

Noch vor ein paar Jahren hätte ich dir für jede Web-Automatisierung – ob Konkurrenzpreise auslesen oder UI-Tests fahren – ohne Umschweife zu Selenium oder Puppeteer geraten, dir ein paar Codebeispiele in die Hand gedrückt und viel Erfolg gewünscht. Inzwischen sieht die Lage anders aus: Die Nachfrage nach Browser-Automatisierung und Web-Datenerfassung ist in Vertrieb, Marketing, E-Commerce und Immobilien geradezu explodiert. Alle wollen Webdaten, aber kaum jemand hat Lust, dafür erst zum Entwickler zu werden.
Klar, Puppeteer, Selenium und Playwright bilden für Entwicklerteams nach wie vor das Rückgrat der Browser-Automatisierung. Business-User brauchen aber etwas anderes: Tools, die ohne Programmierkenntnisse funktionieren, nicht bei jeder kleinen Layout-Änderung auseinanderfallen und keine Wartezeit auf die IT bedeuten. An dieser Stelle kommen KI-gestützte No-Code-Lösungen wie Thunderbit ins Spiel. Doch bevor wir nach vorn schauen, lohnt ein Blick auf die Klassiker – und darauf, warum sich der Markt gerade so stark wandelt.
Was ist Puppeteer? Kurz erklärt
Puppeteer ist das Werkzeug der Wahl, wenn du Chrome oder Chromium per Code steuern willst – Seiten öffnen, Buttons klicken, Screenshots schießen oder Daten extrahieren. Es ist eine Node.js-Bibliothek und funktioniert im Grunde wie eine Fernbedienung für den Browser – nur eben mit JavaScript statt Knöpfen.
Typische Anwendungsfälle für Puppeteer:
- Automatisierte End-to-End-Tests für Webanwendungen (z. B. „Funktioniert mein Checkout noch?“)
- Web-Scraping – Daten aus Webseiten holen, die keine API anbieten
- Screenshots oder PDFs von Webseiten erstellen (super für Berichte oder Archivierung)
- Nutzerinteraktionen simulieren, etwa für Performance- oder SEO-Checks
Die große Stärke von Puppeteer ist die enge Anbindung an Chrome. Es spricht die Sprache des Browsers, arbeitet schnell und zuverlässig und kommt mit modernen Webtechnologien bestens klar – egal ob Single-Page-Apps oder dynamische Inhalte. Der Haken: Es funktioniert im Wesentlichen nur mit Chrome. Wer Firefox oder Safari automatisieren möchte, schaut in die Röhre.
Was ist Selenium? Der Klassiker der Browser-Automatisierung
Selenium ist der Urvater der Browser-Automatisierung und begleitet uns schon seit den frühen „Web 2.0“-Tagen. Es ist nicht bloß eine Bibliothek, sondern ein ganzes Ökosystem – mit Support für zahlreiche Programmiersprachen (Python, Java, C#, JavaScript, Ruby usw.) und praktisch jeden gängigen Browser (Chrome, Firefox, Safari, Edge, sogar Internet Explorer).
Was Selenium besonders macht:
- Mehrsprachigkeit: Du nutzt deine Lieblingssprache – JavaScript ist kein Muss.
- Browser-Vielfalt: Automatisiere Chrome, Firefox, Safari, Edge und mehr.
- Große Community: Unzählige Tutorials, Plugins und Integrationen.
- Skalierbare UI-Tests: Das Rückgrat vieler QA-Teams für automatisierte Tests.
Allerdings ist Seleniums Architektur etwas in die Jahre gekommen. Es setzt auf das „Driver + API“-Prinzip, weshalb du dich häufig mit Treibern, Browserversionen und Troubleshooting herumschlagen musst. Mächtig, ja – aber es fühlt sich manchmal an wie Schaltgetriebe fahren im Zeitalter der E-Autos.
