Die meisten eBay-Scraping-Tutorials haben eine Halbwertszeit von ungefähr drei Monaten. Das weiß ich, weil unser Team bei Thunderbit immer wieder beobachtet hat, wie Entwickler über kaputte Code-Snippets, veraltete CSS-Selektoren und „funktionierende“ GitHub-Repos stolpern, die seit zwei eBay-Redesigns längst still und leise den Dienst eingestellt haben.
eBay verfügt über – nach Amazon der größte Long-Tail-Preisdatenbestand im offenen Web. Diese Daten treiben alles an, von Preisstrategien für Reseller bis hin zu Wettbewerbsanalysen. Doch der programmatische Zugriff ist ein bewegliches Ziel: eBays React-basierte Oberfläche ändert CSS-Klassennamen ständig, A/B-Tests liefern je nach Nutzer unterschiedliche DOM-Strukturen, und Akamai Bot Manager steht zwischen dir und dem HTML. Dieser Leitfaden zeigt dir Python-Code, der heute funktioniert, erklärt, warum Scraper kaputtgehen, damit du robuste Lösungen baust, beleuchtet die Entscheidung zwischen eBay API und Scraping ehrlich und zeigt eine No-Code-Alternative für Fälle, in denen Python den Aufwand nicht wert ist.
Was bedeutet es, eBay mit Python zu scrapen?
eBay mit Python zu scrapen bedeutet, Skripte zu schreiben, die eBay-Webseiten programmgesteuert abrufen, das HTML (oder verstecktes JSON) analysieren und strukturierte Daten extrahieren – etwa Titel, Preise, Verkäuferinfos, Verkaufsdaten oder Varianten – in ein Format, das du direkt weiterverwenden kannst, zum Beispiel CSV, Tabellenkalkulation oder Datenbank.
Du kannst verschiedene eBay-Seitentypen scrapen:
- Suchergebnisse (z. B. alle „AirPods Pro“-Angebote)
- Einzelne Produktdetailseiten (vollständige Spezifikationen, Bilder, Verkäuferinfos)
- Verkaufte/abgeschlossene Angebote (tatsächliche Transaktionspreise und Daten)
- Verkäuferprofile und Bewertungen
Python ist dafür die Standardwahl. Das Ökosystem – Requests, BeautifulSoup, lxml, pandas – macht es einfach, Seiten abzurufen, HTML zu parsen und Daten zu verarbeiten. Es gibt allerdings einen wichtigen Unterschied zwischen dem Scrapen des Website-HTML und der Nutzung der offiziellen eBay-API – darauf gehe ich gleich ein.
Warum eBay scrapen? Praxisnahe Anwendungsfälle für Business-Teams
Wenn du das hier liest, hast du wahrscheinlich schon einen konkreten Anlass. Trotzdem lohnt sich ein Blick auf den geschäftlichen Nutzen, denn der ROI von eBay-Daten ist wirklich beeindruckend. Bain stellte fest, dass eine – über tausende Unternehmen hinweg. McKinsey schreibt dynamischer Preisgestaltung im Handel zu.
Die Anwendungsfälle, die ich am häufigsten sehe:
