
Das Internet ist heutzutage ein riesiger, visueller Spielplatz – jeden Tag werden unzählige Bilder hochgeladen, die alles von Online-Shops bis hin zu viralen Memes befeuern. Wer im Vertrieb, Marketing oder in der Forschung unterwegs ist, weiß, wie nervig es sein kann, Bilder manuell zu sammeln. Ich selbst habe schon oft im „Rechtsklick, Bild speichern unter“-Hamsterrad festgesteckt und mich gefragt: Muss das wirklich so umständlich sein? Die gute Nachricht: Es geht viel einfacher! Mit einem Python Bild-Web-Scraper oder No-Code-Tools wie kannst du Bilder in Massen runterladen – ganz ohne Stress.
In dieser Anleitung zeige ich dir, wie du mit Python Bilder von Webseiten ziehst, auch bei dynamischen Seiten nicht ins Schwitzen kommst und warum die Kombi aus Python und Thunderbit dir maximale Flexibilität bringt. Egal, ob du einen Produktkatalog aufbauen willst, Wettbewerber analysierst oder einfach keine Lust mehr auf Copy-Paste hast – hier bekommst du praktische Schritte, Beispielcode und ein paar Schmunzler obendrauf.
Was ist ein Python Bild-Web-Scraper?
Ein Python Bild-Web-Scraper ist ein Skript oder Tool, das automatisch Webseiten besucht, Bilddateien (z. B. aus <img>-Tags) erkennt und sie gesammelt auf deinen Rechner lädt. Statt jedes Bild einzeln zu speichern, übernimmt Python die Arbeit: Seiten abrufen, HTML analysieren und Bilder in großen Mengen sichern ().
Wer nutzt Python Bild-Scraper? Eigentlich alle, die schnell viele Bilder brauchen:
- E-Commerce-Teams: Produktbilder von Lieferantenseiten für Kataloge herunterladen.
- Marketing-Profis: Social-Media-Bilder für Kampagnen oder Trendanalysen sammeln.
- Forschende: Datensätze für KI/ML-Projekte oder Studien aufbauen.
- Immobilienmakler: Objektfotos für Exposés oder Marktanalysen zusammentragen.
Stell dir einen Python Bild-Scraper wie einen digitalen Praktikanten vor – nur dass er nie müde wird oder sich von Katzenvideos ablenken lässt.
Warum Python für das Scraping von Bildern?
 Python ist das Schweizer Taschenmesser, wenn es ums Web-Scraping geht. Hier die wichtigsten Vorteile beim Bilder-Scraping:
Python ist das Schweizer Taschenmesser, wenn es ums Web-Scraping geht. Hier die wichtigsten Vorteile beim Bilder-Scraping:
- Starke Bibliotheken: Mit Requests, BeautifulSoup und Selenium bist du für alles gerüstet – von simplen HTML-Seiten bis zu komplexen, JavaScript-lastigen Webseiten ().
- Einfacher Einstieg: Die Syntax ist super verständlich, es gibt massig Tutorials und eine riesige Community.
- Flexibel und skalierbar: Egal ob eine Seite oder tausende – du kannst Downloads automatisieren und Bilder easy nachbearbeiten.
- Spart Zeit und Nerven: Ein Test hat gezeigt: 100 Bilder mit Python zu scrapen dauert ca. 12 Minuten – per Hand wären es 2 Stunden ().
Hier ein Überblick über typische Business-Anwendungen:
| Anwendungsfall | Manueller Aufwand | Vorteil mit Python-Scraper |
|---|---|---|
| Produktkataloge | Stundenlanges Kopieren | Tausende Bilder in Minuten sichern |
| Wettbewerbsanalyse | Langsam, unvollständig | Bilder im Bulk direkt vergleichen |
| Trendforschung | Lückenhafte Datensätze | Große, vielfältige Bildsammlung |
| KI/ML-Datensätze | Aufwendiges Labeln | Automatisierte Sammlung & Vorbereitung |
| Immobilienanzeigen | Veraltete, verstreute Fotos | Fotos zentralisieren & aktualisieren |
Die wichtigsten Python-Tools fürs Bild-Scraping
Hier sind die wichtigsten Python-Bibliotheken, wenn du Bilder scrapen willst:
| Bibliothek | Funktion | Einsatzgebiet | Vorteile | Nachteile |
|---|---|---|---|---|
| Requests | Ruft Webseiten und Bilder per HTTP ab | Statische Seiten | Einfach, schnell | Kein HTML-Parsing, kein JS |
| BeautifulSoup | Parst HTML, findet <img>-Tags | Bild-URLs extrahieren | Leicht zu nutzen, fehlertolerant | Kein JS-Support |
| Scrapy | Framework für Scraping & Crawling | Große Projekte | Asynchron, Export integriert | Höhere Einstiegshürde |
| Selenium | Automatisiert Browser (JS, Scrollen) | Dynamische/JS-Seiten | Rendert JS, simuliert Nutzer | Langsamer, mehr Setup |
| Pillow (PIL) | Bildbearbeitung nach dem Download | Bildprüfung/-bearbeitung | Größe ändern, konvertieren, prüfen | Nicht fürs Scraping selbst |
Wann welches Tool?
