

Formulare, Dashboards, endlose Eingabemasken – das Web besteht zu großen Teilen aus Arbeit, die niemand gern zweimal macht. Wer schon zum fünften Mal dieselbe Seite durchklickt, fragt sich irgendwann zu Recht, ob das nicht auch automatisch geht. Die Antwort lautet ja, und immer mehr Leute setzen dafür auf Python: 2024 zog die Sprache an JavaScript vorbei und wurde zur meistgenutzten auf GitHub – knapp ein Viertel der Python-Entwickler setzt sie für Automatisierung und Web-Scraping ein (GitHub Octoverse, JetBrains Survey). Der Grund ist einfach: Mit Python lassen sich Webseiten-Abläufe nicht nur automatisieren. Das Ganze bleibt auch für Leute machbar, die keine reinen Programmierer sind.
Wie du Webseiten-Interaktionen mit Python automatisierst, klären die nächsten Abschnitte Schritt für Schritt. Du erfährst, warum Python sich dafür anbietet, wie du dein Toolset einrichtest, worauf es beim Formulare-Ausfüllen und Navigieren mit Selenium ankommt, und wie KI-Tools wie Thunderbit die Sache noch einmal vereinfachen. Ob du als Business-User wiederkehrende Routine loswerden oder als Entwickler deine Abläufe straffen willst: Hier findest du praktische Tipps, Codebeispiele und Erfahrungswerte aus der Praxis.
Warum Python für die Automatisierung von Webseiten?
Mit KI Daten von jeder Website extrahieren Get Started Free
Also: warum Python? In der Entwickler-Community gilt die Sprache nicht ohne Grund als Allzweckwerkzeug für Automatisierung. Die wichtigsten Argumente:
- Lesbar & einsteigerfreundlich: Python ist bekannt für seine klare, verständliche Syntax. Auch ohne viel Programmiererfahrung kannst du Python-Skripte lesen und anpassen, ohne dich wie ein Archäologe zu fühlen (Monterail).
