Executive Summary
Der stellte eine politische Frage: Wie viele der meistbesuchten Websites der Welt sagen KI-Crawlern, was sie dürfen und was nicht?
Dieser Follow-up stellt die eigentliche operative Frage dahinter: Wie verlässlich ist robots.txt als Infrastruktur, die diese Policy inzwischen tragen soll?
Die Antwort ist unbequem. robots.txt funktioniert weiterhin, weil sie öffentlich, günstig, maschinenlesbar und für Crawler bereits verständlich ist. Gleichzeitig soll sie heute weit mehr leisten, als sie je dafür gedacht war. 2026 kann dieselbe einfache Textdatei SEO-Crawl-Steuerungen, Sitemap-Indizes, alte Suchmaschinen-Erweiterungen, Opt-outs für KI-Training, von Cloudflare eingebettete Policy-Begriffe, Urheberrechtsvorbehalte und juristische Sprache für künftige Streitfälle enthalten.
Das ist Konfigurationsschuld.
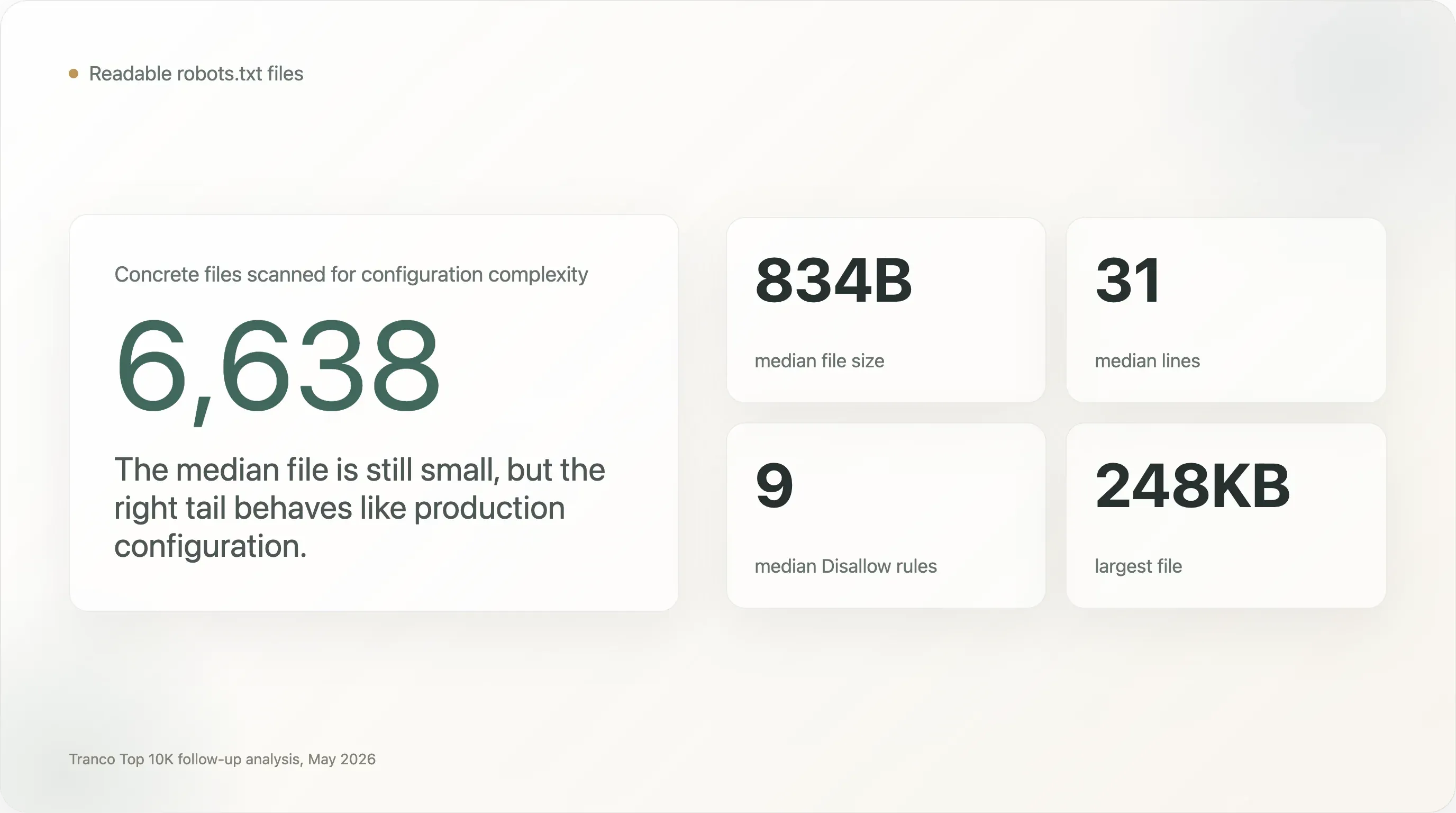
Der Datensatz hinter diesem Bericht ist derselbe Tranco-Top-10.000-Crawl wie in der ursprünglichen Studie zu KI-Crawlern. Von den 10.000 Domains lieferten 6.638 eine lesbare robots.txt; weitere 610 gaben 404 zurück, was im Protokoll als implizite Freigabe gilt. Damit ergeben sich 7.248 analysierbare Sites für Bot-Zugriffsentscheidungen und 6.638 konkrete Dateien für die Analyse der Konfigurationskomplexität.
Sechs Befunde stechen hervor:
-
Die meisten
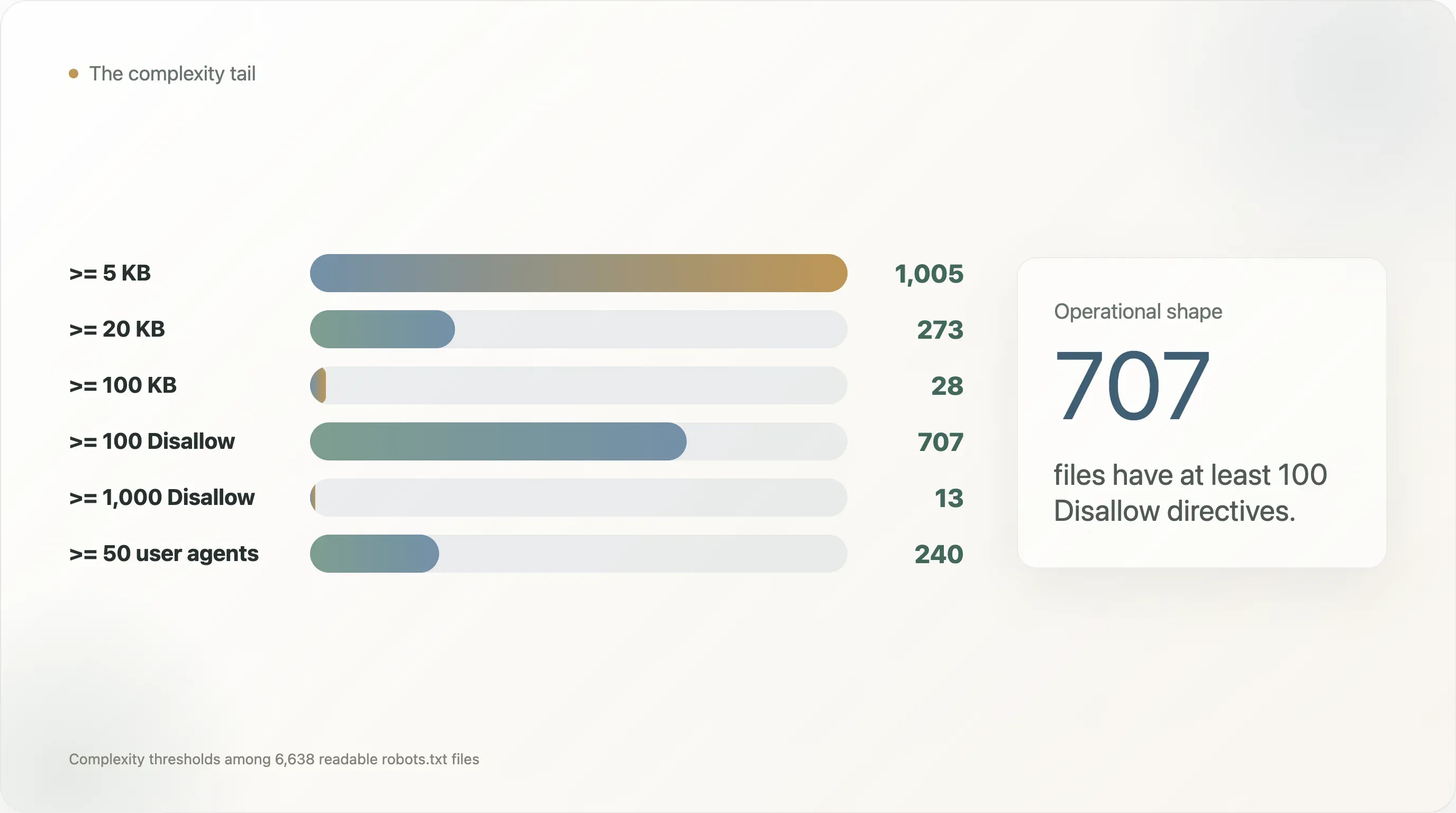
robots.txt-Dateien sind klein, aber das rechte Ende ist extrem komplex. Die Median-Datei hat nur 834 Byte und 31 Zeilen. Doch 1.005 Dateien sind mindestens 5 KB groß, 273 mindestens 20 KB und 28 mindestens 100 KB. Die größte Datei im Sample ist 248 KB. -