- Für die meisten statischen Seiten:
requests + BeautifulSoupist der Klassiker. - Für dynamische Seiten (Endlos-Scroll, JS-Galerien):
Seleniumist dein Freund. - Für große, wiederkehrende Projekte:
Scrapybringt Struktur und Speed. - Für Bildbearbeitung:
Pillowhilft beim Nachbereiten.
Schritt für Schritt: Bilder mit Python von einer Webseite herunterladen
Jetzt wird’s praktisch! So holst du dir Bilder von einer statischen Webseite mit Python.
Python-Umgebung einrichten
Check, ob Python 3 installiert ist. Optional kannst du ein virtuelles Environment nutzen:
1python3 -m venv venv
2source venv/bin/activate # Unter Windows: venv\Scripts\activateInstalliere die nötigen Bibliotheken:
1pip install requests beautifulsoup4Bild-URLs finden und extrahieren
Öffne die Zielseite im Browser. Mit Rechtsklick und „Untersuchen“ findest du die <img>-Tags – das sind deine Ziele.
Beispielskript zum Extrahieren der Bild-URLs:
1import requests
2from bs4 import BeautifulSoup
3from urllib.parse import urljoin
4import os
5url = "https://example.com"
6response = requests.get(url)
7soup = BeautifulSoup(response.text, "html.parser")
8img_tags = soup.find_all("img")
9img_urls = [urljoin(url, img.get("src")) for img in img_tags if img.get("src")]Tipp: Manche Seiten nutzen data-src oder srcset für Lazy-Loading. Schau dir auch diese Attribute an.
Bilder herunterladen und speichern
So speicherst du die Bilder in einem Ordner:
1os.makedirs("images", exist_ok=True)
2for i, img_url in enumerate(img_urls):
3 try:
4 img_resp = requests.get(img_url, headers={"User-Agent": "Mozilla/5.0"})
5 if img_resp.status_code == 200:
6 file_ext = img_url.split('.')[-1].split('?')[0]
7 file_name = f"images/img_{i}.{file_ext}"
8 with open(file_name, "wb") as f:
9 f.write(img_resp.content)
10 print(f"Downloaded {file_name}")
11 except Exception as e:
12 print(f"Failed to download {img_url}: {e}")Tipps zur Organisation:
- Benenne Dateien nach Produkt-IDs oder Seitentiteln, wenn möglich.
- Nutze Unterordner für verschiedene Kategorien oder Quellen.
- Prüfe auf Duplikate vor dem Speichern (z. B. per URL oder Hash).
Häufige Fehler und Troubleshooting
- Fehlende Bilder? Sie werden evtl. per JavaScript geladen – siehe nächster Abschnitt.
- Blockierte Anfragen? Setze einen realistischen User-Agent und baue Pausen (
time.sleep()) zwischen den Downloads ein. - Doppelte Downloads? Führe eine Liste bereits geladener URLs oder Dateinamen.
- Berechtigungsfehler? Stelle sicher, dass dein Skript Schreibrechte für den Zielordner hat.
Bilder von dynamischen und JavaScript-lastigen Seiten scrapen
Manche Webseiten verstecken ihre Bilder hinter JavaScript, Endlos-Scroll oder „Mehr laden“-Buttons. Mit Selenium kommst du trotzdem ran.
Selenium für dynamische Inhalte nutzen
Installiere zuerst Selenium und einen Browser-Treiber (z. B. ChromeDriver):
1pip install seleniumLade herunter und füge ihn deinem PATH hinzu.