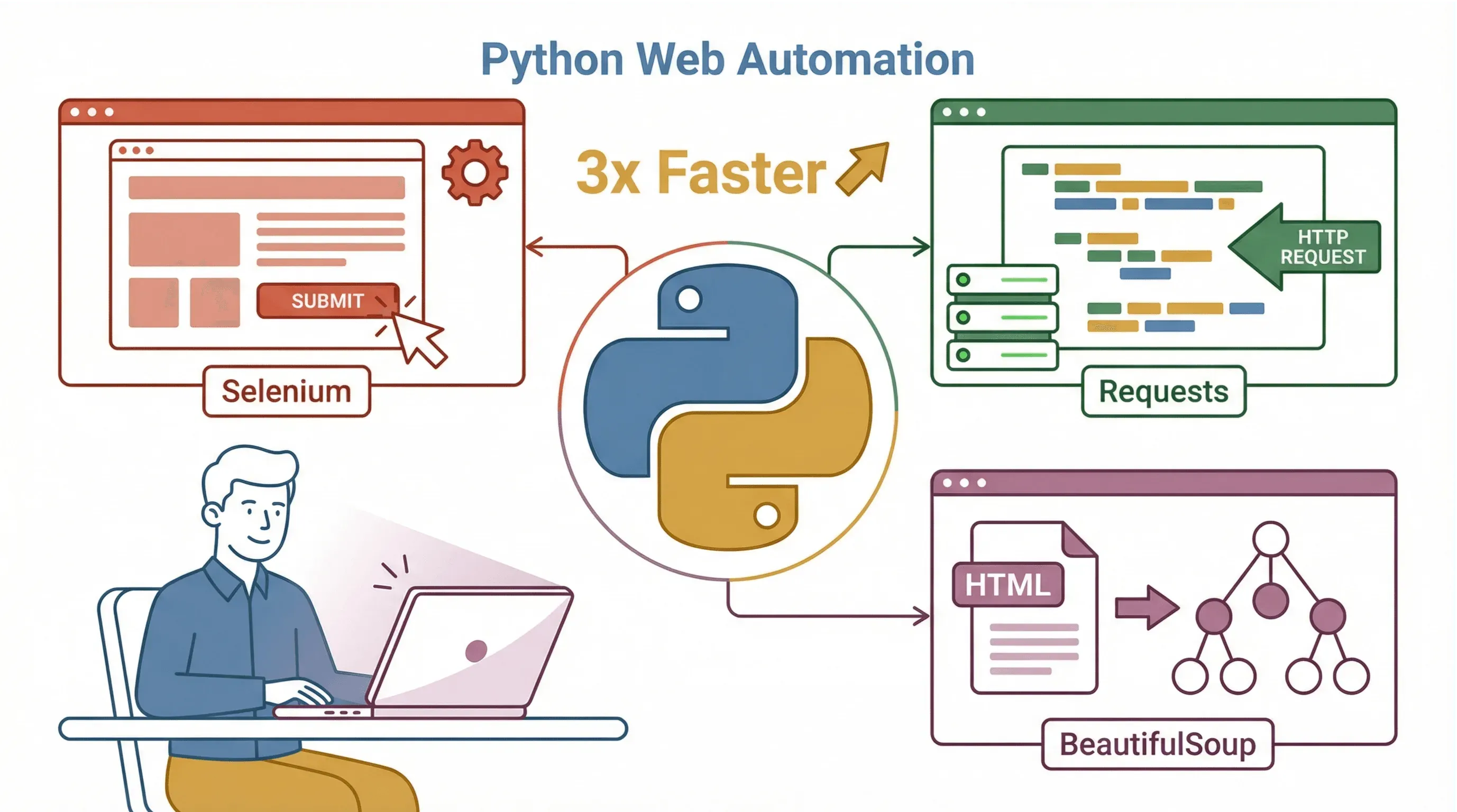
- Riesiges Ökosystem: Es gibt eine breite Auswahl an Bibliotheken für Webautomatisierung. Die wichtigsten:
- Selenium: Simuliert echte Nutzeraktionen im Browser – klicken, tippen, navigieren und mehr (BlazeMeter).
- Requests: Für HTTP-Anfragen, um Webseiten oder APIs ohne Browser abzurufen (Requests Docs).
- BeautifulSoup: Zum Parsen und Extrahieren von Daten aus HTML oder XML (BeautifulSoup Docs).
- Starke Community & Support: Bei Problemen findest du fast immer eine Lösung auf Stack Overflow oder in Blogs.
- Plattformunabhängig: Python-Skripte laufen auf Windows, macOS und Linux fast ohne Anpassungen.
Verglichen mit Java oder C# erreichst du mit Python mehr bei weniger Code und Aufwand. JavaScript kann Browser zwar ebenfalls steuern, aber die Python-Bibliotheken und ihre Doku sind in der Regel zugänglicher – gerade für Business-User (ActiveBatch).
Dein Python-Automatisierungs-Toolkit aufsetzen
Bevor du loslegst, solltest du deine Tools richtig einrichten. So klappt der Start – egal ob auf Windows, macOS oder Linux.
1. Python und Pip installieren
- Windows: Lade Python 3 von python.org runter. Beim Installieren „Add Python to PATH“ anhaken.
- macOS: Nutze den offiziellen Installer oder installiere mit Homebrew:
brew install python3. - Linux: Meist ist Python schon drauf. Sonst:
sudo apt-get install python3 python3-pip.
Installation checken:
python3 --version
pip --version
Falls pip fehlt: separat installieren (sudo apt-get install python3-pip auf Ubuntu).