Puppeteer vs Selenium: Die wichtigsten Unterschiede
Wie schlagen sich Puppeteer und Selenium im direkten Vergleich? Die wichtigsten Punkte auf einen Blick:
| Feature | Puppeteer | Selenium |
|---|---|---|
| Language Support | JavaScript/Node.js only | Multiple (Python, Java, C#, JS, Ruby, etc.) |
| Browser Support | Chrome/Chromium (experimental Firefox) | Chrome, Firefox, Safari, Edge, IE |
| Performance | Fast, optimized for Chrome | Good, but can be slower due to abstraction |
| Ease of Use | Simpler API, modern syntax | More complex, steeper learning curve |
| Community/Ecosystem | Growing, but smaller than Selenium | Huge, mature, lots of resources |
| Use Cases | Testing, scraping, screenshots, PDFs | Testing, scraping, automation |
Architektur im Vergleich:
- Beide setzen auf das „Driver + API“-Modell.
- Puppeteer konzentriert sich auf Chrome und nutzt das DevTools-Protokoll.
- Selenium ist browserunabhängig und verwendet WebDriver für die plattformübergreifende Unterstützung.
Fazit:
Wer ausschließlich mit Chrome arbeitet und JavaScript mag, wird Puppeteer als schnell und modern erleben. Wer Flexibilität braucht – verschiedene Browser, verschiedene Sprachen –, ist mit Selenium gut bedient. Beide setzen allerdings voraus, dass du Skripte schreibst und pflegst, und keines davon „versteht“ Webseiten wirklich – sie arbeiten rein auf DOM-Ebene.
Playwright: Die moderne Alternative zu Puppeteer
Mit Playwright hat Microsoft eine Antwort auf die Anforderungen moderner Webautomatisierung geliefert. Wenn Puppeteer der Sportwagen für Chrome ist, dann ist Playwright der Allrad-SUV für jedes Gelände.
Warum Playwright so beliebt ist:
- Echte plattformübergreifende Unterstützung: Chrome, Firefox, Safari, Edge – alles über eine API.
- Parallele Ausführung: Mehrere Browser-Kontexte gleichzeitig, ideal für CI/CD.
- Automatisches Warten: Schluss mit endlosen „wait for element“-Hacks – Playwright wartet selbstständig auf Elemente.
- Leistungsstarke Selektoren: Elemente lassen sich nach Text, Rolle oder sogar ARIA-Attributen ansprechen.
- Moderne Features: Native Unterstützung für Downloads, Uploads, Geolokalisierung, Berechtigungen und mehr.
Ich habe beobachtet, wie Playwright in Teams mit hohen Anforderungen an Zuverlässigkeit und Tempo – vor allem in CI/CD-Umgebungen – rasant Boden gutgemacht hat. Auch fürs Scraping taugt es, bleibt aber wie Puppeteer und Selenium ein Tool für Entwickler. Wer ungern Code schreibt, stößt schnell an Grenzen.
Playwright-Alternativen: Was gibt es noch?