Beispielskript mit Selenium:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3import time
4import os
5driver = webdriver.Chrome()
6driver.get("https://example.com/gallery")
7# Nach unten scrollen, um mehr Bilder zu laden
8last_height = driver.execute_script("return document.body.scrollHeight")
9while True:
10 driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
11 time.sleep(2) # Warten, bis Bilder geladen sind
12 new_height = driver.execute_script("return document.body.scrollHeight")
13 if new_height == last_height:
14 break
15 last_height = new_height
16img_elements = driver.find_elements(By.TAG_NAME, "img")
17img_urls = [img.get_attribute("src") for img in img_elements if img.get_attribute("src")]
18os.makedirs("dynamic_images", exist_ok=True)
19for i, img_url in enumerate(img_urls):
20 # (Download-Logik wie oben)
21 pass
22driver.quit()Tipps:
- Mit
WebDriverWaitkannst du gezielt auf das Laden von Bildern warten. - Müssen Bilder erst per Klick sichtbar werden, nutze
element.click().
Alternativen: Tools wie Playwright (Python-Bindings) sind für komplexe Seiten oft schneller und stabiler ().
No-Code-Alternative: Bilder mit Thunderbit extrahieren
Nicht jeder hat Lust auf Code oder Browser-Treiber. Hier kommt ins Spiel – eine No-Code, KI-gestützte Web-Scraper Chrome-Erweiterung, mit der du Bilder so easy extrahierst wie Essen bestellen.
So extrahierst du Bilder mit Thunderbit
- Thunderbit installieren: Lade die herunter.
- Zielseite öffnen: Gehe auf die Seite mit den gewünschten Bildern.
- Thunderbit starten: Klicke auf das Erweiterungs-Icon, um die Sidebar zu öffnen.
- AI Suggest Fields: Klicke auf „AI Suggest Fields“ – Thunderbits KI scannt die Seite, erkennt automatisch Bilder und erstellt eine „Bild“-Spalte ().
- Scrapen: Klicke auf „Scrape“. Thunderbit sammelt alle Bilder, auch von Unterseiten oder bei Endlos-Scroll.
- Exportieren: Lade Bild-URLs oder Dateien direkt nach Excel, Google Sheets, Notion, Airtable oder als CSV herunter – kostenlos, auch im Free-Tarif.
Extra: Mit dem kostenlosen Image Extractor von Thunderbit kannst du alle Bild-URLs einer Seite mit nur einem Klick erfassen ().
Warum Thunderbit überzeugt:
