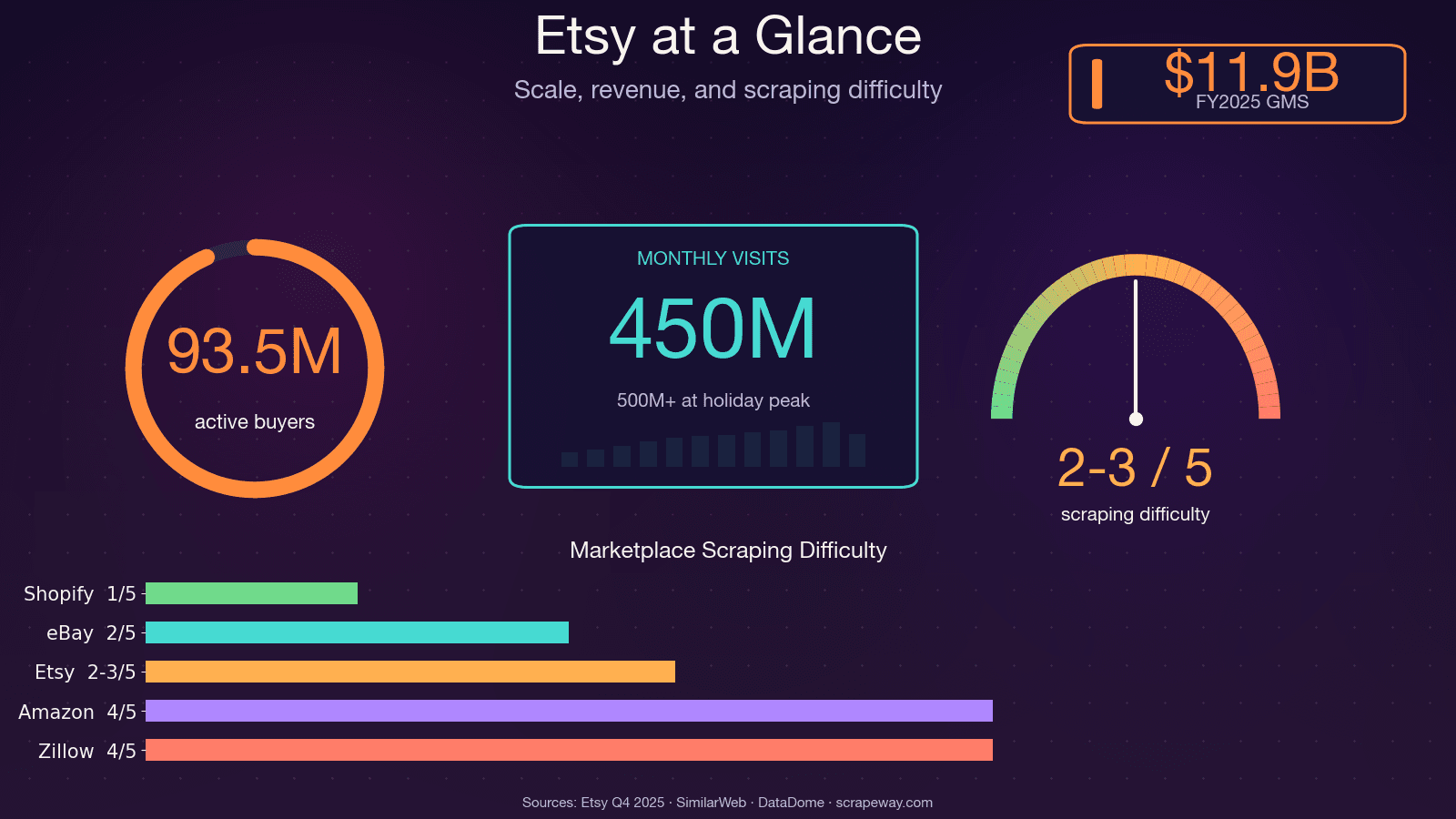
Etsy hat über 100 Millionen aktive Angebote, 5,6 Millionen Verkäufer und rund 450 Millionen Besuche pro Monat. Das sind eine Menge öffentlich verfügbarer Daten zu Preisen, Trends, Bewertungen und Wettbewerbern — und wenn Sie sie schon einmal von Hand zusammengesucht haben, wissen Sie, wie schmerzhaft das ist.
Ich habe einmal ein ganzes Wochenende damit verbracht, Konkurrenzprodukte für ein Marktanalyse-Projekt manuell zu katalogisieren. Bei Produkt Nummer 30 habe ich alles infrage gestellt, was mich zu dieser Tabelle geführt hat. Der Punkt ist: Etsy-Daten sind enorm wertvoll für Preisanalyse, Produktentwicklung, Nischenfindung und Verkäufer-Benchmarking — aber nur, wenn man sie wirklich in großem Umfang erfassen kann. Genau darum geht es in diesem Leitfaden: ein einziges Tutorial, das zeigt, wie man Etsy mit Python über alle vier wichtigen Seitentypen hinweg scrapen kann (Suchergebnisse, Produktseiten, Shop-Seiten und Bewertungen) — plus ehrliche Hinweise zu Etsy's Anti-Bot-Abwehr und eine No-Code-Alternative für alle, die das Programmieren lieber ganz überspringen.