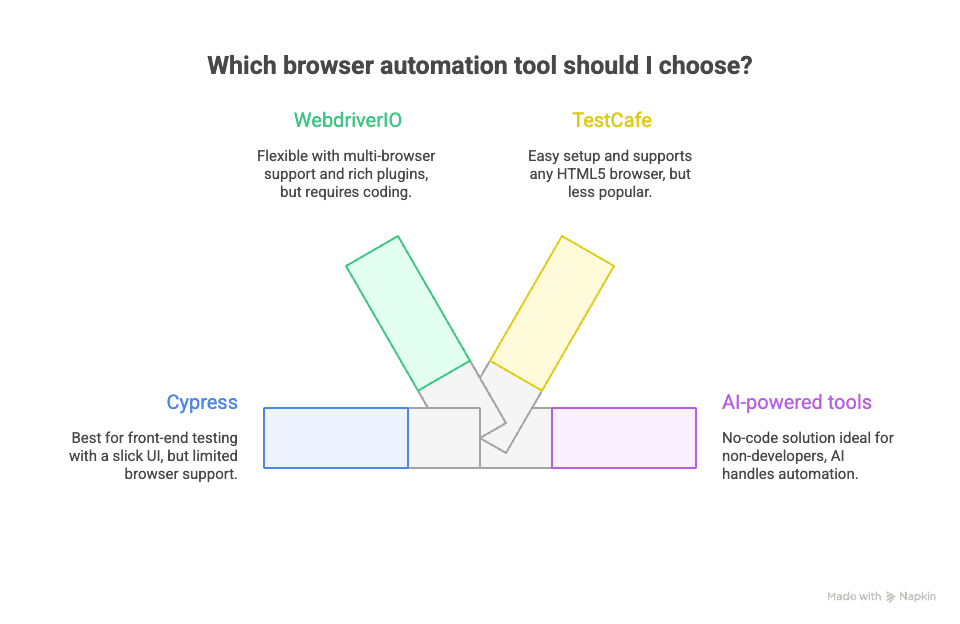
Der Markt für Browser-Automatisierung ist riesig. Hier ein Überblick über weitere Tools und ihre Eigenheiten:
-
Cypress:
Cypress ist auf Frontend-Tests spezialisiert, bietet eine moderne Oberfläche und ein hervorragendes Entwicklererlebnis, beschränkt sich aber auf Chrome-basierte Browser und kommt mit Multi-Tab oder Cross-Origin schlecht zurecht. Für Tests top, fürs Scraping weniger geeignet. Mehr zu Cypress.
-
WebdriverIO:
Eine Node.js-Implementierung des WebDriver-Protokolls, flexibel, unterstützt viele Browser und bringt ein großes Plugin-Ökosystem mit. Für Tests und Scraping geeignet, aber auch hier führt kein Weg am Programmieren vorbei. WebdriverIO Website.
-
TestCafe:
Ebenfalls JavaScript-basiert, leicht einzurichten und läuft in jedem HTML5-fähigen Browser. Weniger verbreitet als Cypress oder Playwright, für einfache Testautomatisierung aber einen Blick wert. TestCafe Website.
-
KI-gestützte Tools wie Thunderbit:
Und genau hier wird es für Business-User interessant. Thunderbit verfolgt einen völlig anderen Ansatz: kein Code, keine Skripte – einfach klicken und die KI übernimmt die Arbeit. Wie das funktioniert, erkläre ich gleich. Für alle, die keine Entwickler sind, ist das die Richtung, die man sich merken sollte.
Vergleichstabelle: Code- vs. No-Code-Automatisierung
| Tool | Browser Support | Language(s) | Coding Required | Best For |
|---|---|---|---|---|
| Puppeteer | Chrome/Chromium | JavaScript | Yes | Devs, Chrome automation |
| Selenium | All major browsers | Many | Yes | Devs, cross-browser testing |
| Playwright | All major browsers | JavaScript, etc. | Yes | Modern automation, CI/CD |
| Cypress | Chrome-family | JavaScript | Yes | Front-end testing |
| WebdriverIO | All major browsers | JavaScript | Yes | Flexible automation |
| TestCafe | All major browsers | JavaScript | Yes | Simple test automation |
| Thunderbit | All major browsers* | N/A (No code) | No | Business users, scraping |
- Thunderbit läuft direkt im Browser und funktioniert überall, wo Chrome läuft.
Von „Browser-Automatisierung“ zu „Intelligentem Scraping“: Der Thunderbit-Ansatz
Mit KI Daten von jeder Website extrahieren Get Started Free
Für Automatisierungsfans wird es an dieser Stelle richtig interessant: Klassische Frameworks wie Puppeteer, Selenium und Playwright arbeiten, indem sie das DOM manipulieren – sie suchen Elemente, klicken Buttons und lesen Texte aus. Was auf der Seite tatsächlich passiert, „verstehen“ sie aber nicht. Ändert sich ein Klassenname, verschiebt sich ein Button oder lädt Inhalt dynamisch nach, sind die Skripte schnell wertlos.