Hunderte Top-Websites betreiben Dateien, die eher wie Produktionskonfigurationen als wie Notizzettel zu Richtlinien wirken. Die Median-Datei hat 9
Disallow-Direktiven. Aber 707 Sites haben mindestens 100Disallow-Regeln, 13 haben mindestens 1.000, 240 benennen mindestens 50 User-Agents und 110 benennen mindestens 100 User-Agents. -
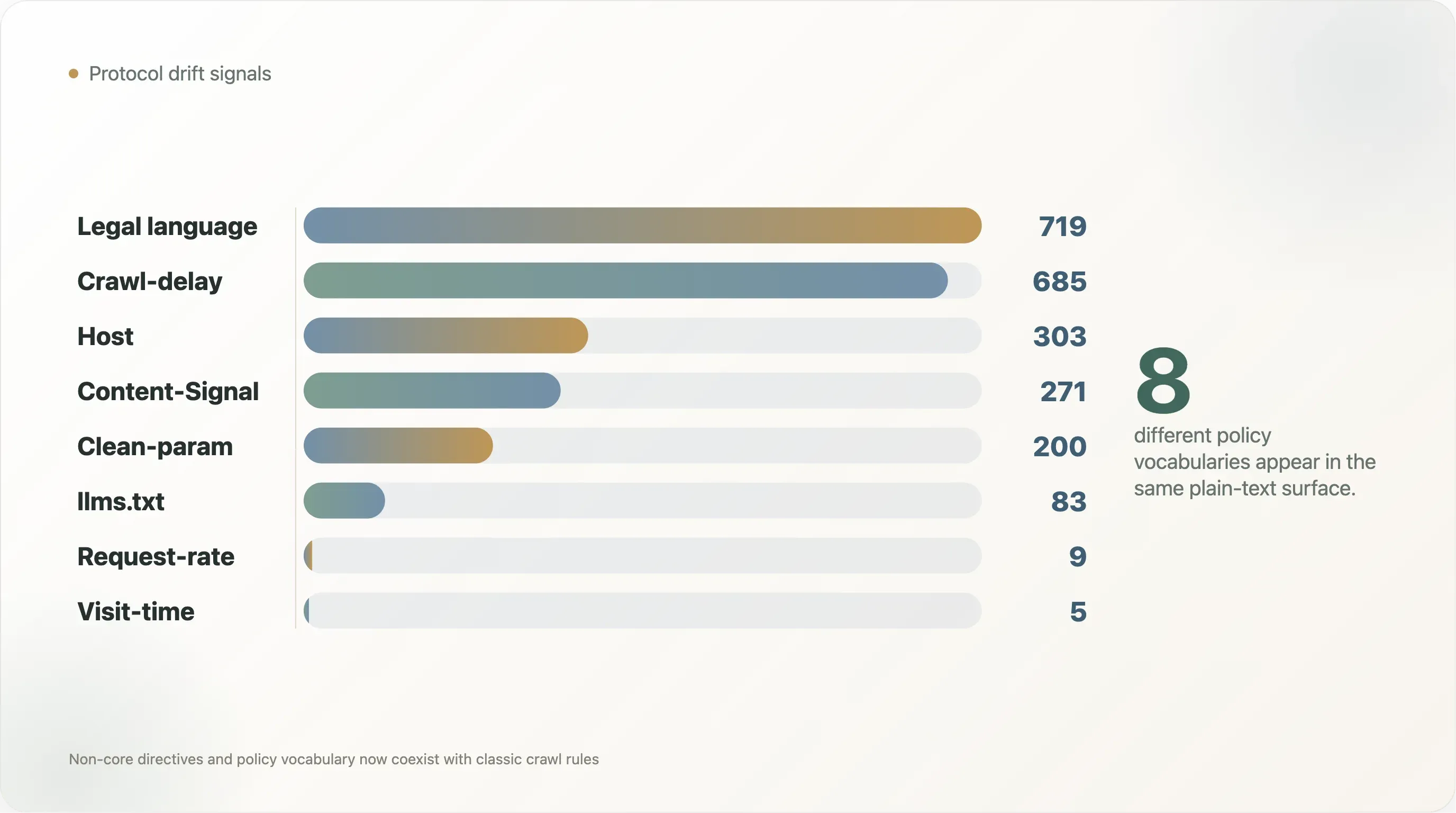
Protokoll-Drift ist nicht theoretisch. Unter den 6.638 lesbaren Dateien enthalten 685
Crawl-delay, 303Host, 200Clean-param, 9Request-rate, 5Visit-timeund 271 eine Cloudflare-artigeContent-Signal-Sprache. Das ist nicht alles Teil desselben sauberen Standards. Das ist angesammelte Crawler-Folklore. -
Googlebot wird als Sonderfall behandelt. 562 analysierbare Domains blockieren mindestens einen traditionellen Suchcrawler. In 404 dieser Fälle ist Googlebot erlaubt, während mindestens ein anderer Suchcrawler blockiert wird. Die Diskriminierung von KI-Crawlern entstand also nicht in einem neutralen Ökosystem;
robots.txthatte die Hierarchie der Suchmaschinen schon längst eingebaut. -
KI-Policy macht die Schulden sichtbarer. 1.377 lesbare Dateien enthalten KI-Policy-Sprache; 719 enthalten Sprache zu Urheberrecht, Nutzungsbedingungen, Lizenzierung oder Vorbehalten; und 501 enthalten beides. Die Datei ist dadurch zugleich Maschinen-Schnittstelle und juristisches Artefakt geworden. Das ist nützlich, aber fragil.
-
Die riskantesten Dateien sind nicht immer die anti-KI-Dateien. E-Commerce, Reisen, Social, Finanzen, Wissenschaft und News erzeugen aus unterschiedlichen Gründen komplexe Dateien: Crawl-Budget-Steuerung, Altpfade, nutzergenerierte Inhalte, Rechtevorbehalte und bot-spezifische Ausnahmen. KI-Regeln werden auf eine bereits unordentliche Grundlage aufgesetzt.