2. Selenium und weitere Pakete installieren
Sind Python und pip bereit, installierst du die nötigen Bibliotheken:
pip install selenium requests beautifulsoup4
- Selenium für Browser-Automatisierung
- Requests für HTTP-Anfragen
- BeautifulSoup für HTML-Parsing
3. WebDriver herunterladen (für Selenium)
Selenium steuert Browser über einen Treiber. Für Chrome: ChromeDriver, für Firefox: geckodriver.
- Lege den Treiber im System-PATH ab oder gib den Pfad im Skript an:
from selenium import webdriver
driver = webdriver.Chrome(executable_path="/path/to/chromedriver")
Neuere Selenium-Versionen finden den Treiber oft automatisch, wenn er im PATH liegt.
4. Virtuelle Umgebung einrichten
Mit einer virtuellen Umgebung (venv oder virtualenv) bleiben die Abhängigkeiten deines Projekts sauber getrennt (Real Python).
Erstellen und aktivieren:
python3 -m venv myenv
source myenv/bin/activate # Unter Windows: myenv\Scripts\activate
Alle pip install-Befehle betreffen jetzt nur dieses Projekt.
5. Tipps & Troubleshooting je Betriebssystem
- Windows: Wird
pythonoderpipnicht erkannt, Python zum PATH hinzufügen oder denpy-Launcher nutzen. - macOS: Nutze
python3stattpython, um Verwechslungen mit dem System-Python zu vermeiden. - Linux: Für Selenium auf Headless-Servern: Headless-Modus oder Xvfb verwenden.
Bei Problemen mit Treiberversionen oder fehlenden Paketen: Kompatibilität checken und ggf. updaten.
Mit Selenium Formulare und Navigation automatisieren
Jetzt wird’s praktisch: Mit Selenium steuerst du den Browser und automatisierst alles – vom Login bis zu komplexen Workflows.
Browser öffnen und Seite laden
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
So startest du Chrome und öffnest die Login-Seite.
Elemente finden und bedienen
Selenium findet Elemente per ID, Name, CSS-Selektor, XPath und mehr:
username_box = driver.find_element(By.ID, "username")
password_box = driver.find_element(By.NAME, "pwd")
login_button = driver.find_element(By.XPATH, "//button[@type='submit']")
- Textfeld ausfüllen:
username_box.send_keys("alice") - Button klicken:
login_button.click() - Dropdown auswählen:
from selenium.webdriver.support.ui import Select
select_elem = Select(driver.find_element(By.ID, "country"))
select_elem.select_by_visible_text("Canada")
- Zu einer anderen Seite navigieren:
driver.get("https://example.com/profile")
Best Practices für die Elementauswahl
- ID oder eindeutige Attribute bevorzugen – das ist stabiler.
- CSS-Selektoren sind oft kompakt und zuverlässig.
- Absolute XPaths vermeiden – die brechen schnell bei Layout-Änderungen (Medium).
Dynamische Inhalte und Wartezeiten
Moderne Webseiten laden Inhalte oft verzögert. Damit dein Skript nicht zu früh klickt, nutze explizite Wartezeiten:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "loginBtn")))
So wartet das Skript bis zu 10 Sekunden, bis der Login-Button klickbar ist. Explizite Waits sind viel zuverlässiger als pauschale time.sleep()-Befehle (BrowserStack).
Beispiel: Mehrstufiges Webformular automatisieren
Hier ein Beispiel für einen zweistufigen Anmeldeprozess (Demo-Seite):
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://practicetestautomation.com/Practice-Signup")
# Schritt 1: Erstes Formular ausfüllen
driver.find_element(By.ID, "name").send_keys("Alice")
driver.find_element(By.ID, "email").send_keys("alice@example.com")
driver.find_element(By.ID, "password").send_keys("SuperSecret123")
driver.find_element(By.ID, "nextBtn").click()
# Schritt 2: Auf zweites Formular warten und ausfüllen
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "address")))
driver.find_element(By.ID, "address").send_keys("123 Maple St")
driver.find_element(By.ID, "phone").send_keys("5551234567")
driver.find_element(By.ID, "submitBtn").click()
# Schritt 3: Bestätigung abwarten
WebDriverWait(driver, 5).until(EC.text_to_be_present_in_element((By.TAG_NAME, "h1"), "Welcome"))
print("Anmeldung erfolgreich!")
driver.quit()
Das Skript füllt beide Formulare aus, wartet aufs Laden und prüft die Erfolgsmeldung – ein Muster, das dir immer wieder begegnen wird.
