Wenn ich an meine ersten Schritte im SaaS- und Automatisierungsbereich zurückdenke, klang „Web Crawling“ für mich wie das entspannte Herumspazieren einer Spinne am Wochenende. Heute ist Web Crawling das Fundament von Diensten wie der Google-Suche oder Preisvergleichsseiten. Das Internet ist ständig in Bewegung, und egal ob Entwickler oder Vertriebler – alle wollen an die wertvollen Daten ran. Das Problem dabei: Python hat den Zugang zu Web Crawlern zwar erleichtert, aber die meisten wollen einfach nur die Daten – und nicht erst HTTP-Header oder JavaScript-Rendering verstehen.
Genau hier wird’s spannend. Als Mitgründer von habe ich hautnah erlebt, wie rasant die Nachfrage nach Webdaten in allen Branchen gestiegen ist. Vertriebler sind ständig auf der Suche nach neuen Leads, E-Commerce-Manager wollen die Preise der Konkurrenz im Blick behalten, und Marketing-Teams brauchen Content-Insights. Aber nicht jeder hat Lust oder Zeit, sich tief in Python einzuarbeiten. Schauen wir uns also an, was ein Web Crawler in Python wirklich ist, warum er so wichtig ist – und wie KI-Tools wie Thunderbit die Spielregeln für Unternehmen und Entwickler verändern.
Web Crawler Python: Was steckt dahinter und warum ist es wichtig?
Lass uns gleich ein Missverständnis aus dem Weg räumen: Web Crawler und Web-Scraper sind nicht das Gleiche. Die Begriffe werden oft durcheinandergeworfen – aber sie sind so unterschiedlich wie ein Saugroboter und ein Handstaubsauger (beide reinigen, aber auf ihre eigene Art).
- Web Crawler sind die Scouts des Internets. Sie durchforsten systematisch Webseiten, folgen Links und indexieren Seiten – wie der Googlebot, der das ganze Web kartiert.
- Web-Scraper dagegen sind eher wie geschickte Sammler. Sie holen gezielt bestimmte Infos von Webseiten, zum Beispiel Produktpreise, Kontaktdaten oder Artikelinhalte.

Wenn von „web crawler python“ die Rede ist, geht’s meistens darum, mit Python automatisierte Bots zu bauen, die das Web durchforsten und manchmal auch Daten extrahieren. Python ist hier die erste Wahl, weil es einfach zu lernen ist, eine riesige Bibliothekslandschaft bietet – und mal ehrlich: Niemand will einen Web Crawler in Assembler schreiben.
Warum Web Crawling und Web Scraping für Unternehmen so wertvoll sind
Warum interessieren sich so viele Teams für Web Crawling und Scraping? Weil Webdaten das neue Öl sind – nur dass man nicht bohren, sondern einfach programmieren (oder, wie wir gleich sehen, klicken) muss.