Die Hauptschlussfolgerung: robots.txt bleibt die wichtigste öffentliche Oberfläche des Webs für Crawler-Policy, ist aber eine schwache Grundlage für hochsensible KI-Governance, solange das Ökosystem Crawler-Identität, KI-Nutzungs-Vokabular und Prüfbarkeit der Policy nicht standardisiert.
Methodik
Dieser Bericht nutzt den Datensatz aus der ursprünglichen Thunderbit-Analyse zur KI-Crawler-Policy auf den Tranco Top 10.000 Domains erneut.
Die Eingangsdaten waren:
tranco_top10k.csv— die ursprüngliche Tranco-Top-10K-Domainliste.out/fetch_meta.csv— Abrufstatus, Byte-Anzahl, Schema, Redirect-Ergebnis und Fehler-Metadaten.out/sites.csv— Domain, Rank, Kategorie, Sprache undrobots.txt-Status.out/site_meta.csv— eine analytische Zeile pro Site, einschließlich Template-Klasse, KI-Blocking-Flags, Dateigröße und Zusammenfassungsfeldern zur Bot-Policy.out/bot_status.csv— eine Zeile pro Domain und Crawler, einschließlich der Frage, ob der Bot blockiert ist und ob eine spezifische Regel existiert.raw_robots/— zwischengespeicherterobots.txt-Inhalte für die 6.638 Sites mit Status200.
Für diesen Follow-up wurden alle lesbaren robots.txt-Dateien auf Folgendes untersucht:
- Dateigröße und Zeilenanzahl;
- aktive, nicht kommentierte Zeilen;
- Anzahl der Direktiven
User-agent,Disallow,AllowundSitemap; - alte oder nicht zentrale Direktiven wie
Crawl-delay,Host,Clean-param,Request-rateundVisit-time; - KI-Vokabular wie
Content-Signal,llms.txt, AI, LLM, machine learning, TDM und2019/790; - juristisches Vokabular wie copyright, terms of service, licensing, permission und rights-reservation language;
- Behandlung von Such-Crawlern für Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider und YandexBot.
Der Bericht definiert außerdem einen einfachen Configuration Debt Score zur Priorisierung. Er kombiniert Dateigröße, User-Agent-Anzahl, Disallow-Anzahl, Allow-Anzahl, die Anzahl nicht standardisierter Direktiven sowie die Mischung aus KI-Policy- und Rechtssprache. Der Score ist nicht als universelles Maß für Korrektheit gedacht. Er soll Dateien identifizieren, die wahrscheinlich schwer zu warten, zu prüfen oder zu interpretieren sind.
Alle abgeleiteten Tabellen und Diagramme sind im Lieferordner enthalten.
Befund 1: Die Median-Datei ist einfach; das rechte Ende nicht
Die typische robots.txt-Datei im Top-Web ist weiterhin klein.
Über die 6.638 lesbaren Dateien hinweg:
| Metrik | Median | P90 | P95 | P99 | Max |
|---|---|---|---|---|---|
| Dateigröße | 834 Byte | 6,7 KB | 15,8 KB | 76,0 KB | 248,3 KB |
| Zeilen | 31 | 238 | 332 | 1.008 | 4.998 |
| Aktive Zeilen | 23 | 198 | 282 | 837 | 4.998 |
User-agent-Direktiven | 1 | 21 | 39 | 137 | 823 |
Disallow-Direktiven | 9 | 103 | 176 | 422 | 4.997 |
Allow-Direktiven | 1 | 17 | 33 | 69 | 890 |
Diese Verteilung ist wichtig, weil robots.txt oft so behandelt wird, als wäre sie eine kleine Erklärung:
1User-agent: *
2Disallow: /private/Dieses mentale Modell ist für einen relevanten Teil des stark frequentierten Webs falsch.
In diesem Datensatz:
This paragraph contains content that cannot be parsed and has been skipped.
Die größten und komplexesten Dateien sind keine akademischen Kuriositäten. Sie gehören zu echten, stark frequentierten Properties:
| Domain | Rank | Kategorie | Bytes | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114.341 | 76 | 4.184 | 281 |
runescape.com | 5.226 | unknown | 113.393 | 1 | 4.997 | 0 |
academia.edu | 832 | academia | 57.384 | 63 | 2.044 | 227 |
etsy.com | 286 | ecommerce | 51.320 | 3 | 1.621 | 120 |
thepaper.cn | 9.395 | news | 56.867 | 1 | 1.496 | 0 |
opentable.com | 4.137 | unknown | 70.494 | 32 | 1.683 | 176 |
alfabank.ru | 2.625 | finance | 73.158 | 2 | 1.566 | 133 |
Diese Dateien ähneln eher Produktions-Routing-Tabellen als Policy-Slogans. Sie kodieren Jahre von Produktstarts, Altpfaden, blockierten Parameter-Mustern, Crawler-Ausnahmen, SEO-Experimenten, CDN-Entscheidungen und inzwischen auch KI-Crawler-Regeln.
Das rechte Ende ist nicht nur eine KI-Geschichte. Von den 273 Dateien mit mindestens 20 KB enthalten 131 KI-Policy-Sprache und 142 nicht. Von den 707 Dateien mit mindestens 100 Disallow-Direktiven enthalten nur 207 KI-Policy-Sprache. Anders gesagt: KI hat das Problem der großen Dateien nicht geschaffen. Sie kam erst, nachdem jahrelange reguläre Web-Operationen die Datei bereits mit Pfadregeln, Sitemap-Verweisen und Crawler-Ausnahmen gefüllt hatten.
Das ist relevant, weil Wartbarkeit von der Form abhängt, nicht nur von der Absicht. Eine kleine Datei mit einem direkten KI-Block kann leicht prüfbar sein. Eine 70-KB-E-Commerce- oder Reise-Datei kann schwer prüfbar sein, selbst wenn sie nichts über KI sagt. Das Risiko besteht nicht darin, dass jede große Datei falsch ist. Das Risiko besteht darin, dass die effektive Policy so schwer zu überprüfen wird, dass die Verantwortlichen sie nicht mehr sicher beurteilen können.
Das operative Risiko ist klar: Wenn robots.txt wächst, wird es für Publisher, Plattform-Ingenieure, Juristen oder SEO-Verantwortliche immer schwerer, die grundlegende Frage zu beantworten: Was erlaubt diese Datei eigentlich?
Diese Frage ist längst nicht mehr trivial. Nach RFC-artiger Analyse kann ein Crawler statt User-agent: * eine spezifischere User-Agent-Gruppe treffen; längere Pfad-Matches können kürzere überschreiben; Allow- und Disallow-Direktiven greifen nach Vorrangregeln ineinander; und generische Alles-verbieten-Regeln können versehentlich neue Crawler erfassen, die es bei der Erstellung der Datei noch gar nicht gab.
Bei einer 30-Zeilen-Datei kann ein Mensch das noch nachvollziehen. Bei einer 4.000-Zeilen-Datei mit Dutzenden benannten Bots sollte das niemand tun müssen.
Befund 2: robots.txt trägt mehr als nur Crawl-Regeln
Die KI-Crawler-Debatte machte robots.txt politisch sichtbar, doch die zugrunde liegende Datei sammelte schon vorher immer neue, fachfremde Aufgaben an.
