

Web Scraping fängt bei vielen Entwicklern ganz pragmatisch an: Man will Produktdaten von einer Konkurrenzseite ziehen und sucht nach einem Tool, das den Job erledigt. Ziemlich schnell landet man bei BeautifulSoup – nur fühlt sich der Anfang oft holprig an. Doch sobald pip install beautifulsoup4 durchläuft und man das erste HTML-Element herauszieht, etwa eine Überschrift, fällt bei den meisten der Groschen. Dieser eine Moment, in dem es plötzlich funktioniert, reicht vielen Python-Einsteigern als Motivation, um beim Scraping dranzubleiben.
Wenn du frisch im Web Scraping bist, wird dir BeautifulSoup mit hoher Wahrscheinlichkeit als Erstes ans Herz gelegt. Logisch: Die Bibliothek ist schlank, leistungsstark und seit über zehn Jahren gesetzt, wenn es um Web Scraping mit Python geht. Ich zeige dir in diesem Leitfaden, wie du BeautifulSoup per pip installierst, wie deine ersten Code-Zeilen aussehen und weshalb Entwickler und Datenanalysten so darauf schwören. Genauso ehrlich rede ich aber über die Schwächen – und darüber, warum immer mehr Teams (gerade ohne Coding-Hintergrund) zu KI-Tools wie Thunderbit wechseln.
Aber was ist BeautifulSoup eigentlich, und warum hält sich die Bibliothek so hartnäckig an der Spitze?
BeautifulSoup vs. KI-Web-Scraper: Der große Vergleich Get Started Free
Im Kern ist BeautifulSoup ein besonders gutmütiger „HTML-Parser“ für Python. Du fütterst die Bibliothek mit HTML- oder XML-Text und bekommst eine aufgeräumte Baumstruktur zurück, die du mit Python durchsuchen, durchklicken und auswerten kannst. Stell es dir wie eine Lupe vor, die das Gewirr aus verschachtelten Tags und Attributen sortiert und greifbar macht.
Was macht BeautifulSoup nach all den Jahren immer noch so beliebt?
Auch wenn es längst neuere Scraping-Frameworks gibt, bleibt BeautifulSoup für die meisten Python-Anfänger die erste Anlaufstelle. Die Zahlen sprechen für sich: Pro Monat wird die Bibliothek über 150 Millionen Mal von PyPI heruntergeladen. Und auf Stack Overflow finden sich mehr als 32.000 Fragen mit dem Tag „beautifulsoup“ – ein klares Zeichen für eine riesige Community, in der Einsteiger schnell Hilfe finden.
Typische Einsatzgebiete:
- Produktdaten extrahieren von E-Commerce-Seiten (z. B. Name, Preis, Bewertung)
- Nachrichtenüberschriften oder Blog-Inhalte für Analysen oder Aggregation sammeln
- Tabellen oder Verzeichnisse für strukturierte Daten auslesen (z. B. Firmenlisten)
- Lead-Generierung durch das Sammeln von E-Mails oder Telefonnummern aus Verzeichnissen
- Änderungen überwachen (z. B. Preisänderungen oder neue Stellenanzeigen)
Seine Stärke spielt BeautifulSoup vor allem bei statischen Webseiten aus – also dort, wo die gewünschten Daten direkt im HTML stehen. Die Bibliothek ist flexibel, kommt auch mit fehlerhaftem Code zurecht und schreibt dir kein starres Framework vor. Genau deshalb ist BeautifulSoup auch 2025 für viele Python-Nutzer noch das „erste richtige Tool“ (mehr zur Beliebtheit).
Pip install beautifulsoup: So gelingt der Einstieg am einfachsten
Was ist pip und warum sollte man es nutzen?
Falls du mit Python noch nicht so vertraut bist: pip ist der Paketmanager, mit dem du Bibliotheken aus dem Python Package Index (PyPI) installierst. Im Prinzip wie ein App Store – nur für Python-Code. Mit pip BeautifulSoup zu installieren, ist der schnellste und zuverlässigste Weg.
Profi-Tipp: Das richtige Paket heißt beautifulsoup4 (nicht nur beautifulsoup). Das „4“ steht für die aktuelle Version.
