Craigslist zieht immer noch rund über etwa 700 lokale Seiten an — und eine öffentliche API gibt es bis heute nicht. Wenn du strukturierte Daten aus Wohnungsanzeigen, Gebrauchtwagen, Jobangeboten oder Gig-Listings brauchst, kommst du am Scraping praktisch nicht vorbei.
Craigslists eigenes Anti-Bot-System ist allerdings gnadenlos. Es nutzt weder Cloudflare noch DataDome — stattdessen läuft ein selbst entwickelter nginx-basierter Rate Limiter, der seit über zehn Jahren immer weiter verfeinert wurde. Wer ihn falsch anspricht, bekommt oft schon vor dem zweiten Kaffee einen knappen 403. Ich habe lange verschiedene Ansätze gegen Craigslists Schutzmechanismen getestet, und genau daraus ist dieser Leitfaden entstanden: ein aktuelles Python-Tutorial für 2025, das für alle Kategorien funktioniert, JSON-LD-Extraktion erklärt (der größte Fortschritt gegenüber veralteten Guides), ehrliche Anti-Ban-Strategien, die rechtliche Lage und eine No-Code-Alternative für alle, die die Daten wollen, aber keinen Code schreiben möchten.
Was bedeutet es, Craigslist mit Python zu scrapen?
Beim Web Scraping von Craigslist nutzt du Python-Skripte, um Craigslist-Seiten programmgesteuert aufzurufen, die relevanten strukturierten Daten zu extrahieren — etwa Titel, Preise, Beschreibungen, Bilder, Standorte und Veröffentlichungsdaten — und sie in einer Tabelle, Datenbank oder JSON-Datei zu speichern.
Python ist dafür die naheliegende Wahl, weil das Ökosystem an Bibliotheken so stark ist. Mit requests, BeautifulSoup, lxml und curl_cffi lässt sich ein funktionierender Craigslist-Scraper in weniger als 100 Zeilen bauen. Dazu kommt eine riesige Community — wenn Craigslist etwas ändert (und das passiert), hat meist schon jemand die Lösung gefunden.
Wichtig ist: Craigslist an. Die einzige offizielle Programmschnittstelle ist die Bulk Posting Interface (BAPI) — aber die ist nur zum Schreiben da. Zugelassene, kostenpflichtige Anbieter können darüber Inserate einstellen, aber keine Daten abrufen. Jedes Produkt mit dem Label „Craigslist API“, das du auf Drittplattformen siehst, ist in Wirklichkeit ein inoffizieller Scraper und kein offiziell unterstützter Endpunkt. Wenn du Massendaten willst, scrapest du.
Warum Craigslist scrapen? Praxisbeispiele aus der echten Welt
Craigslist ist nicht nur ein Ort für gebrauchte Sofas. Es ist ein riesiger, ständig aktualisierter Datensatz über dutzende Kategorien hinweg. Davon profitieren unter anderem:
| Anwendungsfall | Wer davon profitiert | Welche Daten extrahiert werden |
|---|---|---|
| Beobachtung von Miet- und Apartmentpreisen | Makler, Mieter, PropTech-Unternehmen | Preis, Quadratmeter, Schlafzimmer, Stadtteil, Breitengrad/Längengrad |
| Analyse des Gebrauchtwagenmarkts | Autohäuser, Consumer-Apps, Forschende | Preis, Marke, Modell, Baujahr, Kilometerstand, Zustand |
| Forschung zum Arbeitsmarkt | Recruiter, Arbeitsökonom:innen, Workforce-Analyst:innen | Titel, Vergütung, Beschäftigungsart, Veröffentlichungsdatum |
| Lead-Generierung | Vertriebsteams, Dienstleister | Kontaktdaten, Firmennamen, Servicegebiet |
| Wettbewerbsfähige Preisbeobachtung | Lokale Dienstleister, E-Commerce-Teams | Servicepreise, Beschreibungen, Einsatzgebiete |
Das am häufigsten zitierte akademische Beispiel ist das — rund 500.000 US-Gebrauchtwagenanzeigen mit 26 Merkmalen. Es diente als Grundlage für Dutzende Arbeiten, darunter eine ResearchGate-Studie aus 2024 zu Dynamiken des US-Gebrauchtwagenmarkts. Hedgefonds haben aggregierte Craigslist-Mietdaten für Analysen von Miettrends gekauft. Und Vertriebsteams scrapen regelmäßig die Kategorien Services und Gigs für die Lead-Gewinnung.
Die Rechnung ist simpel: 8 Stunden manuelles Kopieren und Einfügen versus etwa 10 Minuten mit einem sauber aufgebauten Scraper.