- Kein Programmieren oder HTML-Kenntnisse nötig.
- Erkennt dynamische Inhalte, Unterseiten und Paginierung automatisch.
- Export ist sofort und unbegrenzt möglich (auch im Free-Plan).
- Die KI passt sich Webseitenänderungen an – kein Wartungsaufwand.
Python und Thunderbit kombinieren: Das Beste aus beiden Welten
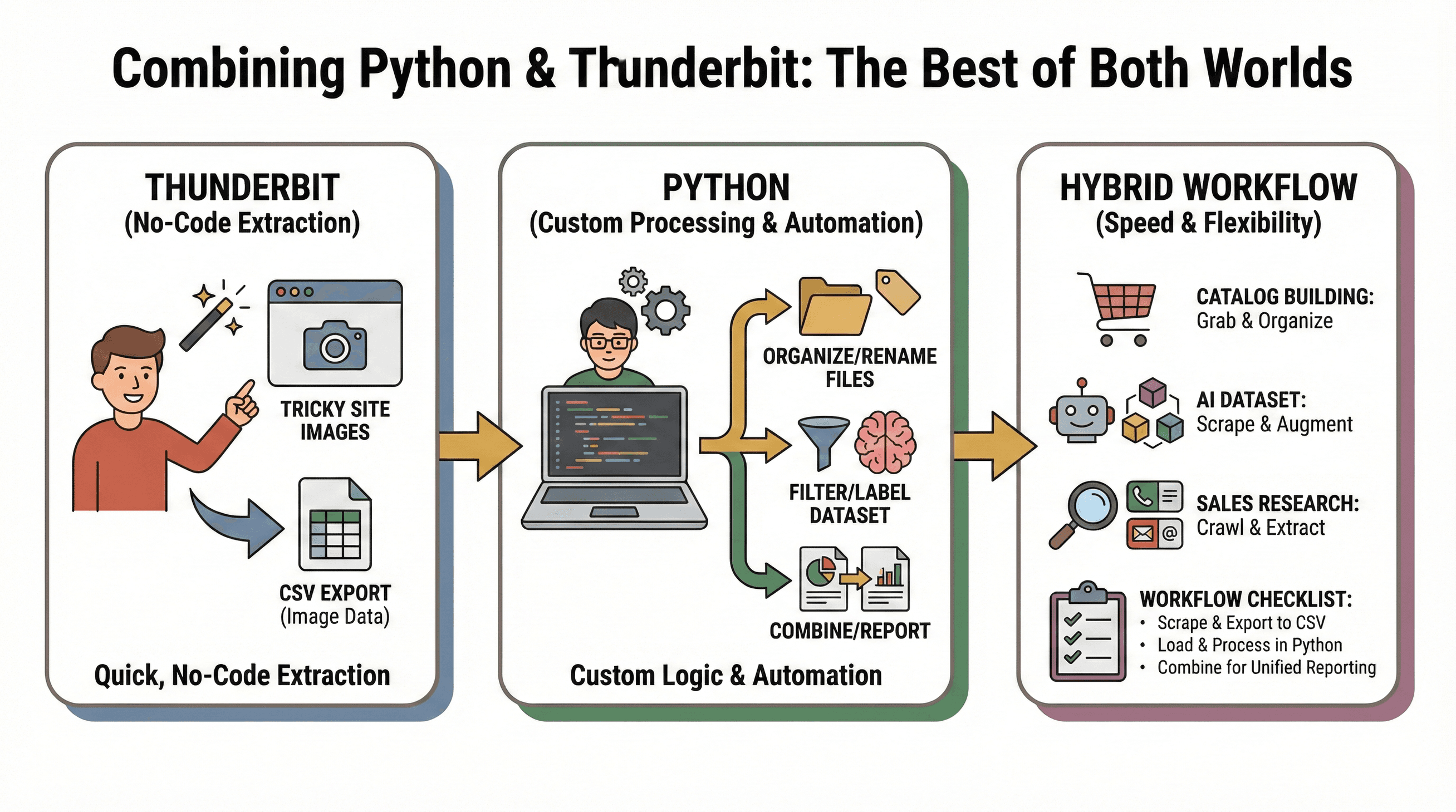 Mein Lieblings-Workflow: Mit Thunderbit schnell und ohne Code Bilder extrahieren, mit Python individuell weiterverarbeiten oder automatisieren.
Mein Lieblings-Workflow: Mit Thunderbit schnell und ohne Code Bilder extrahieren, mit Python individuell weiterverarbeiten oder automatisieren.
Beispiel-Szenarien:
- Katalogaufbau: Mit Thunderbit Bilder von einer schwierigen Seite holen, dann mit Python sortieren, umbenennen oder weiterverarbeiten.
- KI-Datensätze: Thunderbit sammelt Bilder aus verschiedenen Quellen, Python filtert, labelt oder erweitert den Datensatz.
- Vertriebsrecherche: Python crawlt eine Liste von Firmen-URLs, Thunderbit extrahiert Bilder, E-Mails oder Telefonnummern von jeder Seite.
Workflow-Checkliste:
- Mit Thunderbit Bilder scrapen und als CSV exportieren.
- Die CSV in Python für weitere Analysen oder Automatisierung laden.
- Daten aus verschiedenen Quellen kombinieren und zentral auswerten.
Mit diesem hybriden Ansatz bist du schnell, flexibel und für jede Web-Scraping-Herausforderung rund um Bilder bestens gerüstet.
Troubleshooting & Best Practices beim Python Bild-Scraping
Typische Probleme:
- Blockierte Anfragen: Setze einen User-Agent, baue Pausen ein und beachte die
robots.txt. - Fehlende Bilder: Prüfe, ob Inhalte per JS geladen werden – nutze ggf. Selenium oder Thunderbit.
- Doppelte Downloads: Verwalte bereits geladene URLs oder nutze Dateihashes.
- Defekte Dateien: Mit Pillow kannst du Bilder nach dem Download prüfen.
Best Practices:
- Organisiere Bilder in klaren Ordnerstrukturen (nach Seite, Kategorie oder Datum).
- Verwende sprechende Dateinamen (z. B. Produkt-IDs, Seitentitel).
- Filtere irrelevante Bilder (z. B. Werbebanner, Icons) nach Dateigröße oder Abmessungen aus.
- Prüfe immer Urheberrecht und Nutzungsbedingungen, bevor du Bilder scrapest ().
