

Manche Menschen sammeln Briefmarken. Andere sammeln Sneaker. Wer aber 2026 im Vertrieb, Marketing, E-Commerce oder Operations arbeitet, sammelt vermutlich etwas… Digitaleres: Webdaten. Und das nicht zu knapp – Unternehmen geben inzwischen im Schnitt 5 Millionen US-Dollar pro Jahr (rund 4,6 Millionen €) für das Sammeln von Webdaten aus, und Web-Scraping gehört mittlerweile zum Standardrepertoire quer durch alle Abteilungen, von der Strategie bis zum Kundenservice (Quelle).
Mit diesem Boom tauchen zwei Namen in jedem Python-Scraping-Tutorial und jedem Business-Data-Projekt immer wieder auf: Playwright und Selenium. Beide haben als Browser-Automatisierungstools für Tests angefangen, sind heute aber die bevorzugten Frameworks für alle, die das Web in strukturierte, nutzbare Daten verwandeln wollen. Nur: Die Wahl zwischen beiden ist eben nicht bloß eine technische Entscheidung – es geht darum, das richtige Werkzeug für deinen konkreten Scraping-Use-Case zu finden. Und falls du kein Entwickler bist oder einfach schnell Ergebnisse willst, gibt es sogar einen noch einfacheren Weg (Tipp: ganz ohne eine einzige Zeile Python). Fangen wir an.
Von Testing-Tools zu Web-Scraping-Powerhouses: Playwright und Selenium erklärt
Zuerst das Fundament. Selenium gibt es seit 2004 und ist der verlässliche Klassiker der Browserautomatisierung. Ursprünglich für QA-Tester gebaut, steuerst du damit Browser wie Chrome, Firefox und sogar Internet Explorer (für alle, die gern ein Risiko eingehen). Playwright hingegen kam 2020 mit Unterstützung von Microsoft auf den Markt und bringt einen modernen Ansatz für Browserautomatisierung mit – gewissermaßen der jüngere, schnellere Bruder von Selenium.
Mit beiden Tools schreibst du Skripte (oft in Python), die einen Browser öffnen, zu einer Website navigieren, Buttons anklicken, Formulare ausfüllen und – für uns am wichtigsten – Daten extrahieren. Auch wenn ihre Wurzeln im automatisierten Testen liegen, bilden sie heute das Rückgrat des Web-Scrapings, von der Preisüberwachung bis zur Lead-Generierung (Quelle). Und ihre Beliebtheit reicht längst über die Entwicklerszene hinaus: Immer mehr Business-Anwender krempeln die Ärmel hoch, um eigene Scraper zu bauen – oder es zumindest zu versuchen.
Entscheidend ist aber: Beim Scraping verschieben sich die Prioritäten. Testabdeckung ist dir weniger wichtig als die Frage, ob du die Daten zuverlässig bekommst, Blockaden vermeidest und nicht das ganze Wochenende mit dem Debuggen von Python-Fehlern verlierst. Genau hier zeigen sich die echten Unterschiede zwischen Playwright und Selenium.
Die wichtigsten Unterschiede: Playwright vs. Selenium für Web-Scraping

Kurz gesagt: Mit Playwright und Selenium kannst du beide Websites scrapen, aber sie glänzen in unterschiedlichen Szenarien.
- Selenium ist der Veteran. Es funktioniert mit fast jedem Browser und jeder Sprache, hat eine riesige Community und eignet sich hervorragend für ältere, statische Websites mit vorhersehbaren Layouts.
- Playwright ist der Neuling mit modernen Features. Es wurde für die heutigen dynamischen, stark von JavaScript geprägten Websites entwickelt und bringt integrierte Werkzeuge für Logins, Pop-ups, Infinite Scroll und mehr mit. Außerdem ist es schneller und leichter einzurichten, besonders für Python-Nutzer.
Aber verlass dich nicht nur auf mein Wort – gehen wir die Unterschiede Punkt für Punkt durch.