Schritt-für-Schritt: BeautifulSoup installieren
1. Python-Version prüfen
BeautifulSoup benötigt Python 3.7 oder neuer. Prüfe deine Version im Terminal:
python --version
oder
python3 --version
2. BeautifulSoup4 mit pip installieren
Öffne dein Terminal oder die Eingabeaufforderung und gib ein:
pip install beautifulsoup4
Falls du mehrere Python-Versionen hast, nutze ggf.:
pip3 install beautifulsoup4
Unter Windows geht auch:
py -m pip install beautifulsoup4
3. (Optional, aber empfohlen) Parser installieren
BeautifulSoup funktioniert direkt mit dem eingebauten "html.parser" von Python, aber für mehr Geschwindigkeit und Genauigkeit empfiehlt sich die Installation von lxml und html5lib:
pip install lxml html5lib
4. (Optional) Requests installieren
BeautifulSoup lädt keine Webseiten herunter – es analysiert nur HTML. Die meisten nutzen die Requests-Bibliothek, um Seiten zu laden:
pip install requests
5. Installation testen
Probiere es in Python aus:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Wenn du <title>Example Domain</title> siehst, ist alles bereit.
BeautifulSoup in einer virtuellen Umgebung installieren
Ich empfehle grundsätzlich, für Python-Projekte eine virtuelle Umgebung zu nutzen. So bleiben deine Abhängigkeiten sauber und du vermeidest Konflikte.
So richtest du eine virtuelle Umgebung ein:
python -m venv venv
# Unter Windows:
venv\Scripts\activate
# Unter macOS/Linux:
source venv/bin/activate
pip install beautifulsoup4 requests lxml html5lib
Alles, was du installierst, bleibt jetzt in diesem Projektordner. Keine „Warum fehlt mein Paket?“-Probleme mehr.
Alternative Installationsmethoden (Conda, etc.)
Falls du Anaconda nutzt, kannst du BeautifulSoup so installieren:
conda install beautifulsoup4
Und für den Parser:
conda install lxml
Achte darauf, dass deine conda-Umgebung vorher aktiviert ist.
BeautifulSoup Python: Erste Schritte mit Code-Beispielen
Jetzt wird’s praktisch. So nutzt du BeautifulSoup in einem echten Python-Skript.
Beispiel 1: Webseite laden und Titel extrahieren
from bs4 import BeautifulSoup
import requests
url = "https://en.wikipedia.org/wiki/Python_(programming_language)"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Seitentitel auslesen
title_text = soup.title.string
print("Seitentitel:", title_text)
Dieses Skript lädt die Wikipedia-Seite zu Python, analysiert das HTML und gibt den Seitentitel aus. Ganz einfach!
Beispiel 2: Alle Links extrahieren
links = soup.find_all('a')
for link in links[:10]: # Zeige die ersten 10 Links
href = link.get('href')
text = link.get_text()
print(f"{text}: {href}")
Damit erhältst du Text und URL der ersten 10 Links auf der Seite.
Beispiel 3: Überschriften auslesen
headings = soup.find_all('h2')
for h in headings:
print(h.get_text().strip())
So bekommst du alle <h2>-Überschriften.
Beispiel 4: CSS-Selektoren verwenden
items = soup.select("ul.menu > li")
for item in items:
print(item.get_text())
Mit select() kannst du CSS-Selektoren wie gewohnt nutzen.
Beispiel 5: Attribute und verschachtelte Tags auslesen
first_link = soup.find('a')
print(first_link['href']) # Direkter Zugriff (Fehler, falls nicht vorhanden)
print(first_link.get('href')) # Sicherer Zugriff (gibt None zurück, falls nicht vorhanden)
Beispiel 6: Gesamten Text extrahieren
text_content = soup.get_text()
print(text_content)
Damit holst du dir den gesamten Text der Seite – praktisch für schnelle Analysen.
Häufige BeautifulSoup-Aufgaben für Einsteiger
Hier die gängigsten Aufgaben mit BeautifulSoup:
-
Einzelnes Element finden:
soup.find('div', class_='price') -
Alle Elemente finden:
soup.find_all('p', class_='description') -
Textinhalt auslesen:
element.get_text() -
Attributwert auslesen:
element.get('href') -
CSS-Selektoren nutzen:
soup.select('table.data > tr') -
Fehlende Elemente abfangen:
price = soup.find('span', class_='price') if price: print(price.get_text())
Die Syntax ist gut lesbar, einsteigerfreundlich und verzeiht auch fehlerhaftes HTML (siehe Dokumentation).
Die Grenzen von BeautifulSoup beim modernen Web Scraping
So weit, so gut – jetzt zu den Schattenseiten. Für statische Seiten und kleine Projekte ist BeautifulSoup hervorragend, aber eben nicht für jeden Fall die richtige Wahl.
