

Wer 2025 Webdaten braucht, kennt das Gefühl: Eben noch wolltest du nur schnell die Preise der Konkurrenz checken, im nächsten Moment kämpfst du dich durch dynamisches JavaScript und immer raffiniertere Anti-Bot-Sperren. Nach Jahren im Aufbau von Automatisierungslösungen für Sales- und Operations-Teams ist für mich klar: Web-Scraping ist kein nettes Extra mehr, sondern eine Kernkompetenz für jedes Business. 90 % aller Unternehmen stützen ihre strategischen Entscheidungen mittlerweile auf Datenanalysen, und das Online-Datenvolumen ist in nur vier Jahren um 193 % gestiegen. Wer das Datenchaos im Netz in brauchbare Erkenntnisse übersetzt, verschafft sich einen klaren Vorsprung.

Eines vorweg: Web-Scraping funktioniert heute anders als noch vor ein paar Jahren. Die Zeiten, in denen ein paar Zeilen Python gereicht haben, um statisches HTML abzugreifen, sind vorbei. Stattdessen warten dynamische Inhalte, endloses Scrollen und Anti-Bot-Technik, an der auch erfahrene Entwickler ins Schwitzen kommen. Ob du gerade erst startest oder dein Setup auf das nächste Level bringen willst – in diesem Guide gehe ich die besten Methoden, Tools und Workflows für Python-Scraping im Jahr 2025 durch. Und ich zeige dir, wie KI-Tools wie Thunderbit deine Projekte spürbar einfacher machen.
Mit KI Daten von jeder Website extrahieren Get Started Free
Von den Basics zum Scraping-Profi: Python-Scraping verstehen
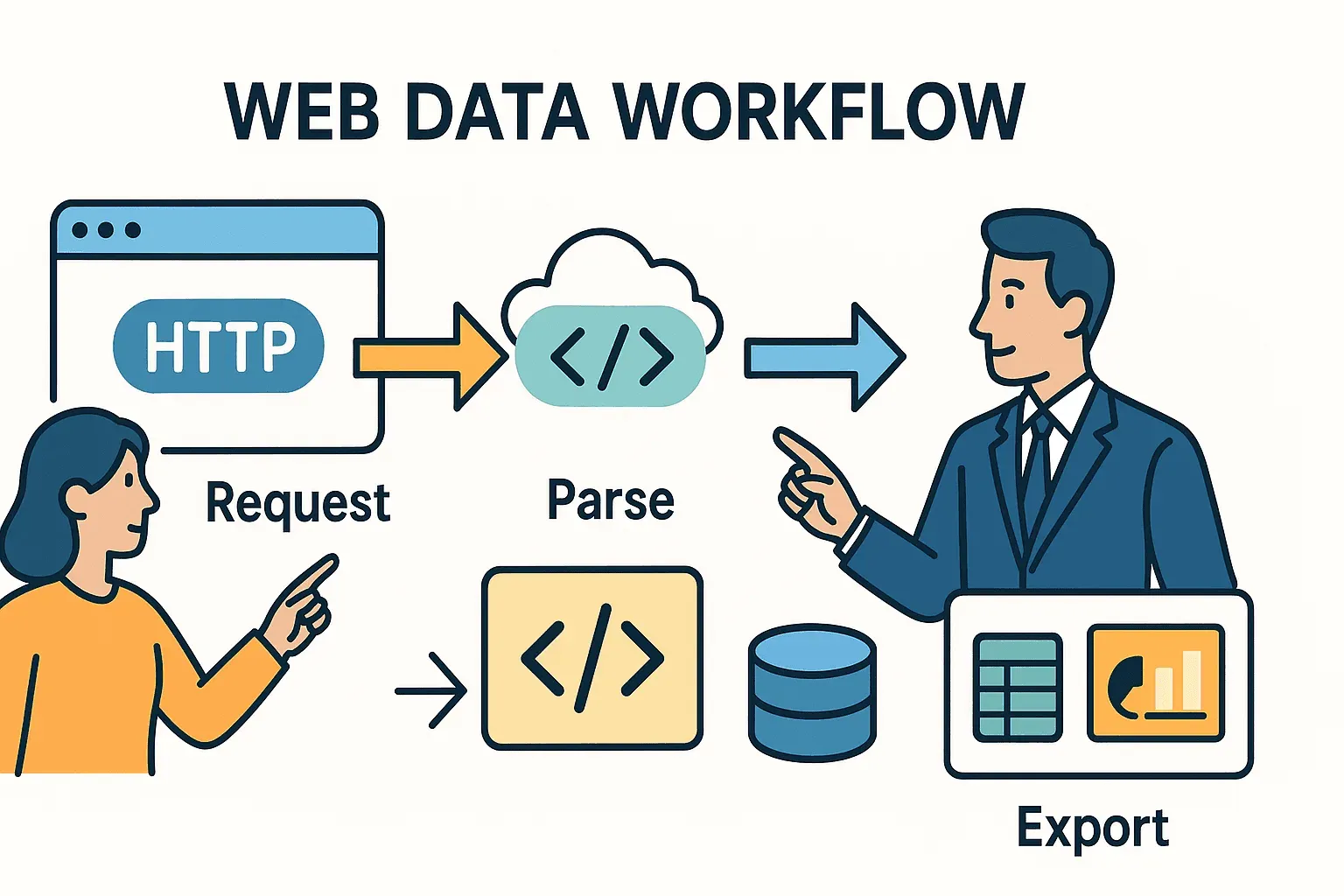
Fangen wir ganz vorne an. Web-Scraping bedeutet im Kern: Was du sonst im Browser manuell erledigst, läuft automatisiert ab – Seite aufrufen, Daten finden, abspeichern. In Python passiert das meistens in drei Schritten:
- HTTP-Anfrage schicken (so wie dein Browser beim Laden einer URL).
- HTML parsen, um die gewünschten Infos herauszufiltern.
- Daten exportieren oder weiterverarbeiten – etwa in eine Tabelle, Datenbank oder ein Dashboard.
Welche Tools du brauchst und welche Hürden auf dich warten, hängt davon ab, wie komplex die Website ist und was du vorhast.