Feature-Vergleich: Playwright vs. Selenium
| Feature | Selenium | Playwright |
|---|---|---|
| Sprachunterstützung | Python, Java, C#, JS, Ruby, mehr | Python, JS/TS, Java, C# |
| Browser-Unterstützung | Chrome, Firefox, Edge, Safari, IE, Opera | Chromium (Chrome/Edge), Firefox, WebKit |
| Einrichtungsaufwand | Benötigt Browser-Driver, manuelle Konfiguration | Ein Befehl installiert alles |
| Geschwindigkeit/Leistung | Langsamer, ressourcenintensiver | In der Regel schneller auf JavaScript-lastigen Seiten; asynchron und parallel konzipiert |
| Umgang mit dynamischen Inhalten | Manuelle Wartezeiten, mehr Code erforderlich | Auto-Waits, kommt mit JavaScript-lastigen Seiten problemlos klar |
| Anti-Bot-Umgehung | Leicht erkennbar, Zusatzmodule nötig | Integrierte Stealth-Funktionen, imitiert Nutzer besser |
| Debugging-Tools | Einfach (Selenium IDE, Screenshots) | Inspector, Videoaufzeichnung, Code-Gen |
| Community-Support | Riesig, ausgereift, viele Tutorials | Wächst schnell, moderne Doku, aktive Entwickler |
| Python-Scraper-Workflow | Mehr Setup, mehr Boilerplate | Reibungsloser, weniger Code, einfacher für Einsteiger |
Das richtige Tool wählen: Wann Playwright oder Selenium für Web-Scraping einsetzen
Welches Tool solltest du also für dein nächstes Scraping-Projekt nehmen? Hier meine Einschätzung nach Jahren in der Entwicklung von Automatisierungstools und beim Helfen von Teams, Daten aus dem wilden Web zu holen.
- Selenium ist die richtige Wahl, wenn:
- Die Website altmodisch ist – also statisches HTML, kaum JavaScript und keine ausgefeilten Pop-ups.
- Du ungewöhnliche Browser unterstützen musst (hallo, Internet Explorer) oder Legacy-Systeme einbinden willst.
- Du den Komfort einer riesigen Community und endloser StackOverflow-Antworten schätzt.
- Du mit Selenium bereits aus Testprojekten vertraut bist.
- Playwright ist die bessere Wahl, wenn:
- Die Website modern, dynamisch und voller JavaScript ist (denk an E-Commerce, Social Media oder alles, was den Lüfter deines Laptops auf Touren bringt).
- Du dich einloggen, durch Tabs klicken, Infinite Scroll verarbeiten oder mit Pop-ups umgehen musst.
- Du schnell loslegen willst, mit weniger Setup und weniger Code.
- Du es leid bist, überall
time.sleep(5)zu schreiben, und lieber möchtest, dass das Tool das Timing für dich übernimmt.
Eine einfache Faustregel: Wenn dein erster Scraping-Versuch mit Selenium aus vielen „Warum lädt das nicht?“-Momenten besteht, ist es wahrscheinlich Zeit, Playwright auszuprobieren.