Das sind die größten Stolpersteine:
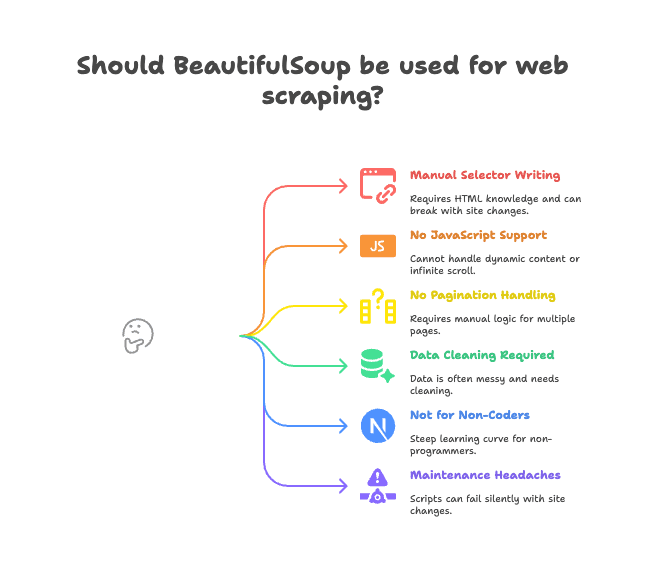
- Selektoren von Hand schreiben: Du musst das HTML selbst durchgehen und die passenden Tags bzw. Klassen angeben. Sobald sich die Seite ändert, läuft dein Skript ins Leere.
- Keine JavaScript-Unterstützung: BeautifulSoup sieht nur das HTML, das der Server ausliefert. Wird der Inhalt erst per JavaScript nachgeladen (z. B. bei Infinite Scroll), schaust du in die Röhre (mehr dazu).
- Keine eingebaute Paginierung oder Unterseiten-Logik: Möchtest du mehrere Seiten oder Detailseiten scrapen, musst du alles selbst programmieren.
- Datenbereinigung nötig: Die extrahierten Daten sind oft unaufgeräumt – mit Leerzeichen, Sonderzeichen oder uneinheitlichen Formaten.
- Nicht für Nicht-Programmierer: Wer nicht coden kann, hat mit BeautifulSoup einen steilen Lernweg.
- Wartungsaufwand: Ändert sich das Webseiten-Layout, kann dein Skript stillschweigend fehlschlagen oder Daten übersehen.
Für Teams läppern sich diese vermeintlichen „Kleinigkeiten“ schnell zu echten Produktivitätsbremsen zusammen. Ich habe genug Projekte ins Stocken geraten sehen, nur weil das Scraping-Skript ständig nachjustiert werden musste.
Warum immer mehr Teams für Webdaten-Extraktion auf Thunderbit setzen
Thunderbit KI-Web-Scraper ausprobieren Mit KI jede Website scrapen. Ganz ohne Code. Get Started Free
Und die Alternative? An dieser Stelle kommt Thunderbit ins Spiel. Thunderbit ist keine weitere Python-Bibliothek, sondern eine Chrome-Erweiterung, die als KI-gestützter Assistent für Webdaten arbeitet.
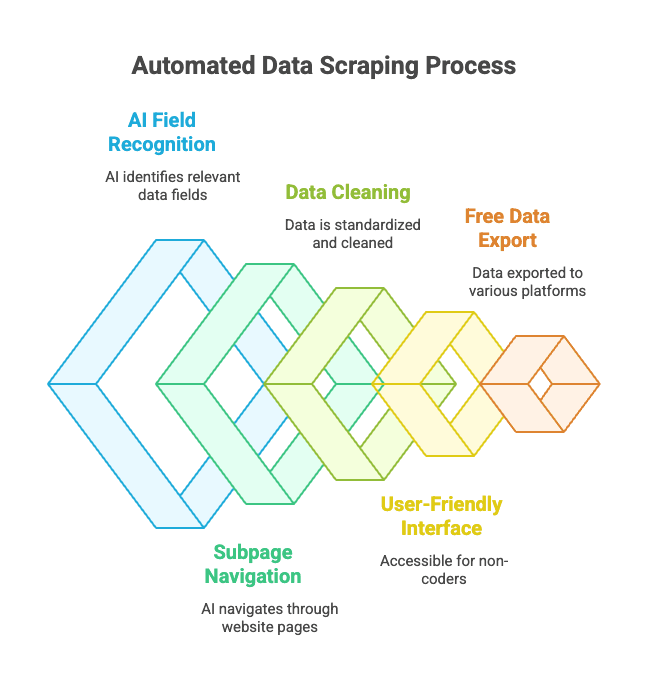
Wie läuft das ab?
- Du öffnest die gewünschte Website.
- Klick auf „KI-Felder vorschlagen“ – Thunderbits KI erkennt automatisch die passenden Spalten (z. B. „Produktname“, „Preis“, „Ort“).
