

Die meisten Beiträge zu „playwright vs puppeteer“ gehen schon davon aus, dass eines der beiden die bessere Lösung fürs web scraping sein muss. Diese Annahme trägt mehr Gewicht, als sie verdient. Ich habe beide Bibliotheken gegen exakt dieselben Seiten getestet — einen statischen Katalog, einen JavaScript-gerenderten Katalog, einen Artikel, einen defekten 500-Fehler, einen kleinen Crawl-Graphen sowie zwei öffentliche Übungsseiten — und die Ergebnisse waren nahezu identisch. Gleiche Trefferquote, gleiches Rendering, gleiche Screenshots, gleiche Lücken.
Das hier ist also keine Krönung eines Siegers. Bei den Aufgaben, die wirklich entscheiden, ob ein Browser-Automation-Tool eine Seite scrapen kann, lag keiner von beiden vorne. Was folgt, ist der eine echte Unterschied, der Ihre Wahl lenken sollte, der Punkt, den beide stillschweigend Ihnen überlassen zu bauen, und ein Hinweis auf den Versionsstand, den ich getestet habe (Stand: 2026-07-09).
Warum dieser Vergleich überhaupt fair ist
Vergleichsartikel haben oft die schlechte Angewohnheit, jedes Tool auf anderen Seiten zu testen und dann einen Gewinner auszurufen — das sagt Ihnen aber mehr über die Seiten als über die Tools. Ich habe das vermieden, indem ich Playwright und Puppeteer gegen denselben lokalen Fixture-Server und dieselben öffentlichen Demos laufen ließ, Books to Scrape und Quotes to Scrape, sodass jede Zahl eins zu eins nebeneinandersteht.
Nur so ergibt ein „Unentschieden“ überhaupt Sinn. Wenn die Fixtures unterschiedlich sind, ist ein Gleichstand nur Rauschen. Wenn sie Byte für Byte identisch sind, sind gleiche Ergebnisse ein echtes Signal über die Tools selbst.
Was die beiden Tools eigentlich sind
Puppeteer ist eine JavaScript-API zur Steuerung von Chrome, umgesetzt über das Chrome DevTools Protocol. Die offizielle Beschreibung trifft es genau: „a JavaScript API to control Chrome (and experimentally Firefox).“ Die Bibliothek ist ausgereift, klar auf Chrome ausgerichtet und für Node gebaut.
Playwright positioniert sich anders — als „a framework for Web Testing and Automation“, das Chromium, Firefox und WebKit über eine einzige API ansteuert, mit offiziellen Clients in JavaScript, Python, Java und .NET. Beide stammen aus demselben Umfeld (Playwright wurde vom Team hinter Puppeteer bei Google entwickelt, bevor es zu Microsoft wechselte), weshalb sie sich eher wie Cousins als wie Rivalen anfühlen.
Für Scraping verhalten sie sich aber praktisch gleich. Einen echten Browser starten, eine Seite öffnen, die Skripte laufen lassen und dann das gerenderte DOM auslesen. Genau deshalb greift man überhaupt zu einem dieser Tools statt zu einem HTTP-Parser: Man will die Seite nach der JavaScript-Ausführung, nicht die leere Hülle davor. Alles unten baut auf genau diesem gemeinsamen Mechanismus auf — und genau deshalb ist vieles am Ende ein Patt.