Was bedeutet es, Etsy mit Python zu scrapen?
Web-Scraping bedeutet ganz einfach: Code zu schreiben, der Webseiten aufruft und automatisch die Daten extrahiert, die Sie interessieren — Produktnamen, Preise, Beschreibungen, Bilder, Bewertungen, Shop-Details — und sie in ein strukturiertes Format wie eine Tabelle oder Datenbank überführt.
Python ist dafür die erste Wahl. Die Sprache ist einsteigerfreundlich, hat eine riesige Community und bietet ein tiefes Ökosystem an Bibliotheken fürs Scraping: Requests (zum Abrufen von Seiten), BeautifulSoup (zum Parsen von HTML), Selenium und Playwright (für Browser-Automatisierung) sowie pandas (zum Organisieren und Exportieren von Daten). Python gehört im jährlichen Entwickler-Umfragebericht von Stack Overflow seit Jahren konstant zu den Top 3 der beliebtesten Sprachen, und seine Scraping-Bibliotheken zählen zu den meistgeladenen auf PyPI.
Wenn Sie Etsy scrapen, ziehen Sie Daten aus dem HTML (und manchmal aus verstecktem JSON), das Etsy an Ihren Browser ausliefert. Zu den Daten, die sich extrahieren lassen, gehören:
- Produktnamen, Preise, Beschreibungen, Bilder und Varianten
- Verkäufer-/Shop-Infos (Name, Verkaufszahlen, Standort, Bewertung)
- Bewertungen und vollständige Rezensionstexte
- Suchergebnis-Listings, Kategorien und Trend-Signale
Warum Etsy scrapen? Praxisnahe Anwendungsfälle mit echtem ROI
Etsy zu scrapen ist nicht nur eine technische Übung — es ist ein Wettbewerbsvorteil. Ob Sie Verkäufer, Produktmanager oder Datenanalyst sind: Strukturierte Etsy-Daten direkt verfügbar zu haben, kann sich unmittelbar auf Ihr Ergebnis auswirken.
| Anwendungsfall | Was Sie scrapen | Wer profitiert | Geschäftlicher Nutzen |
|---|---|---|---|
| Wettbewerbsfähige Preisanalyse | Suchergebnisse + Produktpreise | E-Commerce-Operations, Verkäufer | Dynamische Preisgestaltung kann den Umsatz im Schnitt um 5–22 % steigern |
| Nischen- und Trendentdeckung | Suchergebnisse, trendende Listings | Gründer, Analysten | Frühzeitig trendende Nischen erkennen (z. B. verzeichnete „preppy pajamas“ ein Suchwachstum von +1.112 %) |
| Produktentwicklung & Verbesserung | Bewertungen, Produktdetails | Produktteams | Eine Küchenwarenmarke eroberte mit Stimmungsdaten aus Bewertungen in 60 Tagen den #1-Bestseller zurück |
| SEO- & Keyword-Recherche | Suchergebnisse, Produkttitel/Tags | Marketing-Teams | Keywords mit hoher Nachfrage und geringer Konkurrenz identifizieren |
| Verkäufer-Benchmarking | Shop-Seiten, Verkaufszahlen | Vertriebsteams, Analysten | Qualifizierte Lead-Listen für 0,01–0,10 $ pro Datensatz statt gekaufter Listen aufbauen |
| Bestands- & Lagerüberwachung | Produktverfügbarkeit | E-Commerce-Operations | Schneller auf Bestandsänderungen von Wettbewerbern reagieren |
Jeder dieser Anwendungsfälle benötigt Daten von unterschiedlichen Etsy-Seitentypen — genau deshalb deckt dieses Tutorial alle vier ab.
Zeitersparnis: manuell vs. automatisiert
- Manuelle Etsy-Recherche: 30–45 Minuten pro Produkt (50–75 Stunden für 100 Produkte)
- Automatisiertes Scraping: 100 Listings in 2–5 Minuten
- KI-gestütztes Scraping ist bei bis zu 99,5 % Genauigkeit
Etsy-API vs. Web-Scraping: Was sollten Sie wählen?
Bevor Sie auch nur eine Zeile Code schreiben, lohnt sich die Frage: Soll ich Etsy's offizielle API nutzen oder die Website direkt scrapen? Diese Frage taucht in Foren ständig auf, und die Antwort hängt davon ab, welche Daten Sie brauchen.
Was die Etsy-API kann — und was nicht
Etsy bietet eine API v3 mit OAuth-2.0-Authentifizierung. Sie funktioniert für den Zugriff auf die Daten Ihres eigenen Shops — Listings, Bestellungen, Belege. Sie hat aber klare Grenzen:
- Wettbewerbsdaten: Die API ist größtenteils auf Ihren eigenen Shop beschränkt. Sie können weder Preise noch Verkäufe oder Listings anderer Verkäufer abrufen.
- Bewertungen: Es gibt keinen robusten Endpunkt für vollständige Rezensionstexte in großer Menge.
