
Apollo-Listenabfragen zu optimieren ist nicht einfach nur ein bisschen Feintuning – es ist eine echte 생존 스킬 für alle, die auf Echtzeit-Newsdaten, automatisierte News-Extraktion oder ultraschnelle Sales- und Ops-Workflows angewiesen sind. Ich hab’s selbst erlebt: Eine zähe Listenabfrage macht aus einem eigentlich starken Dashboard plötzlich ein Nadelöhr. Sales-Teams hängen in endlosen Ladeanimationen fest, und Ops basteln hektisch Notlösungen in Excel zusammen. In einer Welt, in der , zählt am Ende wirklich jede Millisekunde.

Wie bekommst du Apollo Client Listenabfragen also so schnell, stabil und skalierbar, dass sie beim News-Scraping, Lead-Tracking oder in geschäftskritischen Dashboards zuverlässig performen? In diesem Guide teile ich Best Practices, die ich mir über die Zeit angeeignet habe (ein paar davon leider auf die harte Tour) – von Query-Design über Caching und Pagination bis hin zur Integration von No-Code-Tools wie , um die Fleißarbeit der News-Extraktion zu automatisieren. Egal ob du Developer bist, Product Manager oder die Person, die am Ende immer schuld ist, wenn das Dashboard langsam ist: Das hier ist dein Playbook für Apollo GraphQL Listen-Performance.
Warum Apollo-Listenabfragen optimieren? (apollo client list performance, optimize apollo list queries)
Seien wir ehrlich: Niemand hat Bock, darauf zu warten, bis News-Headlines oder Sales-Leads endlich laden. In Business-Umgebungen – vor allem dort, wo oder Echtzeitdaten eine Rolle spielen – sind langsame Apollo-Listenabfragen nicht nur nervig. Sie kosten Geld, verzögern Entscheidungen und pushen Teams zurück in manuelle Prozesse. Der zeigt, dass Büroangestellte rund ein Drittel ihres Tages mit Aufgaben geringer Wertschöpfung verbringen – oft, weil Tools zu langsam sind oder nicht sauber zusammenspielen.
Das passiert, wenn Listenabfragen nicht optimiert sind:
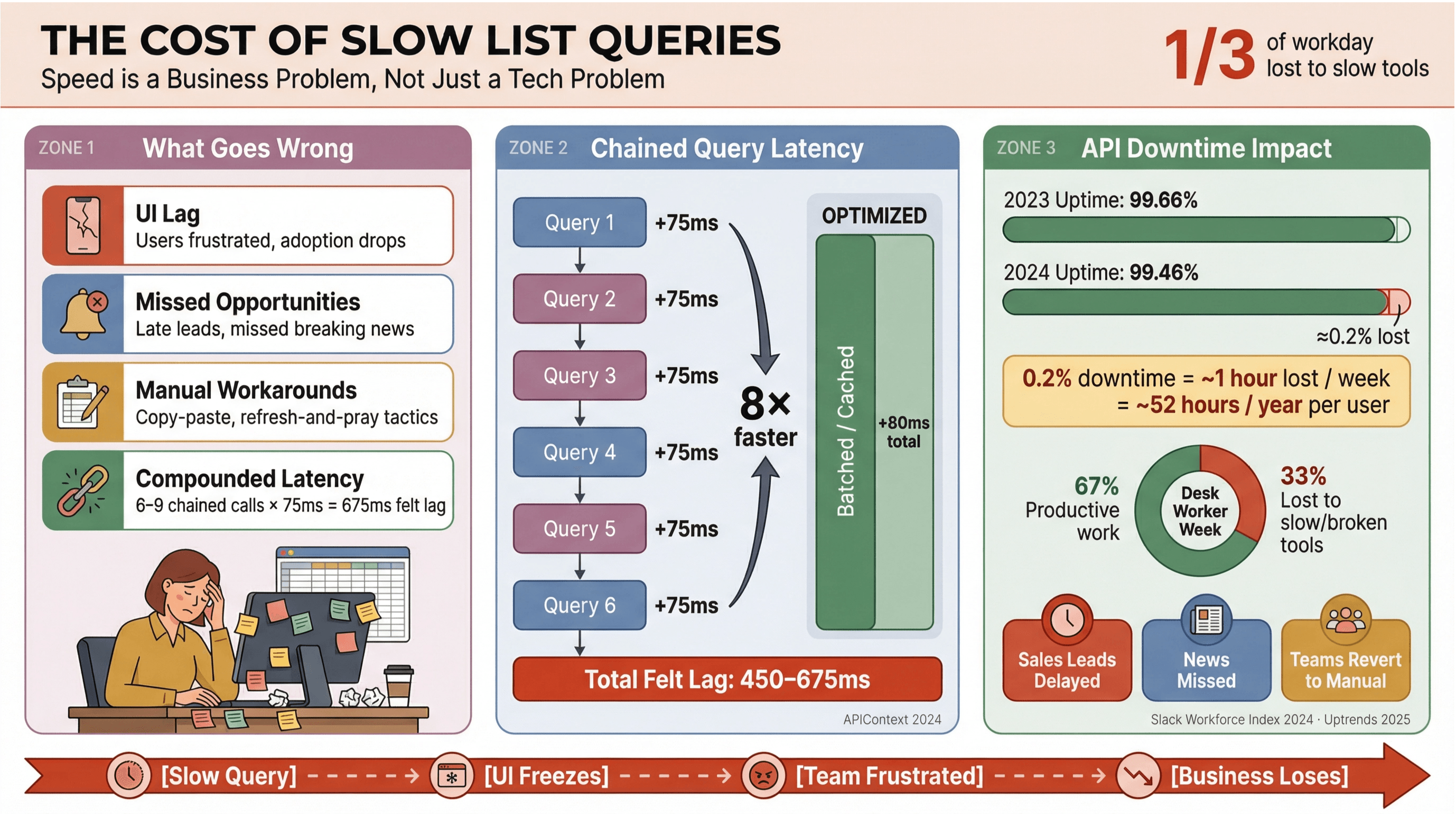
- UI-Lag: Spürbare Verzögerungen frustrieren Nutzer und senken die Akzeptanz.
- Verpasste Chancen: In Sales oder beim News-Monitoring können schon wenige Sekunden bedeuten, dass ein heißer Lead oder eine Breaking News durchrutscht.