Python Bild-Scraper im Vergleich: Code vs. No-Code
Hier ein direkter Vergleich der Möglichkeiten:
| Kriterium | Python (Requests/BS) | Selenium (Python) | Thunderbit (No-Code) |
|---|---|---|---|
| Bedienkomfort | Mittel (Programmierung nötig) | Anspruchsvoll (Code + Browser) | Sehr einfach (Klick & KI) |
| Dynamische Inhalte | Nein | Ja | Ja |
| Einrichtungszeit | Länger (Installation, Code) | Lang (Treiber, Code) | Sehr kurz (Erweiterung) |
| Skalierbarkeit | Manuell (parallelisierbar) | Langsam (Browser-Overhead) | Hoch (Cloud-Scraping, 50 Seiten gleichzeitig) |
| Wartung | Hoch (Skripte brechen bei Änderungen) | Hoch | Gering (KI passt sich an) |
| Exportoptionen | Individuell (CSV, DB) | Individuell | Ein Klick zu Excel, Sheets, Notion etc. |
| Kosten | Kostenlos (Open Source) | Kostenlos | Free-Tarif, kostenpflichtig bei hohem Volumen |
Fazit: Wer gerne programmiert und volle Kontrolle will, ist mit Python bestens bedient. Für Tempo, Einfachheit und dynamische Seiten ist Thunderbit unschlagbar. Die meisten profitieren von der Kombination beider Ansätze.
Fazit & wichtigste Erkenntnisse
Die Bilderflut im Web macht Bilddaten wertvoller – und unübersichtlicher – denn je. Mit Python Bild-Scrapern automatisierst du Downloads flexibel, No-Code-Tools wie Thunderbit machen das Extrahieren für alle zugänglich.
Das Wichtigste auf einen Blick:
- Nutze Python (Requests + BeautifulSoup) für statische Seiten und individuelle Workflows.
- Setze Selenium für dynamische, JavaScript-lastige Seiten ein.
- Thunderbit ist ideal für schnelles, codefreies Extrahieren – besonders bei schwierigen Seiten oder wenn du Bilder direkt nach Excel, Google Sheets oder Notion exportieren willst.
- Die Kombination aus beiden bringt maximale Effizienz: Thunderbit für die Datensammlung, Python für die Weiterverarbeitung und Automatisierung.
Bereit, dein Bild-Scraping aufs nächste Level zu bringen? Schreib ein einfaches Python-Skript oder und spare dir jede Menge Zeit. Noch mehr Tipps und Anleitungen findest du im und im .
Viel Spaß beim Scrapen – und möge dein Bilder-Ordner immer schön sortiert bleiben!
FAQs
1. Was ist ein Python Bild-Scraper?
Ein Python Bild-Scraper ist ein Skript oder Tool, das automatisch Webseiten besucht, Bilddateien (meist aus <img>-Tags) erkennt und sie gesammelt auf deinen Rechner lädt. So sparst du dir das manuelle Speichern einzelner Bilder.
2. Welche Python-Bibliotheken eignen sich am besten fürs Bild-Scraping?
Die beliebtesten Bibliotheken sind Requests (für das Abrufen von Webseiten), BeautifulSoup (für das Parsen von HTML), Selenium (für dynamische Inhalte) und Pillow (für die Bildbearbeitung nach dem Download).
3. Wie kann ich Bilder von JavaScript-lastigen oder Endlos-Scroll-Seiten scrapen?
Nutze Selenium, um einen Browser zu automatisieren, die Seite zu scrollen und Bild-URLs nach dem Laden aller Inhalte zu extrahieren. Thunderbit kann dynamische Inhalte dank KI ebenfalls automatisch erfassen.
4. Gibt es eine No-Code-Lösung zum Scrapen von Bildern?
Ja! Thunderbit ist eine No-Code Chrome-Erweiterung, die mit KI Bilder auf jeder Webseite erkennt und extrahiert. Einfach Seite öffnen, klicken und nach Excel, Google Sheets, Notion oder Airtable exportieren.
5. Kann ich Python und Thunderbit fürs Bild-Scraping kombinieren?
Absolut. Nutze Thunderbit für schnelle, codefreie Extraktion und Python für fortgeschrittene Verarbeitung oder Automatisierung. Exportiere die Daten aus Thunderbit und verarbeite sie mit Python-Skripten weiter – so hast du das Beste aus beiden Welten.
Mehr erfahren