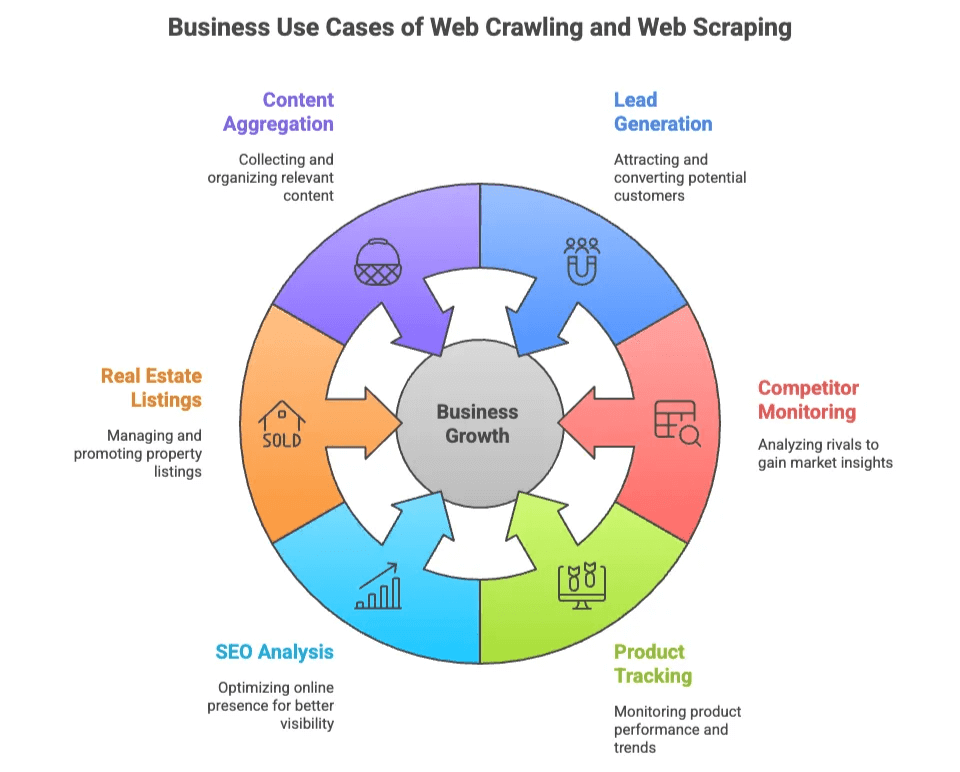
Hier ein paar typische Anwendungsfälle:
| Anwendungsfall | Wer braucht es | Nutzen |
|---|---|---|
| Lead-Generierung | Vertrieb, Marketing | Zielgerichtete Listen von potenziellen Kunden aus Verzeichnissen, sozialen Netzwerken |
| Wettbewerbsbeobachtung | E-Commerce, Operations | Preise, Lagerbestände und neue Produkte bei der Konkurrenz verfolgen |
| Produktüberwachung | E-Commerce, Einzelhandel | Katalogänderungen, Bewertungen und Rezensionen im Blick behalten |
| SEO-Analyse | Marketing, Content | Keywords, Meta-Tags und Backlinks für Optimierung analysieren |
| Immobilienanzeigen | Makler, Investoren | Immobiliendaten und Eigentümerkontakte aus verschiedenen Quellen bündeln |
| Content-Aggregation | Forschung, Medien | Artikel, News oder Forenbeiträge für Insights sammeln |
Das Beste daran: Sowohl technische als auch nicht-technische Teams profitieren davon. Entwickler bauen individuelle Crawler für große Projekte, während Business-User einfach nur schnell und unkompliziert an Daten kommen wollen – am liebsten ohne je von CSS-Selektoren gehört zu haben.
Die beliebtesten Python Web Crawler Bibliotheken: Scrapy, BeautifulSoup und Selenium
Dass Python beim Web Crawling so beliebt ist, kommt nicht von ungefähr – drei Bibliotheken haben jeweils ihre eigenen Fans (und Eigenheiten).
| Bibliothek | Bedienbarkeit | Geschwindigkeit | Dynamische Inhalte | Skalierbarkeit | Ideal für |
|---|---|---|---|---|---|
| Scrapy | Mittel | Schnell | Eingeschränkt | Hoch | Große, automatisierte Crawls |
| BeautifulSoup | Einfach | Mittel | Keine | Gering | Einfache Auswertungen, kleine Projekte |
| Selenium | Anspruchsvoll | Langsam | Hervorragend | Mittel | JavaScript-lastige, interaktive Seiten |
Schauen wir uns die Unterschiede mal genauer an.
Scrapy: Das All-in-One-Framework für Python Web Crawling
Scrapy ist das Schweizer Taschenmesser unter den Python Web Crawlern. Es ist ein komplettes Framework für große, automatisierte Crawls – perfekt, wenn tausende Seiten parallel verarbeitet und Daten direkt weiterverarbeitet werden sollen.
Warum Entwickler darauf schwören:
- Crawling, Parsing und Datenexport in einem System.