Thunderbit: KI-gestützte Automatisierung für komplexe Webseiten
Thunderbit Chrome-Erweiterung ausprobieren Webdaten und Workflows mit KI in wenigen Klicks automatisieren. Get Started Free
Und wenn die Website chaotisch aufgebaut ist, die Daten in PDFs oder Bildern stecken oder du schlicht nicht programmieren willst? Genau für diese Fälle gibt es Thunderbit.
Thunderbit ist ein KI-Web-Scraper als Chrome-Erweiterung, mit dem du Daten und Web-Interaktionen in wenigen Klicks automatisierst – komplett ohne Code. Das macht das Tool gerade für Unternehmen interessant:
- Anweisungen in natürlicher Sprache: Einfach beschreiben, was du brauchst („Produktname, Preis, Bewertung“) – Thunderbit erkennt automatisch, wie die Daten extrahiert werden (Futurepedia).
- Unterseiten-Scraping: Thunderbit kann automatisch Unterseiten besuchen und die Daten direkt in deine Tabelle einfügen.
- Sofort-Vorlagen: Für bekannte Seiten wie Amazon oder Zillow gibt’s Ein-Klick-Vorlagen – keine Einrichtung nötig.
- PDFs und Bilder: Extrahiert Text auch aus PDFs (inklusive Scans) und Bildern – was mit Python zusätzliche Bibliotheken erfordern würde.
- Geplanter Scraper: Wiederkehrende Aufgaben („jeden Montag um 9 Uhr“) lassen sich easy einrichten.
- Kostenloser Datenexport: Exportiere deine Ergebnisse gratis nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON.
Thunderbit lohnt sich vor allem dann, wenn du unstrukturierte Webinhalte in saubere Daten verwandeln oder Kollegen ohne Programmierkenntnisse die Automatisierung in die Hand geben willst. Für wiederkehrende Routinearbeit ist es damit gut geeignet.
Wann Thunderbit und wann Python-Skripte?
-
Python (Selenium/Requests/BeautifulSoup):
- Wenn du individuelle Logik, Integrationen oder volle Kontrolle brauchst.
- Für Workflows, die über Web-Scraping hinausgehen (z. B. Datenanalyse, API-Aufrufe, komplexe Bedingungen).
- Wenn du gerne programmierst und deine Lösung versionieren willst.
-
Thunderbit:
- Für schnelle, codefreie Datenextraktion oder Routineaufgaben.
- Bei unübersichtlichen, unstrukturierten Seiten oder Formaten (PDFs, Bilder).
- Um Nicht-Entwicklern oder Teams schnelle Automatisierung zu ermöglichen.
In der Praxis greife ich oft zu beidem: Thunderbit für schnelle Prototypen oder für Sales und Operations, Python-Skripte für maßgeschneiderte, tief integrierte Workflows.
Thunderbit für No-Code-Webautomatisierung testen
So machst du deine Python-Automatisierung stabil und zuverlässig
Eine Automatisierung ist nur so gut wie ihre Zuverlässigkeit. So bleiben deine Skripte robust – auch wenn sich Webseiten ändern:
Fehlerbehandlung und Wiederholungen
Fehleranfällige Aktionen in try/except-Blöcke packen:
try:
element = driver.find_element(By.ID, "price")
except Exception as e:
print("Fehler beim Finden des Preiselements:", e)
driver.save_screenshot("screenshot_error.png")
# Optional: Wiederholen oder überspringen
Bei Netzwerkproblemen oder instabilen Elementen einfache Wiederholungslogik nutzen:
import time
max_retries = 3
for attempt in range(max_retries):
try:
driver.get(url)
break
except Exception as e:
print(f"Versuch {attempt+1} fehlgeschlagen, wiederhole...")