- Rate Limits: Standardmäßig 10 Anfragen/Sekunde, 10.000 Anfragen/Tag. Die Offset-Grenze liegt bei 12.000 Datensätzen.
- KI/ML-Nutzung: Wird im App-Review ausdrücklich abgelehnt.
- Dokumentation: Beschwerden aus der Community sind weit verbreitet — schlechte Beispiele, veraltete Endpunkte, langsamer Support.
Wann Web-Scraping der bessere Weg ist
Wenn Sie Wettbewerbsinformationen, Bewertungsstimmung, Analysen über mehrere Shops hinweg oder Daten brauchen, die die API nicht liefert, ist Scraping der richtige Weg. Der Haken: Sie werden auf Etsy's Anti-Bot-Abwehr treffen (dazu gleich mehr), und Sie müssen etwas Aufwand in die Einrichtung stecken.
Vergleichstabelle: API vs. Scraping vs. No-Code
| Kriterium | Etsy Official API | Python Web-Scraping | Thunderbit (No-Code) |
|---|---|---|---|
| Zugriff auf Produktpreise | ✅ (begrenzte Felder) | ✅ Vollständiges HTML/JSON-LD | ✅ KI extrahiert jedes sichtbare Feld |
| Bewertungsdaten | ❌ Nicht in großer Menge verfügbar | ✅ Über Bewertungsendpunkt/HTML | ✅ Unterseiten-Scraping |
| Shop-Daten von Wettbewerbern | ❌ Nur eigener Shop | ✅ Jeder öffentliche Shop | ✅ Jeder öffentliche Shop |
| Authentifizierung erforderlich | ✅ OAuth 2.0 | ⚠️ Cookies für eingeloggte Daten | ⚠️ Browser-Scraping für Login |
| Anti-Bot-Risiko | Keines | HOCH (DataDome) | Abgedeckt (browser-nativ) |
| Einrichtungszeit | Mittel (API-Keys, OAuth) | Hoch (Code + Proxies) | ~2 Minuten |
Wenn Sie Wettbewerbsdaten, Bewertungen oder Analysen über mehrere Shops hinweg brauchen, deckt die API das schlicht nicht ab. So ehrlich ist die Lage.
Wählen Sie Ihren Python-Scraping-Ansatz, bevor Sie eine Zeile Code schreiben
Eine Frage, die ich auf Reddit und Stack Overflow ständig sehe: „Soll ich Requests + BeautifulSoup, Selenium, eine Proxy-API oder etwas völlig anderes verwenden?“ Die richtige Antwort hängt von Ihrem Kenntnisstand, Ihrem Budget und Ihrem Anwendungsfall ab.
| Ansatz | Am besten geeignet für | Lernkurve | Unterstützt JS? | Anti-Bot-Handling | Kosten |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Entwickler, die volle Kontrolle wollen | Mittel | ❌ | Manuell (Header, Proxies) | Kostenlos + Proxykosten |
| Selenium / Playwright | JS-lastige Seiten, Login-Flows | Hoch | ✅ | Teilweise (Browser-Fingerprint) | Kostenlos + Proxykosten |
| Proxy-API-Dienste | Skalierung + Umgehung von Anti-Bot | Mittel | ✅ (über API) | ✅ Integriert | ab 49 $/Monat |
| Thunderbit (No-Code) | Nicht-Entwickler, schnelle Extraktion | Sehr niedrig | ✅ (browser-nativ) | ✅ (Browser-Sitzung) | Kostenloser Tarif verfügbar |
Wenn Sie volle Kontrolle wollen und sich mit Python wohlfühlen, nehmen Sie Requests + BeautifulSoup. Wenn Sie JavaScript-Rendering oder Login-Flows brauchen, nutzen Sie Selenium. Wenn Sie Anti-Bot-Umgehung in großem Stil benötigen, sollten Sie einen Proxy-Dienst in Betracht ziehen. Und wenn Sie Etsy-Daten möchten, ohne Code zu schreiben oder zu pflegen, ist Thunderbit einen Blick wert — dazu später mehr.
Wie Etsy sich wehrt: DataDome Anti-Bot-Schutz verstehen
Die meisten Scraping-Guides sagen einfach „nimm einen Proxy“ und gut ist. Für Etsy reicht das nicht. Etsy nutzt DataDome, eines der aggressivsten Anti-Bot-Systeme im Web. In wird Etsy als Erfolgsgeschichte hervorgehoben; dort wird erwähnt, dass Scraper früher rund 1 % der Rechenkosten von Etsy ausmachten.