- Integrierte Unterstützung für parallele Anfragen, Zeitplanung und Datenpipelines.
- Ideal für Projekte, bei denen große Datenmengen automatisiert gesammelt werden.
Aber… Scrapy hat eine gewisse Einstiegshürde. Wie ein Entwickler mal sagte: „Überdimensioniert, wenn man nur ein paar Seiten scrapen will“ (). Man muss sich mit Selektoren, asynchroner Verarbeitung und manchmal auch mit Proxies und Anti-Bot-Strategien auskennen.
So läuft ein Scrapy-Projekt ab:
- Spider (Crawler-Logik) definieren.
- Item-Pipelines für die Datenverarbeitung einrichten.
- Crawl starten und Daten exportieren.
Wer das Web wie Google durchforsten will, ist mit Scrapy bestens beraten. Für einfache Aufgaben wie das Sammeln von E-Mail-Adressen ist es meist zu aufwendig.
BeautifulSoup: Der einfache Einstieg ins Web Crawling
BeautifulSoup ist der „Hallo Welt“-Einstieg ins Web Parsing. Die Bibliothek ist leichtgewichtig und spezialisiert auf das Parsen von HTML und XML – ideal für Einsteiger oder kleine Projekte.
Warum sie so beliebt ist:
- Sehr einfach zu lernen und zu nutzen.
- Perfekt für das Extrahieren von Daten aus statischen Seiten.
- Flexibel für schnelle, unkomplizierte Skripte.
Aber… BeautifulSoup crawlt nicht selbst – sie parst nur. Man braucht zusätzlich z. B. requests, um Seiten abzurufen, und muss die Logik für das Folgen von Links oder das Verarbeiten mehrerer Seiten selbst schreiben ().
Wer erste Schritte im Web Crawling machen will, ist mit BeautifulSoup gut beraten. Für JavaScript-Inhalte oder große Projekte stößt sie aber schnell an Grenzen.
Selenium: Für dynamische und JavaScript-lastige Seiten
Selenium ist der König der Browser-Automatisierung. Es steuert Chrome, Firefox oder Edge, kann Buttons klicken, Formulare ausfüllen und – ganz wichtig – auch JavaScript-Inhalte rendern.

Was Selenium so stark macht:
- Kann Webseiten wie ein Mensch „sehen“ und bedienen.
- Unterstützt dynamische Inhalte und AJAX-geladene Daten.
- Unverzichtbar für Seiten mit Login oder komplexen Nutzerinteraktionen.
Aber… Selenium ist langsam und ressourcenhungrig. Für jede Seite wird ein kompletter Browser gestartet – das kann bei großen Crawls das System ausbremsen (). Auch die Wartung ist aufwendig: Browser-Treiber müssen aktuell gehalten werden, und das Warten auf dynamische Inhalte kostet Zeit.
Selenium ist die richtige Wahl, wenn normale Scraper an JavaScript-Hürden scheitern.