time.sleep(5)
Überall explizite Waits nutzen
Verlass dich nicht darauf, dass Elemente sofort bereit sind. Immer explizite Waits vor Interaktionen einsetzen:
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, "result"))).click()
Logging und Monitoring
Für längere Skripte lohnt sich das logging-Modul von Python, um Fortschritt und Fehler zu protokollieren. Bei kritischen Fehlern kannst du dich per E-Mail oder Slack benachrichtigen lassen. Screenshots bei Fehlern helfen beim Debuggen.
Ressourcenmanagement
Am Ende des Skripts immer driver.quit() aufrufen, damit keine Browser im Hintergrund weiterlaufen.
Throttling und Fairness
Wenn du viele Seiten scrapest, bau zufällige Pausen ein (time.sleep(random.uniform(1,3))), um nicht blockiert zu werden. Respektiere robots.txt und überlaste keine Server.
Auf Webseitenänderungen reagieren
Webseiten ändern sich. IDs werden umbenannt, Layouts angepasst, neue Pop-ups erscheinen. So bleiben deine Skripte flexibel:
- Flexible Selektoren: Stabile Attribute oder
data-*-Attribute bevorzugen statt brüchiger XPaths. - Selektoren zentral verwalten: Alle Selektoren am Anfang des Skripts sammeln, um sie leichter zu aktualisieren.
- Regelmäßig testen: Skripte regelmäßig laufen lassen, um Fehler früh zu erkennen.
- Versionskontrolle: Mit Git Änderungen nachverfolgen und bei Bedarf zurückrollen.
Bei internen Tools kannst du das Webteam bitten, stabile Hooks (z. B. data-automation-id) einzubauen.
Python-Automatisierungstools im Vergleich: Selenium, Requests, BeautifulSoup und Thunderbit