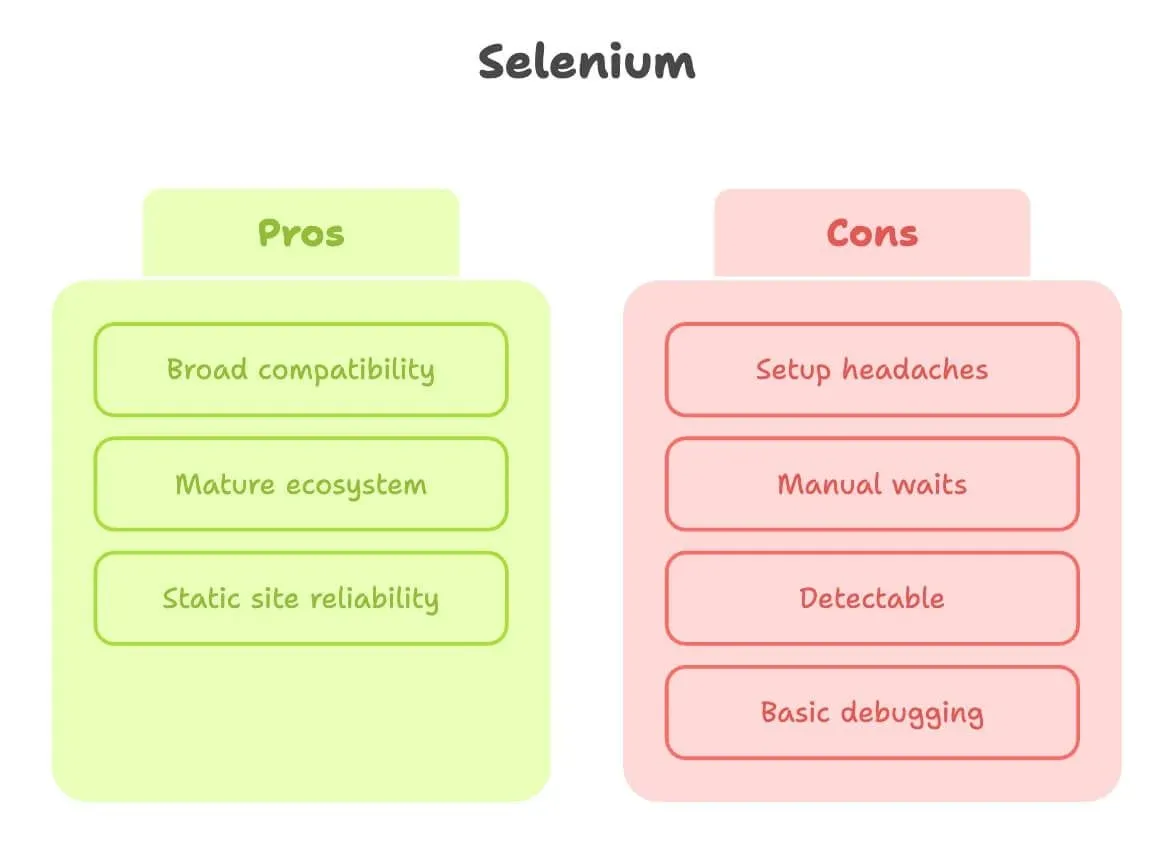
Selenium für Web-Scraping: Stärken und Grenzen
Geben wir Selenium, was ihm gebührt. Es ist der Urvater der Browserautomatisierung, und für viele Scraping-Jobs funktioniert es schlicht.
Stärken:
- Breite Kompatibilität: Funktioniert mit fast jedem Browser und jeder Sprache.
- Ausgereiftes Ökosystem: Unzählige Tutorials, Q&A und Plugins.
- Sehr gut für statische Seiten: Wenn sich die Seite kaum verändert, ist Selenium absolut verlässlich.
Grenzen:
- Aufwendige Einrichtung: Du musst einen Browser-Driver herunterladen und konfigurieren (z. B. ChromeDriver) und ihn aktuell halten. Einsteiger bleiben hier oft hängen (Quelle).
- Manuelle Wartezeiten: Dynamische Inhalte? Dann schreibst du viele explizite Waits oder, schlimmer noch, zufällige Sleep-Anweisungen.
- Leichter zu erkennen: Viele Websites erkennen von Selenium gesteuerte Browser und blockieren sie, besonders auf Cloud-Servern.
- Debugging ist simpel: Keine integrierte Videoaufzeichnung oder interaktiver Inspector.
Kurz gesagt: Selenium ist perfekt für einfache, stabile Websites – auf modernen, interaktiven Seiten kann es sich aber anfühlen, als würde man einen Felsbrocken bergauf schieben.