| Anwendungsfall | Benötigte Daten | Geschäftlicher Nutzen |
|---|---|---|
| Preisbeobachtung & Repricing | Aktive Angebotspreise, Versand, Zustand | Wettbewerbsfähige Preisgestaltung, Marge schützen |
| Wettbewerbsanalyse | Produktsortimente, Aktionen, Versandkonditionen | Strategische Positionierung, Sortimentslücken erkennen |
| Marktforschung & Trendanalyse | Angebotsdynamik, Kategorietrends, Nachfrage-Muster | Neue Produkte identifizieren, Nachfrage prognostizieren |
| Reseller-Preisbewertung / Appraisals | Verkaufspreise, Verkaufsdaten, Zustand | Fairen Marktwert bestimmen, Buy-Box-Entscheidungen treffen |
| Sentiment-Analyse | Bewertungen, Sterne, Rückgaberichtlinien | Produktqualität und Kundenzufriedenheit besser verstehen |
| Lead-Generierung | Verkäuferprofile, Shop-Infos, Kontaktdaten | B2B-Outreach an Verkäufer mit hohem GMV |
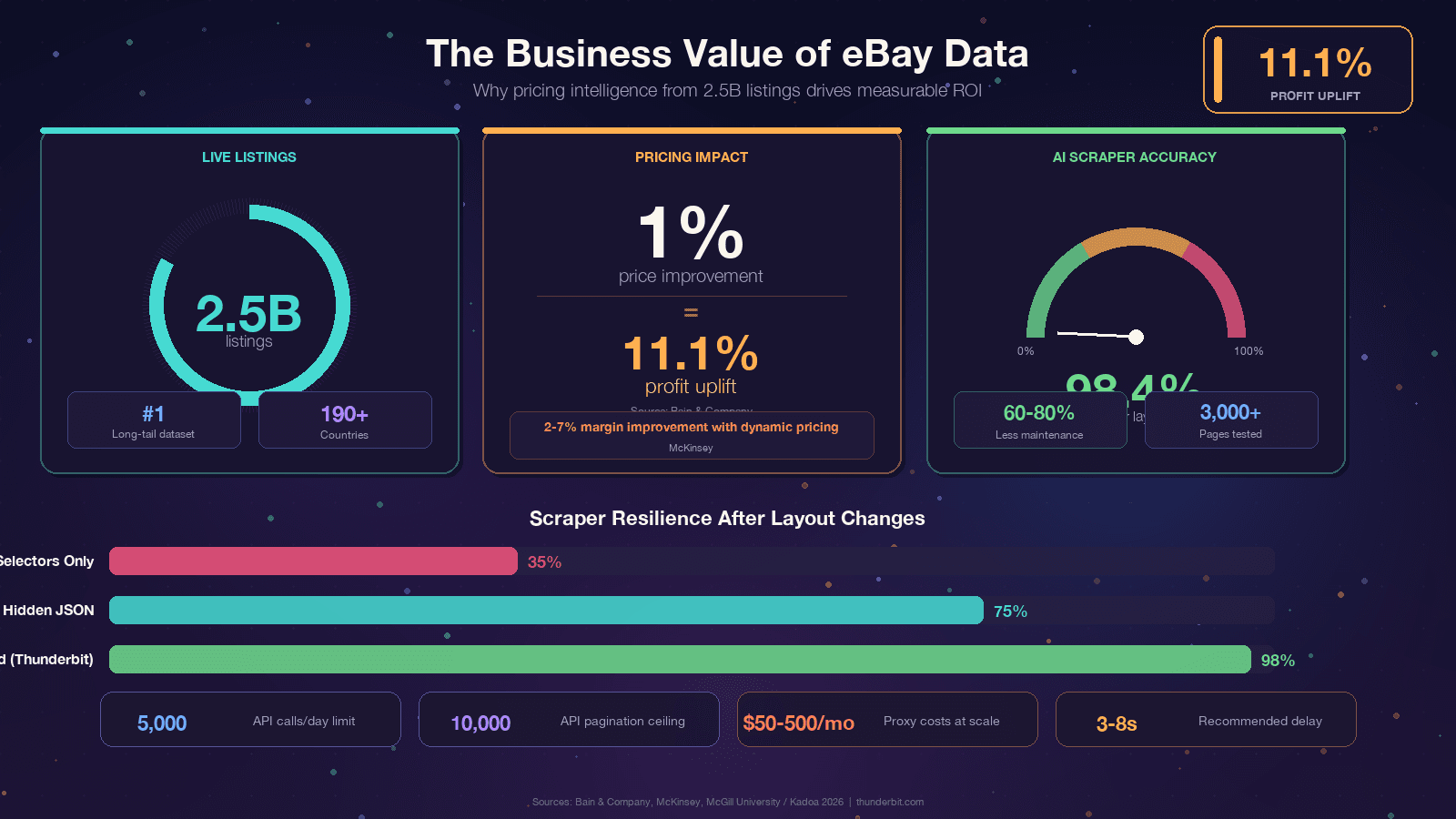
Der gemeinsame Nenner: eBay hat die Daten, aber sie stecken in Webseiten.
Scraping ist der Weg, sie in einen Wettbewerbsvorteil zu verwandeln.
Offizielle eBay-API vs. Python-Webscraping: Was solltest du wählen?
Das ist die Frage, die sich viele Tutorials zu selten ehrlich stellen. eBay bietet offizielle APIs – vor allem die – und viele fragen sich, ob sie diese nutzen oder direkt scrapen sollen. Die Antwort hängt vollständig davon ab, welche Daten du brauchst.
| Kriterium | eBay Browse/Finding API | Python-Webscraping |
|---|---|---|
| Verkaufte/abgeschlossene Angebote | Eingeschränkt – Marketplace Insights API existiert, aber Zugriff wird oft abgelehnt | Vollzugriff über LH_Sold=1&LH_Complete=1 in der URL |
| Rate Limits | 5.000 Aufrufe/Tag im Basistarif | Selbst verwaltet (abhängig von Proxys) |
| Datenfelder | Vordefiniert (Titel, Preis, Kategorie, grundlegende Verkäuferdaten) | Alles, was auf der Seite sichtbar ist (Bewertungen, vollständige Spezifikationen, Variantenmatrix) |
| Einrichtungsaufwand | OAuth 2.0, App-Registrierung, API-Keys | pip install + Code |
| Stabilität | Stabile Endpunkte | Bricht, wenn sich das HTML ändert |
| Kosten | Freier Tarif verfügbar, bei höherem Volumen kostenpflichtig | Code kostenlos, Proxy-Kosten bei großem Umfang |
| Varianten-/MSKU-Daten | Teilweise – oft nur Parent-SKU | Vollständig (über verstecktes JSON) |
| Pagination-Tiefe | hartes Limit von 10.000 Einträgen | Theoretisch unbegrenzt |
Kurzer Hinweis: Die alte Finding API (mit findCompletedItems) wurde . Wenn du ebaysdk-python oder eine andere Bibliothek verwendest, die das Finding-Modul anspricht, funktioniert sie in der Produktion derzeit nicht mehr.