Die Ergebnisse im direkten Vergleich
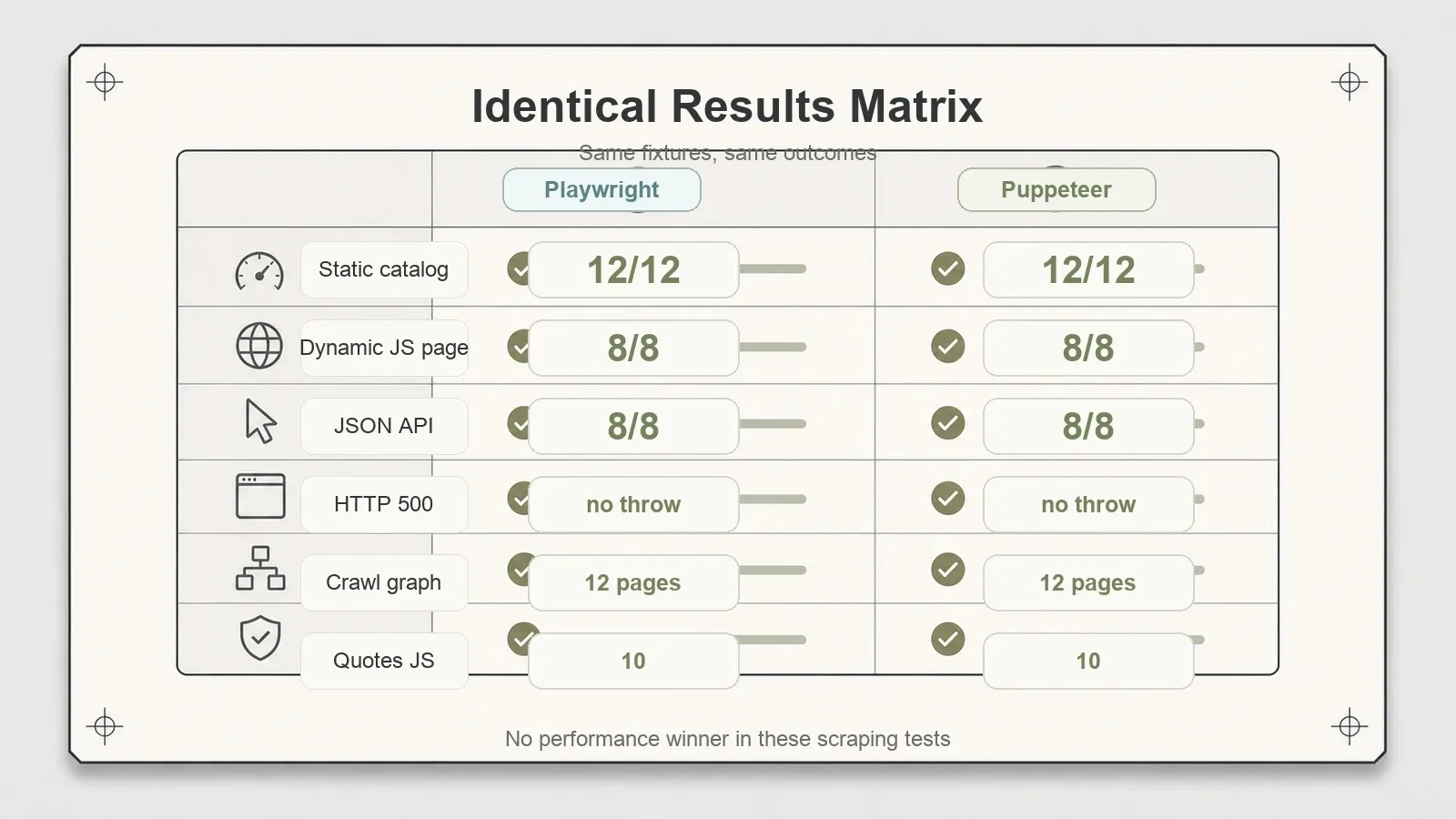
Hier bricht die Geschichte vom „einen klar besseren Tool“ leise zusammen. Gleiche Fixtures, gleiche Zahlen, überall.
| Test | Playwright | Puppeteer |
|---|---|---|
| Statischer Katalog (12 Produkte) | 12/12, Recall 1.0 | 12/12, Recall 1.0 |
| Artikel (Titel + 3 Absätze) | 3/3, Boilerplate getrennt | 3/3, Boilerplate getrennt |
| Dynamische JS-Seite (native Darstellung) | 8/8 + Screenshot | 8/8 + Screenshot |
| Dynamische JSON-API | 8/8, Recall 1.0 | 8/8, Recall 1.0 |
| Umgang mit HTTP 500 | auslesbare Antwort, kein Throw | auslesbare Antwort, kein Throw |
| Crawl-Graph (handgeschriebene BFS) | 12 Seiten, Tiefen {0,1,2} | 12 Seiten, Tiefen {0,1,2} |
| Books to Scrape | 20 Produkte | 20 Produkte |
| Quotes JS (öffentlich) | 10 Zitate | 10 Zitate |
Beide renderten JavaScript nativ, ganz ohne besondere Konfiguration. Beide erstellten Full-Page-Screenshots. Beide behandelten den 500-Fehler so, dass eine auslesbare Response-Objekt zurückgegeben wurde, statt eine Exception zu werfen — eine Kleinigkeit, die bei Scraping in größerem Umfang wichtig wird, wenn man einen schlechten Status protokollieren will, statt einen Lauf abstürzen zu lassen.