- Du kannst die Spaltennamen und Typen anpassen.
- Klick auf „Scrapen“ – Thunderbit sammelt, bereinigt und strukturiert die Daten für dich.
- Exportiere die Daten mit einem Klick nach Excel, Google Sheets, Notion, Airtable oder in dein Lieblingstool.
Kein Code. Keine Selektoren. Keine Wartungsprobleme.
Die Highlights von Thunderbit:
- KI-gestützte Felderkennung: Die KI erkennt die gewünschten Daten, selbst bei unübersichtlichem HTML.
- Unterseiten- und Paginierungs-Scraping: Thunderbit kann automatisch auf Produktseiten klicken oder „Nächste Seite“-Links folgen.
- Automatische Datenbereinigung: Telefonnummern, E-Mails, Bilder und mehr werden standardisiert.
- Auch für Nicht-Programmierer: Wer einen Browser bedienen kann, kann auch Thunderbit nutzen.
- Kostenloser Datenexport: Exportiere zu Excel, Google Sheets, Airtable, Notion – ohne Bezahlschranke für Basisfunktionen.
- Geplantes Scraping: Lege Zeitpläne fest – Thunderbit sammelt die Daten automatisch.
Gerade für Business-Anwender macht das einen spürbaren Unterschied: Statt Python-Skripte zu tippen, klickst du dich einfach zu deinen Daten.
Thunderbit KI-Web-Scraper kostenlos testen
Thunderbit vs. BeautifulSoup: Was passt zu dir?
Hier der direkte Vergleich:
| Funktion | BeautifulSoup (Python-Code) | Thunderbit (No-Code KI) |
|---|---|---|
| Einrichtung | Python, pip, Code nötig | Chrome-Erweiterung, 2 Klicks |
| Zeit bis zu den Daten | Stunden für das erste Skript | Minuten pro Website |
| JavaScript-Unterstützung | Nein (zusätzliche Tools nötig) | Ja (läuft im Browser) |
| Paginierung/Unterseiten | Manuell programmieren | Integriert, per Schalter |
| Datenbereinigung | Manuell im Code | KI-gestützt, automatisch |
| Exportmöglichkeiten | Eigenes CSV/Excel-Skript | Ein Klick zu Sheets, Notion etc. |
| Ideal für | Entwickler, Bastler | Business-Anwender, Nicht-Coder |
| Kosten | Kostenlos (aber zeitintensiv) | Freemium (kleine Jobs gratis) |
Wann BeautifulSoup sinnvoll ist:
- Du bist mit Python vertraut und willst volle Kontrolle.
- Du scrapest statische Seiten oder brauchst individuelle Logik.
- Du integrierst Scraping in einen größeren Python-Workflow.
Wann Thunderbit die bessere Wahl ist:
- Du willst schnelle Ergebnisse ohne Code.
- Du musst dynamische (JavaScript-)Seiten scrapen.
- Du bist im Vertrieb, Marketing, Operations oder willst dich nicht mit Code beschäftigen.
- Du möchtest Daten direkt in deine Business-Tools exportieren.
Selbst als Entwickler greife ich ab und zu zu Thunderbit, wenn ich einfach nur schnell Daten brauche und mir das Aufsetzen eines ganzen Python-Projekts sparen will. Eine Art Turbo-Knopf direkt im Browser.
Best Practices für die Installation und Nutzung von BeautifulSoup
Wenn du bei BeautifulSoup bleibst, hier meine wichtigsten Tipps für einen reibungslosen Ablauf:
- Immer eine virtuelle Umgebung nutzen: Hält deine Abhängigkeiten sauber und verhindert „bei mir geht’s, bei dir nicht“-Probleme.
- pip und Pakete aktuell halten: Regelmäßig
pip install --upgrade pipundpip list --outdatedausführen. - Empfohlene Parser installieren:
pip install lxml html5libfür bessere Performance und Stabilität. - Modularen Code schreiben: Trenne das Laden und Parsen für einfacheres Debugging.
- robots.txt und Rate-Limits beachten: Webseiten nicht überlasten – mit
time.sleep()Pausen einbauen. - Aussagekräftige, aber stabile Selektoren wählen: Vermeide zu spezifische Pfade, die schnell brechen.
- Parsing an gespeicherten HTML-Dateien testen: Lade eine Seite herunter und teste offline, um unnötige Anfragen zu vermeiden.
- Die Community nutzen: Stack Overflow hilft bei fast jedem Problem.