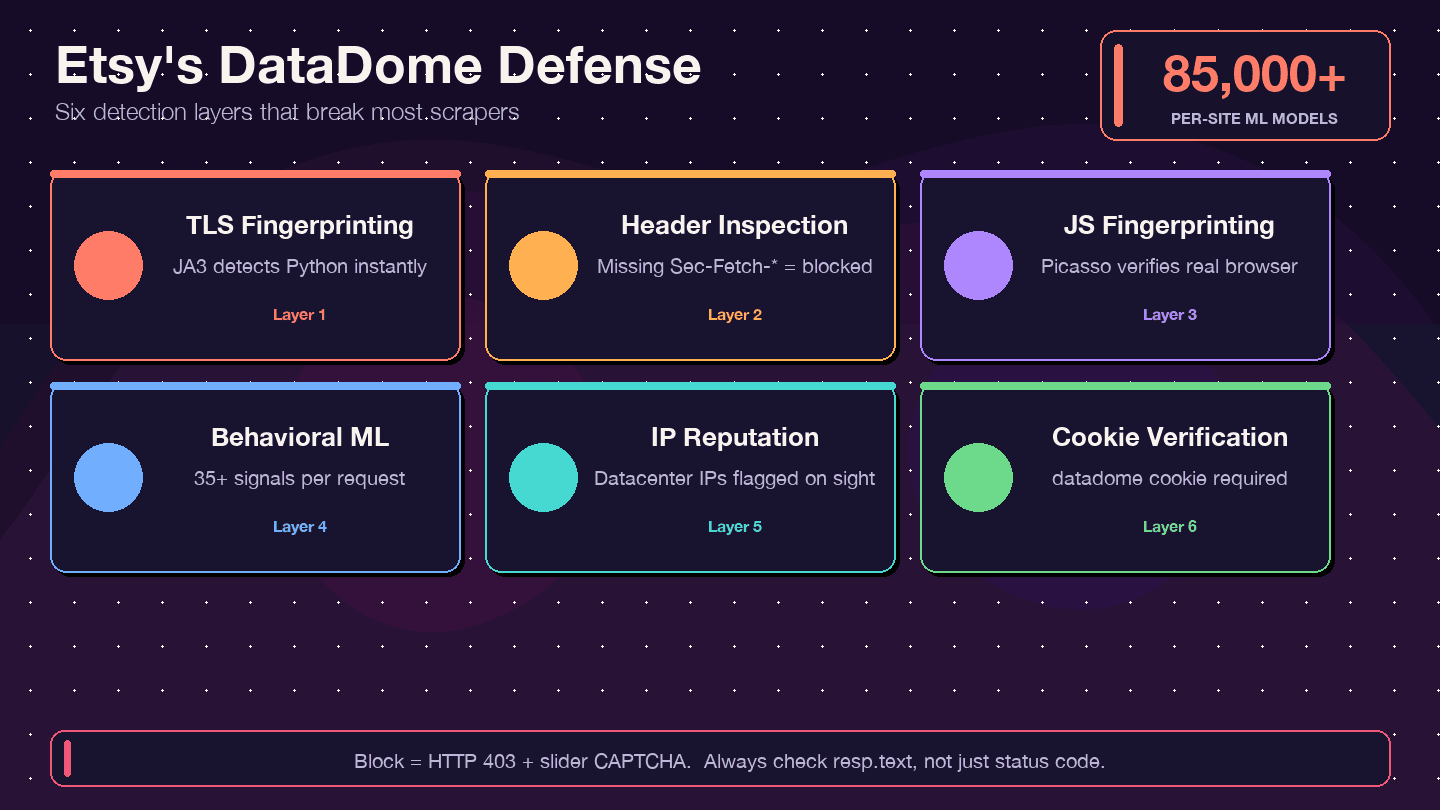
Was ist DataDome und wie funktioniert es?
DataDome prüft nicht nur Ihre IP-Adresse. Es verwendet eine mehrschichtige Erkennungslogik:
- TLS-Fingerprinting (JA3): Die
requests-Bibliothek von Python hat eine auffällige TLS-Signatur, die DataDome sofort erkennen kann. - Prüfung von HTTP-Headern und Protokollen: Es wird auf vollständige, konsistente Browser-Header geprüft — fehlende oder falsch sortierte Header sind ein Warnsignal.
- JavaScript-Fingerprinting (Picasso-Protokoll): JS-Challenges laufen im Browser, um zu verifizieren, dass Sie ein echter Nutzer sind.
- Verhaltensbasiertes ML: Analysiert pro Anfrage mehr als 35 Signale, mit über 85.000 site-spezifischen Modellen.
- IP-Reputationsbewertung: Rechenzentrums-IPs werden sofort markiert.
- Cookie-Prüfung: Das
datadome-Cookie muss vorhanden und gültig sein.
Woran Sie merken, dass Sie blockiert wurden — und wie Sie das prüfen
Einer der häufigsten Stolpersteine: Sie erhalten eine 200 OK-Antwort, aber das HTML ist eigentlich eine CAPTCHA-Seite und nicht die gewünschten Daten. Weitere Anzeichen:
- 403 Forbidden-Fehler
- Weiterleitungsschleifen
- Der Response-Body enthält ein
dd-JavaScript-Objekt oder CAPTCHA-HTML mit Slider
Prüfen Sie immer den Response-Body, nicht nur den Statuscode. Ein schneller Check:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("Blockiert! Statt Daten wurde eine CAPTCHA-Seite zurückgegeben.")Header und Cookies, die die Erkennung erschweren
Sie können nie garantieren, dass Sie nicht geblockt werden, aber realistische Header und sauberes Cookie-Management helfen enorm:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})Ebenfalls wichtig:
- Cookies über mehrere Anfragen hinweg beibehalten mit einer
requests.Session(). - Zufällige Pausen (2–7 Sekunden) zwischen den Anfragen einbauen.
