GitHub zeigt derzeit mehr als . Klingt erst mal wie ein Buffet. Der Haken: Nur etwa 28 % davon haben in den letzten zwölf Monaten überhaupt noch Aktivität gezeigt. Ich habe die letzten Wochen damit verbracht, diese Repos durchzugehen, Endpunkte zu testen, Issue-Queues zu lesen und Reddit-eigene Richtlinien-Updates abzugleichen. Das Ziel: dich davor zu bewahren, ein Repo zu klonen, mit OAuth zu kämpfen und erst um Mitternacht festzustellen, dass alles schon 2024 still und heimlich kaputtging. Die Reddit-Scraper-GitHub-Landschaft im Jahr 2026 ist ein Friedhof guter Absichten, gemischt mit einer Handvoll wirklich brauchbarer Tools. Dieser Leitfaden zeigt, was noch funktioniert, was kaputt ist, wann du Code lieber ganz überspringst und wie du auf der sicheren Seite von Reddits immer strengerer Durchsetzung bleibst. Wenn du eine Abkürzung suchst, ist die No-Code-Option, die wir genau für solche Probleme gebaut haben – aber ich sage auch ehrlich, wo codebasierte Lösungen weiterhin sinnvoller sind.
Was ist ein Reddit-Scraper-GitHub-Repo – und warum sind so viele kaputt?
Ein „reddit scraper github“-Repo ist meist ein Open-Source-Python-Projekt, manchmal auch in JavaScript, das das Abrufen von Posts, Kommentaren, Nutzerdaten oder Medien von Reddit automatisiert. Meist lassen sie sich in vier Gruppen einteilen:
- API-Wrapper (wie PRAW): nutzen Reddits offizielle API, brauchen OAuth und halten sich an Reddits Regeln.
- Pushshift-/PSAW-basierte Tools: griffen früher auf das riesige Reddit-Archiv von Pushshift zu, um historische Daten zu holen.
- Scraper für öffentliche
.json-Endpunkte: hängen.jsonan Reddit-URLs an oder rufen öffentliche Endpunkte ohne Authentifizierung ab. - Browserbasierte Scraper: verwenden Playwright, Selenium oder Browser-Erweiterungen, um Reddit-Seiten zu laden und gerenderten Inhalt auszulesen.
Warum sind so viele davon kaputtgegangen? Drei Gründe.
- Reddits API-Preisänderung Mitte 2023. Die kostenlosen API-Limits sanken auf . Höherer kommerzieller Einsatz kostet jetzt 0,24 $ pro 1.000 API-Aufrufe. Viele Repos wurden für eine Welt gebaut, in der API-Zugang im Grunde unbegrenzt war – und diese Welt ist vorbei.
- Der öffentliche Zugriff auf Pushshift wurde entzogen. Pushshift war das Rückgrat für historische Reddit-Forschung. Nachdem Reddit den Zugriff einschränkte, verlor ein großer Teil der „historischen Scraper“-Repos ihre wichtigste Datenquelle. Manche READMEs lassen diese Tools noch lebendig aussehen, aber die Abhängigkeit darunter ist für normale Nutzer weg.
- Reddit hat sowohl Richtlinien als auch Durchsetzung verschärft. Das robots.txt-Update von 2024, die von 2025 und die vom März 2026 zeigen klar: Reddit betrachtet Massen-Scraping nicht mehr als harmloses Hintergrundrauschen. Sie haben sogar .