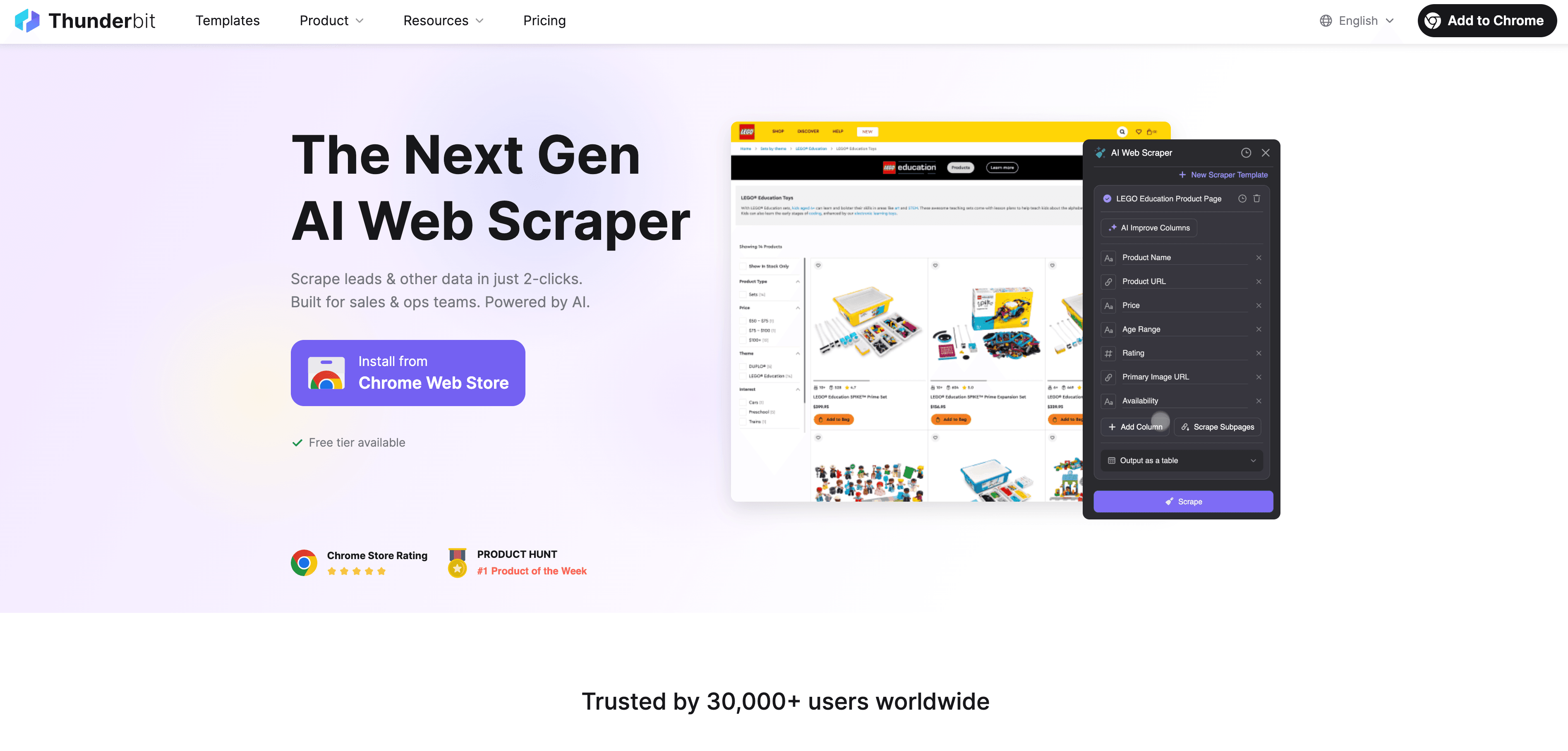
Thunderbit dreht das Prinzip um. Statt nur das DOM zu durchforsten, liest die KI die Seite wie ein Mensch. Zuerst wird die Webseite in ein strukturiertes Markdown-Format überführt, das anschließend von einem KI-Modell semantisch analysiert wird. Die KI erfasst Kontext, die Bedeutung der Felder und die Logik der Daten – sie unterscheidet also zwischen Produktnamen, Preisen und Bewertungen, selbst wenn das HTML ein einziges Chaos ist.