Die größten Herausforderungen beim Python Web Crawling
Kommen wir zu den weniger glamourösen Seiten des Web Crawlings mit Python. Ich habe mehr Stunden mit dem Debuggen von Selektoren und dem Kampf gegen Anti-Bot-Maßnahmen verbracht, als mir lieb ist. Die größten Stolpersteine:
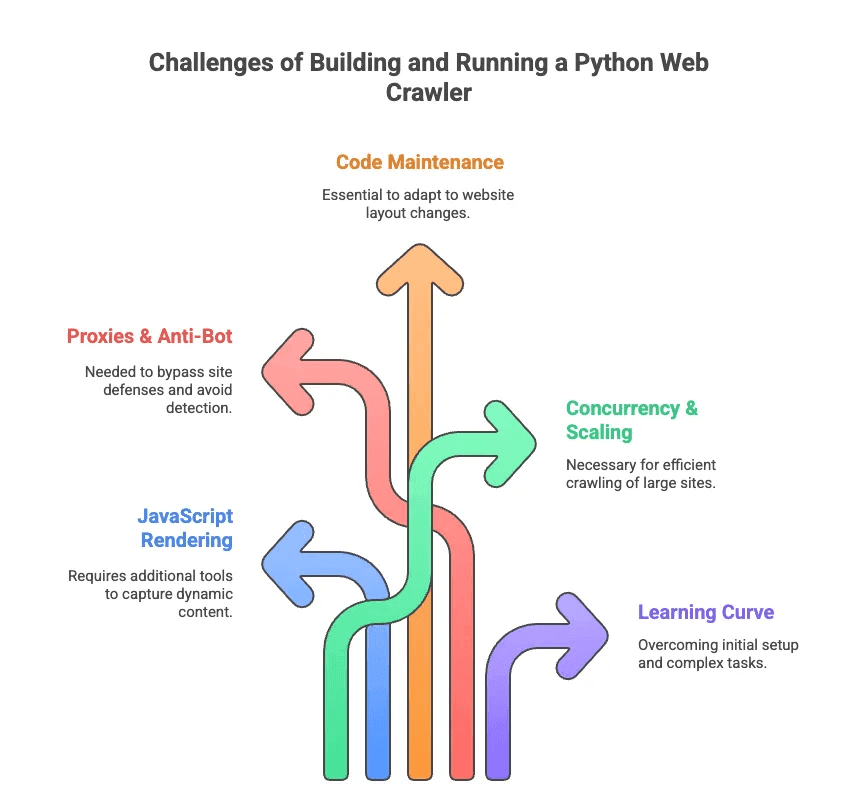
- JavaScript-Rendering: Viele moderne Seiten laden Inhalte dynamisch. Scrapy und BeautifulSoup sehen diese Daten ohne Zusatztools nicht.
- Proxies & Anti-Bot: Viele Seiten mögen keine Crawler. Man muss Proxies rotieren, User-Agents faken und manchmal CAPTCHAs lösen.
- Code-Wartung: Webseiten ändern ständig ihr Layout. Ein mühsam gebauter Scraper kann über Nacht nicht mehr funktionieren – dann heißt es Selektoren und Logik anpassen.
- Skalierung & Parallelisierung: Wer tausende Seiten crawlt, muss asynchrone Anfragen, Fehlerbehandlung und Datenpipelines managen.
- Einarbeitung: Für Nicht-Entwickler ist schon die Python-Installation eine Hürde. An Paginierung oder Login-Flows ist ohne Hilfe kaum zu denken.
Wie ein Ingenieur es mal formulierte: Eigene Scraper zu schreiben fühlt sich oft an, als bräuchte man „einen Doktortitel in Selektoren-Konfiguration“ – nicht gerade das, was Vertrieb oder Marketing erwartet ().
KI-Web-Scraper vs. Python Web Crawler: Der neue Weg für Business-User
Was aber, wenn du einfach nur die Daten willst – ohne den ganzen Aufwand? Hier kommen KI-Web-Scraper ins Spiel. Tools wie richten sich an Business-Anwender statt Entwickler. Sie nutzen KI, um Webseiten zu analysieren, schlagen relevante Datenfelder vor und übernehmen im Hintergrund die komplizierten Aufgaben (Paginierung, Unterseiten, Anti-Bot).
Hier ein schneller Vergleich:
| Funktion | Python Web Crawler | KI-Web-Scraper (Thunderbit) |
|---|---|---|
| Einrichtung | Code, Bibliotheken, Konfiguration | 2-Klick Chrome-Erweiterung |
| Wartung | Manuelle Updates, Debugging | KI passt sich automatisch an |
| Dynamische Inhalte | Selenium oder Plugins nötig | Browser-/Cloud-Rendering integriert |
| Anti-Bot-Umgehung | Proxies, User-Agents | KI & Cloud-Bypass |
| Skalierbarkeit | Hoch (mit Aufwand) | Hoch (Cloud, paralleles Scraping) |
| Bedienkomfort | Für Entwickler | Für alle |
| Datenexport | Code oder Skripte | 1-Klick zu Sheets, Airtable, Notion |
Mit Thunderbit musst du dich nicht um HTTP-Requests, JavaScript oder Proxies kümmern. Einfach auf „KI-Felder vorschlagen“ klicken, die KI erkennt die wichtigsten Daten – und mit „Scrapen“ starten. Es ist wie ein persönlicher Daten-Butler – nur ohne Smoking.