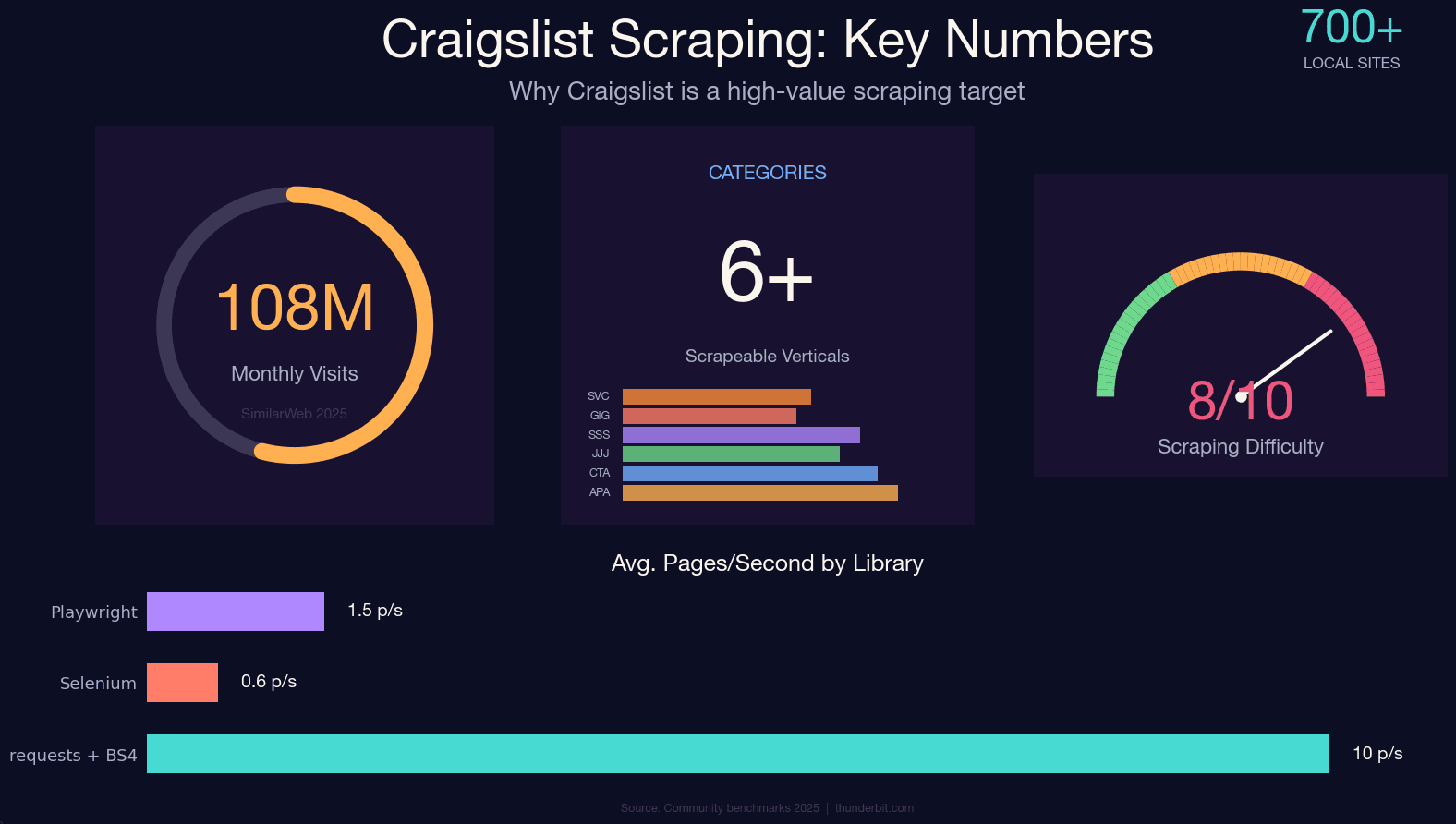
Craigslist mit Python scrapen: Jede Kategorie, nicht nur Autos
Fast jeder Craigslist-Scraping-Guide, den ich gefunden habe, behandelt nur „cars-for-sale“ — ungefähr so, als würde man ein Google-Tutorial schreiben, das nur die Bildersuche erklärt. Craigslist hat jedoch dutzende Kategorien, und die URL-Strukturen unterscheiden sich je nach Bereich.