Python-Scraping 101: So läuft’s ab
Ein einfaches Bild: Stell dir einen Bibliothekar vor, der dir die Zeitung holt – und du schneidest mit der Schere nur die Artikel aus, die dich interessieren. Die Python-Bibliothek requests ist dein Bibliothekar; sie holt das HTML. BeautifulSoup ist deine Schere; damit trennst du gezielt die relevanten Infos heraus.
Aber was, wenn die Zeitung mit unsichtbarer Tinte geschrieben ist (Stichwort JavaScript) oder die Artikel über viele Seiten verteilt liegen? Dann brauchst du fortgeschrittenes Werkzeug – oder ein bisschen KI-Unterstützung.
Die wichtigsten Tools im Vergleich
Hier ein schneller Überblick über die gängigsten Python-Scraping-Tools und wann sie sich lohnen:
| Tool/Bibliothek | Einsatz, wenn... | Vorteile | Nachteile |
|---|---|---|---|
| Requests + BeautifulSoup | Statische Seiten oder kleine Aufgaben | Einfach, schnell, ideal für Einsteiger. Volle Kontrolle. | Kein JavaScript, nicht für große Crawls geeignet. |
| Scrapy | Große Projekte, viele Seiten/Websites | Sehr leistungsstark, integriertes Crawling, asynchron, Pipelines, robustes Fehlerhandling. | Höhere Einstiegshürde, mehr Setup-Aufwand. |
| Selenium/Playwright | Seiten mit JavaScript, Logins oder Nutzerinteraktion | Kann alles extrahieren, was im Browser sichtbar ist. Für dynamische Inhalte, Logins, Infinite Scroll. | Langsamer, ressourcenintensiv, komplexer im Betrieb. |
| Thunderbit (KI) | Unstrukturierte Daten, PDFs, Bilder, No-Code | KI erkennt Felder automatisch, verarbeitet Unterseiten, Export nach Excel/Sheets, kein Coding nötig. | Weniger flexibel bei Spezialfällen, nutzungsabhängig. |
Für die meisten Business-Anwendungen reicht requests mit BeautifulSoup bei einfachen, statischen Seiten völlig aus. Wird es größer oder komplexer, ist Scrapy die richtige Wahl. Und sobald du an Grenzen stößt – dynamische Inhalte, Anti-Bot-Schutz oder unstrukturierte Daten – sind KI-Tools wie Thunderbit oft die Rettung.