- Manuelle Workarounds: Teams fallen zurück auf Copy-Paste, Tabellen oder „Refresh und hoffen“.
- Kumulierte Latenz: Jeder langsame API-Call summiert sich – wenn dein Workflow 6–9 voneinander abhängige Queries auslöst, werden aus 75 ms Verzögerung pro Call schnell 450–675 ms gefühlte Verzögerung ().
Und es geht nicht nur um Speed. : Die durchschnittliche Verfügbarkeit sank innerhalb eines Jahres von 99,66% auf 99,46% – das entspricht bei listenlastigen Apps fast einer Stunde Produktivitätsverlust pro Woche. Wenn dein Business auf Echtzeit-Newsdaten basiert, ist das ein Risiko, das du dir schlicht nicht leisten kannst.
Die richtige Datenstruktur und Feldauswahl (apollo graphql list best practices)
Einer der häufigsten Fehler, den ich immer wieder sehe (und ja, den ich selbst auch gemacht habe): Jede Listenabfrage wird behandelt wie eine Detailabfrage. Dabei kannst du in GraphQL exakt das abfragen, was du brauchst – also nutz das auch. Overfetching ist ein Performance-Killer, besonders bei News-Scraping-Tools und Echtzeit-Dashboards.
Felder gezielt für automatisierte News-Extraktion auswählen
Angenommen, du baust einen News-Feed. Brauchst du in der Listenabfrage wirklich den kompletten Artikeltext, alle Tags, Kommentare und Autor-Bios? In den meisten Fällen: nope. Der Unterschied sieht so aus:
Effiziente Listenabfrage:
1query NewsFeed($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 cursor
5 node {
6 id
7 title
8 url
9 sourceName
10 publishedAt
11 }
12 }
13 pageInfo { endCursor hasNextPage }
14 }
15}Ineffiziente Listenabfrage (bitte nicht so):
1query NewsFeedTooHeavy($after: String, $first: Int) {
2 newsFeed(after: $after, first: $first) {
3 edges {
4 node {
5 id title url publishedAt
6 fullText
7 summary
8 entities { ... }
9 relatedArticles { ... }
10 }
11 }
12 }
13}Die erste Query ist schlank und schnell – perfekt zum Sortieren, Filtern und Rendern von Zeilen. Die zweite ist im Grunde eine Detailabfrage im Tarnanzug: riesige Payloads, unnötige Daten, langsame UI (, ).