Meine Empfehlung: Nutze die Browse API für stabile, strukturierte Katalogabfragen mit moderatem Volumen bei aktiven Angeboten. Verwende Python-Scraping, wenn du Verkaufspreise, Bewertungen, Variantendaten oder andere Felder brauchst, die die API nicht liefert. Viele Teams nutzen beides.
Welche Tools und Bibliotheken du brauchst, um eBay mit Python zu scrapen
Bevor wir Code schreiben, hier das Werkzeug-Set. Für die meisten eBay-Seiten brauchst du keinen Headless Browser – die Daten sind im serverseitig gerenderten HTML eingebettet.
| Bibliothek | Zweck |
|---|---|
requests oder httpx | HTTP-Client zum Herunterladen von eBay-Seiten |
curl_cffi | HTTP-Client mit echtem Browser-TLS-Fingerprint (entscheidend gegen Akamai) |
beautifulsoup4 | HTML-Parser für das Extrahieren per CSS-Selektor |
lxml | Schnelles Parser-Backend für BeautifulSoup |
jmespath | Abfragesprache für verschachtelte JSON-Blöcke |
pandas | Datenbearbeitung sowie CSV-/Excel-Export |
gspread | Integration mit Google Sheets |
Installation in einem Schritt:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadNutze Python 3.11+ – pandas 3.0 benötigt 3.10+, und 3.11 bringt bei I/O-lastigen Aufgaben 10–60 % mehr Geschwindigkeit.
Eine Bibliothek verdient besondere Erwähnung: curl_cffi ist das wichtigste Upgrade, das ein eBay-Scraper im Jahr 2026 machen kann. eBay nutzt den , und Akamais wichtigste Erkennungsmethode ist das TLS-Fingerprinting. Normales requests erzeugt einen Python-typischen JA3-Fingerprint und wird sofort markiert. curl_cffi imitiert den TLS-Handshake eines echten Chrome-Browsers und kommt damit bei rund 90 % der Akamai-geschützten Ziele ohne Headless Browser aus.
Schritt für Schritt: eBay-Suchergebnisse mit Python scrapen
Das ist das Kern-Tutorial. Wir scrapen eBay-Suchergebnisseiten für Produktangebote.
- Schwierigkeitsgrad: Anfänger bis Mittelstufe
- Benötigte Zeit: ca. 30 Minuten bis zum ersten funktionierenden Scrape
- Was du brauchst: Python 3.11+, die oben genannten Bibliotheken, ein Terminal und eine Ziel-URL für die eBay-Suche
Schritt 1: Python-Projekt einrichten
Lege ein Projektverzeichnis an und installiere die Abhängigkeiten:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasErstelle eine Datei namens scrape_ebay.py. Das ist dein Arbeitsbereich.
Schritt 2: Die eBay-Such-URL bauen
eBays Such-URL-Struktur ist recht einfach. Der wichtigste Parameter ist _nkw (Keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # Einträge pro Seite: 60, 120 oder 240 (240 kann Bot-Flags auslösen)
7 "_pgn": "1", # Seitenzahl
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Weitere nützliche Parameter:
LH_BIN=1— nur „Sofort-Kaufen“_sacat=175673— bestimmte Kategorie_sop=12— Sortierung nach bester Übereinstimmung (10 = niedrigster Preis inkl. Versand, 13 = neu eingestellt)LH_Complete=1&LH_Sold=1— verkaufte/abgeschlossene Angebote (weiter unten in einem eigenen Abschnitt erklärt)
Schritt 3: Anfrage senden und Antwort verarbeiten
Hier zeigt curl_cffi, was es kann. Ein einfaches requests.get() liefert oft einen 403 von Akamai. Mit curl_cffi imitieren wir einen echten Chrome-Browser:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, erneuter Versuch in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request-Fehler: {e}, erneuter Versuch...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Nach {max_retries} Versuchen fehlgeschlagen: {url}")Exponentielles Backoff mit Jitter ist wichtig – feste Warteintervalle sind selbst wieder ein Bot-Fingerabdruck.
Schritt 4: Produktangebote aus der Suchseite parsen
eBay befindet sich aktuell mitten in der Migration zwischen zwei Suchergebnis-Layouts. Ein robuster Scraper muss beide beherrschen:
| Feld | Altes Layout | Neues Layout |
|---|---|---|
| Karten-Container | li.s-item | li.s-card oder div.su-card-container |
| Titel | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Preis | span.s-item__price | .s-card__price |
Der Parsing-Code, der beide Layouts verarbeitet:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Titel — beide Layouts prüfen
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Phantom-Karte „Shop on eBay“ überspringen
11 if not title or "Shop on eBay" in title:
12 continue
13 # Preis
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Bild
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Versand
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsDie erste Phantom-Karte ist ein klassischer Stolperstein. Das erste li.s-item auf vielen eBay-Suchergebnisseiten ist ein versteckter Platzhalter mit dem Titel „Shop on eBay“ und ohne echten Preis. Immer herausfiltern.