Unterm Strich: Suche nach „reddit scraper github“ und du bekommst Hunderte Treffer. Das Datum des letzten Commits und die Zahl offener Issues erzählen oft eine ganz andere Geschichte.
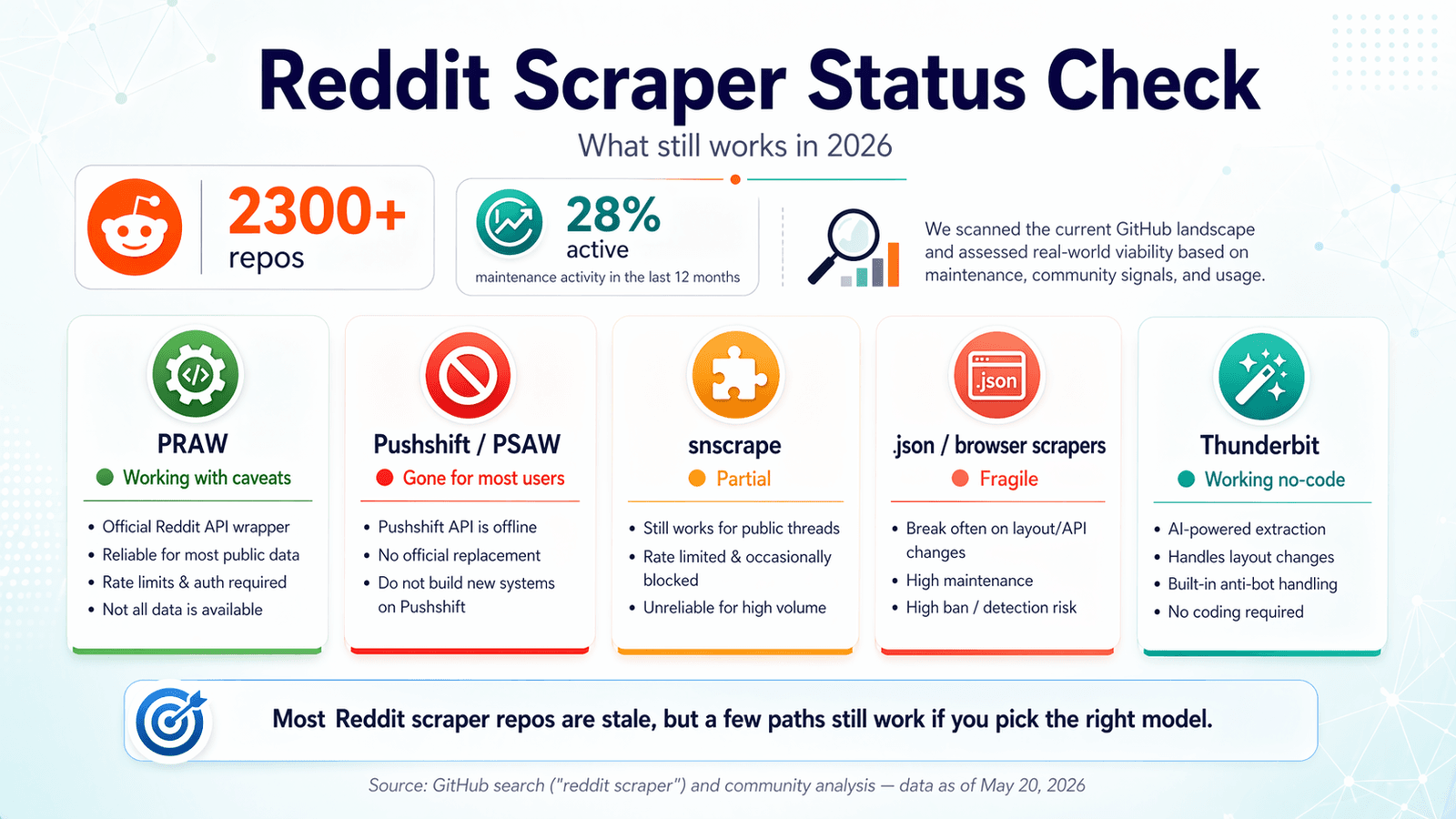
Der Reddit-Scraper-GitHub-Statuscheck 2026: Was noch funktioniert
Die meisten Vergleichsartikel wurden 2023 oder 2024 geschrieben und nie aktualisiert. In Foren melden Nutzer immer wieder Fehler mit Repos, die vor einem Jahr noch funktionierten – ein Hilferuf wie „Immer wieder Reddit-API-Limitierungsfehler :\ Wie komme ich da vorbei?“ ist im Grunde das Reddit-Scraper-Erlebnis 2026 in einem Satz.
Ich habe einen Aktualitäts-Check durchgeführt, Stand April 2026. Das habe ich gefunden.
PRAW: Der offizielle Python-Wrapper
Status: ✅ Funktioniert noch, mit Einschränkungen.
(Python Reddit API Wrapper) bleibt die verlässlichste Open-Source-Basis für Reddit-Scraping. Es wird aktiv gepflegt – 4.099 Sterne, zuletzt gepusht am 20. April 2026, nur 6 offene Issues, und (veröffentlicht im Oktober 2024).
Stärken: Offiziell, gut dokumentiert, abstrahiert den Großteil der API-Komplexität von Reddit.
Einschränkungen 2026:
- Strengere OAuth-Anforderungen. Du brauchst eine registrierte Reddit-App mit genehmigter Beschreibung des Anwendungsfalls.
- Niedrigere Rate Limits seit 2024 (100 Abfragen/Minute mit OAuth, 10 ohne).
- Das harte Listenlimit von ca. 1.000 Posts bleibt bestehen. Community-Threads auf r/redditdev und Stack Overflow bestätigen: pro Listing-Endpunkt abzurufen.
PRAW ist die sicherste Wahl, wenn du innerhalb des API-Rahmens bleiben kannst.
Es ist nur kein frei formulierter Massen-Scraper mehr.
Wenn du einen praktischen Einstieg in den offiziellen API-Weg suchst, passt dieses Tutorial gut zu diesem Abschnitt:
Pushshift / PSAW: Das Archiv, das dunkel wurde
Status: ❌ Öffentlicher Zugriff weg.
war der bevorzugte Python-Wrapper für Pushshift, also früher der einfachste Weg zu historischen Reddit-Daten. 2026 ist das Repo archiviert, die README sagt wörtlich „THIS REPOSITORY IS STALE“, und aktuelle offene Issues tragen Perlen wie „Pushshift.io UNABLE to connect“ und „The code not working. Possibly due to pushshift api.“
Akademischer Zugriff kann über bestimmte Kanäle noch existieren, aber für alle, die heute nach „reddit scraper github“ suchen, ist Pushshift/PSAW keine praktikable Option. Wenn du tiefe historische Reddit-Daten brauchst, musst du dir genehmigten akademischen Datenzugang oder lizenzierte Wege ansehen.
snscrape (Reddit-Modul): Teilweise und unzuverlässig
Status: ⚠️ Teilweise – gelegentliche Ausfälle, weitgehend ungewartet.
hat 5.337 Sterne, aber der letzte Push war am 15. November 2023. In der README steht weiterhin, dass Reddit-Scraping „via Pushshift“ unterstützt wird. Offene Reddit-bezogene Issues enthalten „Error reddit scraping“ und „Reddit scraper returns no submissions before 2022-11-03“, ohne nennenswerte jüngere Reparaturaktivität.