Thunderbit: Der KI-Web-Scraper der nächsten Generation für alle
Konkret: Thunderbit ist eine , die das Extrahieren von Webdaten so einfach macht wie eine Essensbestellung. Das macht Thunderbit besonders:
- KI-Felderkennung: Die KI liest die Seite und schlägt automatisch relevante Spalten vor – kein Rätselraten mit CSS-Selektoren mehr ().
- Dynamische Seitenunterstützung: Funktioniert sowohl mit statischen als auch mit JavaScript-lastigen Seiten – dank Browser- und Cloud-Modus.
- Unterseiten & Paginierung: Du brauchst Details von jedem Produkt oder Profil? Thunderbit klickt automatisch in Unterseiten und sammelt die Infos ().
- Flexible Vorlagen: Eine Scraper-Vorlage kann sich an verschiedene Seitenstrukturen anpassen – kein Neubau bei Layout-Änderungen nötig.
- Anti-Bot-Umgehung: KI und Cloud-Infrastruktur helfen, gängige Anti-Scraping-Maßnahmen zu umgehen.
- Datenexport: Exportiere deine Daten direkt nach Google Sheets, Airtable, Notion oder als CSV/Excel – ohne Bezahlschranke, selbst in der Gratis-Version ().
- KI-Datenaufbereitung: Daten können direkt zusammengefasst, kategorisiert oder übersetzt werden – Schluss mit unübersichtlichen Tabellen.
Praxisbeispiele:
- Vertriebsteams extrahieren in Minuten Kontaktlisten aus Verzeichnissen oder LinkedIn.
- E-Commerce-Manager überwachen automatisch Preise und Produktänderungen der Konkurrenz.
- Makler bündeln Immobilienangebote und Eigentümerkontakte von verschiedenen Plattformen.
- Marketing-Teams analysieren Inhalte, Keywords und Backlinks für SEO – ganz ohne Programmierkenntnisse.
Thunderbit ist so einfach, dass selbst meine nicht-technischen Freunde es nutzen – und das erfolgreich. Einfach die Erweiterung installieren, Zielseite öffnen, „KI-Felder vorschlagen“ klicken – und los geht’s. Für bekannte Seiten wie Amazon oder LinkedIn gibt es sogar Sofort-Vorlagen – ein Klick genügt ().
Wann Python Web Crawler, wann KI-Web-Scraper?
Solltest du einen Python Web Crawler bauen oder einfach Thunderbit nutzen? Hier meine ehrliche Einschätzung:
| Szenario | Python Web Crawler | KI-Web-Scraper (Thunderbit) |
|---|---|---|
| Maßgeschneiderte Logik oder riesige Datenmengen nötig | ✔️ | Vielleicht (Cloud-Modus) |
| Tiefe Integration in andere Systeme erforderlich | ✔️ (mit Code) | Eingeschränkt (per Export) |
| Nicht-technischer Nutzer, schnelle Ergebnisse | ❌ | ✔️ |
| Häufige Layout-Änderungen der Zielseiten | ❌ (manuelle Updates) | ✔️ (KI passt sich an) |
| Dynamische/JS-lastige Seiten | ✔️ (mit Selenium) | ✔️ (integriert) |
| Kleines Budget, kleine Projekte | Vielleicht (kostenlos, aber zeitaufwendig) | ✔️ (Gratis-Version, keine Bezahlschranke) |
Python Web Crawler sind sinnvoll, wenn:
- Du Entwickler bist und volle Kontrolle brauchst.