Ein wichtiger Hinweis, weil er leicht missbraucht wird: Das hier waren Beobachtungen auf einer Maschine in einem Lauf, keine Benchmarks. Ich behaupte nicht, dass eines in Millisekunden schneller ist als das andere, denn ein Stopuhrwert pro Seite auf einem Laptop ist kein echter Geschwindigkeitstest. Was ich behaupte, ist enger und besser belegt: Bei der Extraktionsgenauigkeit und beim Rendering-Verhalten haben sie sich über acht unterschiedliche Seitentypen hinweg nicht unterschieden. Wer gehofft hat, eines würde bei einer realen Seite davonziehen, wurde enttäuscht.
Der eine Unterschied, der die Entscheidung bestimmen sollte
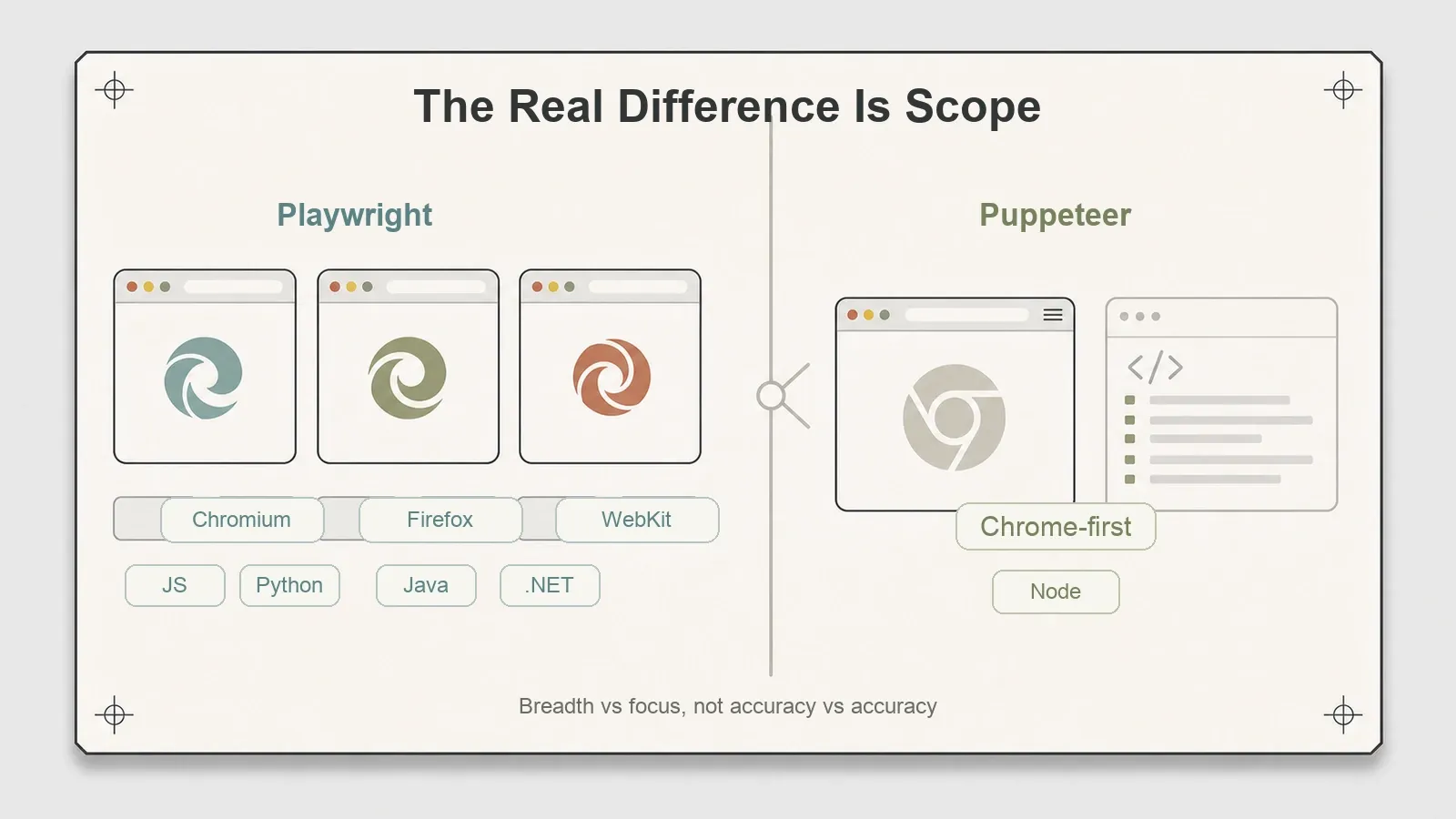
Der eigentliche Unterschied liegt nicht in den Zahlen, sondern im Umfang.
