Das Internet ist eine echte Goldmine für Daten – aber mal ehrlich, wer hat schon Lust, sich durch endlose Produktlisten oder Jobangebote per Copy & Paste zu quälen? Genau deshalb ist Web-Scraping heute ein absolutes Must-have für alle, die im Vertrieb, Operations, E-Commerce oder anderen datengetriebenen Bereichen unterwegs sind. Python ist dabei die Sprache der Wahl, weil sie super einfach zu lernen ist und jede Menge starke Bibliotheken für Web-Scraper bietet. Über setzen mittlerweile auf Python – viel mehr als auf jede andere Sprache.
Aber: So cool Python fürs Scraping auch ist, der Einstieg kann erstmal ganz schön einschüchternd wirken. Und selbst wenn du schon Erfahrung hast, bringen dich dynamische Webseiten, Anti-Bot-Schutz oder chaotische Daten schnell an deine Grenzen. Deshalb gibt’s hier dieses Schritt-für-Schritt-Tutorial. Wir starten ganz von vorn, bauen zusammen ein praktisches Python Web-Scraper Beispiel und schauen, wie du Python mit KI-Tools wie kombinieren kannst, um noch smarter zu scrapen. Egal ob du automatisch Leads sammeln, Preise der Konkurrenz checken oder Webdaten in eine Tabelle bringen willst – hier findest du konkrete Schritte und erprobte Tipps.
Python Web Scraping 101: So legst du los
Fangen wir mit den Basics an. Web-Scraping heißt einfach, dass du das Sammeln von Daten aus Webseiten automatisierst. Statt alles mühsam per Hand zu kopieren, besucht ein Scraper die Seite, liest den HTML-Code aus und fischt gezielt die Infos raus, die du brauchst – zum Beispiel Preise, Kontaktdaten oder Bewertungen. Für Unternehmen bedeutet das: Immer aktuelle Daten für Lead-Listen, Preisvergleiche oder Marktanalysen parat zu haben ().
Schritt 1: Python installieren
Zuerst brauchst du Python 3. Die neueste Version findest du auf der . Unter Windows einfach den Installer starten und „Add Python to PATH“ anhaken. Auf dem Mac kannst du mit brew install python nutzen oder direkt downloaden. Nach der Installation öffnest du das Terminal (oder die Eingabeaufforderung) und checkst:
1python --versionoder
1python3 --versionWenn sowas wie Python 3.11.0 erscheint, bist du startklar.
Schritt 2: Virtuelle Umgebung einrichten
Mit einer virtuellen Umgebung sorgst du dafür, dass die Abhängigkeiten deines Projekts sauber getrennt bleiben und es keinen Ärger mit anderen Python-Projekten gibt. Im Projektordner tippst du:
1# Auf macOS/Linux
2python3 -m venv .venv
3# Auf Windows
4py -m venv .venvAktivieren geht so:
- macOS/Linux:
source .venv/bin/activate - Windows:
.venv\Scripts\activate
Alle Pakete, die du jetzt installierst, gelten nur für dieses Projekt ().
Schritt 3: Wichtige Bibliotheken installieren
Du brauchst ein paar Standard-Pakete:
- Requests: Um Webseiten abzurufen.
- BeautifulSoup (bs4): Um HTML zu parsen.
- Scrapy: Für größere, komplexe Scraping-Projekte.
Installiere sie mit:
1pip install requests beautifulsoup4 scrapy- Requests macht HTTP-Anfragen super easy.
- BeautifulSoup hilft dir, gezielt Infos aus HTML zu ziehen.
- Scrapy ist ein komplettes Framework, wenn du viele Seiten crawlen, Fehler abfangen und Daten exportieren willst.
Für den Anfang reicht Requests + BeautifulSoup völlig aus. Scrapy lohnt sich, wenn du richtig große Projekte planst.
Schritt 4: Projektordner anlegen
Halte deine Dateien ordentlich! Leg einen Ordner für dein Projekt an und pack da deine Skripte, Daten und die virtuelle Umgebung rein. Dein zukünftiges Ich wird’s dir danken.
Python Web-Scraper Beispiel: Einfaches Skript zum Einstieg
Lass uns zusammen einen simplen Scraper bauen. Wir holen uns eine Webseite, parsen sie und extrahieren Daten. Hier ein minimales, kommentiertes Beispiel für :
1import requests
2from bs4 import BeautifulSoup
3URL = "https://example.com"
4response = requests.get(URL)
5response.raise_for_status() # Fehler, falls nicht 200 OK
6soup = BeautifulSoup(response.text, "html.parser")
7# Alle Absatz-Tags finden
8paragraphs = soup.find_all('p')
9for idx, p in enumerate(paragraphs, start=1):
10 print(f"Absatz {idx}: {p.get_text()}")Was passiert hier?
- Wir importieren die Bibliotheken.
- Rufen die Seite mit
requests.getab. - Parsen das HTML mit BeautifulSoup.
- Suchen alle
<p>-Tags und geben deren Text aus.
Typische Stolperfallen:
- Nicht auf
response.status_codeachten (immer auf 200 OK prüfen!). .get_text()auf einNone-Objekt anwenden (wenn das Element nicht gefunden wurde).- Die virtuelle Umgebung nicht aktiviert (dann funktionieren die Importe nicht).
Dieses Grundgerüst – importieren, abrufen, parsen, extrahieren, ausgeben – ist die Basis fast aller Python-Scraper.
Webseiten mit Python scrapen: Schritt für Schritt
So läuft eine echte Scraping-Session ab:
1. Webseite inspizieren
Öffne deinen Browser, mach einen Rechtsklick auf die gewünschten Daten und wähle „Untersuchen“. Die Entwicklertools zeigen dir den HTML-Aufbau. Such nach eindeutigen Tags, Klassen oder IDs, die deine Ziel-Daten markieren ().
2. Seite abrufen
Mit Requests holst du das HTML:
1headers = {"User-Agent": "Mozilla/5.0"}
2response = requests.get(URL, headers=headers)
3response.raise_for_status()Ein User-Agent hilft, einfache Bot-Sperren zu umgehen.
3. HTML parsen
1soup = BeautifulSoup(response.text, "html.parser")4. Daten finden und extrahieren
Angenommen, du scrapest Jobanzeigen, jede in einem <div class="job-card">:
1job_cards = soup.find_all('div', class_='job-card')
2for card in job_cards:
3 title = card.find('h2', class_='title').get_text(strip=True)
4 company = card.find('h3', class_='company').get_text(strip=True)
5 print(title, company)Du kannst .find(), .find_all() oder .select() mit CSS-Selektoren für komplexere Abfragen nutzen.
5. Mehrere Einträge verarbeiten (Listen)
Geh die Container (z. B. Produktlisten, Jobkarten) durch und hol dir die Felder, die du brauchst. Speichere sie als Liste von Dictionaries – so kannst du sie easy exportieren.
6. Fehlerbehebung
- Bei leeren Ergebnissen prüfe deine Selektoren – vielleicht hat sich der Klassenname geändert oder die Inhalte werden per JavaScript geladen.
- Gib
response.text[:500]aus, um zu checken, ob du das erwartete HTML bekommst.
Python Web-Scraper Beispiel: Daten speichern und exportieren
Wenn du deine Daten hast, willst du sie natürlich sichern. Die gängigsten Wege:
In die Konsole ausgeben
Gut zum Testen, aber für echte Projekte nicht zu empfehlen.
In CSV schreiben
1import csv
2data = [
3 {"Name": "Alice", "Age": 25},
4 {"Name": "Bob", "Age": 30},
5]
6with open("output.csv", "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=["Name", "Age"])
8 writer.writeheader()
9 writer.writerows(data)In Excel exportieren
Wenn du pandas und openpyxl installiert hast:
1import pandas as pd
2df = pd.DataFrame(data)
3df.to_excel("output.xlsx", index=False)In eine Datenbank speichern
Für einfache Zwecke reicht SQLite, das in Python schon dabei ist:
1import sqlite3
2conn = sqlite3.connect("scraped_data.db")
3cursor = conn.cursor()
4cursor.execute("CREATE TABLE IF NOT EXISTS people (name TEXT, age INTEGER)")
5for row in data:
6 cursor.execute("INSERT INTO people VALUES (?, ?)", (row["Name"], row["Age"]))
7conn.commit()
8conn.close()Wann was nutzen?
- CSV: Perfekt für Tabellenkalkulationen und schnellen Austausch.
- Excel: Für schicke Berichte und mehrere Blätter.
- Datenbank: Für große oder laufende Projekte.
Immer encoding="utf-8" nutzen, damit es keine Zeichenprobleme gibt ().
Thunderbit und Python: So bringst du dein Scraping aufs nächste Level
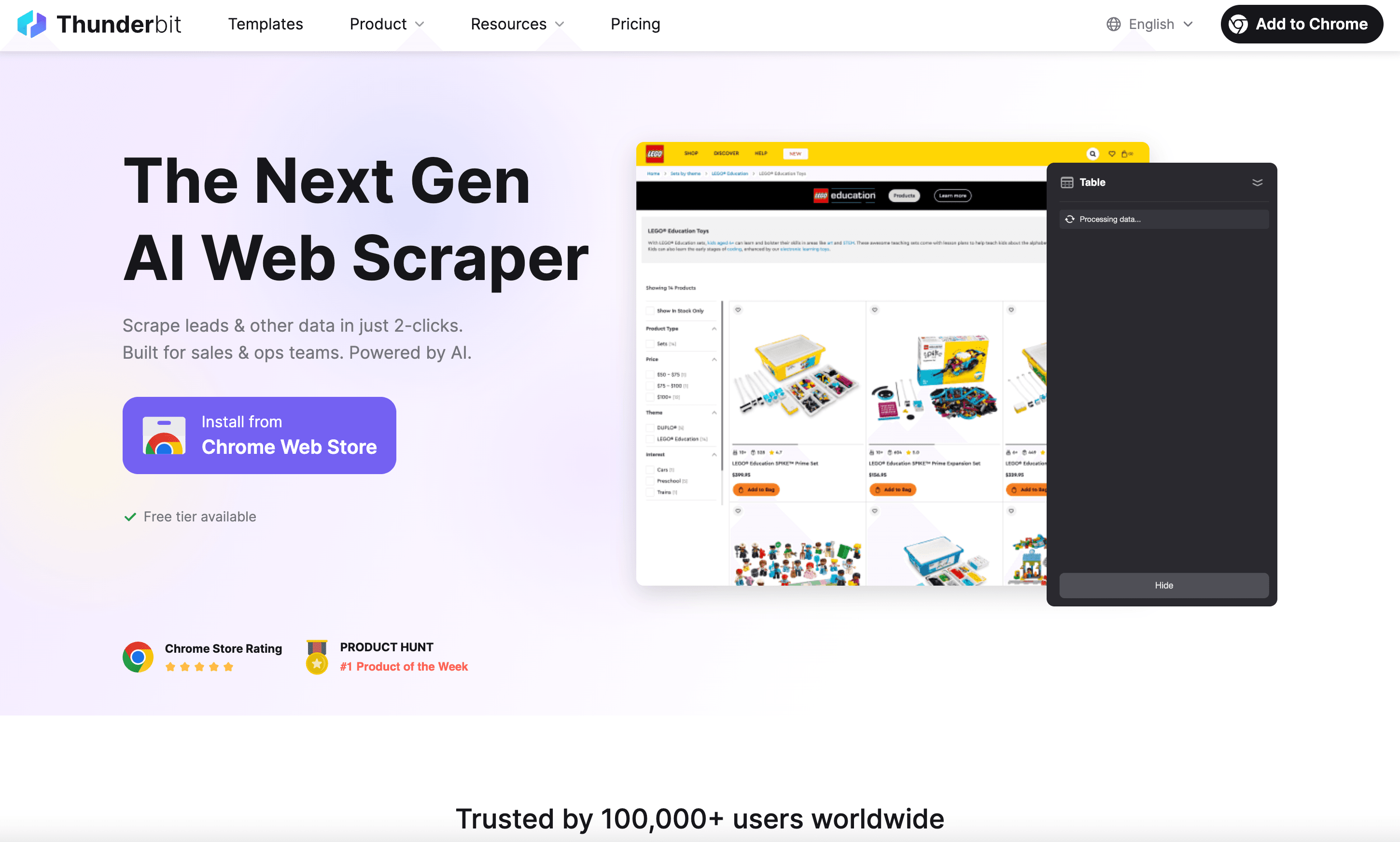 Jetzt schauen wir uns an – die KI-gestützte Web-Scraper Chrome-Erweiterung, die Scraping für Unternehmen auf ein neues Level hebt.
Jetzt schauen wir uns an – die KI-gestützte Web-Scraper Chrome-Erweiterung, die Scraping für Unternehmen auf ein neues Level hebt.
Was macht Thunderbit besonders?
- KI-Feldvorschläge: Thunderbits KI analysiert die Seite und schlägt dir automatisch vor, welche Datenfelder du extrahieren solltest – ganz ohne HTML-Inspektion oder Selektoren.
- Point-and-Click-Workflow: Erweiterung öffnen, KI-Felder übernehmen, auf „Scrapen“ klicken – fertig.
- Unterseiten-Scraping: Thunderbit kann automatisch Detailseiten (z. B. Produkt- oder Profilseiten) besuchen und deine Daten mit weiteren Infos anreichern.
- Flexible Exporte: Lade deine Daten als CSV, Excel oder exportiere direkt nach Google Sheets, Notion oder Airtable ().
Wie ergänzt Thunderbit Python?
Stell dir vor, du willst eine komplexe E-Commerce-Seite mit viel JavaScript und Login-Pflicht scrapen. Klassische Python-Skripte kommen da oft nicht weiter – Thunderbit läuft direkt im Browser und meistert solche Hürden locker. Nach dem Scraping kannst du die Daten exportieren und mit Python weiterverarbeiten, analysieren oder automatisieren.
Beispiel:
- Mit Thunderbit Produktlisten (inklusive Bilder, Preise, Bewertungen) von einer dynamischen Seite scrapen.
- Export als CSV.
- Mit Python Trends analysieren, mit anderen Daten abgleichen oder Benachrichtigungen automatisieren.
So schaffst du auch anspruchsvolle Scraping-Projekte – egal, wie viel Programmiererfahrung du hast.
So bleibt dein Python Web-Scraper stabil und zuverlässig
Web-Scraping heißt nicht nur, Daten zu sammeln – sondern die richtigen Daten, und das möglichst stabil. So sorgst du für zuverlässige Ergebnisse:
1. Auf Webseiten-Änderungen reagieren
Webseiten ändern ihren HTML-Code ständig. Schreib deine Selektoren möglichst robust – nutze eindeutige IDs oder stabile Klassennamen statt fragiler Tag-Positionen.
2. Fehlerbehandlung einbauen
Pack deine Requests und das Parsen in try/except-Blöcke:
1import time
2for attempt in range(3):
3 try:
4 response = requests.get(url, timeout=10)
5 response.raise_for_status()
6 break
7 except Exception as e:
8 if attempt < 2:
9 time.sleep(5)
10 else:
11 print(f"Nach 3 Versuchen gescheitert: {e}")3. User-Agent rotieren und Proxies nutzen
Viele Seiten blockieren Bots. Wechsle regelmäßig den User-Agent und nutze für größere Scraping-Projekte Proxies, um IP-Sperren zu vermeiden ().
4. robots.txt respektieren und fair scrapen
Check immer die robots.txt und die Nutzungsbedingungen der Seite. Scrape nur öffentliche Daten, lass persönliche Infos weg und überlaste keine Server ().