Playwright für Web-Scraping: Stärken und Grenzen
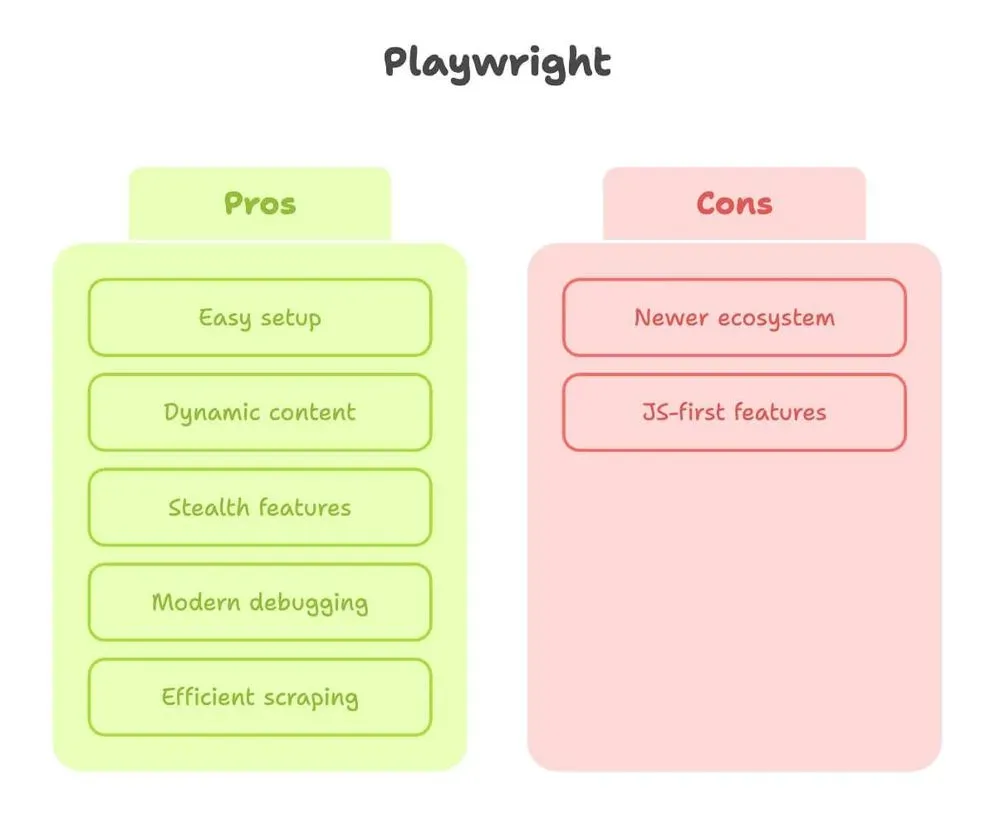
Jetzt zu Playwright. Als jemand, der viel Zeit mit beiden Tools verbracht hat, kann ich sagen: Playwright wirkt, als hätten es Leute gebaut, die selbst genug unter Web-Scraping gelitten haben.
Stärken:
- Einfache Einrichtung: Ein
pip install, ein Befehl, und los geht’s. Kein Driver-Drama. - Beherrscht dynamische Inhalte: Wartet automatisch auf Elemente, sodass du nicht raten musst, wann die Seite bereit ist (Quelle).
- Stealth-Funktionen: Imitiert echte Nutzer besser, mit integriertem Stealth-Modus und Multi-Context-Support (super, wenn du als mehrere „Nutzer“ gleichzeitig scrapen willst).
- Modernes Debugging: Inspector, Videoaufzeichnung und sogar Code-Generierung aus deinen manuellen Klicks.
- Schneller und effizienter: Besonders beim Scrapen vieler Seiten oder beim parallelen Ausführen.
Grenzen:
- Jüngeres Ökosystem: Etwas weniger Tutorials, auch wenn die Lücke schnell kleiner wird.
- Einige Funktionen sind eher JavaScript-first: Das meiste funktioniert in Python, aber gelegentlich ist eine Funktion in JS besser dokumentiert.
Letztlich: Playwright ist meine erste Wahl für jede Seite, die auch nur ein bisschen dynamisch ist – oder wenn ich schnell Ergebnisse will, ohne mit der Einrichtung zu kämpfen.