Playwright steuert drei Engines — Chromium, Firefox und WebKit — über eine einzige API an und bietet erstklassige Clients in Python, Java und .NET zusätzlich zu JavaScript. Das ist eine dokumentierte Stärke, und ich möchte bei dem Wort „dokumentiert“ präzise sein: In diesem Durchlauf habe ich nur Chromium verwendet. Ich gebe Playwrights Unterstützung für drei Engines also als offiziell beschriebene Fähigkeit wieder, die ich nicht selbst unabhängig überprüft habe, nicht als etwas, das ich in diesem Test vollständig validiert hätte. Wenn Sie eine Seite scrapen müssen, die sich unter Safaris WebKit anders verhält, oder Ihr Team in Python arbeitet, dann ist genau diese Breite das Argument für Playwright.
Puppeteer ist klar auf Chrome ausgerichtet, und hier liegt die gängige Kurzfassung falsch. „Nur Chrome“ stimmt inzwischen nicht mehr. Seit Puppeteer v23 gibt es produktionsreife Firefox-Unterstützung über WebDriver BiDi, während für Chrome standardmäßig weiter CDP genutzt wird, um bestehende Automationen beizubehalten — ein Schritt, den sowohl Chrome for Developers als auch Mozilla dokumentiert haben. Die Version, die ich getestet habe (24.16.0), liegt deutlich über v23, also lautet der reale Vergleich nicht „Chrome gegen drei Engines“. Er lautet: Puppeteer deckt Chrome (CDP) plus Firefox (BiDi) ab, aber nicht WebKit, und seine Cross-Engine-Geschichte ist jünger als die von Playwright. Die Engine, die Playwright hat und Puppeteer nicht, ist WebKit.
Das ist die eigentliche Entscheidung, auf den Punkt gebracht. Nicht Geschwindigkeit, nicht Genauigkeit, nicht Rendering-Treue — da sind beide gleichauf. Es ist eine Frage des Umfangs: Brauchen Sie WebKit-Unterstützung oder Clients für Nicht-JavaScript-Sprachen, oder reichen Ihnen Chrome und Firefox aus Node heraus für Ihre Ziele? Für einen großen Teil der Scraping-Aufgaben erfüllen beide Tools die Anforderungen, und die Wahl hängt eher vom Tech-Stack als von der reinen Fähigkeit ab.
Was beide nicht mitbringen
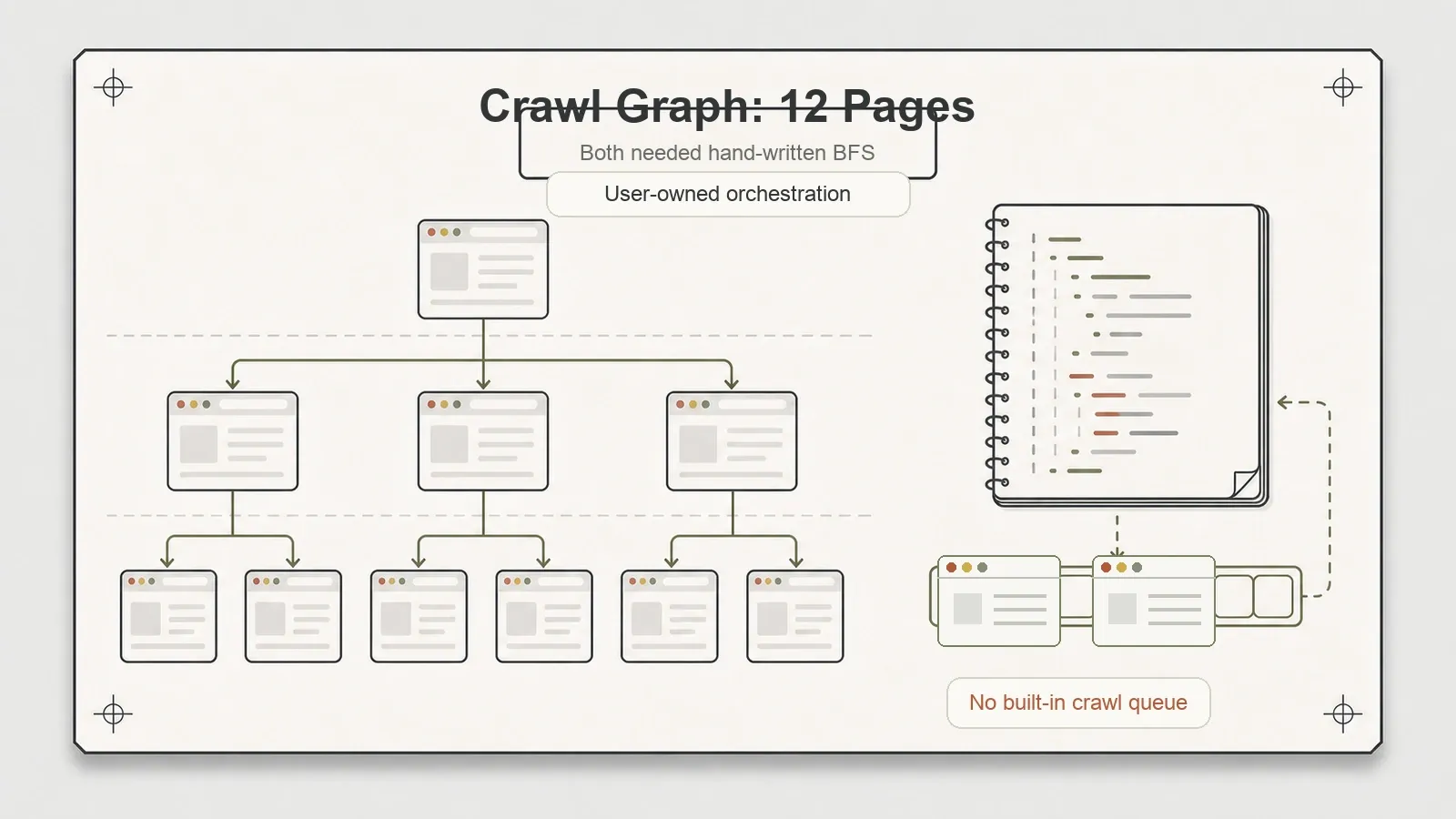
Beide Tools lassen denselben Job auf Ihrem Tisch liegen: die Crawl-Orchestrierung. Keines bringt eine eingebaute Request-Queue, einen Dataset-Writer oder Auto-Throttling mit. Mein Crawl-Graph-Test — interne Links folgen, Tiefe erfassen, keine URL erneut besuchen — brauchte in beiden Fällen eine selbst geschriebene Breadth-First Search. Zwölf Seiten, Tiefen {0,1,2}, meine eigene BFS, beide Male.