Hier ein schneller Überblick, welches Tool sich wofür eignet:
| Tool | Stärken & Anwendungsfälle | Einschränkungen & Hinweise |
|---|---|---|
| Selenium (WebDriver) | Komplette Browser-Automatisierung; verarbeitet dynamisches JavaScript; simuliert echte Nutzeraktionen; ideal für mehrstufige Workflows | Langsamer, benötigt mehr Ressourcen; Treiber-Einrichtung nötig; kann bei instabilen Selektoren fehleranfällig sein |
| Requests + BeautifulSoup | Schnell und ressourcenschonend für statische Seiten/APIs; einfaches HTML-Parsing; ideal für Massendaten, wenn kein JS nötig ist | Kann kein dynamisches JavaScript; keine Nutzerinteraktion; Parsing-Logik muss selbst geschrieben werden |
| Thunderbit | No-Code, KI-basiert; kommt mit unstrukturierten Seiten, PDFs, Bildern klar; Unterseiten-Scraping; Sofort-Vorlagen; kostenloser Export; für Nicht-Entwickler | Weniger flexibel für individuelle Logik; basiert auf externem Service; KI-Vorschläge müssen ggf. angepasst werden |
Schritt-für-Schritt: Webseiten-Interaktion mit Python automatisieren
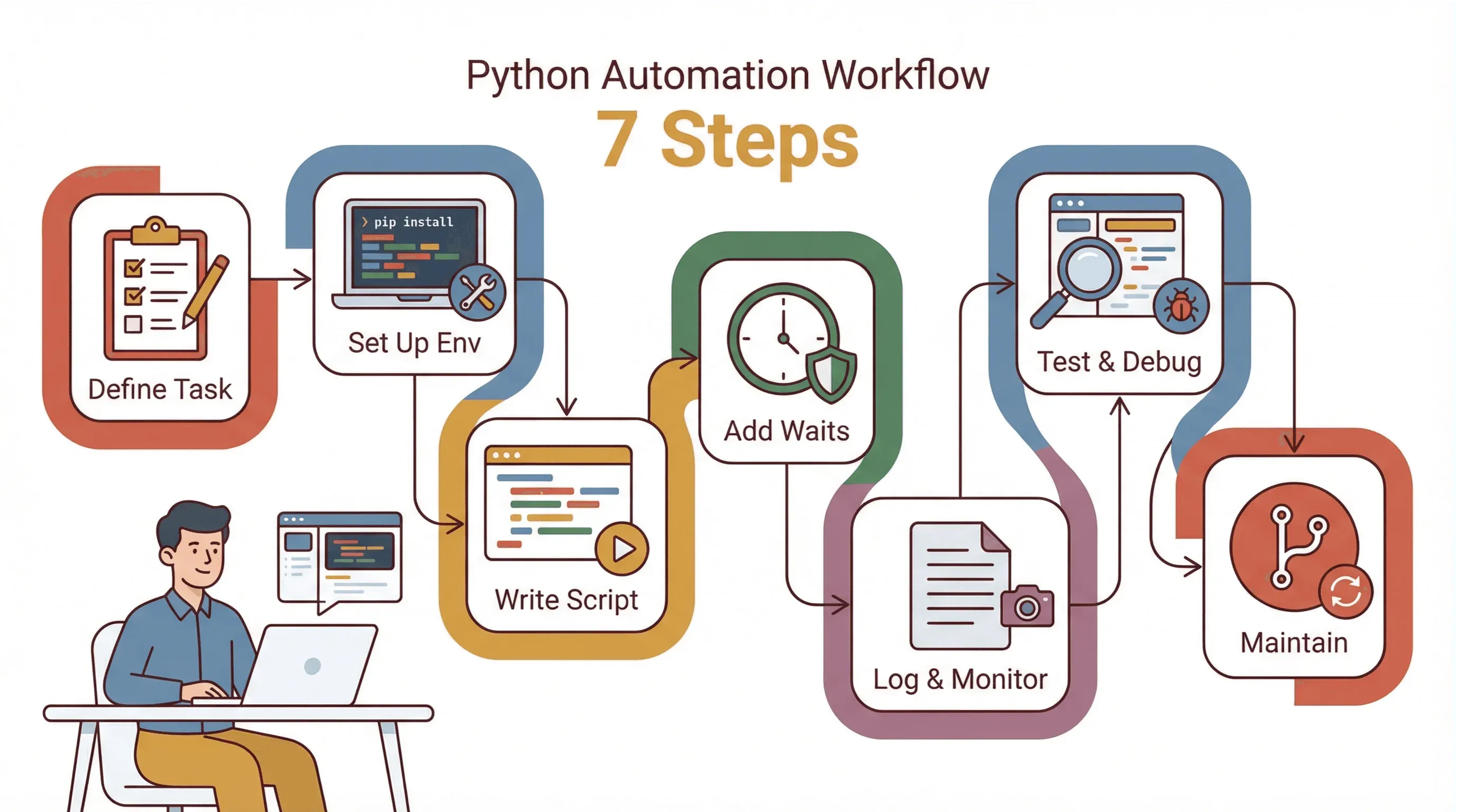 So gehe ich bei jeder Automatisierungsaufgabe vor:
So gehe ich bei jeder Automatisierungsaufgabe vor:
- Aufgabe definieren: Schreib dir die manuellen Schritte auf. Markiere schwierige Stellen (z. B. Logins, Pop-ups, dynamische Inhalte).
- Umgebung einrichten: Python, pip, virtualenv, Selenium und den passenden WebDriver installieren.
- Skript schrittweise schreiben: Mit einfacher Navigation starten, dann Interaktionen Schritt für Schritt ergänzen. Nach jedem Schritt testen.