Schritt 5: Pagination für mehrere Seiten behandeln
eBay paginiert über den _pgn-Parameter. Der Link zur nächsten Seite verwendet a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scrape Seite {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" Keine Ergebnisse auf Seite {page_num}, Abbruch.")
12 break
13 all_results.extend(results)
14 print(f" {len(results)} Angebote gefunden (insgesamt: {len(all_results)})")
15 # Höfliche Pause — 3 bis 8 Sekunden mit Jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsDer zufällige Jitter von 3–8 Sekunden ist nicht optional.
eBays Akamai-Schicht markiert anhaltend mehr als 1 Anfrage/Sekunde von einer einzelnen IP.
Schritt 6: Scraped Daten als CSV oder JSON exportieren
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"{len(df)} Angebote als CSV und JSON exportiert.")Jetzt solltest du eine saubere Tabelle mit eBay-Angeboten haben. Auf meinem Rechner dauerte das Scrapen von 3 Seiten (360 Angebote) inklusive Pausen etwa 45 Sekunden.
Wie man eBay-Produktdetailseiten mit Python scrapt
Suchergebnisse liefern nur eine Zusammenfassung. Produktdetailseiten enthalten die spannenden Daten: vollständige Beschreibungen, Verkäufer-Bewertungen, Artikelspezifikationen, Bildergalerien und Varianten.
Eine einzelne Produktseite parsen
eBay-Artikelseiten liegen unter /itm/<ITEM_ID>. Der stabilste Extraktionsweg ist JSON-LD – eBay bettet einen Product-Schema-Block ein, der fast alle CSS-Änderungen übersteht:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — stabilster Extraktionsweg
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. CSS-Fallbacks für Felder, die nicht in JSON-LD stehen
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Artikelspezifikationen
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemDas Muster hier – erst JSON-LD, dann CSS-Fallbacks – ist der Schlüssel zu Scrapern, die nicht jedes Quartal zerbrechen. Dazu gleich mehr.
eBay-Produktvarianten scrapen (MSKU-Daten)
Einige eBay-Angebote haben mehrere Varianten – verschiedene Farben, Größen oder Speicherkapazitäten. Das sichtbare DOM zeigt zunächst nur eine Preisspanne wie „899 bis 1.099 €“, bis der Nutzer eine Option anklickt. Die tatsächlichen Preise pro Variante liegen in einem versteckten JavaScript-Objekt namens MSKU.
Das ist ein Bereich, in dem die eBay-API nur teilweise Daten liefert (Parent-SKU), weshalb Scraping hier die bessere Wahl ist.
1import re, json
2def extract_variants(html):
3 # Non-greedy ist entscheidend — ein gieriges .+ verschluckt die gesamte Seite
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusGenau dieses nicht-gierige (.+?) bringt fast jeden eBay-Scraper zu Fall. Ein gieriges .+ frisst alles bis zum letzten "QUANTITY" auf der Seite und erzeugt dadurch fehlerhaftes JSON. Diesen Bug habe ich in mindestens drei „funktionierenden“ Tutorials gesehen.
Wie man verkaufte und abgeschlossene eBay-Angebote mit Python scrapt
Das ist der Anwendungsfall, der Scraping gegenüber der API rechtfertigt. Verkaufsdaten – was tatsächlich verkauft wurde, zu welchem Preis und an welchem Datum – sind der Goldstandard für Marktforschung, Reseller-Preise und Bewertungen. Die eBay Browse API liefert das ausdrücklich nicht. Die tut das technisch zwar, aber der Zugriff ist ein „Limited Release“ und wird .
Die URL-Parameter, die du brauchst, sind LH_Complete=1 (abgeschlossene Angebote) und LH_Sold=1 (nur tatsächlich verkaufte). Du musst beide setzen. LH_Sold=1 allein fällt in manchen Kategorien stillschweigend auf aktive Angebote zurück – das ist die häufigste Falle in der Community.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Verkaufte Seite {page_num scrapen...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Nur tatsächlich verkaufte Artikel einbeziehen (grünes POSITIVE-Preislabel)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Nicht verkauftes, aber abgeschlossenes Angebot — überspringen
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Verkaufsdatum parsen
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldDer entscheidende HTML-Unterschied: Verkaufte Artikel zeigen den Preis grün (innerhalb eines .POSITIVE-Wrappers), während nicht verkaufte, aber abgelaufene Angebote den Preis rot und durchgestrichen anzeigen. Deshalb immer auf die .POSITIVE-Klasse filtern.
Warum eBay-Scraper kaputtgehen – und wie du robuste baust
Wenn dein eBay-Scraper nicht mehr funktioniert, bist du in guter Gesellschaft. Das ist das Problem Nr. 1 in jedem eBay-Scraping-Forum, das ich gelesen habe. Die Frage ist nicht ob dein Scraper kaputtgeht, sondern wann.
Warum das passiert:
- eBay nutzt React-basiertes Rendering mit dynamisch erzeugten Klassennamen, die sich bei Deployments ändern
- A/B-Tests liefern je nach Nutzer unterschiedliche DOM-Strukturen (die dualen
s-item/s-card-Layouts sind gerade ein lebendes Beispiel) - Regelmäßige Redesigns ändern die HTML-Verschachtelung, selbst wenn die Daten gleich bleiben
- Alte Selektoren wie
#itemTitleund#prcIsumwurden vor Jahren entfernt, tauchen aber in Tutorials immer noch auf
Wie sagt: „Die eigentliche Herausforderung beim eBay-Webscraping besteht darin, mit den CSS-Selektor-Änderungen von eBay umzugehen. eBay aktualisiert das Frontend regelmäßig und bricht damit Scraper, die auf bestimmten Klassennamen beruhen.“
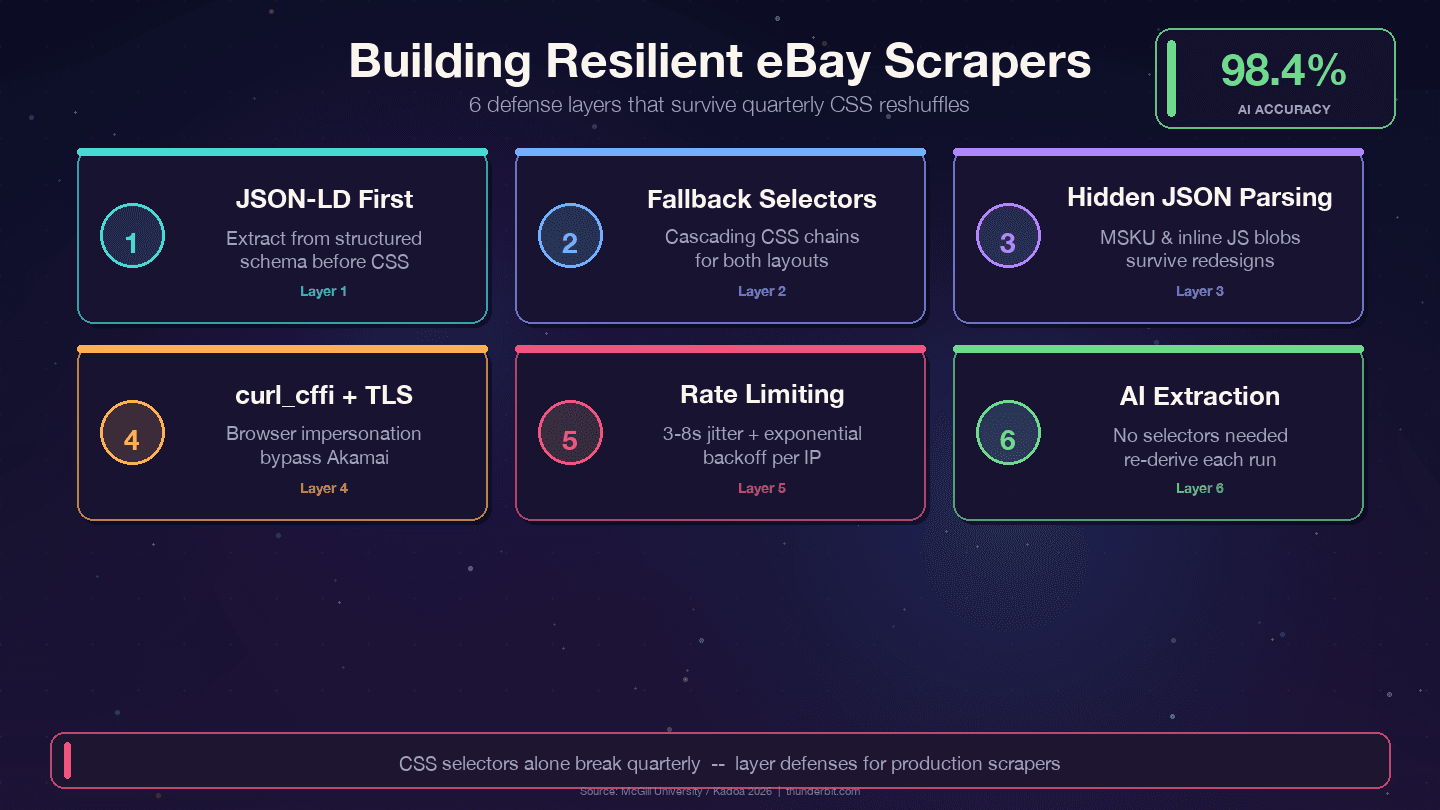
Strategien für langlebige eBay-Scraper
Vier Strategien, die eBays vierteljährliche Umbauten überstehen:
1. JSON-LD vor CSS-Selektoren priorisieren. eBay bettet auf jeder Artikelseite strukturierte Product-Schema-Daten ein. Die Datenebene ändert sich viel seltener als die Darstellungsebene – Designer überarbeiten CSS-Klassen jedes Quartal, aber Backend-Feldnamen wie price, name und seller hängen an internen APIs und werden selten umbenannt.
2. Kaskadierende Fallback-Selektoren nutzen. Verlass dich nie auf einen einzigen CSS-Selektor. Immer Alternativen angeben:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Versteckte JSON-Blöcke parsen. Das MSKU-Variantenobjekt und Inline-JavaScript-Daten überstehen CSS-Änderungen, weil sie serverseitig erzeugt werden. Regex-Extraktion aus <script>-Tags ist anfangs mehr Arbeit, reduziert aber den Wartungsaufwand deutlich.
4. Fehler bei Selektoren protokollieren. Baue Monitoring ein, damit du weißt, wann ein Selektor nicht mehr greift – nicht erst, dass deine Daten leer sind:
1if title is None:
2 print(f"WARNUNG: Titel-Selektor fehlgeschlagen für {url}")5. curl_cffi mit Browser-Impersonation verwenden. Damit umgehst du Akamais TLS-Fingerprinting ohne Headless Browser.
Die KI-Alternative: Kein Selektor-Pflegeaufwand
Wenn du es leid bist, alle paar Monate Selektoren nachzubessern, gibt es einen grundlegend anderen Ansatz. Tools wie nutzen KI, um die Seite bei jedem Lauf neu zu lesen und die Extraktionslogik dynamisch abzuleiten. Eine Studie der McGill University verglich KI- und Selektor-basierte Scraper auf 3.000 Seiten und stellte fest, dass , während Branchen-Benchmarks angeben.
| Ansatz | Bricht bei HTML-Änderungen von eBay? | Wartungsaufwand |
|---|---|---|
| Fest codierte CSS-Selektoren | Ja, vierteljährlich | Hoch — laufende Anpassungen |
| Extraktion aus verstecktem JSON / JSON-LD | Selten | Niedrig |
| KI-basiertes Scraping (Thunderbit) | Nein — KI leitet Selektoren bei jedem Lauf neu ab | Keiner |
Den Thunderbit-Workflow zeige ich später im Detail. Wichtig ist vorerst: Wenn du einen Scraper bauen willst, der über Monate laufen soll, setze auf JSON-first-Extraktion und Fallback-Selektoren. Wenn du Selektoren gar nicht pflegen möchtest, lohnt sich ein Blick auf den KI-Ansatz.
Wiederkehrende eBay-Scrapes für Preisbeobachtung automatisieren
Ein einmaliges Scraping ist nützlich. Preisbeobachtung, Lagerbestandstracking und Wettbewerbsanalyse brauchen jedoch regelmäßige Datenerfassung. Jeder Konkurrenzartikel, den ich gelesen habe, nennt Preismonitoring als Anwendungsfall – aber fast keiner zeigt, wie man es tatsächlich automatisiert.
Option 1: Cron-Jobs (Linux/macOS) oder Task Scheduler (Windows)
Der einfachste Weg. Verpacke dein Python-Skript in einen Cron-Job. Verwende immer den absoluten Pfad zu Python in deiner venv – Cron startet mit einer minimalen Umgebung:
1crontab -e
2# Täglich um 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1Unter Windows kannst du PowerShell nutzen:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TDas erfordert einen dauerhaft laufenden Rechner, und Proxys sowie Anti-Bot-Maßnahmen verwaltest du selbst.
Option 2: Cloud Functions (Serverless)
Mit AWS Lambda oder Google Cloud Functions kannst du Scraper ohne eigenen Server betreiben. Der Einrichtungsaufwand ist höher – du musst Abhängigkeiten paketieren, Timeouts berücksichtigen (Lambda ist auf 15 Minuten begrenzt) und trotzdem Proxys managen. Dafür entfällt die Serverwartung.
Option 3: No-Code-Zeitplanung mit Thunderbit
Die lässt dich das Intervall in Klartext beschreiben (z. B. „jeden Tag um 8 Uhr“), eBay-URLs einfügen und auf Planen klicken. Der Lauf erfolgt in der Cloud mit integriertem Anti-Bot-Schutz.
| Ansatz | Einrichtungsaufwand | Eigener Server nötig? | Anti-Bot-Schutz enthalten? |
|---|---|---|---|
| Cron + Python-Skript | Mittel | Ja (immer laufender Rechner) | Proxys musst du selbst managen |
| Cloud Function (Lambda) | Hoch | Nein (serverless) | Proxys musst du selbst managen |
| Thunderbit Scheduled Scraper | Niedrig (per Beschreibung) | Nein (cloudbasiert) | Integriert |
Für das Speichern regelmäßiger Scrape-Daten ist eine lokale SQLite-Datenbank die richtige Wahl für Preisverläufe. Verwende ON CONFLICT ... DO UPDATE (nicht INSERT OR REPLACE, das ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Keine Lust auf Code? So scrapst du eBay in 2 Minuten mit Thunderbit
Ich habe jetzt 2.000 Wörter über Python-Code geschrieben. Jetzt möchte ich ehrlich sein, wann du das gar nicht brauchst.
Wenn du als Business-Nutzer einmalig Marktforschung machst, als Reseller Vergleichsdaten prüfst oder als E-Commerce-Team Daten heute brauchst, ohne einen Dev-Sprint zu starten, ist Python oft überdimensioniert. Die Einrichtung, die Pflege der Selektoren, das Proxy-Management – das ist viel Aufwand für „Ich brauche nur diese 200 Angebote in einer Tabelle“.
So scrapt Thunderbit eBay (Schritt für Schritt)
- Installiere die – keine Kreditkarte erforderlich.
- Öffne in Chrome eine beliebige eBay-Suchergebnisseite oder Produktseite.
- Klicke in der Thunderbit-Seitenleiste auf „AI Suggest Fields“. Die KI liest die Seite und schlägt Spalten vor: Titel, Preis, Zustand, Versand, Verkäufer, Bewertung.
- Klicke auf „Scrape“. Die Erweiterung folgt der Pagination und füllt die Datentabelle. Für eBay gibt es bei Thunderbit , die per Klick funktionieren.
- Exportiere kostenlos nach Google Sheets, Airtable, Notion, CSV, JSON oder Excel.
Der gesamte Ablauf dauert unter 2 Minuten.
Ich habe es gestoppt.
Unterseiten-Anreicherung: Detailseiten-Daten ohne zusätzlichen Code
Nach dem Scrapen einer Suchergebnisseite kann Thunderbit jede einzelne Angebots-Detailseite besuchen und zusätzliche Felder anhängen – vollständige Spezifikationen, Verkäuferinfos, Beschreibung, alle Bilder. Damit ersetzt du die 20+ Zeilen Python-Code für das Scrapen von Unterseiten, die wir oben geschrieben haben, durch einen einzigen Klick.
Wann Python trotzdem die bessere Wahl ist
Python gewinnt, wenn du Folgendes brauchst:
- Scraping in großem Umfang (Zehntausende Seiten pro Lauf)
- Tief angepasste Parsing-Logik oder Datenumwandlung
- Einbindung in bestehende Datenpipelines (Airflow, dbt, Kafka)
- Feingranulare TLS-/Session-Steuerung für fortgeschrittene Anti-Bot-Arbeit
- Unit Economics – bei Millionen von Zeilen ist ein gepflegter Stack günstiger als ein kreditbasiertes SaaS-Modell
Für die meisten einmaligen oder mittelgroßen Projekte ist Thunderbit schneller und einfacher. Für Produktionspipelines im großen Maßstab gibt dir Python maximale Kontrolle.
Tipps, um beim Scrapen von eBay mit Python nicht blockiert zu werden
eBays Akamai-Schicht ist real. Was in der Praxis wirklich funktioniert:
- Nutze
curl_cffimitimpersonate="chrome124"— das ist die mit Abstand größte Verbesserung gegenüber einfachemrequests - Wechsle User-Agent-Strings aus einer Liste aktueller Browser-Versionen (Chrome 143, Firefox 124, Safari 26)
- Baue zufällige Pausen von ein — feste Intervalle sind ein Fingerabdruck
- Verwende Residential- oder rotierende Proxys für alles über ein paar Dutzend Seiten. Rechenzentrums-IP-Adressen (AWS, GCP, DigitalOcean) werden von Akamai schnell erkannt.
- Beachte die
robots.txt— viele gefilterte Browse-URLs sind ausdrücklich verboten; Artikeldetailseiten (/itm/<id>) dagegen nicht - Behandle CAPTCHAs sauber — erkenne sie und versuche es mit einer anderen IP erneut oder nutze einen CAPTCHA-Lösungsdienst
- Belaste den Server nicht unnötig. Der Präzedenzfall zeigt, dass „trespass to chattels“ relevant wird, wenn Scraping Server tatsächlich beeinträchtigt. Mit 1 Anfrage/Sekunde pro IP bleibst du weit darunter.
Für kommerzielle Nutzung mit hohem Volumen ist es oft am saubersten, die Browse API für aktive Angebote zu verwenden und gezielt nur für Verkaufspreise und Felder zu scrapen, die die API nicht liefert. Dieser Hybridansatz ist technisch und rechtlich meist die bessere Lösung.
Ist es legal, eBay mit Python zu scrapen?
Ich bin kein Anwalt, und dieser Beitrag ist keine Rechtsberatung. Deshalb halte ich mich kurz.