Für ein paar Seiten ist das völlig in Ordnung; eine kleine BFS sind ein Dutzend Zeilen. Für Crawling im großen Maßstab — Hunderte oder Tausende URLs mit Deduplizierung, Retries und höflichen Verzögerungen — bauen Sie diese Mechanik entweder selbst oder greifen zu etwas, das diese Engines umhüllt. Crawlee macht genau das und bietet eine echte Crawling-Schicht über Playwright und Puppeteer.
Das ist kein Makel, und ich möchte es korrekt einordnen: Playwright und Puppeteer sind Browser-Automation-Frameworks, keine Crawler-Frameworks. Die fehlende Queue ist eine Abgrenzung des Umfangs, kein Bug. Das treffende mentale Modell ist: Diese Tools sind der „Seite anzeigen“-Teil eines Scrapers. Den „Website ablaufen“-Teil müssen Sie selbst mitbringen — also selbst schreiben oder einen Wrapper verwenden, der ihn schon hat.
Setup und der Versionshinweis
Die Installation ist nahezu identisch. npm install zieht die Bibliothek plus ein Browser-Binary, und genau dieses Binary ist der schwere Teil — Puppeteer bringt automatisch einen Chrome-Download mit (saubere Installation in meinem Lauf, keine gemeldeten Schwachstellen), während Playwright für seine Browser-Builds zusätzlich npx playwright install verwendet. Keine der beiden Installationen ist schmerzhaft, aber der Download sollte in beiden Fällen einkalkuliert werden; das Browser-Volumen und die Kosten pro Seite sind der eigentliche Preis, den man fürs Rendering zahlt — im Gegensatz zu einem reinen HTTP-Tool.
Nun die Offenlegung, die ich Ihnen schulde. Ich habe Playwright 1.56.0 gegen eine aktuelle Version 1.61.1 getestet und Puppeteer 24.16.0 gegen die aktuelle npm-Version 25.3.0 — bei Puppeteer also eine volle Major-Version zurück, Stand ebenfalls 2026-07-09. Die APIs, die ich verwendet habe, sind über diese Abstände hinweg stabil, daher sind die Ergebnisse belastbar. Wenn Sie diesen Text aber eine Weile nach Veröffentlichung lesen, sollten Sie die Tests mit aktuellen Versionen noch einmal wiederholen, bevor Sie exakte Zahlen darauf aufbauen. Und noch einmal: Ich habe unter Playwright nur Chromium verwendet, daher behaupte ich nichts über Firefox- oder WebKit-Parität über die Aussage hinaus, dass sie dokumentiert ist.