Pro-Tipp: Arbeite zweistufig: In der Liste nur leichte Felder laden, schwere Details (z. B. Volltext oder NLP-Anreicherung) erst nachladen, wenn der Nutzer ein Item öffnet oder darüber hovert.
Apollo Client Cache für schnellere Abfragen nutzen (apollo client list performance)
Der Cache von Apollo Client ist deine Geheimwaffe für snappy Listen. Richtig konfiguriert ermöglicht er dir:
- Wiederholte Abfragen sofort auszuliefern (ohne Netzwerk-Roundtrip)
- Serverlast und API-Kosten zu senken
- Flüssige Navigation (zurück/vor) und Filterwechsel
Caching ist aber kein Selbstläufer – da braucht’s ein bisschen Setup und konsequente Umsetzung.
Sinnvolle Cache-Policies festlegen
Apollo unterstützt mehrere :
| Policy | Was sie macht | Bestes Einsatzszenario für News-Listen |
|---|---|---|
| cache-first | Liest aus dem Cache, holt aus dem Netzwerk wenn nötig | Listen erneut öffnen, Filter wechseln, zurück/vor navigieren |
| network-only | Holt immer aus dem Netzwerk | Manuelles Refresh, „neueste Headlines“ |
| cache-and-network | Liefert Cache sofort, aktualisiert dann per Netzwerk | Schneller First Paint + Update im Hintergrund (top für Feeds) |
| no-cache | Holt immer, speichert aber nie im Cache | Einmalige sensible Abfragen (selten bei Listen) |
Für Echtzeit-Newsdaten mag ich cache-and-network: Nutzer sehen sofort Ergebnisse und bekommen danach ein Update im Hintergrund. Achte nur auf UI-Flackern, wenn sich die Reihenfolge beim Refresh ändert ().
Tipps zur Cache-Konfiguration:
- Nutze stabile IDs (
idoder_id) für Normalisierung (). - Cache-Größe und Garbage Collection für große Listen passend einstellen ().
- Vermeide riesige, nicht normalisierte Blobs unter
ROOT_QUERY– das kann deine App ausbremsen ().
Pagination umsetzen und Item-Anzahl begrenzen (apollo graphql list best practices)
Wenn du Hunderte oder Tausende News-Artikel oder Sales-Leads auf einmal lädst, ist Ärger vorprogrammiert. Pagination ist nicht nur UX – sie ist Pflicht, wenn du Performance ernst meinst.
Apollo unterstützt sowohl als auch . So unterscheiden sie sich:
| Pagination-Typ | Vorteile | Nachteile | Am besten für |
|---|---|---|---|
| Offset-basiert | Einfach, schnell umzusetzen | Kann Items überspringen/duplizieren | Unveränderliche/kleine Listen |
| Cursor-basiert | Stabil, robust bei Datenänderungen | Etwas komplexer | News-Feeds, große Listen |
Für die meisten Echtzeit-News- oder Lead-Listen ist Cursor-Pagination die beste Wahl. Sie hält die Ergebnisse konsistent, auch wenn neue Items dazukommen oder alte verschwinden ().
Apollo-Pagination-Tipps:
keyArgskonfigurieren, um Cache-Keys für paginierte Felder zu steuern ().- Eine
merge-Funktion implementieren, um Seiten im Cache zusammenzuführen. fetchMorenutzen, um weitere Seiten zu laden, ohne vorherige Ergebnisse zu überschreiben.
Praktische Pagination-Muster für News-Scraping-Tools
Eine typische News-Scraping-UI:
- zeigt die neuesten 20–50 Headlines (nur schlanke Felder)
- lädt bei Scroll oder „Nächste Seite“ nach
- holt Details nur bei Bedarf
So bleibt die UI schnell, die API entspannt und die Nutzer produktiv.
Thunderbit für automatisierte News-Extraktion integrieren
Kommen wir zum Elefanten im Raum: Woher kommen diese strukturierten Newsdaten überhaupt? Genau hier spielt seine Stärken aus.
Thunderbit ist eine No-Code KI-Web-Scraper Chrome Extension, mit der du aus praktisch jeder Website News-Headlines, URLs, Quellen, Autoren, Veröffentlichungsdaten, Zusammenfassungen und Bilder extrahieren kannst – ganz ohne Programmierung. Ich habe Teams gesehen, die damit die komplette News-Extraktion automatisiert haben: aus unstrukturierten Webseiten werden saubere, strukturierte Datensätze, die direkt in eine Datenbank oder eine GraphQL-API fließen.