- Eine Referrer-Kette simulieren: Erst die Startseite aufrufen, dann die Suche, dann die Produktseiten.
- Im großen Maßstab ist Residential-Proxy-Rotation unverzichtbar. Rechenzentrums-IPs werden nahezu sofort markiert.
Diese Techniken reduzieren die Erkennung, beseitigen sie aber nicht vollständig. Für Scraping mit hohem Volumen brauchen Sie wahrscheinlich einen Proxy-Dienst oder einen browserbasierten Ansatz.
Python-Umgebung einrichten, um Etsy zu scrapen
Bevor Sie beginnen:
- Schwierigkeitsgrad: Mittel
- Benötigte Zeit: ~30–60 Minuten (Einrichtung + erster Scrape)
- Was Sie brauchen: Python 3.8+, pip, einen Code-Editor, den Chrome-Browser (für die DevTools-Analyse)
Abhängigkeiten installieren
Erstellen Sie einen Projektordner, richten Sie eine virtuelle Umgebung ein und installieren Sie die benötigten Bibliotheken:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # Unter Windows: venv\\Scripts\\activate
4pip install requests beautifulsoup4 lxml pandas- requests — ruft Webseiten ab
- beautifulsoup4 — parst HTML
- lxml — schnellerer HTML-Parser (optional, aber empfohlen)
- pandas — strukturiert Daten und exportiert sie nach CSV/Excel
Wenn Sie später Browser-Automatisierung benötigen (für Login oder JS-lastige Seiten), installieren Sie außerdem:
1pip install seleniumVerstehen Sie die Seitenstruktur von Etsy, bevor Sie Code schreiben
Hier ist ein Tipp, der eine Menge Zeit spart: Etsy bettet auf den meisten Seiten strukturierte Produktdaten in <script type="application/ld+json">-Tags ein. Diese JSON-LD-Daten sind bereits organisiert — Produktname, Preis, Bewertung, Bilder — sodass Sie nicht für jedes Feld mit fragilen CSS-Selektoren kämpfen müssen.
Öffnen Sie eine beliebige Etsy-Produktseite, klicken Sie mit der rechten Maustaste auf „Seitenquelltext anzeigen“ und suchen Sie nach application/ld+json. Sie finden einen Block mit @type: Product, der die meisten benötigten Daten enthält. Suchergebnisseiten haben @type: ItemList.
CSS-Selektoren sind trotzdem als Fallback nützlich (für Daten, die nicht in JSON-LD enthalten sind, etwa Versanddetails oder Rezensionstext), aber JSON-LD sollte Ihr erster Anlaufpunkt sein.
Schritt 1: Etsy-Suchergebnisse mit Python scrapen
Suchergebnisse sind der Ausgangspunkt für die meisten Etsy-Scraping-Projekte — ob Sie eine Nische überwachen, die Preisentwicklung von Wettbewerbern verfolgen oder eine Produktdatenbank aufbauen.
Die Such-URL erstellen
Etsy-Such-URLs folgen diesem Muster:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}Bei mehrteiligen Suchanfragen sollten Sie die Leerzeichen URL-codieren (z. B. handmade+jewelry oder handmade%20jewelry). Der Parameter ref=pagination lässt die Anfrage mehr wie eine echte Browser-Navigation aussehen.
Weitere nützliche Parameter: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Jede Seite liefert 48 Einträge.
Anfrage senden und HTML parsen
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Auf Seite \{page\} blockiert. Versuchen Sie es mit Pausen oder Proxies.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsListing-Daten aus JSON-LD extrahieren
Das itemListElement-Array liefert Ihnen Name, URL, Bild, Preis und Währung jedes Listings. Wenn Sie zusätzlich Sternebewertungen oder Ergebniszahlen brauchen (nicht immer in JSON-LD enthalten), greifen Sie auf CSS-Selektoren zurück:
- Listing-Karte:
.v2-listing-card - Titel:
h3.v2-listing-card__title - Preis:
span.currency-value - Link:
a.listing-link(href)
Paginierung handhaben
Durchlaufen Sie die Seiten und fügen Sie zwischen den Anfragen eine zufällige Pause ein. Etsy gibt je nach Suchanfrage typischerweise bis zu 20–250 Seiten zurück.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"{len(results)} Produkte gescraped.")Bei einem 5-Seiten-Scrape dauerte das in meinen Tests etwa 20 Sekunden — verglichen mit mehr als 30 Minuten manuellem Copy-Paste.
Schritt 2: Etsy-Produktseiten mit Python scrapen
Sobald Sie eine Liste von Produkt-URLs aus der Suche haben, ist der nächste Schritt, detaillierte Daten von jeder Angebotsseite zu ziehen.
Die Produktseite abrufen
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NonePreisvarianten behandeln
Einige Produkte haben nur einen einzelnen offers.price. Andere (mit Varianten wie Größe oder Farbe) verwenden offers.lowPrice und offers.highPrice. Der Code oben deckt beides ab, indem er von price auf lowPrice zurückfällt.