Playwright und Puppeteer: Vor- und Nachteile
Das Unentschieden bedeutet, dass die Vor- und Nachteile weniger um „Gewinnen“ gehen und mehr darum, worauf Sie sich einlassen.
Playwright
- Vorteile: dokumentierte Unterstützung für drei Engines (Chromium, Firefox, WebKit) über eine einzige API; offizielle Clients für Python, Java und .NET; natives JavaScript-Rendering mit voller Trefferquote; aktiv ausgebaut.
- Nachteile: keine eingebaute Crawl-Queue; Browser-Volumen und Kosten pro Seite; in diesem Test nur Chromium verwendet; die getestete Version lag hinter dem neuesten Release.
Puppeteer
- Vorteile: ausgereifte, stabile Chrome-Automation über CDP; natives JavaScript-Rendering mit voller Trefferquote; sauberer Umgang mit HTTP 500 (Response-Objekt, kein Throw); tiefes, bewährtes Ökosystem; dokumentierte Firefox-Unterstützung via WebDriver BiDi seit v23.
- Nachteile: klar auf Chrome und Node fokussiert, ohne WebKit-Engine; keine eingebaute Crawl-Queue; Browser-Volumen; die getestete Version lag eine volle Major-Version hinter dem neuesten npm-Stand.
Wer sollte was wählen?
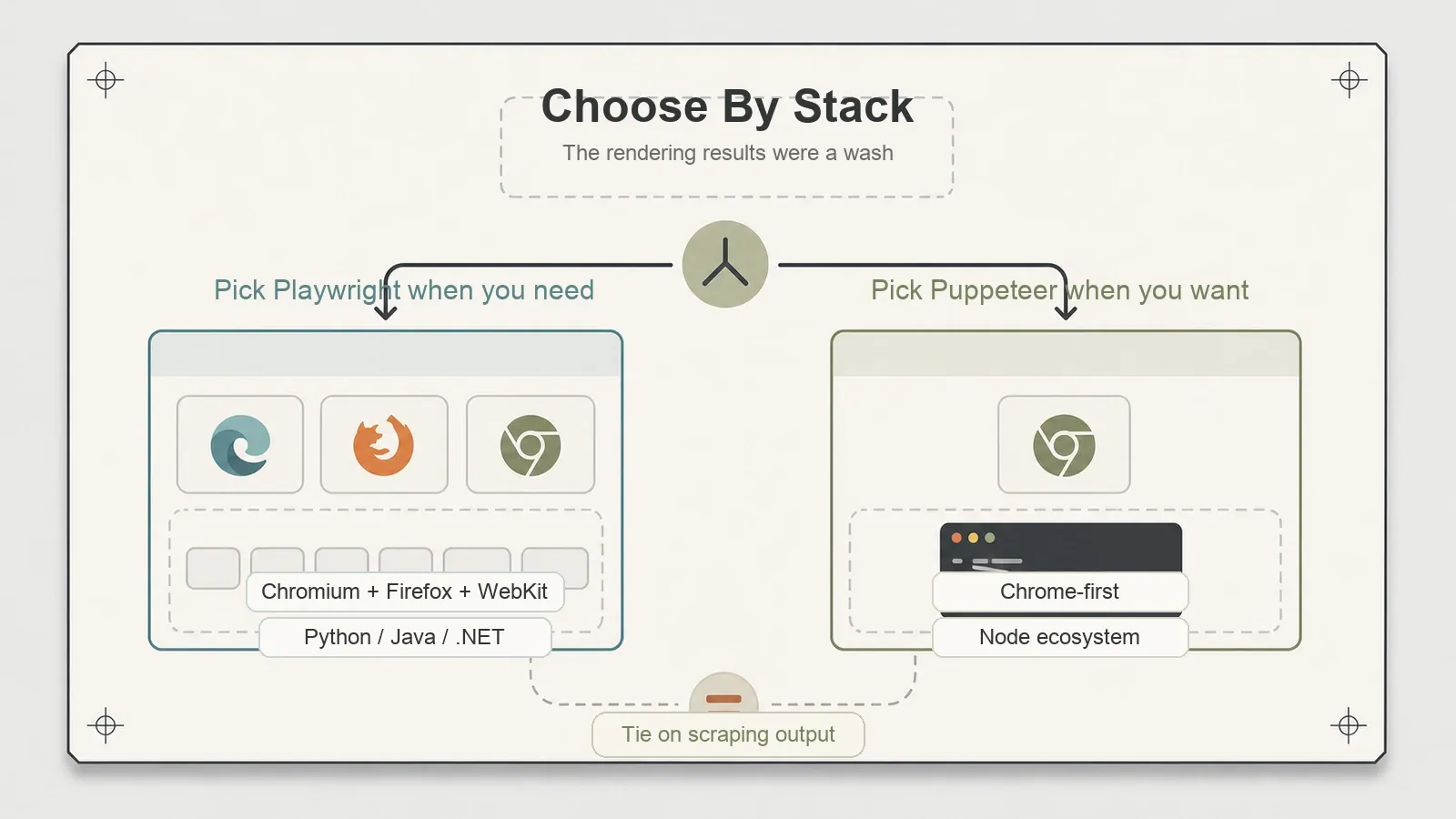
Nehmen Sie Puppeteer, wenn Sie in Node arbeiten, Ihre Ziele in Chrome sauber gerendert werden (bei den meisten ist das so) und Sie eine ausgereifte, fokussierte Bibliothek mit einem tiefen Ökosystem und einer Komplexitätsachse weniger wollen. Die Firefox-Option über BiDi steht bereit, falls Sie sie später brauchen.