Für kleine, einmalige Abrufe kann es in manchen Umgebungen noch funktionieren, aber für Produktion oder regelmäßige Scrapes ist es nicht zuverlässig. Behandle es als Legacy.
Playwright und .json-Endpunkt-Scraper: Der Workaround, der funktioniert – manchmal
Status: ✅ Funktioniert, aber fragil.
Die Idee ist simpel: Einen Headless-Browser (Playwright, Puppeteer) verwenden, um Reddit-Seiten zu laden und gerenderten Inhalt zu scrapen, oder .json an Reddit-URLs anhängen, um strukturierte Daten ohne offizielle API zu bekommen.
Stärken: Kein API-Key nötig, kann das 1k-Post-Limit umgehen, Zugriff auf gerenderten Inhalt.
Schwächen: Bricht, wenn Reddit sein Frontend-Layout oder die JSON-Struktur ändert, kann Anti-Bot-Maßnahmen auslösen und erfordert mehr technisches Setup. In meinen eigenen Tests in diesem Monat lieferten direkte Anfragen an öffentliche Reddit-.json-Endpunkte 403-Antworten. Das heißt nicht, dass jede Umgebung blockiert wird, aber es heißt sehr wohl, dass man bei diesem .json-Shortcut nicht mehr davon ausgehen sollte, dass er „einfach so“ funktioniert.
Repos wie sind dabei angenehm ehrlich: In der README wird empfohlen, „Use with rotating proxies, or Reddit might gift you with an IP ban.“ Genau das ist im Grunde die Geschichte vom April 2026 in einem Satz.
Wenn du den Browser-Automations-Workaround bewertest, ist dieses Playwright-Tutorial ein starker Begleiter zum nächsten Abschnitt:
Thunderbit: KI-gestütztes Browser-Scraping (kein Code, kein API-Key)
Status: ✅ Funktioniert – passt sich Seitenänderungen automatisch an.
verfolgt einen grundlegend anderen Ansatz. Es ist eine , die KI nutzt, um Reddit-Seiten zu lesen, Datenfelder vorzuschlagen (Post-Titel, Autor, Upvotes, Zeitstempel, URL usw.) und strukturierte Daten mit zwei Klicks zu extrahieren. Kein OAuth-Setup, keine API-Key-Registrierung, keine Python-Umgebung, kein Dependency-Management. Die KI liest die Seite jedes Mal frisch, sodass Thunderbit sich automatisch anpasst, wenn Reddit sein Layout ändert, statt still und heimlich zu brechen.
Kostenloser Export nach CSV, Google Sheets, Airtable oder Notion. Unterstützt Pagination und das Scraping von Unterseiten (z. B. zuerst eine Subreddit-Liste scrapen und dann jeden Post besuchen, um Kommentare zu ziehen). Für alle, die Reddit-Daten wollen, ohne ein GitHub-Repo zu pflegen, ist das der Weg mit dem geringsten Widerstand.
(Vollständige Offenlegung: Wir haben Thunderbit gebaut, also bin ich nicht neutral – aber ich sage später im Artikel klar, wo codebasierte Lösungen weiterhin mehr Sinn ergeben.)
Statusübersicht im direkten Vergleich
| Tool / Kategorie | Funktioniert noch (April 2026)? | API-Key nötig? | Hinweise |
|---|---|---|---|
| PRAW | ✅ Ja, mit Einschränkungen | Ja (OAuth) | Am besten gewartete Open-Source-Basis. Begrenzung durch Rate Limits und 1k-Post-Cap. |
| Pushshift / PSAW | ❌ Nein (für die meisten Nutzer) | N/A | Öffentlicher Zugriff weg. Repo archiviert. |
| snscrape (Reddit-Modul) | ⚠️ Teilweise / unzuverlässig | Nein | Dokumentiert Reddit weiterhin „via Pushshift“. Wartung seit 2023 ins Stocken geraten. |
| .json / öffentliche Endpunkt-Scraper | ⚠️ Teilweise | Nein | Kann funktionieren, aber direkte Anfragen werden zunehmend blockiert. Hängt von Proxies ab. |
| Playwright / Browser-Scraper | ✅ Ja, aber fragil | Meist nein | Der praktikabelste No-API-Do-it-yourself-Workaround. Seitenänderungen und Anti-Bot-Prüfungen bleiben relevant. |
| Thunderbit | ✅ Ja | Nein | KI-/Browser-Workflow. Kein OAuth, keine Selektoren. Am besten für Nicht-Entwickler geeignet. |
Rate Limits, das 1k-Post-Limit und was wirklich hilft
Das ist der größte Schmerzpunkt für alle, die ein reddit scraper github-Projekt nutzen. Foren-Threads sind voller Frust: „müde davon, dass Runs mitten drin wegen Rate Limits sterben“, „Warum bekomme ich nur etwa 1.000 Einträge?“ Die beiden Kernbeschränkungen sind Reddits API-Rate-Limits (Anfragen pro Minute) und das Listenlimit von etwa 1.000 Posts (die API gibt pro Listing-Endpunkt nur die neuesten rund 1.000 Posts zurück).