Thunderbit KI-Web-Scraper kostenlos testen
Schritt für Schritt: Best Practices für komplexes Scraping
Wie kommst du von „Ich will diese Daten“ zu einem stabilen, wartbaren Scraper? Das ist der Workflow, der sich bei mir bewährt hat:
1. Zielseite analysieren und verstehen
Bevor du loslegst, öffne die Entwicklertools deines Browsers (F12 oder Rechtsklick > Untersuchen). Suche die gewünschten Daten im HTML. Stehen sie in einer Tabelle? In mehreren <div>s? Gibt es vielleicht einen versteckten API-Call, der JSON liefert? Häufig liegt der einfachste Weg direkt vor dir.
Tipp: Siehst du im Netzwerk-Tab eine Anfrage, die beim Klick auf „Nächste Seite“ oder „Mehr laden“ JSON zurückgibt, kannst du diese API meist direkt mit Python ansprechen – das HTML-Parsing entfällt dann komplett.
2. Prototyp auf einer Einzelseite bauen
Starte klein. Hole mit requests eine Seite, extrahiere mit BeautifulSoup ein paar Felder und gib sie aus. Wirst du blockiert oder fehlen Daten, probiere es mit Headern (z. B. ein User-Agent wie im Browser) oder prüfe, ob die Inhalte per JavaScript nachgeladen werden (dann weiter zu Schritt 3).
3. Dynamische Inhalte und Paginierung meistern
Stehen die Daten nicht im HTML, werden sie wahrscheinlich per JavaScript geladen. Deine Optionen:
- Browser-Automatisierung: Nutze Selenium oder Playwright, um die Seite zu öffnen, auf Inhalte zu warten und das gerenderte HTML zu extrahieren.
- API-Calls: Suche im Netzwerk-Tab nach XHR-Anfragen. Findest du eine JSON-API, kannst du sie meist direkt mit
requestsansprechen. - Paginierung: Bei mehreren Seiten durchläufst du die Seitennummern oder folgst „Weiter“-Links. Bei Infinite Scroll scrollst du mit Selenium nach unten oder simulierst die API-Calls, die beim Scrollen ausgelöst werden.
4. Fehlerbehandlung und Fairness
Websites freuen sich selten über Scraper. Damit du nicht blockiert wirst:
- robots.txt beachten: Prüfe immer
example.com/robots.txtauf gesperrte Pfade oder Crawl-Delays. - Rate Limiting: Baue Pausen (
time.sleep()) zwischen den Anfragen ein. Steht in der robots.txtCrawl-delay: 5, dann warte mindestens 5 Sekunden. - Eigener User-Agent: Stelle dich höflich vor (z. B.
"MyScraper/1.0 (your@email.com)"). - Retry-Logik: Fange Fehler mit try/except ab. Wiederhole Anfragen bei Fehlern und pausiere bei HTTP 429 (zu viele Anfragen).