Nehmen Sie Playwright, wenn Sie WebKit abdecken müssen, Ihr Scraper in Python oder .NET geschrieben werden soll oder Sie lieber auf das Projekt mit der breiteren Engine- und Sprachabdeckung setzen. Gerade die Sprachpassung ist oft der klarste Grund, warum sich ein Python-Team für Playwright entscheidet.
Und eine dritte Antwort, die Vergleichsartikel gern auslassen: Nehmen Sie keines von beiden, wenn Ihre Seiten gar kein JavaScript brauchen, um ihre Daten zu zeigen. Wenn ein HTTP-Request plus Parser den Inhalt direkt liefert, ist ein Headless Browser teurer Overkill — das ist eine andere Werkzeugklasse, und dort einen echten Browser zu benutzen, verbrennt nur Speicher und Setup-Zeit.
Wo eine verwaltete API passt, inklusive Thunderbit
Thunderbit für Web-Datenextraktion testen
Playwright und Puppeteer sind beide kostenlose Open-Source-Bibliotheken, die Sie selbst betreiben und warten. Sie verantworten die Browser-Umgebung, Updates, den zusätzlich angebauten Crawl-Code und das Anti-Bot-Katz-und-Maus-Spiel. Für viele Projekte ist genau diese Verantwortung richtig, und nichts hier ist ein Gegenargument dagegen.
Aber schauen Sie sich an, wie viel der eigentlichen Scraping-Arbeit außerhalb dieser Tools liegt. Sie rendern eine Seite gut; sie queue-en keine URLs, rotieren nicht um Sperren herum, liefern keine strukturierten JSON-Daten und Sie müssen die Browser-Flotte am Laufen halten. Das ist eine andere Ebene im Stack als ein verwalteter Extraktionsdienst, und das sollte man Entwicklern, die zwischen Eigenbau und Kauf abwägen, offen benennen. Unser eigener Thunderbit-Developer-Stack sitzt genau auf dieser anderen Ebene: POST /distill wandelt eine Seite in sauberes, LLM-taugliches Markdown um und POST /extract gibt strukturiertes JSON auf Basis eines von Ihnen definierten Schemas zurück, inklusive JavaScript-Rendering, Anti-Bot-Handling und CAPTCHAs, die serverseitig statt auf Ihrem Laptop abgewickelt werden. Es gibt einen Thunderbit MCP-Server für KI-Agenten und Coding-Assistenten (dabei läuft thunderbit_suggest_fields kostenlos, bevor Sie überhaupt etwas ausgeben), sowie eine CLI über npx @thunderbit/thunderbit-cli für CI und Cron.
Ich behaupte nicht, dass das grundsätzlich besser ist — es ist ein anderer Kompromiss. Mit Playwright oder Puppeteer behalten Sie Rendering und alles, was Sie darum herum bauen, unter Ihrer Kontrolle, ohne Kosten pro Aufruf. Mit einer verwalteten API lagern Sie Rendering, Anti-Bot und die Crawling-Infrastruktur aus und zahlen pro Request (bei Thunderbit nach Verbrauch pro Aufruf — ein Credit für ein Distill, zwanzig für ein Extract — nicht pro Zeile). Klein, selbst gehostet, und Sie möchten den Browser selbst besitzen? Dann sind diese Bibliotheken die richtigen Werkzeuge. Skalierung, und Sie wollen lieber keine Headless-Flotte plus Crawler plus Block-Rotation betreiben? Dann nimmt Ihnen ein verwalteter Ansatz genau diese Arbeit ab.