Eine moderne robots.txt einer Top-Site kann enthalten:
- Steuerungen für Crawler-Pfade;
- Sitemap-Entdeckung;
- suchmaschinenspezifische Erweiterungen;
- Hinweise zur Crawl-Rate;
- Hinweise zur Host-Kanonisierung;
- Hinweise zur Bereinigung von URL-Parametern;
- von CDNs eingebettete Policy-Sprache;
- Texte zum Vorbehalt von Urheberrechten;
- Opt-outs für KI-Training;
- lesbare juristische Kommentare.
Der Datensatz zeigt diese Überlagerung deutlich.
| Signal | Dateien | Anteil der lesbaren Dateien |
|---|---|---|
Crawl-delay | 685 | 10,3% |
Host | 303 | 4,6% |
Clean-param | 200 | 3,0% |
Content-Signal | 271 | 4,1% |
Request-rate | 9 | 0,1% |
Visit-time | 5 | 0,1% |
Erwähnung von llms.txt | 83 | 1,3% |
| Urheberrecht, Nutzungsbedingungen, Lizenzierung oder Vorbehaltssprache | 719 | 10,8% |
| KI-Policy-Sprache | 1.377 | 20,7% |
Einige dieser Direktiven sind für bestimmte Crawler weithin bekannt. Einige sind Legacy-Konventionen. Einige sind anbieterspezifisch. Einige sind gar keine Crawler-Direktiven, sondern juristische oder produktbezogene Sprache in Kommentaren.
So sieht Protokoll-Drift aus.
Crawl-delay ist ein gutes Beispiel. Vielen Website-Betreibern ist sie vertraut, doch die Unterstützung durch große Crawler ist uneinheitlich. Host und Clean-param wurden historisch mit Yandex-Verhalten assoziiert. Content-Signal gehört zur KI-Policy-Sprache von Cloudflare. llms.txt ist ein vorgeschlagenes, angrenzendes Discovery-Format, kein universell anerkanntes Standardformat. Trotzdem tauchen all diese Dinge im selben Dateityp auf, oft direkt neben klassischen User-agent- und Disallow-Regeln.
Die Zahlen zeigen auch, wie alte und neue Konventionen inzwischen nebeneinander existieren. Crawl-delay erscheint in 685 Dateien und damit mehr als doppelt so oft wie Content-Signal in 271 Dateien. Host erscheint in 303 Dateien und Clean-param in 200, meist als Echo aus der Suchmaschinen-Ära. llms.txt wird trotz intensiver Diskussion in KI- und Suchkreisen nur in 83 lesbaren Dateien erwähnt. Das Live-Web einigt sich nicht auf ein Vokabular. Es stapelt Vokabulare.
Das Problem ist nicht, dass jede einzelne Erweiterung falsch wäre. Das Problem ist, dass die Datei zu einem nicht versionierten Container für mehrere überlappende Governance-Systeme geworden ist.
Das erzeugt drei Arten von Schuld:
- Semantische Schuld. Unterschiedliche Crawler können dieselbe Datei unterschiedlich interpretieren.
- Ownership-Schuld. SEO-, Rechts-, Infrastruktur-, Sicherheits- und Produktteams haben womöglich alle Gründe, die Datei zu bearbeiten, aber keines besitzt die gesamte Policy.
- Audit-Schuld. Eine Site kann eine Policy veröffentlichen, die bewusst wirkt, während nur ein Parser ihr tatsächliches Verhalten bestimmen kann.
KI macht das wichtiger, weil sich die Einsätze verändert haben. Wenn ein alter Crawl-Rate-Hinweis ignoriert wird, kann das nur zusätzlicher Traffic sein. Wenn ein Opt-out für KI-Training unklar ist, kann das in einem Urheberrechts- oder Lizenzstreit als Beweis dienen.
Befund 3: Die Datei ist zugleich Maschinen-Schnittstelle und juristisches Artefakt
Der ursprüngliche KI-Crawler-Bericht zeigte, dass 17,0 % der analysierbaren Sites explizite KI-spezifische Regeln geschrieben hatten. Dieser Follow-up betrachtet die textliche Last, die diese Policies mit sich bringen.
Unter den 6.638 lesbaren robots.txt-Dateien:
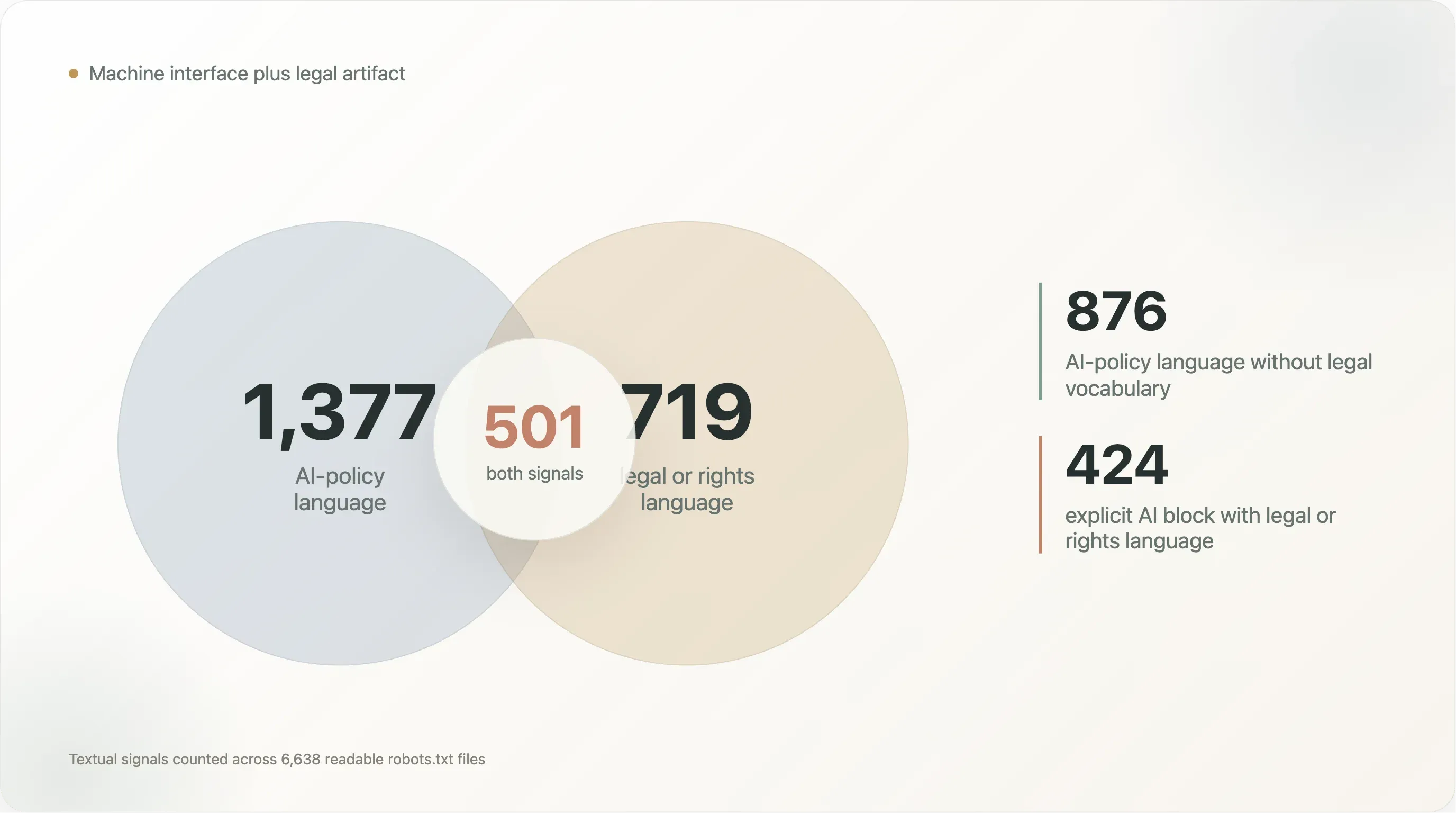
- 1.377 enthalten KI-Policy-Sprache;
- 719 enthalten Sprache zu Urheberrecht, Nutzungsbedingungen, Lizenzen, Rechten oder Vorbehalten;
- 271 enthalten
Content-Signal; - 83 erwähnen
llms.txt.