Zusätzliche Felder per CSS-Selektor parsen
Für Daten, die nicht in JSON-LD stehen — Versandinfos, Variantenoptionen, vollständige Verkäuferdetails — brauchen Sie CSS-Selektoren:
- Titel:
h1[data-buy-box-listing-title] - Varianten:
select[data-selector-id]oderdiv[data-option-set] - Versand:
div.wt-text-captionin der Nähe des Versandbereichs
Der Kompromiss: JSON-LD ist sauberer und stabiler bei Layout-Änderungen. CSS-Selektoren sind fragiler, decken aber mehr Felder ab.
Schritt 3: Etsy-Shop-Seiten mit Python scrapen
Das ist der Abschnitt, den die meisten Konkurrenz-Guides komplett auslassen — und er ist für Vertriebsteams und Wettbewerbsanalysten wahrscheinlich der wertvollste.
Die Shop-URL erstellen und die Seite abrufen
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Shop-Metadaten aus HTML (nicht in JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Listings aus JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataWas Sie von Shop-Seiten extrahieren können
JSON-LD auf Shop-Seiten ist @type: ItemList — es deckt die Produkt-Listings ab, aber nicht Shop-Metadaten wie Verkaufszahl, Standort oder Bewertung. Dafür brauchen Sie CSS-Selektoren:
| Datenpunkt | Selektor | Hinweise |
|---|---|---|
| Shop-Name | h1 oder Meta-Titel | Meist im Seitentitel |
| Gesamtverkäufe | div.shop-sales-reviews a | Text wie „12.345 Verkäufe“ |
| Sternebewertung | Wert von input[name="initial-rating"] | Numerisch 1–5 |
| Standort | div.shop-location | Stadt, Land |
| Mitglied seit | div.shop-info | Datumsangabe |
Shop-Daten sind besonders wertvoll, wenn Sie Lead-Listen aufbauen, Wettbewerber benchmarken oder Top-Verkäufer in einer Nische identifizieren möchten.
Schritt 4: Etsy-Bewertungen mit Python scrapen
Bewertungen gehören zu den wertvollsten — und kniffligsten — Datenpunkten auf Etsy. Der vollständige Rezensionstext, die Bewertungen und die Daten stehen nicht im anfänglichen Seiten-HTML; sie werden über einen internen API-Endpunkt geladen.
Ansatz 1: Etsy's internen Reviews-API-Endpunkt finden
Öffnen Sie eine Produktseite in Chrome, starten Sie die DevTools (F12), wechseln Sie zum Network-Tab und scrollen Sie zum Bewertungsbereich. Dort sehen Sie eine POST-Anfrage an etwas wie:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsDieser Endpunkt liefert HTML-Fragmente mit den Bewertungskarten zurück. Um ihn zu nutzen, brauchen Sie:
- listing_id — die numerische ID aus der Produkt-URL
- shop_id — aus dem Produktseiten-HTML per Regex extrahieren
- csrf_nonce — aus einem
<meta>-Tag auf der Seite extrahieren
IDs und CSRF-Token extrahieren
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfBewertungen mit Paginierung scrapen
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsAnsatz 2: Bewertungen aus HTML parsen (Fallback)
Wenn der API-Ansatz scheitert (z. B. wegen CSRF-Token-Problemen), können Sie die erste Bewertungsseite direkt aus dem HTML der Produktseite parsen. Die Einschränkung: Nur der erste Block an Bewertungen steckt im statischen HTML. Für mehr brauchen Sie die API oder ein Browser-Automatisierungstool wie Selenium.
Login-pflichtige Daten handhaben: Ihren eigenen Etsy-Shop scrapen
Das ist eine Lücke, die kein anderer Leitfaden abdeckt, aber ein echter Bedarf — besonders für Etsy-Verkäufer, die ihre eigenen Bestellungen, Umsätze und Kennzahlen extrahieren möchten.
Das Problem: Mit requests allein kommen Sie nicht an Ihr Etsy-Dashboard, weil die Login-Session-Cookies fehlen.
Option 1: Selenium mit manuellem Login und Cookie-Erfassung
Verwenden Sie Selenium, um einen Browser zu öffnen, sich manuell anzumelden (oder den Login zu automatisieren) und dann im authentifizierten Zustand weiterzuscrapen:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Im Browserfenster manuell einloggen, dann:
5input("Drücken Sie nach dem Login Enter...")
6cookies = driver.get_cookies()
7# Danach driver.get() nutzen, um zu Ihren Dashboard-Seiten zu navigieren und zu scrapenSie können Cookies aus der Selenium-Sitzung auch speichern und mit requests.Session() wiederverwenden, um nach dem ersten Login schneller und leichter zu scrapen.