Anti-Bot-Umgehung: Welcher Python-Scraper kommt mit modernen Websites besser klar?
Sprechen wir das offen aus: blockiert werden. Beim Web-Scraping ist die größte Hürde nicht das Schreiben von Code – sondern sicherzustellen, dass die Website dir nicht sofort die Tür vor der Nase zuschlägt.
- Selenium: Von Haus aus ist es leichter zu erkennen. Websites können das
webdriver-Flag, Headless-User-Agents und andere verräterische Signale ausmachen. Es gibt Umgehungen (z. B. undetected-chromedriver), aber sie brauchen zusätzliche Einrichtung und hinken den Anti-Bot-Technologien ständig hinterher (Quelle). - Playwright: Bringt integrierte Stealth-Funktionen mit, versteckt Automatisierungs-Fingerabdrücke automatisch, unterstützt mehrere Browser-Contexts und wartet auf echte, nutzerähnliche Interaktionen. Es ist keine Zauberei, aber du wirst beim ersten Versuch seltener blockiert.
Die Wahrheit ist aber: Keines der beiden Tools ist vollständig immun gegen Anti-Bot-Maßnahmen. Bei besonders kritischem Scraping (denk an Sneaker-Drops oder Ticketing-Seiten) brauchst du weiterhin Proxys, IP-Rotation und vielleicht sogar CAPTCHAs. Playwright macht es nur etwas weniger schmerzhaft.
Developer Experience: Einrichtung, Lernkurve und Debugging
Reden wir über die tatsächliche Erfahrung beim Einstieg – besonders, wenn du Anfänger bist oder den Job einfach erledigen willst, ohne einen Doktortitel in Python zu haben.
- Selenium:
- Einrichtung: Python installieren, Selenium installieren, den passenden Browser-Driver herunterladen, in deinen PATH legen und hoffen, dass die Versionen zusammenpassen. (Ich habe mehr Leute am Driver-Schritt scheitern sehen als am eigentlichen Scraping.)
- Lernkurve: Viele Ressourcen, aber auch viel Legacy-Code und veraltete Tutorials.
- Debugging: Meist Print-Anweisungen und Screenshots. Selenium IDE gibt es zwar, aber sie ist ziemlich simpel.
- Playwright:
- Einrichtung:
pip install playwright, dannplaywright install. Fertig. - Lernkurve: Moderne Doku, viele Beispiele, und die API wirkt menschlicher – du kannst Elemente über Text, Rolle oder sogar Platzhalter auswählen.
- Debugging: Mit dem Inspector gehst du dein Skript Schritt für Schritt durch, beobachtest den Browser und zeichnest sogar Videos deiner Scraping-Läufe auf (Quelle).
- Einrichtung:
Wenn du schnell Ergebnisse sehen und weniger Zeit mit Setup und Fehlersuche verbringen willst, ist Playwright der klare Gewinner. Selenium ist großartig, wenn du mit seinen Eigenheiten bereits vertraut bist oder seine breite Kompatibilität brauchst.
Schritt für Schritt: Deinen ersten Python-Web-Scraper mit Playwright oder Selenium bauen
Schauen wir uns an, wie es konkret aussieht, einen Scraper mit jedem Tool zu bauen – ohne Code, nur die Schritte.
Playwright (Python):
- Playwright und Browser installieren:
pip install playwright+playwright install - Browser starten: Chromium-, Firefox- oder WebKit-Browser öffnen (headless oder sichtbar).
- Zur Seite navigieren:
page.goto("<https://example.com>") - Auf Inhalte warten: Playwright wartet automatisch, bis Elemente geladen sind.
- Daten extrahieren: Mit benutzerfreundlichen Selektoren arbeiten (z. B.
get_by_text,locator("span.price")). - Paginierung oder Unterseiten behandeln: Durch Seiten iterieren oder Links anklicken – Playwright macht es leicht, mehrere Seiten parallel auszuführen.