- Wartezeiten und Fehlerbehandlung einbauen: Explizite Waits und try/except-Blöcke für fehleranfällige Schritte nutzen.
- Logging und Monitoring: Fortschritt und Fehler protokollieren. Bei Fehlern Screenshots speichern.
- Testen und Debuggen: Browser-Entwicklertools nutzen, um Selektoren zu prüfen. Im sichtbaren Modus laufen lassen, um Pop-ups oder Weiterleitungen zu erkennen.
- Pflegen und aktualisieren: Selektoren zentral ablegen, Versionskontrolle nutzen und Skripte regelmäßig überprüfen.
Wenn du neu in der Automatisierung bist, fang klein an – etwa mit dem Login auf einer Testseite oder dem Ausfüllen eines einfachen Formulars. Jeder kleine Erfolg gibt dir mehr Sicherheit.
Fazit & wichtigste Erkenntnisse
Webseiten mit Python zu automatisieren gehört zu den effektivsten Wegen, um Zeit und Nerven zu sparen. Dank der klaren Syntax und der mächtigen Bibliotheken automatisierst du vom einfachen Formular bis zum komplexen Workflow so ziemlich alles. Die Community ist riesig, an Ressourcen mangelt es nicht – und schon 15 Minuten täglich eingespart summieren sich auf fast 90 Stunden pro Jahr (LinkedIn).
Manchmal ist der schnellste Weg aber ein KI-Tool wie Thunderbit. Gerade bei unstrukturierten Seiten oder wenn du Kollegen ohne Programmierkenntnisse einbinden willst, automatisierst du Datenextraktion und Web-Interaktion in wenigen Klicks.
Ein guter Einstieg: Such dir eine kleine, nervige Webaufgabe, die du ständig machst, und automatisiere sie mit Python oder Thunderbit. Meist ist so eine Aufgabe schneller erledigt, als man denkt.
Mehr Tipps und Anleitungen findest du im Thunderbit Blog.
Thunderbit KI-Web-Scraper ausprobieren
Häufige Fragen (FAQ)
1. Warum ist Python so beliebt für die Automatisierung von Webseiten?
Dank der leicht verständlichen Syntax, der vielen Bibliotheken (wie Selenium, Requests und BeautifulSoup) und der großen Community ist Python die erste Wahl für Webautomatisierung und Scripting (GitHub Octoverse).
2. Was unterscheidet Selenium, Requests und BeautifulSoup?
Selenium steuert echte Browser für dynamische Seiten und Nutzeraktionen. Requests ruft Webseiten oder APIs ohne Browser ab (ideal für statische Inhalte). BeautifulSoup parst HTML und extrahiert Daten, meist in Kombination mit Requests.
3. Wann sollte ich Thunderbit statt Python-Skripten nutzen?
Thunderbit eignet sich, wenn du eine No-Code-, KI-basierte Lösung für unstrukturierte Seiten, PDFs/Bilder oder für Nicht-Entwickler suchst. Python-Skripte sind ideal für individuelle Logik, Integrationen oder maßgeschneiderte Workflows.
4. Wie mache ich meine Python-Automatisierung zuverlässiger?
Nutze explizite Waits, robuste Fehlerbehandlung (try/except), Wiederholungslogik bei Netzwerkproblemen und Logging zur Überwachung. Selektoren zentral ablegen und bei Änderungen anpassen.
5. Kann ich Thunderbit und Python kombinieren?
Klar! Extrahiere Daten schnell mit Thunderbit und verarbeite sie dann mit Python weiter. Oder automatisiere komplexe Logik mit Python und nutze Thunderbit für schnelle, codefreie Scraping-Aufgaben.
Wer wiederkehrende Webaufgaben loswerden will, probiert die kostenlose Thunderbit Chrome-Erweiterung aus oder legt mit Python los. So arbeitest du schon bald deutlich effizienter.
KI-Web-Scraper ausprobieren Get Started Free
Mehr erfahren