Thunderbit mit Apollo für Echtzeit-Newsdaten kombinieren
Ein Workflow, den ich besonders für Sales- und Ops-Teams mag, die aktuelle News brauchen:
- Extraktionsschicht: Mit Thunderbits strukturierte Newsdaten zeitgesteuert von Zielseiten ziehen.
- Speicherschicht: Die extrahierten Daten in einer Datenbank ablegen, die auf schnelle Abfragen optimiert ist.
- GraphQL-Schicht: Über die API ein
newsFeed-Listenfeld und einnewsArticle(id)-Detailfeld bereitstellen. - Client-Schicht: Mit Apollo Client die Liste (schlank, paginiert) laden und Details nur bei Bedarf nachziehen.
Diese „scrape → store → query“-Pipeline sorgt dafür, dass deine Apollo-Queries immer mit frischen, strukturierten Daten arbeiten – ohne Copy-Paste und ohne fragile Skripte.
Bonus: Thunderbit kann deine Listen außerdem um zusätzliche Felder (z. B. Sentiment oder Kategorie) erweitern – dank KI-gestützter Feldvorschläge wird dein News-Feed noch smarter.
Schritt-für-Schritt: Apollo-Listenabfragen optimieren
Bereit, das umzusetzen? Hier ist meine Checkliste für die Optimierung von Apollo-Listenabfragen:
-
Queries verschlanken
- Nur Felder anfordern, die fürs Listen-Rendering nötig sind (Titel, URL, Zeitstempel usw.).
- Schwere Felder (Volltext, Bilder, Enrichment) in Detail-Queries auslagern.
-
Pagination implementieren
- Für große oder dynamische Listen Cursor-Pagination verwenden.
keyArgsundmergekorrekt konfigurieren, damit der Cache stimmt.
-
Apollo Cache ausnutzen
- Entitäten mit stabilen IDs normalisieren.
- Passende Fetch Policy wählen (
cache-and-networkist super für News). - Cache-Größe und Garbage Collection an dein Datenvolumen anpassen.
-
Automatisierte Extraktion integrieren
- News-Scraping mit Thunderbit automatisieren, damit die Daten aktuell bleiben.
- Strukturierte Daten direkt in Datenbank oder Spreadsheet exportieren.
-
Monitoring & Troubleshooting
- Mit den Queries, Cache und Performance prüfen.
- Auf große Cache-Writes, zu viele „watched queries“ und UI-Ruckler achten.
- p95/p99-Latenz und Fehlerraten tracken (, ).
Query-Performance überwachen und Probleme finden
Die Devtools von Apollo sind hier wirklich Gold wert. Damit kannst du:
- aktive Queries und Cache-Status inspizieren
- doppelte Queries oder zu viele Watcher erkennen
- große Cache-Blobs oder Normalisierungsprobleme identifizieren
Wenn du UI-Lag oder langsame Updates siehst, check zuerst:
- zu große Listenabfragen (verschlanken)
- schlechte Cache-Normalisierung (IDs korrigieren)
- Pagination-Merge-Probleme (deine
keyArgsundmergeauditieren)
Und miss unbedingt Tail-Latenz – nicht nur Durchschnittswerte. Genau dort versteckt sich der echte Nutzerfrust.
Traditionelle vs. KI-gestützte News-Scraping-Ansätze im Vergleich
Hand aufs Herz: Früher bedeutete News-Scraping oft eigene Skripte, Headless-Browser-Chaos und die stille Hoffnung, dass sich das Layout nicht über Nacht ändert. Mit KI-Tools wie Thunderbit lässt sich der Prozess heute weitgehend automatisieren – ohne Code und ohne Drama.
| Ansatz | Stärken | Einschränkungen für Business-User |
|---|---|---|
| Skriptbasiertes Scraping | Voll flexibel, günstig bei großem Scale | Hoher Wartungsaufwand, braucht Engineering-Zeit |
| Managed Scraping-Plattformen | Schnell startklar, Anti-Bot wird ausgelagert | Braucht trotzdem Setup, Kosten steigen mit Nutzung |
| KI-gestützte Extraktion (Thunderbit) | Kommt mit chaotischen Layouts klar, kein Code | Output braucht QA, Mapping aufs Schema nötig |
| No-Code Visual Scraper | Für Nicht-Engineers zugänglich | Bricht bei UI-Änderungen, begrenzte Skalierung |
| Proxy/Unlocker-Infrastruktur | Umgeht Blocks, hoher Durchsatz möglich | Extraktionslogik bleibt nötig, Compliance-Risiken |
Rechtlicher Hinweis: Das Scrapen öffentlich zugänglicher Daten ist in der Regel legal – respektiere aber immer Nutzungsbedingungen und Rate Limits ().