- Daten exportieren: Als CSV, Excel oder in eine Datenbank speichern.
- Debugging: Den Inspector oder Videoaufzeichnung nutzen, wenn etwas schiefläuft.
Selenium (Python):
- Selenium installieren:
pip install selenium - Browser-Driver herunterladen: (z. B. ChromeDriver für Chrome), in deinen PATH legen.
- Browser starten: Chrome, Firefox oder einen anderen Browser öffnen.
- Zur Seite navigieren:
driver.get("<https://example.com>") - Auf Inhalte warten: Manuell explizite Wartezeiten (
WebDriverWait) hinzufügen oder, wenn du Glücksritter bist,time.sleepverwenden. - Daten extrahieren:
find_elementoderfind_elementsverwenden (CSS-/XPath-Selektoren). - Paginierung oder Unterseiten behandeln: Über URLs iterieren oder Buttons anklicken, aber Timing und Navigation musst du selbst managen.
- Daten exportieren: Als CSV, Excel oder in eine Datenbank speichern.
- Debugging: Meist manuell – Browser beobachten, HTML ausgeben oder Screenshots machen.
Merkst du den Unterschied? Playwright ist für moderne Websites einfach ein Stück mehr „Plug and Play“.
Jenseits von Code: No-Code-Web-Scraping mit Thunderbit AI Web Scraper
Daten von jeder Website mit KI extrahieren Get Started Free
Seien wir ehrlich: Nicht jeder will Python-Guru werden, nur um eine Tabelle mit Produktpreisen oder eine Lead-Liste zu bekommen. Vielleicht arbeitest du in Vertrieb, Marketing, Immobilien oder Operations und willst die Daten einfach – jetzt. Genau hier kommt Thunderbit ins Spiel.
Als Mitgründer von Thunderbit habe ich aus erster Hand erlebt, wie viele Business-Anwender den Code einfach überspringen und direkt zum Ergebnis wollen. Deshalb haben wir eine KI-gestützte Chrome-Erweiterung entwickelt, mit der du jede Website in zwei Klicks scrapst – kein Python, keine Drivers, kein Debugging.