Für den breiteren Markt hat unser Team außerdem Crawllees Zwei-Engine-Ansatz und eine Reihe HTTP-first-Frameworks gegen dieselben Fixtures getestet — ein sinnvoller nächster Schritt, wenn Sie entschieden haben, dass ein vollständiger Browser mehr ist, als Ihre Seiten tatsächlich brauchen.
Fazit
Sollten Sie Playwright oder Puppeteer verwenden? Für das Rendering von JavaScript-Seiten gilt: beides ist möglich — bei allen relevanten Tests hier gab es ein Unentschieden, also verlieren Sie keine Fähigkeiten, wenn Sie nach anderen Kriterien wählen. Entscheiden Sie sich für Puppeteer, wenn Chrome und Firefox aus Node heraus zu Ihrem Stack passen und Sie Reife sowie Fokus wollen. Entscheiden Sie sich für Playwright, wenn Sie WebKit brauchen oder Nicht-JavaScript-Clients bevorzugen.
Zwei Dinge, die Vergleichsartikel oft auslassen, sollten Sie mitnehmen. Erstens: Bei echten Scraping-Aufgaben sind diese beiden ein echtes Unentschieden, also machen Sie sich nicht über einen vermeintlichen Performance-Unterschied verrückt, der in acht verschiedenen Tests gar nicht aufgetaucht ist. Zweitens: Keines der beiden Tools ist ein Crawler — sie rendern, und das Crawling müssen Sie selbst übernehmen oder an einen Wrapper wie Crawlee abgeben. Wenn Sie diese beiden Punkte sauber trennen und den Umfang an Ihren Stack anpassen, wird die Wahl klein. Die Engine-Entscheidung ist weit weniger wichtig als der Teil der Arbeit, den Ihnen keines der beiden Tools abnimmt.
Mehr erfahren
Thunderbit für Web-Datenextraktion testen Get Started Free
FAQs
Ist Playwright oder Puppeteer schneller fürs Web Scraping? Auf identischen Fixtures waren beide praktisch gleichauf — gleiche Trefferquote bei statischen Seiten (12/12), dynamischen Seiten (8/8) und JSON-API-Extraktion, gleiches natives Rendering, gleiches 500-Handling. Das waren Einzelbeobachtungen auf einer Maschine, keine Benchmarks; Unterschiede pro Seite sind also kein belastbarer Geschwindigkeitstest. Entscheiden Sie nach Umfang und Sprache, nicht nach einem Geschwindigkeitsvorteil, der nicht aufgetaucht ist.
Was ist der eigentliche Unterschied zwischen Playwright und Puppeteer? Engine- und Sprachumfang. Playwright steuert Chromium, Firefox und WebKit über eine einzige API und bietet Clients für Python, Java und .NET. Puppeteer ist über CDP zuerst auf Chrome ausgelegt, mit dokumentierter Firefox-Unterstützung via WebDriver BiDi seit v23, aber ohne WebKit, und ist auf Node basiert. Beide rendern JavaScript nativ, und keines der beiden enthält eine eingebaute Crawl-Orchestrierung.
Kann ich mit Playwright oder Puppeteer eine ganze Website crawlen? Nicht direkt. Keines von beiden bringt eine Request-Queue, einen Dataset-Writer oder Auto-Throttling mit — mein Crawl-Graph-Test brauchte in beiden Fällen eine handgeschriebene BFS, zwölf Seiten bei Tiefen {0,1,2}. Für größere Mengen ergänzt man eine Crawling-Schicht wie Crawlee, die beide Engines mit echter Crawl-Infrastruktur umhüllt.
Brauche ich fürs Scraping überhaupt ein Browser-Tool? Nur dann, wenn die Seite JavaScript braucht, um ihre Daten sichtbar zu machen. Wenn ein HTTP-Request plus Parser den gewünschten Inhalt liefert, ist ein Headless Browser teurer Overkill — verwenden Sie dann lieber ein HTTP-first-Tool und sparen Sie sich den Browser-Overhead komplett.
Wofür sollte sich ein Python-Team entscheiden? Für Playwright, weil es einen erstklassigen Python-Client hat. Puppeteer ist Node-basiert, daher müssten Sie es aus Python über eine Brücke nutzen, die Sie selbst betreiben und warten müssten. Diese Sprachpassung ist einer der klarsten Gründe, Playwright gegenüber Puppeteer zu wählen.