Fehlerbehebung bei der Installation von BeautifulSoup
Hakt es irgendwo? Hier eine schnelle Checkliste:
- „ModuleNotFoundError: No module named bs4“
- Hast du
beautifulsoup4in der richtigen Umgebung installiert? Probierepython -m pip install beautifulsoup4.
- Hast du
- Falsches Paket installiert (
beautifulsoupstattbeautifulsoup4)- Altes Paket deinstallieren:
pip uninstall beautifulsoup - Richtiges installieren:
pip install beautifulsoup4
- Altes Paket deinstallieren:
- Parser-Warnungen oder Unicode-Fehler
- Installiere
lxmlundhtml5libund gib den Parser an:BeautifulSoup(html, "lxml")
- Installiere
- Elemente werden nicht gefunden
- Wird der Inhalt per JavaScript geladen? BeautifulSoup sieht nur das Quell-HTML, nicht das gerenderte DOM.
- pip-Fehler oder Berechtigungsprobleme
- Nutze eine virtuelle Umgebung oder versuche
pip install --user beautifulsoup4 - pip aktualisieren:
pip install --upgrade pip
- Nutze eine virtuelle Umgebung oder versuche
- Conda-Probleme
- Probiere
conda install beautifulsoup4oder nutze pip innerhalb deiner conda-Umgebung.
- Probiere
Immer noch Probleme? Die BeautifulSoup-Dokumentation und Stack Overflow decken fast alle Fälle ab.
Fazit: Das Wichtigste zur Installation und Nutzung von BeautifulSoup
-
BeautifulSoup ist die beliebteste Python-Bibliothek fürs Web Scraping – einfach, flexibel und ideal für Einsteiger.
-
Installation mit pip:
pip install beautifulsoup4 lxml html5lib requests -
Virtuelle Umgebung nutzen für eine saubere Installation.
-
BeautifulSoup ist ideal für statische Seiten und kleine Projekte, stößt aber bei JavaScript, Paginierung und Wartung an Grenzen.
-
Thunderbit ist die moderne, KI-gestützte Alternative für Business-Anwender und Nicht-Programmierer – kein Code, kein Aufwand, einfach Daten.
-
Wähle das passende Tool für deinen Bedarf:
- Entwickler und Bastler: BeautifulSoup gibt dir volle Kontrolle.
- Business-Teams: Thunderbit liefert schnelle Ergebnisse.
Probier ruhig beide Ansätze aus – manchmal ist die beste Lösung schlicht die, die dich am schnellsten ans Ziel bringt.
Thunderbit KI-Web-Scraper kostenlos testen Get Started Free
FAQ: Pip install BeautifulSoup und mehr
Frage: Was ist der Unterschied zwischen beautifulsoup und beautifulsoup4?
Antwort: Installiere immer beautifulsoup4 – das ist die aktuelle, unterstützte Version. Das alte Paket beautifulsoup ist veraltet und nicht mit Python 3 kompatibel. Importiert wird trotzdem mit from bs4 import BeautifulSoup (Details hier).
Frage: Muss ich lxml oder html5lib mit BeautifulSoup installieren?
Antwort: Nicht zwingend, aber sehr empfehlenswert. Sie machen das Parsen schneller und robuster. Installiere sie mit pip install lxml html5lib (warum das wichtig ist).
Frage: Kann BeautifulSoup JavaScript-lastige Webseiten scrapen?
Antwort: Nein – BeautifulSoup sieht nur das statische HTML. Für JavaScript-Inhalte nutze Browser-Automatisierung wie Selenium oder ein KI-gestütztes Tool wie Thunderbit (mehr dazu).
Frage: Wie deinstalliere ich BeautifulSoup?
Antwort: Führe im Terminal pip uninstall beautifulsoup4 aus (Schritt-für-Schritt-Anleitung).
Frage: Ist Thunderbit kostenlos nutzbar?
Antwort: Thunderbit setzt auf ein Freemium-Modell – kleine Jobs sind gratis, für größere Datenmengen oder Zusatzfunktionen gibt es kostenpflichtige Pläne. Direkt im Browser kannst du es kostenlos testen (Preise hier).
Wenn du wissen willst, wie Thunderbit und BeautifulSoup im direkten Vergleich abschneiden, schau dir unseren ausführlichen Vergleich an. Und wenn du tiefer ins Web Scraping einsteigen möchtest, findest du bei uns auch Anleitungen zu Was ist Data Scraping? und Wie man Amazon-Produkte und -Bewertungen scraped.
Viel Erfolg beim Scrapen – ob als Python-Profi oder einfach jemand, der seine Daten schnell in einer Tabelle braucht: Für jeden gibt es das passende Tool (und eine Community, die mit anpackt).