So funktioniert Thunderbit
- Ruf die Website auf, die du scrapen willst.
- Klicke auf „KI-Felder vorschlagen“. Die KI von Thunderbit analysiert die Seite und empfiehlt die Datenfelder (z. B. Produktname, Preis, Bild, Bewertung).
- Klicke auf „Scrapen“. Sofort erhältst du eine strukturierte Datentabelle.
- Export nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON. Fertig.
Kein Herumprobieren mit Selektoren, kein Trial-and-Error, kein Code. So einfach wie Essen zu bestellen – und mal ehrlich, wahrscheinlich schneller, als auf das Essen zu warten.
Thunderbit AI Web Scraper kostenlos testen
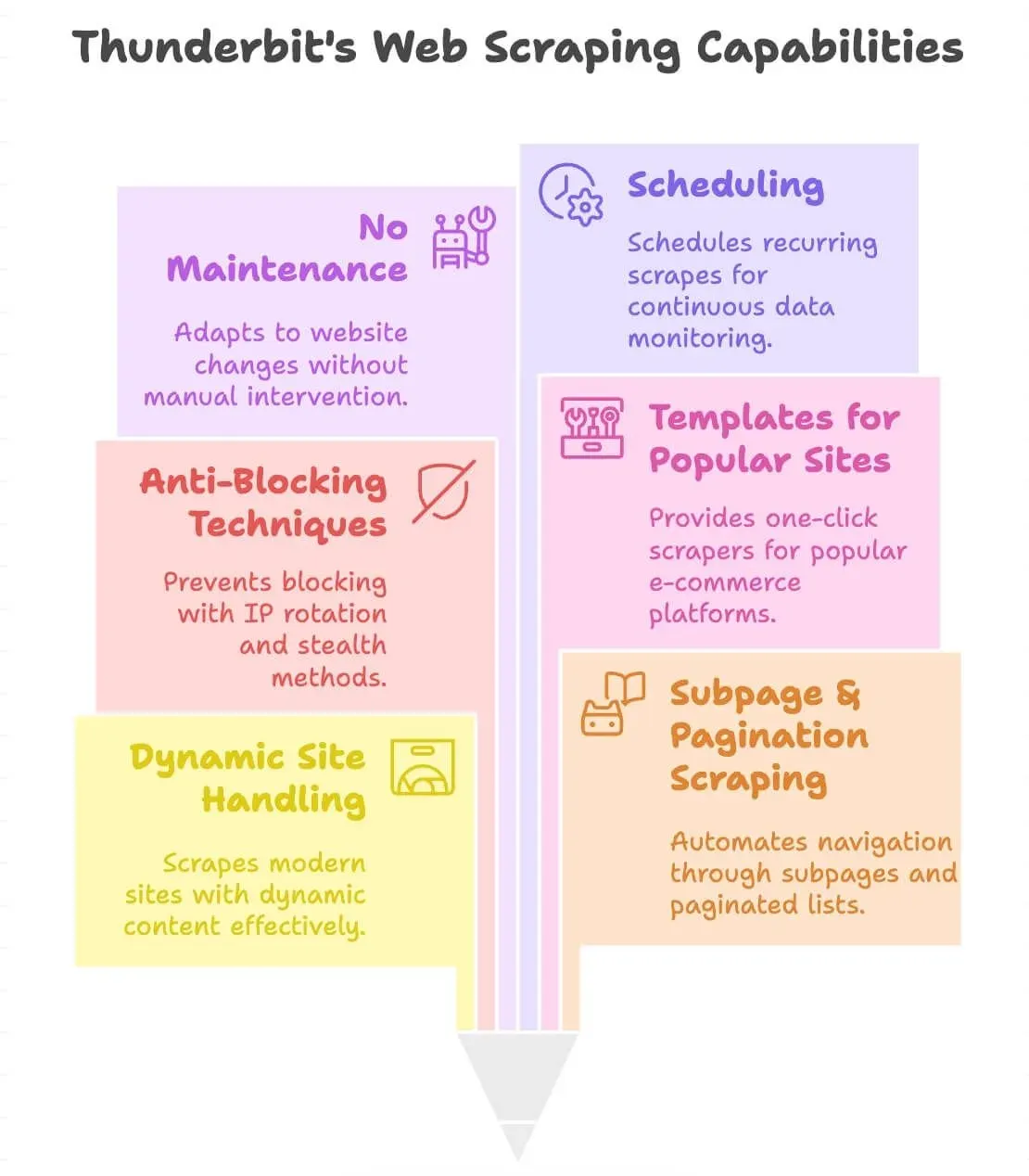
Was macht Thunderbit anders?
- Beherrscht dynamische Websites: Scrapt moderne E-Commerce-Seiten, Verzeichnisse und sogar Seiten mit Infinite Scroll oder Pop-ups.
- Scraping von Unterseiten und Paginierung: Klickt automatisch durch Produktseiten oder paginierte Listen, damit du alle benötigten Daten bekommst.
- Integrierter Blockierschutz: Nutzt IP-Rotation im Backend und Stealth-Techniken, damit du seltener blockiert wirst.
- Vorlagen für beliebte Websites: Ein-Klick-Scraper für Amazon, eBay, Shopify, Zillow und mehr (Details in unserem Blog).
- Weniger Wartung: Ändert sich das Layout einer Website, erkennt der Durchlauf „KI-Felder vorschlagen“ die Felder oft neu – meist führst du also nur den Vorschlag erneut aus, statt ein Selektor-Skript komplett neu zu bauen.
- Zeitplanung: Richte wiederkehrende Scrapes für laufendes Monitoring ein (z. B. tägliche Preisprüfungen).
- Unterstützt 55 Sprachen: Daten von nahezu überall scrapen und übersetzen.
Und das Beste? Du musst nichts über HTML, CSS oder Python wissen. Wer einen Browser bedienen kann, kann auch Thunderbit nutzen.