Die Grundstruktur lautet immer: https://{city}.craigslist.org/search/{category_slug}
Wenn du die Stadt-Subdomain und den Slug austauschst, scrapest du plötzlich eine ganz andere Kategorie. Hier ist eine Referenztabelle der beliebtesten Bereiche (Stand: April 2025):
| Kategorie | URL-Slug | Typische zu extrahierende Felder |
|---|---|---|
| Apartments / Wohnen | /search/apa | Preis, Quadratmeter, Schlafzimmer, Lage, Haustierregelung |
| Autos & Trucks | /search/cta | Preis, Marke, Modell, Baujahr, Kilometerstand |
| Jobs | /search/jjj | Titel, Unternehmen, Gehalt, Beschäftigungsart |
| Services | /search/bbb | Titel, Beschreibung, Telefonnummer, Region |
| Gigs | /search/ggg | Titel, Vergütung, Datum, Kategorie |
| Zu verkaufen (allgemein) | /search/sss | Titel, Preis, Zustand, Ort |
Du kannst auch Suchparameter für Filter kombinieren:
| Parameter | Zweck | Beispiel |
|---|---|---|
query | Volltext-Suchbegriff | ?query=studio |
min_price / max_price | Preisbereich | &min_price=1500&max_price=3000 |
hasPic | Nur Beiträge mit Bildern | &hasPic=1 |
postedToday | Letzte 24 Stunden | &postedToday=1 |
sort | Sortierung | &sort=priceasc |
s | Seitenoffset (120 pro Seite) | ?s=120 |
Eine URL wie https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 liefert dir also Apartments in New York zwischen 1.500 und 3.000 US-Dollar mit Fotos. Jeder Python-Scraper in diesem Leitfaden funktioniert über alle Kategorien hinweg — du musst nur den Slug anpassen.
Craigslist-HTML-Selektoren 2025: alt vs. neu (und der JSON-Abkürzungsweg)
Der häufigste Grund, warum Craigslist-Scraper kaputtgehen, sind Änderungen an der HTML-Struktur. Wenn du einem Tutorial aus 2022 folgst, das .result-row oder .result-info verwendet, ist dein Scraper schon längst nicht mehr funktionsfähig.
Craigslist hat sein Markup für die Suchergebnisse 2023–2024 neu aufgebaut. Die alten Klassennamen existieren zwar noch innerhalb neuer Wrapper, aber wenn du sie auf oberster Ebene im DOM ansprichst, bekommst du eine leere Liste. Das hat sich geändert:
| Element | Alter Selektor (vor 2024) | Aktueller Selektor (2025) |
|---|---|---|
| Container des Inserats | .result-info | .cl-search-result |
| Titel-Link | .result-title | .posting-title a |
| Preis | .result-price | .priceinfo |
| Metadaten (Gebiet) | .result-hood | .meta |
Aber hier liegt der eigentliche Durchbruch — und genau das trennt einen wirklich aktuellen 2025-Scraper von allen älteren Ansätzen: Du musst Suchergebnisse gar nicht per HTML parsen.
Craigslist bettet inzwischen jedes sichtbare Inserat in einem <script id="ld_searchpage_results">-Tag als strukturierten JSON-LD-Datensatz ein. Ein einziger requests.get()-Aufruf liefert das vollständige schema.org-ItemList mit allen Anzeigen auf der Seite — Titel, Preis, Währung, Standort, Bild-URL, Link zur Detailseite. Kein JavaScript-Rendering nötig. Keine fragile CSS-Selektor-Logik.
Der JSON-LD-Ansatz ist schneller, stabiler und bricht deutlich seltener, wenn Craigslist das UI anpasst. Genau so arbeiten alle aktiv gepflegten GitHub-Repos, und genau so machen wir es auch im folgenden Tutorial.
Ein Hinweis: Der JSON-LD-Block ist — etwa Wohnungen (apa), Zu verkaufen (sss), Autos (cta) und Housing (hhh). Bei Jobs (jjj), Gigs (ggg), Community (ccc) und Services (bbb) fehlt er oft oder ist nur teilweise vorhanden, weil diese Anzeigen keine schema.org/Offer-Preisdaten haben. Für diese Kategorien solltest du auf den HTML-Pfad mit .cl-search-result zurückgreifen.