5. Daten extrahieren und bereinigen
Nutze BeautifulSoup- oder Scrapy-Selektoren, um die Felder herauszuziehen. Entferne überflüssige Leerzeichen, wandle Preise in Zahlen um, parse Datumsangaben und prüfe die Vollständigkeit. Bei großen Datenmengen hilft pandas beim Bereinigen und beim Entfernen von Duplikaten.
6. Unterseiten scrapen
Oft stecken die wirklich wertvollen Infos auf den Detailseiten. Extrahiere eine Liste von Links und besuche jede Seite einzeln, um weitere Daten zu holen. In Python heißt das: URLs durchlaufen und jede Seite abfragen. Mit Thunderbit übernimmt das die Funktion „Unterseiten scrapen“ – die KI besucht automatisch jede Detailseite und ergänzt deinen Datensatz.
7. Export und Automatisierung
Exportiere deine bereinigten Daten als CSV, Excel, Google Sheets oder in eine Datenbank. Für wiederkehrende Aufgaben planst du dein Skript mit cron, Airflow oder – bei Thunderbit – per Klartext-Eingabe wie „jeden Montag um 9 Uhr“ als Cloud-Scrape.
So extrahierst du Websitedaten mit KI nach Excel Get Started Free
Thunderbit: Wenn KI dein Python-Scraping aufs nächste Level hebt
Manchmal stößt auch der beste Python-Code an seine Grenzen – etwa bei unstrukturierten, chaotischen oder geschützten Daten. Genau hier kommt Thunderbit ins Spiel.
So ergänzt Thunderbit Python
Thunderbit ist eine KI-basierte Chrome-Erweiterung, die Webseiten (oder PDFs, Bilder usw.) liest und strukturierte Daten ausgibt – ganz ohne Programmierung. So setze ich es ein:
- Bei unstrukturierten Daten: Stoße ich auf PDFs, Bilder oder unvorhersehbares HTML, überlasse ich die Arbeit Thunderbits KI. Sie extrahiert Tabellen aus PDFs, liest Texte aus Bildern und schlägt sogar Felder automatisch vor.
- Für Unterseiten und mehrstufiges Scraping: Die Funktion „Unterseiten scrapen“ spart enorm Zeit. Du legst eine Liste an, dann besucht die KI jede Detailseite und kombiniert die Ergebnisse – ohne dass ich verschachtelte Schleifen schreiben oder Zustände verwalten muss.
- Für den Export: Thunderbit exportiert direkt nach Excel, Google Sheets, Notion oder Airtable. Diese Daten übernehme ich anschließend in meine Python-Pipeline und verarbeite sie weiter.
Praxisbeispiel: Python + Thunderbit im Zusammenspiel
Angenommen, ich beobachte Immobilienangebote. Mit Python und Scrapy sammle ich die Listing-URLs verschiedener Portale. Auf einer Seite stehen die Details aber nur in herunterladbaren PDFs. Statt selbst einen PDF-Parser zu bauen, lade ich die Dateien bei Thunderbit hoch, lasse die KI die Tabellen extrahieren und exportiere als CSV. Danach führe ich alle Daten in Python zu einer Marktanalyse zusammen.
Oder ich baue eine Lead-Liste für den Vertrieb. Mit Python sammle ich die Firmen-URLs, dann ziehe ich mit Thunderbits E-Mail- und Telefon-Extraktoren (kostenlos) die Kontaktdaten von jeder Seite – ganz ohne Regex-Frust.
Unstrukturierte Daten mit Thunderbit KI extrahieren
Einen nachhaltigen Scraping-Workflow aufbauen: Von Skript zu Pipeline
Ein einmaliges Skript ist praktisch für schnelle Ergebnisse, aber die meisten Business-Scraping-Prozesse laufen regelmäßig. So baue ich einen wartbaren, skalierbaren Scraping-Stack:
Das CCCD-Modell: Crawl, Collect, Clean, Debug
- Crawl: Sammle alle Ziel-URLs (aus Sitemaps, Suchseiten oder Listen).