- Du Millionen von Seiten crawlen oder individuelle Datenpipelines benötigst.
- Du bereit bist, regelmäßig zu warten und zu debuggen.
Thunderbit ist ideal, wenn:
- Du sofort Daten brauchst, ohne tagelanges Coden.
- Du im Vertrieb, E-Commerce, Marketing oder Immobilienbereich arbeitest und einfach Ergebnisse willst.
- Du keine Lust auf Proxies, Selektoren oder Anti-Bot-Probleme hast.
Noch unsicher? Hier eine schnelle Checkliste:
- Du kennst dich mit Python und Web-Technologien aus? Dann probiere Scrapy oder Selenium.
- Du willst einfach und schnell saubere Daten? Dann ist Thunderbit die richtige Wahl.
Fazit: Webdaten nutzen – das richtige Tool für jeden Bedarf
Web Crawling und Web Scraping sind heute unverzichtbare Skills. Aber mal ehrlich: Nicht jeder will zum Web-Crawling-Profi werden. Python-Tools wie Scrapy, BeautifulSoup und Selenium sind mächtig, aber mit steiler Lernkurve und viel Wartungsaufwand verbunden.
Deshalb freue ich mich über den Siegeszug von KI-Web-Scrapern wie . Wir haben Thunderbit entwickelt, um Webdaten für alle zugänglich zu machen – nicht nur für Entwickler. Mit KI-gestützter Felderkennung, Unterstützung für dynamische Seiten und No-Code-Workflows kann jeder in Minuten die gewünschten Daten extrahieren.
Egal, ob du gerne coden willst oder einfach nur Ergebnisse brauchst: Es gibt für jeden das passende Tool. Überlege, was du brauchst, wie technisch du bist und wie schnell du Ergebnisse willst. Und wenn du erleben möchtest, wie einfach Webdaten-Extraktion heute sein kann, – dein zukünftiges Ich (und deine Tabellenkalkulation) werden es dir danken.
Du willst tiefer einsteigen? Weitere Anleitungen findest du im , zum Beispiel oder . Viel Erfolg beim Crawlen – und beim Scrapen!
FAQs
1. Was ist der Unterschied zwischen einem Python Web Crawler und einem Web-Scraper?
Ein Python Web Crawler ist darauf ausgelegt, Webseiten systematisch zu erkunden und zu indexieren, indem er Links folgt – ideal, um die Struktur von Websites zu erfassen. Ein Web-Scraper hingegen extrahiert gezielt bestimmte Daten wie Preise oder E-Mails. Crawler kartieren das Internet, Scraper holen die gewünschten Infos. In Python werden beide Ansätze oft kombiniert, um komplette Daten-Workflows abzubilden.
2. Welche Python-Bibliotheken eignen sich am besten für Web Crawler?
Beliebte Bibliotheken sind Scrapy, BeautifulSoup und Selenium. Scrapy ist schnell und skalierbar für große Projekte; BeautifulSoup ist besonders einsteigerfreundlich, aber eher für statische Seiten geeignet; Selenium glänzt bei JavaScript-lastigen Seiten, ist aber langsamer. Die beste Wahl hängt von deinen technischen Kenntnissen, dem Inhaltstyp und der Projektgröße ab.
3. Gibt es eine einfachere Möglichkeit, Webdaten zu bekommen, ohne einen Python Web Crawler zu programmieren?
Ja – Thunderbit ist eine KI-basierte Chrome-Erweiterung, mit der jeder in nur zwei Klicks Webdaten extrahieren kann. Kein Code, keine Einrichtung. Felder werden automatisch erkannt, Paginierung und Unterseiten werden übernommen, und der Export zu Sheets, Airtable oder Notion ist inklusive. Perfekt für Vertrieb, Marketing, E-Commerce oder Immobilien – für alle, die einfach und schnell saubere Daten brauchen.
Mehr erfahren: