

Niemand steht morgens auf und freut sich darauf, 500 Zeilen Produktpreise per Copy-and-paste in eine Tabelle zu übertragen. (Wer es trotzdem tut, hat meinen Respekt – und sollte über eine gute Handgelenkbandage nachdenken.) Ob Sie im Vertrieb arbeiten, in den Operations oder Ihr Unternehmen schlicht einen Schritt vor der Konkurrenz halten wollen: Das mühsame Sammeln von Website-Daten kennen Sie wahrscheinlich aus eigener Erfahrung. Die Wirtschaft läuft heute auf Web-Daten, und die Nachfrage nach automatisierter Extraktion explodiert förmlich – der Markt für Web-Scraping-Software soll bis 2032 auf über 11 Milliarden US-Dollar (ca. 10 Milliarden Euro) wachsen.
Ich habe jahrelang im Maschinenraum von SaaS und Automatisierung gearbeitet und dort so ziemlich alles gesehen: von heroischen Excel-Makros bis zu Python-Skripten, die um 2 Uhr nachts mit Klebeband zusammengeflickt wurden. In diesem Leitfaden zeige ich Ihnen, wie Sie mit einem Python-HTML-Parser echte Daten scrapen (ja, wir holen uns gemeinsam IMDb-Filmbewertungen), und ich erkläre Ihnen außerdem, warum es 2026 einen besseren Weg gibt – KI-gestützte Tools wie Thunderbit, mit denen Sie den Code überspringen und direkt zu den Erkenntnissen kommen.
Was ist ein HTML-Parser und warum sollte man in Python einen verwenden?
Fangen wir ganz vorne an: Was macht ein HTML-Parser eigentlich? Stellen Sie ihn sich als Ihren persönlichen Bibliothekar fürs Web vor. Er liest den unübersichtlichen HTML-Code hinter einer Webseite und ordnet ihn in eine saubere, baumartige Struktur. So können Sie genau die Daten herausziehen, die Sie brauchen – Titel, Preise, Links – ohne sich in einem Meer aus spitzen Klammern und divs zu verlieren.
Python ist dafür die erste Wahl – und das aus gutem Grund. Die Sprache ist gut lesbar, einsteigerfreundlich und verfügt über ein riesiges Ökosystem an Bibliotheken für Web-Scraping und Parsing. Tatsächlich ist Python mit Abstand die beliebteste Sprache für Web Scraping, dank der sanften Lernkurve und der starken Community-Unterstützung.
Die wichtigsten Python-HTML-Parser im Überblick
Das sind die Hauptkandidaten, auf die Sie beim HTML-Parsing in Python stoßen werden:
- BeautifulSoup: Der Klassiker und die einsteigerfreundliche Wahl. Wird weiterhin aktiv gepflegt —
beautifulsoup44.14.3 wurde Ende 2025 auf PyPI veröffentlicht — Sie lernen hier also keine veraltete Bibliothek. - lxml: Schnell und leistungsstark, mit erweiterten Abfragen.
- html5lib: Extrem tolerant gegenüber unsauberem HTML, genau wie Ihr Browser.
- PyQuery: Ermöglicht jQuery-ähnliche Selektoren in Python.
- HTMLParser: Der eingebaute Parser von Python – immer da, aber eher minimalistisch.
Jede dieser Lösungen hat ihre Eigenheiten, aber alle helfen Ihnen dabei, rohes HTML in strukturierte Daten zu verwandeln.
Wichtige Anwendungsfälle: Wie Unternehmen von Python-HTML-Parsern profitieren
Die Extraktion von Web-Daten ist längst nicht mehr nur etwas für Techies oder Data Scientists. Sie ist zu einer zentralen Geschäftsaktivität geworden, besonders in Vertrieb und Operations. Darum geht es:
| Anwendungsfall (Branche) | Typischer extrahierter Datentyp | Geschäftlicher Nutzen |
|---|---|---|
| Preisüberwachung (Einzelhandel) | Konkurrenzpreise, Lagerbestände | Dynamische Preisgestaltung, bessere Margen (Quelle) |
| Produktintelligenz für Wettbewerber | Angebote, Bewertungen, Verfügbarkeit | Lücken erkennen, Leads generieren (Quelle) |
| Lead-Generierung (B2B-Vertrieb) | Firmennamen, E-Mails, Kontakte | Automatisierte Neukundenansprache, wachsender Vertriebstrichter (Quelle) |
| Marktstimmung (Marketing) | Social-Media-Beiträge, Bewertungen, Rezensionen | Echtzeit-Feedback, Trend-Erkennung (Quelle) |
| Aggregation von Immobilienangeboten | Inserate, Preise, Maklerinformationen | Marktanalyse, Preisstrategie (Quelle) |
| Recruiting-Intelligence | Kandidatenprofile, Gehälter | Talentgewinnung, Gehaltsbenchmarking (Quelle) |
Kurz gesagt: Wer Daten noch manuell kopiert, verschenkt Zeit und Geld.
Das Python-HTML-Parser-Toolkit im Vergleich: Beliebte Bibliotheken
Jetzt wird’s praktisch. Hier ist ein kurzer Vergleich der beliebtesten Python-HTML-Parser-Bibliotheken, damit Sie das richtige Tool für Ihre Aufgabe auswählen können:
| Bibliothek | Einfachheit der Nutzung | Geschwindigkeit | Flexibilität | Wartungsaufwand | Am besten geeignet für |
|---|---|---|---|---|---|
| BeautifulSoup | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | Mittel | Einsteiger, unübersichtliches HTML |
| lxml | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Mittel | Geschwindigkeit, XPath, große Dokumente |
| html5lib | ⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | Gering | Browserähnliches Parsing, fehlerhaftes HTML |
| PyQuery | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | Mittel | jQuery-Fans, CSS-Selektoren |
| HTMLParser | ⭐⭐⭐ | ⭐⭐⭐ | ⭐ | Gering | Einfache, eingebaute Aufgaben |
BeautifulSoup: Die einsteigerfreundliche Wahl
BeautifulSoup ist beim HTML-Parsing das, was „Hello World“ beim Programmieren ist – der natürliche erste Schritt. Die Syntax ist intuitiv, die Dokumentation stark, und die Bibliothek verzeiht auch hässliches, fehlerhaftes HTML (mehr dazu). Der Nachteil? Sie ist nicht die schnellste, vor allem nicht bei großen oder komplexen Seiten, und unterstützt erweiterte Selektoren wie XPath nicht standardmäßig.
lxml: Schnell und leistungsstark
Wenn Sie Geschwindigkeit brauchen oder XPath-Abfragen verwenden möchten, ist lxml Ihr Freund (Details). Die Bibliothek basiert auf C-Bibliotheken und ist dadurch extrem schnell, kann aber schwieriger zu installieren sein und hat eine steilere Lernkurve.
Weitere Optionen: html5lib, PyQuery und HTMLParser
- html5lib: Parst HTML genau wie Ihr Browser – ideal für kaputtes oder seltsames Markup, aber langsam (Vergleich).
- PyQuery: Ermöglicht jQuery-ähnliche Selektoren in Python, was praktisch ist, wenn Sie aus dem Frontend-Bereich kommen (siehe Docs).
- HTMLParser: Die eingebaute Option von Python – schnell und immer verfügbar, aber nicht ganz so funktionsreich.
Schritt 1: Ihre Python-HTML-Parser-Umgebung einrichten
Bevor Sie irgendetwas parsen können, müssen Sie Ihre Python-Umgebung einrichten. So geht’s:
-
Python installieren: Laden Sie es von python.org herunter, falls Sie es noch nicht haben.
-
pip installieren: Kommt normalerweise mit Python 3.4+ mit, Sie können es aber mit
pip --versionim Terminal prüfen. -
Die Bibliotheken installieren (wir verwenden für dieses Tutorial BeautifulSoup und requests):
pip install beautifulsoup4 requests lxmlbeautifulsoup4ist der Parser.requestslädt Webseiten herunter.lxmlist ein schneller Parser, den BeautifulSoup im Hintergrund verwenden kann.
-
Installation überprüfen:
python -c "import bs4, requests, lxml; print('All good!')"
Tipps zur Fehlersuche:
- Wenn Sie Berechtigungsfehler erhalten, versuchen Sie
pip install --user ... - Auf Mac/Linux benötigen Sie möglicherweise statt dessen
python3undpip3. - Wenn „ModuleNotFoundError“ erscheint, prüfen Sie Schreibweise und Python-Umgebung noch einmal.
Schritt 2: Ihre erste Webseite mit Python parsen
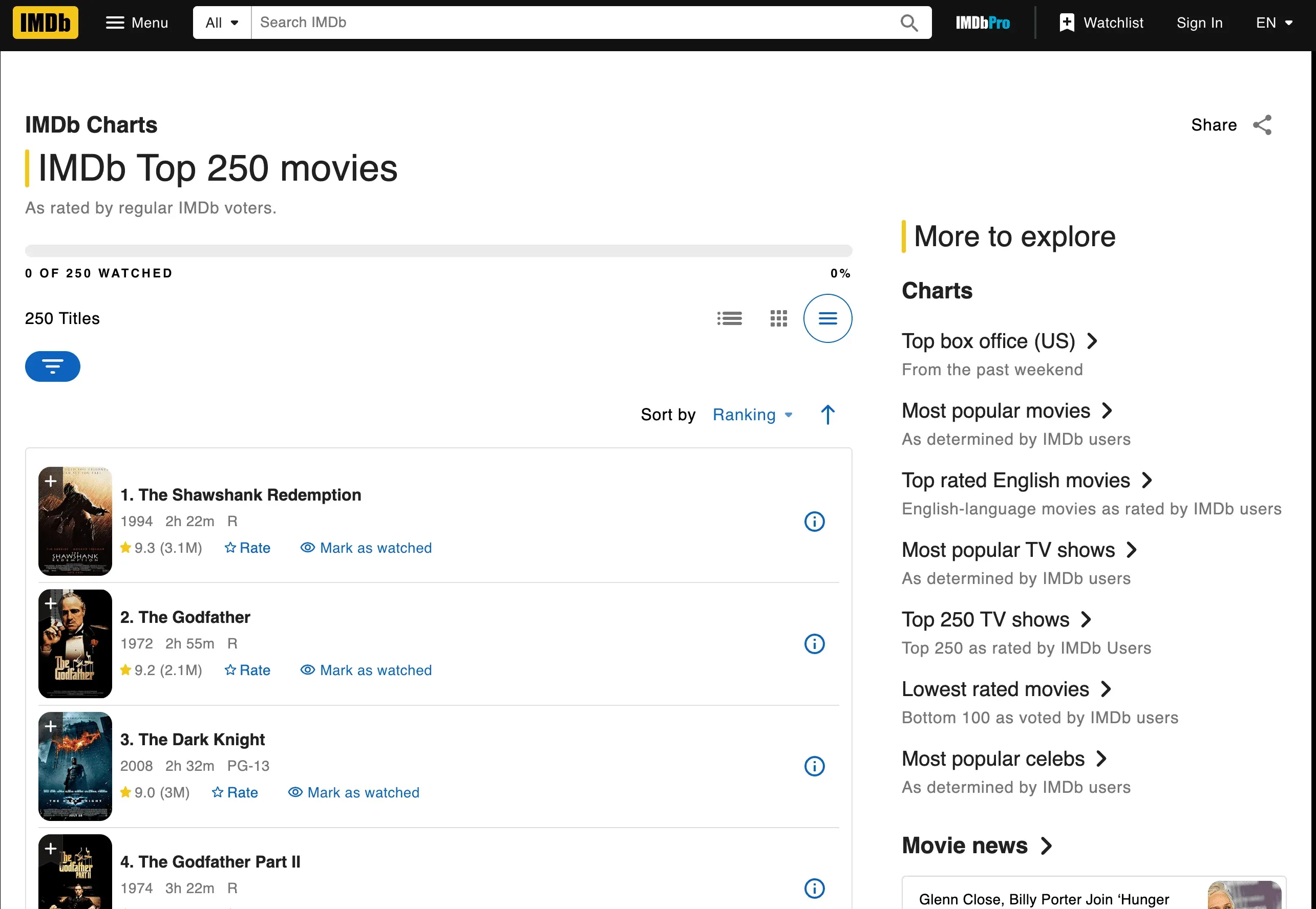
Jetzt geht es ans Eingemachte: Wir scrapen die IMDb Top 250 Filme und holen uns die Filmtitel, Jahre und Bewertungen.
Die Seite abrufen und parsen
Hier ist ein Skript Schritt für Schritt. Kurzer Hinweis, bevor Sie es kopieren: IMDb hat die Top-250-Seite im Juni 2023 neu gestaltet, sodass die alten Selektoren td.titleColumn / td.ratingColumn, die Sie in älteren Tutorials noch sehen, inzwischen nichts mehr finden. Das aktuelle Markup verwendet ipc--Präfixe, die vom Komponenten-System generiert werden, und IMDb hat die Seite seitdem noch einige weitere Male umgebaut (einschließlich Mitte 2025), also planen Sie ein, jedes Mal mit den DevTools neu hineinzuschauen, wenn Sie zu diesem Beispiel zurückkehren.
import requests
from bs4 import BeautifulSoup
url = "https://www.imdb.com/chart/top/"
headers = {"User-Agent": "Mozilla/5.0"} # IMDb liefert ohne echten UA nur spärliches Markup aus
resp = requests.get(url, headers=headers)
soup = BeautifulSoup(resp.text, "html.parser")
# Jede Zeile ist ein Listenelement im Chart-Container
rows = soup.select("li.ipc-metadata-list-summary-item")
for i, row in enumerate(rows[:3], start=1):
title_el = row.select_one("h3.ipc-title__text")
year_el = row.select_one("span.cli-title-metadata-item")
rating_el = row.select_one("span.ipc-rating-star--rating")
title = title_el.get_text(strip=True) if title_el else None
# Der h3-Text kommt als "1. The Shawshank Redemption" zurück — die Rangnummer entfernen
if title and ". " in title:
title = title.split(". ", 1)[1]
year = year_el.get_text(strip=True) if year_el else None
rating = rating_el.get_text(strip=True) if rating_el else None
print(f"{i}. {title} ({year}) -- Rating: {rating}")
Was passiert hier?
- Wir verwenden
requests.get(), um die Seite abzurufen (mit einem realistisch wirkendenUser-Agent– IMDb liefertpython-requests-Clients manchmal nur ein reduziertes Grundgerüst aus). BeautifulSoupparst das HTML.- Wir greifen über
li.ipc-metadata-list-summary-itemauf jede Filmzeile zu und ziehen dann mitselect_one()Titel (h3.ipc-title__text), Jahr (span.cli-title-metadata-item) und Bewertung (span.ipc-rating-star--rating) heraus. - Wir extrahieren den Text für Titel, Jahr und Bewertung und entfernen die führende Rangnummer (
"1. "), die IMDb in den Titeltext einbettet.
Wenn Sie etwas Dauerhaftes wollen, statt alle paar Monate wechselnden Klassennamen hinterherzulaufen, liefert IMDb auf derselben Seite auch einen <script type="application/ld+json">-Block mit denselben Daten in strukturierter Form aus – Sie können ihn mit json.loads(soup.find("script", type="application/ld+json").string) parsen und das Array itemListElement durchlaufen. Das wäre mein Ansatz in der Produktion; die CSS-Selektor-Variante oben ist leichter zu erklären, aber deutlich fragiler.
Ausgabe:
1. The Shawshank Redemption (1994) -- Rating: 9.3
2. The Godfather (1972) -- Rating: 9.2
3. The Dark Knight (2008) -- Rating: 9.0
Daten extrahieren: Titel, Bewertungen und mehr finden
Woher wusste ich, welche Tags und Klassen ich verwenden musste? Ich habe mir das HTML der IMDb-Seite angesehen (Rechtsklick > Element untersuchen in Ihrem Browser). Achten Sie auf Muster – hier sitzt jede Filmzeile in einem <li class="ipc-metadata-list-summary-item">, der Titel steckt unter <h3 class="ipc-title__text"> und die Bewertung unter <span class="ipc-rating-star--rating">. Ein wichtiger Hinweis: IMDb hat dieses Markup schon mehr als einmal umgestellt (das td.titleColumn-Layout, das Sie noch in älteren Anleitungen finden, funktioniert seit dem Redesign im Juni 2023 nicht mehr), also behandeln Sie die exakten Klassennamen immer nur als Beispiel und schauen Sie vor dem Ausführen des Skripts noch einmal nach.
Profi-Tipp: Wenn Sie eine andere Website scrapen, beginnen Sie immer damit, die HTML-Struktur zu inspizieren und eindeutige Klassennamen oder Tags zu identifizieren.
Ihre Ergebnisse speichern und exportieren
Speichern wir unsere Daten in einer CSV-Datei:
import csv
movies = []
for i in range(len(title_cells)):
title_cell = title_cells[i]
rating_cell = rating_cells[i]
title = title_cell.a.text
year = title_cell.span.text.strip("()")
rating = rating_cell.strong.text if rating_cell.strong else rating_cell.text
movies.append([title, year, rating])
with open('imdb_top250.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['Title', 'Year', 'Rating'])
writer.writerows(movies)
Bereinigungstipps:
- Verwenden Sie
.strip(), um Leerzeichen zu entfernen. - Behandeln Sie fehlende Daten mit
if-Prüfungen. - Für den Excel-Export können Sie die CSV in Excel öffnen oder mit
pandas.xlsx-Dateien schreiben.
Schritt 3: HTML-Änderungen und Wartungsprobleme bewältigen
Jetzt wird es ernst. Websites ändern ihr Layout gern – manchmal wirkt es, als täten sie es nur, um Scraper auf Trab zu halten. Wenn IMDb class="titleColumn" in class="movieTitle" ändert, gibt Ihr Skript plötzlich leere Ergebnisse zurück. Schon erlebt, schon debuggt.
Wenn Skripte kaputtgehen: Probleme aus der Praxis
Häufige Probleme:
- Selektoren nicht gefunden: Ihr Code findet das angegebene Tag bzw. die Klasse nicht.
- Leere Ergebnisse: Die Seitenstruktur hat sich geändert, oder Inhalte werden jetzt per JavaScript geladen.
- HTTP-Fehler: Die Seite hat Anti-Bot-Maßnahmen eingeführt.
Schritte zur Fehlersuche:
- Prüfen Sie, ob das HTML, das Sie parsen, mit dem übereinstimmt, was Sie im Browser sehen.
- Aktualisieren Sie Ihre Selektoren, damit sie zur neuen Struktur passen.
- Wenn Inhalte dynamisch geladen werden, müssen Sie vielleicht auf ein Browser-Automatisierungstool wie Selenium umsteigen oder einen API-Endpunkt finden.
Das eigentliche Problem? Wenn Sie 10, 50 oder 500 verschiedene Websites scrapen, verbringen Sie möglicherweise mehr Zeit mit dem Reparieren von Skripten als mit der eigentlichen Datenanalyse (siehe Entwicklerberichte).
Schritt 4: Skalieren – die versteckten Kosten des manuellen Python-HTML-Parsens
Angenommen, Sie möchten nicht nur IMDb scrapen, sondern auch Amazon, Zillow, LinkedIn und ein Dutzend weitere Websites. Jede einzelne braucht ihr eigenes Skript. Und jedes Mal, wenn eine Seite sich ändert, sitzen Sie wieder im Code-Editor.
Die versteckten Kosten:
- Wartungsaufwand: Manche schätzen, dass Wartung das Zehnfache der ursprünglichen Entwicklungskosten beträgt.
- Infrastruktur: Sie brauchen Proxys, Fehlerbehandlung und Monitoring.
- Performance: Skalierung bedeutet, Parallelität, Rate Limits und mehr zu handhaben.
- Qualitätssicherung: Mehr Skripte = mehr Stellen, an denen etwas kaputtgehen kann.
Für nicht-technische Teams wird das schnell untragbar. Es ist, als würde man ein Team von Praktikanten einstellen, die den ganzen Tag Daten kopieren und einfügen – nur dass die Praktikanten Python-Skripte sind und sich jedes Mal krankmelden, wenn sich eine Website ändert.
Eine kurze Anmerkung zu KI-Coding-Agenten
Bevor wir zu No-Code-Tools kommen, lohnt sich ein Blick auf einen Mittelweg, den es zur Zeit der meisten „Lernen Sie BeautifulSoup“-Tutorials noch kaum gab: KI-Coding-Agenten. Tools wie Claude Code oder Cursor setzen eine englische Beschreibung („hole die Top 250 von IMDb, schreibe Titel / Jahr / Bewertung in eine CSV“) gern direkt in ein funktionierendes requests-plus-BeautifulSoup-Skript um – inklusive der Art von Selektor-Bereinigung, die wir gerade noch manuell gemacht haben. Für Browser-Workflows in natürlicher Sprache – Anmelden, Paginierung, Cookie-Banner – kann eine Bibliothek wie Browser Use einen Headless Browser direkt per Prompt steuern.
Ganz verschwinden die schwierigen Teile dadurch aber nicht. Rate Limits, robots.txt, Login-Walls und Anti-Bot-Abwehr bleiben Ihr Problem, und wenn ein Selektor stillschweigend kaputtgeht (wie bei IMDb), müssen Sie trotzdem erkennen, was der Agent erzeugt hat, und es korrigieren. Selbst mit einem Agenten im Loop ist also das Verständnis des HTML-Parser-Workflows aus diesem Tutorial das, was Ihnen hilft, die Ausgabe zu debuggen, statt nur auf leere Listen zu starren.
Jenseits von Python-HTML-Parsern: Lernen Sie Thunderbit kennen, die KI-gestützte Alternative
Jetzt zum interessanten Teil. Was wäre, wenn Sie den Code überspringen, die Wartung überspringen und einfach die Daten bekommen könnten – ganz gleich, wie sich die Website verändert?
Genau das haben wir mit Thunderbit gebaut. Es ist eine Chrome-Erweiterung für KI-Web-Scraping, mit der Sie strukturierte Daten von jeder Website in zwei Klicks extrahieren können. Kein Python, keine Skripte, kein Kopfzerbrechen.
Python-HTML-Parser vs. Thunderbit: Direktvergleich
| Aspekt | Python-HTML-Parser | Thunderbit (Preise ansehen) |
|---|---|---|
| Einrichtungszeit | Hoch (installieren, programmieren, debuggen) | Gering (Erweiterung installieren, klicken) |
| Benutzerfreundlichkeit | Erfordert Programmierung | Kein Code — zeigen und klicken |
| Wartung | Hoch (Skripte brechen häufig) | Gering (KI passt sich automatisch an) |
| Skalierbarkeit | Komplex (Skripte, Proxys, Infrastruktur) | Integriert (Cloud-Scraping, Batch-Jobs) |
| Datenanreicherung | Manuell (mehr Code schreiben) | Integriert (Kennzeichnung, Bereinigung, Übersetzung, Unterseiten) |
Warum etwas bauen, wenn Sie das Problem mit KI lösen können?
Warum KI für die Extraktion von Web-Daten wählen?
Der KI-Agent von Thunderbit liest die Seite, erkennt die Struktur und passt sich an, wenn sich etwas ändert. Es ist, als hätten Sie einen Super-Praktikanten, der nie schläft und sich nie über wechselnde Klassennamen beschwert.
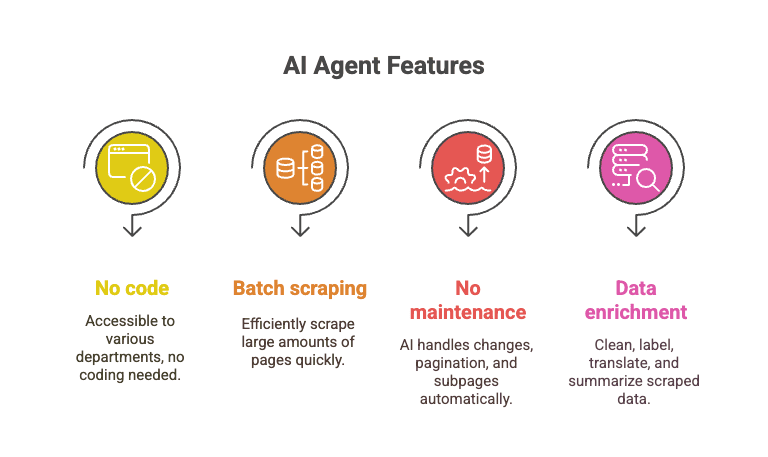
- Kein Code erforderlich: Jeder kann es verwenden – Vertrieb, Operations, Marketing, was auch immer.
- Batch-Scraping: Über 10.000 Seiten scrapen in der Zeit, die Sie brauchen würden, um ein einziges Python-Skript zu debuggen.
- Keine Wartung: Die KI übernimmt Layout-Änderungen, Paginierung, Unterseiten und mehr.
- Datenanreicherung: Bereinigen, kennzeichnen, übersetzen und zusammenfassen, während Sie die Daten erfassen.
Die Kehrseite des gerade besprochenen BeautifulSoup-Workflows ist genau die Art von Fragilität, die wir oben bei den IMDb-Selektoren gesehen haben – wenn die Seite umgebaut wird, liefert das Skript stillschweigend leere Ergebnisse, und Sie verbringen den Nachmittag in den DevTools statt mit den Daten. Ein No-Code-KI-Scraper versteckt diesen Schritt hinter seiner eigenen Inferenzschicht; das ist ein echter Kompromiss (Sie vertrauen darauf, dass die Extraktion eines anderen korrekt ist), kein Wundermittel.
Schritt für Schritt: IMDb-Filmbewertungen mit Thunderbit scrapen
Schauen wir uns an, wie Thunderbit dieselbe IMDb-Aufgabe löst:
- Installieren Sie die Thunderbit Chrome-Erweiterung.
- Öffnen Sie die IMDb Top 250-Seite.
- Klicken Sie auf das Thunderbit-Symbol.
- Klicken Sie auf „KI-Felder vorschlagen“. Thunderbit liest die Seite und empfiehlt Spalten (Titel, Jahr, Bewertung).
- Prüfen oder passen Sie die Spalten bei Bedarf an.
- Klicken Sie auf „Scrapen“. Thunderbit extrahiert sofort alle 250 Zeilen.
- Exportieren Sie nach Excel, Google Sheets, Notion oder CSV – ganz wie Sie möchten.
Das war’s. Kein Code, kein Debugging, kein „Warum ist diese Liste leer?“
Sie möchten sehen, wie es funktioniert? Schauen Sie sich den Thunderbit-YouTube-Kanal für Anleitungen an oder lesen Sie unseren Schritt-für-Schritt-Leitfaden zum Scrapen von Amazon für ein weiteres Praxisbeispiel.
Fazit: Das richtige Tool für Ihre Web-Datenanforderungen wählen
Python-HTML-Parser wie BeautifulSoup und lxml sind leistungsstark, flexibel und kostenlos. Sie sind ideal für Entwickler, die volle Kontrolle wollen und bereit sind, selbst Hand anzulegen. Aber sie bringen eine steile Lernkurve, laufende Wartung und versteckte Kosten mit sich – vor allem, wenn Ihre Scraping-Anforderungen wachsen.
Für Business-User, Vertriebsteams und alle, die einfach nur die Daten wollen und nicht den Code, sind KI-gestützte Tools wie Thunderbit eine echte Erleichterung. Sie ermöglichen es, Web-Daten in großem Maßstab zu extrahieren, zu bereinigen und anzureichern – ganz ohne Programmierung und ohne Wartungsaufwand.
Mein Rat? Nutzen Sie Python, wenn Sie Skripte lieben und maximale Anpassung brauchen. Aber wenn Ihnen Ihre Zeit wichtig ist (und Ihre Nerven auch), probieren Sie Thunderbit aus. Warum Skripte bauen und betreuen, wenn KI die schwere Arbeit übernehmen kann?
Sie möchten mehr über Web Scraping, Datenextraktion und KI-Automatisierung erfahren? Stöbern Sie in weiteren Tutorials im Thunderbit-Blog, zum Beispiel Wie man Website-Daten mit KI in Excel überführt oder Die besten Web-Scraping-Tools und -Software 2025.