- Collect: Extrahiere die Daten von jeder URL (mit Python, Thunderbit oder beidem).
- Clean: Normalisiere, entferne Duplikate und prüfe die Daten.
- Debug/Monitor: Protokolliere jeden Lauf, fange Fehler ab und richte Benachrichtigungen bei Problemen oder Auffälligkeiten ein.
Denk an eine Pipeline:
URLs → [Crawler] → [Scraper] → [Cleaner] → [Exporter] → [Business-Plattform]
Planung und Überwachung
- Für Python: Nutze Cronjobs, Airflow oder Cloud-Scheduler, um Skripte regelmäßig laufen zu lassen. Protokolliere Ausgaben und verschicke E-Mail- oder Slack-Benachrichtigungen bei Fehlern.
- Für Thunderbit: Nutze den integrierten Scheduler – einfach „jeden Montag um 9 Uhr“ eintippen, und Thunderbit erledigt den Rest in der Cloud und exportiert die Daten dorthin, wo du sie brauchst.
Dokumentation und Übergabe
Lege deinen Code in einer Versionsverwaltung (z. B. Git) ab, dokumentiere den Workflow und sorge dafür, dass mindestens eine weitere Person weiß, wie die Pipeline läuft und aktualisiert wird. Bei gemischten Python/Thunderbit-Workflows notiere, welches Tool welche Seite übernimmt und wohin die Ergebnisse gehen (z. B. „Thunderbit extrahiert Site C nach Google Sheets, Python führt wöchentlich alle Daten zusammen“).
Ethik und Recht: Verantwortungsvolles Scraping 2025
Mit großer Scraping-Power kommt große Verantwortung. So bleibst du rechtlich und ethisch auf der sicheren Seite:
Robots.txt und Fairness
- robots.txt prüfen: Sieh dir immer die robots.txt der Seite an, um gesperrte Pfade und Crawl-Delays zu erkennen. Mit Pythons
robotparserlässt sich das automatisieren. - Höfliches Scraping: Baue Pausen zwischen den Anfragen ein, besonders wenn ein Crawl-Delay angegeben ist. Überlaste die Seite nie mit zu vielen Anfragen.
- User-Agent: Gib dich ehrlich zu erkennen. Tarn dich nicht als Googlebot oder Browser.
Datenschutz und Compliance
- DSGVO/CCPA: Sammelst du personenbezogene Daten (Namen, E-Mails, Telefonnummern), musst du sie gemäß Datenschutzgesetzen behandeln. Nur das Nötigste extrahieren, Daten sicher speichern und auf Anfrage löschen können.
- Nutzungsbedingungen: Scrape keine Inhalte hinter Logins ohne Erlaubnis. Viele Nutzungsbedingungen verbieten automatisierten Zugriff – Verstöße können zu Sperrungen oder Schlimmerem führen.
- Nur öffentliche Daten: Beschränke dich auf öffentlich zugängliche Informationen. Keine privaten, urheberrechtlich geschützten oder sensiblen Daten extrahieren.