Deinen Python-Stack wählen: Requests + BS4 vs. Selenium vs. Playwright
Die Frage taucht in jedem Scraping-Forum auf: „Welche Bibliothek soll ich verwenden?“ Für Craigslist ist die Antwort deutlich klarer als bei vielen anderen Seiten.
| Faktor | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Geschwindigkeit | 5–15 Seiten/Sek. (netzwerkbegrenzt) | 0,3–1 Seite/Sek. | 0,5–2 Seiten/Sek. |
| JS-gerenderte Inhalte | Nein | Ja | Ja |
| Speicherverbrauch | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Einrichtungsaufwand | Gering | Mittel | Mittel |
| Anti-Bot-Resistenz | Gering (braucht Header/Proxies) | Mittel (echter Browser) | Mittel bis hoch |
| Bester Craigslist-Anwendungsfall | Suchergebnisse (JSON-LD) | Detailseiten mit dynamischen Inhalten | Skalierbares asynchrones Scraping |
| Lernkurve | Einsteigerfreundlich | Mittel | Mittel |
Craigslists Seiten werden serverseitig gerendert. Der JSON-LD-Block steckt im initialen HTML. Für Lesezugriffe gibt es keine JavaScript-Hürde. Jeder aktiv gepflegte setzt auf requests + BeautifulSoup oder Scrapy. Selenium oder Playwright werden dort praktisch nie eingesetzt. Das ist kein Zufall — ein Browser-Automationsframework kostet Hunderte Megabyte RAM, ist 10- bis 100-mal langsamer und hinterlässt einen deutlich auffälligeren Fingerabdruck, ohne hier einen echten Vorteil zu bringen.
Meine Empfehlung:
- requests + BS4: Hier solltest du anfangen. Die Kombination passt perfekt zur JSON-LD-Extraktion und deckt 95 % aller Craigslist-Use-Cases ab.
- Selenium: Nur wenn du mit dynamischen Inhalten auf bestimmten Detailseiten interagieren musst — das ist bei Craigslist selten.
- Playwright: Wenn du auf Tausende Seiten mit asynchroner Parallelität skalierst — aber ehrlich gesagt ist bei Craigslist meist der Rate Limiter der Engpass, nicht dein Tool.
Eine ausführliche Gegenüberstellung von und eine Übersicht der findest du in separaten Beiträgen, falls du tiefer einsteigen möchtest.
Die No-Code-Alternative: Craigslist scrapen, ohne Python zu schreiben
Kurzer Abstecher vor dem Code — dieser Abschnitt ist für alle gedacht, die keine Entwickler sind. Makler, Vertriebsteams, Operations-Manager: Wenn du einfach nur die Daten willst und kein Python schreiben möchtest, gibt es einen schnelleren Weg.
ist ein AI Web Scraper als Chrome-Erweiterung. Damit kannst du Craigslist in etwa zwei Klicks scrapen — ganz ohne Code. Der Ablauf sieht so aus:
- Öffne eine beliebige Craigslist-Suchergebnisseite (Wohnungen, Autos, Jobs — egal welche Kategorie).
- Klicke in der Thunderbit-Seitenleiste auf „KI-Felder vorschlagen“. Die KI liest die Seite und erkennt Spalten wie Titel, Preis, Standort und Link automatisch.
- Klicke auf „Scrapen“ — die Daten werden in Sekunden extrahiert.
- Nutze Unterseiten-Scraping, um jede Detailseite aufzurufen und deine Daten mit vollständigen Beschreibungen, Telefonnummern, Bildern und Attributen anzureichern.
- Exportiere direkt nach Google Sheets, Excel, Airtable oder Notion — komplett kostenlos.
Für wiederkehrende Aufgaben — etwa tägliches Monitoring von Apartmentpreisen oder wöchentliche Snapshots von Jobanzeigen — kannst du mit Thunderbits Geplantem Scraper den Zeitplan in normaler Sprache beschreiben, und er läuft automatisch. Keine Cronjobs, kein Server-Setup.
Thunderbit übernimmt Anti-Bot-Schutz außerdem über den Cloud-Scraping-Modus automatisch, sodass du dir keine Gedanken über rotierende Proxies oder speziell formulierte Header machen musst. Wenn du es ausprobieren willst, hol dir die und teste es selbst.
Wenn du volle Kontrolle und maximale Anpassung willst, lies einfach weiter und nutze die Python-Schritt-für-Schritt-Anleitung.
Schritt für Schritt: Craigslist mit Python scrapen (vollständiges Tutorial)
- Schwierigkeitsgrad: Mittel
- Zeitbedarf: ca. 30 Minuten (Setup + erster Scrape)
- Was du brauchst: Python 3.8+, Chrome-Browser (zum Inspizieren der Seiten), ein Terminal
Schritt 1: Python-Umgebung einrichten
Installiere die benötigten Bibliotheken:
1pip install requests beautifulsoup4 lxmllxml ist optional, beschleunigt das Parsen mit BeautifulSoup aber spürbar. Wenn du später Probleme mit TLS-Fingerprinting bekommst (mehr dazu im Anti-Ban-Abschnitt), kannst du zusätzlich curl_cffi installieren:
1pip install curl_cffiDein Import-Block:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomDamit hast du jetzt eine saubere Python-Umgebung mit allen notwendigen Abhängigkeiten.
Schritt 2: Craigslist-URL für jede Kategorie bauen
Erzeuge die Ziel-URL dynamisch aus Stadt + Kategorie-Slug + optionalen Filtern:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Beispiel: Wohnungen in New York, 1500–3000 $, mit Fotos
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Ersetze "apa" durch "cta" (Autos), "jjj" (Jobs), "bbb" (Services) oder einen anderen Slug aus der obigen Tabelle. Tausche "newyork" gegen "sfbay", "chicago", "losangeles" usw.
Schritt 3: Seite abrufen und eingebettetes JSON extrahieren
Sende eine GET-Anfrage mit passenden Headern und parse dann den JSON-LD-Block:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Wenn tag None ist, ist der JSON-LD-Block für diese Kategorie nicht vorhanden — dann musst du auf das HTML-Parsen ausweichen (siehe Selektortabelle oben). Bei Apartments, Autos und „for sale“-Kategorien ist der JSON-LD-Block in der Regel zuverlässig vorhanden.
Schritt 4: Listendaten in strukturierte Datensätze umwandeln
Gehe durch die JSON-Elemente und extrahiere die Felder, die du brauchst:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Gefunden: {len(listings)} Inserate")Du solltest etwas wie „Gefunden: 120 Inserate“ sehen (Craigslist zeigt 120 Ergebnisse pro Seite). Manche Anzeigen haben eventuell None als Preis, wenn der Anbieter keinen eingetragen hat — damit solltest du in deiner weiteren Logik sauber umgehen.
Schritt 5: Detailseiten für mehr Daten scrapen
Suchergebnisse liefern nur eine Zusammenfassung. Für vollständige Beschreibungen, Attribute (Schlafzimmer, Quadratmeter, Haustierregelung), Koordinaten und Bilder musst du jede Detailseite öffnen.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # wichtig: Anti-Ban-Jittertime.sleep(random.uniform(3, 6)) ist nicht optional. Wenn du das weglässt, läufst du bei wenigen Dutzend Anfragen sehr wahrscheinlich in einen 403. Detailseiten sind serverseitig gerendert und haben stabile Selektoren (#titletextonly, #postingbody, #map), die sich seit ungefähr 2017 kaum verändert haben — eine der wenigen wirklich verlässlichen Dinge bei Craigslist.
Schritt 6: Pagination handhaben und alle Ergebnisse scrapen
Craigslist nutzt für die Seitennavigation den Offset-Parameter ?s=120. Jede Seite zeigt 120 Ergebnisse, und der maximale Offset liegt typischerweise bei 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))Versuche nicht, in sehr kurzer Zeit Tausende Seiten zu scrapen. Craigslists Rate Limiter arbeitet pro IP, und ein nachhaltiger Durchsatz mit einer einzelnen IP liegt unabhängig von der Bibliothek nur bei etwa 0,3–0,5 Anfragen pro Sekunde. Diese Grenze setzt Craigslist — nicht Python.
Schritt 7: Craigslist-Daten nach CSV, JSON oder Google Sheets exportieren
Speichere deine Ergebnisse:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Wenn du den Exportcode lieber ganz überspringen willst, kannst du mit Thunderbit Daten direkt und kostenlos aus dem Browser nach Google Sheets, Excel, Airtable oder Notion exportieren. Für Python-Pipelines sind CSV und JSON jedoch die Standardausgaben. Du kannst die Daten auch direkt für Analysen in pandas oder in eine Datenbank mit sqlite3 weiterreichen.
Wie du beim Craigslist-Scraping mit Python nicht gesperrt wirst
Die meisten Tutorials gehen über diesen Teil hinweg. Craigslists Anti-Bot-System ist Eigenentwicklung und keine Standardlösung — und es hat ein paar sehr spezifische Eigenheiten.

Realistische Request-Header verwenden
Craigslist prüft Reihenfolge und Vollständigkeit der Header. Eine Anfrage ohne Sec-Fetch-Dest oder mit veraltetem User-Agent wird oft schon vor dem eigentlichen Seiteninhalt erkannt. Das vollständige Chrome-120+-Header-Set (oben in Schritt 3 gezeigt) ist das Minimum. Du kannst den User-Agent pro Session zwischen 5–10 aktuellen Chrome-/Firefox-Desktop-Strings rotieren — aber nicht mitten in der Session ändern, das wirkt unnatürlich.
Fehlende Sec-Fetch-*-Header sind der häufigste Grund, warum Einsteiger sofort blockiert werden.
Zufällige Pausen zwischen Anfragen einbauen
Der Konsens aus (ScrapingBee, Scraperly, Oxylabs, Multilogin) liegt bei zufälligen 2–5 Sekunden zwischen Suchseiten und 3–6 Sekunden zwischen Detailseiten. Feste Intervalle wirken wie ein Bot. Nutze time.sleep(random.uniform(2, 5)) — niemals einfach time.sleep(2).
Proxies rotieren, wenn du in größerem Maßstab scrapen willst
Craigslist blockt ganze IP-Bereiche von AWS, GCP und Azure vorab. Datacenter-Proxies sind oft sofort unbrauchbar. Für alles jenseits weniger hundert Seiten brauchst du Residential Proxies mit Rotation, idealerweise alle 20–30 Anfragen gewechselt. Mobile Proxies haben das geringste Erkennungsrisiko, sind aber mit 8–30 US-Dollar pro GB deutlich teurer.
| Proxy-Typ | Erkennungsrisiko bei Craigslist | Kosten (2025) |
|---|---|---|
| Datacenter | Sehr hoch — oft schon beim ersten Request blockiert | 0,50–2 $/GB |
| Residential rotating | Niedrig — empfohlen | 5–15 $/GB |
| Mobile | Am niedrigsten | 8–30 $/GB |
Thunderbits Cloud-Scraping-Modus übernimmt die Proxy-Rotation automatisch, wenn du das nicht selbst verwalten möchtest.
CAPTCHAs sauber behandeln
CAPTCHAs kommen auf Craigslist auf Lesezugriffen selten vor — meist tauchen sie beim Posten oder Antworten auf. Wenn doch eines erscheint: mindestens 60 Sekunden pausieren, IP wechseln, Cookies löschen und die Geschwindigkeit reduzieren. Wiederholte CAPTCHAs bedeuten meist, dass dein Tempo zu aggressiv ist — nicht, dass du das Rätsel per Solver „knacken“ solltest.
Rate Limits respektieren und Backoff einbauen
Craigslist liefert 403 (nicht 429), wenn du das Rate Limit überschreitest. Ein 403 bedeutet, dass die aktuelle IP auf einer Sperrliste gelandet ist — nicht blind erneut versuchen. IP wechseln, User-Agent ändern und warten.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Noch ein Tipp: Aus der Community kommen sehr konsistent Hinweise, dass 2–6 Uhr Ortszeit der Zielstadt das sicherste Zeitfenster ist — mit etwa 30–40 % niedrigeren Blockraten als tagsüber.
TLS-Fingerprinting — die versteckte Falle
Craigslists Bot-Layer prüft den TLS ClientHello. Die Python-Bibliothek requests (auf OpenSSL-Basis) hat einen JA3-Fingerprint, der zu keinem echten Browser passt. Ein perfekter User-Agent zusammen mit einem nicht-browsertypischen TLS-Fingerprint ist ein klar erkennbarer Widerspruch. Die Abhilfe ist mit impersonate="chrome124", das den TLS-Handshake von Chrome emuliert:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Wenn du trotz sauberer Residential-IP und korrekter Header unerklärliche 403s bekommst, ist TLS-Fingerprinting sehr wahrscheinlich die Ursache.
Craigslist robots.txt, Nutzungsbedingungen und ethisches Scraping
Die meisten Guides überspringen das komplett oder verstecken einen Einzeiler in den FAQs. Da Craigslist 2017 in einem Scraping-Streit ein Urteil über gegen einen Scraper (RadPad) erwirkt hat, verdient das mehr als nur eine Fußnote.
Was Craigslist in der robots.txt tatsächlich sagt
Die ist überraschend kurz. Sie enthält nur einen User-agent: *-Block mit sieben gesperrten Pfaden:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafAlle sieben sind interaktive oder verändernde Endpunkte: antworten, melden, vorschlagen, E-Mail an Freund senden. Anzeigenseiten (/search/..., einzelne Post-URLs) sind nicht gesperrt. Eine Crawl-delay-Anweisung gibt es nicht — dennoch setzt Craigslist faktisch über IP-Sperren ein Limit durch.
Die Stadt-Subdomains veröffentlichen außerdem Sitemaps — zum Beispiel https://newyork.craigslist.org/sitemap/index.xml — also den offiziell auffindbaren Weg zu den Inseraten.
Rechtliche Präzedenzfälle: die wichtigen Fälle
Craigslist v. 3Taps (2013, Vergleich 2015): 3Taps scrapt und verkaufte Craigslist-Anzeigen weiter. Als Craigslist eine Unterlassungserklärung schickte und die IPs sperrte, umging 3Taps die Blockade mit rotierenden Proxies. Das Gericht befand, dass das Umgehen von IP-Sperren nach ausdrücklichem Widerruf „without authorization“ im Sinne des CFAA darstellt. 3Taps einigte sich später auf einen .
Meta v. Bright Data (2024): Ein neueres Urteil stellte fest, dass die Nutzungsbedingungen von Meta das Scraping öffentlich verfügbarer Daten im ausgeloggten Zustand nicht verbieten können. Das Gericht sah einen ausgeloggten Scraper „in derselben Rolle wie ein Besucher“. Das ist für Scraper in den Jahren 2024–2025 besonders wichtig: Wenn du nie ein Craigslist-Konto anlegst, dich nie einloggst und nur öffentlich sichtbare Seiten aufrufst, sind die Nutzungsbedingungen möglicherweise nicht als Vertrag gegen dich durchsetzbar.
Die praktische Konsequenz: Das CFAA-Risiko ist nach Van Buren (2021) und hiQ v. LinkedIn (2022) für öffentlich zugängliche Seiten deutlich geringer. Aber zivilrechtliche Ansprüche nach Landesrecht — etwa trespass to chattels oder misappropriation — bleiben relevant. Genau diese Ansprüche spielten beim 3Taps-Vergleich und dem 60,5-Mio.-Urteil gegen RadPad eine Rolle.
Das hier ist eine Informationsquelle, keine Rechtsberatung. Wenn du Craigslist kommerziell scrapen willst, sprich mit einem Anwalt.
Praktische Checkliste für ethisches Scraping
- ✅ Halte dich an alle
Disallow-Einträge in der robots.txt — besonders an die sieben Aktions-Endpunkte - ✅ Bleibe deutlich unter 1.000 Seiten pro 24 Stunden und IP (Craigslists Nutzungsbedingungen setzen darüber als pauschalierten Schadensersatz an)
- ✅ Bleibe ausgeloggt — lege niemals für Scraping einen Craigslist-Account an
- ✅ Umgehe IP-Sperren nach einem ausdrücklichen Block nicht per Proxy-Wechsel (genau daran ist 3Taps gescheitert)
- ✅ Baue Pausen zwischen den Anfragen ein — mindestens 2–5 Sekunden
- ✅ Scrape keine personenbezogenen Kontaktdaten für Spam
- ✅ Gib rohe Craigslist-Daten nicht einfach weiter und stelle sie nicht als deine eigene Plattform dar
- ✅ Nutze die Daten für legitime Forschung, Analyse oder private Zwecke
- ✅ Nutze veröffentlichte Sitemaps, wo immer es möglich ist, statt stumpf alles zu crawlen
- ✅ Entferne personenbezogene Daten (E-Mails, Telefonnummern) direkt beim Import, wenn du die Daten speicherst
Wir haben einen ausführlicheren Leitfaden zu den , wenn du das Gesamtbild verstehen möchtest.
Python vs. No-Code: Welcher Ansatz passt zu dir?
| Faktor | Python (requests + BS4) | Thunderbit (No-Code) |
|---|---|---|
| Einrichtungszeit | 30–60 Min. (installieren, Code schreiben) | 2 Minuten (Chrome-Erweiterung installieren) |
| Erforderliches technisches Know-how | Mittlere Python-Kenntnisse | Keine |
| Anpassbarkeit | Volle Kontrolle über Logik, Felder und Ablauf | KI erkennt Felder automatisch; Nutzer kann anpassen |
| Skalierung | Unbegrenzt (mit Proxies und Zeitplänen) | Geplanter Scraper für wiederkehrende Aufgaben |
| Umgang mit Sperren | Manuell (Header, Pausen, Proxies, TLS) | Integriert (Cloud Scraping) |
| Exportoptionen | CSV, JSON (selbst programmieren) | Google Sheets, Excel, Airtable, Notion — kostenlos |
| Am besten geeignet für | Entwickler, Data Scientists, individuelle Pipelines | Vertrieb, Makler, Operations-Teams |
Nutze Python, wenn du maximale Anpassung brauchst, das Ganze in eine größere Datenpipeline einbinden willst oder exakt verstehen möchtest, was im Hintergrund passiert. Nutze , wenn du schnell Ergebnisse willst, ohne Code schreiben oder pflegen zu müssen. Beides ist richtig. Es hängt davon ab, wofür du es brauchst und ob du deine Zeit lieber im Terminal oder im Browser verbringst.
Fazit
Craigslist ist eine reichhaltige, ständig aktualisierte Datenquelle für Wohnungen, Autos, Jobs, Services, Gigs und mehr — und ohne öffentliche API ist Scraping der einzige Weg, strukturierte Daten im großen Stil zu bekommen. Der Ansatz für 2025, der wirklich funktioniert: eingebettetes JSON-LD aus den Suchergebnissen extrahieren statt fragiler CSS-Selektoren, requests + BeautifulSoup statt Selenium verwenden, realistische Header inklusive Sec-Fetch-* setzen, Pausen zufällig variieren und bei mehr als ein paar hundert Seiten Residential Proxies einsetzen.
Die JSON-LD-Methode ist der mit Abstand größte Fortschritt gegenüber älteren Guides. Sie ist schneller, robuster gegenüber Layout-Änderungen und benötigt keinerlei JavaScript-Rendering. Kombiniert mit den Anti-Ban-Strategien oben vermeidest du die 403-Fehler, die die meisten Scraper ausbremsen.
Wenn du den Code lieber ganz überspringen willst, kann die jede Craigslist-Kategorie mit wenigen Klicks scrapen und direkt in deine bevorzugte Tabelle oder Datenbank exportieren. Wenn du tiefer einsteigen möchtest, erklären unsere Leitfäden zu und zu die Grundlagen ausführlicher.
FAQs
Ist es legal, Craigslist zu scrapen?
Craigslists Nutzungsbedingungen verbieten automatisiertes Scraping und enthalten eine Klausel zu pauschaliertem Schadensersatz (0,25 $ pro Seite über 1.000/Tag). Allerdings haben jüngere Gerichtsurteile — insbesondere Meta v. Bright Data (2024) und hiQ v. LinkedIn (2022) — die Haftung nach CFAA für das Scraping öffentlich verfügbarer Daten im ausgeloggten Zustand eingeschränkt. Zivilrechtliche Ansprüche nach Landesrecht (trespass to chattels) bleiben ein Risiko, vor allem bei kommerzieller Weiterverbreitung. Halte dich an robots.txt, bleibe ausgeloggt, baue Pausen ein und verbreite die Rohdaten nicht weiter. Das ist allgemeine Information, keine Rechtsberatung.
Gibt es eine öffentliche API für Craigslist?
Nein. Craigslist bietet nur eine rein schreibende Bulk Posting Interface (BAPI) für zugelassene, kostenpflichtige Anbieter. Es gibt keine öffentliche Read-API, kein Entwicklerportal und keinen limitierten Datenabruf-Tarif. Jedes „Craigslist API“-Produkt auf Drittplattformen ist in Wirklichkeit ein inoffizieller Scraper.
Warum bricht mein Craigslist-Scraper immer wieder?
Fast immer liegt es an Änderungen in der HTML-Struktur. Craigslist hat 2023–2024 sein Markup für Suchergebnisse neu geschrieben, und Anleitungen mit alten Selektoren wie .result-row oder .result-info funktionieren nicht mehr. Wechsle zur eingebetteten JSON-LD-Methode (script#ld_searchpage_results), das ist deutlich robuster. Prüfe außerdem, ob deine Header Sec-Fetch-*-Felder enthalten — fehlen sie, wirst du oft sofort blockiert.
Kann ich Craigslist auch ohne Python scrapen?
Ja. Thunderbits AI-Web-Scraper-Chrome-Erweiterung funktioniert auf jeder Craigslist-Seite — Wohnungen, Autos, Jobs, Services. Klicke auf „KI-Felder vorschlagen“, damit die Spalten automatisch erkannt werden, klicke auf „Scrapen“, um die Daten zu extrahieren, und exportiere anschließend kostenlos nach Google Sheets, Excel, Airtable oder Notion. Kein Coding, kein Setup, keine Proxy-Verwaltung.
Wie oft kann ich Craigslist scrapen, ohne gesperrt zu werden?
Mit einer einzelnen Residential-IP liegt der nachhaltige Durchsatz bei etwa 0,3–0,5 Requests pro Sekunde, wenn du zwischen den Seiten zufällige Pausen von 2–5 Sekunden einbaust. Bleibe unter 1.000 Seiten pro 24 Stunden und IP, um sowohl Sperren als auch die Schwelle für pauschalierten Schadensersatz in Craigslists Nutzungsbedingungen zu vermeiden. Scraping in Nebenzeiten (2–6 Uhr Ortszeit der Zielstadt) reduziert die Blockrate um etwa 30–40 %. Bei größeren Mengen solltest du Residential Proxies alle 20–30 Anfragen rotieren.
Mehr erfahren