Wichtigste Learnings: Apollo GraphQL Listen Best Practices
Die wichtigsten Punkte zusammengefasst:
- Auf Tempo und Klarheit optimieren: Listen-Queries schlank halten, paginieren und konsequent cachen.
- Struktur ist entscheidend: Nur das abfragen, was du wirklich brauchst – schwere Felder in Detail-Queries.
- Cache ist dein Verbündeter: Normalisierung und Fetch Policies nutzen, um Daten sofort auszuliefern.
- Extraktion automatisieren: Tools wie machen News-Scraping und Listen-Enrichment für alle zugänglich.
- Messen und iterieren: Mit Devtools und Observability-Dashboards Engpässe früh erkennen.
Für Sales-, Ops- und News-Teams heißt das: weniger Warten, schneller Handeln – und deutlich weniger „Warum ist das so langsam?“-Slack-Nachrichten.
Fazit: Nächste Schritte zur Optimierung deiner Apollo-Listenabfragen
Wenn du noch schwere, unpaginierte oder cache-unfreundliche Listenabfragen im Einsatz hast, ist jetzt der richtige Zeitpunkt für ein Audit und ein Upgrade. Fang klein an: Felder reduzieren, Pagination ergänzen, Cache tunen. Danach kannst du mit automatisierten Extraktions-Tools wie den nächsten Schritt gehen – damit deine Daten aktuell bleiben und wirklich nutzbar sind.
Du willst tiefer einsteigen? Schau in die , in den oder in die für Praxistipps und Troubleshooting. Und wenn du deine News-Extraktion automatisieren willst, probier Thunderbits aus – ein echter Game-Changer für alle, die Echtzeitdaten ohne Kopfschmerzen brauchen.
Viel Spaß beim Querying – und mögen deine Listen immer laden, bevor der Kaffee kalt wird.
FAQs
1. Warum werden Apollo-Listenabfragen in Echtzeit-News- oder Sales-Dashboards langsam?
Listenabfragen werden oft langsam, wenn sie zu viele Daten laden, keine Pagination nutzen oder nicht sauber gecacht sind. In hochfrequenten Workflows wie News-Monitoring summieren sich selbst kleine Verzögerungen und führen zu UI-Lag und Produktivitätsverlust.
2. Wie strukturiere ich Apollo-Listenabfragen am besten für automatisierte News-Extraktion?
Frage nur die Felder ab, die du zum Rendern der Liste brauchst (z. B. Titel, URL, Zeitstempel). Schwere Felder (wie Volltext oder Bilder) gehören in Detail-Queries. Zusätzlich solltest du paginieren, damit Payloads klein und schnell bleiben.
3. Wie verbessert der Cache von Apollo Client die Listen-Performance?
Der Apollo-Cache speichert bereits geladene Daten und kann wiederholte Abfragen sofort beantworten. Mit korrekter Normalisierung und passenden Fetch Policies (z. B. cache-and-network) werden Listenansichten deutlich schneller und die Serverlast sinkt.
4. Wie hilft Thunderbit beim News-Scraping und bei der Apollo-Integration?
Thunderbit ist ein No-Code KI-Web-Scraper, der strukturierte Newsdaten aus beliebigen Websites extrahiert. Damit kannst du die News-Extraktion automatisieren und die Daten anschließend in deine Datenbank oder GraphQL-API einspeisen – zur Nutzung mit Apollo Client.
5. Welche Tools eignen sich zum Monitoring und Troubleshooting der Apollo-Listenabfrage-Performance?
Mit den kannst du Queries, Cache-Status und Performance in Echtzeit prüfen. Ergänze das mit Observability-Dashboards (z. B. New Relic oder Uptrends), um Latenzen und Fehlerraten zu verfolgen und dein Query-Design iterativ zu verbessern.
Mehr Tipps zu Web Scraping, Automatisierung und Echtzeit-Datenworkflows findest du im – mit Deep Dives, Tutorials und den neuesten Updates rund um KI-gestützte Produktivität.
Mehr erfahren