Option 2: Browser-Cookies exportieren und mit Requests verwenden
Nutzen Sie eine Browser-Erweiterung (z. B. „EditThisCookie“), um Ihre aktiven Etsy-Sitzungscookies zu exportieren, und laden Sie sie dann in eine Requests-Sitzung:
1import requests
2session = requests.Session()
3# Aus dem Browser exportierte Cookies hinzufügen
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... bei Bedarf weitere Session-Cookies hinzufügen
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)Der einfache Weg: Thunderbit's Browser-Scraping-Modus
Da direkt in Ihrem Chrome-Browser läuft, übernimmt es Ihre aktive Etsy-Sitzung automatisch. Kein Authentifizierungscode, kein Cookie-Export — einfach Ihr Etsy-Dashboard öffnen und scrapen. Das ist wirklich hilfreich, um Bestellungen, Umsätze, Kennzahlen und andere Verkäuferdaten ohne Programmierung zu extrahieren.
Ihre gescrapten Etsy-Daten exportieren und nutzen
Als CSV oder JSON speichern
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Best Practices: Fügen Sie Zeitstempel in Ihre Dateinamen ein, verwenden Sie UTF-8-Kodierung und gehen Sie sorgfältig mit Sonderzeichen in Produktnamen um (Etsy-Verkäufer lieben Emojis und Akzentzeichen).
Nach Google Sheets, Airtable oder Notion exportieren
Für Python-Nutzer ermöglichen Bibliotheken wie gspread (Google Sheets) oder die Airtable-API den programmgesteuerten Export. Wenn Sie jedoch verwenden, sind alle Exporte — nach Google Sheets, Excel, Airtable und Notion — kostenlos und mit einem Klick erledigt. Keine API-Keys, kein OAuth-Setup.
Den Code überspringen: Etsy mit Thunderbit scrapen (No-Code-Alternative)
Nicht jeder möchte Python-Skripte schreiben, Proxy-Konfigurationen pflegen oder um 2 Uhr morgens CSS-Selektoren debuggen. Wenn Sie sich darin wiedererkennen, so kommen Sie mit an Etsy-Daten.
Die Thunderbit-Chrome-Erweiterung installieren
Gehen Sie zum und installieren Sie Thunderbit. Erstellen Sie ein kostenloses Konto — der Gratis-Tarif umfasst , und alle Exporte sind kostenlos.
Auf jeder Etsy-Seite „AI Suggest Fields“ verwenden
Navigieren Sie zu einer Etsy-Suche, Produkt- oder Shop-Seite. Klicken Sie in der Thunderbit-Seitenleiste auf „AI Suggest Fields“. Die KI scannt die Seite und schlägt Spalten vor — Produktname, Preis, Bewertung, Bilder, Shop-Name, Tags, Versandinfos. Passen Sie die Spalten bei Bedarf an oder fügen Sie weitere hinzu.
Auf „Scrape“ klicken und exportieren
Klicken Sie auf „Scrape“, um Daten von der aktuellen Seite zu extrahieren. Für mehrseitige Ergebnisse nutzen Sie das Pagination-Scraping von Thunderbit. Wenn Sie eine Liste von Produkt-URLs mit Details von jeder Produktseite anreichern möchten (Beschreibungen, Bewertungen, Versand), verwenden Sie Unterseiten-Scraping — Thunderbit besucht jeden Link und zieht die zusätzlichen Daten automatisch.
Exportieren Sie nach Excel, Google Sheets, Airtable oder Notion — alles kostenlos.
Wann Thunderbit für Etsy-Scraping besser ist als Python
- Kein Proxy-Setup und kein Anti-Bot-Code nötig. Thunderbit läuft in Ihrem echten Chrome-Browser, übernimmt Ihre Sitzung und wirkt für DataDome wie ein normaler Nutzer.
- Die KI passt sich Layout-Änderungen automatisch an. Keine kaputten Selektoren, die repariert werden müssen, wenn Etsy sein Frontend aktualisiert.
- Ideal für Einzelrecherchen, Wettbewerbsanalysen oder nicht-technische Teammitglieder. Wenn Sie nur schnell einen Datensatz brauchen, benötigen Sie keine Python-Umgebung.
- Unterseiten-Scraping ermöglicht es, eine Liste von Produkt-URLs mit detaillierten Daten anzureichern, ohne verschachtelte Schleifen zu schreiben.
Für eine Schritt-für-Schritt-Anleitung sehen Sie sich den an.
Python vs. Thunderbit: Kostenvergleich über 6 Monate
| Faktor | Python DIY | Thunderbit |
|---|---|---|
| Einrichtungszeit | 8–20 Stunden | Unter 5 Minuten |
| Kosten über 6 Monate (inkl. Arbeit, Proxies) | 2.720–9.450 $ | 90–228 $ |
| Monatliche Wartung | 4–10+ Stunden (Selektor-Updates = 80 %+ Overhead) | 0–1 Stunden |
| Anti-Bot-Handling | Residential Proxies zu 85-fachen Standard-Guthabenkosten | Browserbasiert, umgeht DataDome nativ |
| Datenqualität | Hoch (mit Aufwand) | Hoch (KI-gestützt) |
Ich sage nicht, dass Python die falsche Wahl ist — wenn Sie volle Kontrolle, eigene Logik oder die Einbindung in eine größere Pipeline brauchen, ist Code unschlagbar. Aber für die meisten Business-User, die einfach Etsy-Daten benötigen, spricht die ROI-Rechnung eher für ein No-Code-Tool.
Rechtliche und ethische Hinweise zum Scraping von Etsy
Zu jedem Scraping-Beitrag werde ich nach der Legalität gefragt, daher die Kurzfassung:
- Etsy's Nutzungsbedingungen verbieten automatisierten Zugriff ausdrücklich. Allerdings setzt Etsy vor allem auf technische Durchsetzung (DataDome) statt auf Klagen — bekannte Etsy-spezifische Prozesse gegen Scraper gibt es nicht.
- Scrapen Sie nur öffentlich verfügbare Daten. Umgehen Sie keine Authentifizierung und greifen Sie nicht auf private Verkäufer-Dashboards zu, die Ihnen nicht gehören.
- Verwenden Sie angemessene Request-Raten. 2–7 Sekunden Pause zwischen den Anfragen, und überlasten Sie Etsy's Server nicht.
- Beachten Sie
robots.txt. Etsy erlaubt Suchseiten, sperrt aber einige Pfade. - Gehen Sie verantwortungsvoll mit personenbezogenen Daten um im Sinne von Datenschutzgesetzen wie der DSGVO.
- Lassen Sie sich rechtlich beraten bei Scraping-Projekten im kommerziellen Maßstab.
Weitere Hintergründe finden Sie in unserem Beitrag zu den — einschließlich Meta v. Bright Data (2024), in dem öffentliches Scraping bestätigt wurde.
Fazit: Die wichtigsten Erkenntnisse
Wir haben hier viel abgedeckt. Das sollten Sie mitnehmen:
- Etsy's strukturierte JSON-LD-Daten machen das Extrahieren für die meisten Felder sauberer als das Parsen von Roh-HTML.
- DataDome ist ein echtes Hindernis — verwenden Sie bei Python-Scraping im großen Stil passende Header, Pausen, Cookie-Management und Residential Proxies.
- Die Etsy-API ist eingeschränkt. Wenn Sie Bewertungen, Konkurrenz-Shops oder Analysen über mehrere Verkäufer hinweg brauchen, ist Scraping der praktische Weg.
- Thunderbit bietet eine No-Code-Alternative, die Anti-Bot-Schutz und Authentifizierung nativ handhabt — einen Versuch wert, wenn Sie Etsy-Daten möchten, ohne Skripte zu pflegen.
- Scrapen Sie immer verantwortungsvoll und respektieren Sie Etsy's Bedingungen.
Wenn Sie loslegen möchten, ohne Code zu schreiben, . Oder nutzen Sie den Python-Code aus diesem Tutorial, um Ihren eigenen benutzerdefinierten Scraper zu bauen — und möge Ihr Selektor niemals an einem Freitagnachmittag brechen.
Weitere Scraping-Leitfäden finden Sie in unserem und im Überblick zu den .
FAQs
1. Ist es legal, Etsy mit Python zu scrapen?
Das Scrapen öffentlich verfügbarer Daten ist nach aktuellen Rechtsgrundsätzen im Allgemeinen zulässig (z. B. Meta v. Bright Data, hiQ v. LinkedIn). Etsy's Nutzungsbedingungen verbieten jedoch automatisierten Zugriff, daher sollten Sie vor dem Scraping immer die Nutzungsbedingungen und robots.txt prüfen. Für große oder kommerzielle Vorhaben sollten Sie juristischen Rat einholen.
2. Kann ich Etsy scrapen, ohne blockiert zu werden?
Etsy nutzt DataDome, eines der härtesten Anti-Bot-Systeme überhaupt. Realistische Header, Pausen zwischen Anfragen, persistente Cookies und die Rotation von Residential Proxies helfen alle dabei, Blockierungen zu reduzieren. Thunderbit's browser-nativer Ansatz vermeidet die meisten Erkennungen, da er in Ihrer echten Chrome-Sitzung arbeitet.
3. Hat Etsy eine API, die ich statt Scraping nutzen kann?
Ja — Etsy bietet eine API v3, aber sie ist größtenteils auf die Daten Ihres eigenen Shops beschränkt und bietet keinen robusten Zugriff auf Bewertungen. Für die meisten Anwendungsfälle rund um Wettbewerbsinformationen und Analysen über mehrere Shops hinweg ist Scraping erforderlich.
4. Welche Python-Bibliotheken brauche ich, um Etsy zu scrapen?
Mindestens: requests, beautifulsoup4, pandas (für den Export) und json (integriert). Für JS-lastige oder login-pflichtige Seiten fügen Sie selenium hinzu. Für schnelleres HTML-Parsen verwenden Sie lxml.
5. Wie scrape ich gezielt Etsy-Bewertungen?
Etsy-Bewertungen werden über einen internen API-Endpunkt geladen (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Sie müssen die Listing-ID, Shop-ID und das CSRF-Token von der Produktseite extrahieren und dann mit Paginierung an den Endpunkt posten. Als Fallback können Sie den ersten Bewertungsblock direkt aus dem HTML der Produktseite parsen — beide Vorgehensweisen werden in diesem Tutorial Schritt für Schritt erklärt.
Mehr erfahren