Compliance-Checkliste
- robots.txt auf Regeln und Delays geprüft
- Fairen Rate-Limit und eigenen User-Agent gesetzt
- Nur öffentliche, nicht sensible Daten extrahiert
- Personenbezogene Daten datenschutzkonform behandelt
- Keine Verstöße gegen Nutzungsbedingungen oder Urheberrecht
Häufige Fehler und Debugging-Tipps: So wird dein Scraper robust
Auch die besten Scraper laufen mal gegen eine Wand. Das sind die häufigsten Fehler – und wie ich sie löse:
| Fehlertyp | Symptom/Meldung | Debugging-Tipp |
|---|---|---|
| HTTP 403/429/500 | Blockiert, Rate-Limit, Serverfehler | Header prüfen, langsamer werden, IPs rotieren oder Proxies nutzen. Crawl-Delays beachten. |
| Fehlende Daten/NoneType | Daten nicht im HTML gefunden | HTML ausgeben und prüfen. Vielleicht hat sich die Struktur geändert oder du bist auf einer Blockseite gelandet. |
| JavaScript-gerenderte Daten | Daten fehlen im statischen HTML | Selenium/Playwright nutzen oder die zugrundeliegende API suchen. |
| Parsing-/Encoding-Probleme | Unicode-Fehler, seltsame Zeichen | Korrekte Kodierung setzen, .text oder html.unescape() verwenden. |
| Duplikate/Inkonsistenzen | Wiederholte oder fehlerhafte Daten | Nach eindeutiger ID oder URL deduplizieren. Felder auf Vollständigkeit prüfen. |
| Anti-Bot/CAPTCHA | CAPTCHA-Seite oder Login erforderlich | Langsamer werden, Browser-Automatisierung nutzen oder für schwierige Fälle Thunderbit/KI einsetzen. |
Debugging-Workflow:
- Gib das rohe HTML aus, wenn etwas schiefgeht.
- Vergleiche mit den Browser-DevTools, was dein Skript sieht und was der Browser anzeigt.
- Logge jeden Schritt – URLs, Statuscodes, Anzahl der extrahierten Elemente.
- Teste erst mit einer kleinen Stichprobe, bevor du skalierst.
Fortgeschrittene Projektideen: So hebst du dein Python-Scraping aufs nächste Level
Lust, die Best Practices direkt umzusetzen? Hier ein paar Praxisprojekte:
1. Preisüberwachung für E-Commerce
Preise und Lagerbestände von Amazon, eBay und Walmart extrahieren. Anti-Bot-Maßnahmen und dynamische Inhalte meistern, täglich nach Google Sheets exportieren und Trends analysieren. Nutze Thunderbits Sofortvorlagen für schnelle Ergebnisse.
2. Jobbörsen-Aggregator
Stellenanzeigen von Indeed und Nischenportalen sammeln. Titel, Unternehmen, Standorte und Veröffentlichungsdaten extrahieren. Paginierung meistern und nach Job-ID deduplizieren. Tägliche Exporte nach Airtable planen.
3. Kontakt-Extraktor für Lead-Generierung
Aus einer Liste von Firmen-URLs E-Mails und Telefonnummern von Start- und Kontaktseiten extrahieren. Regex in Python oder Thunderbits kostenlose Extraktoren für Ein-Klick-Ergebnisse nutzen. Export nach Excel für das Vertriebsteam.
4. Immobilienanzeigen-Vergleich
Angebote von Zillow und Realtor.com für eine bestimmte Region scrapen. Adressen und Preise normalisieren, Trends vergleichen und Ergebnisse in Google Sheets visualisieren.
5. Social-Media-Mentions-Tracker
Markenerwähnungen auf Reddit über deren JSON-API verfolgen. Beitragszahlen aggregieren, Sentiment analysieren und Zeitreihendaten für Marketing-Insights exportieren.
Fazit: Die wichtigsten Erkenntnisse für Python-Scraping 2025
Die wichtigsten Punkte im Überblick:
- Web-Scraping ist wichtiger denn je für Business Intelligence, Vertrieb und Operations. Das Web ist eine Goldgrube – wenn du weißt, wie du sie erschließt.
- Python ist dein Allzweckwerkzeug: Starte einfach mit
requestsundBeautifulSoup, skaliere mit Scrapy und nutze Browser-Automatisierung für dynamische Seiten. - KI-Tools wie Thunderbit sind dein Geheimtipp für unstrukturierte, komplexe oder No-Code-Scraping-Aufgaben. Kombiniere Python und KI für maximale Effizienz.
- Best Practices entscheiden: Erst analysieren, modular coden, Fehler abfangen, Daten bereinigen und den Workflow automatisieren.