Die Überschneidung ist der spannendere Teil der Geschichte:
| Textmuster | Dateien |
|---|---|
| KI-Policy-Sprache und juristische/Rechte-Sprache | 501 |
| KI-Policy-Sprache ohne juristische/Rechte-Sprache | 876 |
| Juristische/Rechte-Sprache ohne KI-Policy-Sprache | 218 |
Content-Signal mit juristischer/Rechte-Sprache | 242 |
| Expliziter KI-Block mit juristischer/Rechte-Sprache | 424 |
Das ist ein neuer Dateityp.
Eine traditionelle robots.txt richtet sich an Crawler. Eine robots.txt mit juristischem Vorspann richtet sich gleichzeitig an mindestens vier Zielgruppen:
- Crawler-Betreiber, die maschinenlesbare Direktiven brauchen;
- Such- und KI-Anbieter, die Policy-Signale brauchen;
- Juristen, die einen ausdrücklichen Rechtevorbehalt wollen;
- künftige Prüfer, Gerichte oder Journalisten, die die Kommentare als Beweis für die Absicht lesen könnten.
Dieses Multi-Audience-Design erklärt, warum manche Dateien inzwischen wie Policy-Dokumente lesen. Es verwischt aber auch die saubere Trennung zwischen dem, was ein Crawler parsen kann, und dem, was ein Jurist deklarieren möchte.
Die 876 Dateien mit KI-Policy-Sprache ohne juristisches Vokabular sind meist Maschinen-Policy-Dateien: Bot-Namen, Disallow-Blöcke und Template-Sprache. Die 501 Dateien mit KI- und Rechtssprache sind anders. Sie versuchen zugleich Crawler-Anweisung und Rechtevorbehalt zu sein. Die 218 Dateien mit Rechtssprache ohne KI-Vokabular zeigen, dass dieses Muster nicht mit LLMs begann; robots.txt wurde schon vorher als Ort genutzt, um Bedingungen, Zugriffsgrenzen und Rechteansprüche zu formulieren.
Zum Beispiel kann ein Kommentar sagen, dass Machine Learning verboten ist, während der eigentliche Direktivenblock nur eine Teilmenge bekannter User-Agents sperrt. Eine Site kann Rechte pauschal beanspruchen, aber nur einige Crawler nennen. Ein CDN-Template kann KI-bezogene Sprache in eine Datei einfügen, deren Betreiber die juristische Sprache nie selbst verfasst hat. Eine Site kann eine breite User-agent: *-Regel schreiben, die zukünftige Crawler unbeabsichtigt blockiert.
Aus Governance-Sicht ist robots.txt gerade deshalb attraktiv, weil sie öffentlich und maschinenlesbar ist. Doch je mehr Policy sie trägt, desto stärker werden ihre Grenzen sichtbar:
- Es gibt keine Authentifizierungsschicht, die belegt, dass eine bestimmte Policy vom Rechteinhaber geprüft wurde und nicht von der Infrastruktur geerbt ist.
- Es gibt keine native Versionshistorie.
- Es gibt kein strukturiertes Feld für die beabsichtigte Nutzung, etwa Training, Retrieval, Suchindexierung, Zusammenfassung, Caching oder Modellbewertung.
- Es gibt kein universelles Register für KI-Crawler-Identitäten.
- Es gibt keinen Durchsetzungsmechanismus.
Das macht die Datei nicht nutzlos. Es macht sie fragil.
Die bessere Lesart ist, dass robots.txt zu einer Hinweis-Ebene wird: einer öffentlichen, prüfbaren Erklärung von Präferenz und Absicht. Sie ist für sich genommen kein vollständiges Rechteverwaltungssystem.
Befund 4: Suchmaschinen waren schon vor KI nicht gleich behandelt
Eine der stärksten Erkenntnisse des ursprünglichen Berichts war, dass viele Publisher zwischen KI-Trainings-Crawlern und Such-Crawlern unterscheiden. Sie blockieren CCBot, GPTBot oder Google-Extended, lassen aber die Google-Sichtbarkeit unangetastet.
Dieser Follow-up ergänzt einen anderen Punkt: Auch traditionelle Such-Crawler werden nicht gleich behandelt.
Wir haben sechs Such-Crawler geprüft:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Über die 7.248 analysierbaren Sites hinweg:
| Behandlung von Such-Crawlern | Sites |
|---|---|
| Blockiert mindestens einen Such-Crawler | 562 |
| Erlaubt Googlebot, blockiert aber mindestens einen anderen Such-Crawler | 404 |
| Blockiert alle sechs geprüften Such-Crawler | 152 |
Die Anzahl blockierter Bots ist nicht gleichmäßig verteilt:
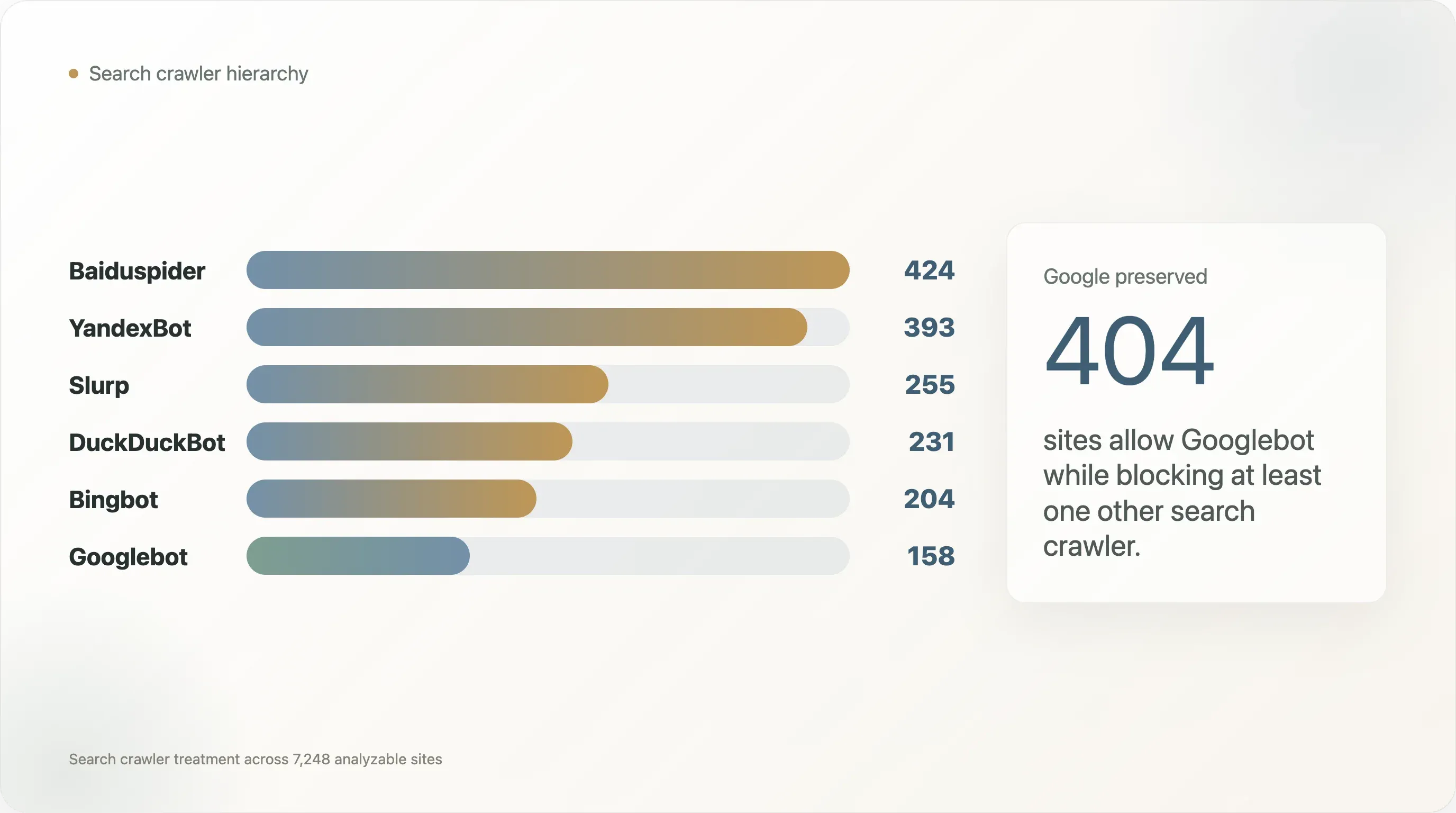
| Such-Crawler | Sites, die ihn blockieren |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot ist in dieser Gruppe der am seltensten blockierte Crawler. Baiduspider und YandexBot werden deutlich häufiger blockiert, und in den meisten dieser Fälle bleibt Googlebot erlaubt. Unter den 404 Sites, die Googlebot erlauben, aber einen anderen Such-Crawler blockieren, blockieren 269 Baiduspider und 240 YandexBot.
Die Beispiele sind prominent:
| Domain | Blockierte Such-Crawler, während Googlebot erlaubt ist |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Das ist für die KI-Debatte wichtig, weil es zeigt, dass robots.txt schon vor dem Auftreten von LLM-Crawlern kein neutrales Universal-Zugangsprotokoll war. Das öffentliche Web hatte bereits eine Hierarchie:
- Googlebot wird oft geschont, weil Googles Such-Traffic zu wertvoll ist, um ihn zu riskieren.
- Regionale oder konkurrierende Crawler lassen sich leichter blockieren.
- Manche Sites behandeln den Zugriff von Such-Crawlern als Entscheidung pro Markt oder pro Anbieter.
KI-Crawler kamen also in ein Ökosystem, in dem differenzierter Zugriff schon normal war.
Das macht den Policy-Wechsel leichter verständlich. Ein Publisher, der schreibt „Google-Extended blockieren, Googlebot erlauben“, erfindet keine neue Form von Diskriminierung. Er überträgt ein altes Muster auf eine neue Crawler-Klasse: Verteilung bewahren, Extraktion beschränken.
Die offene Frage ist, ob dieses alte Muster skaliert. Bei der Suche gab es nur eine Handvoll wirtschaftlich relevanter Crawler. Bei KI ist die Crawler-Identität fragmentiert über Modellanbieter, Retrieval-Bots, Datenbroker, akademische Crawler, synthetische Browser-Agenten und Fetcher auf Infrastrukturebene. Die Zahl benannter User-Agents wird weiter wachsen, solange das Ökosystem nicht auf eine kleinere Menge zweckbasierter Signale konsolidiert.
So wächst Konfigurationsschuld.
Befund 5: Die Komplexität variiert nach Sektor, aber nicht so wie die KI-Blockraten
Der ursprüngliche Bericht zeigte eine große sektorale Streuung beim KI-Blocking: News blockiert stark; Telekom, Regierung und SaaS blockieren wenig.
Konfigurationskomplexität schneidet das Web anders.
Unter ausgewählten Kategorien mit genügend lesbaren robots.txt-Dateien für einen brauchbaren Vergleich:
| Kategorie | n | Median-Bytes | P90-Bytes | Median Disallow | P90 Disallow | Median User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1.738 | 10.388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2.074 | 27.368 | 41 | 779 | 5 | 34 |
| news | 647 | 1.534 | 7.039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1.002 | 8.337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3.959 | 14 | 75 | 1 | 11 |
| government | 151 | 1.227 | 3.263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12.606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9.255 | 3 | 58 | 1 | 10 |
This paragraph contains content that cannot be parsed and has been skipped.
News ist politisch komplex, weil es explizite KI-Regeln und Rechtstexte schreibt. E-Commerce und Reisen sind dagegen operativ komplex, weil sie große Kataloge, facettierte Navigation, Suchergebnisseiten, Filter, User-Account-Pfade und parametrisierte URLs haben.
Dieser Unterschied ist wichtig.
Reisen ist das deutlichste Beispiel. In dieser Kategorie gibt es zwar nur 63 lesbare Dateien in diesem Ausschnitt, aber die P90-robots.txt ist 27,4 KB groß und die P90-Disallow-Anzahl liegt bei 779 — weit über News. Das heißt nicht, dass Reise-Sites eine fortschrittlichere KI-Policy haben. Es heißt, dass Reise-Sites mehr Oberflächen haben, auf denen Crawler-Betreiber versehentlich Budget verschwenden können: Datumssuchen, Verfügbarkeitsseiten, Review-Paginierung, Buchungsabläufe, Filterkombinationen und lokalisierte Bestands-Pfade.
SaaS ist die überraschende Gegenrichtung. Die Median-Datei ist nur 485 Byte groß, aber die P90-Datei springt auf 12,6 KB. Die meisten SaaS-Sites sind offen und leichtgewichtig; eine kleinere Gruppe trägt lange Pfadsteuerungsdateien, oft weil Dokumentation, Login-Oberflächen, App-Routen und Marketingseiten unter derselben Domain liegen.
News liegt operativ in der Mitte, politisch aber fast an der Spitze. Die P90-Anzahl der User-agent-Einträge beträgt 68 und liegt damit in dieser Tabelle über E-Commerce, Reisen, Finanzen, Wissenschaft, Regierung, SaaS und Dev Tools. Das ist ein Zeichen für bot-spezifische Policy, nicht nur für saubere Pfadpflege.
Die robots.txt eines Publishers kann wegen Rechtemanagement komplex sein. Die Datei eines Marktplatzes kann wegen Crawl-Budget-Management komplex sein. Die Datei einer Universität kann komplex sein, weil sich unter einer Domain Tausende Altpfade angesammelt haben. Die Datei einer Social-Plattform kann komplex sein, weil sie manche Oberflächen zeigen und andere in großem Maßstab unterdrücken muss.
KI-Policy kommt obendrauf. Sie ersetzt nicht die bestehenden Gründe für Komplexität.
Das hilft zu erklären, warum sich KI-Ära-robots.txt-Governance nicht mit einer universellen Blockliste lösen lässt. Die zugrunde liegenden Dateien haben unterschiedliche Aufgaben:
- E-Commerce-Sites verwalten doppelte Pfade und Inventar-Oberflächen;
- Reise-Sites verwalten Listings, Kalender, Reviews und dynamische Suchseiten;
- News-Sites verwalten Urheberrecht, Archive und Lizenzpositionen;
- SaaS- und Dev-Tooling-Sites wollen oft KI-Sichtbarkeit;
- Regierungen brauchen häufig öffentlichen Zugriff, müssen aber dennoch sensible Systeme ausschließen;
- Social-Plattformen verwalten nutzergenerierte Inhalte, Profil-Oberflächen und Missbrauchsschutz.
Dieselbe KI-Crawler-Regel bedeutet in jeder Umgebung etwas anderes.
Befund 6: Ein Configuration Debt Index zeigt Review-Risiko, nicht moralisches Versagen
Diese Analyse hat einen einfachen Configuration-Debt-Score erstellt, um robots.txt-Dateien zu identifizieren, die wahrscheinlich schwer zu prüfen sind.
Der Score gewichtet:
- Dateigröße;
- Anzahl der
User-agent-Direktiven; - Anzahl der
Disallow-Direktiven; - Anzahl der
Allow-Direktiven; - Anzahl der nicht zentralen Direktiven;
- Vorhandensein von KI-Policy-Sprache;
- Mischung aus explizitem KI-Blocking und juristischer oder Urheberrechtssprache.
Das ist kein Korrektheits-Score. Eine hochkomplexe Datei kann völlig absichtlich so aussehen. Eine wenig komplexe Datei kann trotzdem falsch sein. Der Punkt ist Triage: Wenn eine Datei groß, policy-lastig, bot-spezifisch und voller Ausnahmen ist, verdient sie strengere Review-Disziplin.
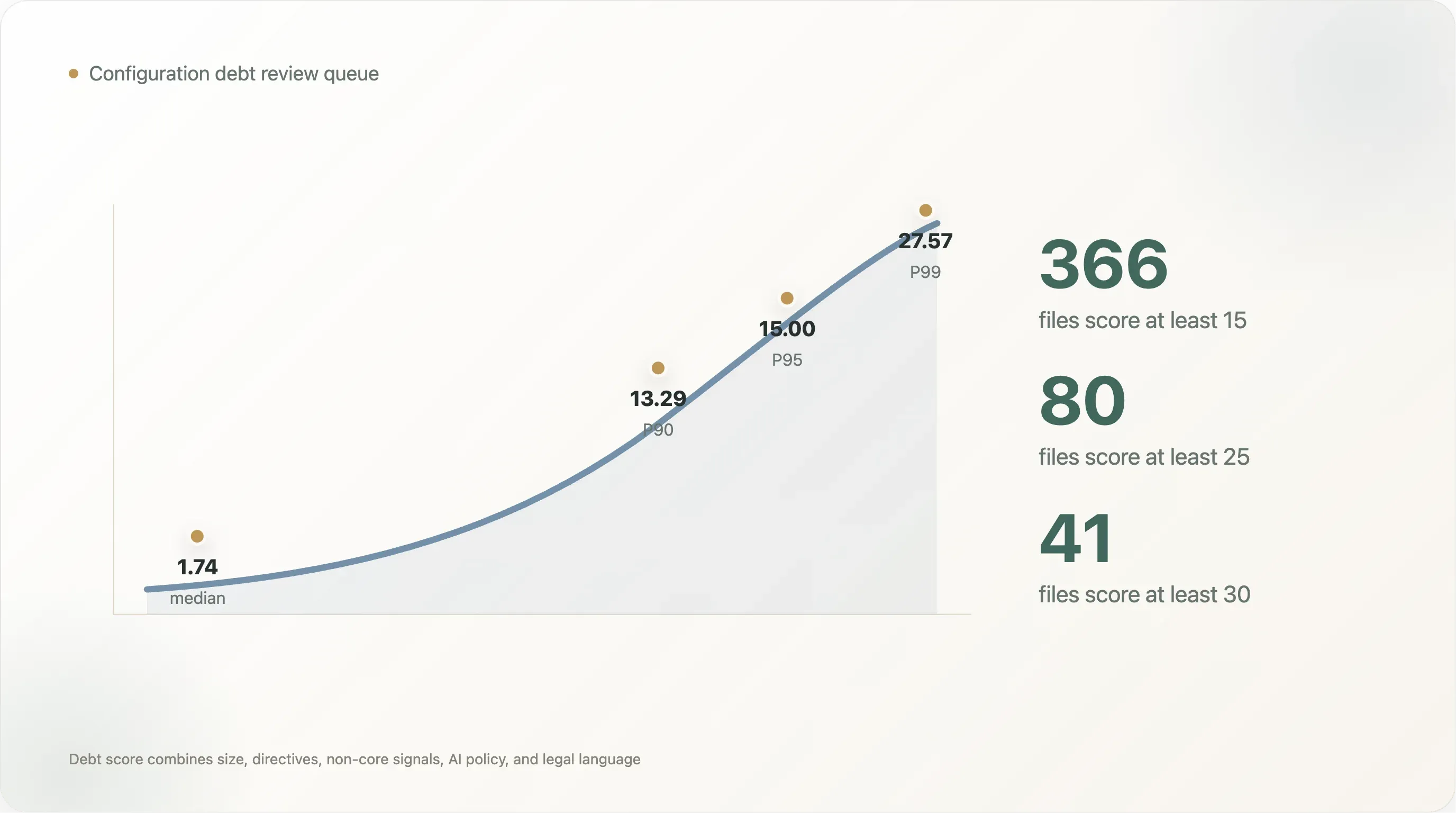
Die Verteilung des Scores ist steil. Die Median-Datei mit Lesbarkeit erzielt 1,74. Der P90 liegt bei 13,29, der P95 bei 15,00 und der P99 bei 27,57. Nur 366 Dateien erreichen mindestens 15, 80 erreichen mindestens 25 und 41 mindestens 30. Das ist die praktische Review-Queue: Nicht jede Site braucht ein Governance-Projekt, aber der obere Rand schon.
Auch die Kategorienansicht zeigt, warum ein einzelnes Label wie „AI-Blocker“ zu grob ist:
| Kategorie | Median-Score | P90-Score |
|---|---|---|
| travel | 4,92 | 28,94 |
| search | 2,97 | 24,23 |
| social | 2,25 | 15,00 |
| news | 4,91 | 14,92 |
| finance | 1,67 | 12,61 |
| SaaS | 0,98 | 11,85 |
| ecommerce | 3,88 | 10,87 |
| government | 1,57 | 6,38 |
Travel und Search haben die höchsten P90-Werte, weil eine Minderheit der Dateien sehr groß und regelintensiv wird. News hat einen der höchsten Median-Werte, weil Policy-Sprache und bot-spezifische Behandlung in der gesamten Kategorie häufiger sind. E-Commerce hat eine hohe mediane Disallow-Anzahl, aber einen niedrigeren P90-Score als Travel, weil sich die Komplexität stärker auf Pfadregeln als auf gemischte Policy-/Rechtssignale konzentriert.
Zu den höchstbewerteten Dateien in diesem Datensatz gehören:
| Domain | Warum der Score hoch ist |
|---|---|
linkedin.com | Sehr große Datei, Tausende Pfadregeln, viele benannte User-Agents, explizite KI-Policy-Sprache |
lnkd.in | Gleiche Policy-Oberfläche wie die Shortlink-Infrastruktur von LinkedIn |
fragrantica.com | Hunderte benannter User-Agent-Blöcke plus KI-Policy-Sprache |
sovcombank.ru | Hunderte User-Agent-Blöcke und juristische/Policy-Sprache |
academia.edu | Große Allow-/Disallow-Matrix und explizite KI-Blocking-Policy |
opentable.com | Großer Satz an Pfadregeln, viele Sitemap-Direktiven, KI-bezogene Policy-Oberfläche |
etsy.com | Große E-Commerce-Pfadsteuerungsdatei mit mehr als 1.600 Disallow-Regeln |
runescape.com | Fast 5.000 Disallow-Direktiven unter einer User-Agent-Gruppe |
Diese Dateien sollte man nicht dafür verspotten, dass sie komplex sind. Komplexität spiegelt oft echte Geschäftsanforderungen wider. Sie zeigen aber, warum robots.txt-Policy dieselbe technische Disziplin verdient wie andere Produktionskonfigurationen:
- Ownership sollte explizit sein;
- Änderungen sollten geprüft werden;
- generierte Abschnitte sollten gekennzeichnet sein;
- juristische Kommentare sollten möglichst von maschinellen Direktiven getrennt werden;
- Testfälle sollten das erwartete Bot-Verhalten für kritische Crawler absichern;
- Versionshistorien sollten erhalten bleiben;
- alte Bot-Namen sollten ausgemustert oder dokumentiert werden;
- KI-Training, KI-Retrieval, Suchindexierung und Archivierung sollten als getrennte Zwecke behandelt werden.
Der letzte Punkt ist der wichtigste. Die aktuelle Grammatik ist User-Agent-zentriert: Sie verlangt von Site-Betreibern, Bots zu benennen. Der Bedarf in der KI-Ära ist zweckzentriert: Er verlangt, dass Site-Betreiber sagen, welche Nutzungen erlaubt sind.
Das ist nicht dasselbe.
Diese Diskrepanz ist der Grund, warum längere Blocklisten nicht gut altern werden. Ein Publisher kann heute GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended und PerplexityBot hinzufügen, aber schon morgen kann der nächste Crawler-Name, Retrieval-Agent oder Datenbroker auftauchen. Eine zweckbasierte Policy würde es der Site erlauben zu sagen: „Suchindexierung ja, KI-Training nein, nutzerinitiierte Retrievals vielleicht“ — ohne robots.txt zu einem Adressbuch der Bots zu machen.
Was das für KI-Governance bedeutet
Die öffentliche Debatte stellt robots.txt oft entweder als wirksam oder als überholt dar. Die Daten sprechen für eine praktischere Antwort:
robots.txt ist wirksam, aber überladen.
Sie ist wirksam, weil große Sites sie nutzen, Crawler sie parsen können und Policy-Entscheidungen für Forschende, Journalisten, Anbieter und Gerichte sichtbar sind. Der ursprüngliche Bericht zeigte, dass 17,0 % der analysierbaren Top-Sites absichtliche KI-spezifische Regeln hatten. Das ist kein symbolisches Rauschen.
Sie ist überladen, weil die Datei inzwischen mehr ausdrücken muss als Bot-Zugriff:
- „Trainiere nicht mit diesen Inhalten.“
- „Du darfst diese Inhalte für die Suchindexierung nutzen.“
- „Du darfst diese Inhalte für Live-Retrieval nutzen.“
- „Du darfst keine gecachten Datensätze erstellen.“
- „Dieser juristische Vorbehalt gilt nach dem EU-Recht zu Text und Data Mining.“
- „Diese von einem CDN verwaltete Site sendet
Content-Signal: ai-train=no.“ - „Diese Site will Googlebot, aber nicht YandexBot.“
- „Diese Site hat 1.000 alte URL-Pfade, die nicht gecrawlt werden sollen.“
Die Grammatik wurde nicht für so viele Aufgaben entworfen.
Drei Änderungen würden die Schuld reduzieren:
-
Crawler-Identität braucht ein Register. Site-Betreiber sollten nicht eine immer längere Liste von
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Userund vielen weiteren pflegen müssen. Ohne Register hinkt die Policy immer dem Crawler-Verhalten hinterher. -
KI-Nutzung braucht strukturiertes Vokabular. Training, Retrieval, Indexierung, Zusammenfassung, Dataset-Weiterverkauf, Modellbewertung und nutzerinitiierter Browser-Zugriff sind unterschiedliche Nutzungen. Sie über anbieterspezifische User-Agent-Namen auszudrücken, ist fragil.
-
Policy braucht Prüfbarkeit. Das Web braucht eine Möglichkeit, zwischen selbst verfassten Rechtevorbehalten und geerbten CDN-Defaults, generierten CMS-Templates, veralteten Legacy-Regeln und versehentlichen Alles-erfassen-Blöcken zu unterscheiden. Dieser Unterschied ist für Vertrauen und für Streitfälle wichtig.
Nichts davon bedeutet, robots.txt über Nacht zu ersetzen. Der bessere Weg ist ein Schichtenmodell: robots.txt als Entdeckungs- und Kompatibilitätsebene beibehalten, aber eine angrenzende maschinenlesbare Policy für KI-spezifische Nutzungen standardisieren.
llms.txt ist ein Versuch in diese Richtung, aber die Verbreitung in diesem Datensatz ist noch sehr klein: Nur 83 lesbare Dateien erwähnen sie. Content-Signal ist sichtbarer, weil Cloudflare es über die Infrastruktur ausliefern kann, und alle 271 Content-Signal-Dateien in diesem Scan trafen zugleich auf KI-Policy-Sprache. Dennoch ist Verbreitung nicht dasselbe wie Konsens. Eine belastbare Lösung braucht wahrscheinlich die langweilige, aber notwendige Maschinerie der Standardisierung: klare Felder, klare Semantik, Crawler-Verpflichtungen und öffentliche Test-Suites.
Fazit
Der Streit um KI-Crawler hat robots.txt zu einem Governance-Artefakt gemacht. Das ist zugleich nützlich und riskant.
Nützlich, weil die Datei öffentlich ist. Forschende können sie prüfen. Publisher können sie ändern. Crawler können sie respektieren. Gerichte können sie lesen. Infrastruktur-Anbieter können sie im großen Maßstab ausrollen.
Riskant, weil sie zu viel tragen muss.
Die Median-robots.txt im Tranco Top 10K ist immer noch klein genug, um verstanden zu werden. Aber das lange Ende des stark frequentierten Webs ist voll mit großen, alten, mehrschichtigen, anbieterspezifischen und rechtlich aufgeladenen Dateien. Hunderte Sites betreiben inzwischen robots.txt-Konfigurationen, die besser als Produktions-Policy-Systeme denn als einfache Crawling-Hinweise verstanden werden.
Die zentrale Lehre ist nicht, dass robots.txt versagt hat. Sie ist, dass das Web sie befördert hat, ohne sie zu refaktorisieren.
Wenn KI-Zugriffsrichtlinien auf maschinenlesbaren öffentlichen Erklärungen beruhen sollen, ist der nächste Schritt keine weitere längere Blockliste. Es ist eine bessere Policy-Infrastruktur: zweckbasierte Berechtigungen, stabile Crawler-Identität, prüfbare Templates und Audit-Trails.
Bis dahin wird die KI-Governance-Schicht des öffentlichen Webs weiter auf einer Textdatei ruhen, die niemals dafür gedacht war, so viel zu tragen.
Hinweise zur Reproduzierbarkeit
Der Lieferordner enthält:
source_data/analysis.json— ursprüngliche aggregierte Metriken.source_data/site_meta.csv— ursprüngliche analytische Tabelle pro Site.source_data/bot_status.csv— ursprüngliche Policy-Tabelle Domain-gegen-Bot.source_data/fetch_meta.csv— ursprüngliche Fetch-Metadaten.source_data/sites.csv— ursprüngliche Tabelle Domain/Kategorie/Status.derived_data/robots_complexity_by_site.csv— pro Site generierte Komplexitätsmetriken für diesen Bericht.derived_data/search_bot_treatment.csv— Matrix zur Behandlung von Such-Crawlern.derived_data/category_complexity_summary.csv— Zusammenfassung der Komplexität auf Kategorieebene.derived_data/top_config_debt_sites.csv— Top-Sites nach dem oben beschriebenen Triage-Score.derived_data/summary_metrics.json— alle in diesem Bericht zitierten Headline-Metriken.
Methodik-Korrekturen, Datenprobleme und Folgeanalysen sind willkommen unter support@thunderbit.com. Dieser Bericht erscheint unabhängig von jeder kommerziellen Position, die Thunderbit hat; wir bauen einen KI-gestützten Web-Scraper, und wir haben ein strukturelles Interesse daran, dass robots.txt auf dem öffentlichen Web ein bedeutender, maschinenlesbarer Vertrag bleibt. Die Daten in diesem Bericht stehen für sich. — Das Thunderbit-Forschungsteam, Mai 2026.