Welche Web-Scraping-Lösung ist die richtige für dich?
Zum Abschluss ein kurzer Entscheidungsleitfaden:
| Deine Situation | Bestes Tool |
|---|---|
| Du scrapest eine statische, einfache Website und stört dich das Setup nicht | Selenium |
| Du scrapest eine moderne, dynamische Website und willst schnelle Ergebnisse | Playwright |
| Du musst Legacy-Browser oder -Sprachen unterstützen | Selenium |
| Du willst einfache Einrichtung, modernes Debugging und weniger Code | Playwright |
| Du bist kein Entwickler und willst Daten sofort, ohne Code und ohne Setup | Thunderbit |
| Du musst mehrere Seiten, Unterseiten oder geplante Jobs scrapen | Thunderbit |
| Du willst direkt nach Excel, Sheets, Notion oder Airtable exportieren | Thunderbit |
| Du hasst das Debuggen von Python-Fehlern | Thunderbit |
Wenn du Entwickler bist oder gern mit Code herumtüftelst, sind Playwright und Selenium beide starke Optionen. Geht es dir aber darum, Daten so schnell wie möglich in eine Tabelle zu bekommen, sparst du mit Thunderbit Stunden – vielleicht sogar Tage – an Arbeit.
Mit Thunderbit AI Web Scraper starten
Fazit: Schnelles, zuverlässiges Web-Scraping – auf deine Weise
Web-Scraping ist im Mainstream angekommen, und das aus gutem Grund: Unternehmen brauchen Daten, um konkurrenzfähig zu bleiben, und sie brauchen sie jetzt. Playwright und Selenium haben sich beide von bescheidenen Test-Tools zu unverzichtbaren Scraping-Frameworks entwickelt, jedes mit seinen eigenen Stärken. Selenium ist der bewährte Klassiker für statische Websites und Legacy-Setups; Playwright die moderne, schnelle Wahl für dynamische, interaktive Seiten.
Mein ehrlicher Rat nach Jahren in SaaS, Automatisierung und KI: Wenn es dir nicht ums Coden geht, verschwende deine Zeit nicht mit Drivers, Selektoren und Anti-Bot-Tricks. Mit Thunderbits AI Web Scraper kommst du in Minuten – nicht Tagen – von „Ich brauche diese Daten“ zu „Hier ist meine Excel-Datei“.
Egal also, ob du ein Python-Profi bist oder ein Business-Anwender, der einfach Ergebnisse will: Es gibt eine Scraping-Lösung, die zu deinen Bedürfnissen – und deiner Geduld – passt. Probier sie aus, finde heraus, was für deinen Workflow funktioniert, und behalte im Hinterkopf: Der beste Scraper ist der, der dir die benötigten Daten mit möglichst wenig Aufwand liefert.
Und falls du dich jemals um 2 Uhr morgens beim Debuggen eines Selenium-Driver-Fehlers erwischst, denk einfach daran: Thunderbit ist dann immer noch da – bereit, in zwei Klicks zu scrapen. Viel Erfolg beim Scrapen.
Möchtest du mehr über No-Code-Scraping, KI-gestützte Datenerfassung und darüber erfahren, wie Thunderbit deinem Team helfen kann? Schau dir unseren Blog an oder starte noch heute mit der Thunderbit Chrome Extension.
P.S. Wenn du dir noch nicht sicher bist, welches Tool du verwenden sollst, oder Thunderbit in Aktion sehen möchtest, schau auf unserem YouTube-Kanal vorbei – für Demos, Tipps und gelegentliche Web-Scraping-Witze. (Ja, die gibt’s bei uns.)
Weiterführende Lektüre:
- Was ist Data Scraping und wie macht man es 2025
- Wie man Amazon-Produkte und -Bewertungen 2025 mit KI scraped
- Die besten Web-Scraping-Tools & Software im Jahr 2025
KI-Web-Scraper testen Get Started Free