5. Logging und Monitoring
Nutze das logging-Modul von Python, um Fehler und Erfolge zu protokollieren. Bei geplanten Scrapes solltest du Benachrichtigungen für Fehler oder leere Ergebnisse einrichten.
Wie Thunderbits KI-Funktionen Python Web-Scraping verbessern
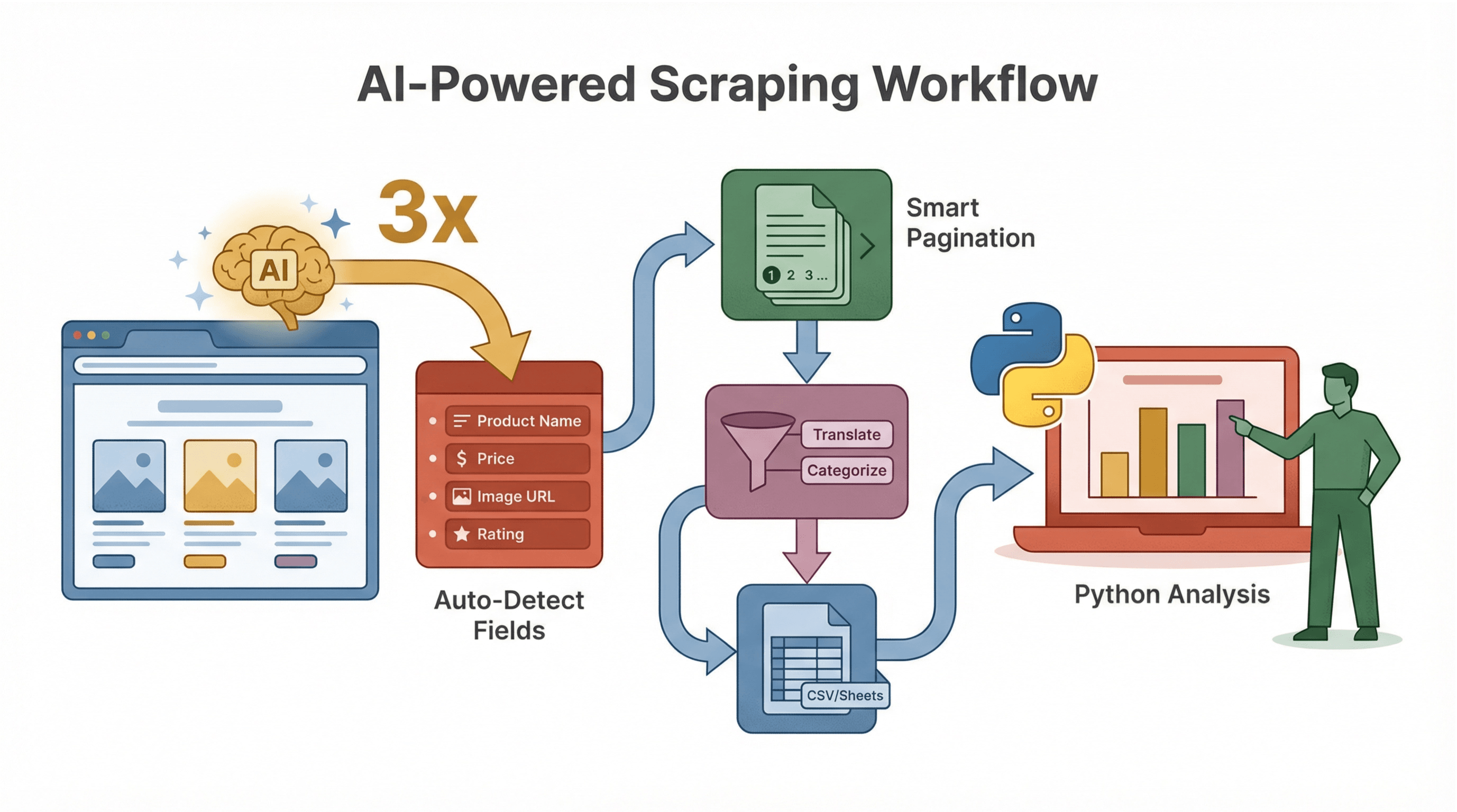 Thunderbit kann mehr als nur Scraping – es macht den ganzen Prozess schlauer und effizienter.
Thunderbit kann mehr als nur Scraping – es macht den ganzen Prozess schlauer und effizienter.
KI-gestützte Datenschema-Vorschläge
Thunderbits KI erkennt sofort, welche Felder sich zum Extrahieren eignen. So sparst du dir das mühsame HTML-Analysieren und Selektoren-Schreiben. Auf einer Produktseite erkennt Thunderbit z. B. automatisch „Produktname“, „Preis“, „Bild-URL“ und mehr.
Unterseiten und Paginierung automatisch erfassen
Thunderbit erkennt, wenn es Detailseiten oder mehrere Ergebnisseiten gibt, und kann diese automatisch scrapen – ganz ohne Zusatzcode. Das ist besonders praktisch für E-Commerce, Immobilien oder Lead-Generierung.
KI-gestützte Datenbereinigung und Anreicherung
Du willst Daten direkt beim Scrapen übersetzen, zusammenfassen oder kategorisieren? Mit Thunderbit kannst du jedem Feld einen KI-Prompt zuweisen – zum Beispiel, um Bewertungen als „Positiv“ oder „Negativ“ zu labeln oder nur den Zahlenwert aus einem Preis zu extrahieren.
Beispiel-Workflow
- Mit Thunderbit Daten strukturiert scrapen (inkl. KI-Feldvorschlägen).
- Export als CSV oder direkt nach Google Sheets.
- Mit Python analysieren, visualisieren oder Folgeaktionen automatisieren.
Perfekt für Teams, in denen nicht jeder programmieren kann: Thunderbit übernimmt das Scraping, Python die Auswertung.
Python Web-Scraper Beispiel: Profi-Tipps und typische Probleme
Bereit für den nächsten Schritt? Hier ein paar Tipps aus der Praxis:
Dynamische Inhalte scrapen
Viele moderne Seiten laden Daten per JavaScript. Wenn Requests + BeautifulSoup keine oder unvollständige Daten liefern, probiere:
- Selenium oder Playwright: Steuere einen echten Browser, um die Seite zu rendern und dann das HTML zu extrahieren.