Die Rechtslage hat sich zugunsten des Scraping öffentlich zugänglicher Daten verschoben. Wichtige Präzedenzfälle:
- (9. Cir., 2022): Scraping öffentlich zugänglicher Daten verstößt nicht gegen den CFAA
- Van Buren v. United States (US Supreme Court, 2021): schränkte die CFAA-Klausel „exceeds authorized access“ ein
- (N.D. Cal., 2024): Scraping im ausgeloggten Zustand verletzt nicht die Plattform-AGB, weil der Scraper kein „Nutzer“ ist
Allerdings verbietet eBays ausdrücklich „Buy-for-me-Agenten, LLM-gesteuerte Bots oder End-to-End-Abläufe, die versuchen, Bestellungen ohne menschliche Prüfung aufzugeben“. Die Grenze ist klar: schreibgeschütztes Scraping öffentlicher Seiten ist rechtlich deutlich solider; Checkout-Automatisierung ist es nicht.
Best Practices: Scrape nur öffentlich sichtbare Daten. Erstelle keine Fake-Accounts und umgehe keine Login-Schranken. Verbreite keine urheberrechtlich geschützten Angebotsbilder in großem Stil weiter. Und ziehe bei kommerziellen Großprojekten Rechtsberatung hinzu.
Fazit und wichtigste Erkenntnisse
Python ist der flexibelste Weg, eBay zu scrapen – verlangt aber laufende Pflege, wenn sich das HTML der Website ändert. Der Entscheidungsrahmen:
- Nutze die eBay Browse API für stabile, strukturierte Abfragen mit moderatem Volumen bei aktiven Angeboten
- Nutze Python-Scraping für verkaufte Angebote, Bewertungen, Variantendaten und alles, was die API nicht preisgibt
- Nutze , wenn du eBay-Daten ohne Code oder Wartungsaufwand möchtest
Der Code in diesem Leitfaden setzt auf Robustheit: erst JSON-LD-Extraktion, dann kaskadierende CSS-Fallbacks, bei Varianten zusätzlich verstecktes JSON. Dieser mehrschichtige Ansatz sorgt dafür, dass dein Scraper nicht beim nächsten Frontend-Redesign von eBay ausfällt.
Wenn du den No-Code-Weg testen willst, kannst du mit dem sofort auf eBay-Seiten loslegen. Und wenn du sehen willst, wie die funktioniert, ist sie nur einen Klick entfernt.
Mehr zu Web-Scraping-Tools findest du in unseren Leitfäden zu den , und . Außerdem kannst du Tutorials auf dem ansehen.
FAQs
1. Kann ich eBay mit Python kostenlos scrapen?
Ja. Alle Bibliotheken (Requests, BeautifulSoup, curl_cffi, pandas) sind kostenlos und Open Source. Kosten entstehen im größeren Maßstab – Residential Proxys für hohes Volumen liegen je nach Bandbreite meist bei 50–500 $ pro Monat. Für kleine Projekte (ein paar hundert Seiten) kannst du mit sauberem Rate Limiting auch von deiner Heim-IP scrapen.
2. Wie scrape ich verkaufte eBay-Artikel und abgeschlossene Angebote mit Python?
Füge LH_Complete=1&LH_Sold=1 zu deinen Such-URL-Parametern hinzu. Du musst beide setzen – LH_Sold=1 allein fällt in manchen Kategorien stillschweigend auf aktive Angebote zurück. Filtere die Ergebnisse, indem du beim Preiselement auf die CSS-Klasse .POSITIVE prüfst; sie zeigt einen tatsächlichen Verkauf an und nicht ein nicht verkauftes, abgelaufenes Angebot.
3. Blockiert eBay Webscraping?
eBay nutzt den Akamai Bot Manager, der Scraper vor allem über TLS-Fingerprinting und Verhaltensanalyse erkennt. Einfache requests-Aufrufe liefern oft 403-Antworten. Mit curl_cffi, Browser-Imitation, rotierenden User-Agents und zufälligen Pausen von 3–8 Sekunden zwischen den Anfragen lassen sich die meisten Blockaden umgehen. Residential Proxys helfen im größeren Maßstab.
4. Sollte ich die eBay-API oder Webscraping nutzen?
Nutze die Browse API für stabile Abfragen mit moderatem Volumen bei aktiven Angeboten (bis zu 5.000 Aufrufe/Tag). Scraping ist sinnvoll, wenn du Preisverläufe verkaufter Artikel, vollständige Varianten-/MSKU-Daten, Bewertungen oder andere Felder brauchst, die die API nicht anbietet. Die Marketplace Insights API liefert technisch verkaufte Daten, der Zugriff ist jedoch eingeschränkt und wird .
5. Was ist der einfachste Weg, eBay ohne Programmierung zu scrapen?
Die nutzt KI, um eBay-Seiten zu lesen, passende Datenfelder vorzuschlagen und Angebote mit einem Klick zu extrahieren. Sie übernimmt Pagination, Unterseiten-Anreicherung und Export nach Google Sheets, Excel, Airtable oder Notion. Vorgefertigte machen häufige Anwendungsfälle noch schneller.
Mehr erfahren