Best Practices für das Rate-Limit-Management
Reddits aktueller öffentlicher Richtwert: . So gehst du in der Praxis damit um:
- Exponential Backoff. Wenn du eine Rate-Limit-Antwort bekommst, warte und versuche es jedes Mal nach einer längeren Pause erneut (1 s, 2 s, 4 s, 8 s …). Den Endpunkt nicht einfach dauernd beschießen.
X-Ratelimit-Remaining-Header lesen. Die API-Antworten von Reddit enthalten Header, die dir sagen, wie viele Anfragen noch übrig sind und wann das Zeitfenster zurückgesetzt wird. Steuere deine Requests auf Basis dieser Werte, nicht nach Bauchgefühl.- Rotierende User-Agents. Manche Repos empfehlen das, um Erkennung zu vermeiden. Das kann helfen, aber nutze es ethisch – nicht, um Sperren zu umgehen, die du dir verdient hast.
- Alles loggen. Füge Logging für API-Antworten, Rate-Limit-Header und Fehler hinzu. Wenn dein Scraper um 2 Uhr morgens stirbt, sind Logs dein bester Freund.
Das 1.000-Post-Limit umgehen
Der glaubwürdigste Workaround für das ca. 1.000-Item-Listenlimit der API ist Zeitfenster-Segmentierung:
- Einen Zeitabschnitt mit
before- undafter-Zeitstempelparametern abfragen. - Das Fenster vorwärts (oder rückwärts) verschieben.
- Wiederholen.
- Nach Post-ID deduplizieren.
Das ist nicht elegant, aber ehrlicher als so zu tun, als könne eine einzige Request-Schleife beliebige Historie aus einem Listing-Endpunkt ziehen. Für wirklich historische Daten brauchst du genehmigten akademischen Zugriff oder einen lizenzierten Weg – Pushshift ist nicht mehr die Standardantwort.
Browserbasiertes Scraping (Playwright oder Thunderbit) umgeht dieses Limit vollständig, weil es das scrapt, was auf der Seite gerendert wird, nicht das, was die API zurückgibt. Mit Thunderbits Pagination-Funktion kannst du dich durch Seiten klicken und Daten über so viele Seiten sammeln, wie du brauchst.
Deduplizierung und Fehlerwiederaufnahme
Die meisten reddit scraper github-Repos haben Deduplizierung oder Fehlerwiederaufnahme nicht von Haus aus drin. Nutzer beschweren sich ausdrücklich, dass „keine Deduplizierung, keine Rate-Limit-Vermeidung nach Fehlern, keine Prüfung, ob Dateien bereits heruntergeladen sind“ vorhanden sei. So gehst du vor:
- Deduplizierung: Hashe die ID jedes Posts (oder ID + Inhalt). Speichere bereits gesehene Hashes in einer einfachen SQLite-Datenbank oder sogar in einer flachen Datei. Vor dem Einfügen prüfen, ob der Hash schon existiert. Besonders wichtig ist das beim Segmentieren von Zeitfenstern oder beim erneuten Starten fehlgeschlagener Jobs.
- Fehlerwiederaufnahme: Speichere den Fortschritt nach jeweils N Datensätzen in einer Checkpoint-Datei. Wenn der Lauf fehlschlägt, starte vom letzten Checkpoint statt ganz von vorn. So wird aus einem 3-Stunden-Job, der nach 2 Stunden abstürzt, ein 1-stündiger Fortsetzungs-Job.
Wie die verschiedenen Ansätze mit diesen Einschränkungen umgehen

| Ansatz | Umgang mit Rate Limits | >1k Posts? | Auto-Dedupe? | Fehlerwiederaufnahme? |
|---|---|---|---|---|
| PRAW (roh) | Manuell (sleep/retry) | ❌ (API-Cap) | ❌ | ❌ |
| PRAW + Zeitfenster-Segmentierung | Manuell | ✅ (Workaround) | ❌ | ❌ (außer du baust es ein) |
| Playwright-.json-Scraping | N/A (keine API) | ✅ | ❌ | ❌ |
| Thunderbit (Browser-Scraping) | Integriert (KI-Taktung) | ✅ (Pagination) | N/A (visuelle Prüfung) | Integriert |
Wann ein Reddit-Scraper-GitHub-Repo nicht die Antwort ist: Der No-Code-Weg
Die meisten reddit scraper github-Artikel setzen Python-Kenntnisse voraus. Aber viele der Menschen, die nach Reddit-Scraping-Lösungen suchen, sind Marketer, Sales-Teams, Forscher oder Indie-Gründer, die nicht täglich Python schreiben. Für diese Zielgruppe bringt ein GitHub-Repo versteckte Kosten mit sich:
- Einrichten von OAuth-Anmeldedaten und einer Reddit-Developer-App
- Verwalten von Python-virtuellen Umgebungen und Abhängigkeitskonflikten
- Debuggen kryptischer Fehlermeldungen, wenn sich PRAW intern ändert
- Umgang mit dem Widerruf von API-Keys, falls Reddit deinen Anwendungsfall nicht genehmigt
- Pflege des Skripts bei jeder Änderung auf Reddit
Das ist nicht hypothetisch. hat 2.563 Sterne und 107 offene Issues. Aktuelle Berichte sprechen von „Struggling to install“, „PRAW module error“ und „Exception not allowing to even authenticate.“
Nimm ein GitHub-Repo, wenn …
- du individuelle Scraping-Logik brauchst (z. B. spezielle Traversierung von Kommentarbäumen, Integration in eine eigene NLP-Pipeline).
- du in eine bestehende Python-Datenpipeline integrieren willst.
- du in sehr großem Maßstab mit eigener Speicherung scrapen musst (Datenbank, Data Warehouse).
- du dich mit Codepflege und Breaking Changes auskennst.
Nimm ein No-Code-Tool, wenn …
- du Reddit-Daten schnell brauchst – in Minuten statt nach stundenlangem Setup.
- du keine API-Keys, OAuth-Apps oder Python-Umgebungen verwalten willst.
- du direkt in Tabellen, Notion oder Airtable exportieren möchtest, um sofort weiterzuarbeiten.
- du möchtest, dass sich das Tool automatisch anpasst, wenn Reddit sein Layout ändert.
Thunderbit passt genau in die No-Code-Schiene. Nutzer können – mit KI-vorgeschlagenen Feldern, Export gratis nach CSV/Google Sheets/Airtable/Notion und Pagination ohne Code. Das browserbasierte Scraping bedeutet kein OAuth-Setup und keine API-Key-Registrierung.
Kurzanleitung: Reddit mit Thunderbit scrapen, Schritt für Schritt
- Installiere die .
- Öffne die Reddit-Seite, die du scrapen möchtest (Subreddit, Suchergebnisse, Nutzerprofil).
- Klicke auf „KI-Felder vorschlagen“. Thunderbit liest die Seite und schlägt Spalten vor – Post-Titel, Autor, Upvotes, Zeitstempel, URL usw.
- Passe die Felder bei Bedarf an und klicke dann auf „Scrapen“.
- Prüfe die Datentabelle. Optional kannst du auf „Unterseiten scrapen“ klicken, um jeden Post zu besuchen und Kommentare oder zusätzliche Details zu holen.
- Exportiere an dein bevorzugtes Ziel: Google Sheets, Excel, Airtable, Notion, CSV oder JSON.
Zwei Minuten. Null Codezeilen. Wenn du es in Aktion sehen willst, schau dir den an.
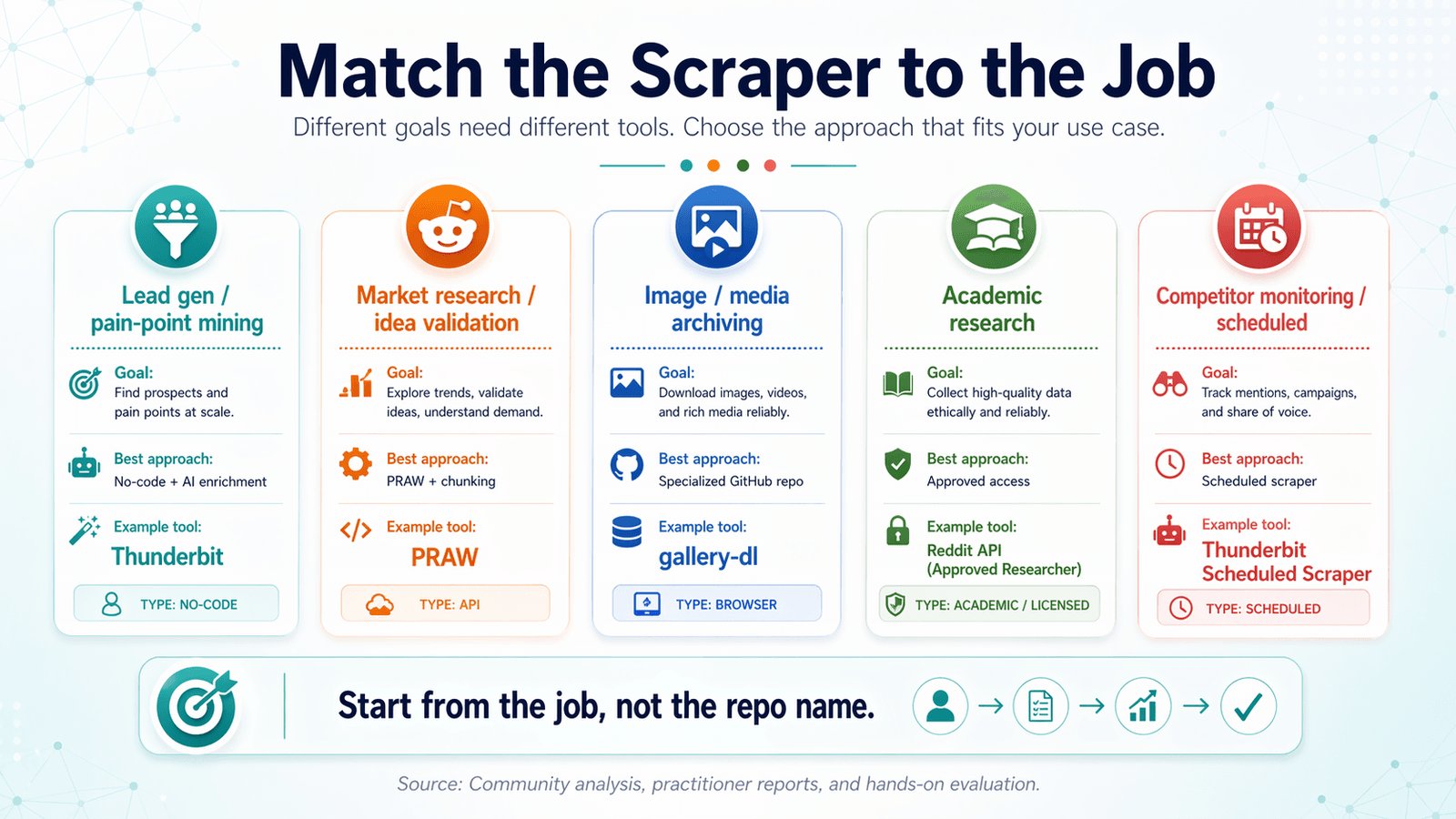
Den Reddit-Scraper an den Job anpassen: eine Matrix zur Anwendungsfall-Entscheidung
Die meisten reddit scraper github-Artikel ordnen nach Tool. Das ist rückwärts.
Starte mit deinem Ziel und arbeite dich dann zum passenden Tool zurück.
Lead-Generierung und Pain-Point-Recherche
Was du brauchst: Posts + Kommentare mit Keyword-Filterung, KI-Tagging/Labeling, Export in CRM-taugliche Formate.
Bester Ansatz: No-Code-Scraper mit KI-Anreicherung.
Empfohlenes Tool: (KI-Labeling + Export nach Google Sheets/Airtable für den CRM-Import).
Beispiel-Workflow: Ein Subreddit nach Posts scrapen, die einen bestimmten Schmerzpunkt erwähnen. Mit Thunderbits Field AI Prompt Sentiment kategorisieren oder Themen taggen. Dann in das Airtable oder Google Sheet deines Sales-Teams exportieren.
Marktforschung und Ideenvalidierung
Was du brauchst: Viele Post-Titel + Scores, Trenddaten auf Subreddit-Ebene.
Bester Ansatz: PRAW mit Zeitfenster-Segmentierung für Volumen, oder Thunderbit für schnelle Abrufe.
Beispiel: r/SaaS oder r/startups nach Trendthemen und Upvote-Mustern der letzten 90 Tage scrapen.
Archivierung von Bildern und Medien
Was du brauchst: Medien-URLs, Deduplizierung, geplante Läufe.
Bester Ansatz: Spezielles GitHub-Repo (z. B. ) + Cron-Job.
Hinweis: Deduplizierung ist hier wichtig – dass dasselbe Bild in mehreren Subreddits gepostet wird, kommt häufig vor.
Akademische Forschung und historische Daten
Was du brauchst: Historische Daten, vollständige Kommentarbäume, große Datensätze.
Bester Ansatz: Genehmigter akademischer Zugriff oder ein lizenzierter Datenpfad. Pushshift ist nicht mehr die allgemeine Antwort.
Realitätscheck: Das ist 2026 der schwierigste Anwendungsfall wegen Pushshift-Beschränkungen und Reddits verschärften Datenrichtlinien.
Wettbewerbsbeobachtung und geplantes Scraping
Was du brauchst: Wiederkehrende Scrapes in festen Intervallen, Änderungserkennung.
Bester Ansatz: Thunderbits (Zeitintervall in normalem Englisch beschreiben, URLs eingeben, auf „Planen“ klicken) oder Cron + Skript für codebasierte Nutzer.
Matrix zur Anwendungsfall-Entscheidung
| Anwendungsfall | Was du brauchst | Bester Ansatz | Beispiel-Tool |
|---|---|---|---|
| Lead-Gen / Pain-Point-Recherche | Posts + Kommentare, Keyword-Filterung, KI-Tagging | No-Code-Scraper + KI-Anreicherung | Thunderbit |
| Marktforschung / Ideenvalidierung | Viele Post-Titel + Scores, Daten auf Subreddit-Ebene | PRAW + Zeitfenster-Segmentierung oder Thunderbit | PRAW oder Thunderbit |
| Archivierung von Bildern/Medien | Medien-URLs, Dedupe, geplante Läufe | Spezielles GitHub-Repo + Cron | bulk-downloader-for-reddit |
| Akademische Forschung | Historische Daten, vollständige Kommentarbäume | Genehmigter akademischer Zugriff oder Playwright | Pushshift Academic API (falls zugänglich) |
| Wettbewerbsbeobachtung / geplant | Wiederkehrende Scrapes, Änderungserkennung | Geplanter Scraper | Thunderbit Scheduled Scraper oder Cron + Skript |
So bewertest du jedes Reddit-Scraper-GitHub-Repo, bevor du dich festlegst
Bevor du ein Repo klonst und mit dem Debugging beginnst, mach diesen 5-Minuten-Check. Er spart dir Stunden.
Der 5-Minuten-Repo-Health-Check
- Datum des letzten Commits. Liegt es mehr als 6 Monate zurück, sei vorsichtig. Reddits API ändert sich häufig.
- Verhältnis offener zu geschlossenen Issues. Viele unbeantwortete Issues sind ein Warnsignal. Prüfe, ob in aktuellen Issues von Auth-Fehlern, 403s oder Pushshift-Ausfällen die Rede ist.
- LICENSE-Datei. Prüfe, ob es eine gibt. Keine Lizenz = rechtlich unklar (mehr dazu weiter unten).
- Abhängigkeiten. Sind die benötigten Bibliotheken aktuell? Nutzt das Projekt veraltete Pakete? Eine
requirements.txtvoller fest verdrahteter Versionen von 2022 ist ein Warnzeichen. - Qualität der README. Erklärt sie das Setup klar? Gibt es Nutzungsbeispiele? Schlechte Doku = mehr Debugging für dich.
- Sterne vs. Forks vs. aktuelle Aktivität. Viele Sterne, aber wenig jüngere Aktivität können heißen: Das Projekt war mal beliebt, ist aber jetzt aufgegeben. Vergleiche Sterne mit dem
pushed_at-Datum.
Ein kurzes Beispiel: hat 364 Sterne – wirkt auf den ersten Blick glaubwürdig. Aber das Repo ist archiviert und die README sagt: „THIS REPOSITORY IS STALE.“
Sterne allein erzählen nicht die ganze Geschichte.
Tipps, um das Maximum aus deinem Reddit-Scraper-GitHub-Setup herauszuholen
Wenn du dich doch für den Code-Weg entscheidest, so sparst du dir Ärger.
Immer eine virtuelle Umgebung verwenden
Eine virtuelle Umgebung hält die Abhängigkeiten deines Scrapers isoliert, damit sie nicht mit anderen Python-Projekten kollidieren. Ein Befehl: python -m venv venv und dann vor der Installation alles aktivieren. Das ist Grundhygiene, aber ich habe genug GitHub-Issues mit dem Titel „module not found“ gesehen, um zu wissen, dass man es ruhig wiederholen darf.
Anmeldedaten sicher speichern
Speichere deine Reddit-API-Client-ID oder dein Secret niemals fest im Skript. Nutze Umgebungsvariablen oder eine .env-Datei und füge .env zu .gitignore hinzu. Wenn du Anmeldedaten versehentlich zu GitHub pushst, drehe sie sofort neu – Bots scannen nach offengelegten API-Keys.
Alles loggen
Füge Logging für API-Antworten, Rate-Limit-Header und Fehler hinzu. Wenn etwas bricht, ist Logging der Unterschied zwischen „Ich weiß genau, was passiert ist“ und „Ich habe keine Ahnung, warum es aufgehört hat.“
Geplant und automatisiert, aber mit Augenmaß
Wenn du wiederkehrende Scrapes laufen lässt, nutze Cron (Linux/Mac) oder Task Scheduler (Windows) – aber überwache Fehler. Ein Cron-Job, der zwei Wochen lang still scheitert, ist schlimmer als gar keine Automatisierung.
Alternative: Mit Thunderbits beschreibst du das Intervall in normalem Englisch, ohne Cron-Syntax.
Rechtliche und ethische Best Practices für Reddit-Scraping
Das ist kein Wegwerf-Hinweis. Reddit setzt seine Bedingungen seit den API-Änderungen 2023 aggressiv durch, und das Scraping personenbezogener Daten birgt reale rechtliche Risiken.
Worauf es wirklich ankommt:
Reddits Nutzungsbedingungen: Was dort tatsächlich steht
Reddits (überarbeitet bis 31. März 2026) verbietet ausdrücklich den automatisierten Zugriff auf, das Durchsuchen oder das Sammeln von Daten aus den Diensten, sofern dies nicht durch die Bedingungen oder eine separate Vereinbarung erlaubt ist. Die und werden noch konkreter: Reddit darf die Nutzung durch Entwickler überwachen und prüfen, Zugänge ändern oder einstellen und bei übermäßiger oder missbräuchlicher Nutzung dauerhaft sperren. Kommerzielle Nutzung erfordert in der Regel eine ausdrückliche Genehmigung.
Die vom März 2026 geht noch weiter: Vor dem Zugriff auf Reddit-Daten über die API ist eine Genehmigung erforderlich, nicht genehmigte Monetarisierung sowie KI-/Data-Mining-Nutzung sind verboten, und die Durchsetzung kann das Widerrufen von Tokens, das Sperren von Apps oder Konten sowie das Sperren zugehöriger Bots oder Domains umfassen.
Einhaltung von robots.txt
Reddits aktuelle ist ungewöhnlich restriktiv:
1User-agent: *
2Disallow: /Das ist ein pauschales Verbot für alle automatisierten User-Agents. Sie verweist außerdem auf die . Das ist deutlich strenger als die großzügigen robots.txt-Muster, die manche Entwickler noch aus älteren Web-Scraping-Normen kennen.
Best Practice: Vor dem Scrapen immer robots.txt prüfen, auch wenn dein Tool das nicht automatisch erzwingt.
Personenbezogene Daten und Privatsphäre (DSGVO/CCPA)
Wenn du Nutzernamen, Post-Historien oder sonstige personenbezogene Daten scrapest, können (EU) und CCPA (Kalifornien) relevant sein. Best Practice: Personenbezogene Daten vor der Speicherung anonymisieren oder aggregieren. Keine Profile einzelner Nutzer ohne rechtliche Grundlage aufbauen.
Lizenzierung von GitHub-Repos: Erst prüfen, dann bauen
Viele reddit scraper github-Repos nutzen MIT- oder Apache-Lizenzen (großzügig), aber manche haben gar keine LICENSE-Datei – rechtlich bedeutet das „alle Rechte vorbehalten“. Bevor du ein Repo forkst, modifizierst oder darauf aufbaust, prüfe immer die LICENSE-Datei. Keine Lizenz = rechtlich unklar, egal wie viele Sterne es hat.
Durchsetzung ist 2025–2026 real
Reddits Durchsetzung hörte 2023 nicht auf. Reddit reichte 2025 eine Beschwerde gegen Anthropic ein und warf unautorisiertes Scraping/Nutzen von Reddit-Inhalten vor, und ging Ende 2025 auch gegen Reddit v. SerpApi vor. Das sind klare Zeichen dafür, dass Reddit bereit ist, rechtlich durchzugreifen, nicht nur technisch zu blockieren.
Die richtige Reddit-Scraper-GitHub-Strategie 2026 wählen
Die Reddit-Scraper-GitHub-Landschaft hat sich seit 2023 dramatisch verändert. Die meisten Repos sind veraltet. Rate Limits und das 1k-Post-Cap sind echte Grenzen. Pushshift ist für normale Nutzer weg. Und Reddits Richtlinienpaket ist expliziter und stärker durchgesetzt als je zuvor.
Die Kurzfassung:
- PRAW ist weiterhin die zuverlässigste Open-Source-Basis, wenn du Reddits API-Limits akzeptieren kannst und eigene Logik bauen willst.
- Pushshift/PSAW ist nicht mehr die allgemeine Antwort.
- snscrapes Reddit-Modul ist Legacy und unzuverlässig.
.json- und Public-Endpunkt-Scraper sind fragil und 2026 oft blockiert.- Browserbasierte Tools – ob Playwright-Repos oder No-Code-Optionen wie – sind für viele Nutzer der praktischste Weg, besonders für Nicht-Entwickler.
Starte mit deinem Anwendungsfall, nicht mit dem Tool. Mach vor jedem GitHub-Projekt den 5-Minuten-Repo-Health-Check.
Und wenn du das Setup lieber überspringen und in wenigen Minuten mit Reddit-Scraping starten willst, .
FAQs
Was sind 2026 die besten Open-Source-Reddit-Scraper auf GitHub?
bleibt der verlässlichste API-Wrapper mit aktiver Pflege und guter Dokumentation. ist ein glaubwürdiges, gepflegtes CLI-Tool auf Basis von PRAW. Playwright-basierte Scraper funktionieren für Nicht-API-Scraping, und das Reddit-Modul von snscrape ist teilweise funktionsfähig, aber weitgehend ungewartet. Prüfe immer das Datum des letzten Commits und die offenen Issues, bevor du ein Repo nutzt – die meisten der auf GitHub sind veraltet.
Ist es legal, Reddit zu scrapen?
Das Scrapen öffentlich verfügbarer Daten bewegt sich in einer rechtlichen Grauzone, aber Reddits eigene Regeln sind restriktiv. Das , die , die , die und sprechen alle gegen unautorisierte Massen-Scrapes. Eine kommerzielle Weiterverbreitung gescrapter Daten kann Reddits ausdrückliche Zustimmung erfordern. Wenn du personenbezogene Daten scrapest, können auch DSGVO und CCPA gelten.
Wie komme ich an Reddits API-Rate-Limits vorbei?
Nutze Exponential Backoff, beobachte die Header X-Ratelimit-Remaining und erwäge Zeitfenster-Segmentierung, um innerhalb der Limits zu arbeiten. Browserbasiertes Scraping (Playwright oder ) umgeht API-Rate-Limits, weil es gerenderte Seiten scrapt, bringt aber eigene Themen mit sich (Seitenladezeit, Anti-Bot-Maßnahmen). Es gibt keinen Zaubertrick, um Rate Limits komplett zu entfernen – sie werden serverseitig durchgesetzt.
Kann ich Reddit ohne API-Key scrapen?
Ja. Playwright-basierte Scraper und der .json-URL-Trick brauchen keinen API-Key. benötigt ebenfalls keinen API-Key, weil es über den Browser scrapt. Die Nachteile: .json-Endpunkte werden zunehmend blockiert (Stand April 2026 in vielen Umgebungen mit 403), und browserbasiertes Scraping ist langsamer und ressourcenintensiver als API-Aufrufe.
Was ist mit Pushshift beim Reddit-Scraping passiert?
Der öffentliche API-Zugang von Pushshift wurde im Zuge von Reddits Änderungen an der Datenlizenzierung ab 2023 entfernt. Der -Wrapper ist archiviert und veraltet. Eingeschränkter akademischer Zugang kann über bestimmte genehmigte Kanäle noch existieren, aber für die meisten Nutzer, die heute nach „reddit scraper github“ suchen, ist Pushshift keine praktikable Option mehr. Wenn du tiefe historische Reddit-Daten brauchst, schau dir Reddits genehmigte akademische oder lizenzierte Datenpfade an.
Mehr erfahren