Was bedeutet das konkret?
- Stabiles Scraping auch bei komplexen oder dynamischen Seiten: Unendliches Scrollen, Pop-ups oder nutzergenerierte Inhalte? Kein Problem.
- Keine Selector-Probleme mehr: Die KI passt sich Layout-Änderungen an – ständiges Nachjustieren von Skripten entfällt.
- Semantische Extraktion: Thunderbit zieht strukturierte Daten (Tabellen, Listen oder verschachtelte Infos) auch aus scheinbar unübersichtlichen Seiten heraus.
Ich habe Thunderbit schon bei Facebook Marketplace, langen Kommentarspalten und dynamischen E-Commerce-Seiten im Einsatz gesehen – also genau in den Szenarien, an denen klassische Web-Scraper reihenweise scheitern. Und das alles mit wenigen Klicks.
Warum Geschäftsteams semantisches No-Code-Web-Scraping brauchen
Was ist Data Scraping und wie funktioniert es 2025? Get Started Free
Die Realität sieht so aus: Die meisten Teams in Vertrieb, Marketing, E-Commerce oder Immobilien haben keinen Entwickler auf Abruf. Und wenn doch, ist dieser meist anderweitig ausgelastet. Was bedeutet das für Code-basierte Tools?
- Skript-Wartungschaos: Jede Webseitenänderung verlangt Anpassungen an Selektoren oder Skripten.
- Abhängigkeit von Entwicklern: Nicht-Techniker müssen auf IT-Unterstützung warten.
- Hohe Einstiegshürde: Selbst „einfache“ Automatisierungstools erfordern Einarbeitung und Debugging.
- Fragile Workflows: Eine kleine Änderung auf der Zielseite – und alles bricht zusammen.
Thunderbit ist genau dafür gebaut, diese Probleme zu lösen:
- 2-Klick-Scraping: Einfach „KI-Felder vorschlagen“ und dann „Scrapen“ klicken. Die KI erkennt, was extrahiert werden soll.
- KI-Feldvorschläge: Thunderbit liest die Seite und schlägt passende Spalten und Datentypen vor.
- Subseiten-Scraping: Daten von verlinkten Seiten (z. B. Produktdetails oder Bewertungen) lassen sich automatisch ergänzen.
- Kein Code, keine Skripte: Jeder kann es bedienen – ganz ohne Technikkenntnisse.
Vergleichstabelle für Geschäftsanwender
| Feature | Puppeteer/Selenium/Playwright | Thunderbit |
|---|---|---|
| Coding Required | Yes | No |
| Script Maintenance | Frequent | None (AI adapts) |
| Handles Dynamic Content | Manual scripting | AI semantic understanding |
| Subpage/Linked Data | Custom code | 1-click Subpage Scraping |
| Data Export (Excel, Sheets) | Manual parsing | Built-in, free export |
| Learning Curve | Steep | Minimal |
| Best For | Developers, QA | Sales, Marketing, Ops, Real Estate |
Wann sollte man Puppeteer, Selenium, Playwright oder Thunderbit nutzen? (Entscheidungshilfe)
Welches Tool ist nun das richtige? Hier meine Einschätzung aus jahrelanger Automatisierungsarbeit für Entwickler- und Business-Teams:
Nutze Puppeteer, Selenium oder Playwright, wenn:
- Ein Entwickler- oder QA-Team zur Verfügung steht.
- Hochgradig individuelle Workflows (z. B. komplexe Testautomatisierung, spezielle Browser-Interaktionen) nötig sind.
- Integration in CI/CD-Pipelines oder Testframeworks gefragt ist.
- Das Team bereit ist, Code zu pflegen und Skriptbrüche zu beheben.
Nutze Thunderbit, wenn:
- Du schnell und ohne Code Daten von Webseiten extrahieren möchtest.