- Compliance ist Pflicht: Immer robots.txt prüfen, Datenschutzgesetze beachten und ethisch scrapen.
- Bleib flexibel: Das Web verändert sich – überwache deine Scraper, debugge regelmäßig und passe deine Strategie an.
Die Zukunft des Web-Scrapings ist hybrid, verantwortungsvoll und businessorientiert. Ob Einsteiger oder Profi: Bleib neugierig, lerne weiter und lass die Daten deinen nächsten Erfolg antreiben.
Anhang: Python-Scraping-Tutorials & Tools
Meine Favoriten zum Lernen und Troubleshooten:
- Requests Dokumentation – HTTP für Menschen, mit allen Extras.
- BeautifulSoup Doku – HTML-Parsing wie ein Profi lernen.
- Scrapy Dokumentation – Für große, produktive Scraping-Projekte.
- Selenium mit Python / Playwright für Python – Für Browser-Automatisierung und dynamische Inhalte.
- Thunderbit Chrome Extension – Der einfachste KI-Web-Scraper für Business-Anwender.
- Thunderbit Blog – Tutorials, Praxisbeispiele und Best Practices für KI-gestütztes Scraping.
- AIMultiple’s Legal Guide – Immer auf dem neuesten Stand zu Compliance und Ethik.
- Stack Overflow / Reddit r/webscraping** – Community-Fragen und Troubleshooting.
Und wenn du sehen willst, wie Thunderbit dein Scraping wirklich vereinfacht, schau auf unserem YouTube-Kanal vorbei – dort gibt’s Demos und Deep Dives.
FAQs
1. Welche Python-Bibliothek ist 2025 am besten für Web-Scraping?
Für statische Seiten und kleine Aufgaben bleibt requests + BeautifulSoup die erste Wahl. Für große oder mehrseitige Scrapes ist Scrapy optimal. Für dynamische Inhalte nutze Selenium oder Playwright. Für unstrukturierte oder schwierige Daten sind KI-Tools wie Thunderbit unschlagbar.
2. Wie gehe ich mit JavaScript-lastigen oder dynamischen Seiten um?
Nutze Browser-Automatisierung wie Selenium oder Playwright, um die Seite zu rendern und Daten zu extrahieren. Alternativ: Im Netzwerk-Tab nach API-Calls suchen, die JSON liefern – das ist oft einfacher und stabiler zu scrapen.
3. Ist Web-Scraping legal?
Das Extrahieren öffentlicher Daten ist in den USA meist legal, aber prüfe immer die robots.txt, beachte die Nutzungsbedingungen und halte dich an Datenschutzgesetze wie DSGVO/CCPA. Niemals private, urheberrechtlich geschützte oder sensible Daten scrapen.
4. Wie kann ich meine Scraping-Workflows automatisieren und planen?
Für Python-Skripte nutze Cronjobs, Airflow oder Cloud-Scheduler. Für No-Code-Automatisierung bietet Thunderbit einen integrierten Scheduler – einfach Zeitplan in Klartext eingeben und die Cloud erledigt den Rest.
5. Was tun, wenn mein Scraper nicht mehr funktioniert?
Prüfe zuerst, ob sich die Website-Struktur geändert hat oder ob du blockiert wirst (HTTP 403/429). HTML inspizieren, Selektoren anpassen, Anfragen verlangsamen und auf Anti-Bot-Maßnahmen achten. Bei hartnäckigen Problemen Thunderbits KI-Features oder Browser-Automatisierung nutzen.
Viel Erfolg beim Scrapen – möge deine Datenquelle immer sauber, compliant und einsatzbereit sein. Wenn du sehen willst, wie Thunderbit in deinen Workflow passt, lade die Chrome-Erweiterung herunter und probiere es aus. Und für noch mehr Tipps ist der Thunderbit Blog immer einen Besuch wert.
Thunderbit KI-Web-Scraper kostenlos testen Get Started Free