- APIs suchen: Oft werden Daten im Hintergrund per API (meist als JSON) geladen. Im Netzwerk-Tab deines Browsers findest du diese Endpunkte – das Scrapen ist dann meist viel einfacher!
Paginierung meistern
Geh Seiten durch, indem du den URL-Parameter änderst (z. B. ?page=2). Oder nutze BeautifulSoup, um den „Weiter“-Link zu finden und folge ihm, bis keine Seiten mehr übrig sind.
Scrapes automatisieren
Mit der Python-Bibliothek schedule oder einem Cronjob kannst du deinen Scraper automatisch laufen lassen. Oder nutze Thunderbits integrierte Zeitplanung – ganz ohne Code.
Häufige Probleme
- CAPTCHAs: Anfragen verlangsamen, Proxies nutzen oder auf menschliche Hilfe setzen.
- Zeichenkodierung: Immer
encoding="utf-8"beim Schreiben von Dateien angeben. - IP-Sperren: Proxies rotieren, User-Agent variieren und Abfrageintervalle einhalten.
Fazit & wichtigste Erkenntnisse
Web-Scraping mit Python muss nicht kompliziert sein. Starte mit den Grundlagen:
- Richte deine Umgebung und die wichtigsten Bibliotheken ein.
- Untersuche die Zielseite und plane deine Selektoren.
- Schreibe ein einfaches Skript zum Abrufen, Parsen und Extrahieren der Daten.
- Exportiere die Ergebnisse in das für dich passende Format.
Mit wachsender Erfahrung kannst du Python mit KI-Tools wie kombinieren, um auch komplexe, dynamische oder großvolumige Scraping-Aufgaben zu meistern. Thunderbits KI-Funktionen – wie Feldvorschläge, Unterseiten-Scraping und Sofort-Exporte – sparen dir viel Zeit und machen Scraping auch für Nicht-Programmierer zugänglich.
Denk dran: Die besten Scraper sind zuverlässig, fair und auf das Ziel ausgerichtet. Egal ob du im Vertrieb, E-Commerce oder als Datenfan unterwegs bist – Web-Scraping eröffnet dir neue Möglichkeiten. Fang klein an, probiere aus und lerne immer weiter dazu.
Du willst tiefer einsteigen? Schau im vorbei oder teste die , um KI-gestütztes Scraping live zu erleben.
Häufige Fragen
1. Wie starte ich am einfachsten mit Web-Scraping in Python?
Installiere Python 3 und nutze die Bibliotheken Requests und BeautifulSoup, um Webseiten abzurufen und zu parsen. Fang mit einfachen Seiten an und steigere dich nach und nach zu komplexeren Projekten.
2. Wie gehe ich mit Webseiten um, die Daten per JavaScript laden?
Für Seiten mit viel JavaScript nutze Browser-Automatisierungstools wie Selenium oder Playwright. Alternativ kannst du im Netzwerk-Tab deines Browsers nach API-Aufrufen suchen, die strukturierte Daten (z. B. JSON) liefern.
3. Wie exportiere ich gescrapte Daten am besten für den geschäftlichen Einsatz?
CSV ist das universellste Format (lässt sich in Excel, Google Sheets usw. öffnen), aber du kannst auch nach Excel, JSON oder in Datenbanken wie SQLite exportieren. Thunderbit unterstützt zudem den Direkt-Export nach Google Sheets, Notion und Airtable.
4. Wie kann ich verhindern, beim Scraping blockiert zu werden?
Wechsle regelmäßig den User-Agent, nutze Proxies für große Scraping-Projekte, halte dich an Abfrageintervalle und prüfe immer die robots.txt der Seite. Verzichte auf das Scrapen persönlicher oder sensibler Daten.
5. Wie erleichtert Thunderbit Web-Scraping für Nicht-Programmierer?
Thunderbit nutzt KI, um Datenfelder vorzuschlagen, Unterseiten und Paginierung zu erkennen und strukturierte Daten mit wenigen Klicks zu exportieren – ganz ohne Programmierkenntnisse. Ideal für alle, die schnell und zuverlässig Ergebnisse wollen, ohne sich mit Technik zu beschäftigen.
Bereit, deine Datensammlung zu automatisieren? Teste kostenlos und bring dein Web-Scraping mit KI aufs nächste Level.
Mehr erfahren