- Dein Team in Vertrieb, Marketing, E-Commerce oder Immobilien arbeitet und Daten sofort braucht – nicht erst nach einem Sprint.
- Du keine Lust mehr auf kaputte Skripte bei jeder Webseitenänderung hast.
- Du komplexe, dynamische oder sich häufig ändernde Seiten verarbeiten musst.
- Du Daten direkt nach Excel, Google Sheets, Airtable oder Notion exportieren willst.
Entscheidungsmatrix
| Scenario | Best Tool(s) |
|---|---|
| Custom browser automation | Playwright, Puppeteer |
| Cross-browser UI testing | Selenium, Playwright |
| No-code web scraping | Thunderbit |
| Dynamic, changing web pages | Thunderbit |
| Business team, no devs | Thunderbit |
| Deep integration with CI/CD | Playwright, Selenium |
Thunderbit KI-Web-Scraper kostenlos testen
Die Zukunft: Automatisierungs-Frameworks und KI-Scraping wachsen zusammen
Und jetzt zum spannendsten Teil: Die klassische „Browser-Automatisierung“ verschmilzt mit dem neuen Ansatz des „intelligenten Scraping“. Ich sehe eine Zukunft, in der technische und nicht-technische Teams nicht mehr zwischen Code und No-Code wählen müssen – sondern beides verbinden.
Hybride Workflows gewinnen an Bedeutung:
- Entwickler nutzen Frameworks wie Playwright für individuelle Automatisierung und binden bei Bedarf KI-Module für die semantische Datenerfassung ein.
- Geschäftsanwender starten mit No-Code-Tools wie Thunderbit und steigen bei Bedarf auf Code-Lösungen um.
- KI-Modelle werden immer besser darin, Webseitenstruktur, Kontext und sogar Absichten zu erkennen – Scraping wird dadurch robuster und weniger fehleranfällig.
Unternehmen, die diese Entwicklung mitgehen und Workflows schaffen, die sowohl programmierbar als auch für Nicht-Techniker zugänglich sind, werden agiler, datengetriebener und deutlich weniger frustriert sein.
Fazit: Das richtige Tool für dein Unternehmen wählen
Zusammengefasst:
- Puppeteer ist ein schnelles, Chrome-fokussiertes Automatisierungstool für JavaScript-Entwickler.
- Selenium ist der plattformübergreifende, mehrsprachige Klassiker – mächtig, aber etwas altbacken.
- Playwright ist die moderne, browserübergreifende und parallelisierungsfreundliche Alternative, ideal für CI/CD und fortgeschrittene Automatisierung.
- Thunderbit ist die No-Code-, KI-basierte Lösung für Geschäftsanwender, die zuverlässiges, semantisches Web Scraping ohne Aufwand wollen.
Die entscheidende Frage ist nicht, welches Tool „am besten“ ist – sondern welches zu den Fähigkeiten, Anforderungen und Wartungswünschen deines Teams passt. Entwickler, die individuelle Workflows bauen, fahren mit den klassischen Frameworks gut. Wer als Business-Anwender einfach schnell und zuverlässig an Daten kommen will – ohne Kopfschmerzen – sollte Thunderbit unbedingt ausprobieren.
Und wer wissen will, wie KI die Web-Scraping-Welt umkrempelt, sollte die aktuellen Entwicklungen verfolgen. Wir bewegen uns weg von „Klick hier, warte da“-Skripten hin zu Tools, die Webseiten wirklich verstehen – und damit wird Datenerfassung nicht nur schneller und smarter, sondern auch deutlich angenehmer.
Du willst mehr darüber erfahren, wie KI das Web Scraping verändert? Schau dir unsere weiteren Guides im Thunderbit Blog an, zum Beispiel Was ist Data Scraping und wie funktioniert es 2025 oder Wie man mit KI jede Website scrapt.
Und wenn du No-Code-, KI-gestütztes Scraping selbst ausprobieren willst, hol dir die Thunderbit Chrome Extension und erlebe intelligente Automatisierung in Aktion. Dein zukünftiges Ich (und dein datenhungriges Team) werden es dir danken.
Starte mit dem Thunderbit KI-Web-Scraper
FAQs
1. Was sind die Hauptunterschiede zwischen Puppeteer und Selenium?
Puppeteer ist eine Node.js-Bibliothek, die vor allem für die Automatisierung von Chrome und Chromium entwickelt wurde und eine moderne, einfache API für Aufgaben wie UI-Tests, Scraping und das Erstellen von Screenshots oder PDFs bietet. Selenium hingegen ist ein ausgereiftes, plattformübergreifendes Automatisierungs-Framework, das viele Programmiersprachen und alle gängigen Browser unterstützt. Während Puppeteer für Chrome-spezifische Aufgaben schneller und einfacher zu bedienen ist, bietet Selenium mehr Flexibilität für browserübergreifende Tests und verfügt über eine größere Community.
2. Wie verbessert Playwright die Arbeit mit Puppeteer und Selenium?
Playwright, entwickelt von Microsoft, baut auf den Stärken von Puppeteer auf und bietet echte plattformübergreifende Unterstützung (Chrome, Firefox, Safari, Edge) über eine einzige API. Es bringt Features wie parallele Ausführung, automatisches Warten auf Elemente und leistungsstarke Selektoren mit. Besonders beliebt ist Playwright für moderne Web-App-Tests und Automatisierung in CI/CD-Pipelines, da es zuverlässiger und wartungsfreundlicher ist als seine Vorgänger.
3. Welche Vorteile bieten No-Code-, KI-basierte Tools wie Thunderbit beim Web Scraping?
No-Code-, KI-basierte Tools wie Thunderbit richten sich an Geschäftsanwender, die schnell und ohne technische Hürden Webdaten benötigen. Thunderbit nutzt KI, um Webseiten semantisch zu verstehen, ist dadurch unempfindlich gegenüber Layout-Änderungen und dynamischen Inhalten. Nutzer können strukturierte Daten mit wenigen Klicks extrahieren, ohne Skripte zu schreiben oder zu pflegen. So entfallen typische Probleme wie Skriptbrüche, Entwicklerabhängigkeit und hohe Einstiegshürden.
4. Wann sollte ich ein Code-basiertes Tool (wie Puppeteer, Selenium oder Playwright) einem No-Code-Tool wie Thunderbit vorziehen?
Code-basierte Tools eignen sich am besten für Teams mit eigenen Entwicklern oder QA-Experten, die hochgradig individuelle Workflows, tiefe Integration in CI/CD-Pipelines oder fortgeschrittene Browser-Automatisierung benötigen. Wenn dein Projekt komplexe Testautomatisierung, spezielle Browser-Interaktionen oder Unterstützung für mehrere Programmiersprachen und Browser erfordert, sind diese Frameworks ideal. No-Code-Lösungen wie Thunderbit sind die bessere Wahl, wenn schnelle, zuverlässige Datenerfassung durch Nicht-Techniker – vor allem im Business-Kontext – gefragt ist.
5. Wie sieht die Zukunft von Browser-Automatisierung und Web-Scraping-Tools aus?
Die Zukunft der Browser-Automatisierung geht in Richtung hybrider Modelle, die die Programmierbarkeit klassischer Frameworks mit der Intelligenz und Zugänglichkeit von KI-basierten No-Code-Tools verbinden. Da KI-Modelle Webseitenstruktur und -kontext immer besser verstehen, profitieren sowohl technische als auch nicht-technische Nutzer von robusteren, weniger fehleranfälligen Automatisierungs-Workflows. Unternehmen, die sowohl Code- als auch No-Code-Lösungen nutzen, werden agiler und datengetriebener sein.
Mehr erfahren:
- Wie man mit KI jede Website scrapt
- Bilder in Excel umwandeln: JPG zu Word und Text
- MAP-Preisüberwachung: Der komplette Leitfaden
- Puppeteer vs Selenium: Was ist besser?
KI-Web-Scraper ausprobieren Get Started Free




